
文章目录
1.0什么是Hadoop
1)hadoop简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。 Hadoop实现了一个分布式文件系统HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的硬件上;而且它提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算
2)hadoop优点
Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。
可靠性: Hadoop将数据存储在多个备份,Hadoop提供高吞吐量来访问应用程序的数据。
高扩展性: Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
高效性: Hadoop以并行的方式工作,通过并行处理加快处理速度。
高容错性: Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
低成本: Hadoop能够部署在低廉的(low-cost)硬件上。
2.0什么是Spark
1)spark简介
Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark拥有Hadoop MapReduce所具有的优点,Spark在Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark性能以及运算速度高于MapReduce。
2)spark优点
计算速度快: 因为spark从磁盘中读取数据,把中间数据放到内存中,,完成所有必须的分析处理,将结果写回集群,所以spark更快。
Spark 提供了大量的库: 包括Spark Core、Spark SQL、Spark Streaming、MLlib、GraphX。
支持多种资源管理器: Spark 支持 Hadoop YARN,及其自带的独立集群管理器
操作简单: 高级 API 剥离了对集群本身的关注,Spark 应用开发者可以专注于应用所要做的计算本身
3.0什么是Tez
1)Tez简介
MapReduce模型虽然很厉害,但是它不够的灵活,一个简单的join都需要很多骚操作才能完成,又是加标签又是笛卡尔积。那有人就说我就是不想这么干那怎么办呢?Tez应运起,图飞入MR。
Tez采用了DAG(有向无环图)来组织MR任务(DAG中一个节点就是一个RDD,边表示对RDD的操作)。它的核心思想是把将Map任务和Reduce任务进一步拆分,Map任务拆分为Input-Processor-Sort-Merge-Output,Reduce任务拆分为Input-Shuffer-Sort-Merge-Process-output,Tez将若干小任务灵活重组,形成一个大的DAG作业。
Tez对外提供了6种可编程组件,分别是:
Input:对输入数据源的抽象,它解析输入数据格式,并吐出一个个Key/value
Output:对输出数据源的抽象,它将用户程序产生的Key/value写入文件系统
Paritioner:对数据进行分片,类似于MR中的Partitioner
Processor:对计算的抽象,它从一个Input中获取数据,经处理后,通过Output输出
Task:对任务的抽象,每个Task由一个Input、Ouput和Processor组成
Maser:管理各个Task的依赖关系,并按顺依赖关系执行他们
2)Tez优点
Tez可以将多个有依赖的作业转换为一个作业,这样只需写一次HDFS,且中间节点较少,从而大大提升作业的计算性能。
