
这篇文章主要介绍了show create table命令执行的源码流程,弄清楚了sparksql是怎么和hive元数据库交互,查询对应表的metadata,然后拼接成最终的结果展示给用户的。
如果你正好也想了解这块,就点赞、收藏吧~
今天这篇文章也是来自于【源码共读群】的一个讨论,先上聊天:
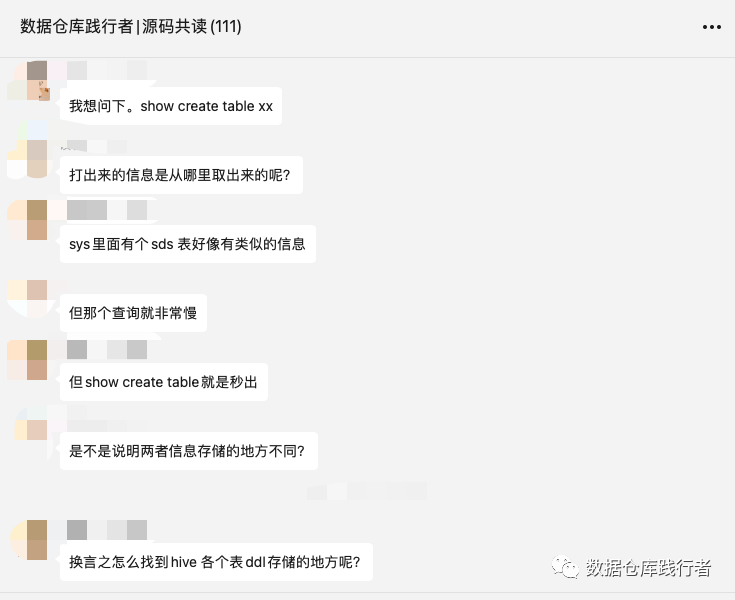
我们平时都很关注select这样的查询语句,却很少关注show create table 这样的语句的执行过程,在网上确实也很难搜到写相关内容的博客。正好借这个问题,深挖一下运行原理,于是,花2个小时,撸一遍源码,得到了基本的结论:
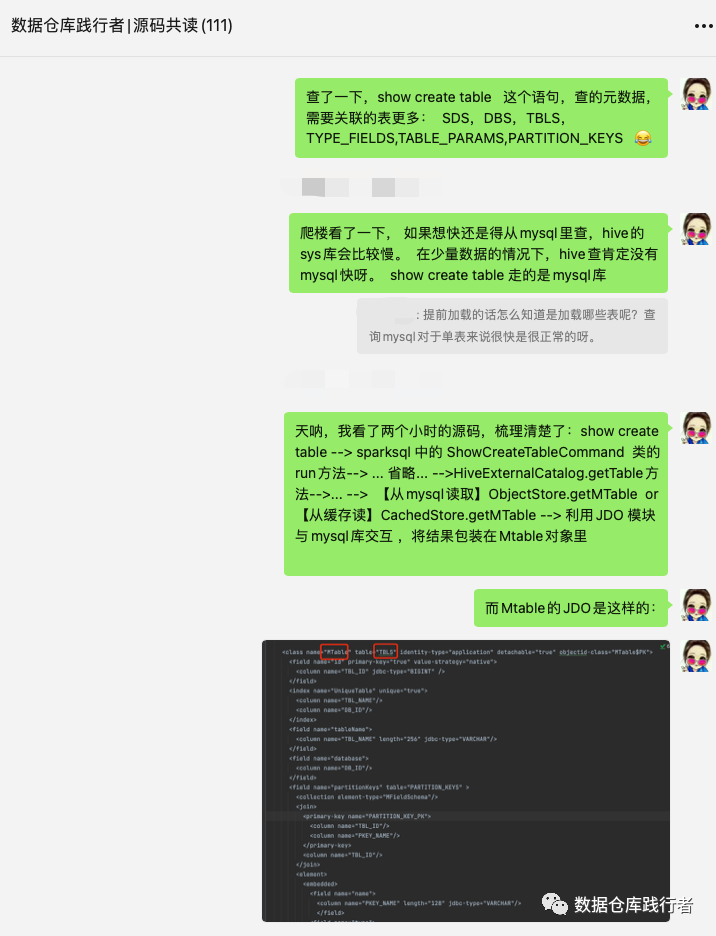


哈哈,感谢大家认可啦,群友都希望录个视频,那我先写文章,然后,再录个短屏。
下面开挖,源码是枯燥的,但也是我们能看到真相的窗口~~
本文基于spark 3.2
本文大纲
1、写能模拟从hive查表的本地测试类
2、hive中的实体类和元数据库表及字段的对应关系
3、源码分析执行过程

1、写能模拟从hive查表的本地测试类
我们在读sparksql源码时,为了方便,基本上都是用df.createOrReplaceTempView("XXX")这样的形式,来产生一些数据,这些足够我们去研究90%以上的规则,但这些不能模拟hive的情况,如果我们搭建远程连hive的环境,又会花费大量的精力。
还好,在sparksql源码工程里,我们可以通过继承TestHiveSingleton,在不用搭建hive环境的情况下,来模拟hive。
这个在【源码共读】的分享上我们会专门讲~~
测试类代码如下:

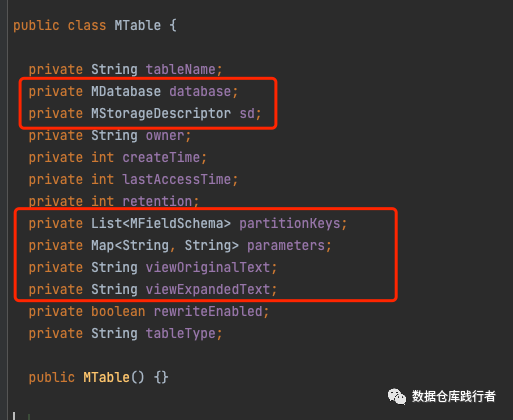
2、hive中的实体类和元数据库表及字段的对应关系
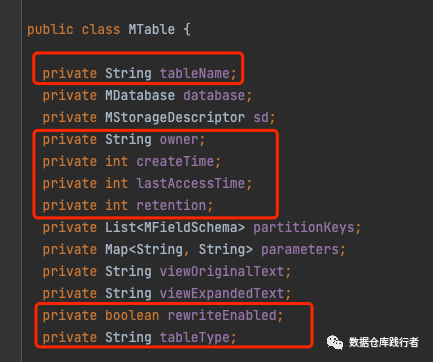
MTable(类)--> TBLS(表)
MDatabase(类)-->DBS(表)
MStorageDescriptor(类)-->SDS(表)
MFieldSchema(类)-->TYPE_FIELDS(表)
