
前言
本文内容是根据自身对相应知识的浅薄理解,如有错误欢迎指正~
大数据生态圈

Hadoop架构
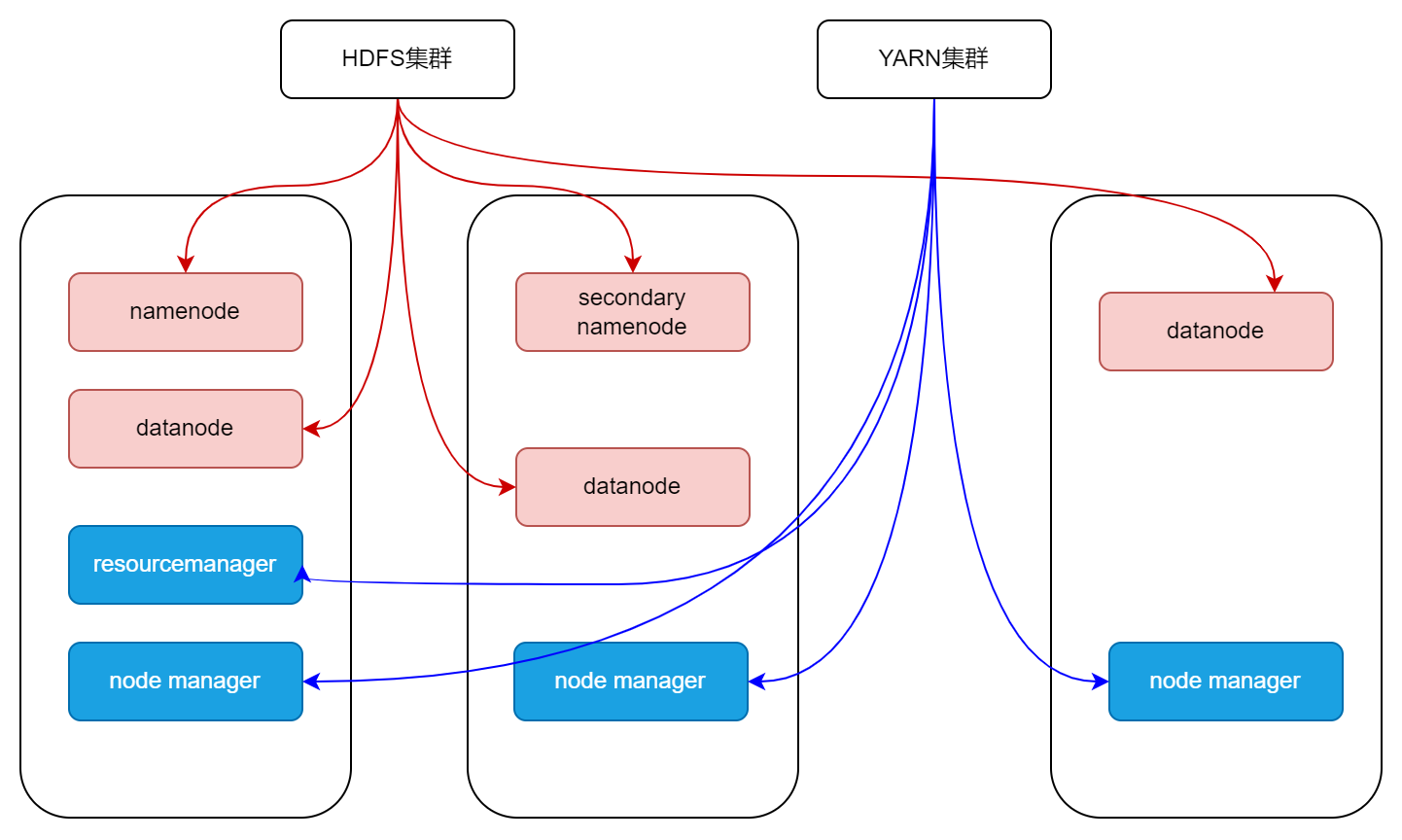
- HDFS(分布式文件系统) : 解决海量数据的存储问题
- NameNode:集群当中的主节点,管理元数据,主要用于管理集群当中的各种数据
- SecondaryNameNode:辅助Hadoop对中元数据信息的管理
- DataNode:集群当中的从节点,主要用于存储集群当中的各种数据
- MapReduce(分布式运算编程框架):解决海量数据的计算
- Map:负责数据的拆分
- Shuffile:负责数据的处理
- Reduce:负责数据的合并
- YARN(作业调度和集群资源管理的框架):解决系统任务的调度
- ResourceManager:接收用户的计算请求任务,并负责集群的资源分配和计算任务的划分
- NodeManagers:负责执行主节点ResourceManager分配的任务
Hadoop面试题汇总
ZooKeeper
HDFS
MapReduce
YARN
Hive
本文转载自: https://blog.csdn.net/weixin_42322454/article/details/127260753
版权归原作者 Kazi_1024 所有, 如有侵权,请联系我们删除。
版权归原作者 Kazi_1024 所有, 如有侵权,请联系我们删除。