
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
最新最全计算机专业毕设选题精选推荐汇总
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯**基于原型学习网络的手写字识别系统**
课题背景和意义
手写字识别一直是计算机视觉领域的一个重要研究方向。随着深度学习技术的快速发展,利用神经网络进行手写字识别已取得了显著的成果。然而,传统的神经网络在处理手写字识别时面临着一些挑战,如对不同样式和形态的字体进行准确分类。手写字识别系统,旨在提高手写字识别的准确率和鲁棒性。
实现技术思路
一、算法理论基础
1.1 卷积神经网络
卷积神经网络通过卷积层和池化层的结构,卷积神经网络能够有效地捕捉和提取手写汉字中的局部特征,实现对笔画、笔迹等细节的敏感性,从而提高了识别的准确性;卷积神经网络能够自动学习特征表示,无需手动设计特征提取器,减轻了人工特征工程的负担;由于卷积层的参数共享和池化层的降采样操作,卷积神经网络具有较少的参数和计算量,能够快速训练和推理,适用于实时性要求较高的手写汉字识别系统;卷积神经网络还具有一定的平移不变性和空间不变性,能够对手写汉字在不同位置和角度的变化具有较好的鲁棒性,提高了识别的稳定性。综上所述,卷积神经网络在手写汉字系统中能够有效地捕捉局部特征、自动学习特征表示、具有较少的参数和计算量,并具备平移不变性和空间不变性,从而为手写汉字识别提供了强大的优势特点。
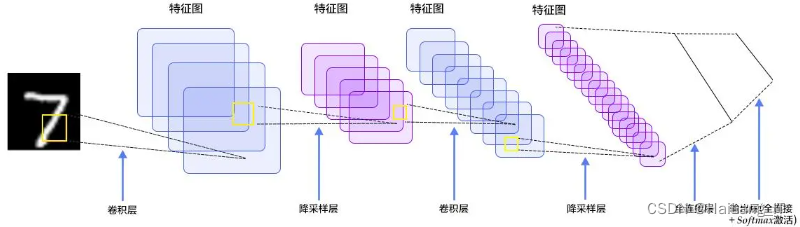
卷积神经网络(CNN)是一种深度学习模型,用于处理具有网格结构的数据,如图像和语音。它通过卷积层、池化层和全连接层构建网络结构,自动学习输入数据中的特征表示。卷积层利用可学习的滤波器对输入数据进行卷积操作,捕捉局部特征和特定模式。池化层进行下采样,减少特征图的尺寸和参数数量,保留重要的特征信息。全连接层将特征图展平并通过全连接层进行分类或回归。CNN的训练使用反向传播算法优化网络参数,可采用正则化和批归一化等技术提高模型性能。卷积神经网络在图像处理任务中具有自动学习特征、参数共享、平移不变性和空间不变性等优势,成为计算机视觉领域的重要工具。
卷积神经网络的优势体现在以下几个方面:首先,它能够自动学习具有层次结构的特征表示,避免了手动设计特征提取器的繁琐过程,提高了模型的效果和泛化能力。其次,卷积操作的参数共享和局部连接性减少了模型的参数量,降低了过拟合的风险,提高了模型的训练效率。此外,卷积神经网络具有平移不变性和空间不变性的特性,对于图像中的平移、旋转和尺度变化具有一定的鲁棒性,使得模型具备更好的泛化能力。综上所述,卷积神经网络通过高效地提取和学习特征表示,在图像处理任务中取得了显著的成果,成为计算机视觉领域中不可或缺的工具。
1.2 原型学习网络
原型学习网络是一种用于分类和识别任务的深度学习模型,它通过学习数据样本的原型表示来实现模式匹配和分类。这种网络结构在小样本学习和元学习等领域表现出色,被广泛应用于人脸识别、语音识别和自然语言处理等任务中。原型学习网络的核心思想是通过学习类别的原型表示来进行分类。在训练阶段,该网络将输入样本映射到一个低维的嵌入空间,并通过计算每个类别的原型向量来表示该类别的中心。原型向量是同一类别样本的平均值或聚类中心,它们在嵌入空间中形成了类别的原型。在测试阶段,输入样本与所有类别的原型向量进行比较,通过计算它们之间的距离或相似度来进行分类决策。
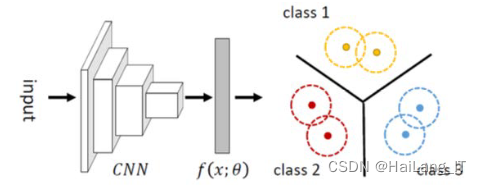
原型学习网络的训练过程可以分为两个阶段:原型构建和原型分类。在原型构建阶段,网络学习将样本映射到嵌入空间,并计算每个类别的原型向量。常用的嵌入方法包括欧氏距离、余弦相似度等。在原型分类阶段,网络根据输入样本与原型向量之间的距离或相似度进行分类决策。常用的分类方法包括最近邻分类和软近邻分类。原型学习网络在小样本学习和元学习任务中具有许多优势。首先,它能够通过原型向量捕捉类别的中心和代表性特征,从而在小样本情况下实现准确的分类。其次,原型学习网络具有较少的参数量和计算复杂度,训练和推理效率高。此外,原型学习网络还具有较好的泛化能力,能够适应新类别的样本。
二、 数据集
2.1 数据集
由于网络上缺乏现有的合适的数据集,我们决定使用网络爬取的方式自行收集手写字数据。我们编写了爬虫程序,从各种在线资源中收集了大量包含不同风格和形态的手写字图像。通过这种方式,我们能够获得真实且多样化的手写字样本,为我们的研究提供更准确、可靠的数据。我们相信这个自制的数据集将为手写字识别系统的研究提供有力的支持,并对该领域的发展做出积极贡献。
2.2 数据扩充
为了增加数据样本的多样性和数量,我们对收集到的手写字图像进行了数据扩充。采用了旋转、缩放、平移等变换操作,生成了更多变体的手写字样本。此外,为了进行监督学习,我们对数据集进行了标注,人工为每个样本标注了对应的字母或数字标签。这样的数据扩充和标注工作为我们的手写字识别系统的训练和评估提供了基础。
三、实验及结果分析
3.1 实验环境搭建
实验环境使用Windows操作系统,并利用Python作为主要的编程语言进行算法和模型的实现。使用PyTorch作为深度学习框架,构建和训练神经网络模型。借助Pandas等库,完成数据的加载、处理和转换。这样的实验环境提供了一个方便和高效的平台,用于开发和测试算法系统。
