
系列文章目录
通过Java+Selenium查询文章质量分
通过Java+Selenium查询某个博主的Top40文章质量分
通过Java+Selenium查询某个博主的Top100文章质量分
文章目录

前言
大家好,我是青花,本篇给大家分享一下《通过Java+Selenium查询某个博主的Top100文章质量分》,针对上一章Top40文章,做了简单的优化,在查询博客质量分的时候,控制了频繁的开关Chrome浏览器,避免了重复的加载Chrome驱动以及打开Chrome浏览器。
备注: 在上章节里,加载100文章,在50-60文章数时,就会被限制访问。
一、环境准备
浏览器:本篇使用的是Chrome
Chrome浏览器版本:113
Chrome驱动版本:113(Java爬虫第一篇)
Java版本:Jdk1.8
selenium版本: 4.9.1
二、查询某个博主的Top100文章
2.1、修改pom.xml配置
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup --><dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.11.3</version></dependency><dependency><groupId>org.seleniumhq.selenium</groupId><artifactId>selenium-java</artifactId><version>4.9.1</version></dependency><dependency><groupId>com.google.code.gson</groupId><artifactId>gson</artifactId><version>2.10.1</version></dependency>
2.2、配置Chrome驱动
publicfinalstaticString CHROMEDRIVERPATH ="/Users/apple/Downloads/chromedriver_mac64/chromedriver";
System.setProperty("webdriver.chrome.driver",SeleniumUtil.CHROMEDRIVERPATH );// chromedriver localPath
2.3、引入浏览器配置
WebDriver driver;ChromeOptions chromeOptions =newChromeOptions();
2.4、设置无头模式
chromeOptions.addArguments('--headless')
chromeOptions.addArguments("--remote-allow-origins=*");
2.5、启动浏览器实例,添加配置信息
driver =newChromeDriver(chromeOptions);
2.6、窗口设置
chromeOptions.addArguments("–no-sandbox");//--start-maximized
2.7、禁止加载图片设置
// 增加禁止加载图片的设置HashMap<String,Object> prefs =newHashMap<>();
prefs.put("profile.default_content_settings",2);
chromeOptions.setExperimentalOption("prefs", prefs);
chromeOptions.addArguments("blink-settings=imagesEnabled=false");//禁用图片
2.8、加载博主地址
String baseUrl ="https://blog.csdn.net/s445320?type=blog";
