
文章目录
本篇主要讲解一下Hive的文件格式,官方文档见《
https://cwiki.apache.org/confluence/display/Hive/FileFormats》、《
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-StorageFormatsStorageFormatsRowFormat,StorageFormat,andSerDe》
一、Hive文件存储格式
HIve的文件存储格式常见的有四种:textfile 、sequencefile、orc、parquet ,前面两种是行式存储,后面两种是列式存储。
hive的存储格式指表的数据是如何在HDFS上组织排列的。
文件格式类型存储备注使用情况TextFile文本行存储存储为纯文本文件。
TEXTFILE是默认的文件格式
,除非配置参数
hive.default.fileframe
具有不同的设置。
一般
SequenceFile二进制行存储存储为压缩序列文件。生产中基本不会用,k-v格式,比源文本格式占用磁盘更多RCFile二进制列存储存储为记录列文件格式。生产中用的少,行列混合存储,ORC是他得升级版ORC二进制列存储存储为ORC文件格式。ORC支持ACID事务和基于成本的优化器(CBO)。存储列级元数据。
生产中最常用,列式存储
Parquet二进制列存储
生产中最常用,列式存储
Avro二进制行存储生产中几乎不用JSONFILE二进制列存储Hive 4.0.0 及以上版本才支持STORED BY非hive的表,例如Hbase、Druid or Accumulo的表INPUTFORMAT and OUTPUTFORMAT自定义的文件格式
注:RCFile 和 ORCFile 并不是纯粹的列式存储,它是先基于行对数据表进行分组(行组),然后对行组进行列式存储
行存储 VS 列存储 行存储和列存储方式是指数据在磁盘中按照行或者列的方式进行组织和物理存储
行存储 –适合增加、插入、删除、修改的事务处理处理 –对列的统计分析却需要耗费大量的I/O。对指定列进行统计分析时,需要把整张表读取到内存,然后再逐行对列进行读取分析操作
列存储 –对增加、插入、删除、修改的事务处理I/O高、效率低 –非常适合做统计查询类操作,统计分析一般是针对指定列进行,只需要把指定列读取到内存进行操作
1.1、行存储与列存储
行式存储下一张表的数据都是放在一起的,但列式存储下数据被分开保存了。
行式存储:
- 优点:数据被保存在一起,insert和update更加容易
- 缺点:选择(selection)时即使只涉及某几列,所有数据也都会被读取
列式存储:
- 优点:查询时只有涉及到的列会被读取,效率高
- 缺点:选中的列要重新组装,insert/update比较麻烦
如下图,箭头的方向代表了数据是如何进行(写入)组织排列的。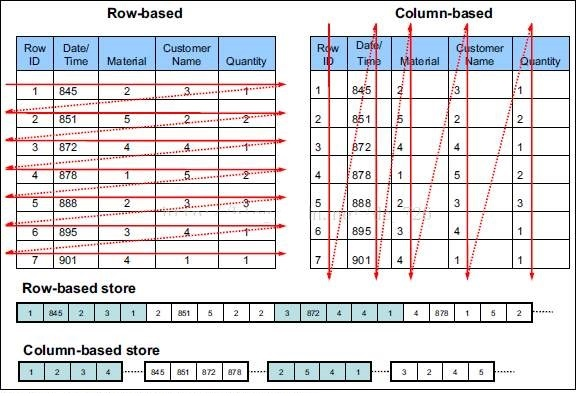
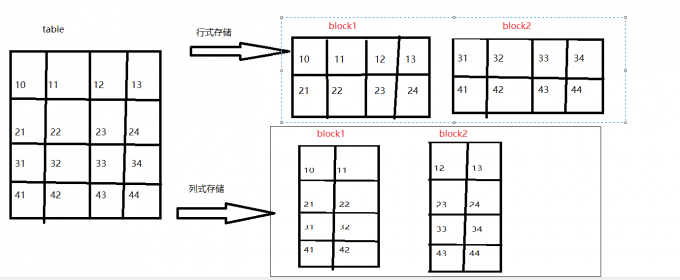
【结论:由上图可知】
- 行式存储一定会把同一行数据存到同一个块中,在select查询的时候,是对所有字段的查询,不可以单独查询某一列。
- 列式存储同一列数据一定是存储到同一个块中,换句话说就是不同的列可以放到不同块中,在进行select查询的时候可以单独查询某一列。
我们看下这几种存储结构的优缺点:
以下表格为例:
1> 水平的行存储结构:
采用行式存储时,数据在磁盘上的组织结构为:
行存储模式就是把一整行存在一起,包含所有的列,这是最常见的模式。这种结构能很好的适应动态的查询。
比如:
