
Hadoop系列文章目录
1、hadoop3.1.4简单介绍及部署、简单验证
2、HDFS操作 - shell客户端
3、HDFS的使用(读写、上传、下载、遍历、查找文件、整个目录拷贝、只拷贝文件、列出文件夹下文件、删除文件及目录、获取文件及文件夹属性等)-java
4、HDFS-java操作类HDFSUtil及junit测试(HDFS的常见操作以及HA环境的配置)
5、HDFS API的RESTful风格–WebHDFS
6、HDFS的HttpFS-代理服务
7、大数据中常见的文件存储格式以及hadoop中支持的压缩算法
8、HDFS内存存储策略支持和“冷热温”存储
9、hadoop高可用HA集群部署及三种方式验证
10、HDFS小文件解决方案–Archive
11、hadoop环境下的Sequence File的读写与合并
12、HDFS Trash垃圾桶回收介绍与示例
13、HDFS Snapshot快照
14、HDFS 透明加密KMS
15、MapReduce介绍及wordcount
16、MapReduce的基本用法示例-自定义序列化、排序、分区、分组和topN
17、MapReduce的分区Partition介绍
18、MapReduce的计数器与通过MapReduce读取/写入数据库示例
19、Join操作map side join 和 reduce side join
20、MapReduce 工作流介绍
21、MapReduce读写SequenceFile、MapFile、ORCFile和ParquetFile文件
22、MapReduce使用Gzip压缩、Snappy压缩和Lzo压缩算法写文件和读取相应的文件
23、hadoop集群中yarn运行mapreduce的内存、CPU分配调度计算与优化
目录
本文介绍hadoop的发展过程、3.1.4的特性、部署及简单验证。
本文前提依赖:免密登录设置、jdk已经安装、zookeeper部署完成且正常运行。具体参见相关文章,具体在zookeeper专栏、环境配置。
本文分为三个部分介绍,即hadoop发展史、hadoop3.1.4部署及验证。
一、hadoop发展史
1、Hadoop介绍
Hadoop是Apache旗下的一个用java语言实现开源软件框架,是一个开发和运行处理大规模数据的软件平台。允许使用简单的编程模型在大量计算机集群上对大型数据集进行分布式处理。
狭义上说,Hadoop指Apache这款开源框架,它的核心组件有:
- HDFS(分布式文件系统):解决海量数据存储
- YARN(作业调度和集群资源管理的框架):解决资源任务调度
- MAPREDUCE(分布式运算编程框架):解决海量数据计算 Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
 当下的Hadoop已经成长为一个庞大的体系,随着生态系统的成长,新出现的项目越来越多,其中不乏一些非Apache主管的项目,这些项目对HADOOP是很好的补充或者更高层的抽象。比如:
当下的Hadoop已经成长为一个庞大的体系,随着生态系统的成长,新出现的项目越来越多,其中不乏一些非Apache主管的项目,这些项目对HADOOP是很好的补充或者更高层的抽象。比如: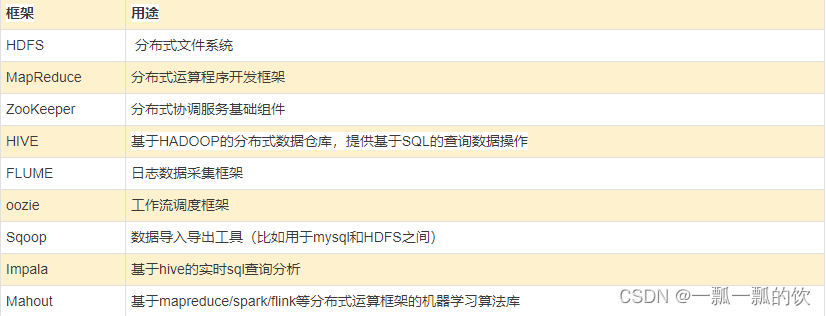
2、Hadoop发展简史
Hadoop是Apache Lucene创始人 Doug Cutting 创建的。最早起源于Nutch,它是Lucene的子项目。
Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题:如何解决数十亿网页的存储和索引问题。
2003年Google发表了一篇论文为该问题提供了可行的解决方案。论文中描述的是谷歌的产品架构,该架构称为:谷歌分布式文件系统(GFS),可以解决他们在网页爬取和索引过程中产生的超大文件的存储需求。
2004年 Google发表论文向全世界介绍了谷歌版的MapReduce系统。同时期,以谷歌的论文为基础,Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目,迎来了它的快速发展期。
2006年Google发表了论文是关于BigTable的,这促使了后来的Hbase的发展。因此,Hadoop及其生态圈的发展离不开Google的贡献。
3、Hadoop特性优点
- 扩容能力(Scalable):Hadoop是在可用的计算机集群间分配数据并完成计算任务的,这些集群可用方便的扩展到数以千计的节点中。
- 成本低(Economical):Hadoop通过普通廉价的机器组成服务器集群来分发以及处理数据,以至于成本很低。
- 高效率(Efficient):通过并发数据,Hadoop可以在节点之间动态并行的移动数据,使得速度非常快。
- 可靠性(Rellable):能自动维护数据的多份复制,并且在任务失败后能自动地重新部署(redeploy)计算任务。所以Hadoop的按位存储和处理数据的能力值得人们信赖。 Hadoop的历史版本和发行版公司
4、Hadoop历史版本
1.x版本系列:hadoop版本当中的第二代开源版本,主要修复0.x版本的一些bug等,该版本已被淘汰
2.x版本系列:架构产生重大变化,引入了yarn平台等许多新特性,是现在使用的主流版本。
3.x版本系列:对HDFS、MapReduce、YARN都有较大升级,还新增了Ozone key-value存储。
5、Hadoop发行版公司
Hadoop发行版本分为开源社区版和商业版。社区版是指由Apache软件基金会维护的版本,是官方维护的版本体系。
商业版Hadoop是指由第三方商业公司在社区版Hadoop基础上进行了一些修改、整合以及各个服务组件兼容性测试而发行的版本,比较著名的有cloudera的CDH、mapR、hortonWorks等。
1)、免费开源版本Apache
http://hadoop.apache.org/
优点:拥有全世界的开源贡献者,代码更新迭代版本比较快,
缺点:版本的升级,版本的维护,版本的兼容性,版本的补丁都可能考虑不太周到
Apache所有软件的下载地址(包括各种历史版本):http://archive.apache.org/dist/
2)、免费开源版本HortonWorks:
hortonworks主要是雅虎主导Hadoop开发的副总裁,带领二十几个核心成员成立Hortonworks,核心产品软件HDP(ambari),HDF免费开源,并且提供一整套的web管理界面,供我们可以通过web界面管理我们的集群状态,web管理界面软件HDF网址(http://ambari.apache.org/),2018年,大数据领域的两大巨头公司Cloudera和Hortonworks宣布平等合并,Cloudera以股票方式收购Hortonworks,Cloudera股东最终获得合并公司60%的股份
3)、收费版本
软件收费版本Cloudera:
https://www.cloudera.com/
cloudera主要是美国一家大数据公司在apache开源hadoop的版本上,通过自己公司内部的各种补丁,实现版本之间的稳定运行,大数据生态圈的各个版本的软件都提供了对应的版本,解决了版本的升级困难,版本兼容性等各种问题。该版本中是根据节点进行收费的,一定数量节点也是免费的。
6、Hadoop 3.x的版本架构和模型介绍
由于Hadoop 2.0是基于JDK 1.7开发的,而JDK 1.7在2015年4月已停止更新,使Hadoop社区基于JDK 1.8重新发布一个新的Hadoop版本,即hadoop 3.0。
Hadoop 3.0中引入了一些重要的功能和优化,包括HDFS 可擦除编码、多Namenode支持、MR Native Task优化、YARN基于cgroup的内存和磁盘IO隔离、YARN container resizing等。
Apache hadoop 项目组最新消息,hadoop3.x以后将会调整方案架构,将Mapreduce 基于内存+io+磁盘,共同处理数据。改变最大的是hdfs,hdfs 通过最近block块计算,根据最近计算原则,本地block块,加入到内存,先计算,通过IO,共享内存计算区域,最后快速形成计算结果,比Spark快10倍。
1)、Hadoop 3.0新特性
Hadoop 3.0在功能和性能方面,对hadoop内核进行了多项重大改进,主要包括:
- 1、通用性
1、精简Hadoop内核,包括剔除过期的API和实现,将默认组件实现替换成最高效的实现。
2、Classpath isolation:以防止不同版本jar包冲突
3、Shell脚本重构: Hadoop 3.0对Hadoop的管理脚本进行了重构,修复了大量bug,增加了新特性。
- 2、HDFS
Hadoop3.x中Hdfs在可靠性和支持能力上作出很大改观:
1、HDFS支持数据的擦除编码,这使得HDFS在不降低可靠性的前提下,节省一半存储空间。
2、多NameNode支持,即支持一个集群中,一个active、多个standby namenode部署方式。注:多ResourceManager特性在hadoop 2.0中已经支持。
- 3、HDFS纠删码
在Hadoop3.X中,HDFS实现了Erasure Coding这个新功能。Erasure coding纠删码技术简称EC,是一种数据保护技术.最早用于通信行业中数据传输中的数据恢复,是一种编码容错技术。
它通过在原始数据中加入新的校验数据,使得各个部分的数据产生关联性。在一定范围的数据出错情况下,通过纠删码技术都可以进行恢复。
hadoop-3.0之前,HDFS存储方式为每一份数据存储3份,这也使得存储利用率仅为1/3,hadoop-3.0引入纠删码技术(EC技术),实现1份数据+0.5份冗余校验数据存储方式。与副本相比纠删码是一种更节省空间的数据持久化存储方法。标准编码(比如Reed-Solomon(10,4))会有1.4 倍的空间开销;然而HDFS副本则会有3倍的空间开销。
- 4、支持多个NameNodes
最初的HDFS NameNode high-availability实现仅仅提供了一个active NameNode和一个Standby NameNode;并且通过将编辑日志复制到三个JournalNodes上,这种架构能够容忍系统中的任何一个节点的失败。然而,一些部署需要更高的容错度。我们可以通过这个新特性来实现,其允许用户运行多个Standby NameNode。比如通过配置三个NameNode和五个JournalNodes,这个系统可以容忍2个节点的故障,而不是仅仅一个节点。
- 5、MapReduce
Hadoop3.X中的MapReduce较之前的版本作出以下更改:
1、Tasknative优化:为MapReduce增加了C/C++的map output collector实现(包括Spill,Sort和IFile等),通过作业级别参数调整就可切换到该实现上。对于shuffle密集型应用,其性能可提高约30%。
2、MapReduce内存参数自动推断。在Hadoop 2.0中,为MapReduce作业设置内存参数非常繁琐,一旦设置不合理,则会使得内存资源浪费严重,在Hadoop3.0中避免了这种情况。
Hadoop3.x中的MapReduce添加了Map输出collector的本地实现,对于shuffle密集型的作业来说,这将会有30%以上的性能提升。
- 6、默认端口更改 在hadoop3.x之前,多个Hadoop服务的默认端口都属于Linux的临时端口范围(32768-61000)。这就意味着用户的服务在启动的时候可能因为和其他应用程序产生端口冲突而无法启动。 现在这些可能会产生冲突的端口已经不再属于临时端口的范围,这些端口的改变会影响NameNode, Secondary NameNode, DataNode以及KMS。与此同时,官方文档也进行了相应的改变,具体可以参见 HDFS-9427以及HADOOP-12811。
Namenode ports: 50470 --> 9871, 50070 --> 9870, 8020 --> 9820
Secondary NN ports: 50091 --> 9869,50090 --> 9868
Datanode ports: 50020 --> 9867, 50010 --> 9866, 50475 --> 9865, 50075 --> 9864
Kms server ports: 16000 --> 9600 (原先的16000与HMaster端口冲突)
- 7、YARN 资源类型
YARN 资源模型(YARN resource model)已被推广为支持用户自定义的可数资源类型(support user-defined countable resource types),不仅仅支持 CPU 和内存。
比如集群管理员可以定义诸如 GPUs、软件许可证(software licenses)或本地附加存储器(locally-attached storage)之类的资源。YARN 任务可以根据这些资源的可用性进行调度。
二、hadoop3.1.4集群部署
本文部署使用的是Apache 的3.1.4版本。
1、集群简介
HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起。
- HDFS集群负责海量数据的存储,集群中的角色主要有:NameNode、DataNode、SecondaryNameNode
- YARN集群负责海量数据运算时的资源调度,集群中的角色主要有: ResourceManager、NodeManager
- mapreduce是一个分布式运算编程框架,是应用程序开发包,由用户按照编程规范进行程序开发,后打包运行在HDFS集群上,并且受到YARN集群的资源调度管理。
2、集群部署方式
Hadoop部署方式分三种:
- standalone mode(独立模式)
独立模式又称为单机模式,仅1个机器运行1个java进程,主要用于调试。
- Pseudo-Distributed mode(伪分布式模式)
伪分布模式也是在1个机器上运行HDFS的NameNode和DataNode、YARN的 ResourceManger和NodeManager,但分别启动单独的java进程,主要用于调试。
- Cluster mode(群集模式)
集群模式主要用于生产环境部署。会使用N台主机组成一个Hadoop集群。这种部署模式下,主节点和从节点会分开部署在不同的机器上。
3、hadoop重新编译
由于appache给出的hadoop的安装包没有提供带C程序访问的接口,所以我们在使用本地库(本地库可以用来做压缩,以及支持C程序等等)的时候就会出问题,需要对Hadoop源码包进行重新编译。
编译步骤参考:hadoop 3.1.4在centos7上snappy编译过程
4、Hadoop集群安装
集群模式主要用于生产环境部署,需要多台主机,并且这些主机之间可以相互访问,我们在之前搭建好基础环境的三台虚拟机上进行Hadoop的搭建。
以下部署使用的是alanchan用户,其中为了后续的配置,需要做免密登录,具体参考链接:linux centos7免密登录设置
1)、集群规划
搭建的是集群模式,以四台主机为例(四台机子上均创建了alanchan用户,且在root组,也创建了usr/local/bigdata文件夹),以下是集群规划:
机器设置参考zookeeper的配置,同时该三台机器上部署了zookeeper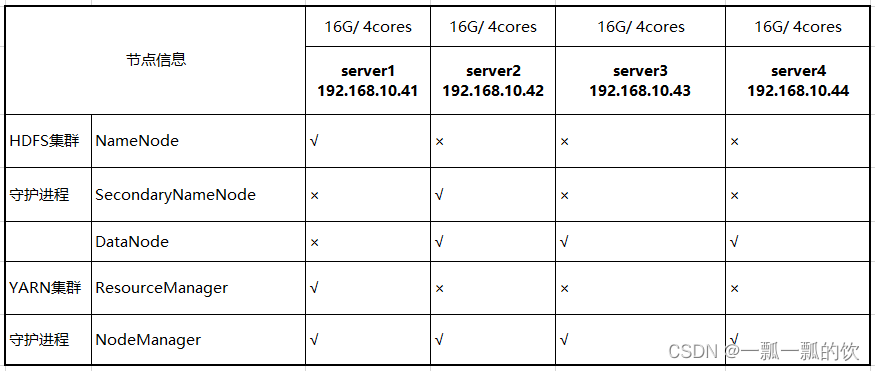
2)、主机名(4台机器)
该步骤是root用户操作,如果之前在免密登录时已经设置,则跳过。
vi /etc/hostname
server1
#root用户做,保存退出,重启机器reboot#依次做4台机器(server2、server3、server4)#验证[root@server1 ~]# hostname
server1
3)、Hosts映射(4台机器)
该步骤是root用户操作,如果之前在免密登录时已经设置,则跳过。
vi /etc/hosts
#依次修改四台机器127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 server41
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.10.41 server1
192.168.10.42 server2
192.168.10.43 server3
192.168.10.44 server4
4)、集群时间同步(4台机器)
该步骤是root用户操作,如果之前在免密登录时已经设置,则跳过。
yum -y install ntpdate
ntpdate ntp4.aliyun.com
#验证命令date
5)、解压(在server1上做)
该步骤是alanchan用户操作。
前提是hadoop-3.1.4-bin-snappy-CentOS7.tar.gz安装文件已经上传至server1上。
# 创建目录/usr/local/bigdatamkdir -p /usr/local/bigdata
# 上传解压hadoop-3.1.4-bin-snappy-CentOS7.tar.gz安装文件su alanchan
[alanchan@server bigdata]$ cd /usr/local/bigdata/
[alanchan@server bigdata]$ ll
-rw-r--r-- 1 alanchan root 3031341118月 2316:49 hadoop-3.1.4-bin-snappy-CentOS7.tar.gz
# 解压tar -xvzf hadoop-3.1.4-bin-snappy-CentOS7.tar.gz
[alanchan@server bigdata]$ ll
drwxr-xr-x 9 alanchan root 409611月 42020 hadoop-3.1.4
-rw-r--r-- 1 alanchan root 3031341118月 2316:49 hadoop-3.1.4-bin-snappy-CentOS7.tar.gz
# 在每个节点中创建用于存放数据的data目录# NameNode数据mkdir -p /usr/local/bigdata/hadoop-3.1.4/data/namenode
# DataNode数据mkdir -p /usr/local/bigdata/hadoop-3.1.4/data/datanode
解压后的目录结构如下:
6)、关键文件说明
- hadoop-env.sh
文件中设置的是Hadoop运行时需要的环境变量。
JAVA_HOME是必须设置的,即使我们当前的系统中设置了JAVA_HOME,因为Hadoop即使是在本机上执行,它也是把当前的执行环境当成远程服务器。
- core-site.xml
hadoop的核心配置文件,有默认的配置项core-default.xml。
