
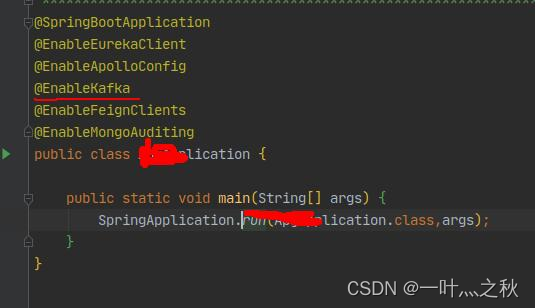
1.XXXAppication启动类中添加默认注解
2.application.properties配置文件
### kafka configure
spring.kafka.bootstrap-servers = ${kafka.ip}:9092
#spring.kafka.consumer.group-id = milestone-subscription
spring.kafka.consumer.group-id = label-common-service
spring.kafka.consumer.enable-auto-commit = false
spring.kafka.consumer.auto-offset-reset = earliest
spring.kafka.consumer.max-poll-records = 50
spring.kafka.producer.retries = 3
spring.kafka.producer.batch-size = 16384
spring.kafka.producer.buffer-memory = 33554432
spring.kafka.consumer.topic = label_generator_apg
spring.kafka.update.result.topic = label.provider.response
3.kafka配置文件
@EnableKafka
@Configuration
public class KafkaConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Value("${spring.kafka.consumer.group-id}")
private String groupId;
@Value("${spring.kafka.consumer.enable-auto-commit}")
private Boolean autoCommit;
@Value("${spring.kafka.consumer.auto-offset-reset}")
private String autoOffsetReset;
@Value("${spring.kafka.consumer.max-poll-records}")
private Integer maxPollRecords;
@Value("${spring.kafka.producer.retries}")
private Integer retries;
@Value("${spring.kafka.producer.batch-size}")
private Integer batchSize;
@Value("${spring.kafka.producer.buffer-memory}")
private Integer bufferMemory;
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = Maps.newHashMap();
props.put(ProducerConfig.ACKS_CONFIG, "0");
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.RETRIES_CONFIG, retries);
props.put(ProducerConfig.BATCH_SIZE_CONFIG, batchSize);
props.put(ProducerConfig.LINGER_MS_CONFIG, 1);
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, bufferMemory);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return props;
}
@Bean
public ProducerFactory<String, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
@Bean
public Map<String, Object> consumerConfigs() {
Map<String, Object> props = Maps.newHashMap();
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, autoCommit);
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetReset);
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, maxPollRecords);
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 120000);
props.put(ConsumerConfig.REQUEST_TIMEOUT_MS_CONFIG, 180000);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return props;
}
@Bean
public KafkaListenerContainerFactory<?> batchFactory() {
ConcurrentKafkaListenerContainerFactory<Integer, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(new DefaultKafkaConsumerFactory<>(consumerConfigs()));
//设置为批量消费,每个批次数量在Kafka配置参数中设置ConsumerConfig.MAX_POLL_RECORDS_CONFIG
factory.setBatchListener(true);
// set the retry template
// factory.setRetryTemplate(retryTemplate());
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL);
return factory;
}
}
4.消费topic,手动提交offerset
@Component
@Slf4j
public class OrderDataConsumer {
@KafkaListener(topics = "${spring.kafka.consumer.topic}",containerFactory = "batchFactory")
public void listen(List<ConsumerRecord<String,String>> records, Acknowledgment ack){
try {
log.info("====> Start of APGOrderDataConsumer");
for (ConsumerRecord<String, String> record : records) {
log.info("==> Records.offset() value is {}",record.offset());
if (JSON.parseArray(record.value()).size() > 0) {
record.value() // 获取的数据是jsonArry 后续根据业务逻辑进行处理
}else {
log.info("==>the list size of ConsumerRecord record is 0, no need to handle.");
}
}
//手动提交offset
ack.acknowledge();
log.info("==> End of APGOrderDataConsumer");
} catch (Exception e) {
log.error("==> Handel APGOrderDataConsumer fail, the exception is {} ", e);
}
}
}
本文转载自: https://blog.csdn.net/weixin_56331248/article/details/129955153
版权归原作者 一叶灬之秋 所有, 如有侵权,请联系我们删除。
版权归原作者 一叶灬之秋 所有, 如有侵权,请联系我们删除。