
一、前置知识1
顾名思义网络爬虫第一步,爬取目标 URL的网页的信息
可以使用 urllib.request 和 requests发送请求,然后返回对应的数据(py3)
1、urllib 库是 Python 内置的
2、requests 库是第三方库(需额外安装,pip install requests)
二、前置知识2
requests库的7个主要方法
方法 说明requests.request() 构造一个请求requests.get() 获取HTML网页的主要方法(即HTTP的GET)requests.head() 获取HTML网页头的信息方法(即HTTP的HEAD)requests.post() 向HTML网页提交POST请求方法(即HTTP的POST)requests.put() 向HTML网页提交PUT请求的方法(即HTTP的PUT)requests.patch() 向HTML网页提交局部修改请求(即HTTP的PATCH)requests.delete() 向HTML页面提交删除请求(即HTTP的DELETE)
语法:
requests.request(method,url,**kwargs)
注解:
1、method:请求方式(get/put/post等七种)
如resp = requests.request(‘GET’,url,**kwargs)
2、url:目标url
必选项(不可或缺)
3、**kwargs:控制访问参数(13个,为可选项)
params : 字典或字节序列,作为参数增加到url中
data : 字典、字节序列或文件对象,作为Request的内容
json : JSON格式的数据,作为Request的内容
headers : 字典,HTTP定制头(模拟浏览器进行访问)
cookies : 字典或CookieJar,Request中的cookie
files : 字典类型,传输文件
timeout : 设定超时时间,秒为单位
proxies : 字典类型,设定访问代理服务器,可以增加登录认证
allow_redirects : True/False,默认为True,重定向开关
stream : True/False,默认为True,获取内容立即下载开关
verify : True/False,默认为True,认证SSL证书开关
cert : 本地SSL证书路径
auth : 元组,支持HTTP认证功能
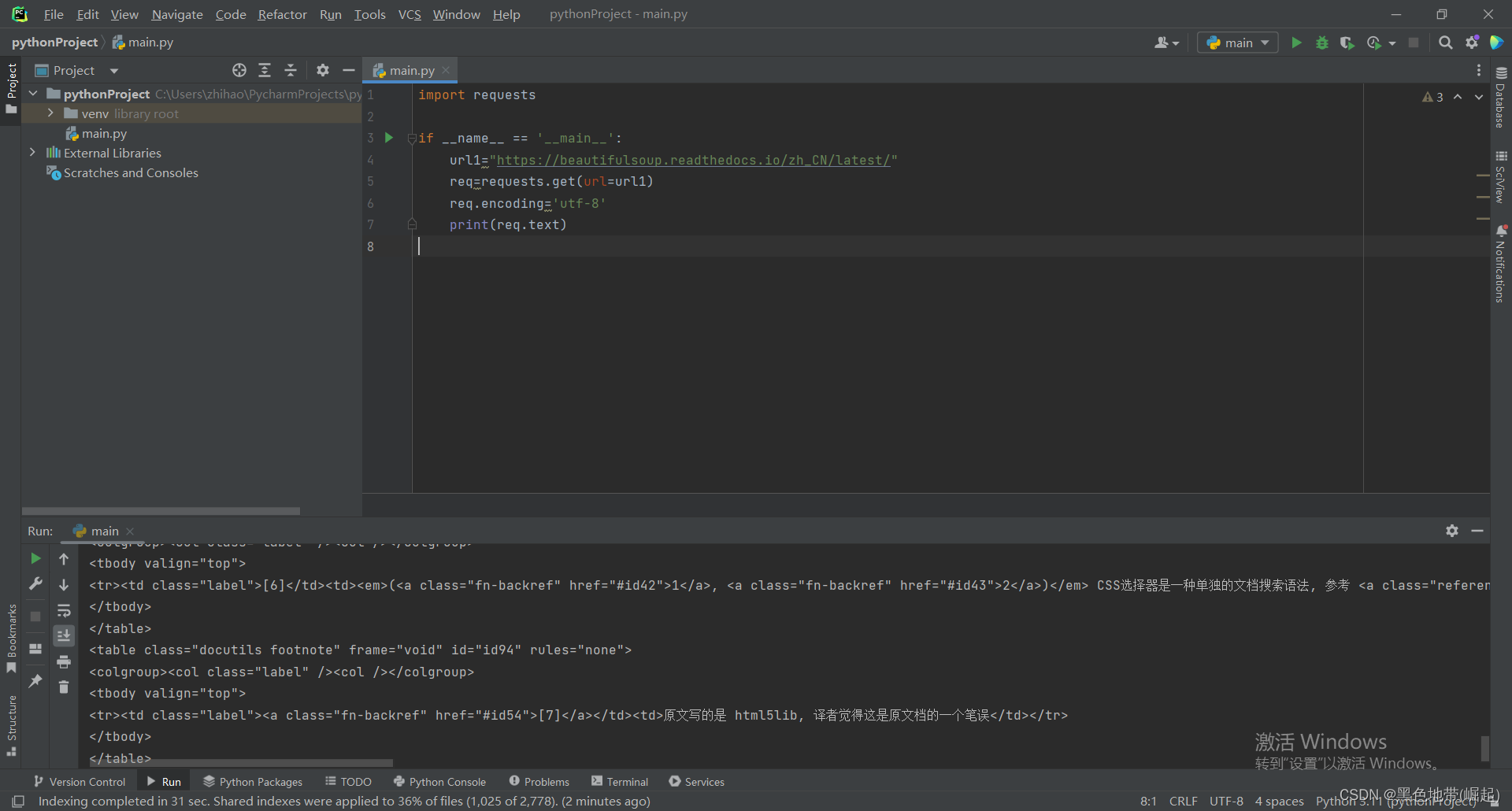
import requests
if __name__ == '__main__':
url1="https://beautifulsoup.readthedocs.io/zh_CN/latest/"
req=requests.get(url=url1)
req.encoding='utf-8'
print(req.text)
注:
导入
requests模块。
如果该脚本被直接执行(而不是被引入为模块),则执行以下操作:
- 将变量
url1赋值为"Beautiful Soup 4.4.0 文档 — beautifulsoup 4.4.0q 文档"。- 使用
requests.get()函数发送一个GET请求到url1指定的URL,并将返回的响应对象赋值给变量req。- 设置
req对象的编码为UTF-8。- 打印
req.text,即获取到的响应文本内容。
获取到的返回包内容在最下方方框中
(使用pycharm工具)
三、扩展工具
jupyter notebook工具(平时可能都习惯使用pycharm)
安装
pip3 install jupyter
查看帮助信息
jupyter notebook -h