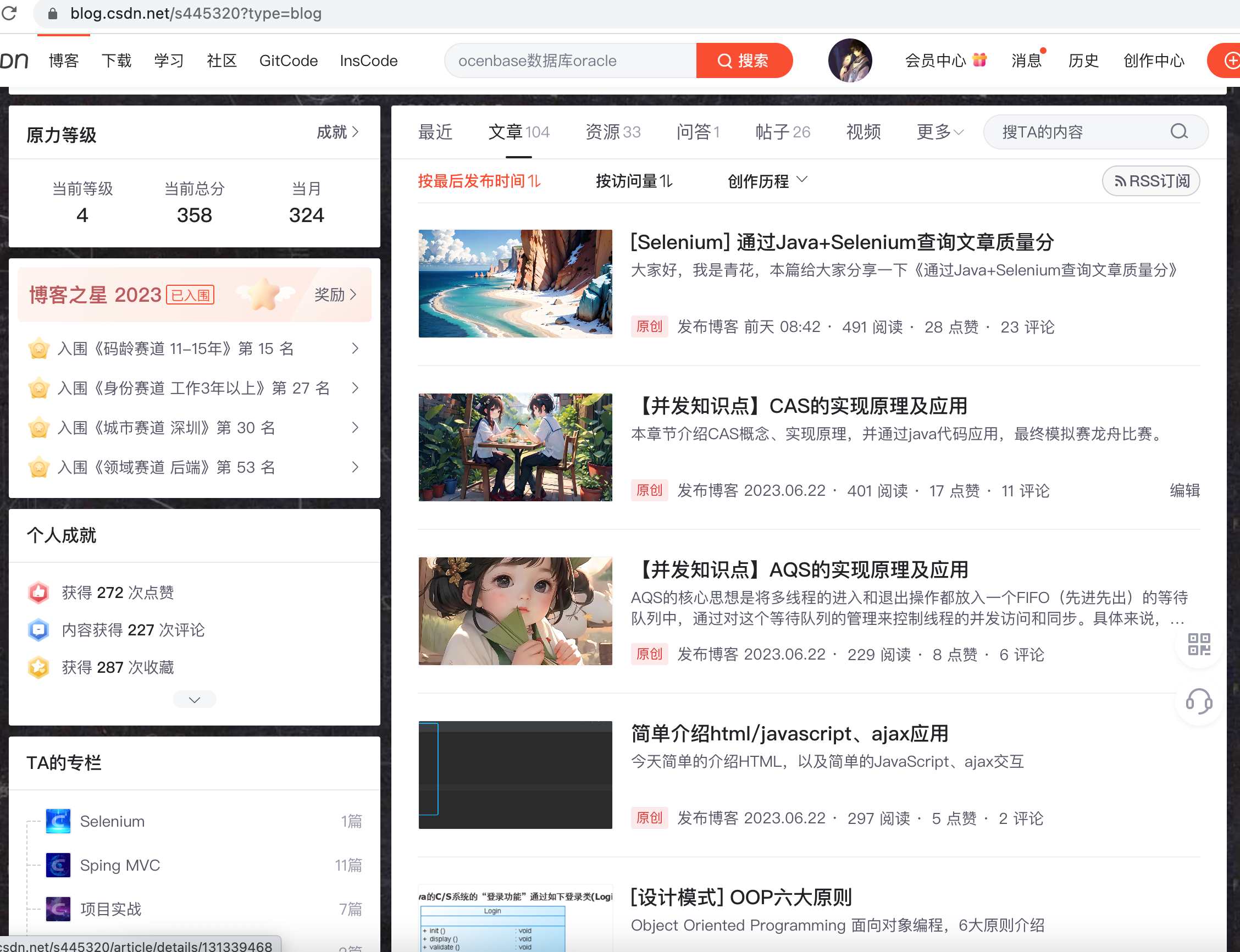
2.9、加载文章列表
//定位到文章列表WebElement mainSelectE = driver.findElement(By.cssSelector("div.mainContent"));
2.10、加载下一页
模拟浏览器滚动条下拉,加载下一页数据
//加载下一页JavascriptExecutor jsDriver =(JavascriptExecutor) driver;//将java中的driver强制转型为JS类型
jsDriver.executeScript("window.scrollTo(0, 50)");
jsDriver.executeScript("window.scrollTo(0, document.body.scrollHeight-20)");SeleniumUtil.sleep(500);
jsDriver.executeScript("window.scrollTo(0, document.body.scrollHeight +1)");SeleniumUtil.sleep(2000);
2.11、设置加载100条数据
// 获取Top100的数量int topNum =100;//如果加载的数据超过或等于 要求的最大长度,返回现在已加载的数据if( webElements.size()>= topNum ){for(WebElement element : webElements ){System.out.println( element.getAttribute("href"));
blogUrlList.add(element.getAttribute("href"));}