select a from tableA 和 select a, b, c, d, e, f, g from tableA
这样两个查询其实查询的开销差不多,都需要把所有的行读进来过一遍,拿出需要的列。
而且这种情况下,属于同一行的数据都在同一个 HDFS 块上,重建一行数据的成本比较低。
但是这样做有两个主要的弱点:
- 当一行中有很多列,而我们只需要其中很少的几列时,我们也不得不把一行中所有的列读进来,然后从中取出一些列。这样大大降低了查询执行的效率。
- 基于多个列做压缩时,由于不同的列数据类型和取值范围不同,压缩比不会太高。
2> 垂直的列存储结构:
采用列式存储时,数据在磁盘上的组织结构为:
列存储是将每列单独存储或者将某几个列作为列组存在一起。
好处:
- 列存储在执行查询时可以避免读取不必要的列。
- 而且一般同列的数据类型一致,取值范围相对多列混合更小,在这种情况下压缩数据能达到比较高的压缩比。
弱点:
- 这种结构在重建行时比较费劲,尤其当一行的多个列不在一个 HDFS 块上的时候。比如我们从第一个 DataNode 上拿到 column A,从第二个 DataNode 上拿到了 column B,又从第三个 DataNode 上拿到了 column C,当要把 A,B,C 拼成一行时,就需要把这三个列放到一起重建出行,需要比较大的网络开销和运算开销。
3> 混合的 PAX 存储结构:
PAX 结构是将行存储和列存储混合使用的一种结构,主要是传统数据库中提高 CPU 缓存利用率的一种方法,并不能直接用到 HDFS 中。但是 RCFile 和 ORC 是继承自它的思想,先按行存再按列存。
二、Hive存储格式
2.1、TextFile
TextFile 为 Hive 默认格式,建表时无需指定,一般默认这种格式,以这种格式存储的文件,可以直接在 HDFS 上 cat 查看数据。
可以用任意分隔符对列分割,建表时需要指定分隔符。
不会对文件进行压缩,因此加载数据的时候会比较快,因为不需要解压缩;但也因此更占用存储空间。
默认文件存储格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合 Gzip、Bzip2 使用,进行数据的压缩,但是使用Gzip的时候,数据不能进行切分。
stored as textfile; -- 可不指定(默认格式)
TextFile 优缺点:
- TextFile 格式因为不对导入的数据文件做处理,所以可以直接使用 load 方式加载数据,其他存储格式则不能使用 load 直接导入数据文件。所以 TextFile 的加载速度是最高的。
- TextFile 格式虽然可以使用 Gzip 压缩算法,但压缩后的文件不支持 split切分。在反序列化过程中,必须逐个字符判断是不是分隔符和行结束符,因此反序列化开销会比 SequenceFile 高几十倍。
2.2、SequenceFile
SequenceFile是Hadoop API提供的一种二进制文件格式, 文件内容是以序列化的kv对象来组织的,其具有使用方便、可分割、可压缩的特点。 SequenceFile支持三种压缩选择:none,record,block。Record压缩率低,一般建议使用BLOCK压缩。
无压缩(NONE):如果没有启用压缩(默认设置)那么每个记录就由它的记录长度(字节数)、键的长度,键和值组成。长度字段为 4 字节。
记录压缩(RECORD):记录压缩格式与无压缩格式基本相同,不同的是值字节是用定义在头部的编码器来压缩。注意:键是不压缩的。