partitionKeys(MTable类中的filed) -->PARTITION_KEYS(表)
parameters (MTable类中的filed--> TABLE_PARAMS(表)
下面的配制包含了类中的字段及表字段的对应关系:
<class name="MTable" table="TBLS" identity-type="datastore" detachable="true">
<datastore-identity>
<column name="TBL_ID"/>
</datastore-identity>
<index name="UniqueTable" unique="true">
<column name="TBL_NAME"/>
<column name="DB_ID"/>
</index>
<field name="tableName">
<column name="TBL_NAME" length="256" jdbc-type="VARCHAR"/>
</field>
<field name="database">
<column name="DB_ID"/>
</field>
<field name="partitionKeys" table="PARTITION_KEYS" >
<collection element-type="MFieldSchema"/>
<join>
<primary-key name="PARTITION_KEY_PK">
<column name="TBL_ID"/>
<column name="PKEY_NAME"/>
</primary-key>
<column name="TBL_ID"/>
</join>
<element>
<embedded>
<field name="name">
<column name="PKEY_NAME" length="128" jdbc-type="VARCHAR"/>
</field>
<field name="type">
<column name="PKEY_TYPE" length="767" jdbc-type="VARCHAR" allows-null="false"/>
</field>
<field name="comment" >
<column name="PKEY_COMMENT" length="4000" jdbc-type="VARCHAR" allows-null="true"/>
</field>
</embedded>
</element>
</field>
<field name="sd" dependent="true">
<column name="SD_ID"/>
</field>
<field name="owner">
<column name="OWNER" length="767" jdbc-type="VARCHAR"/>
</field>
<field name="createTime">
<column name="CREATE_TIME" jdbc-type="integer"/>
</field>
<field name="lastAccessTime">
<column name="LAST_ACCESS_TIME" jdbc-type="integer"/>
</field>
<field name="retention">
<column name="RETENTION" jdbc-type="integer"/>
</field>
<field name="parameters" table="TABLE_PARAMS">
<map key-type="java.lang.String" value-type="java.lang.String"/>
<join>
<column name="TBL_ID"/>
</join>
<key>
<column name="PARAM_KEY" length="256" jdbc-type="VARCHAR"/>
</key>
<value>
<column name="PARAM_VALUE" length="32672" jdbc-type="VARCHAR"/>
</value>
</field>
<field name="viewOriginalText" default-fetch-group="false">
<column name="VIEW_ORIGINAL_TEXT" jdbc-type="LONGVARCHAR"/>