core-default.xml与core-site.xml的功能是一样的,如果在core-site.xml里没有配置的属性,则会自动会获取core-default.xml里的相同属性的值。
在该文件中的标签中添加以下配置
<configuration>
在这里添加配置
</configuration>
- hdfs-site.xml
HDFS的核心配置文件,主要配置HDFS相关参数,有默认的配置项hdfs-default.xml。
hdfs-default.xml与hdfs-site.xml的功能是一样的,如果在hdfs-site.xml里没有配置的属性,则会自动会获取hdfs-default.xml里的相同属性的值。
- mapred-site.xml
MapReduce的核心配置文件,Hadoop默认文件mapred-default.xml,需要使用该文件复制出来一份mapred-site.xml文件
- yarn-site.xml
YARN的核心配置文件,YARN的相关参数在该文件中配置,默认的是yarn-default.xml。
- workers
workers文件里面记录的是集群主机名。一般有以下两种作用:
- 配合一键启动脚本如start-dfs.sh、stop-yarn.sh用来进行集群启动。这时候slaves文件里面的主机标记的就是从节点角色所在的机器。
- 可以配合hdfs-site.xml里面dfs.hosts属性形成一种白名单机制。
dfs.hosts指定一个文件,其中包含允许连接到NameNode的主机列表。必须指定文件的完整路径名,那么所有在workers中的主机才可以加入的集群中。如果值为空,则允许所有主机。
5、修改配置文件
解压后的配置文件都是空的,形如下面,如果没有配置,系统会使用其自带的配置文件,例如core-site.xml会使用core-default.xml。
该步骤是alanchan用户操作。
<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!--
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
--><!-- Do not modify this file directly. Instead, copy entries that you --><!-- wish to modify from this file into core-site.xml and change them --><!-- there. If core-site.xml does not already exist, create it. --><configuration></configuration>
Apache Hadoop 3.3.4 – Hadoop Cluster Setup
Configuring Hadoop in Non-Secure Mode
Hadoop’s Java configuration is driven by two types of important configuration files:
Read-only default configuration - core-default.xml, hdfs-default.xml, yarn-default.xml and mapred-default.xml.
Site-specific configuration - etc/hadoop/core-site.xml, etc/hadoop/hdfs-site.xml, etc/hadoop/yarn-site.xml and etc/hadoop/mapred-site.xml.
Additionally, you can control the Hadoop scripts found in the bin/ directory of the distribution, by setting site-specific values via the etc/hadoop/hadoop-env.sh and etc/hadoop/yarn-env.sh.
To configure the Hadoop cluster you will need to configure the environment in which the Hadoop daemons execute as well as the configuration parameters for the Hadoop daemons.
HDFS daemons are NameNode, SecondaryNameNode, and DataNode. YARN daemons are ResourceManager, NodeManager, and WebAppProxy. If MapReduce is to be used, then the MapReduce Job History Server will also be running. For large installations, these are generally running on separate hosts.
1)、配置NameNode(core-site.xml)
源码位置:hadoop-3.1.4-src\hadoop-common-project\hadoop-common\src\main\resources\core-default.xml
[alanchan@server bigdata]$ cd /usr/local/bigdata/hadoop-3.1.4/etc/hadoop
[alanchan@server hadoop]$ ll
-rw-r--r-- 1 alanchan root 921311月 42020 capacity-scheduler.xml
-rw-r--r-- 1 alanchan root 133511月 42020 configuration.xsl
-rw-r--r-- 1 alanchan root 194011月 42020 container-executor.cfg
-rw-r--r-- 1 alanchan root 77411月 42020 core-site.xml
-rw-r--r-- 1 alanchan root 399911月 42020 hadoop-env.cmd
-rw-r--r-- 1 alanchan root 1590311月 42020 hadoop-env.sh
-rw-r--r-- 1 alanchan root 332311月 42020 hadoop-metrics2.properties
-rw-r--r-- 1 alanchan root 1139211月 42020 hadoop-policy.xml
-rw-r--r-- 1 alanchan root 341411月 42020 hadoop-user-functions.sh.example
-rw-r--r-- 1 alanchan root 77511月 42020 hdfs-site.xml
-rw-r--r-- 1 alanchan root 148411月 42020 httpfs-env.sh
-rw-r--r-- 1 alanchan root 165711月 42020 httpfs-log4j.properties
-rw-r--r-- 1 alanchan root 2111月 42020 httpfs-signature.secret
-rw-r--r-- 1 alanchan root 62011月 42020 httpfs-site.xml
-rw-r--r-- 1 alanchan root 351811月 42020 kms-acls.xml
-rw-r--r-- 1 alanchan root 135111月 42020 kms-env.sh
-rw-r--r-- 1 alanchan root 174711月 42020 kms-log4j.properties
-rw-r--r-- 1 alanchan root 68211月 42020 kms-site.xml
-rw-r--r-- 1 alanchan root 1471311月 42020 log4j.properties
-rw-r--r-- 1 alanchan root 95111月 42020 mapred-env.cmd
-rw-r--r-- 1 alanchan root 176411月 42020 mapred-env.sh
-rw-r--r-- 1 alanchan root 411311月 42020 mapred-queues.xml.template
-rw-r--r-- 1 alanchan root 75811月 42020 mapred-site.xml
drwxr-xr-x 2 alanchan root 409611月 42020 shellprofile.d
-rw-r--r-- 1 alanchan root 231611月 42020 ssl-client.xml.example
-rw-r--r-- 1 alanchan root 269711月 42020 ssl-server.xml.example
-rw-r--r-- 1 alanchan root 264211月 42020 user_ec_policies.xml.template
-rw-r--r-- 1 alanchan root 1011月 42020 workers
-rw-r--r-- 1 alanchan root 225011月 42020 yarn-env.cmd
-rw-r--r-- 1 alanchan root 627211月 42020 yarn-env.sh
-rw-r--r-- 1 alanchan root 259111月 42020 yarnservice-log4j.properties
-rw-r--r-- 1 alanchan root 69011月 42020 yarn-site.xml
#修改core-site.xml文件 /usr/local/bigdata/hadoop-3.1.4/etc/hadoop/core-site.xml# 以下内容均为增加部分<property><name>fs.defaultFS</name><value>hdfs://server1:8020</value><description>配置NameNode的URL</description></property><property><name>fs.default.name</name><value>hdfs://server1:8020</value><description>Deprecated. Use (fs.defaultFS) property instead</description></property><!-- hadoop本地数据存储目录 format时自动生成数据存储目录最好是放在本工程的外面,避免扩容时需要剔除该部分内容,本例没有放在外面--><property><name>hadoop.tmp.dir</name><value>/usr/local/bigdata/hadoop-3.1.4</value></property><!-- 在Web UI访问HDFS使用的用户名。--><property><name>hadoop.http.staticuser.user</name><value>alanchan</value></property># 以上内容均为增加部分
2)、配置HDFS文件(hdfs-site.xml)
源码位置:hadoop-3.1.4-src\hadoop-hdfs-project\hadoop-hdfs\src\main\resources\hdfs-default.xml
# 文件路径:/usr/local/bigdata/hadoop-3.1.4/etc/hadoop/hdfs-site.xml
<!-- 设定SNN运行主机和端口。--><property><name>dfs.namenode.secondary.http-address</name><value>server2:9868</value><description>
The secondary namenode http server address and port.
</description></property><property><name>dfs.namenode.name.dir</name><value>/usr/local/bigdata/hadoop-3.1.4/data/namenode</value><description>NameNode存储名称空间和事务日志的本地文件系统上的路径</description></property><property><name>dfs.datanode.data.dir</name><value>/usr/local/bigdata/hadoop-3.1.4/data/datanode</value><description>DDataNode存储名称空间和事务日志的本地文件系统上的路径</description></property>
一般为了将来能方便的增加黑白名单配置
#在namenode机器的hdfs-site.xml配置文件中需要提前配置dfs.hosts.exclude属性,该属性指向的文件就是所谓的黑名单列表,会被namenode排除在集群之外。如果文件内容为空,则意味着不禁止任何机器。
#提前配置好的目的是让namenode启动的时候就能加载到该属性,只不过还没有指定任何机器。否则就需要重启namenode才能加载,因此这样的操作我们称之为具有前瞻性的操作。
<property><name>dfs.hosts.exclude</name><value>/usr/local/bigdata/hadoop-3.1.4/etc/hadoop/excludes</value></property>
#编辑dfs.hosts.exclude属性指向的excludes文件,添加需要退役的主机名称。
#注意:如果副本数是3,服役的节点小于等于3,是不能退役成功的,需要修改副本数后才能退役。
<!-- 白名单 --><property><name>dfs.hosts</name><value></value><description>Names a file that contains a list of hosts that are permitted to connect to the namenode. The full pathname of the file must be specified. If the value is empty, all hosts are permitted.</description></property><!-- 黑名单 --><property><name>dfs.hosts.exclude</name><value></value><description>Names a file that contains a list of hosts that are not permitted to connect to the namenode. The full pathname of the file must be specified. If the value is empty, no hosts are excluded.</description></property>
3)、配置YARN(yarn-site.xml)
源码位置:hadoop-3.1.4-src\hadoop-yarn-project\hadoop-yarn\hadoop-yarn-common\src\main\resources\yarn-default.xml
# 文件位置 /usr/local/bigdata/hadoop-3.1.4/etc/hadoop/yarn-site.xml
<property><description>为每个容器请求分配的最小内存限制资源管理器</description><name>yarn.scheduler.minimum-allocation-mb</name><value>1024</value></property><property><description>为每个容器请求分配的最大内存限制资源管理器</description><name>yarn.scheduler.maximum-allocation-mb</name><value>8192</value></property><property><description>虚拟内存比例,默认为2.1</description><name>yarn.nodemanager.vmem-pmem-ratio</name><value>2.1</value></property><!-- NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MR程序 --><property><description>A comma separated list of services where service name should only
contain a-zA-Z0-9_ and can not start with numbers</description><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value><!--<value>mapreduce_shuffle</value>--></property><!-- yarn集群主角色RM运行机器 --><property><description>The hostname of the RM.</description><name>yarn.resourcemanager.hostname</name><value>server1</value></property>
4)、配置MapReduce(mapred-site.xml)
源码位置:hadoop-3.1.4-src\hadoop-mapreduce-project\hadoop-mapreduce-client\hadoop-mapreduce-client-core\src\main\resources\mapred-default.xml
# 文件路径: /usr/local/bigdata/hadoop-3.1.4/etc/hadoop/mapred-site.xml
<!-- mr程序默认运行方式。yarn集群模式 local本地模式--><property><name>mapreduce.framework.name</name><value>yarn</value><description>The runtime framework for executing MapReduce jobs.