块压缩(BLOCK):块压缩一次压缩多个记录,因此它比记录压缩更紧凑,而且一般优先选择。当记录的字节数达到最小大小,才会添加到块。该最小值由 io.seqfile.compress.blocksize 中的属性定义。默认值是 1000000 字节。格式为记录数、键长度、键、值长度、值。Record 压缩率低,一般建议使用 BLOCK 压缩。
stored as sequencefile;
设置压缩格式为块压缩:
setmapred.output.compression.type=BLOCK;
生产中基本不会用,k-v格式,比源文本格式占用磁盘更多
2.3、RCFile
RCFile 文件格式是 FaceBook 开源的一种 Hive 的文件存储格式,首先将表分为几个行组,对每个行组内的数据进行按列存储,每一列的数据都是分开存储,正是 “先水平划分,再垂直划分” 的理念。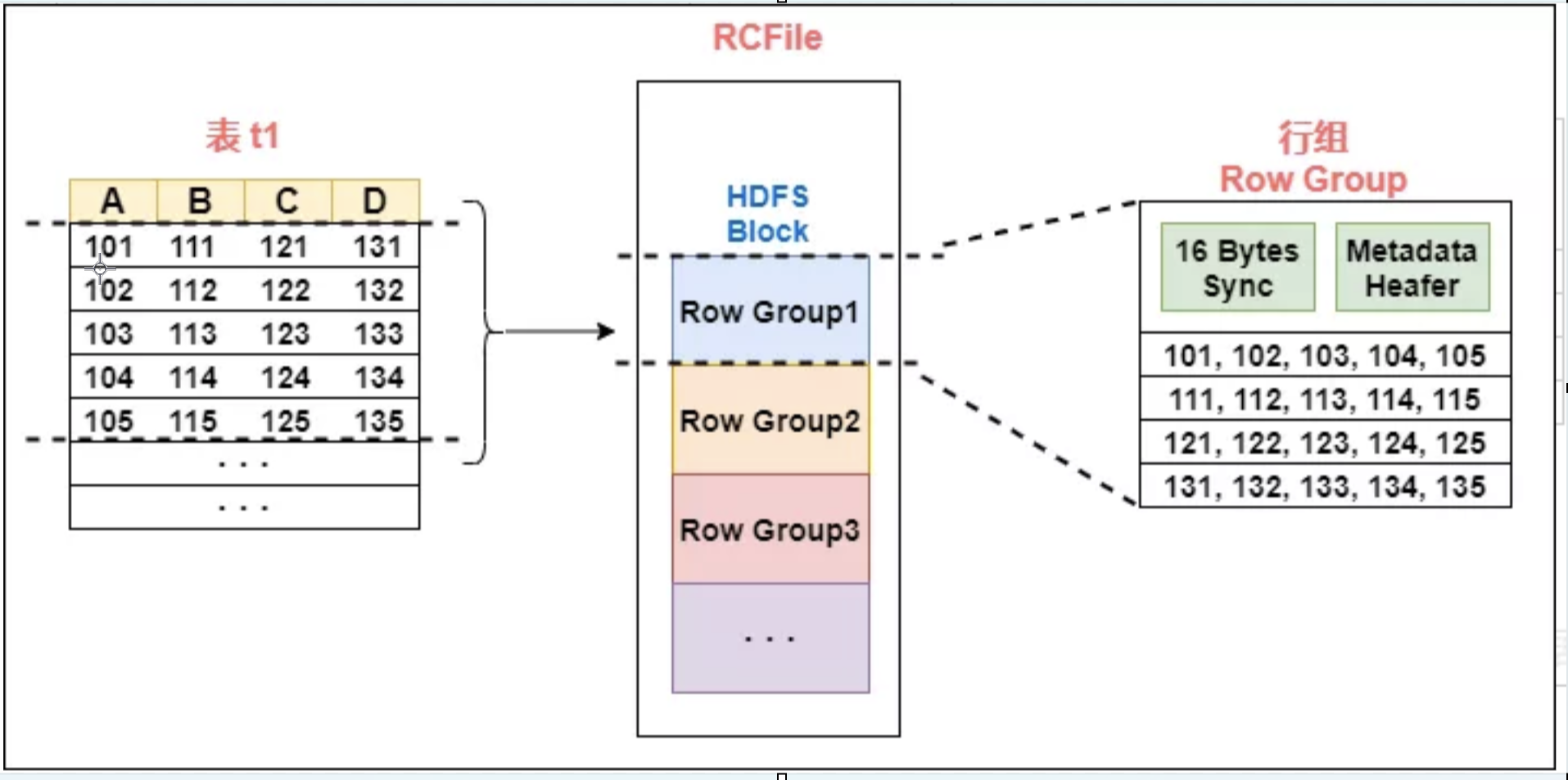
首先对表进行行划分,分成多个行组。一个行组主要包括:
- 16 字节的 HDFS 同步块信息,主要是为了区分一个 HDFS 块上的相邻行组;
- 元数据的头部信息主要包括该行组内的存储的行数、列的字段信息等等;
- 数据部分我们可以看出 RCFile 将每一行,存储为一列,将一列存储为一行,因为当表很大,我们的字段很多的时候,我们往往只需要取出固定的一列就可以。
在一般的行存储中 select a from table,虽然只是取出一个字段的值,但是还是会遍历整个表,所以效果和 select * from table 一样,在 RCFile 中,像前面说的情况,只会读取该行组的一行。
stored as rcfile;
在存储空间上:
- RCFile 是行划分,列存储,采用游程编码,相同的数据不会重复存储,很大程度上节约了存储空间,尤其是字段中包含大量重复数据的时候。 懒加载:
- 数据存储到表中都是压缩的数据,Hive 读取数据的时候会对其进行解压缩,但是会针对特定的查询跳过不需要的列,这样也就省去了无用的列解压缩。
如:
select c from table where a>1
针对行组来说,会对每个行组的a列进行解压缩,如果当前列中有 a>1 的值,然后才去解压缩 c。若当前行组中不存在 a>1 的列,那就不用解压缩 c,从而跳过整个行组。
生产中用的少,行列混合存储,ORC是他得升级版
2.4、ORCFile
ORCFile 是列式存储。
建表时需指定
STORED AS ORC
,文件存储方式为二进制文件。
Orc表支持None、Zlib、Snappy压缩,默认支持Zlib压缩。
Zlib 压缩率比 Snappy 高,Snappy 效率比 Zlib 高。
这几种压缩方式都不支持文件分割,所以压缩后的文件在执行 Map 操作时只会被一个任务所读取。
因此若压缩文件较大,处理该文件的时间比处理其它普通文件的时间要长,造成数据倾斜。
另外,
hive 建事务表需要指定为 orc 存储格式。
2.4.1-ORC相比较 RCFile 的优点
- ORC 是在一定程度上扩展了 RCFile,是对 RCFile 的优化:
- ORC 扩展了 RCFile 的压缩,除了 Run-length(游程编码),引入了字典编码和 Bit 编码。
- 每个 task 只输出单个文件,这样可以减少 NameNode 的负载; 支持各种复杂的数据类型,比如:datetime,decimal,以及一些复杂类型(struct, list, map,等);
- 文件是可切分(Split)的。在 Hive 中使用 ORC 作为表的文件存储格式,不仅节省 HDFS 存储资源,查询任务的
2.4.2-ORC的基本结构
