
本案例软件包:链接:https://pan.baidu.com/s/1zABhjj2umontXe2CYBW_DQ
提取码:1123(若链接失效在下面评论,我会及时更新).
(1)安装Spark
1.先用xftp将安装包传到home/hadoop/Downloads文件夹下,然后解压安装。
2.解压缩:
sudo tar -zxf spark-2.1.0-bin-without-hadoop.tgz -C /usr/local
3. 更改文件夹名称:
cd /usr/local
sudo mv spark-2.1.0-bin-without-hadoop spark
4.修改hadoop用户对文件夹spark的访问权限:
sudo chown -R hadoop:hadoop ./spark
(2)配置
1.复制一份由Spark安装文件自带的配置文件模板:
cd /usr/local/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
vim ./conf/spark-env.sh
2.使用vim编辑器打开spark-env.sh,再第一行添加配置信息:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
3.验证Spark安装是否成功:
cd /usr/local/spark
bin/run-example SparkPi 2>&1 | grep "Pi is roughly"

如图所示:返回结果:Pi is roughly 3.144115720578603
既安装成功!!!
4. 启动HDFS后,Spark可以对HDFS中的数据进行读写。
(3)Spark-shell的启动
1.启动
cd /usr/local/spark
./bin/spark-shell
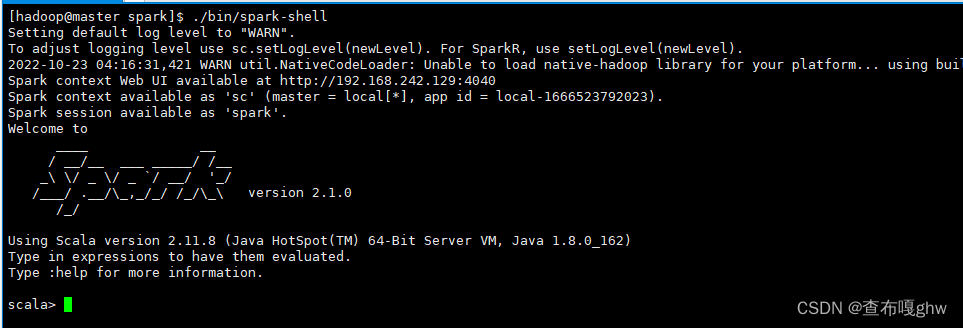
2. 读取文件,统计行数
scala> val textFile = sc.textFile("file:///usr/local/spark/README.md")
