
文章目录
一:Zookeeper集群组成
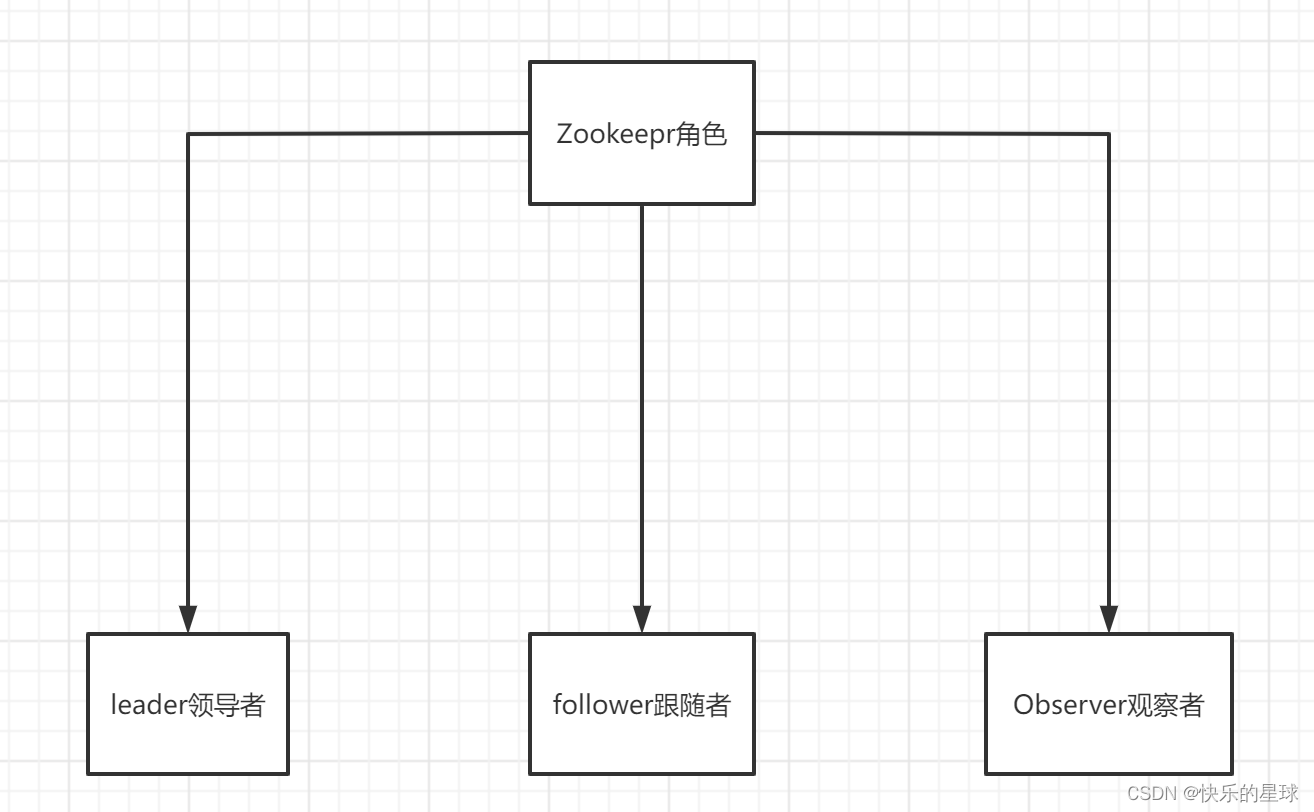
1.1 Leader领导者
zookeeper是基于读写分离设计的,leader既可以进行读操作,也可以进行写操作,而其它的follower和Observer只能处理client的读操作。
一个Zookeeper集群中有且只能有一个leader,而且必须有leader。zookeeper数据一致性采用的是最终一致性,所以一旦leader发生了单点故障,为了避免client从zk集群中取出错误的数据,整个服务器会进行不可用状态。所以如何在原先的leader挂掉之后快速选举一个新的leader是zk集群可靠性的关键,这点之后会讲。
1.2 Follower跟随者
Follower是作为leader的从属出现的,由于zk的最终一致性,follower最终会具备全量数据即zk特性中的统一视图,完全可以来降低leader的读压力,解决client的读操作。当leader挂掉之后,集群会进行选主工作,会从follower中选举出一个新的leader,从中可以看成follower还具备发起选举leader,以及投票权。
1.3 Observer观察者
observer的功能比follower更加单一,它不具备像follower选举新的leader的权利,它仅仅只有接收client读操作的权力。
**
如何配置Observer:
**
大家可以去zookeeper中文网上看教程:zookeeper中文网
二:zookeeper的数据结构–目录树
zookeeper和redis一样也可以储存数据,redis是以kv结构和五大基础数据类型来储存数据的,那zookeeper是如何来储存数据的呢?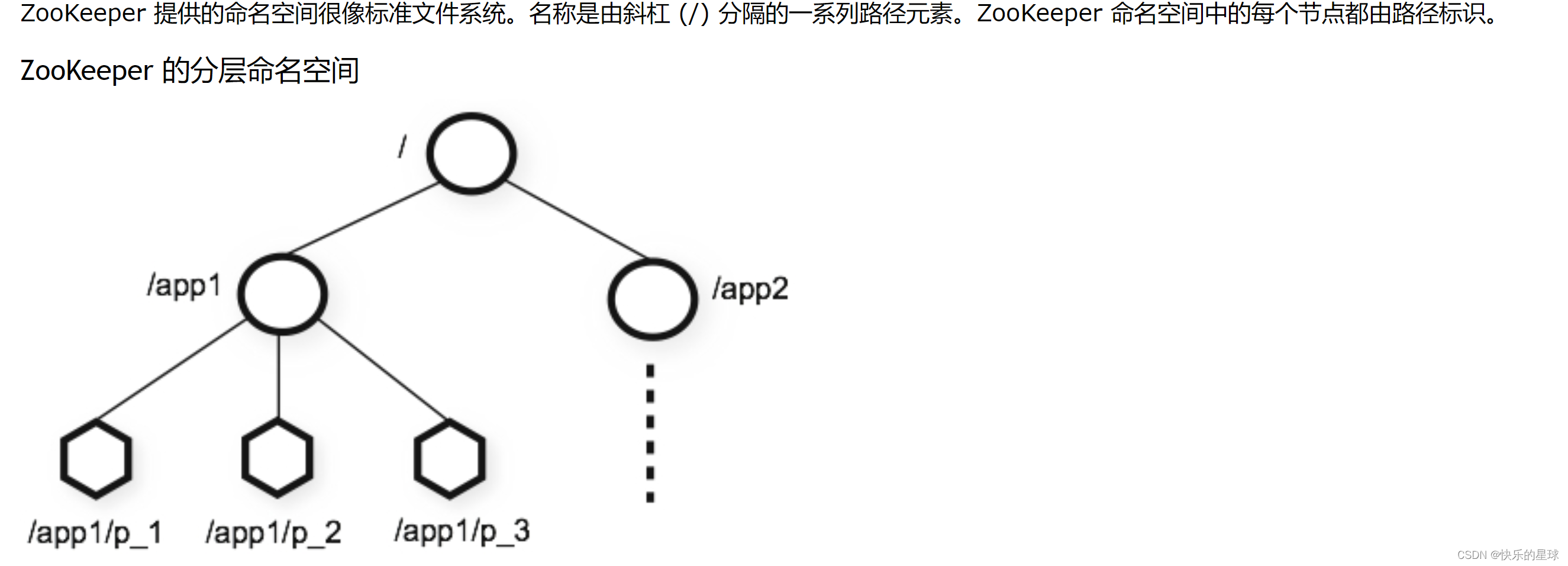 图片摘自zookeeper中文网