Can be one of local, classic or yarn.执行MapReduce的方式:yarn/local
</description></property><!-- MR App Master环境变量。--><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><!-- MR MapTask环境变量。--><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><!-- MR ReduceTask环境变量。--><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property>
5)、workers文件
# 设置三个datanode# 文件位置:/usr/local/bigdata/hadoop-3.1.4/etc/hadoop/workers# 文件内容如下:
server2
server3
server4
6)、修改hadoop.env环境变量
# 设置jdk的安装目录,改成实际环境的目录exportJAVA_HOME=/usr/java/jdk1.8.0_144
#设置用户以执行对应角色shell命令,改成实际的用户名exportHDFS_NAMENODE_USER=alanchan
exportHDFS_DATANODE_USER=alanchan
exportHDFS_SECONDARYNAMENODE_USER=alanchan
exportYARN_RESOURCEMANAGER_USER=alanchan
exportYARN_NODEMANAGER_USER=alanchan
7)、配置环境变量
该步骤操作用户是root。
vi /etc/profile
# 设置内容如下:exportHADOOP_HOME=/usr/local/bigdata/hadoop-3.1.4
exportPATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
8)、分发配置好的Hadoop安装文件和环境变量
cd /usr/local/bigdata
# 复制hadoop,在server1上执行scp -r hadoop-3.1.4 server2:$PWDscp -r hadoop-3.1.4 server3:$PWDscp -r hadoop-3.1.4 server4:$PWD# 复制环境变量,在server1上执行scp /etc/profile server2:/etc
scp /etc/profile server3:/etc
scp /etc/profile server4:/etc
# 在每个节点上执行,使环境变量生效source /etc/profile
#验证环境变量是否生效,如果正常识别出来hadoop命令,即生效了。直接在centos中输入命令
hadoop
# 出现如下信息则表示配置成功[alanchan@server3 bin]$ hadoop
Usage: hadoop [OPTIONS] SUBCOMMAND [SUBCOMMAND OPTIONS]
or hadoop [OPTIONS] CLASSNAME [CLASSNAME OPTIONS]
where CLASSNAME is a user-provided Java class
OPTIONS is none or any of:
buildpaths attempt to add class files from build tree
--config dir Hadoop config directory
--debug turn on shell script debug mode
--help usage information
hostnames list[,of,host,names] hosts to use in slave mode
hosts filename list of hosts to use in slave mode
loglevel level set the log4j level for this command
workers turn on worker mode
SUBCOMMAND is one of:
Admin Commands:
daemonlog get/set the log level for each daemon
Client Commands:
archive create a Hadoop archive
checknative check native Hadoop and compression libraries availability
classpath prints the class path needed to get the Hadoop jar and the required libraries
conftest validate configuration XML files
credential interact with credential providers
......
9)、格式化HDFS
其实就是初始化hadoop的环境。使用alanchan用户,在server1上执行。
首次启动HDFS时,必须对其进行格式化操作(hdfs namenode -format)。
cd /usr/local/bigdata/hadoop-3.1.4/bin
[alanchan@server1 bin]$ ll
总用量 880
-rwxr-xr-x 1 alanchan root 39267211月 42020 container-executor
-rwxr-xr-x 1 alanchan root 870711月 42020 hadoop
-rwxr-xr-x 1 alanchan root 1126511月 42020 hadoop.cmd
-rwxr-xr-x 1 alanchan root 1102611月 42020 hdfs
-rwxr-xr-x 1 alanchan root 808111月 42020 hdfs.cmd
-rwxr-xr-x 1 alanchan root 623711月 42020 mapred
-rwxr-xr-x 1 alanchan root 631111月 42020 mapred.cmd
-rwxr-xr-x 1 alanchan root 41638411月 42020 test-container-executor
-rwxr-xr-x 1 alanchan root 1188811月 42020yarn
-rwxr-xr-x 1 alanchan root 1284011月 42020 yarn.cmd
[alanchan@server1 bin]$ hdfs namenode -format
2022-08-25 09:59:36,957 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host= server1/192.168.10.41
STARTUP_MSG: args =[-format]
STARTUP_MSG: version =3.1.4
STARTUP_MSG: classpath = /usr/local/bigdata/hadoop-3.1.4/etc/hadoop:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/jsp-api-2.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/guava-27.0-jre.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/commons-configuration2-2.1.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/jackson-core-asl-1.9.13.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/curator-client-2.13.0.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/slf4j-api-1.7.25.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/asm-5.0.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/kerb-util-1.0.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/jetty-security-9.4.20.v20190813.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/failureaccess-1.0.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/jaxb-impl-2.2.3-1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/jcip-annotations-1.0-1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/animal-sniffer-annotations-1.17.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/accessors-smart-1.2.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/kerby-asn1-1.0.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/jetty-http-9.4.20.v20190813.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/jackson-xc-1.9.13.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/snappy-java-1.0.5.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/checker-qual-2.5.2.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/woodstox-core-5.0.3.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/httpcore-4.4.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/jaxb-api-2.2.11.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/hadoop-auth-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/kerb-core-1.0.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/jackson-annotations-2.9.10.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/jersey-core-1.19.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/kerby-pkix-1.0.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/kerb-admin-1.0.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/jackson-core-2.9.10.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/log4j-1.2.17.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/jackson-mapper-asl-1.9.13.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/jettison-1.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/token-provider-1.0.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/commons-lang-2.6.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/jersey-server-1.19.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/jul-to-slf4j-1.7.25.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/kerb-server-1.0.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/kerb-common-1.0.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/kerby-util-1.0.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/jsch-0.1.55.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/jsr311-api-1.1.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/nimbus-jose-jwt-7.9.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/kerb-identity-1.0.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/jersey-json-1.19.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/kerby-config-1.0.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/htrace-core4-4.1.0-incubating.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/jersey-servlet-1.19.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/jetty-server-9.4.20.v20190813.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/jsr305-3.0.2.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/curator-recipes-2.13.0.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/curator-framework-2.13.0.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/jetty-util-9.4.20.v20190813.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/re2j-1.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/kerb-crypto-1.0.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/j2objc-annotations-1.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/commons-lang3-3.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/commons-cli-1.2.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/json-smart-2.3.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/audience-annotations-0.5.0.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/kerby-xdr-1.0.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/commons-net-3.6.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/commons-codec-1.11.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/protobuf-java-2.5.0.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/gson-2.2.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/httpclient-4.5.2.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/javax.servlet-api-3.1.0.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/stax2-api-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/jetty-webapp-9.4.20.v20190813.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/commons-beanutils-1.9.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/commons-math3-3.1.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/zookeeper-3.4.13.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/jetty-io-9.4.20.v20190813.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/kerb-simplekdc-1.0.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/jackson-databind-2.9.10.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/paranamer-2.3.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/avro-1.7.7.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/hadoop-annotations-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/kerb-client-1.0.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/jetty-servlet-9.4.20.v20190813.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/commons-logging-1.1.3.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/jetty-xml-9.4.20.v20190813.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/commons-compress-1.19.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/metrics-core-3.2.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/error_prone_annotations-2.2.0.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/commons-io-2.5.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/netty-3.10.6.Final.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/listenablefuture-9999.0-empty-to-avoid-conflict-with-guava.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/jackson-jaxrs-1.9.13.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/lib/commons-collections-3.2.2.