scala> textFile.count()

返回结果如上图所示!!!
(3) Spark集群环境搭建
1.按照上面的(1)部分安装与配置完spark
2.配置环境变量
在master(主节点)配置环境变量
sudo vim ~/.bashrc
在.bashrc文件中增加:
#spark
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SCALA_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin
使用source命令使配置生效:
source ~/.bashrc
3.配置Spark
a:在master(主机)配置slaves文件
cd /usr/local/spark
cp ./conf/slaves.template ./conf/slaves
在salves文件中设置Spark集群的Worker节点
[hadoop@master spark]$ vim ./conf/slaves
添加以下内容:

b: 在master节点配置spark-env.sh文件
[hadoop@master spark]$ cp ./conf/spark-env.sh.template ./conf/spark-env.sh
编辑spark-env.sh文件:
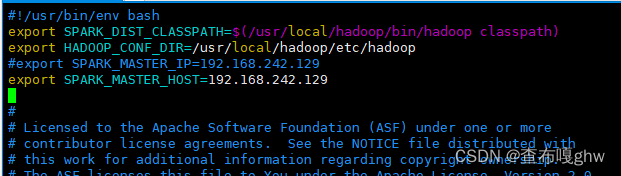
[hadoop@master spark]$ vim ./conf/spark-env.sh
#!/usr/bin/env bash
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
#export SPARK_MASTER_IP=192.168.242.129 //自己maser的IP
export SPARK_MASTER_HOST=192.168.242.129
c:配置slave节点
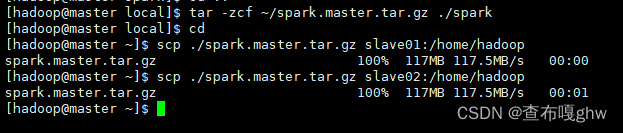