启动
jupyter notebook
(如果端口占用的情况:jupyter notebook --port <port_number>)

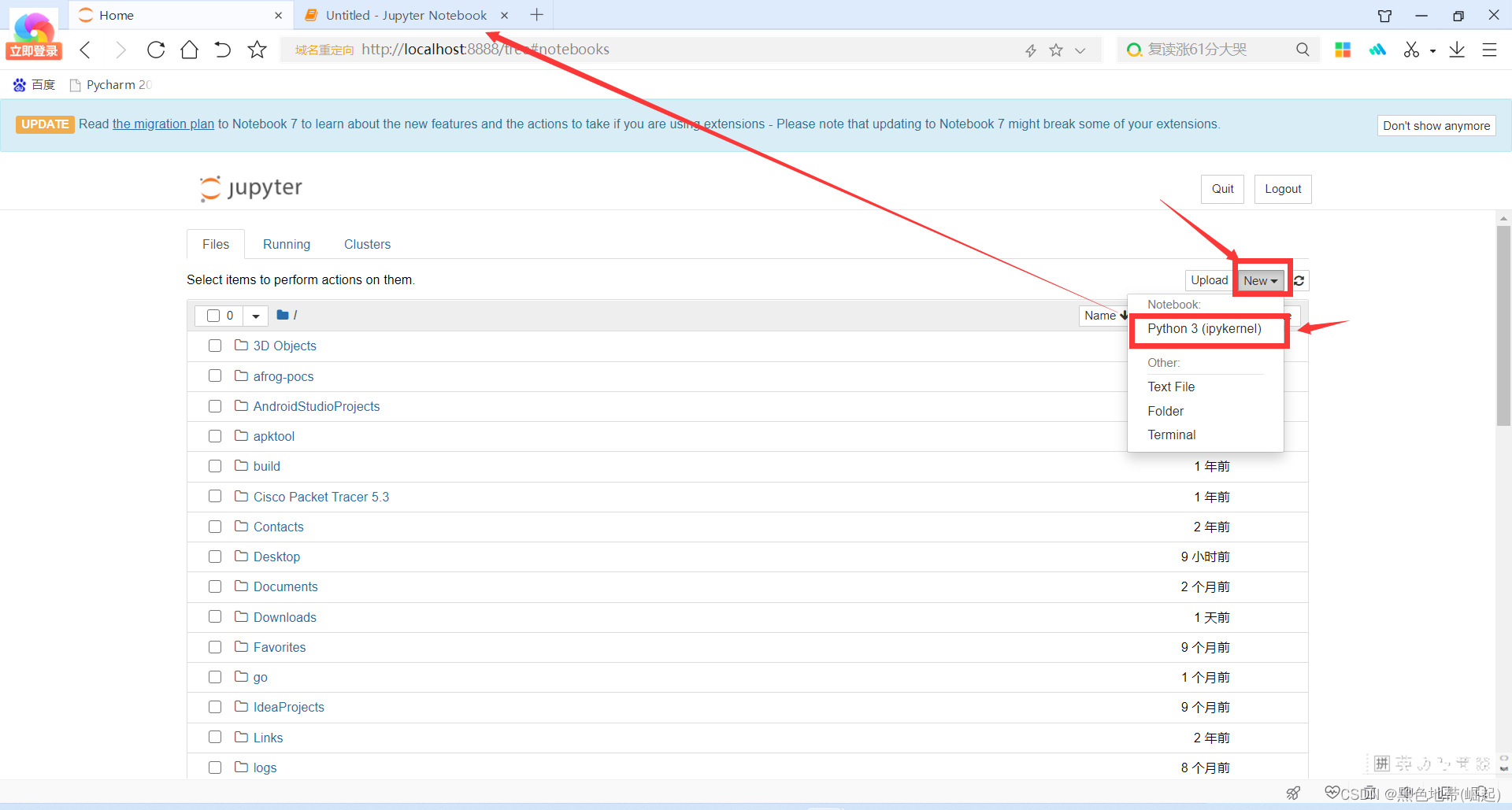
进入到了主页面
(还有很多配置,可以使界面更清爽,我只想使用软件的功能,界面想配置清爽可以查看一下软件的其他配置)
软件的使用:
如图所示点击完成以后会新建一个窗口
在里面复制代码运行即可
四、网络安全小圈子

版权归原作者 黑色地带(崛起) 所有, 如有侵权,请联系我们删除。