ORCFile 在 RCFile 基础上引申出来 Stripe 和 Footer 等。每个 ORC 文件首先会被横向切分成多个 Stripe,而每个 Stripe 内部以列存储,所有的列存储在一个文件中,而且每个 stripe 默认的大小是 250MB,相对于 RCFile 默认的行组大小是 4MB,所以比 RCFile 更高效。
下图是 ORC 的文件结构示意图: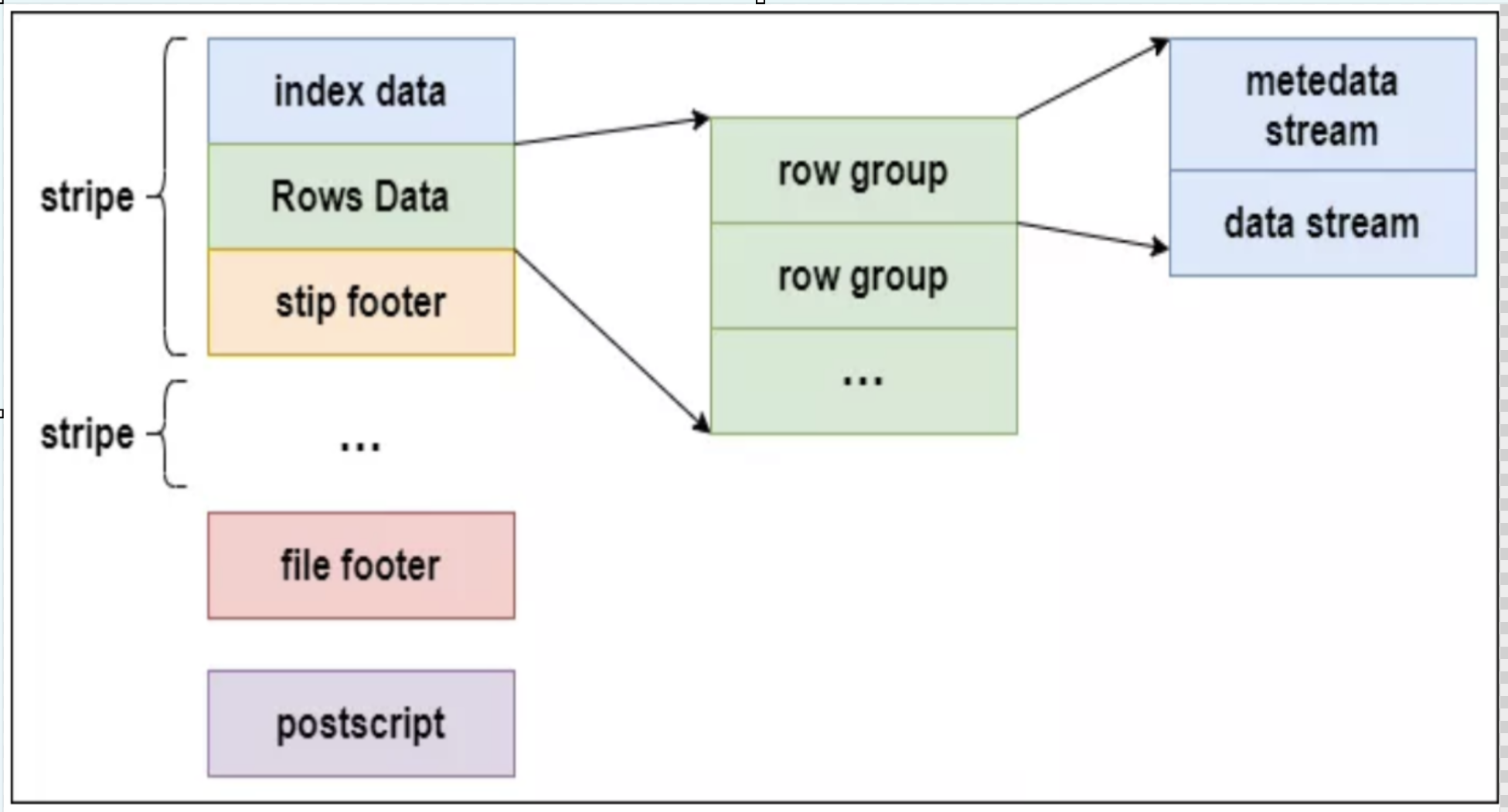
ORC 文件结构由三部分组成:
条带(stripe):ORC 文件存储数据的地方。
文件脚注(file footer):包含了文件中 stripe 的列表,每个 stripe 的行数,以及每个列的数据类型。它还包含每个列的最小值、最大值、行计数、 求和等聚合信息。
postscript:记录了Stripe的压缩类型以及FileFooter的长度信息等。
stripe 结构同样可以分为三部分:index data、rows data 和 stripe footer:
index data:一个轻量级的索引,默认每隔1W行做一个索引,记录某行的各字段在Row Data中的offset;
rows data:存储的是具体的数据,先取数据中部分行,将行按列进行存储。并对每个列进行了编码,分成多个Stream存储;
stripe footer:存储的是各个Stream的类型,长度等信息。
rows data 存储两部分的数据,即 metadata stream 和 data stream:
metadata stream:用于描述每个行组的元数据信息。
data stream:存储数据的地方。
读取文件时,先从文件尾部读取Post Script,解析到File Footer的长度,再读File Footer,解析到每个Stripe信息,获取到每个Stream的信息,随后通过Stream,以及Index进行读取数据。
生产中最常用,列式存储
2.5、Parquet
源自于googleDremel系统,Parquet相当于Google Dremel中的数据存储引擎 Apache Parquet 最初的设计动机是存储嵌套式数据,比如Protocolbuffer,thrift,json等,将这类数据存储成列式格式,以方便对其高效压缩和编码,使用更少的IO操作取出需要的数据,这也是Parquet相比于ORC的优势,它能够透明地将Protobuf和thrift类型的数据进行列式存储 存储metadata,支持schema变更
Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。
STORED AS PARQUET
可以使用的压缩方式有 UNCOMPRESSED、 SNAPPY、GZP和LZO。默认值为 UNCOMPRESSED,表示页的压缩方式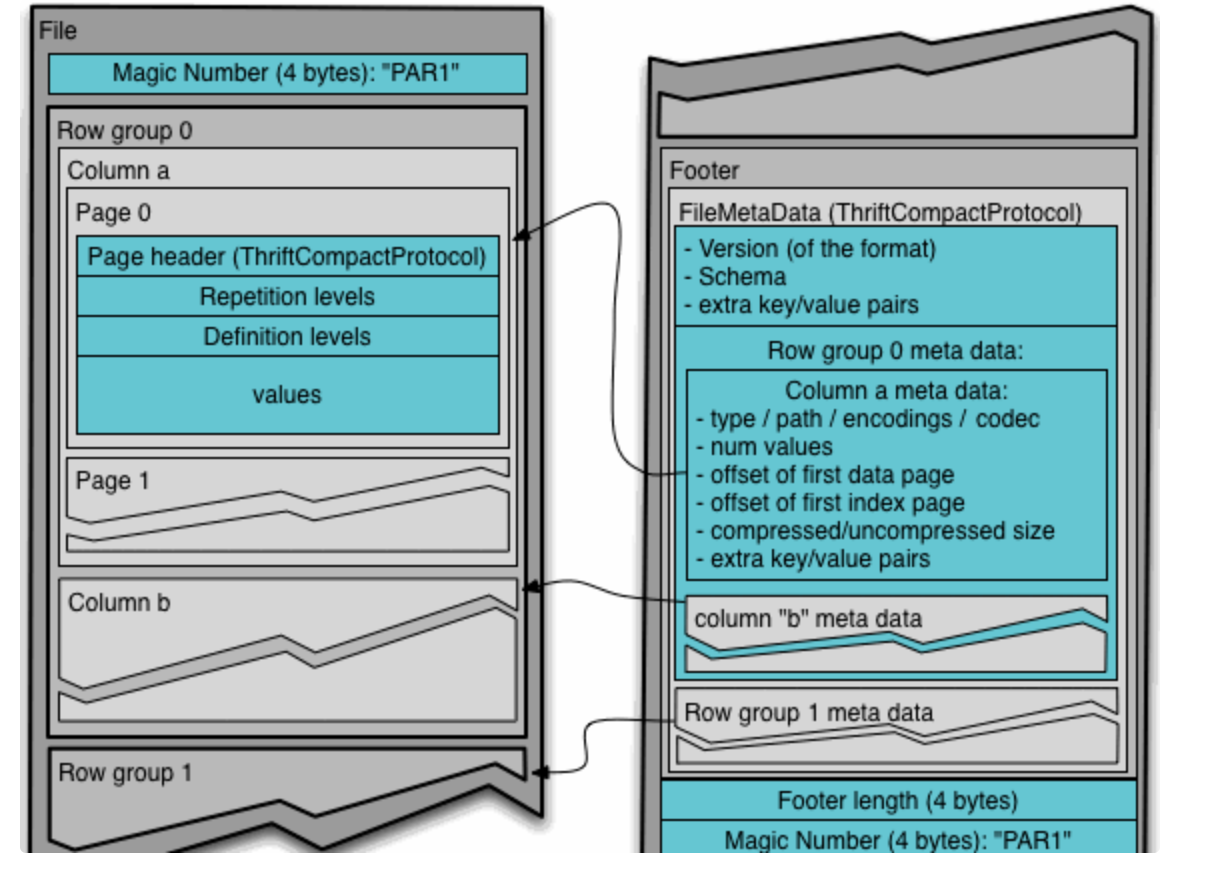
上图展示了一个Parquet文件的内容,一个文件中可以存储多个行组,
- 文件的首位是该文件的Magic Code,用于校验它是否是一个Parquet文件
- Footer length记录了文件元数据的大小,通过该值和文件长度可以计算出元数据的偏移量
- 元数据:包括行组的元数据信息和该文件存储数据的Schema信息。除了文件中每一个行组的元数据,每一页的开始都会存储该页的元数据。
- 在Parquet中,有三种类型的页:数据页、字典页和索引页。 - 数据页存储行组中该列的值;- 字典页存储该列值的编码字典,每一个列块中最多包含一个字典页- 索引页用来存储当前行组下该列的索引,目前Parquet中还不支持索引页。
生产中最常用,列式存储