log.info("文章已读取 {} 条,最大限制 {} 条!", webElements.size(), topNum);break;}
2.12、对频繁的开关Chrome浏览器做了优化
优化1
针对上一章Top40文章,做了简单的优化,在查询博客质量分的时候,控制了频繁的开关Chrome浏览器,避免了重复的加载Chrome驱动以及打开Chrome浏览器。
优化2
初次的时候加载查询博客质量分页面,后续只需要更换博客文章链接地址,去获取数据即可。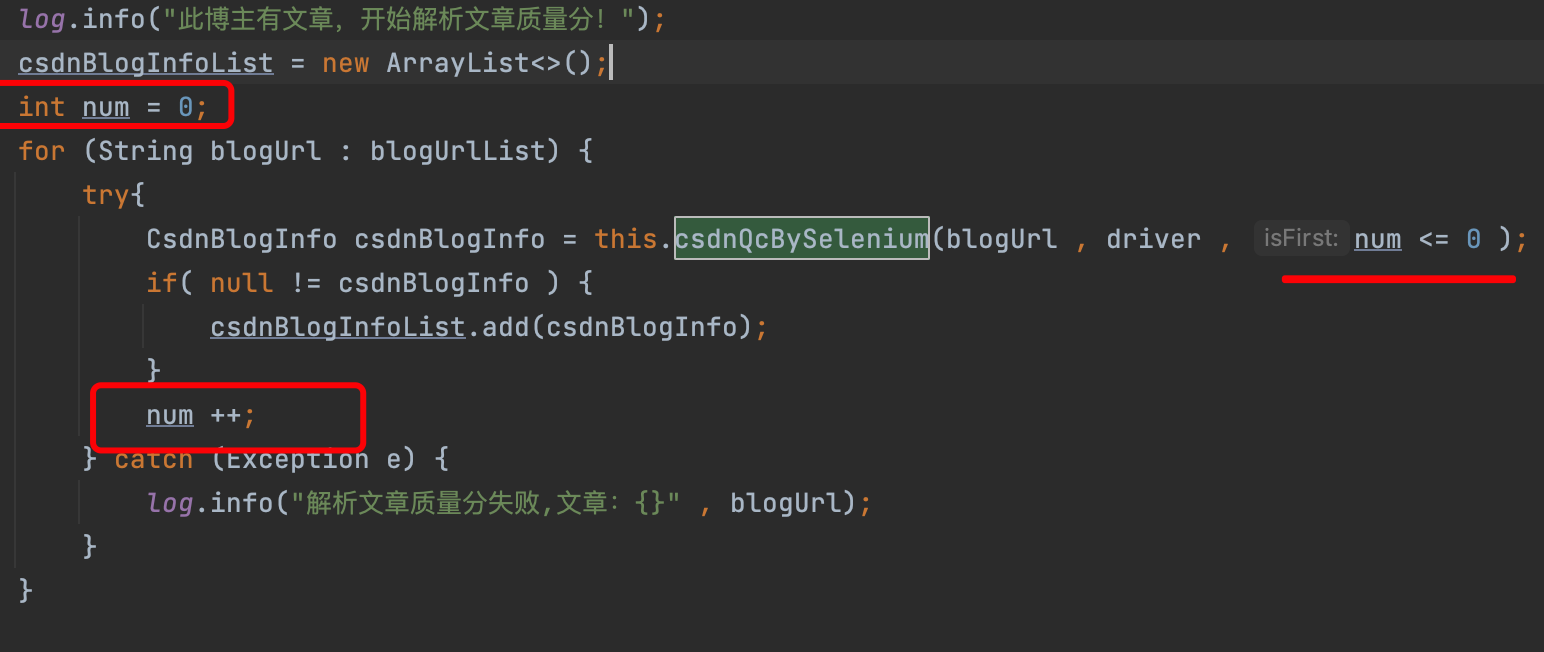
/**
* 获取质量数据
* @throws IOException
*/CsdnBlogInfocsdnQcBySelenium(String blogUrl ,WebDriver driver ,boolean isFirst){
log.info("csdnQcBySelenium start!");CsdnBlogInfo csdnBlogInfo =newCsdnBlogInfo();//第一次时加载查询质量分页面if( isFirst ){
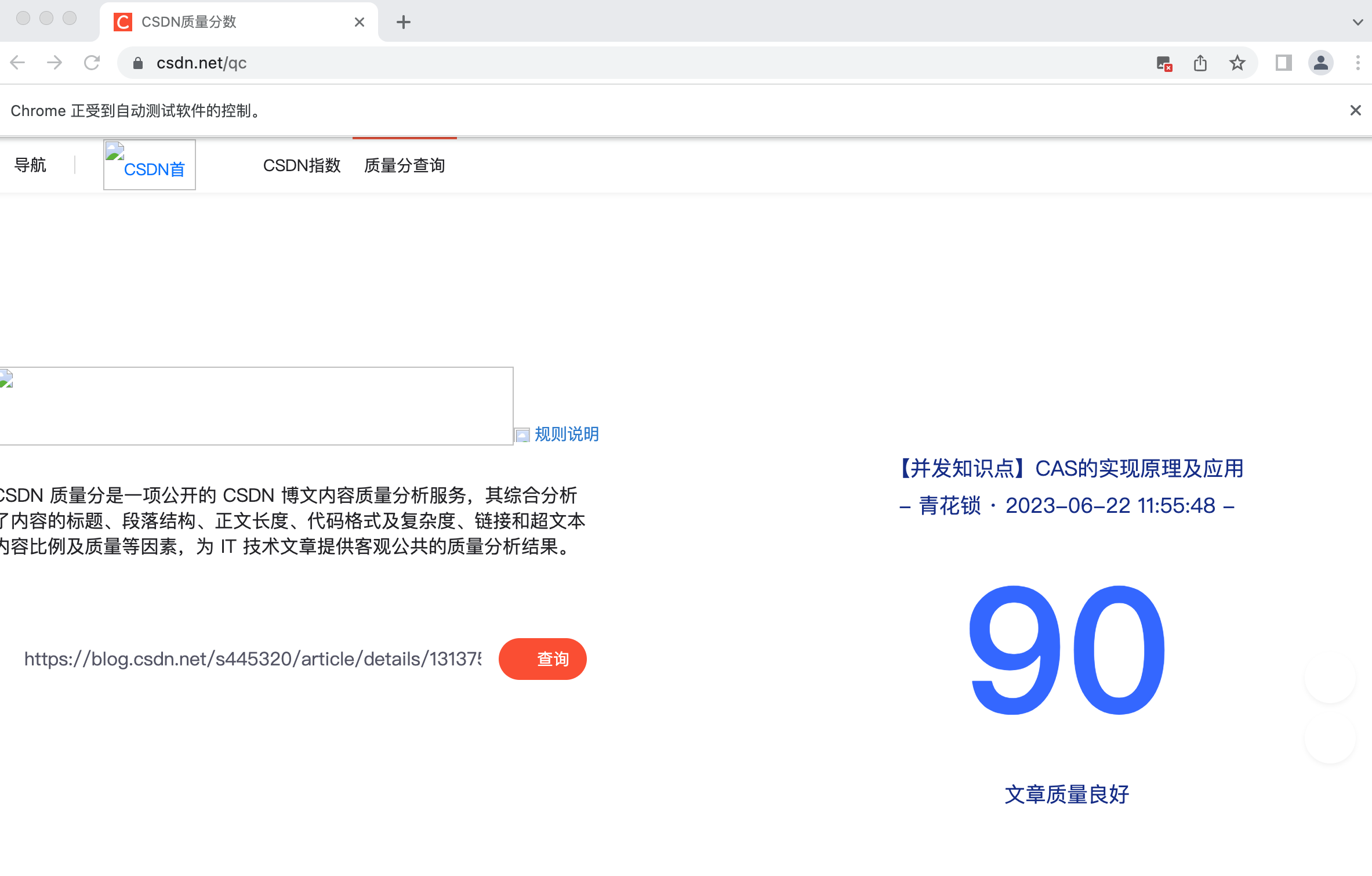
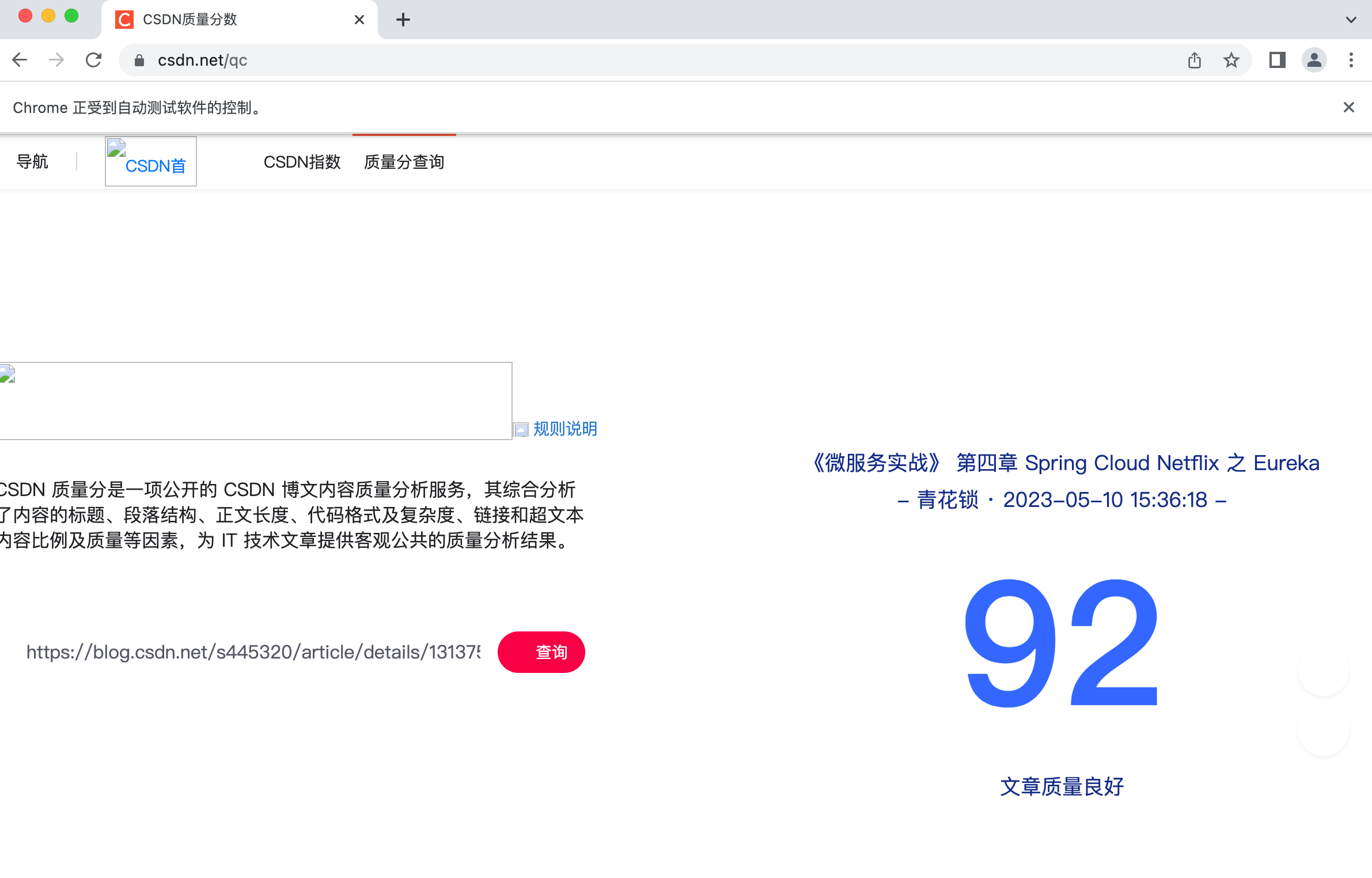
driver.get("https://www.csdn.net/qc");SeleniumUtil.sleep(500);}
2.13、成果
00:44:50.693 [main] INFO com.kelvin.spiderx.service.CsdnQcService - csdnQcBySelenium start!
00:45:03.151 [main] INFO com.kelvin.spiderx.service.CsdnQcService - 文章已读取 100 条,最大限制 100 条!