</field>
<field name="viewExpandedText" default-fetch-group="false">
<column name="VIEW_EXPANDED_TEXT" jdbc-type="LONGVARCHAR"/>
</field>
<field name="rewriteEnabled">
<column name="IS_REWRITE_ENABLED"/>
</field>
<field name="tableType">
<column name="TBL_TYPE" length="128" jdbc-type="VARCHAR"/>
</field>
</class>
3、源码分析执行过程
通过println,输出 show create table orders 的物理执行计划,可看到,真正执行的是ShowCreateTableCommand这个类。
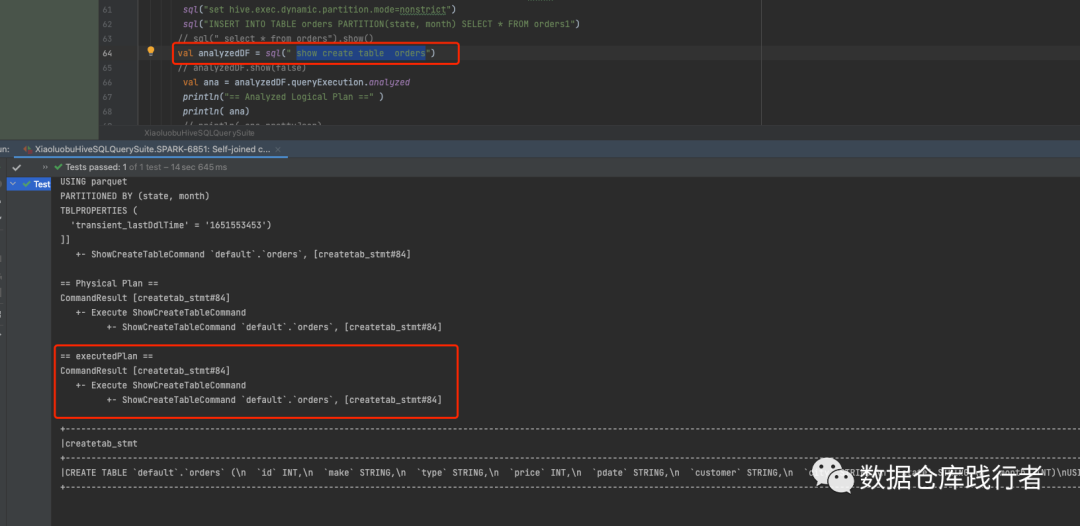
代码流程:
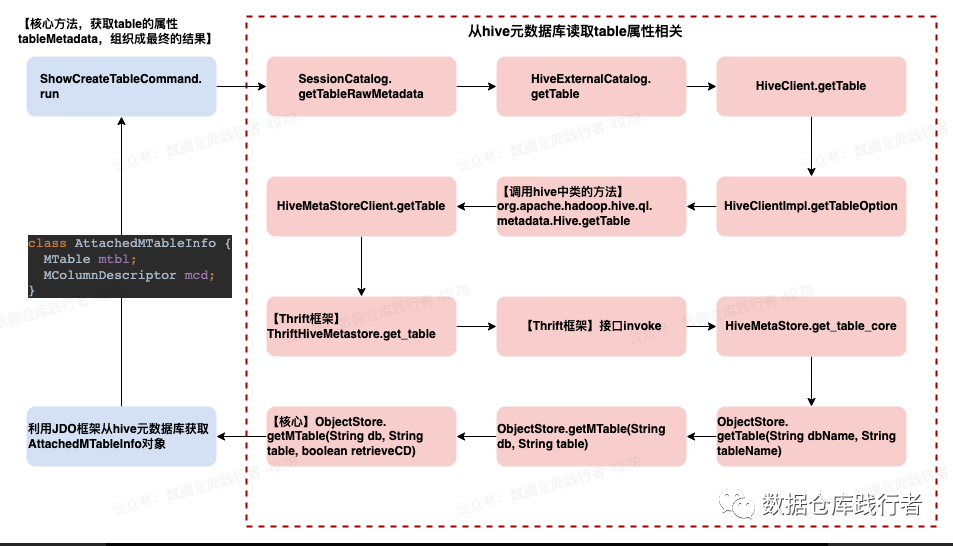
两个核心方法:
查hive元数据库(ObjectStore.getMTable)
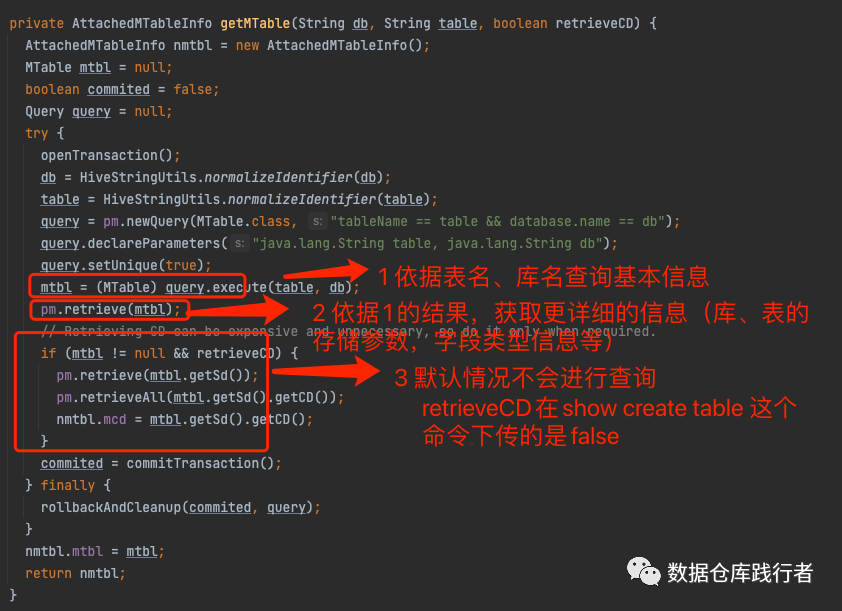
mtbl = (MTable) query.execute(table, db)对应的sql:
获取表的一些基本信息(tbl_id, tbl_type等)
SELECT
DISTINCT 'org.apache.hadoop.hive.metastore.model.MTable' AS NUCLEUS_TYPE,
A0.CREATE_TIME,
A0.LAST_ACCESS_TIME,
A0.OWNER,
A0.RETENTION,
A0.IS_REWRITE_ENABLED,
A0.TBL_NAME,
A0.TBL_TYPE,
A0.TBL_ID
FROM
TBLS A0
LEFT OUTER JOIN DBS B0 ON A0.DB_ID = B0.DB_ID
WHERE
A0.TBL_NAME = ?