图片摘自zookeeper中文网
zk储存数据类似于kv结构,key是路径path,value是data
zk是以节点为单位来储存数据的,但是zk是作为分布式协调服务出现的,虽然zk能够储存数据且数据可靠,但是一定不要将zk当作数据库用,zk在以读为主的系统中效率最高,如果频繁的写数据,或者写占用内存大的数据会降低zk的性能,zk更多的是储存ip,config配置中心,以及一些简单的数据,也可以做分布式锁,但一定不要把它当数据库用。
zk中node最多储存1M的数据。
2.1 Node节点的分类
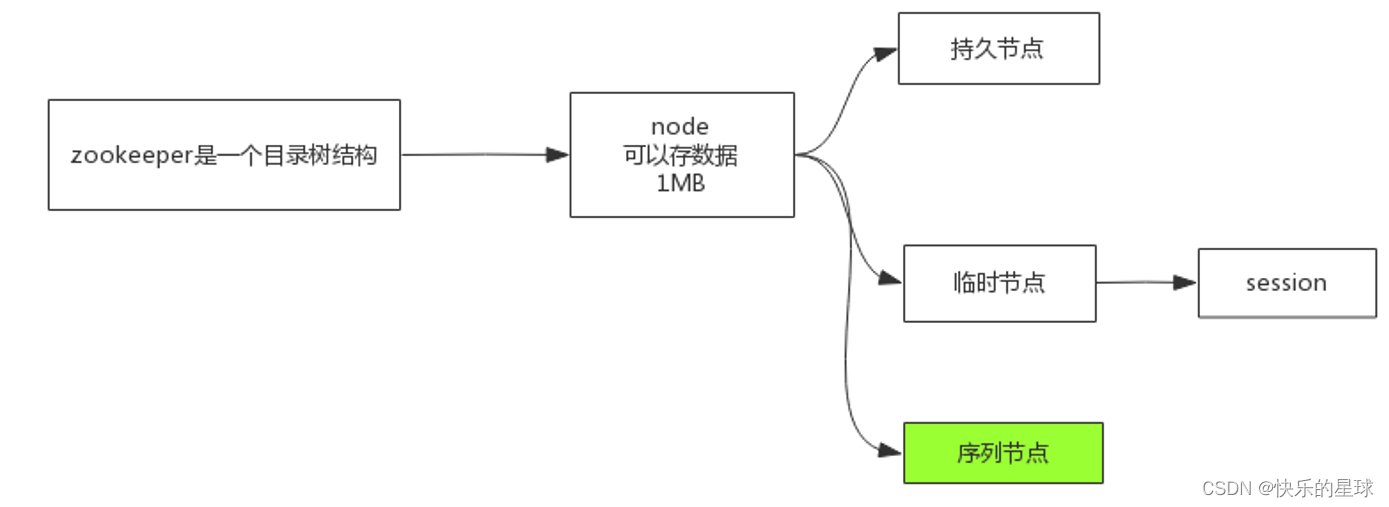
持久节点:永久储存的节点
临时节点:zk和redis等中间件不一样,zk是没有连接池这种概念的,客户端通过session与zk server进行连接,我们可以选择将节点保存在session中,但保存在session中的节点会随着client断开或者session有效期过期而丢失。
2.2 并发写同名path覆盖问题-序列节点
我们可以通过create path date 向指定目录下创建一个节点,但如果是并发环境下,多个客户端向zookeeper同一个目录下设置相同名称的节点就会产生覆盖问题,后面执行的会把前面执行的覆盖掉。如果我们不想覆盖的话,只需要为每一个名称后面拼接一个唯一标识的后缀即可。
在zookeeper中可以通过 create -s path data 来创建一个名称序列化节点

**
注意:实际存入的是序列化后的节点,所以get的时候要用序列化后的文件目录路径。