00:45:03.151 [main] INFO com.kelvin.spiderx.service.CsdnQcService - blogUrlList size:100
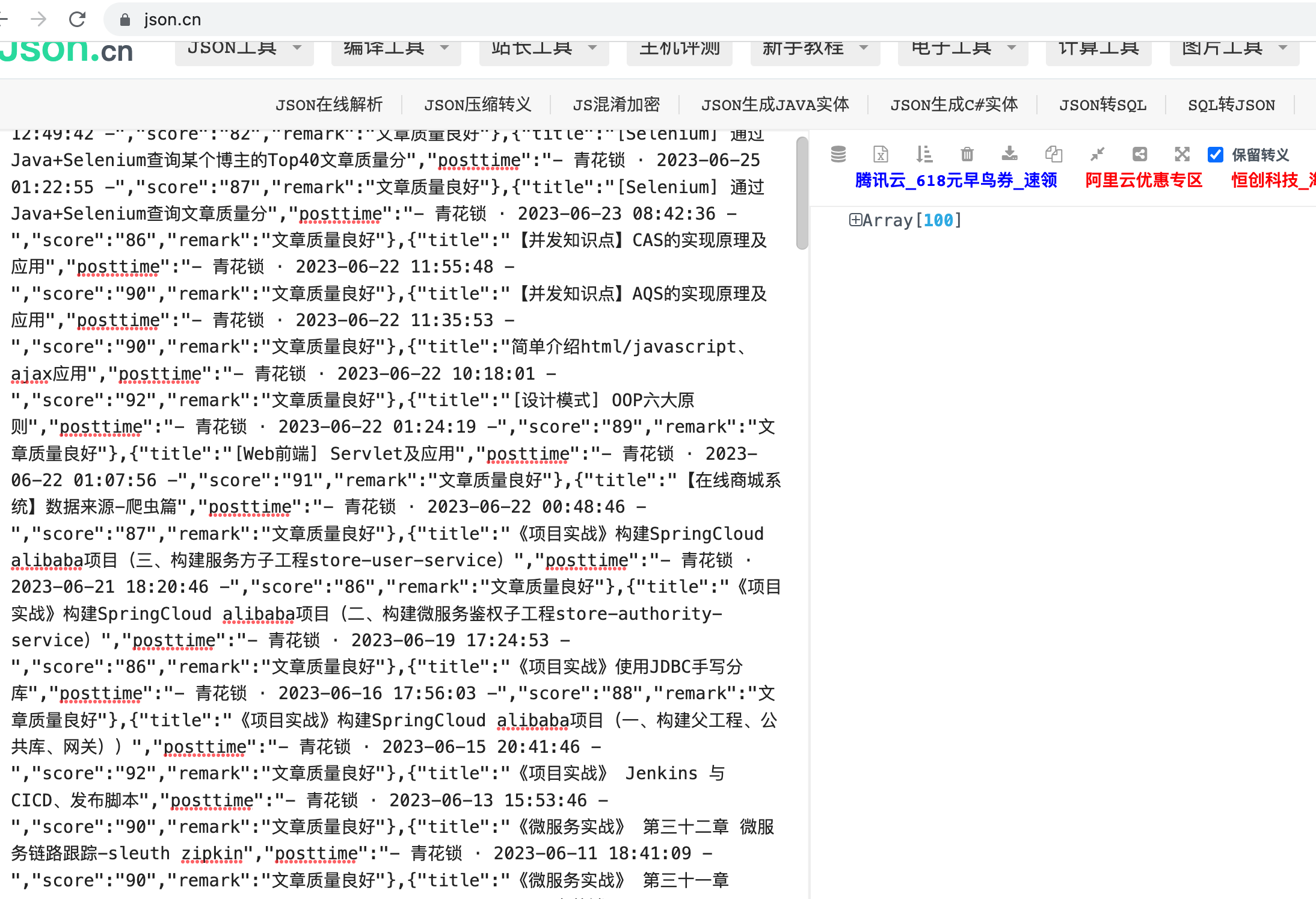
00:45:03.294 [main] INFO com.kelvin.spiderx.service.CsdnQcService - blogUrlList:
[{"title":"[刷题] 删除有序数组中的重复项","posttime":"- 青花锁 · 2023-06-25 12:49:42 -","score":"82","remark":"文章质量良好"},{"title":"[Selenium] 通过Java+Selenium查询某个博主的Top40文章质量分","posttime":"- 青花锁 · 2023-06-25 01:22:55 -","score":"87","remark":"文章质量良好"},{"title":"[Selenium] 通过Java+Selenium查询文章质量分","posttime":"- 青花锁 · 2023-06-23 08:42:36 -","score":"86","remark":"文章质量良好"},{"title":"【并发知识点】CAS的实现原理及应用","posttime":"- 青花锁 · 2023-06-22 11:55:48 -","score":"90","remark":"文章质量良好"},{"title":"【并发知识点】AQS的实现原理及应用","posttime":"- 青花锁 · 2023-06-22 11:35:53 -","score":"90","remark":"文章质量良好"},{"title":"简单介绍html/javascript、ajax应用","posttime":"- 青花锁 · 2023-06-22 10:18:01 -","score":"92","remark":"文章质量良好"},{"title":"[设计模式] OOP六大原则","posttime":"- 青花锁 · 2023-06-22 01:24:19 -","score":"89","remark":"文章质量良好"},{"title":"[Web前端] Servlet及应用","posttime":"- 青花锁 · 2023-06-22 01:07:56 -","score":"91","remark":"文章质量良好"},{"title":"【在线商城系统】数据来源-爬虫篇","posttime":"- 青花锁 · 2023-06-22 00:48:46 -","score":"87","remark":"文章质量良好"},{"title":"《项目实战》构建SpringCloud alibaba项目(三、构建服务方子工程store-user-service)","posttime":"- 青花锁 · 2023-06-21 18:20:46 -","score":"86","remark":"文章质量良好"},{"title":"《项目实战》构建SpringCloud alibaba项目(二、构建微服务鉴权子工程store-authority-service)","posttime":"- 青花锁 · 2023-06-19 17:24:53 -","score":"86","remark":"文章质量良好"},{"title":"《项目实战》使用JDBC手写分库","posttime":"- 青花锁 · 2023-06-16 17:56:03 -","score":"88","remark":"文章质量良好"},{"title":"《项目实战》构建SpringCloud alibaba项目(一、构建父工程、公共库、网关))","posttime":"- 青花锁 · 2023-06-15 20:41:46 -","score":"92","remark":"文章质量良好"},{"title":"《项目实战》 Jenkins 与 CICD、发布脚本","posttime":"- 青花锁 · 2023-06-13 15:53:46 -","score":"90","remark":"文章质量良好"},{"title":"《微服务实战》 第三十二章 微服务链路跟踪-sleuth zipkin","posttime":"- 青花锁 · 2023-06-11 18:41:09 -","score":"90","remark":"文章质量良好"},{"title":"《微服务实战》 第三十一章 ShardingSphere - ShardingSphere-JDBC","posttime":"- 青花锁 · 2023-06-11 18:25:34 -","score":"80","remark":"文章质量良好"},{"title":"《微服务实战》 第三十章 分布式事务框架seata TCC模式","posttime":"- 青花锁 · 2023-06-11 10:38:21 -","score":"89","remark":"文章质量良好"},{"title":"《微服务实战》 第二十九章 分布式事务框架seata AT模式","posttime":"- 青花锁 · 2023-06-11 10:23:44 -","score":"92","remark":"文章质量良好"},{"title":"《微服务实战》 第二十八章 分布式锁框架-Redisson","posttime":"- 青花锁 · 2023-06-09 17:55:59 -","score":"91","remark":"文章质量良好"},{"title":"【项目实战】一、Spring boot整合JWT、Vue案例展示用户鉴权","posttime":"- 青花锁 · 2023-06-09 09:06:43 -","score":"92","remark":"文章质量良好"},{"title":"《微服务实战》 第二十七章 CAS","posttime":"- 青花锁 · 2023-05-30 16:26:30 -","score":"87","remark":"文章质量良好"},{"title":"《微服务实战》 第二十六章 Java锁的分类","posttime":"- 青花锁 · 2023-05-29 17:28:47 -","score":"91","remark":"文章质量良好"},{"title":"《微服务实战》 第二十五章 Java多线程安全与锁","posttime":"- 青花锁 · 2023-05-29 16:07:53 -","score":"91","remark":"文章质量良好"}.....]
00:45:03.296 [main] INFO com.kelvin.spiderx.service.CsdnQcService - 此博主有文章,开始解析文章质量分!
00:45:03.296 [main] INFO com.kelvin.spiderx.service.CsdnQcService - csdnQcBySelenium start!
---------- 省略解析过程
此博主质量分如下:
00:50:40.699 [main] INFO com.kelvin.spiderx.service.CsdnQcService - {"title":"[刷题] 删除有序数组中的重复项","posttime":"- 青花锁 · 2023-06-25 12:49:42 -","score":"82","remark":"文章质量良好"},{"title":"[Selenium] 通过Java+Selenium查询某个博主的Top40文章质量分","posttime":"- 青花锁 · 2023-06-25 01:22:55 -","score":"87","remark":"文章质量良好"},{"title":"[Selenium] 通过Java+Selenium查询文章质量分","posttime":"- 青花锁 · 2023-06-23 08:42:36 -","score":"86","remark":"文章质量良好"},{"title":"【并发知识点】CAS的实现原理及应用","posttime":"- 青花锁 · 2023-06-22 11:55:48 -","score":"90","remark":"文章质量良好"},{"title":"【并发知识点】AQS的实现原理及应用","posttime":"- 青花锁 · 2023-06-22 11:35:53 -","score":"90","remark":"文章质量良好"},{"title":"简单介绍html/javascript、ajax应用","posttime":"- 青花锁 · 2023-06-22 10:18:01 -","score":"92","remark":"文章质量良好"},{"title":"[设计模式] OOP六大原则","posttime":"- 青花锁 · 2023-06-22 01:24:19 -","score":"89","remark":"文章质量良好"},{"title":"[Web前端] Servlet及应用","posttime":"- 青花锁 · 2023-06-22 01:07:56 -","score":"91","remark":"文章质量良好"}....]
00:50:40.693 [main] INFO com.kelvin.spiderx.service.CsdnQcService - csdnQcBySelenium end!