2.6、Avro
Avro是一种用于支持数据密集型的二迚制文件格式。它的文件格式更为紧凑,若要读取大量数据时,Avro能够提供更好的序列化和反序列化性能。并且Avro数据文件天生是带Schema定义的,所以它不需要开发者在API 级别实现自己的Writable对象。最近多个Hadoop子项目都支持Avro 数据格式,如Pig 、Hive、Flume、Sqoop和Hcatalog
生产中几乎不用
2.7、自定义文件格式
除了默认的几种文件格式,用户还可以自定义文件格式 通过继承InputFormat和OutputFormat来自定义文件格式 创建表时指定InputFormat和OutputFormat,来读取Hive中的数据
CREATE TABLE base64example(line string) STORED AS inputformat'org.apache.hadoop.hive.contrib.fileformat.base64.Base64TextInputFormat' outputformat'org.apache.hadoop.hive.contrib.fileformat.base64.Base64TextOutputFormat';
三、Parquet 和 ORC对比
3.1、ORC和Parquet有什么区别
ORC和Parquet是两种不同的列式存储文件格式,他们的区别如下:
1.压缩比率: ORC通常比Parquet具有更高的压缩比率,因为他使用了更先进的压缩算法,如Snappy、LZO、Zlib等。 但这也导致ORC在写入时需要更高的CPU消耗。
2.读取速度: Parquet通常比ORC读取地更快,因为Parquet采用更简单和更快速的压缩算法。 但在查询和过滤性方面,ORC可能更好一点,因为它支持更复杂的谓词下推和向量化处理。
3.使用场景: ORC通常在需要高度压缩和低延迟的场景下使用,如交互式分析和实时报告。 而Parquet适用于需要高吞吐量和可伸缩性的场景,如数据仓库和批量ETL作业。
4.支持的数据类型: ORC支持较多种类的数据类型,包括Map和Array等复杂的数据类型,而Parquet支持的数据类型较少,适用于简单的数据类型。
5.支持的生态系统: Parquet被广泛地支持和采用,如sprak、hadoop、hive;ORC相对较少得到支持,只有一些特定的工具和平台使用它,如hive。
综上所述,选择ORC还是Parquet取决于具体的应用场景和需求,需要权衡数据大小、读写速度以及压缩率等因素。
3.2、Parquet 和 ORC 压缩格式对比

- ORC 表支持 None、Zlib、Snappy 压缩,默认为 ZLIB 压缩。但这 3 种压缩格式不支持切分,所以适合单个文件不是特别大的场景。使用 Zlib 压缩率高,但效率差一些;使用 Snappy 效率高,但压缩率低。
- Parquet 表支持 Uncompress、Snappy、Gzip、Lzo 压缩,默认不压缩(Uncompressed)。其中 Lzo 压缩是支持切分的,所以在表的单个文件较大的场景会选择 Lzo 格式。Gzip 方式压缩率高,效率低;而 Snappy、Lzo 效率高,压缩率低。
四、实际生产中Hive一般用什么文件格式和压缩方式?
文件格式:TextFile格式(文本文件)、ORC格式(ORC文件)、Parquet格式
压缩方式:Snappy压缩(速度快、但无法切分)、Gzip压缩
根据性能测试总结:
- 从存储文件的压缩比来看,ORC和Parquet文件格式占用的空间相对而言要小得多。
- 从存储文件的查询速度看,当表数据量较大时Parquet文件格式查询耗时相对而言要小得多。