AND B0."NAME" = ?
debug中的sql:
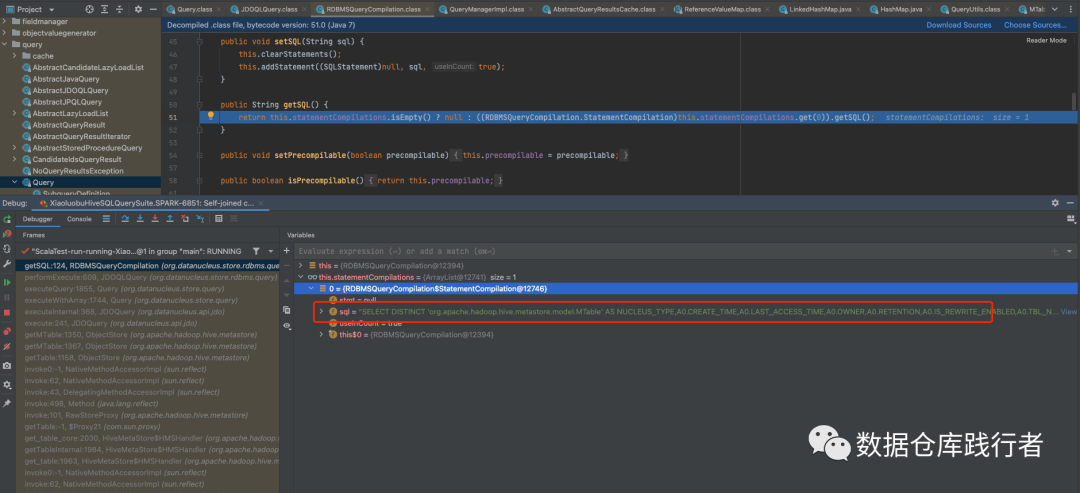
sql字段和实体类的对应关系:
debug的过程如下:
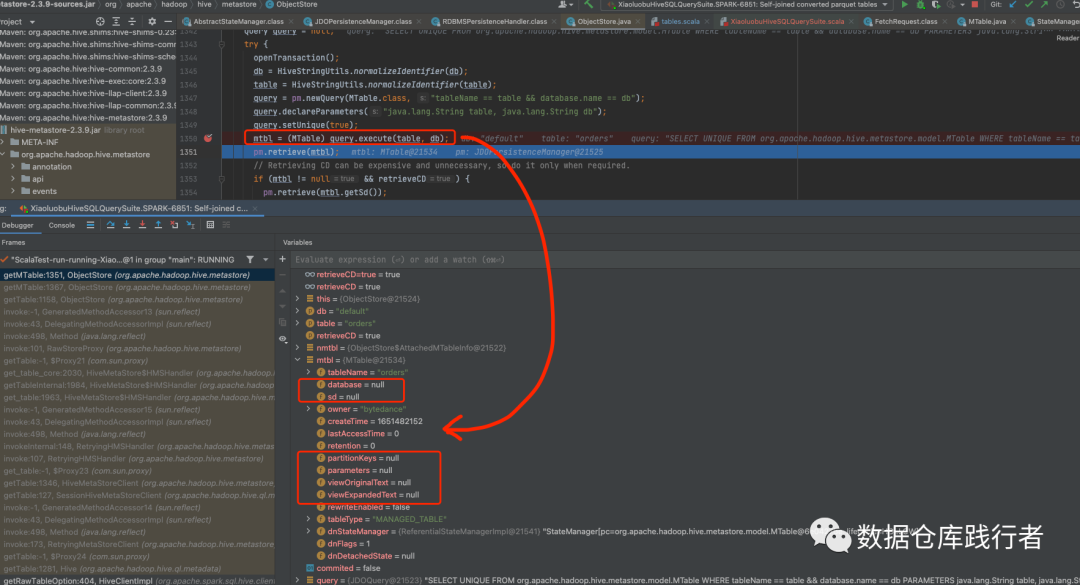
可以看到执行过该方法后,一些基本字段被填充上了
pm.retrieve(mtbl)对应的sql:
获得database(MDatabase),sd(MStorageDescriptor),parameters,partitionKeys
SELECT
B0."DESC",
B0.DB_LOCATION_URI,
B0."NAME",
B0.OWNER_NAME,
B0.OWNER_TYPE,
B0.DB_ID,
C0.INPUT_FORMAT,
C0.IS_COMPRESSED,
C0.IS_STOREDASSUBDIRECTORIES,
C0.LOCATION,
C0.NUM_BUCKETS,
C0.OUTPUT_FORMAT,
C0.SD_ID,
A0.VIEW_EXPANDED_TEXT,
A0.VIEW_ORIGINAL_TEXT
FROM
TBLS A0
LEFT OUTER JOIN DBS B0 ON A0.DB_ID = B0.DB_ID
LEFT OUTER JOIN SDS C0 ON A0.SD_ID = C0.SD_ID
WHERE
A0.TBL_ID = ?