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/hadoop-common-3.1.4-tests.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/hadoop-common-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/hadoop-kms-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/common/hadoop-nfs-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/guava-27.0-jre.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/commons-configuration2-2.1.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/jackson-core-asl-1.9.13.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/curator-client-2.13.0.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/asm-5.0.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/kerb-util-1.0.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/jetty-security-9.4.20.v20190813.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/failureaccess-1.0.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/jaxb-impl-2.2.3-1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/jcip-annotations-1.0-1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/animal-sniffer-annotations-1.17.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/accessors-smart-1.2.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/kerby-asn1-1.0.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/json-simple-1.1.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/jetty-http-9.4.20.v20190813.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/jackson-xc-1.9.13.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/snappy-java-1.0.5.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/checker-qual-2.5.2.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/woodstox-core-5.0.3.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/netty-all-4.1.48.Final.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/httpcore-4.4.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/jaxb-api-2.2.11.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/hadoop-auth-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/jetty-util-ajax-9.4.20.v20190813.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/kerb-core-1.0.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/jackson-annotations-2.9.10.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/jersey-core-1.19.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/kerby-pkix-1.0.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/kerb-admin-1.0.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/jackson-core-2.9.10.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/log4j-1.2.17.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/jackson-mapper-asl-1.9.13.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/jettison-1.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/leveldbjni-all-1.8.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/token-provider-1.0.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/commons-lang-2.6.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/jersey-server-1.19.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/kerb-server-1.0.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/kerb-common-1.0.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/kerby-util-1.0.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/jsch-0.1.55.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/jsr311-api-1.1.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/nimbus-jose-jwt-7.9.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/kerb-identity-1.0.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/jersey-json-1.19.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/kerby-config-1.0.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/htrace-core4-4.1.0-incubating.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/jersey-servlet-1.19.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/jetty-server-9.4.20.v20190813.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/jsr305-3.0.2.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/curator-recipes-2.13.0.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/curator-framework-2.13.0.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/jetty-util-9.4.20.v20190813.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/re2j-1.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/kerb-crypto-1.0.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/j2objc-annotations-1.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/commons-daemon-1.0.13.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/commons-lang3-3.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/commons-cli-1.2.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/json-smart-2.3.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/audience-annotations-0.5.0.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/kerby-xdr-1.0.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/commons-net-3.6.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/commons-codec-1.11.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/protobuf-java-2.5.0.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/gson-2.2.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/httpclient-4.5.2.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/javax.servlet-api-3.1.0.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/okhttp-2.7.5.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/stax2-api-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/jetty-webapp-9.4.20.v20190813.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/commons-beanutils-1.9.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/commons-math3-3.1.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/zookeeper-3.4.13.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/okio-1.6.0.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/jetty-io-9.4.20.v20190813.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/kerb-simplekdc-1.0.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/jackson-databind-2.9.10.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/paranamer-2.3.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/avro-1.7.7.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/hadoop-annotations-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/kerb-client-1.0.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/jetty-servlet-9.4.20.v20190813.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/commons-logging-1.1.3.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/jetty-xml-9.4.20.v20190813.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/commons-compress-1.19.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/error_prone_annotations-2.2.0.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/commons-io-2.5.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/netty-3.10.6.Final.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/listenablefuture-9999.0-empty-to-avoid-conflict-with-guava.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/jackson-jaxrs-1.9.13.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/lib/commons-collections-3.2.2.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/hadoop-hdfs-client-3.1.4-tests.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/hadoop-hdfs-native-client-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/hadoop-hdfs-httpfs-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/hadoop-hdfs-3.1.4-tests.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/hadoop-hdfs-nfs-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/hadoop-hdfs-rbf-3.1.4-tests.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/hadoop-hdfs-rbf-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/hadoop-hdfs-client-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/hadoop-hdfs-native-client-3.1.4-tests.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/hdfs/hadoop-hdfs-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/mapreduce/lib/junit-4.11.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/mapreduce/lib/hamcrest-core-1.3.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-client-core-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-client-app-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-client-shuffle-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-client-uploader-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-client-common-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-plugins-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.4-tests.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-client-nativetask-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/lib/jersey-guice-1.19.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/lib/swagger-annotations-1.5.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/lib/dnsjava-2.1.7.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/lib/mssql-jdbc-6.2.1.jre7.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/lib/fst-2.50.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/lib/jackson-jaxrs-base-2.9.10.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/lib/aopalliance-1.0.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/lib/ehcache-3.3.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/lib/jersey-client-1.19.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/lib/jackson-module-jaxb-annotations-2.9.10.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/lib/objenesis-1.0.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/lib/javax.inject-1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/lib/json-io-2.5.1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/lib/geronimo-jcache_1.0_spec-1.0-alpha-1.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/lib/java-util-1.9.0.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/lib/HikariCP-java7-2.4.12.