实际情况:
根据目前主流的做法来看,Hive中选用ORC和Parquet文件格式似乎更好一点,但是为什么Hive默认的文件存储格式是TextFile?
这是因为大多数情况下源数据文件都是以text文件格式保存(便于查看验数和防止乱码),这样TextFile文件格式的Hive表能直接load data数据。如果说我们想使用ORC文件或者Parquet文件格式的表数据,可以先通过TextFile表加载后再insert到指定文件存储格式的表中。而这些不同文件格式的表我们可以通过数据分层保存,便于后期进行数据统计。
五、存储空间与执行效率的对比
这里我们根据不同的文件格式,新建测试表。
--textfile文件格式
CREATE TABLE `test_textfile`(`id` STRING,…,`desc` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS textfile;
--parquet文件格式
CREATE TABLE `test_parquet`(`id` STRING,…,`desc` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS parquet;
--orc文件格式
CREATE TABLE `test_orc`(`id` STRING,…,`desc` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS orc;
--sequence文件格式
CREATE TABLE `test_sequence`(`id` STRING,…,`desc` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS sequence;
--rc文件格式
CREATE TABLE `test_rc`(`id` STRING,…,`desc` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS rc;
--avro文件格式
CREATE TABLE `test_avro`(`id` STRING,…,`desc` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS avro;
区别比较
我们从同一个源表新增数据到这六张测试表,为了体现存储数据的差异性,我们选取了一张数据量比较大的源表(源表数据量为30000000条)。
下面从存储空间和SQL查询两个方面进行比较。
其中SQL查询为包含group by的计量统计和不含group by的计量统计。
sql01:select count(*) from test_table;
sql02:select id,count(*) from test_table group by id;
相关的查询结果如下(为了防止出现偶然性,我们每条SQL至少执行三次,取平均值)
文件存储格式HDFS存储空间不含group by含group byTextFile7.3 G105s370sParquet769.0 M
28s
195s
ORC
246.0 M
34s310sSequence7.8 G135s385sRC6.9 G92s330sAVRO8.0G240s530s
结论
从上面的测试结果可以看出
- 从占用存储空间来看,ORC和Parquet文件格式占用的空间相对而言要小得多。
- 从执行SQL效率来看,Parquet文件格式查询耗时要相对而言要小得多。
六. Hive压缩格式