三、循环查询文章质量分
通过Java+Selenium查询文章质量分
查询文章质量分可见上述文章,在上一章中对返回值,禁止图片加载做了优化。在本章中,对driver做了优化,多个查询页面共用一个driver,且在进入查询质量分阶段,只在初次加载页面。
备注: 后期针对查询质量分,在并发情况下,可考虑driver池化技术,100篇文章分为N段,分别去作业,优化性能。
四、代码
packagecom.kelvin.spiderx.service;importcom.google.gson.Gson;importcom.kelvin.spiderx.util.SeleniumUtil;importlombok.Data;importlombok.extern.slf4j.Slf4j;importorg.jsoup.Jsoup;importorg.jsoup.nodes.Document;importorg.openqa.selenium.By;importorg.openqa.selenium.JavascriptExecutor;importorg.openqa.selenium.WebDriver;importorg.openqa.selenium.WebElement;importorg.openqa.selenium.chrome.ChromeDriver;importorg.openqa.selenium.chrome.ChromeOptions;importorg.springframework.util.CollectionUtils;importorg.springframework.util.StringUtils;importjava.io.IOException;importjava.util.ArrayList;importjava.util.HashMap;importjava.util.List;/***
* @title CsdnQcService
* @desctption CSDN查询质量分
* @author LTF
* @create 2023/6/21 23:02
**/@Slf4jpublicclassCsdnQcService{@DataclassCsdnBlogInfo{privateString title;privateString posttime;privateString score;privateString remark;}/**
* 获取质量数据
* @throws IOException
*/CsdnBlogInfocsdnQcBySelenium(String blogUrl ,WebDriver driver ,boolean isFirst){
log.info("csdnQcBySelenium start!");CsdnBlogInfo csdnBlogInfo =newCsdnBlogInfo();if( isFirst ){
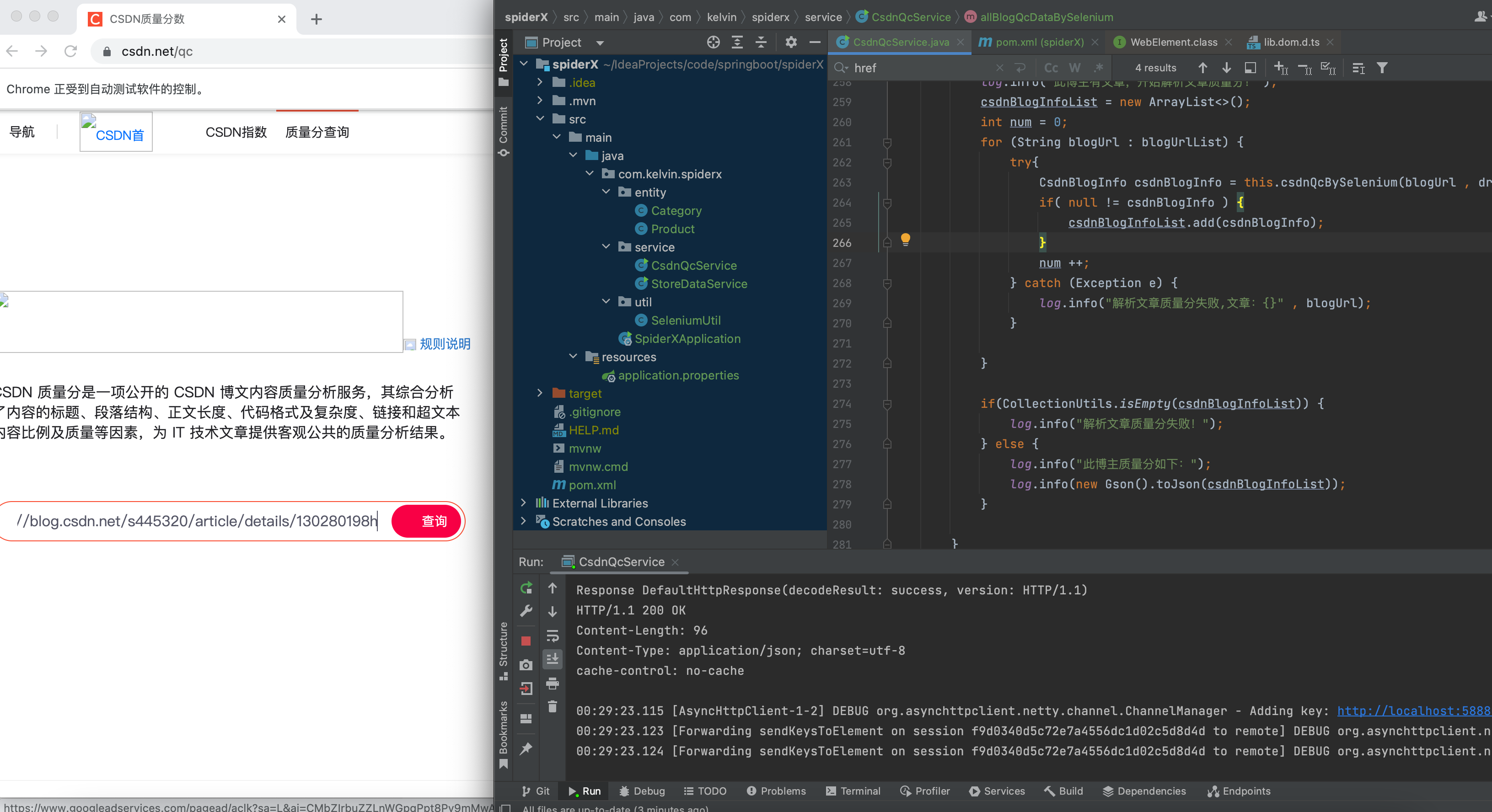
driver.get("https://www.csdn.net/qc");SeleniumUtil.sleep(500);}//定位到输入框WebElement inputSelectE = driver.findElement(By.cssSelector("input.el-input__inner"));//输入文字地址
inputSelectE.sendKeys(blogUrl);SeleniumUtil.sleep(100);//定位查询按钮WebElement qcSelectE = driver.findElement(By.cssSelector("div.trends-input-box-btn"));//点击查询按钮
qcSelectE.click();SeleniumUtil.sleep(1000);//获取右边区域 -- 文章质量分结果区域WebElement mainSelectE = driver.findElement(By.cssSelector("div.csdn-body-right"));//转化为Jsoup文档处理Document doc =Jsoup.parse( mainSelectE.getAttribute("outerHTML"));//获取文章标题String title = doc.select("span.title").text();if(!StringUtils.isEmpty(title)){
csdnBlogInfo.setTitle(title);}//获取作者和发布时间String posttime = doc.select("span.name").text();if(!StringUtils.isEmpty(posttime)){
csdnBlogInfo.setPosttime(posttime);}//获取质量分String score = doc.select("p.img").text();if(!StringUtils.isEmpty(score)){
csdnBlogInfo.setScore(score);}//获取博文质量分建议String remark = doc.select("p.desc").text();if(!StringUtils.isEmpty(remark)){
csdnBlogInfo.setRemark(remark);}//打印结果
log.info("文章标题:{} , 作者和发布时间:{} , 质量分:{} , 博文建议:{}", title , posttime , score , remark );// driver.quit();
log.info("csdnQcBySelenium end!");return csdnBlogInfo;}/**
* 查询指定博主的文章质量分
*/voidallBlogQcDataBySelenium(){String baseUrl ="https://blog.csdn.net/s445320?type=blog";System.setProperty("webdriver.chrome.driver",SeleniumUtil.CHROMEDRIVERPATH );// chromedriver localPathChromeOptions chromeOptions =newChromeOptions();