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/lib/jackson-jaxrs-json-provider-2.9.10.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/lib/guice-servlet-4.0.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/lib/metrics-core-3.2.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/lib/guice-4.0.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/lib/snakeyaml-1.16.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/hadoop-yarn-applications-unmanaged-am-launcher-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/hadoop-yarn-applications-distributedshell-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/hadoop-yarn-server-nodemanager-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/hadoop-yarn-server-tests-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/hadoop-yarn-server-resourcemanager-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/hadoop-yarn-server-web-proxy-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/hadoop-yarn-server-common-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/hadoop-yarn-server-timeline-pluginstorage-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/hadoop-yarn-server-router-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/hadoop-yarn-services-api-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/hadoop-yarn-server-applicationhistoryservice-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/hadoop-yarn-registry-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/hadoop-yarn-client-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/hadoop-yarn-services-core-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/hadoop-yarn-server-sharedcachemanager-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/hadoop-yarn-common-3.1.4.jar:/usr/local/bigdata/hadoop-3.1.4/share/hadoop/yarn/hadoop-yarn-api-3.1.4.jar
STARTUP_MSG: build = Unknown -r Unknown; compiled by 'root' on 2020-11-04T09:35Z
STARTUP_MSG: java =1.8.0_144
************************************************************/
2022-08-25 09:59:36,964 INFO namenode.NameNode: registered UNIX signal handlers for[TERM, HUP, INT]2022-08-25 09:59:37,059 INFO namenode.NameNode: createNameNode [-format]2022-08-25 09:59:37,186 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Formatting using clusterid: CID-ffdc8a28-a92d-45fc-bd34-382c1645e64a
2022-08-25 09:59:37,519 INFO namenode.FSEditLog: Edit logging is async:true
2022-08-25 09:59:37,545 INFO namenode.FSNamesystem: KeyProvider: null
2022-08-25 09:59:37,546 INFO namenode.FSNamesystem: fsLock is fair: true2022-08-25 09:59:37,546 INFO namenode.FSNamesystem: Detailed lock hold time metrics enabled: false2022-08-25 09:59:37,561 INFO namenode.FSNamesystem: fsOwner = alanchan (auth:SIMPLE)2022-08-25 09:59:37,561 INFO namenode.FSNamesystem: supergroup = supergroup
2022-08-25 09:59:37,561 INFO namenode.FSNamesystem: isPermissionEnabled =true2022-08-25 09:59:37,566 INFO namenode.FSNamesystem: HA Enabled: false2022-08-25 09:59:37,611 INFO common.Util: dfs.datanode.fileio.profiling.sampling.percentage set to 0. Disabling file IO profiling
2022-08-25 09:59:37,621 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit: configured=1000, counted=60, effected=10002022-08-25 09:59:37,621 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true
2022-08-25 09:59:37,625 INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to 000:00:00:00.000
2022-08-25 09:59:37,626 INFO blockmanagement.BlockManager: The block deletion will start around 2022 八月 25 09:59:37
2022-08-25 09:59:37,627 INFO util.GSet: Computing capacity for map BlocksMap
2022-08-25 09:59:37,627 INFO util.GSet: VM type=64-bit
2022-08-25 09:59:37,630 INFO util.GSet: 2.0% max memory 3.5 GB =70.9 MB
2022-08-25 09:59:37,630 INFO util.GSet: capacity =2^23 =8388608 entries
2022-08-25 09:59:37,641 INFO blockmanagement.BlockManager: dfs.block.access.token.enable =false2022-08-25 09:59:37,647 INFO Configuration.deprecation: No unit for dfs.namenode.safemode.extension(30000) assuming MILLISECONDS
2022-08-25 09:59:37,647 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.threshold-pct =0.99900001287460332022-08-25 09:59:37,647 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.min.datanodes =02022-08-25 09:59:37,647 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.extension =300002022-08-25 09:59:37,684 INFO blockmanagement.BlockManager: defaultReplication =32022-08-25 09:59:37,684 INFO blockmanagement.BlockManager: maxReplication =5122022-08-25 09:59:37,684 INFO blockmanagement.BlockManager: minReplication =12022-08-25 09:59:37,684 INFO blockmanagement.BlockManager: maxReplicationStreams =22022-08-25 09:59:37,684 INFO blockmanagement.BlockManager: redundancyRecheckInterval = 3000ms
2022-08-25 09:59:37,684 INFO blockmanagement.BlockManager: encryptDataTransfer =false2022-08-25 09:59:37,684 INFO blockmanagement.BlockManager: maxNumBlocksToLog =10002022-08-25 09:59:37,729 INFO namenode.FSDirectory: GLOBAL serial map: bits=24maxEntries=167772152022-08-25 09:59:37,745 INFO util.GSet: Computing capacity for map INodeMap
2022-08-25 09:59:37,745 INFO util.GSet: VM type=64-bit
2022-08-25 09:59:37,745 INFO util.GSet: 1.0% max memory 3.5 GB =35.4 MB
2022-08-25 09:59:37,745 INFO util.GSet: capacity =2^22 =4194304 entries
2022-08-25 09:59:37,747 INFO namenode.FSDirectory: ACLs enabled? false2022-08-25 09:59:37,747 INFO namenode.FSDirectory: POSIX ACL inheritance enabled? true2022-08-25 09:59:37,747 INFO namenode.FSDirectory: XAttrs enabled? true2022-08-25 09:59:37,747 INFO namenode.NameNode: Caching file names occurring more than 10times2022-08-25 09:59:37,752 INFO snapshot.SnapshotManager: Loaded config captureOpenFiles: false, skipCaptureAccessTimeOnlyChange: false, snapshotDiffAllowSnapRootDescendant: true, maxSnapshotLimit: 655362022-08-25 09:59:37,754 INFO snapshot.SnapshotManager: SkipList is disabled
2022-08-25 09:59:37,758 INFO util.GSet: Computing capacity for map cachedBlocks
2022-08-25 09:59:37,758 INFO util.GSet: VM type=64-bit
2022-08-25 09:59:37,758 INFO util.GSet: 0.25% max memory 3.5 GB =8.9 MB
2022-08-25 09:59:37,758 INFO util.GSet: capacity =2^20 =1048576 entries
2022-08-25 09:59:37,765 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets =102022-08-25 09:59:37,765 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users =102022-08-25 09:59:37,765 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes =1,5,25
2022-08-25 09:59:37,769 INFO namenode.FSNamesystem: Retry cache on namenode is enabled
2022-08-25 09:59:37,769 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis
2022-08-25 09:59:37,770 INFO util.GSet: Computing capacity for map NameNodeRetryCache
2022-08-25 09:59:37,770 INFO util.GSet: VM type=64-bit
2022-08-25 09:59:37,770 INFO util.GSet: 0.029999999329447746% max memory 3.5 GB =1.1 MB
2022-08-25 09:59:37,771 INFO util.GSet: capacity =2^17 =131072 entries
2022-08-25 09:59:37,793 INFO namenode.FSImage: Allocated new BlockPoolId: BP-74677984-192.168.10.41-1661392777786
2022-08-25 09:59:37,859 INFO common.Storage: Storage directory /usr/local/bigdata/hadoop-3.1.4/dfs/name has been successfully formatted.
2022-08-25 09:59:37,879 INFO namenode.FSImageFormatProtobuf: Saving image file /usr/local/bigdata/hadoop-3.1.4/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
2022-08-25 09:59:37,968 INFO namenode.FSImageFormatProtobuf: Image file /usr/local/bigdata/hadoop-3.1.4/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 395 bytes saved in0 seconds .2022-08-25 09:59:37,997 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >=02022-08-25 09:59:38,002 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid =0 when meet shutdown.
2022-08-25 09:59:38,002 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at server1/192.168.10.41
************************************************************/
出现以上信息,则表明初始化成功。
重要参考信息:**
Storage directory /usr/local/bigdata/hadoop-3.1.4/dfs/name has been successfully formatted.
**
10)、启动Hadoop集群
#1、Hadoop集群启动关闭-手动逐个进程启停#每台机器上每次手动启动关闭一个角色进程# HDFS集群
hdfs --daemon start namenode|datanode|secondarynamenode
hdfs --daemon stop namenode|datanode|secondarynamenode
# YARN集群yarn --daemon start resourcemanager|nodemanager
yarn --daemon stop resourcemanager|nodemanager
#2、 Hadoop集群启动关闭-shell脚本一键启停# 在server1上,使用软件自带的shell脚本一键启动#前提:配置好机器之间的SSH免密登录和workers文件。#HDFS集群
start-dfs.sh
stop-dfs.sh
#YARN集群
start-yarn.sh
stop-yarn.sh
#Hadoop集群
start-all.sh
stop-all.sh
#验证
server1
[alanchan@server1 bin]$ cd../
[alanchan@server1 hadoop-3.1.4]$ cd sbin
[alanchan@server1 sbin]$ ll
总用量 112
-rwxr-xr-x 1 alanchan root 275611月 42020 distribute-exclude.sh
drwxr-xr-x 4 alanchan root 409611月 42020 FederationStateStore
-rwxr-xr-x 1 alanchan root 198311月 42020 hadoop-daemon.sh
-rwxr-xr-x 1 alanchan root 252211月 42020 hadoop-daemons.sh
-rwxr-xr-x 1 alanchan root 154211月 42020 httpfs.sh
-rwxr-xr-x 1 alanchan root 150011月 42020 kms.sh
-rwxr-xr-x 1 alanchan root 184111月 42020 mr-jobhistory-daemon.sh
-rwxr-xr-x 1 alanchan root 208611月 42020 refresh-namenodes.sh
-rwxr-xr-x 1 alanchan root 177911月 42020 start-all.cmd
-rwxr-xr-x 1 alanchan root 222111月 42020 start-all.sh
-rwxr-xr-x 1 alanchan root 188011月 42020 start-balancer.sh
-rwxr-xr-x 1 alanchan root 140111月 42020 start-dfs.cmd
-rwxr-xr-x 1 alanchan root 517011月 42020 start-dfs.sh
-rwxr-xr-x 1 alanchan root 179311月 42020 start-secure-dns.sh
-rwxr-xr-x 1 alanchan root 157111月 42020 start-yarn.cmd
-rwxr-xr-x 1 alanchan root 334211月 42020 start-yarn.sh
-rwxr-xr-x 1 alanchan root 177011月 42020 stop-all.cmd
-rwxr-xr-x 1 alanchan root 216611月 42020 stop-all.sh
-rwxr-xr-x 1 alanchan root 178311月 42020 stop-balancer.sh
-rwxr-xr-x 1 alanchan root 145511月 42020 stop-dfs.cmd
-rwxr-xr-x 1 alanchan root 389811月 42020 stop-dfs.sh
-rwxr-xr-x 1 alanchan root 175611月 42020 stop-secure-dns.sh
