
一、整体流程
每个Aciton操作会创建一个JOB,JOB会提交给DAGScheduler,DAGScheduler根据RDD依赖的关系划分为多个Stage,每个Stage又会创建多个TaskSet,每个TaskSet包含多个Task,这个Task就是每个分区的并行计算的任务。DAGScheduler将TaskSet按照顺序提交给TaskScheduler,TaskScheduler将每一个任务去找SchedulerBackend申请执行所需要的资源,获取到资源后,SchedulerBackend将这些Task提交给Executor,Executor负责将这些任务运行起来。

二、JOB提交
2.1、为什么需要action操作
在Spark中,分为transformation操作和action操作。执行用户程序时,transformation操作将一个RDD转换成了新的RDD,并在compute()函数中,记录了如何根据父RDD计算出当前RDD的数据、RDD如何分区等信息,并且能够得出最后一个RDD的数据。 但是RDD中的每个分区中依然是一条一条的分散的数据,那么要对最后一个RDD执行什么操作呢?这就是action操作的作用。
2.2、Job提交
每个action操作都会生成一个Job,这个Job包含了需要计算的RDD对象、需要计算的分区、需要执行什么样的计算。RDD和用户执行的计算都是可以序列化的,RDD序列化之后,在Executor中反序列化之后即可得到该RDD对象,再根据对象compute()函数就可以计算出某个分区的数据。JOB中包含的数据如下所示
2.3、分布式执行
当提交Job以后,就可以将Job划分为多个并行的任务,每个任务计算指定分区的一个分区即可。通过RDD的计算函数即可计算出该分区的数据,今儿计算出分区的结果。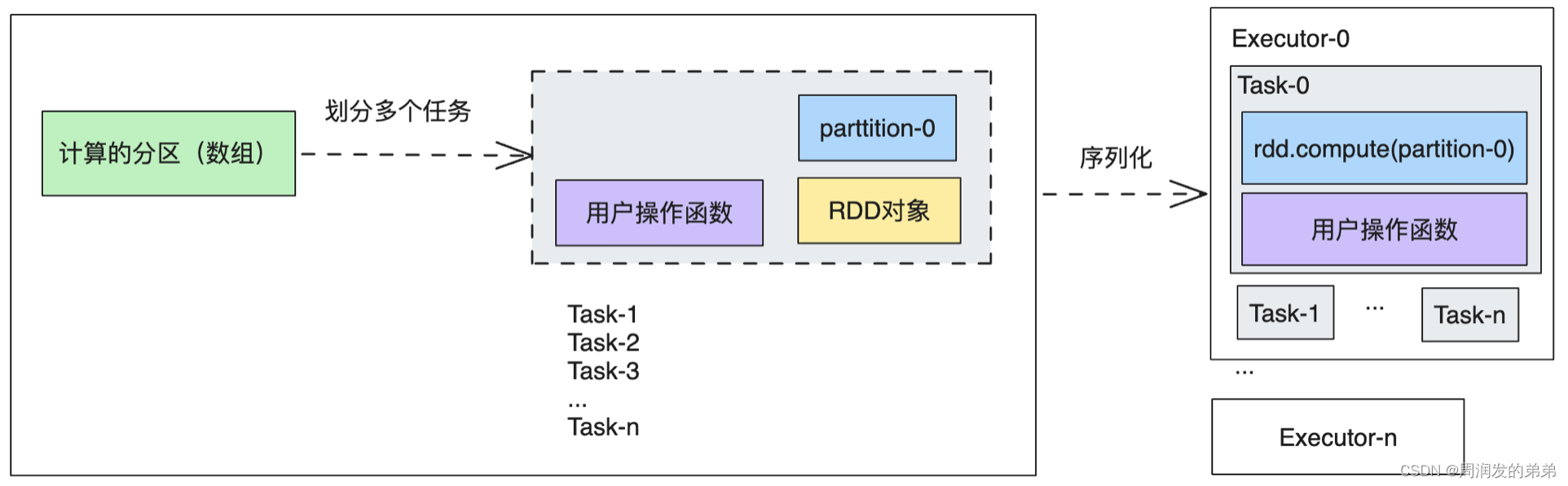
三、Stage划分
3.1、宽依赖和窄依赖
如果一个RDD的每个分区最多只能被一个Child RDD的一个分区所使用, 则称之为窄依赖(Narrow dependency), 如果被多个Child RDD分区依赖, 则称之为宽依赖(wide dependency)
3.2、Stage划分
在用户编写的一系列转换中,多个RDD可能既形成了多次窄依赖,也形成了多次宽依赖,连续的窄依赖可以通过一个任务进行流水线处理,但是如果遇到了宽依赖,就必须先将父RDD的所有数据都进行计算并保存起来,再进行RDD的运算。在一个Job中,action操作知识定义了在最后的RDD中执行何种操作,而最后的RDD会依赖上个RDD,上个RDD又会有其他依赖,这样就形成了一系列的依赖关系。如果为宽依赖的话,就在依赖的地方进行切分,先将宽依赖的父RDD进行计算出来,再计算后续的RDD,按照快依赖被划分的过程,即为Stage划分的过程。

如上图所示,rdd1->rdd2,rdd3->rdd4是窄依赖,rdd2->rdd3,rdd4->rdd5是宽依赖。在发生shuffle的位置,Spark将计算分为两个阶段分别执行,每发生一次shuffle,Spark就将计算划分为先后的两个阶段,如下图