debug中的sql:

sql字段和实体类的对应关系:
debug的过程如下:
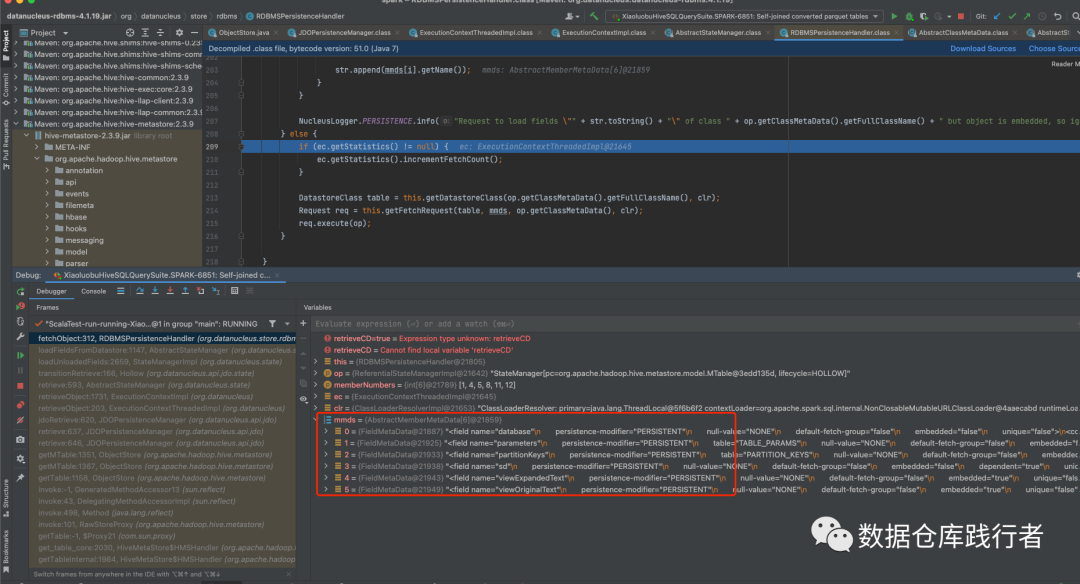
真正计算parameters,partitionKeys时,还会再经过一次回调,才能获取字段的schema:

依据的hive元数据信息,生成最终要展示的内容 (ShowCreateTableCommand.run )
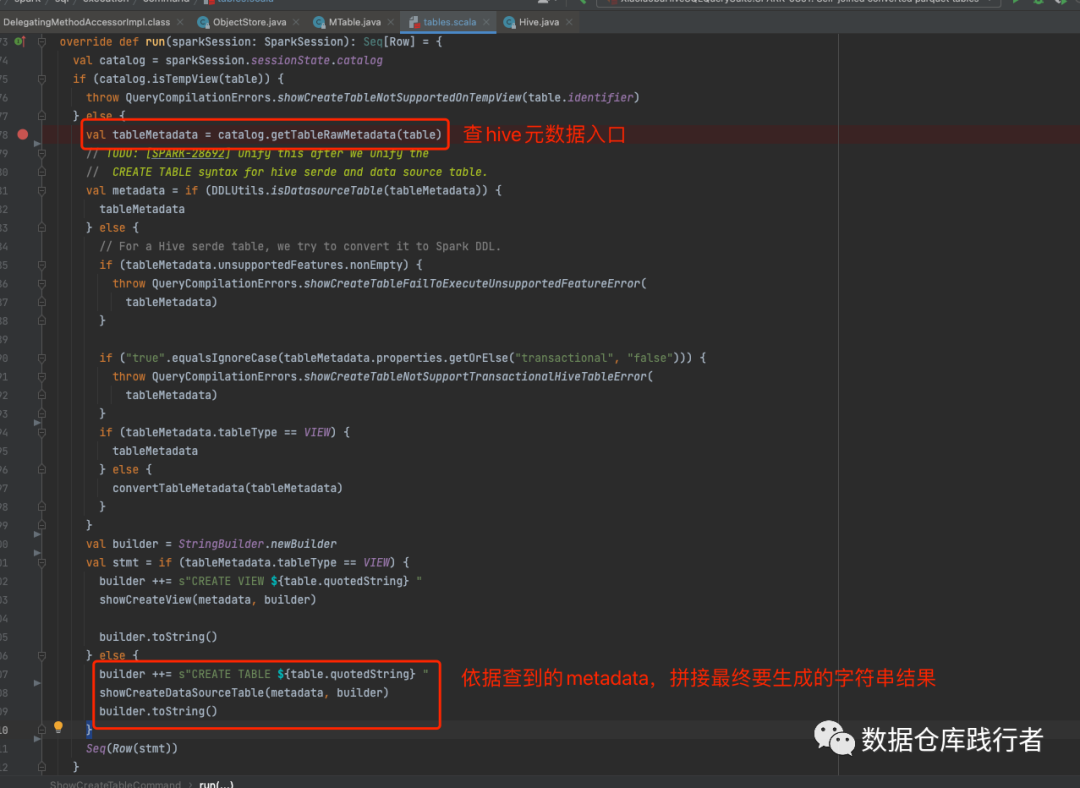
private def showCreateDataSourceTable(metadata: CatalogTable, builder: StringBuilder): Unit = {
//colums
showDataSourceTableDataColumns(metadata, builder)
//table的参数:存储格式等
showDataSourceTableOptions(metadata, builder)
showDataSourceTableNonDataColumns(metadata, builder)
//table的注释
showTableComment(metadata, builder)
//location
showTableLocation(metadata, builder)
//比如:TBLPROPERTIES
showTableProperties(metadata, builder)
}
最后拼接的结果:
CREATE TABLE `default`.`orders` (
\ n `id` INT,
\ n `make` STRING,
\ n `type` STRING,
\ n `price` INT,
\ n `pdate` STRING,
\ n `customer` STRING,
\ n `city` STRING,
\ n `state` STRING,
\ n `month` INT
) \ nUSING parquet \ nPARTITIONED BY (state, month) \ nTBLPROPERTIES (\ n 'transient_lastDdlTime' = '1651553453') \ n
读下来会有一些难度,我要给录成短视频啦,视频会同步B站和视频号~~
推荐阅读:
sparksql源码系列 | 最全的logical plan优化规则整理(spark2.3)
澄清 | snappy压缩到底支持不支持split? 为啥?
以后的事谁也说不准
转型【数仓开发】该怎么学
Hey!
我是小萝卜算子
欢迎关注:数据仓库践行者
分享是最好的学习,这里记录我对数据仓库的实践的思考和总结
每天学习一点点
知识增加一点点
思考深入一点点
在成为最厉害最厉害最厉害的道路上
很高兴认识你
版权归原作者 小萝卜算子 所有, 如有侵权,请联系我们删除。