-rwxr-xr-x 1 alanchan root 164211月 42020 stop-yarn.cmd
-rwxr-xr-x 1 alanchan root 308311月 42020 stop-yarn.sh
-rwxr-xr-x 1 alanchan root 198211月 42020 workers.sh
-rwxr-xr-x 1 alanchan root 181411月 42020 yarn-daemon.sh
-rwxr-xr-x 1 alanchan root 232811月 42020 yarn-daemons.sh
[alanchan@server sbin]$ start-all.sh
WARNING: Attempting to start all Apache Hadoop daemons as alanchan in10 seconds.
WARNING: This is not a recommended production deployment configuration.
WARNING: Use CTRL-C to abort.
Starting namenodes on [server1]
Starting datanodes
Starting secondary namenodes [server2]2022-08-24 14:46:31,052 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting resourcemanager
Starting nodemanagers
[alanchan@server sbin]$ jps
10818 ResourceManager
10229 NameNode
22171 Jps
server2
[root@localhost bigdata]# jps5648 DataNode
6067 NodeManager
17931 Jps
5837 SecondaryNameNode
server3
[root@localhost bigdata]# jps19674 Jps
6923 NodeManager
6590 DataNode
server4
[root@localhost bigdata]# jps19762 Jps
12408 DataNode
12622 NodeManager
至此,理论上已经完成了部署,接下来进行初步的验证。
11)、web UI登录验证
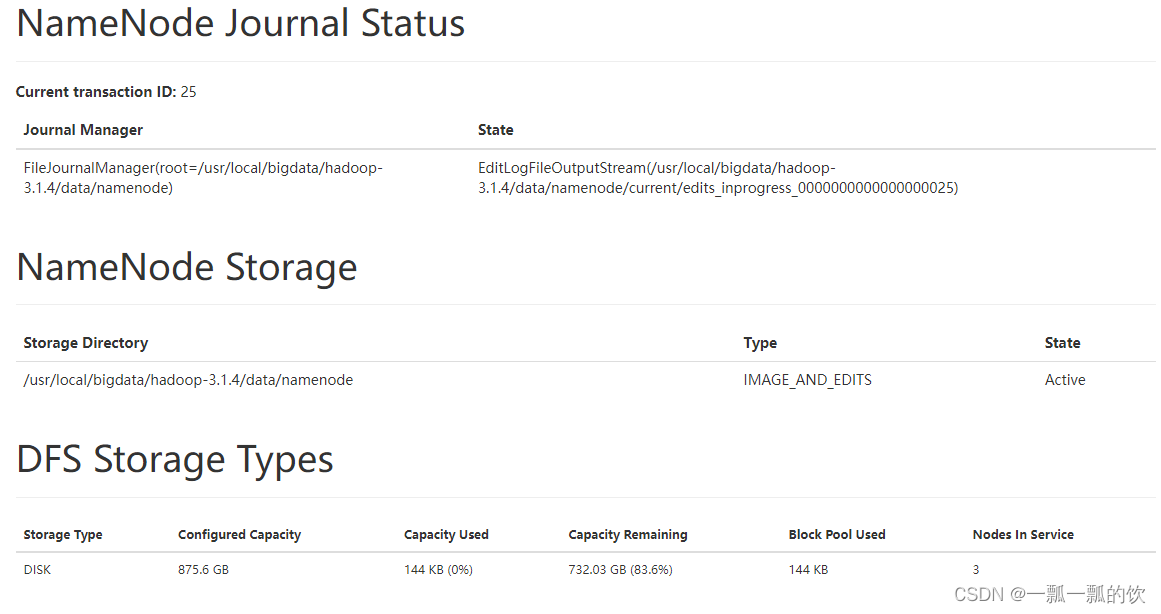
1、验证namenode
http://192.168.10.41:9870/dfshealth.html#tab-overview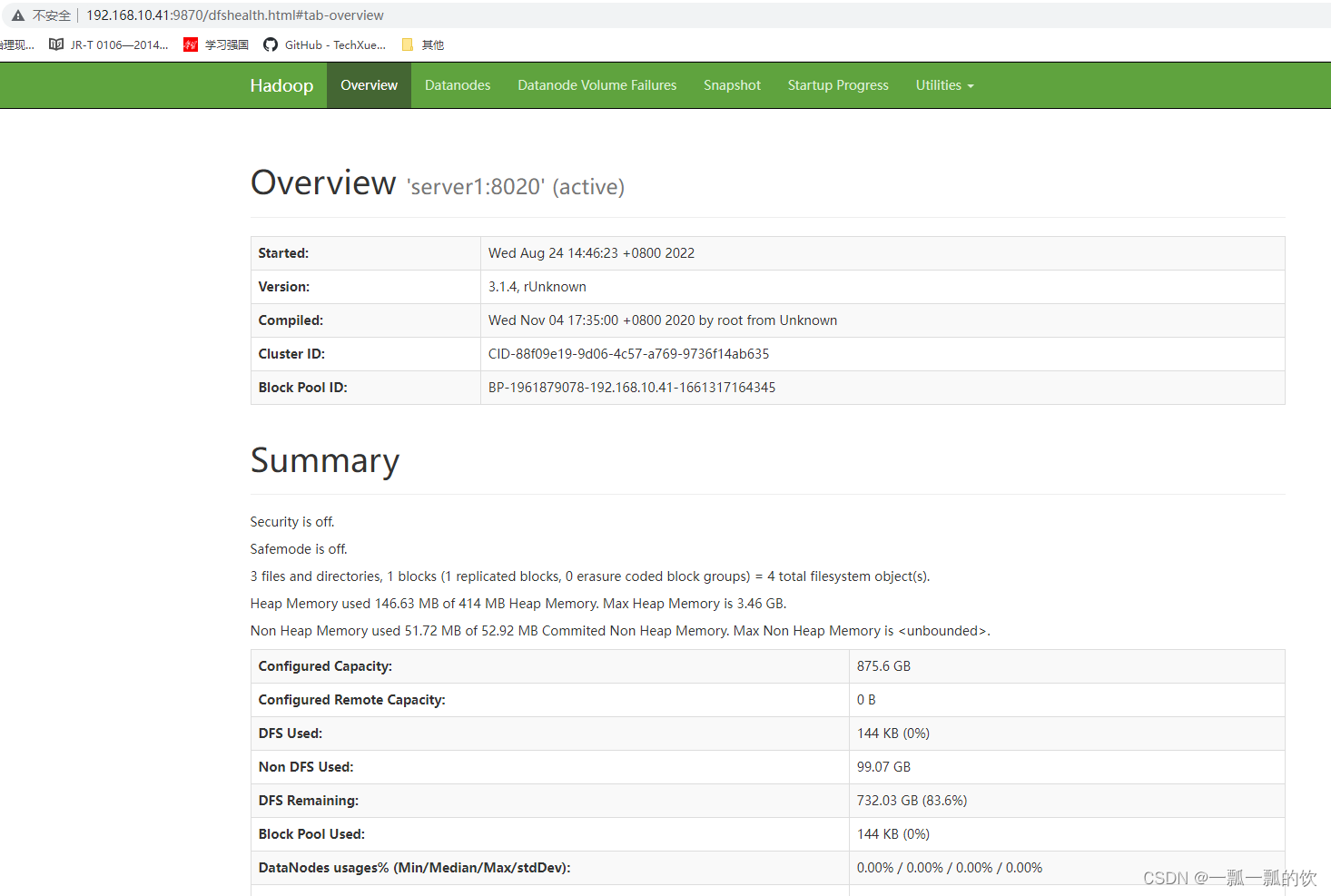
2、验证datanode
点击首页的live datanodes(http://192.168.10.41:9870/dfshealth.html#tab-datanode)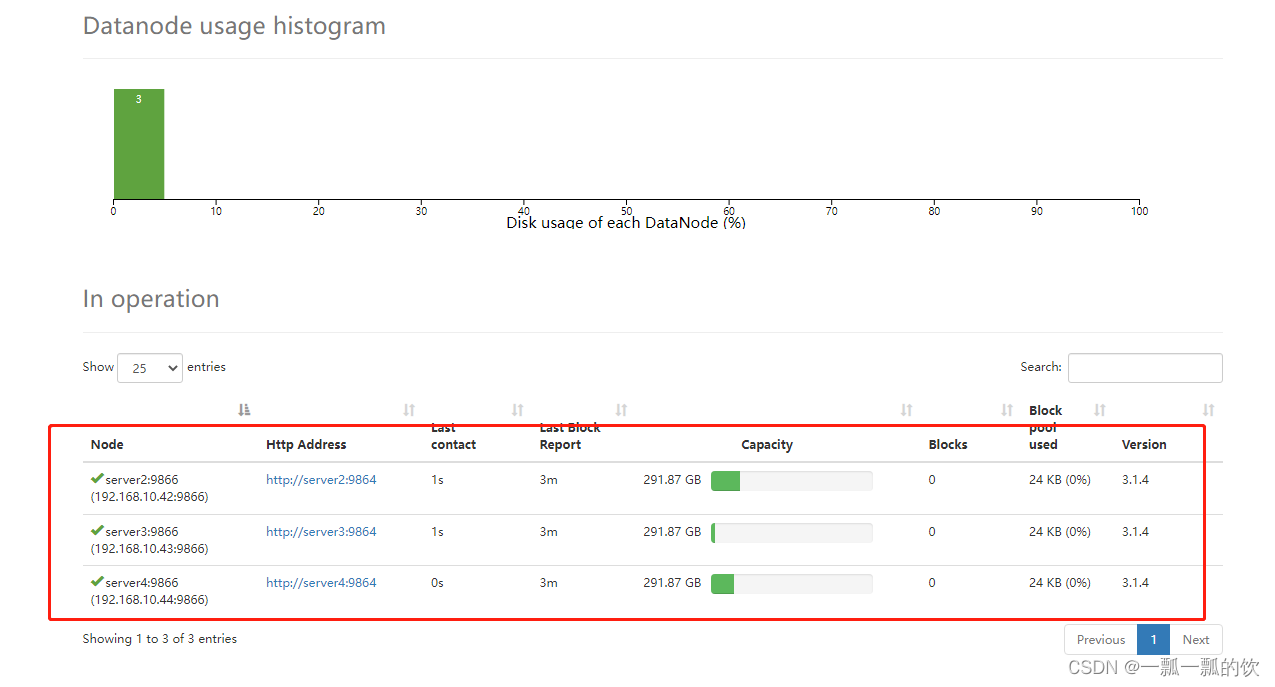
每个datanode链接地址可以点击进去,比如http://server2:9864/datanode.html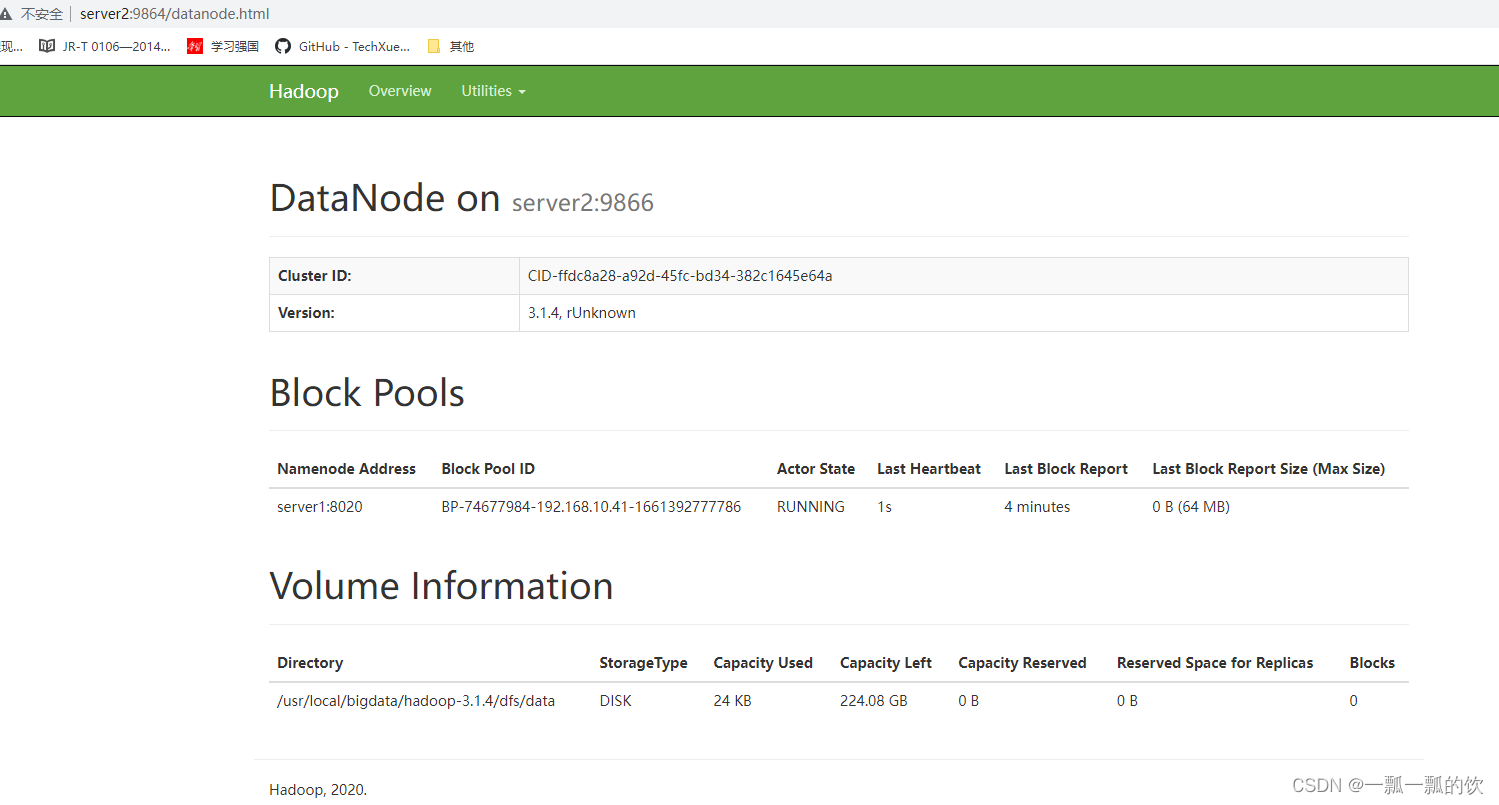
3、验证hadoop集群
http://server1:8088/cluster(本机配置了hosts访问方式)
http://192.168.10.41:8088/cluster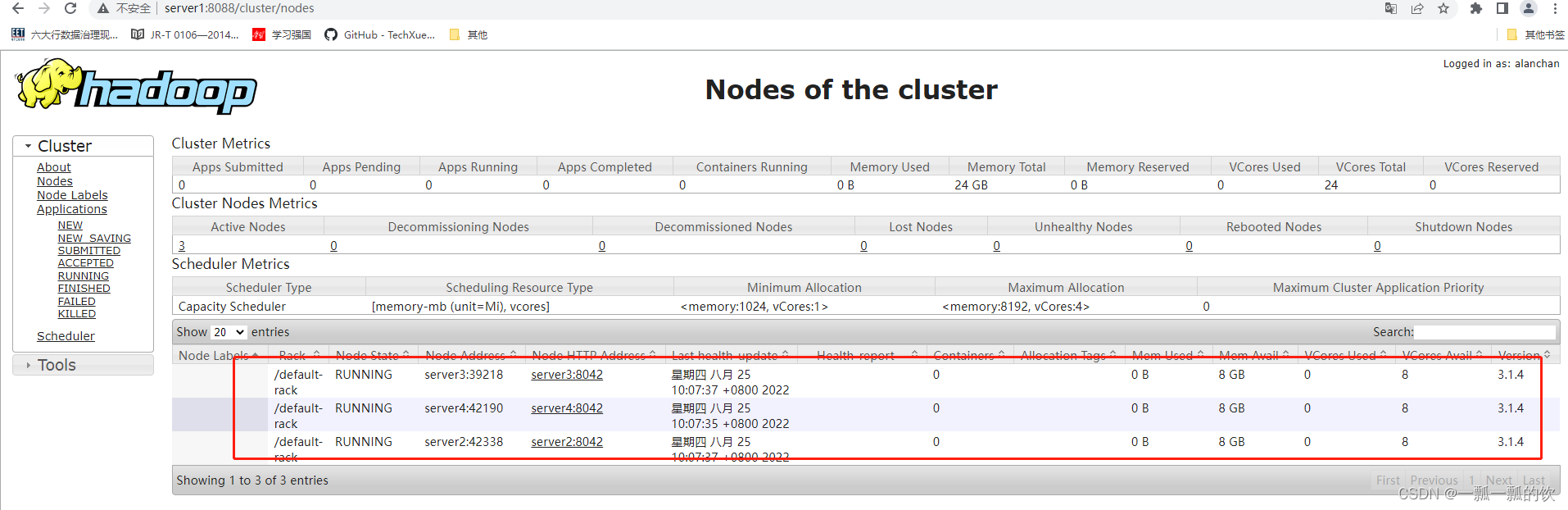
三、简单验证
经过以上的步骤算是完成了hadoop集群的部署,下面将进行简单的功能验证。
1、shell
#在hadoop集群上任何一台机子均可执行#创建目录testhadoopcreate[alanchan@localhost bigdata]$ hadoop fs -mkdir /testhadoopcreate
#查看根目录下文件情况[alanchan@localhost bigdata]$ hadoop fs -ls /
Found 3 items
-rw-r--r-- 3 alanchan supergroup 22042022-08-24 06:20 /in
drwxr-xr-x - alanchan supergroup 02022-08-24 05:55 /testdata
drwxr-xr-x - alanchan supergroup 02022-08-24 07:12 /testhadoopcreate
#上传文件到指定目录[alanchan@localhost bigdata]$ hadoop fs -put /usr/local/bigdata/hadoop-3.1.4/NOTICE.txt /testhadoopcreate
#查看上传文件情况[alanchan@localhost bigdata]$ hadoop fs -ls /testhadoopcreate
Found 1 items
-rw-r--r-- 3 alanchan supergroup 218672022-08-24 07:15 /testhadoopcreate/NOTICE.txt
#如果出现如下异常(由于本机是安装好了后,再做编译,使相应的路径有变化,会出现这种情况)[alanchan@server1 sbin]$ hadoop fs /
2022-08-26 10:42:25,170 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
/: Unknown command#检查命令
hadoop checknative -a
[alanchan@server1 sbin]$ hadoop checknative -a
2022-08-26 10:43:59,775 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Native library checking:
hadoop: false
zlib: false
zstd :false
snappy: false
lz4: false
bzip2: false
openssl: false
ISA-L: false
PMDK: false2022-08-26 10:43:59,904 INFO util.ExitUtil: Exiting with status 1: ExitException
https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/NativeLibraries.html#Native_Hadoop_Library
2、web Ui
创建目录test,并且在test目录下上传文件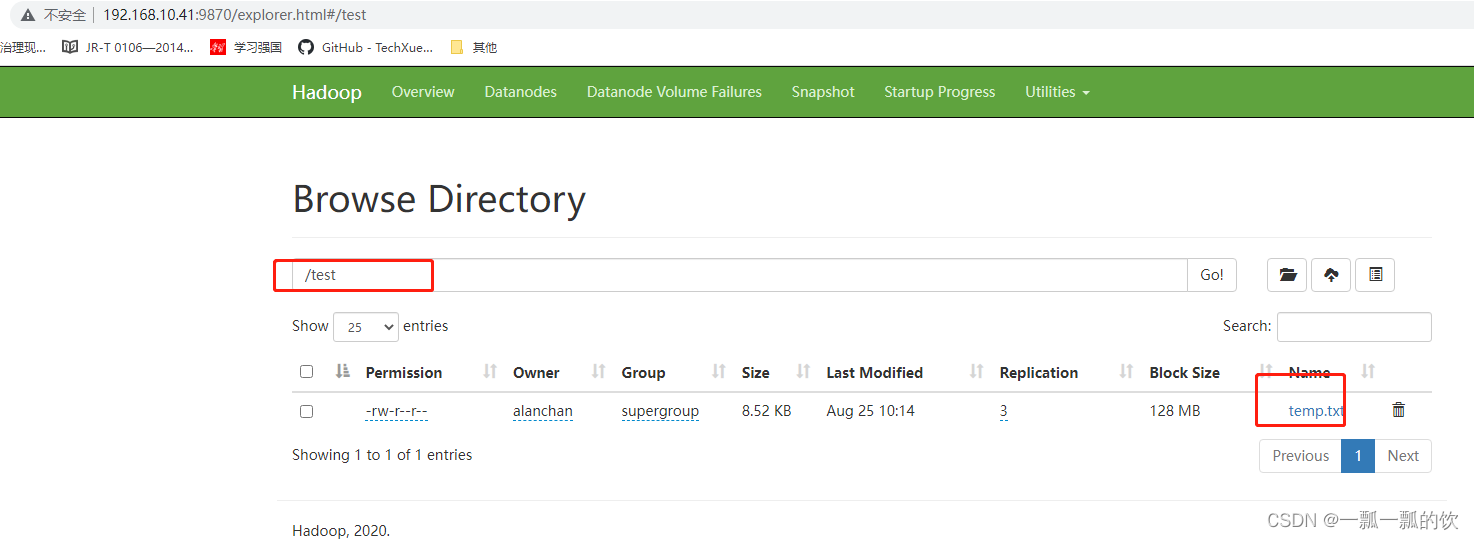
3、map-reduce
cd /usr/local/bigdata/hadoop-3.1.4/share/hadoop/mapreduce/
#运行圆周率计算的例子
hadoop jar hadoop-mapreduce-examples-3.1.4.jar pi 24[alanchan@server4 root]$ cd /usr/local/bigdata/hadoop-3.1.4/share/hadoop/mapreduce/
[alanchan@server4 mapreduce]$ ll
总用量 5612
-rw-r--r-- 1 alanchan root 6221328月 25 01:58 hadoop-mapreduce-client-app-3.1.4.jar
-rw-r--r-- 1 alanchan root 8034838月 25 01:58 hadoop-mapreduce-client-common-3.1.4.jar
-rw-r--r-- 1 alanchan root 16562998月 25 01:58 hadoop-mapreduce-client-core-3.1.4.jar
-rw-r--r-- 1 alanchan root 2152928月 25 01:58 hadoop-mapreduce-client-hs-3.1.4.jar
-rw-r--r-- 1 alanchan root 453328月 25 01:58 hadoop-mapreduce-client-hs-plugins-3.1.4.jar
-rw-r--r-- 1 alanchan root 853988月 25 01:58 hadoop-mapreduce-client-jobclient-3.1.4.jar
-rw-r--r-- 1 alanchan root 16819288月 25 01:58 hadoop-mapreduce-client-jobclient-3.1.4-tests.jar
-rw-r--r-- 1 alanchan root 1261438月 25 01:58 hadoop-mapreduce-client-nativetask-3.1.4.jar
-rw-r--r-- 1 alanchan root 971408月 25 01:58 hadoop-mapreduce-client-shuffle-3.1.4.jar
-rw-r--r-- 1 alanchan root 576928月 25 01:58 hadoop-mapreduce-client-uploader-3.1.4.jar
-rw-r--r-- 1 alanchan root 3163108月 25 01:58 hadoop-mapreduce-examples-3.1.4.jar
drwxr-xr-x 2 alanchan root 40968月 25 01:58 jdiff
drwxr-xr-x 2 alanchan root 40968月 25 01:58 lib
drwxr-xr-x 2 alanchan root 40968月 25 01:58 lib-examples
drwxr-xr-x 2 alanchan root 40968月 25 01:58 sources
[alanchan@server4 mapreduce]$ hadoop jar hadoop-mapreduce-examples-3.1.4.jar pi 24
Number of Maps =2
Samples per Map =4
Wrote input for Map #0
Wrote input for Map #1
Starting Job
2022-08-25 02:15:32,519 INFO client.RMProxy: Connecting to ResourceManager at server1/192.168.10.41:8032
2022-08-25 02:15:32,855 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/alanchan/.staging/job_1661393017372_0001
2022-08-25 02:15:33,000 INFO input.FileInputFormat: Total input files to process :22022-08-25 02:15:33,082 INFO mapreduce.JobSubmitter: number of splits:2
2022-08-25 02:15:33,258 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1661393017372_0001
2022-08-25 02:15:33,259 INFO mapreduce.JobSubmitter: Executing with tokens: []2022-08-25 02:15:33,400 INFO conf.Configuration: resource-types.xml not found
2022-08-25 02:15:33,400 INFO resource.ResourceUtils: Unable to find'resource-types.xml'.2022-08-25 02:15:33,782 INFO impl.YarnClientImpl: Submitted application application_1661393017372_0001
2022-08-25 02:15:33,814 INFO mapreduce.Job: The url to track the job: http://server1:8088/proxy/application_1661393017372_0001/
2022-08-25 02:15:33,815 INFO mapreduce.Job: Running job: job_1661393017372_0001
2022-08-25 02:15:40,888 INFO mapreduce.Job: Job job_1661393017372_0001 running in uber mode :false2022-08-25 02:15:40,889 INFO mapreduce.Job: map 0% reduce 0%
2022-08-25 02:15:46,935 INFO mapreduce.Job: map 100% reduce 0%
2022-08-25 02:15:52,962 INFO mapreduce.Job: map 100% reduce 100%
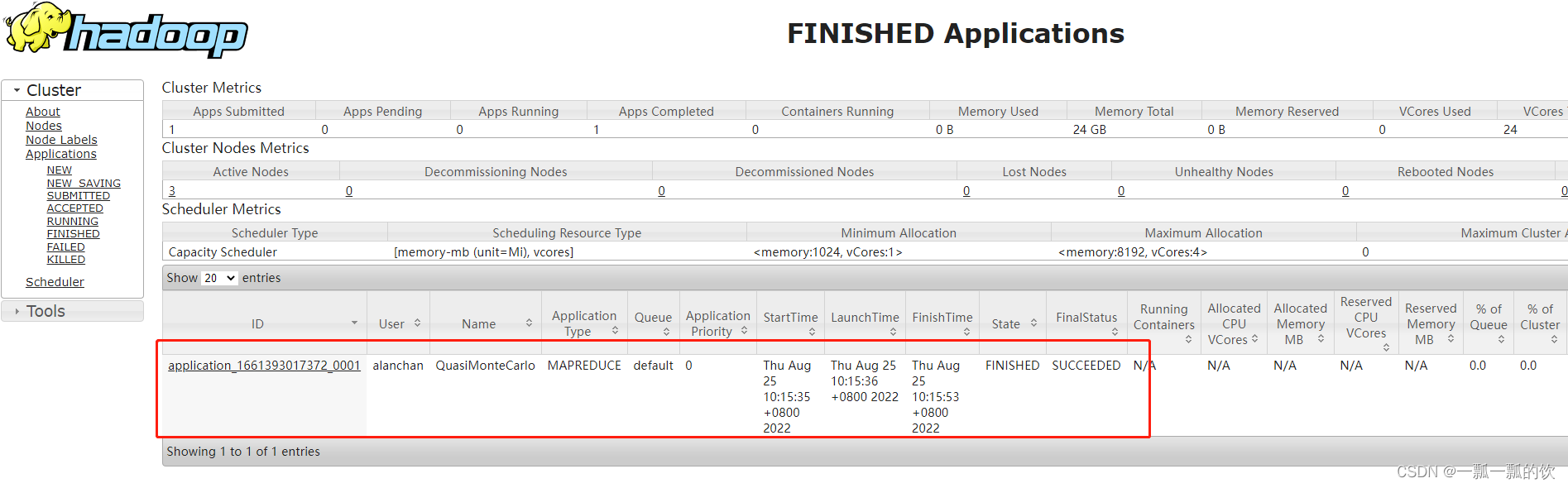
2022-08-25 02:15:52,968 INFO mapreduce.Job: Job job_1661393017372_0001 completed successfully
2022-08-25 02:15:53,047 INFO mapreduce.Job: Counters: 53
File System Counters
FILE: Number of bytes read=50
FILE: Number of bytes written=666276
FILE: Number of readoperations=0
FILE: Number of large readoperations=0
FILE: Number of writeoperations=0
HDFS: Number of bytes read=530
HDFS: Number of bytes written=215
HDFS: Number of readoperations=13
HDFS: Number of large readoperations=0
HDFS: Number of writeoperations=3
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=6316
Total time spent by all reduces in occupied slots (ms)=3252
Total time spent by all map tasks (ms)=6316
Total time spent by all reduce tasks (ms)=3252
Total vcore-milliseconds taken by all map tasks=6316
Total vcore-milliseconds taken by all reduce tasks=3252
Total megabyte-milliseconds taken by all map tasks=6467584
Total megabyte-milliseconds taken by all reduce tasks=3330048
Map-Reduce Framework
Map input records=2
Map output records=4
Map output bytes=36
Map output materialized bytes=56
Input splitbytes=294
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=56
Reduce input records=4
Reduce output records=0
Spilled Records=8
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=145
CPU time spent (ms)=1640
Physical memory (bytes)snapshot=844423168
Virtual memory (bytes)snapshot=8351129600
Total committed heap usage (bytes)=749207552
Peak Map Physical memory (bytes)=342159360
Peak Map Virtual memory (bytes)=2788798464
Peak Reduce Physical memory (bytes)=200597504
Peak Reduce Virtual memory (bytes)=2775109632
Shuffle Errors
BAD_ID=0CONNECTION=0IO_ERROR=0WRONG_LENGTH=0WRONG_MAP=0WRONG_REDUCE=0
File Input Format Counters
Bytes Read=236
File Output Format Counters
Bytes Written=97
Job Finished in20.591 seconds
Estimated value of Pi is 3.50000000000000000000
四、hadoop集群的基准测试
1、测试写入速度
#向HDFS文件系统中写入数据,100个文件,每个文件100MB,文件存放到/benchmarks/TestDFSIO中#Throughput:吞吐量、Average IO rate:平均IO率、IO rate std deviation:IO率标准偏差
hadoop jar /usr/local/bigdata/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.4-tests.jar TestDFSIO -write -nrFiles 100 -fileSize 100MB
[alanchan@server4 mapreduce]$ hadoop jar /usr/local/bigdata/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.4-tests.jar TestDFSIO -write -nrFiles 100 -fileSize 100MB
2022-08-25 02:54:12,517 INFO fs.TestDFSIO: TestDFSIO.1.8
2022-08-25 02:54:12,518 INFO fs.TestDFSIO: nrFiles =1002022-08-25 02:54:12,518 INFO fs.TestDFSIO: nrBytes (MB)=100.02022-08-25 02:54:12,518 INFO fs.TestDFSIO: bufferSize =10000002022-08-25 02:54:12,518 INFO fs.TestDFSIO: baseDir = /benchmarks/TestDFSIO
2022-08-25 02:54:13,127 INFO fs.TestDFSIO: creating control file: 104857600 bytes, 100 files
2022-08-25 02:54:15,421 INFO fs.TestDFSIO: created control files for: 100 files
2022-08-25 02:54:15,493 INFO client.RMProxy: Connecting to ResourceManager at server1/192.168.10.41:8032
2022-08-25 02:54:15,648 INFO client.RMProxy: Connecting to ResourceManager at server1/192.168.10.41:8032
2022-08-25 02:54:15,834 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/alanchan/.staging/job_1661395853554_0002
2022-08-25 02:54:16,127 INFO mapred.FileInputFormat: Total input files to process :1002022-08-25 02:54:16,201 INFO mapreduce.JobSubmitter: number of splits:100
2022-08-25 02:54:16,329 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1661395853554_0002
2022-08-25 02:54:16,331 INFO mapreduce.JobSubmitter: Executing with tokens: []2022-08-25 02:54:16,467 INFO conf.Configuration: resource-types.xml not found
2022-08-25 02:54:16,467 INFO resource.ResourceUtils: Unable to find'resource-types.xml'.2022-08-25 02:54:16,517 INFO impl.YarnClientImpl: Submitted application application_1661395853554_0002