在划分阶段的过程中,对于某个阶段而言其并行的计算任务都完全相同,因此在Job执行的过程中,并行计算就是指每个阶段中任务并行的计算。如在Stage1中,每个分区的数据可以使用一个任务进行计算。10000个分区即可在集群中并行运行10000个任务进行计算。如果集群资源不够,可以将10000个任务依次在集群中运行,直到运行完毕,再进行Stage2的计算。Stage2也会根据分区数启动多个任务并行的加载Stage1生成的数据,完成Stage2的计算。
在一个Job的运行过程中,所有的Stage其实都是为最后一个Stage做准备,因为action操作只需要最后一个RDD的数据。因此最后一个Stage称为ResultStage,之前所有的Stage都是由Shuffle引起的中间计算过程,被称为ShuffleMapStage。其过程如下图

3.3、Spark实现
再Spark实现中,SparkContext将Job提交至DAGScheduler,DAGScheduler获取Job中执行action操作的RDD,将最后执行action操作的RDD划分到最后的ResultStage中,然后遍历该RDD的依赖和所有的父依赖,每遇到宽依赖就将两个RDD划分到两个不同的Stage中,遇到窄依赖就将窄依赖的多个RDD划分到一个Stage中,经过这次操作,一个RDD就划分为有多个依赖关系的Stage。再每个Stage中,所有的RDD之间都是窄依赖的关系,Stage之间的RDD都是宽依赖的关系。DAGScheduler将最初被依赖的Stage提交,计算该Stage中的数据,计算完成后,再将后续的Stage提交,知道最后运行的ResultStage,则整个计算Job完成。ResultStage和ShuffleMapStage结构如下图
在生成ShuffleapStage时,ShuffleDependency起到了承上启下的作用,如果两个RDD之间为宽依赖,子RDD的依赖为ShuffleDependency;在划分Stage的时候,父Stage会保存该ShuffleDependency,以便在执行父Stage的时候,根据ShuffleDependency获取Shuffle的写入器,在子Stage执行的时候,会根据RDD的依赖关系使用相同的ShuffleDependency获取Shuffle的读取器。
在计算过程中,ShuffleMapStage会生成该Stage的结果,为下一个Stage提供数据,计算下一个Stage的RDD的时候,会拉取上一个Stage的计算结果。上一个Stage的计算保存在哪呢?答案是Spark的组件MapOutputTracker。MapOutputTracker也是主从结构,Executor端是MapOutputTrackerWroker,当ShuffleMapStage的任务运行完成后,会通过Executor上的MapOutputTrackerWroker将数据保存的位置发送到Driver上的MapOutputTrackerMaster中。在后续Stage需要上一个Stage的计算结果的时候,就通过MapOutputTrackerMaster询问计算结果的保存位置,进而加载相应的数据。
四、Task划分
DAGScheduler将Job划分为多个Stage之后,下一步就是将Stage划分为多个可以在集群中并行执行的任务,只有将任务并行执行,Stage才能更快的完成。