chromeOptions.addArguments("--remote-allow-origins=*");
chromeOptions.addArguments("–no-sandbox");//--start-maximized// 增加禁止加载图片的设置HashMap<String,Object> prefs =newHashMap<>();
prefs.put("profile.default_content_settings",2);
chromeOptions.setExperimentalOption("prefs", prefs);
chromeOptions.addArguments("blink-settings=imagesEnabled=false");//禁用图片WebDriver driver =newChromeDriver(chromeOptions);
driver.get(baseUrl);SeleniumUtil.sleep(200);//定位到文章列表WebElement mainSelectE = driver.findElement(By.cssSelector("div.mainContent"));boolean isEnd =false;// 获取Top40的数量int topNum =100;// 上一次读取的文章数int prePoint =0;List<String> blogUrlList =newArrayList<>();List<WebElement> webElements =null;while( isEnd ==false){JavascriptExecutor jsDriver =(JavascriptExecutor) driver;//将java中的driver强制转型为JS类型
jsDriver.executeScript("window.scrollTo(0, 50)");
jsDriver.executeScript("window.scrollTo(0, document.body.scrollHeight-20)");SeleniumUtil.sleep(500);
jsDriver.executeScript("window.scrollTo(0, document.body.scrollHeight +1)");SeleniumUtil.sleep(2000);
webElements = mainSelectE.findElements(By.cssSelector("article.blog-list-box>a"));// 如果上一次的文章数// 等于 当前页面的文章数:文章已全部读取完// 否则,继续加载下一页if( webElements.size()== prePoint){for(WebElement element : webElements ){System.out.println( element.getAttribute("href"));
blogUrlList.add(element.getAttribute("href"));}
log.info("文章已全部读取完");break;}else{
prePoint = webElements.size();}//如果加载的数据超过或等于 要求的最大长度,返回现在已加载的数据if( webElements.size()>= topNum ){for(WebElement element : webElements ){System.out.println( element.getAttribute("href"));
blogUrlList.add(element.getAttribute("href"));}
log.info("文章已读取 {} 条,最大限制 {} 条!", webElements.size(), topNum);break;}}
log.info("blogUrlList size:{}", blogUrlList.size());
log.info("blogUrlList:{}",newGson().toJson(blogUrlList));List<CsdnBlogInfo> csdnBlogInfoList =null;if(CollectionUtils.isEmpty(blogUrlList)){
log.info("此博主没有发表文章!");}else{
log.info("此博主有文章,开始解析文章质量分!");
csdnBlogInfoList =newArrayList<>();int num =0;for(String blogUrl : blogUrlList){try{CsdnBlogInfo csdnBlogInfo =this.csdnQcBySelenium(blogUrl , driver , num <=0);if(null!= csdnBlogInfo ){
csdnBlogInfoList.add(csdnBlogInfo);}
num ++;}catch(Exception e){
log.info("解析文章质量分失败,文章:{}", blogUrl);}}if(CollectionUtils.isEmpty(csdnBlogInfoList)){
log.info("解析文章质量分失败!");}else{
log.info("此博主质量分如下:");
log.info(newGson().toJson(csdnBlogInfoList));}}
driver.quit();
log.info("读取数据完毕!the end!");}publicstaticvoidmain(String[] args){CsdnQcService csdnQcService =newCsdnQcService();
csdnQcService.allBlogQcDataBySelenium();}}
总结
通过Java+Selenium查询某个博主的Top100文章质量分至此结束,优化空间还有很大,以实现效果为主。
本文转载自: https://blog.csdn.net/s445320/article/details/131407965
版权归原作者 青花锁 所有, 如有侵权,请联系我们删除。
版权归原作者 青花锁 所有, 如有侵权,请联系我们删除。