在实际工作当中,hive当中处理的数据,一般都需要经过压缩,使用压缩来节省我们的MR处理的网络带宽。
6.1、mr支持的压缩格式:
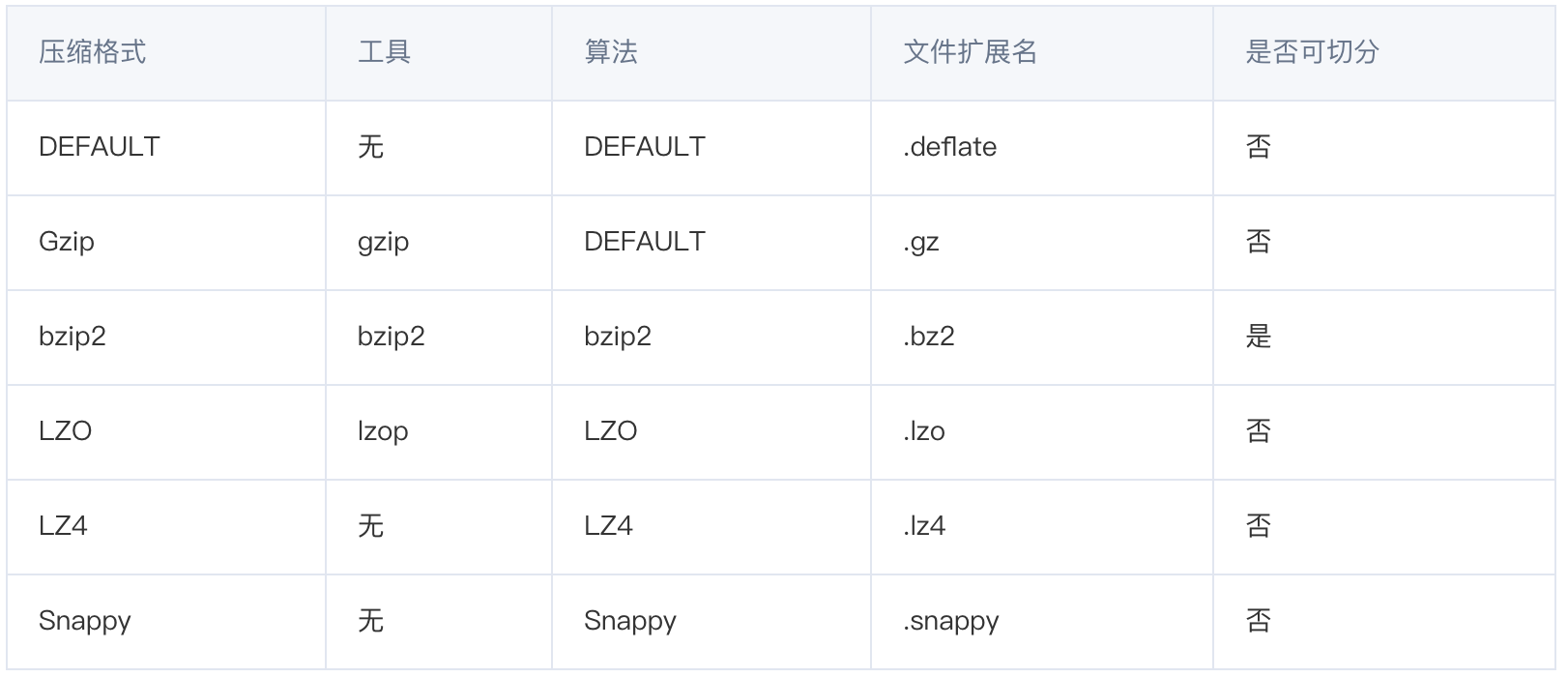
hadoop支持的解压缩的类: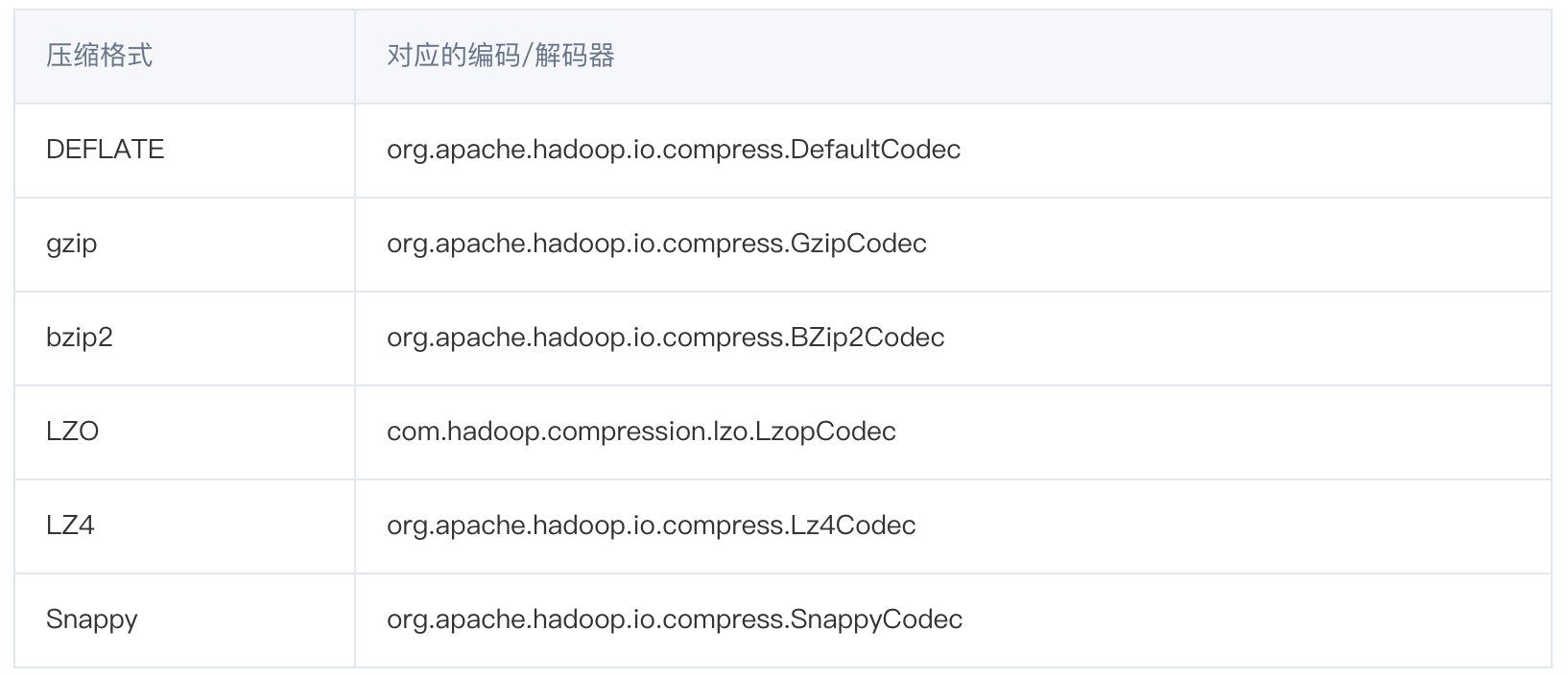
压缩性能的比较: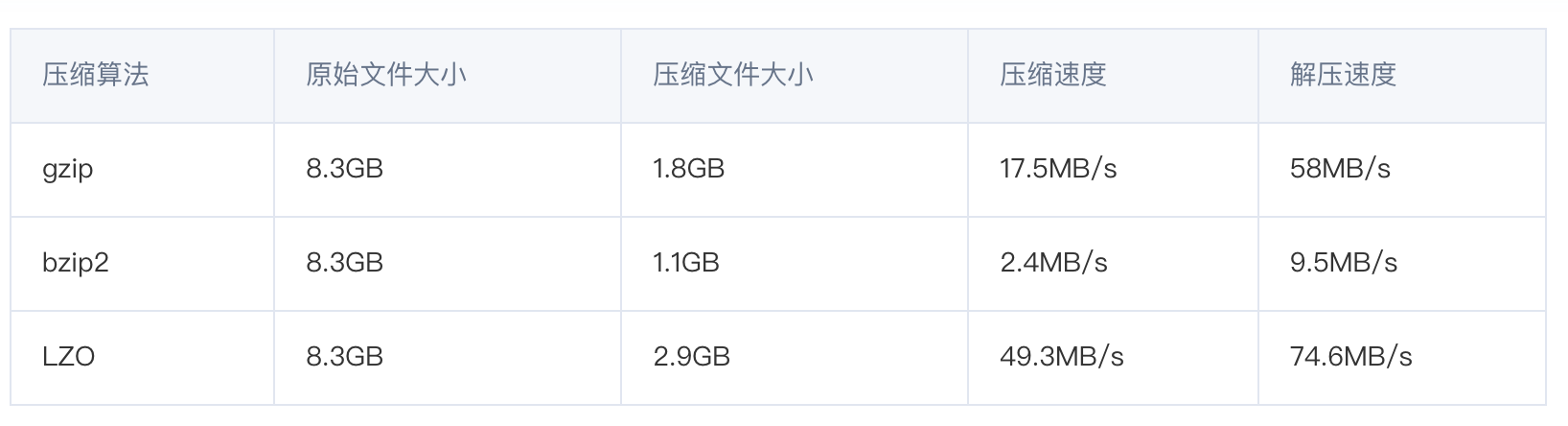
hadoop需要配置的压缩参数: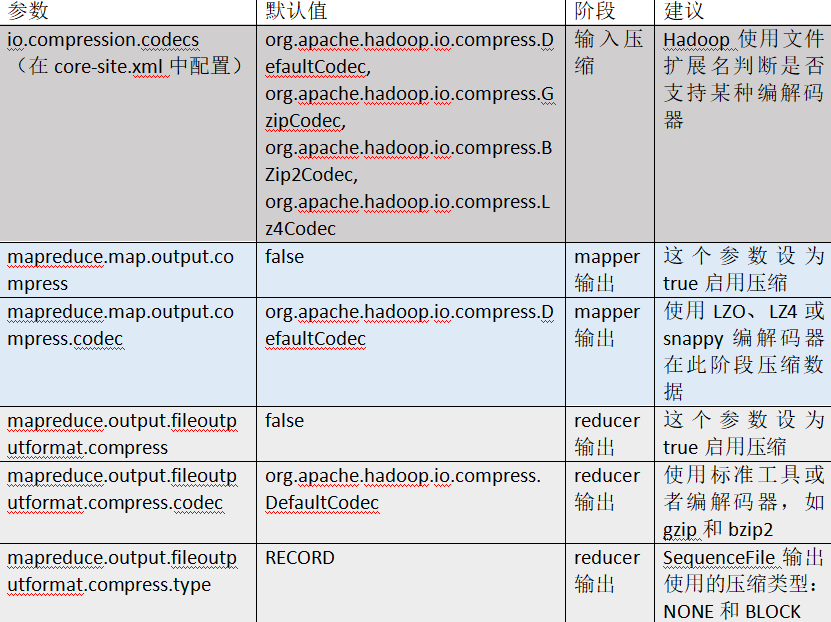
6.2、hive配置压缩的方式:
6.2.1、开启map端的压缩方式:
1.1)开启hive中间传输数据压缩功能
hive (default)>set hive.exec.compress.intermediate=true;1.2)开启mapreduce中map输出压缩功能
hive (default)>set mapreduce.map.output.compress=true;1.3)设置mapreduce中map输出数据的压缩方式
hive (default)>set mapreduce.map.output.compress.codec
= org.apache.hadoop.io.compress.SnappyCodec;1.4)执行查询语句
select count(1) from score;
6.2.2、开启reduce端的压缩方式:
1)开启hive最终输出数据压缩功能
hive (default)>set hive.exec.compress.output=true;2)开启mapreduce最终输出数据压缩
hive (default)>set mapreduce.output.fileoutputformat.compress=true;3)设置mapreduce最终数据输出压缩方式
hive (default)>set mapreduce.output.fileoutputformat.compress.codec
= org.apache.hadoop.io.compress.SnappyCodec;4)设置mapreduce最终数据输出压缩为块压缩
hive (default)>set mapreduce.output.fileoutputformat.compress.type
=BLOCK;5)测试一下输出结果是否是压缩文件
insert overwrite local directory '/export/servers/snappy'select * from score distribute by s_id sort by s_id desc;
七、hive中存储格式和压缩相结合
以ORC举例,相关配置参数: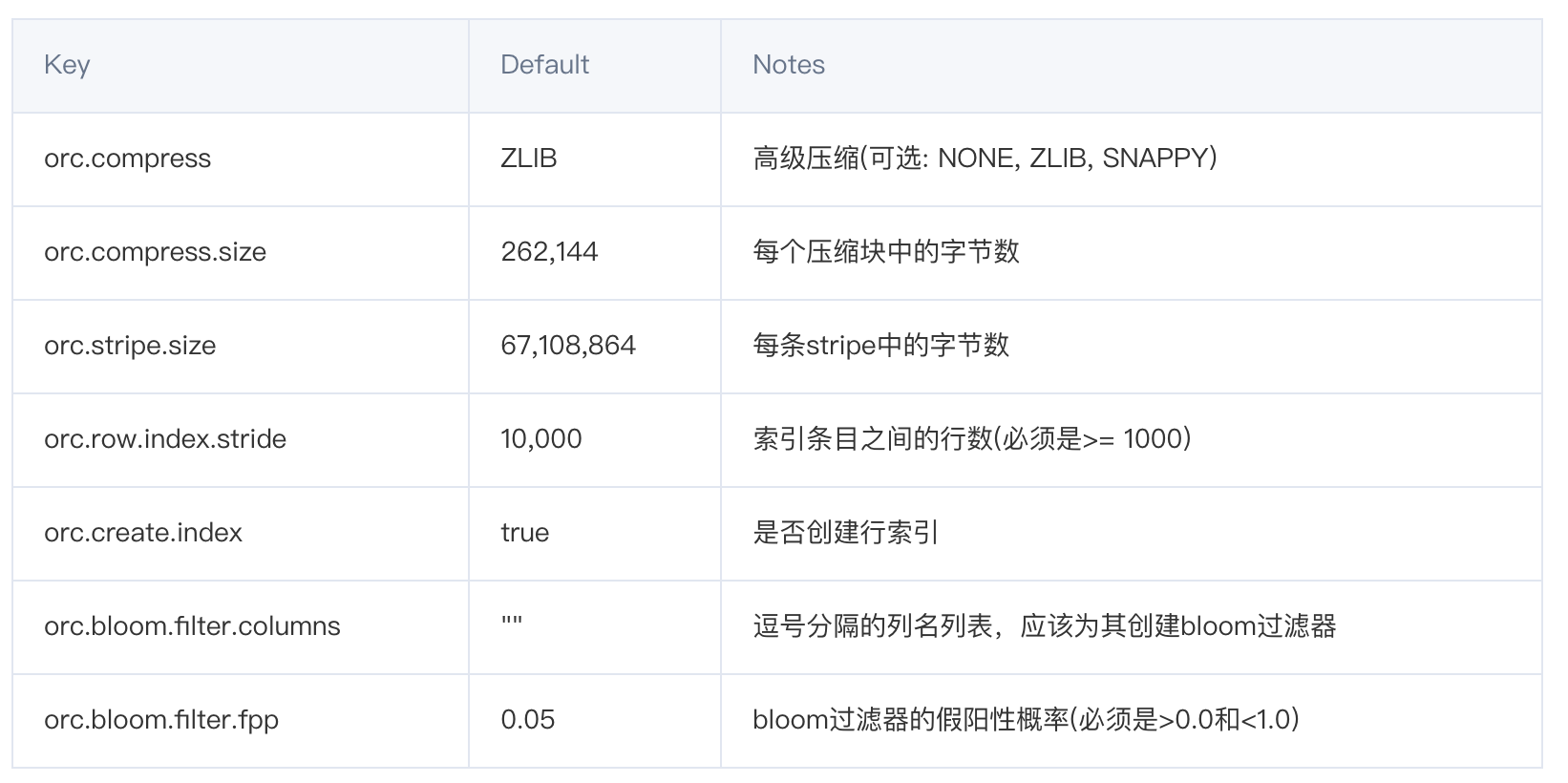
创建一个非压缩的ORC存储方式:
1)建表语句
create table log_orc_none(
track_time string,
url string,
session_id string
)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS orc tblproperties ("orc.compress"="NONE");2)插入数据
insert into table log_orc_none select * from log_text ;3)查看插入后数据
dfs -du-h /user/hive/warehouse/myhive.db/log_orc_none;
