
简介
hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。hive十分适合对数据仓库进行统计分析。
hive是在hadoop为基础的一个存储和计算的一款软件,他利用hadoop的hdfs分布式文件系统存储数据,然后利用hadoop的MapReduce计算数据。
hive能将hadoop中结构化的数据文件映射(元数据)为一张数据库表,然后用户只要编写hive sql,hive专注于帮我们将sql转变成MapReduce程序执行从而实现数据的分析,从而将执行结果返回给用户。如果没有hive,我们要分析hadoop中的数据,只能自己编写map和Reduce程序,然后打包,在上传jar包执行。
安装
HIve安装配置(超详细)_hive安装与配置详解_W_chuanqi的博客-CSDN博客
安装前准备
由于Apache Hive是一款基于Hadoop的数据仓库软件,通常部署运行在Linux系统之上。因此不管使用何种方式配置Hive Metastore(可以先理解为就是hive服务),必须要先保证服务器的基础环境正常,Hadoop集群健康可用。
服务器基础环境
集群时间同步、防火墙关闭、主机Host映射、免密登录、JDK安装
hadoop集群
启动Hive之前必须先启动Hadoop集群。特别要注意,需等待HDFS** 安全模式关闭之后再启动运行Hive**。
Hive不是分布式安装运行的软件,Hive只要安装在一台服务器上即可。其分布式的特性主要借由Hadoop完成。包括分布式存储、分布式计算。
Hadoop与Hive整合
因为Hive需要把数据存储在HDFS上,并且通过MapReduce作为执行引擎处理数据;
因此需要在Hadoop中添加相关配置属性,以满足Hive可以在Hadoop上运行。
修改Hadoop中core-site.xml,并且Hadoop集群同步配置文件,重启生效。
<property>
<name>hadoop.proxyuser.atguigu.groups</name>
<value>*</value>
</property>
<!--指定了允许代理用户"atguigu"代理任何用户(users),同样,*表示所有用户都被允许-->
<property>
<name>hadoop.proxyuser.atguigu.users</name>
<value>*</value>
</property>
这段Hadoop配置是为了配置代理用户(proxy user)的权限。代理用户是指一个用户被授权代表其他用户(这边应该是代理hive)执行某些操作,通常是在Hadoop集群中执行特定的任务或访问特定的资源。
在这里,配置了两个属性来指定代理用户"atguigu"的权限:
安装mysql
项目部署Linux步骤-CSDN博客
metastore服务三种安装模式
metastore服务配置有3种模式:内嵌模式、本地模式、远程模式。区分3种配置方式的关键是弄清楚两个问题:
- Metastore服务是否需要单独配置、单独启动?
- Metadata是存储在内置的derby中,还是第三方RDBMS,比如Mysql。

企业推荐模式--远程模式部署。
开始安装
# 上传解压安装包
cd /export/server/
tar zxvf apache-hive-3.1.2-bin.tar.gz
mv apache-hive-3.1.2-bin hive
#解决hadoop、hive之间guava版本差异
cd /export/server/hive
rm -rf lib/guava-19.0.jar
cp /export/server/hadoop-3.1.4/share/hadoop/common/lib/guava-27.0-jre.jar ./lib/
#添加mysql jdbc驱动到hive安装包lib/文件下
mysql-connector-java-5.1.32.jar
#修改hive环境变量文件 添加Hadoop_HOME
cd /export/server/hive/conf/
mv hive-env.sh.template hive-env.sh
vim hive-env.sh
export HADOOP_HOME=/export/server/hadoop-3.1.4
export HIVE_CONF_DIR=/export/server/hive/conf
export HIVE_AUX_JARS_PATH=/export/server/hive/lib
#新增hive-site.xml 配置mysql等相关信息
vim hive-site.xml
#添加hive的环境变量