3.2 模型训练
手写字识别系统的设计思路如下:
- 数据准备:首先,我们需要准备一个手写字数据集,其中包含各种不同字母和数字的手写样本。这个数据集可以包括多个人的手写样本,以增加样本的多样性和泛化能力。每个样本都要经过预处理步骤,如图像归一化、去噪和标准化,以确保输入数据的一致性和可比性。
- 原型学习网络架构:接下来,我们构建基于原型学习网络的模型架构。该网络由多个卷积层、池化层和全连接层组成。卷积层和池化层用于提取手写字图像的特征,全连接层用于将提取的特征映射到嵌入空间中的原型向量。嵌入空间中的每个原型向量代表一个字母或数字的类别。
- 原型构建:在训练阶段,我们使用原型学习网络将手写字样本映射到嵌入空间,并计算每个类别的原型向量。原型向量可以通过计算每个类别样本的平均值或聚类中心来得到。这些原型向量将成为模型对应每个类别的中心表示。
- 原型分类:在测试阶段,我们使用输入的手写字图像与所有类别的原型向量进行比较。通过计算输入图像与每个原型向量之间的距离或相似度,我们可以确定输入图像属于哪个类别。通常,使用最近邻分类或软近邻分类的方法进行判断。根据距离或相似度的大小,选择最匹配的类别作为识别结果。
- 模型训练和优化:在训练过程中,我们使用已标记的手写字样本来训练原型学习网络。通过反向传播算法和损失函数,优化网络参数以最小化预测误差。可以使用一些优化技术,如随机梯度下降法(SGD)或自适应学习率算法(如Adam)来加速训练过程和提高模型性能。
- 模型评估和改进:完成训练后,我们需要评估模型在测试数据集上的性能。可以使用指标如准确率、召回率和F1分数来评估模型的分类性能。根据评估结果,我们可以进一步改进模型,如调整网络架构、增加训练数据量或调整超参数等,以提高模型的准确性和泛化能力。
相关代码示例:
# 导入必要的库
import numpy as np
from sklearn.metrics.pairwise import euclidean_distances
# 定义原型学习网络类
class PrototypicalNetwork:
def __init__(self, num_classes, num_prototypes_per_class):
self.num_classes = num_classes
self.num_prototypes_per_class = num_prototypes_per_class
self.prototypes = None
def train(self, X_train, y_train):
# 初始化原型向量矩阵
self.prototypes = np.zeros((self.num_classes, self.num_prototypes_per_class, X_train.shape[1]))
# 对每个类别计算原型向量
for class_id in range(self.num_classes):
# 选择当前类别的训练样本
class_samples = X_train[y_train == class_id]
# 随机选择原型样本
prototype_indices = np.random.choice(len(class_samples), self.num_prototypes_per_class, replace=False)
# 计算原型向量
self.prototypes[class_id] = class_samples[prototype_indices]
def predict(self, X_test):
# 初始化预测结果列表
y_pred = []
# 对测试样本进行预测
for sample in X_test:
# 计算测试样本与所有原型向量的距离
distances = euclidean_distances([sample], self.prototypes.reshape(-1, self.prototypes.shape[-1]))
# 将距离转化为相似度,这里使用倒数作为相似度度量
similarities = 1 / (1 + distances)
# 对于每个类别计算平均相似度
class_similarities = np.mean(similarities.reshape(self.num_classes, self.num_prototypes_per_class), axis=1)
# 预测样本所属类别为相似度最高的类别
predicted_class = np.argmax(class_similarities)
y_pred.append(predicted_class)
return y_pred
海浪学长项目示例:



最后
我是海浪学长,创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!
本文转载自: https://blog.csdn.net/qq_37340229/article/details/137431270
版权归原作者 HaiLang_IT 所有, 如有侵权,请联系我们删除。
版权归原作者 HaiLang_IT 所有, 如有侵权,请联系我们删除。