Mr引擎:多Job串联,基于磁盘,落盘的地方比较多,虽然慢,但一定能跑出结果,一般处理:周、月、年指标。
4.0三者之间的关系
首先我们要了解到,Hadoop是具有对数据的存储和计算能力的,而Tez和Spark只对数据由计算能力,同时也会依赖Hadoop上的Hdfs和Yarn组件,因此他们三者之间的对比,应该是Hadoop中的MR与Tez、Spark之间的对比。
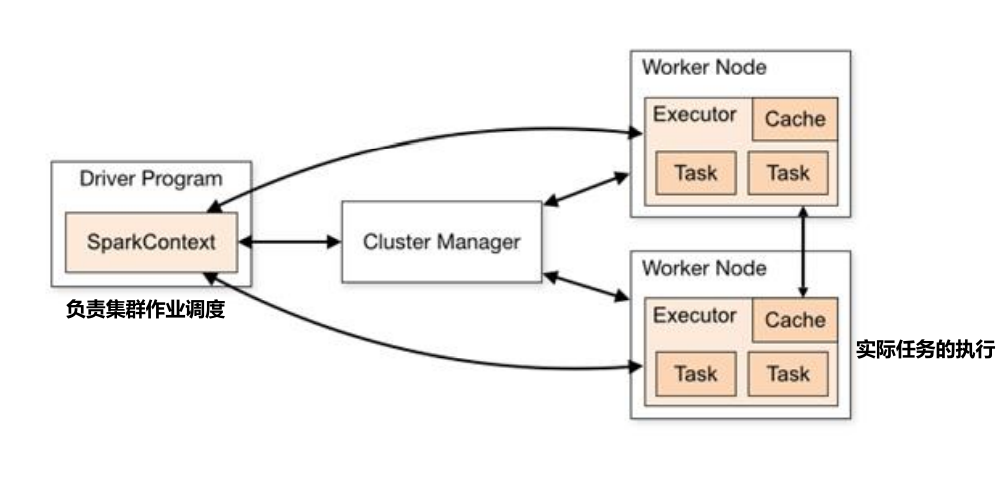
Mr运行图:
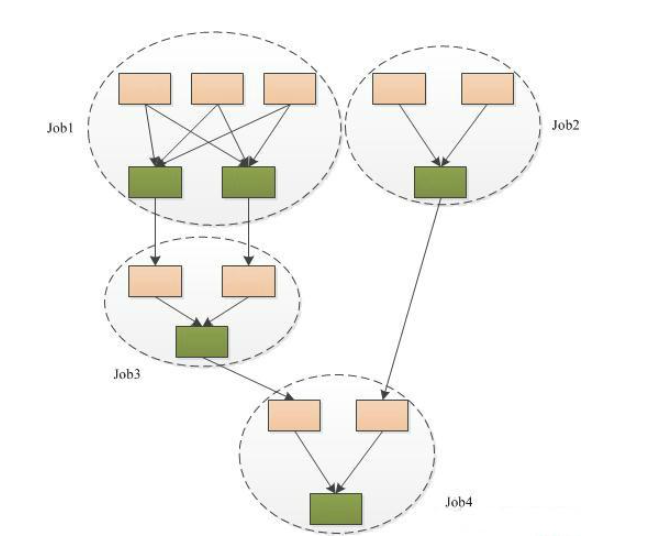
Tez工作流程图:
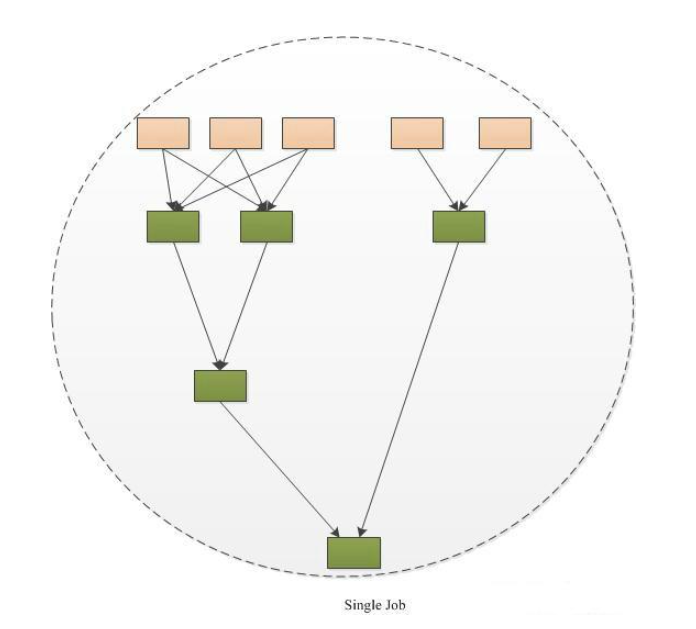
Spark运行图:
通过三张运行图,或许你已经对这三种计算框架的运行原理有了一定的理解:
在学习大数据的过程中,我们每学习一种计算框架都会首先和Mr做对比,接下来,我们也按照这样的顺序说明。
5.0Mr,Tez,Spark的对比
MR计算,会对磁盘进行多次的读写操作,这样启动多轮job的代价略有些大,不仅占用资源,更耗费大量的时间,
而采用TEZ计算框架,就会生成一个简洁的DAG作业,算子跑完不退出,下轮继续使用上一轮的算子,这样大大减少磁盘IO操作,从而计算速度更快。 TEZ比MR至少快5倍
spark号称比mr快100倍,而tez也号称比mr快100倍;二者性能都远程mr,为什么都能远超mr?使用场景有什么区别?两者各自的优势又是在哪里?
我们知道了,Tez比Mr更快,那么Spark为什么也比Tez更快呢?
mr和spark都是基于多进程的并发计算模型,但是却采用了不同的并发计算机制,Spark拥有HadoopMapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。mr是多进程单线程模型,而spark是多进程多线程模型;mr应用程序由多个独立的Task进程组成,每个task相互独立,申请资源和申请数据,再到计算完成结果存储都是独立进行的;Spark应用程序的运行环境是由多个独立的executer进程构建的临时资源池构成的,而每个executer又分为多个task进程,拥有独立的mapshuffer,reduceshuffer,而且同一个executer中的数据可以进行复用,大大提高了数据和资源的利用率,节省了大量的频繁申请资源,调用数据所浪费的性能。
参考原文:https://blog.csdn.net/lipviolet/article/details/88621034
既然这样,Spark与Tez都具有较高性能,那么Spark与Tez的区别又是什么呢?
(1)应用场景不同
- spark更像是一个通用的计算引擎,提供内存计算,实时流处理,机器学习等多种计算方式,适合迭代计算
- tez作为一个框架工具,特定为hive和pig提供批量计算
(2)各自的优势
spark属于内存计算,支持多种运行模式,可以跑在standalone,yarn上;而tez只能跑在yarn上;虽然spark与yarn兼容,但是spark不适合和其他yarn应用跑在一起
tez能够及时的释放资源,重用container,节省调度时间,对内存的资源要求率不高; 而spark如果存在迭代计算时,container一直占用资源;
总结: tez与spark两者并不矛盾,不存在冲突,在实际生产中,如果数据需要快速处理而且资源充足,则可以选择spark;如果资源是瓶颈,则可以使用tez;可以根据不同场景不同数据层次做出选择;这个总结同样也适合spark与mr的比较;
参考原文:https://blog.csdn.net/w892824196/article/details/102465885
版权归原作者 程序员小憨 所有, 如有侵权,请联系我们删除。