sudo vim /etc/profile.d/my_env.sh
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin
source /etc/profile.d/my_env.sh
#初始化metadata
cd /export/server/hive
bin/schematool -initSchema -dbType mysql -verbos
#初始化成功会在mysql中创建74张表
hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--连接mysql的url-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<!--连接mysql的驱动-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!--连接mysql的用户名-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!--连接mysql的密码-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!--关闭元数据版本的验证-->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!--H2S运行绑定host-->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<!--远程模式部署metastore服务地址-->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop102:9083</value>
</property>
<!--关闭元数据存储授权-->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
</configuration>
启动hive metastore服务
远程模式下,必须首先启动Hive** metastore服务才可以使用hive**。
#前台启动 关闭ctrl+c
/export/server/hive/bin/hive --service metastore
#后台启动 进程挂起 关闭使用jps + kill
#输入命令回车执行 再次回车 进程将挂起后台
nohup /export/server/hive/bin/hive --service metastore &
#前台启动开启debug日志
/export/server/hive/bin/hive --service metastore --hiveconf hive.root.logger=DEBUG,console
元数据库乱码
Hive元数据库的字符集默认为Latin1,由于其不支持中文字符,故若建表语句中包含中文注释,会出现乱码现象。如需解决乱码问题,须做以下修改。
修改Hive元数据库中存储注释的字段的字符集为utf-8
(1)字段注释
mysql> alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
(2)表注释
mysql> alter table TABLE_PARAMS modify column PARAM_VALUE mediumtext character set utf8;
客户端连接

hive经过发展,推出了第二代客户端beeline,但是beeline客户端不是直接访问metastore服务的,而是需要单独启动hiveserver2服务。
在hive运行的服务器上,首先启动metastore服务,然后启动hiveserver2服务。
#先启动metastore服务 然后启动hiveserver2服务
nohup /export/server/hive/bin/hive --service metastore &
nohup /export/server/hive/bin/hive --service hiveserver2 &
数据类型
复杂数据类型
array
map
struct
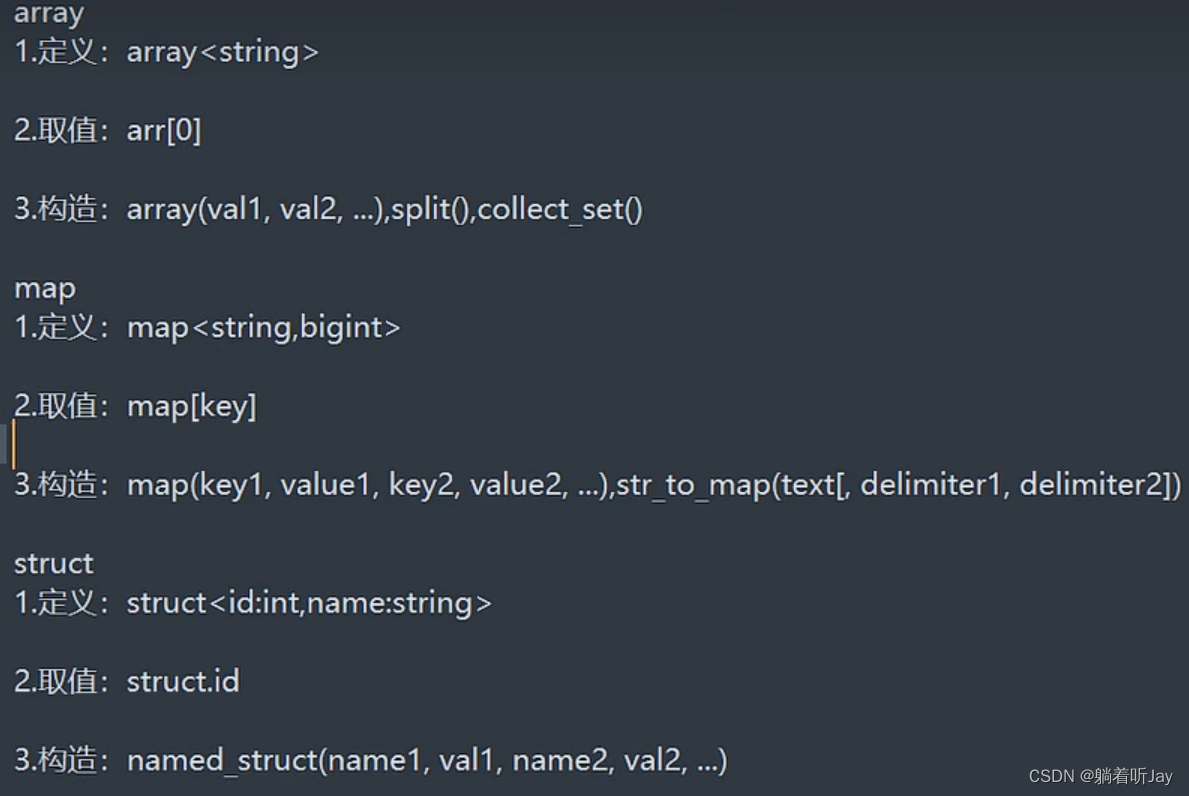
定义
`common` STRUCT<ar :STRING,ba :STRING,ch :STRING,is_new :STRING,md :STRING,mid :STRING,os :STRING,uid :STRING,vc
:STRING> COMMENT '公共信息',
版权归原作者 躺着听Jay 所有, 如有侵权,请联系我们删除。