启动slave01和slave02节点,然后,在master节点执行如下命令,将master节点的/usr/local/spark文件夹复制到各个slave节点:
[hadoop@master local]$ tar -zcf ~/spark.master.tar.gz ./spark
[hadoop@master local]$ cd
[hadoop@master ~]$ scp ./spark.master.tar.gz slave01:/home/hadoop
[hadoop@master ~]$ scp ./spark.master.tar.gz slave02:/home/hadoop
在slave01和slave02节点上分别执行如下命令(下面以slave01为例):
sudo rm -rf /usr/local/spark
sudo tar -zcf sparm.master.tar.gz -C /usr/local
sudo chown -R hadoop:hadoop /usr/local/spark
4.启动spark
在master主机上启动hdfs yarn
在master上再启动spark
cd /usr/local/spark
sbin/start-master.sh
sbin/start-slaves.sh
如下图已开启spark进程
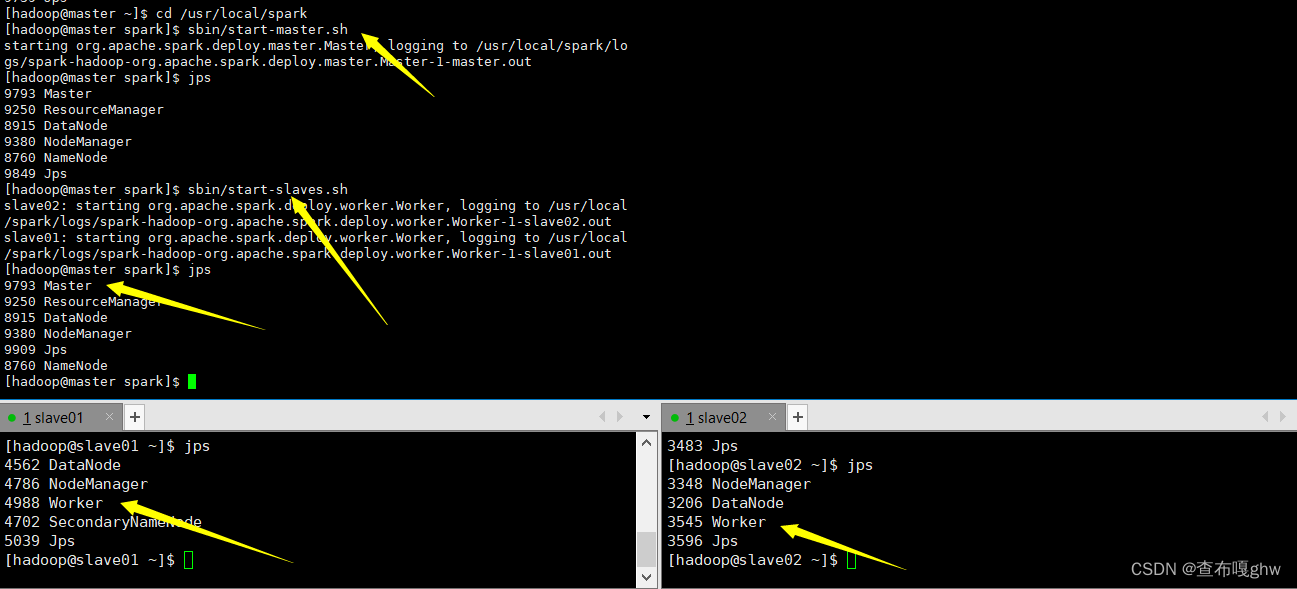
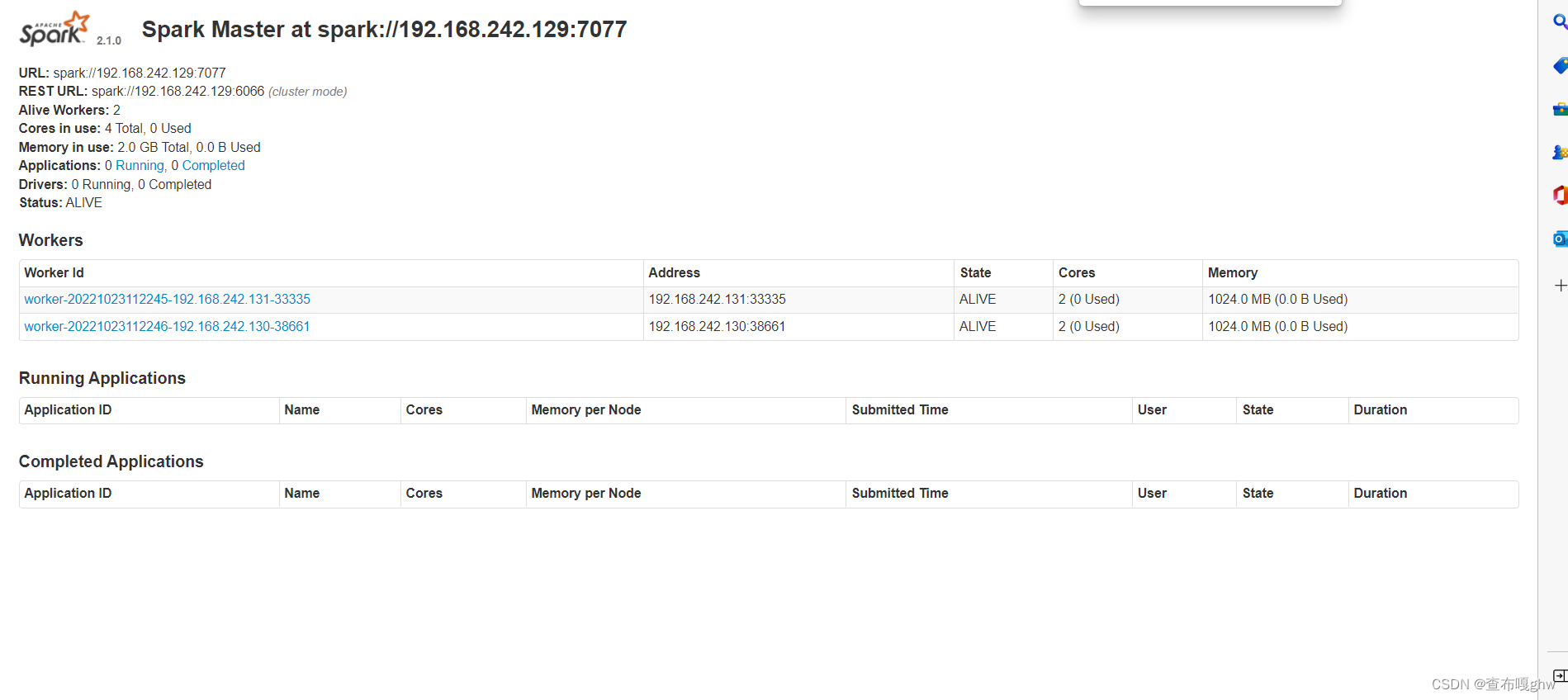
测试:链接http://192.168.242.129:8080
在master节点上,通过浏览器查看集群信息有两个worker
5.关闭spark
stop-master.sh
stop-slaves.sh
stop-yarn.sh
stop-dfs.sh
本文转载自: https://blog.csdn.net/ghw666666666/article/details/127472243
版权归原作者 查布嘎ghw 所有, 如有侵权,请联系我们删除。
版权归原作者 查布嘎ghw 所有, 如有侵权,请联系我们删除。