**
注意这个拼接的后缀id是递增且不会回退的,也就是说我们可以利用这种机制来设置按照时间先后对这个同名的key进行排序,这个会在zk实现分布式锁的时候用到,后面会讲。
2.3 server宕机导致session切换问题
如果客户端连接zookeeper集群其中任意一台server,并向session中写入临时节点数据,这时,如果这台server发生宕机,那么在zookeeper集群任然可用的前提下,会自动切换到另一台server,并且储存在server中的数据并不会发生数据丢失,会与新的server建立一个同sessionid的session并保留之前的数据。
一开始连接 155机
手动关闭155server后切换到154服务器
发现其session id没有发生变化,在故障转移时,session也会跟着转移并保留内部数据。
2.4 总结
目录树的结构可以帮我们完成很多功能
- 小于等于1M的数据统一配置管理
- 按不同的path目录来完成节点的分类管理
- sequential序列化可以完成统一命名管理
- 可以利用临时节点来完成分布式锁
三: zookeeper的选主机制
**
前置知识:在学习zk选主之前我们先来了解一下zk自增永不回退的事务id--Zxid
**
3.1 zk的事务id–Zxid
Zxid是一个64位的数字,其高32位代表者当前leader的版本(每更换一个leader其版本+1),其低32位代表当前当前zk写操作的版本,每一次写操作都为导致其低32位+1。
具体细节可参考这篇博客:Zookeeper的zxid
**
前置知识:zk的重要端口
**
3.2 zk集群的2888和3888端口
我们先看一看zk的配置文件 zoo.cfg
我们可以观察到在每一个zk server都配置了2888和3888两个端口,那么这两个端口具体有什么含义呢?