结果显示:
7.7 M /user/hive/warehouse/log_orc_none/123456_0
创建一个SNAPPY压缩的ORC存储方式:
1)建表语句
create table log_orc_snappy(
track_time string,
url string,
session_id string
)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS orc tblproperties ("orc.compress"="SNAPPY");2)插入数据
insert into table log_orc_snappy select * from log_text ;3)查看插入后数据
dfs -du-h /user/hive/warehouse/myhive.db/log_orc_snappy ;
结果显示:
3.8 M /user/hive/warehouse/log_orc_snappy/123456_0
4)实际上:默认orc存储文件默认采用ZLIB压缩。比snappy压缩率还高。
存储方式和压缩总结:
在实际的项目开发当中,hive表的数据存储格式一般选择:orc或parquet。 压缩方式一般选择snappy。
八、hive主流存储格式性能对比
从存储文件的压缩比和查询速度两个角度对比
8.1、压缩比比较
(1)创建表,存储数据格式为TEXTFILE、ORC、Parquet
create table log_text (
track_time string,
url string,
session_id string,
)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE ;
(2)向表中加载数据
load data local inpath '/export/servers/hivedatas/log.data' into table log_text ;
(3)查看表中数据大小,大小为18.1M
dfs -du-h /user/hive/warehouse/myhive.db/log_text;...
textfile:结果显示:
18.1 M /user/hive/warehouse/log_text/log.data
ORC 结果显示:
2.8 M /user/hive/warehouse/log_orc/123456_0
Parquet结果显示:
13.1 M /user/hive/warehouse/log_parquet/123456_0
数据压缩比结论: ORC > Parquet > textFile
8.2、存储文件的查询效率测试
1)textfile
hive (default)>select count(*) from log_text;
_c0
100000
Time taken: 21.54 seconds, Fetched: 1 row(s)2)orc
hive (default)>select count(*) from log_orc;
_c0
100000
Time taken: 20.867 seconds, Fetched: 1 row(s)3)parquet
hive (default)>select count(*) from log_parquet;
_c0
100000
Time taken: 22.922 seconds, Fetched: 1 row(s)
存储文件的查询效率比较: ORC > TextFile > Parquet
版权归原作者 五月天的尾巴 所有, 如有侵权,请联系我们删除。