2022-08-25 02:54:16,547 INFO mapreduce.Job: The url to track the job: http://server1:8088/proxy/application_1661395853554_0002/
2022-08-25 02:54:16,548 INFO mapreduce.Job: Running job: job_1661395853554_0002
2022-08-25 02:54:21,619 INFO mapreduce.Job: Job job_1661395853554_0002 running in uber mode :false2022-08-25 02:54:21,620 INFO mapreduce.Job: map 0% reduce 0%
2022-08-25 02:54:41,466 INFO mapreduce.Job: map 1% reduce 0%
2022-08-25 02:54:42,556 INFO mapreduce.Job: map 4% reduce 0%
2022-08-25 02:54:43,609 INFO mapreduce.Job: map 5% reduce 0%
2022-08-25 02:54:44,694 INFO mapreduce.Job: map 11% reduce 0%
2022-08-25 02:54:45,749 INFO mapreduce.Job: map 15% reduce 0%
2022-08-25 02:56:13,530 INFO mapreduce.Job: map 16% reduce 0%
2022-08-25 02:56:18,956 INFO mapreduce.Job: map 17% reduce 0%
2022-08-25 02:56:33,059 INFO mapreduce.Job: map 18% reduce 0%
2022-08-25 02:56:34,150 INFO mapreduce.Job: map 19% reduce 0%
2022-08-25 02:57:19,554 INFO mapreduce.Job: map 20% reduce 0%
2022-08-25 02:57:25,523 INFO mapreduce.Job: map 21% reduce 0%
2022-08-25 02:57:28,760 INFO mapreduce.Job: map 22% reduce 0%
2022-08-25 02:57:30,919 INFO mapreduce.Job: map 22% reduce 4%
2022-08-25 02:57:32,000 INFO mapreduce.Job: map 24% reduce 4%
2022-08-25 02:57:33,084 INFO mapreduce.Job: map 25% reduce 4%
2022-08-25 02:57:34,167 INFO mapreduce.Job: map 26% reduce 4%
2022-08-25 02:57:37,641 INFO mapreduce.Job: map 27% reduce 8%
2022-08-25 02:57:39,795 INFO mapreduce.Job: map 28% reduce 8%
2022-08-25 02:57:44,378 INFO mapreduce.Job: map 29% reduce 8%
2022-08-25 02:57:45,694 INFO mapreduce.Job: map 30% reduce 8%
2022-08-25 02:57:46,785 INFO mapreduce.Job: map 31% reduce 8%
2022-08-25 02:57:47,880 INFO mapreduce.Job: map 32% reduce 8%
2022-08-25 02:57:50,052 INFO mapreduce.Job: map 34% reduce 8%
2022-08-25 02:57:51,136 INFO mapreduce.Job: map 36% reduce 8%
2022-08-25 02:57:52,215 INFO mapreduce.Job: map 37% reduce 8%
2022-08-25 02:58:53,057 INFO mapreduce.Job: map 38% reduce 8%
2022-08-25 02:59:04,346 INFO mapreduce.Job: map 39% reduce 8%
2022-08-25 02:59:07,803 INFO mapreduce.Job: map 40% reduce 8%
2022-08-25 02:59:08,880 INFO mapreduce.Job: map 40% reduce 9%
2022-08-25 02:59:18,849 INFO mapreduce.Job: map 41% reduce 9%
2022-08-25 02:59:21,029 INFO mapreduce.Job: map 41% reduce 10%
2022-08-25 02:59:22,113 INFO mapreduce.Job: map 42% reduce 10%
2022-08-25 02:59:28,829 INFO mapreduce.Job: map 43% reduce 10%
2022-08-25 02:59:57,449 INFO mapreduce.Job: map 44% reduce 10%
2022-08-25 03:00:02,848 INFO mapreduce.Job: map 44% reduce 11%
2022-08-25 03:00:08,275 INFO mapreduce.Job: map 45% reduce 11%
2022-08-25 03:00:12,603 INFO mapreduce.Job: map 46% reduce 11%
2022-08-25 03:00:14,989 INFO mapreduce.Job: map 47% reduce 12%
2022-08-25 03:00:18,244 INFO mapreduce.Job: map 48% reduce 12%
2022-08-25 03:00:20,414 INFO mapreduce.Job: map 49% reduce 12%
2022-08-25 03:00:21,499 INFO mapreduce.Job: map 49% reduce 13%
2022-08-25 03:00:23,674 INFO mapreduce.Job: map 50% reduce 13%
2022-08-25 03:00:29,091 INFO mapreduce.Job: map 51% reduce 13%
2022-08-25 03:00:30,176 INFO mapreduce.Job: map 52% reduce 13%
2022-08-25 03:00:32,348 INFO mapreduce.Job: map 53% reduce 13%
2022-08-25 03:00:33,437 INFO mapreduce.Job: map 53% reduce 15%
2022-08-25 03:00:35,598 INFO mapreduce.Job: map 54% reduce 15%
2022-08-25 03:00:38,831 INFO mapreduce.Job: map 55% reduce 15%
2022-08-25 03:00:40,993 INFO mapreduce.Job: map 56% reduce 15%
2022-08-25 03:00:43,150 INFO mapreduce.Job: map 57% reduce 15%
2022-08-25 03:00:45,313 INFO mapreduce.Job: map 58% reduce 15%
2022-08-25 03:00:47,458 INFO mapreduce.Job: map 59% reduce 15%
2022-08-25 03:00:54,249 INFO mapreduce.Job: map 60% reduce 15%
2022-08-25 03:00:58,591 INFO mapreduce.Job: map 60% reduce 16%
2022-08-25 03:01:08,314 INFO mapreduce.Job: map 61% reduce 16%
2022-08-25 03:01:52,066 INFO mapreduce.Job: map 62% reduce 16%
2022-08-25 03:02:00,733 INFO mapreduce.Job: map 63% reduce 16%
2022-08-25 03:02:04,201 INFO mapreduce.Job: map 63% reduce 17%
2022-08-25 03:02:09,610 INFO mapreduce.Job: map 64% reduce 17%
2022-08-25 03:02:15,017 INFO mapreduce.Job: map 65% reduce 17%
2022-08-25 03:02:25,848 INFO mapreduce.Job: map 66% reduce 17%
2022-08-25 03:02:28,243 INFO mapreduce.Job: map 66% reduce 18%
2022-08-25 03:02:29,329 INFO mapreduce.Job: map 67% reduce 18%
2022-08-25 03:02:39,335 INFO mapreduce.Job: map 68% reduce 18%
2022-08-25 03:02:40,408 INFO mapreduce.Job: map 68% reduce 19%
2022-08-25 03:02:43,653 INFO mapreduce.Job: map 69% reduce 19%
2022-08-25 03:02:44,726 INFO mapreduce.Job: map 70% reduce 19%
2022-08-25 03:02:50,110 INFO mapreduce.Job: map 71% reduce 19%
2022-08-25 03:02:52,830 INFO mapreduce.Job: map 72% reduce 20%
2022-08-25 03:03:03,013 INFO mapreduce.Job: map 73% reduce 20%
2022-08-25 03:03:04,098 INFO mapreduce.Job: map 74% reduce 20%
2022-08-25 03:03:07,344 INFO mapreduce.Job: map 75% reduce 20%
2022-08-25 03:03:12,764 INFO mapreduce.Job: map 76% reduce 20%
2022-08-25 03:03:17,339 INFO mapreduce.Job: map 76% reduce 21%
2022-08-25 03:03:22,761 INFO mapreduce.Job: map 76% reduce 22%
2022-08-25 03:03:23,839 INFO mapreduce.Job: map 77% reduce 22%
2022-08-25 03:03:26,010 INFO mapreduce.Job: map 78% reduce 22%
2022-08-25 03:03:27,097 INFO mapreduce.Job: map 79% reduce 22%
2022-08-25 03:03:29,266 INFO mapreduce.Job: map 79% reduce 23%
2022-08-25 03:03:34,908 INFO mapreduce.Job: map 80% reduce 23%
2022-08-25 03:03:39,241 INFO mapreduce.Job: map 82% reduce 23%
2022-08-25 03:03:52,923 INFO mapreduce.Job: map 83% reduce 23%
2022-08-25 03:03:57,470 INFO mapreduce.Job: map 84% reduce 23%
2022-08-25 03:03:59,630 INFO mapreduce.Job: map 84% reduce 24%
2022-08-25 03:04:10,447 INFO mapreduce.Job: map 85% reduce 24%
2022-08-25 03:04:20,630 INFO mapreduce.Job: map 86% reduce 24%
2022-08-25 03:04:27,116 INFO mapreduce.Job: map 87% reduce 24%
2022-08-25 03:04:29,281 INFO mapreduce.Job: map 87% reduce 25%
2022-08-25 03:04:35,742 INFO mapreduce.Job: map 88% reduce 25%
2022-08-25 03:04:36,816 INFO mapreduce.Job: map 89% reduce 25%
2022-08-25 03:04:42,448 INFO mapreduce.Job: map 90% reduce 26%
2022-08-25 03:04:44,597 INFO mapreduce.Job: map 91% reduce 26%
2022-08-25 03:04:47,840 INFO mapreduce.Job: map 91% reduce 27%
2022-08-25 03:04:50,001 INFO mapreduce.Job: map 92% reduce 27%
2022-08-25 03:04:52,377 INFO mapreduce.Job: map 93% reduce 27%
2022-08-25 03:04:55,620 INFO mapreduce.Job: map 94% reduce 27%
2022-08-25 03:05:17,872 INFO mapreduce.Job: map 95% reduce 28%
2022-08-25 03:05:29,747 INFO mapreduce.Job: map 96% reduce 29%
2022-08-25 03:05:44,877 INFO mapreduce.Job: map 97% reduce 29%
2022-08-25 03:05:48,361 INFO mapreduce.Job: map 97% reduce 30%
2022-08-25 03:06:06,105 INFO mapreduce.Job: map 98% reduce 31%
2022-08-25 03:06:12,564 INFO mapreduce.Job: map 98% reduce 32%
2022-08-25 03:06:13,585 INFO mapreduce.Job: map 100% reduce 32%
2022-08-25 03:06:15,589 INFO mapreduce.Job: map 100% reduce 100%
2022-08-25 03:06:15,594 INFO mapreduce.Job: Job job_1661395853554_0002 completed successfully
2022-08-25 03:06:15,667 INFO mapreduce.Job: Counters: 53
File System Counters
FILE: Number of bytes read=8600
FILE: Number of bytes written=22446697
FILE: Number of readoperations=0
FILE: Number of large readoperations=0
FILE: Number of writeoperations=0
HDFS: Number of bytes read=23480
HDFS: Number of bytes written=10485760081
HDFS: Number of readoperations=405
HDFS: Number of large readoperations=0
HDFS: Number of writeoperations=102
Job Counters
Launched map tasks=100
Launched reduce tasks=1
Data-local map tasks=100
Total time spent by all maps in occupied slots (ms)=14377072
Total time spent by all reduces in occupied slots (ms)=537813
Total time spent by all map tasks (ms)=14377072
Total time spent by all reduce tasks (ms)=537813
Total vcore-milliseconds taken by all map tasks=14377072
Total vcore-milliseconds taken by all reduce tasks=537813
Total megabyte-milliseconds taken by all map tasks=14722121728
Total megabyte-milliseconds taken by all reduce tasks=550720512
Map-Reduce Framework
Map input records=100
Map output records=500
Map output bytes=7594
Map output materialized bytes=9194
Input splitbytes=12190
Combine input records=0
Combine output records=0
Reduce input groups=5
Reduce shuffle bytes=9194
Reduce input records=500
Reduce output records=5
Spilled Records=1000
Shuffled Maps =100
Failed Shuffles=0
Merged Map outputs=100
GC time elapsed (ms)=12694
CPU time spent (ms)=233920
Physical memory (bytes)snapshot=35032891392
Virtual memory (bytes)snapshot=280810868736
Total committed heap usage (bytes)=41180725248
Peak Map Physical memory (bytes)=389386240
Peak Map Virtual memory (bytes)=2800513024
Peak Reduce Physical memory (bytes)=362102784
Peak Reduce Virtual memory (bytes)=2801356800
Shuffle Errors
BAD_ID=0CONNECTION=0IO_ERROR=0WRONG_LENGTH=0WRONG_MAP=0WRONG_REDUCE=0
File Input Format Counters
Bytes Read=11290
File Output Format Counters
Bytes Written=812022-08-25 03:06:15,705 INFO fs.TestDFSIO: ----- TestDFSIO ----- :write2022-08-25 03:06:15,705 INFO fs.TestDFSIO: Date & time: Thu Aug 25 03:06:15 GMT 20222022-08-25 03:06:15,705 INFO fs.TestDFSIO: Number of files: 1002022-08-25 03:06:15,705 INFO fs.TestDFSIO: Total MBytes processed: 100002022-08-25 03:06:15,705 INFO fs.TestDFSIO: Throughput mb/sec: 0.722022-08-25 03:06:15,705 INFO fs.TestDFSIO: Average IO rate mb/sec: 0.772022-08-25 03:06:15,705 INFO fs.TestDFSIO: IO rate std deviation: 0.212022-08-25 03:06:15,705 INFO fs.TestDFSIO: Test exectime sec: 720.252022-08-25 03:06:15,705 INFO fs.TestDFSIO:
按照上面的yarn-site.xml配置会出现如下异常(虚拟内存不够)
[2022-08-25 02:37:18.885]Container [pid=20349,containerID=container_1661393017372_0006_01_000007] is running 515447296B beyond the 'VIRTUAL' memory limit. Current usage: 142.5 MB of 1 GB physical memory used;2.6 GB of 2.1 GB virtual memory used. Killing container.