4.1、任务的个数
由于Stage中都是对RDD的计算,RDD又是分区的,所以在对任务进行划分的时候,每个分区可以启动一个任务进行计算。无论是ResultStage还是ShuffleMapStage,每个阶段能够并行执行的任务数量都取决于该阶段中最后一个Rdd的分区数量
上面已经介绍,在一个Stage中,RDD的依赖关系是窄依赖,所以最后一个RDD的分区数量取决于其依赖的RDD的分区数量,一直依赖到该阶段的开始的RDD的分区。对于第一阶段开始的RDD分为两种情况:
- 第一种为初始的RDD,即从数据源加载数据形成的初始RDD,这种情况的分区数量取决于初始RDD的形成分区方式。
- 第二种为该阶段的初始RDD为Shuffle阶段的Reduce任务,这种情况下,该RDD的分区数量取决于在Shuffle的Map阶段最后一个RDD的分区器设置的分区数量。
4.2、Task的生成
当确定了每个Stage的分区数量之后,就需要为每个分区生成相应的计算任务,该计算任务就是需要对该阶段的最后一个RDD执行什么操作
在ResultStage中,需要对最后一个RDD的每个分区分别执行用户自定义的action操作,所以在ResultStage中生成的每个Task都包含以下三个部分
- 需要对哪个RDD进行操作
- 需要对RDD哪个分区进行操作
- 需要对分区的内容执行什么样的操作
在ResultStage中划分的Task称为ResultTask,ResultTask中包含了ResultStage中最后一个RDD,即执行action操作的的RDD,需要计算的RDD分区的id和执行action操作的函数。
在ShuffleMapStage中,最终需要完成Shuffle过程中的Map阶段的操作,每个分区按照Shuffle中的Map端定义的过程执行数据的分组操作,将分组结果进行保存,并将保存结果位置通知Driver端的MapOutputTrackerMaster,MapOutputTrackerMaster保存着每一个Shuffle中Map输出的位置。在ShuffleMapStage中划分的Task称为ShuffleMapTask。ShuffleMapTask同样由三个重要的部分组成:Stage中最后的RDD、需要计算的分区的id、划分Stage的ShuffleDependency
4.3、Task的最佳运行位置
生成Task时,还会计算Task的最佳运行位置。虽然RDD包含计算RDD的所有信息,可以在任何节点上运行,但是如果通过为Task计算分配最佳的运行位置,可以将Task调度到含有该Task需要的数据的节点,从而实现移动计算而不是移动数据的目的。Spark会根据RDD可能分布的的情况,将Task的运行位置主要分为Host级别和Executor级别。当一个RDD被某个Executor缓存,则对该RDD计算时,优先会把计算的Task调度到该Executor中执行。当一个RDD需要的数据存在某个host中时,则会把该Task调度到这个节点的Executor中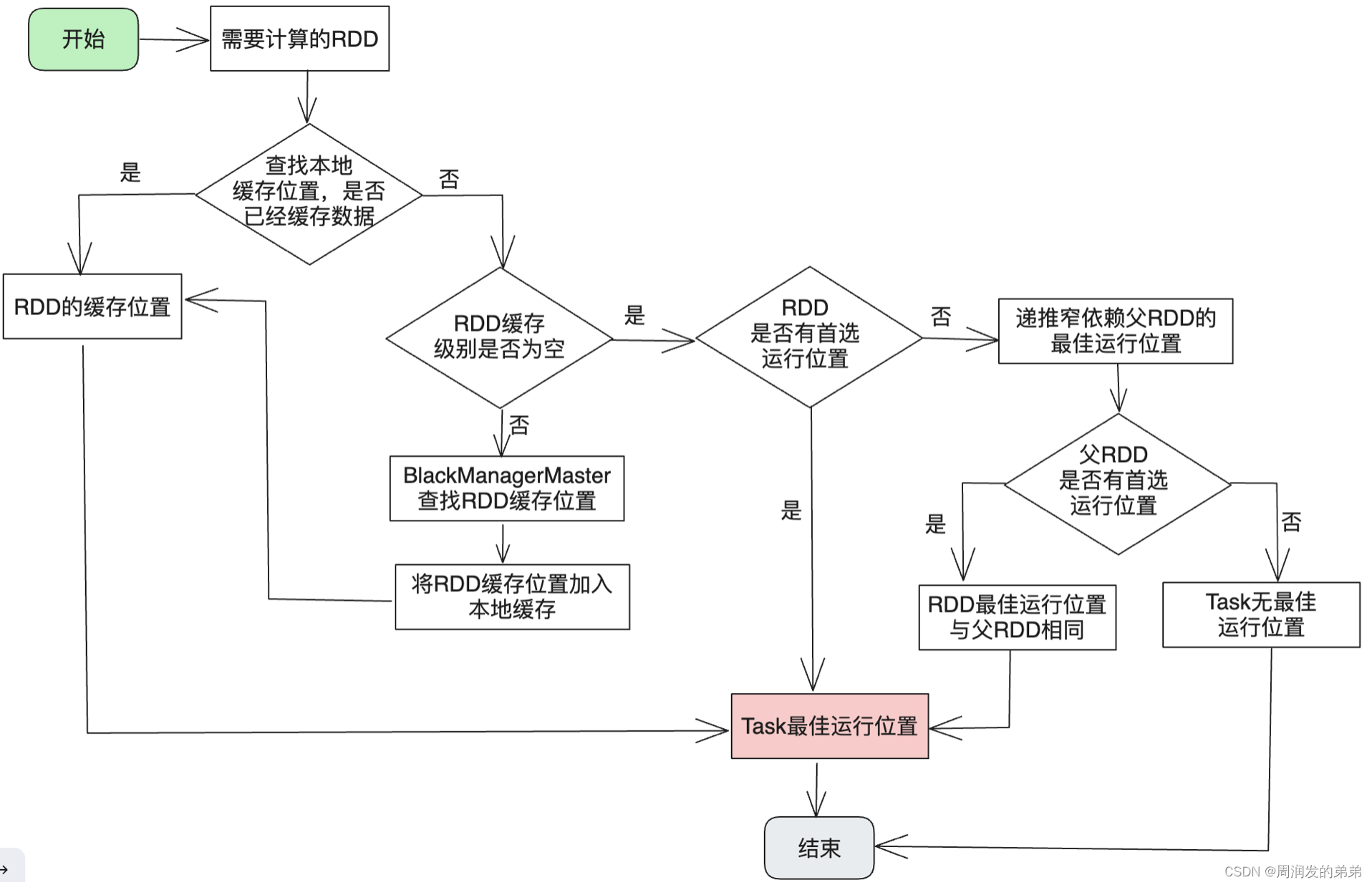
版权归原作者 周润发的弟弟 所有, 如有侵权,请联系我们删除。