Dump of the process-tree for container_1661393017372_0006_01_000007 :|- PID PPID PGRPID SESSID CMD_NAME USER_MODE_TIME(MILLIS) SYSTEM_TIME(MILLIS) VMEM_USAGE(BYTES) RSSMEM_USAGE(PAGES) FULL_CMD_LINE
|- 20393203492034920349(java)2428265444966436137 /usr/java/jdk1.8.0_144/bin/java -Djava.net.preferIPv4Stack=true -Dhadoop.metrics.log.level=WARN -Xmx820m -Djava.io.tmpdir=/usr/local/bigdata/hadoop-3.1.4/nm-local-dir/usercache/alanchan/appcache/application_1661393017372_0006/container_1661393017372_0006_01_000007/tmp -Dlog4j.configuration=container-log4j.properties -Dyarn.app.container.log.dir=/usr/local/bigdata/hadoop-3.1.4/logs/userlogs/application_1661393017372_0006/container_1661393017372_0006_01_000007 -Dyarn.app.container.log.filesize=0 -Dhadoop.root.logger=INFO,CLA -Dhadoop.root.logfile=syslog org.apache.hadoop.mapred.YarnChild 192.168.10.44 44408 attempt_1661393017372_0006_m_000005_0 7|- 20349203452034920349(bash)00115855360352 /bin/bash -c /usr/java/jdk1.8.0_144/bin/java -Djava.net.preferIPv4Stack=true -Dhadoop.metrics.log.level=WARN -Xmx820m -Djava.io.tmpdir=/usr/local/bigdata/hadoop-3.1.4/nm-local-dir/usercache/alanchan/appcache/application_1661393017372_0006/container_1661393017372_0006_01_000007/tmp -Dlog4j.configuration=container-log4j.properties -Dyarn.app.container.log.dir=/usr/local/bigdata/hadoop-3.1.4/logs/userlogs/application_1661393017372_0006/container_1661393017372_0006_01_000007 -Dyarn.app.container.log.filesize=0 -Dhadoop.root.logger=INFO,CLA -Dhadoop.root.logfile=syslog org.apache.hadoop.mapred.YarnChild 192.168.10.44 44408 attempt_1661393017372_0006_m_000005_0 71>/usr/local/bigdata/hadoop-3.1.4/logs/userlogs/application_1661393017372_0006/container_1661393017372_0006_01_000007/stdout 2>/usr/local/bigdata/hadoop-3.1.4/logs/userlogs/application_1661393017372_0006/container_1661393017372_0006_01_000007/stderr
[2022-08-25 02:37:18.959]Container killed on request. Exit code is 143
解决办法:
#修改yarn-site.xml文件,将虚拟内存与物理内存比例设置为4,增加虚拟内存检查为false,默认是true<!-- 容器虚拟内存与物理内存之间的比率。--><property><name>yarn.nodemanager.vmem-pmem-ratio</name><value>4</value></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value><description>Whether virtual memory limits will be enforced for containers</description></property>
设置完成后,先关闭yarn,然后再启动
stop-yarn.sh
start-yarn.sh
2、测试读取速度
#在HDFS文件系统中读入100个文件,每个文件100M#Throughput:吞吐量、Average IO rate:平均IO率、IO rate std deviation:IO率标准偏差
hadoop jar /export/server/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.4-tests.jar TestDFSIO -read -nrFiles 100 -fileSize 100MB
[alanchan@server4 mapreduce]$ hadoop jar /usr/local/bigdata/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.4-tests.jar TestDFSIO -read -nrFiles 100 -fileSize 100MB
2022-08-25 03:55:28,687 INFO fs.TestDFSIO: TestDFSIO.1.8
2022-08-25 03:55:28,689 INFO fs.TestDFSIO: nrFiles =1002022-08-25 03:55:28,689 INFO fs.TestDFSIO: nrBytes (MB)=100.02022-08-25 03:55:28,689 INFO fs.TestDFSIO: bufferSize =10000002022-08-25 03:55:28,689 INFO fs.TestDFSIO: baseDir = /benchmarks/TestDFSIO
2022-08-25 03:55:29,301 INFO fs.TestDFSIO: creating control file: 104857600 bytes, 100 files
2022-08-25 03:55:31,885 INFO fs.TestDFSIO: created control files for: 100 files
2022-08-25 03:55:31,957 INFO client.RMProxy: Connecting to ResourceManager at server1/192.168.10.41:8032
2022-08-25 03:55:32,114 INFO client.RMProxy: Connecting to ResourceManager at server1/192.168.10.41:8032
2022-08-25 03:55:32,369 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/alanchan/.staging/job_1661395853554_0008
2022-08-25 03:55:32,652 INFO mapred.FileInputFormat: Total input files to process :1002022-08-25 03:55:32,729 INFO mapreduce.JobSubmitter: number of splits:100
2022-08-25 03:55:32,859 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1661395853554_0008
2022-08-25 03:55:32,861 INFO mapreduce.JobSubmitter: Executing with tokens: []2022-08-25 03:55:33,001 INFO conf.Configuration: resource-types.xml not found
2022-08-25 03:55:33,001 INFO resource.ResourceUtils: Unable to find'resource-types.xml'.2022-08-25 03:55:33,049 INFO impl.YarnClientImpl: Submitted application application_1661395853554_0008
2022-08-25 03:55:33,079 INFO mapreduce.Job: The url to track the job: http://server1:8088/proxy/application_1661395853554_0008/
2022-08-25 03:55:33,080 INFO mapreduce.Job: Running job: job_1661395853554_0008
2022-08-25 03:55:38,165 INFO mapreduce.Job: Job job_1661395853554_0008 running in uber mode :false2022-08-25 03:55:38,166 INFO mapreduce.Job: map 0% reduce 0%
2022-08-25 03:55:47,245 INFO mapreduce.Job: map 3% reduce 0%
2022-08-25 03:55:48,255 INFO mapreduce.Job: map 6% reduce 0%
2022-08-25 03:55:50,263 INFO mapreduce.Job: map 14% reduce 0%
2022-08-25 03:55:51,270 INFO mapreduce.Job: map 22% reduce 0%
2022-08-25 03:55:55,306 INFO mapreduce.Job: map 24% reduce 0%
2022-08-25 03:55:56,310 INFO mapreduce.Job: map 28% reduce 0%
2022-08-25 03:55:58,322 INFO mapreduce.Job: map 30% reduce 0%
2022-08-25 03:56:00,335 INFO mapreduce.Job: map 35% reduce 0%
2022-08-25 03:56:01,340 INFO mapreduce.Job: map 36% reduce 0%
2022-08-25 03:56:02,351 INFO mapreduce.Job: map 43% reduce 0%
2022-08-25 03:56:03,355 INFO mapreduce.Job: map 45% reduce 0%
2022-08-25 03:56:04,363 INFO mapreduce.Job: map 49% reduce 0%
2022-08-25 03:56:06,369 INFO mapreduce.Job: map 50% reduce 0%
2022-08-25 03:56:07,373 INFO mapreduce.Job: map 51% reduce 0%
2022-08-25 03:56:08,377 INFO mapreduce.Job: map 55% reduce 17%
2022-08-25 03:56:09,381 INFO mapreduce.Job: map 57% reduce 17%
2022-08-25 03:56:11,392 INFO mapreduce.Job: map 60% reduce 17%
2022-08-25 03:56:12,396 INFO mapreduce.Job: map 66% reduce 17%
2022-08-25 03:56:13,401 INFO mapreduce.Job: map 71% reduce 17%
2022-08-25 03:56:14,405 INFO mapreduce.Job: map 71% reduce 24%
2022-08-25 03:56:15,409 INFO mapreduce.Job: map 73% reduce 24%
2022-08-25 03:56:16,414 INFO mapreduce.Job: map 75% reduce 24%
2022-08-25 03:56:17,419 INFO mapreduce.Job: map 77% reduce 24%
2022-08-25 03:56:18,422 INFO mapreduce.Job: map 79% reduce 24%
2022-08-25 03:56:19,427 INFO mapreduce.Job: map 84% reduce 24%
2022-08-25 03:56:20,430 INFO mapreduce.Job: map 84% reduce 28%
2022-08-25 03:56:21,440 INFO mapreduce.Job: map 86% reduce 28%
2022-08-25 03:56:23,446 INFO mapreduce.Job: map 92% reduce 28%
2022-08-25 03:56:24,449 INFO mapreduce.Job: map 99% reduce 28%
2022-08-25 03:56:25,452 INFO mapreduce.Job: map 100% reduce 28%
2022-08-25 03:56:26,455 INFO mapreduce.Job: map 100% reduce 100%
2022-08-25 03:56:26,460 INFO mapreduce.Job: Job job_1661395853554_0008 completed successfully
2022-08-25 03:56:26,539 INFO mapreduce.Job: Counters: 53
File System Counters
FILE: Number of bytes read=8588
FILE: Number of bytes written=22446471
FILE: Number of readoperations=0
FILE: Number of large readoperations=0
FILE: Number of writeoperations=0
HDFS: Number of bytes read=10485783480
HDFS: Number of bytes written=84
HDFS: Number of readoperations=505
HDFS: Number of large readoperations=0
HDFS: Number of writeoperations=2
Job Counters
Launched map tasks=100
Launched reduce tasks=1
Data-local map tasks=100
Total time spent by all maps in occupied slots (ms)=823913
Total time spent by all reduces in occupied slots (ms)=35507
Total time spent by all map tasks (ms)=823913
Total time spent by all reduce tasks (ms)=35507
Total vcore-milliseconds taken by all map tasks=823913
Total vcore-milliseconds taken by all reduce tasks=35507
Total megabyte-milliseconds taken by all map tasks=843686912
Total megabyte-milliseconds taken by all reduce tasks=36359168
Map-Reduce Framework
Map input records=100
Map output records=500
Map output bytes=7582
Map output materialized bytes=9182
Input splitbytes=12190
Combine input records=0
Combine output records=0
Reduce input groups=5
Reduce shuffle bytes=9182
Reduce input records=500
Reduce output records=5
Spilled Records=1000
Shuffled Maps =100
Failed Shuffles=0
Merged Map outputs=100
GC time elapsed (ms)=11482
CPU time spent (ms)=72370
Physical memory (bytes)snapshot=30965710848
Virtual memory (bytes)snapshot=280591712256
Total committed heap usage (bytes)=20881342464
Peak Map Physical memory (bytes)=353017856
Peak Map Virtual memory (bytes)=2795540480
Peak Reduce Physical memory (bytes)=214671360
Peak Reduce Virtual memory (bytes)=2798829568
Shuffle Errors
BAD_ID=0CONNECTION=0IO_ERROR=0WRONG_LENGTH=0WRONG_MAP=0WRONG_REDUCE=0
File Input Format Counters
Bytes Read=11290
File Output Format Counters
Bytes Written=842022-08-25 03:56:26,576 INFO fs.TestDFSIO: ----- TestDFSIO ----- :read2022-08-25 03:56:26,576 INFO fs.TestDFSIO: Date & time: Thu Aug 25 03:56:26 GMT 20222022-08-25 03:56:26,576 INFO fs.TestDFSIO: Number of files: 1002022-08-25 03:56:26,576 INFO fs.TestDFSIO: Total MBytes processed: 100002022-08-25 03:56:26,576 INFO fs.TestDFSIO: Throughput mb/sec: 195.682022-08-25 03:56:26,576 INFO fs.TestDFSIO: Average IO rate mb/sec: 243.472022-08-25 03:56:26,576 INFO fs.TestDFSIO: IO rate std deviation: 138.982022-08-25 03:56:26,576 INFO fs.TestDFSIO: Test exectime sec: 54.652022-08-25 03:56:26,576 INFO fs.TestDFSIO:
3、清除测试数据
#测试期间,会在HDFS集群上创建 /benchmarks目录,测试完毕后,我们可以清理该目录。
hadoop jar /usr/local/bigdata/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.4-tests.jar TestDFSIO -clean
[alanchan@server4 mapreduce]$ hadoop jar /usr/local/bigdata/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.4-tests.jar TestDFSIO -clean
2022-08-25 03:59:44,676 INFO fs.TestDFSIO: TestDFSIO.1.8
2022-08-25 03:59:44,677 INFO fs.TestDFSIO: nrFiles =12022-08-25 03:59:44,677 INFO fs.TestDFSIO: nrBytes (MB)=1.02022-08-25 03:59:44,677 INFO fs.TestDFSIO: bufferSize =10000002022-08-25 03:59:44,677 INFO fs.TestDFSIO: baseDir = /benchmarks/TestDFSIO
2022-08-25 03:59:45,287 INFO fs.TestDFSIO: Cleaning up test files
五、常见异常处理
1、浏览器HDFS文件系统上传文件时报Couldn’t upload the file错误
F12打开谷歌控制台,看到报as been blocked by CORS policy: No ‘Access-Control-Allow-Origin’ header is present on the requested resource.错误,大概意思是由于跨域访问CORS policy策略,访问阻塞了:
有时候是网络的原因,有时候是用户配置的原因
2、在格式化期间可能出现如下异常的解决办法
以下警告解决
2022-08-25 09:59:37,186 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Formatting using clusterid: CID-ffdc8a28-a92d-45fc-bd34-382c1645e64a
[root@master native]# ldd libhadoop.so.1.0.0
./libhadoop.so.1.0.0: /lib64/libc.so.6: version `GLIBC_2.14' not found (required by ./libhadoop.so.1.0.0)
linux-vdso.so.1 =>(0x00007fff31efd000)
libdl.so.2 => /lib64/libdl.so.2 (0x00007f654dd25000)
libpthread.so.0 => /lib64/libpthread.so.0 (0x00007f654db07000)
libc.so.6 => /lib64/libc.so.6 (0x00007f654d775000)
/lib64/ld-linux-x86-64.so.2 (0x00007f654e155000)[root@master sbin]# ldd --version
ldd (GNU libc)2.12
Copyright (C)2010 Free Software Foundation, Inc.
This is free software; see the sourcefor copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
由 Roland McGrath 和 Ulrich Drepper 编写。
[root@master sbin]# strings /lib64/libc.so.6|grep GLIBC
GLIBC_2.2.5
GLIBC_2.2.6
GLIBC_2.3
GLIBC_2.3.2
GLIBC_2.3.3
GLIBC_2.3.4
GLIBC_2.4
GLIBC_2.5
GLIBC_2.6
GLIBC_2.7
GLIBC_2.8
GLIBC_2.9
GLIBC_2.10
GLIBC_2.11
GLIBC_2.12
GLIBC_PRIVATE
# 最大支持到2.12版本,而我们hadoop中的版本是2.14,可以确定基本是这个问题造成的;那接下来的解决办法就是更新系统的CLIBC版本。cd /usr/local/tools
wget http://ftp.gnu.org/gnu/glibc/glibc-2.17.tar.gz
[root@master tools]# tar -zxvf glibc-2.17.tar.gz -C /usr/local[root@master tools]# cd /usr/local/glibc-2.17[root@master glibc-2.17]#[root@master glibc-2.17]# mkdir build[root@master glibc-2.17]# cd build/[root@master build]#../configure --prefix=/usr --disable-profile --enable-add-ons --with-headers=/usr/include --with-binutils=/usr/bin[root@master build]#make && make install [root@master build]# strings /lib64/libc.so.6|grep GLIBC
GLIBC_2.2.5
GLIBC_2.2.6
GLIBC_2.3
GLIBC_2.3.2
GLIBC_2.3.3
GLIBC_2.3.4
GLIBC_2.4
GLIBC_2.5
GLIBC_2.6
GLIBC_2.7
GLIBC_2.8
GLIBC_2.9
GLIBC_2.10
GLIBC_2.11
GLIBC_2.12
GLIBC_2.13
GLIBC_2.14
GLIBC_2.15
GLIBC_2.16
GLIBC_2.17
GLIBC_PRIVATE
#重新启动[alanchan@server1 sbin]$ start-all.sh
WARNING: Attempting to start all Apache Hadoop daemons as alanchan in10 seconds.
WARNING: This is not a recommended production deployment configuration.
WARNING: Use CTRL-C to abort.
Starting namenodes on [server1]
Starting datanodes
Starting secondary namenodes [server2]
Starting resourcemanager
Starting nodemanagers
版权归原作者 一瓢一瓢的饮 alanchan 所有, 如有侵权,请联系我们删除。