在zookeeper集群中所有节点都会开启3888端口,3888端口用来leader发生故障时,投票选举出新的leader。
所有节点都会与其它节点的3888端口建立TCP连接
但只有leader才会开启2888端口,其它节点都会与leader2888端口建立TCP连接, 其主要功能是接收其它follwoer和observer节点发送过来的写事务并执行。
**
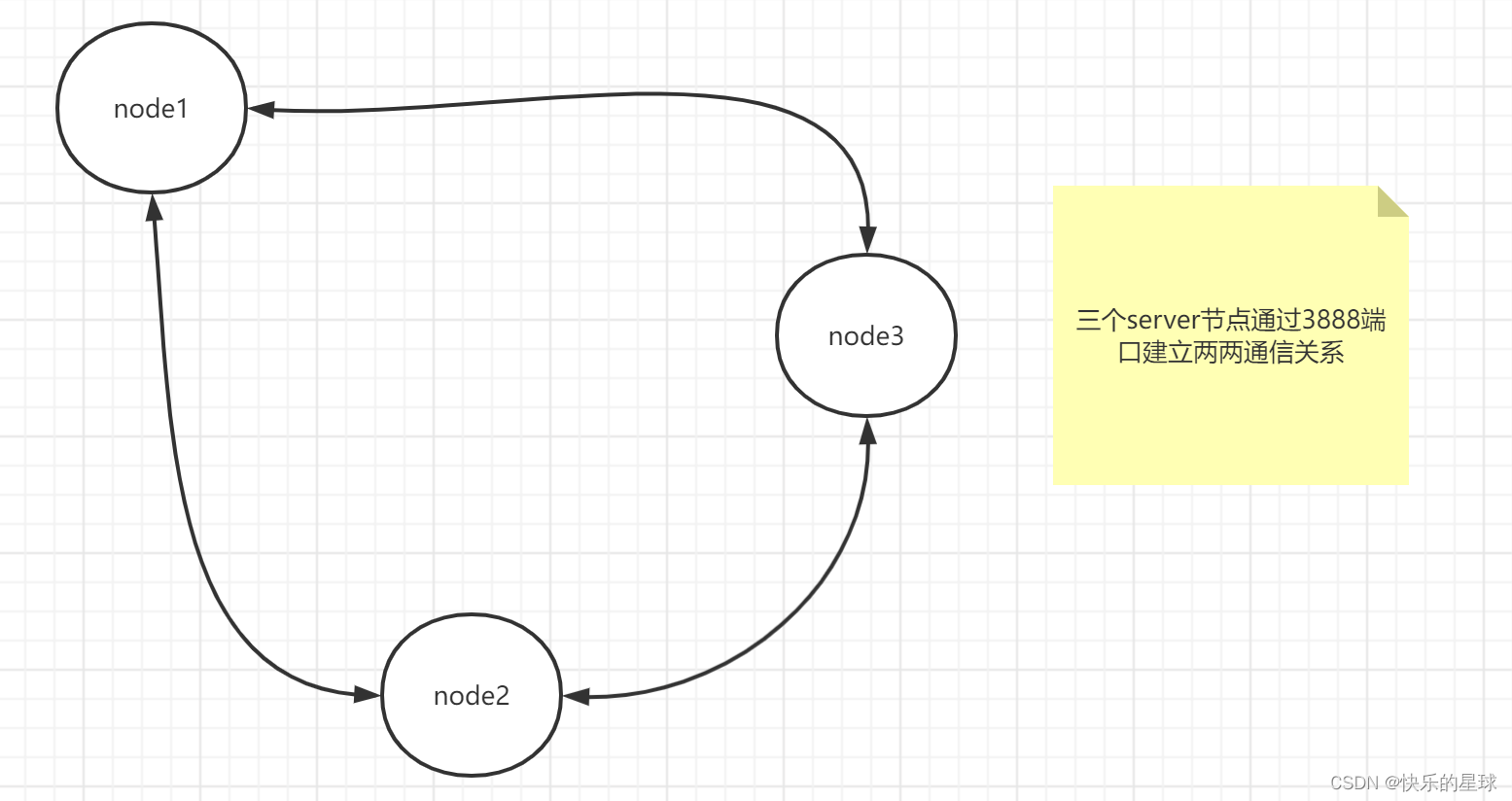
通过上述条件我们可以知道任何两台follower之间均可通过3888端口进行通信。这是在leader挂了之后能够快速选主的基础条件。
**
3.3 zk集群选主的规则
每一个zk server都会有自己的Zxid与myid,而具体要选哪个follower称为leader呢?毫无疑问,选最有经验最老道的(即保存数据最全,Zxid最大),如果Zxid相同都拥有原先leader的全量数据,那就选myid最大的。
- 先按Zxid比较
- Zxid相同则按myid比较
- 只有一个follower获得过半的支持票,它才能称为新的leader
zk集群选主规则简单吧?但实际上确有一系列的问题。接下来我们通过一个例子,带大家深入了解zk的选主规则。
3.4 zk集群选主案例
**
本案例是四台server组建的zk集群,其中leader挂了之后,另三台follower集群选主的过程。
**
首先我们要考虑一件事情,我们要进行集群选主,那么必定要到集群属于无主状态才能选主,那么follower怎么知道它的leader有没有挂?对了,可以通过定时心跳去看看主有没有挂,或者follower主动去向zk同步数据/发送写事务时发现连接不上leader,从而得知leader挂了。而这种机制是具有延时性的比如某个follower刚和leader心跳完leader就挂了,那么它可能会到下一次心跳时才会发觉leader挂了,这种延时性是难以接收的。
那么如何去解决leader挂了之后可能只有部分follower意识到的情况下,要让所有网络通信正常的follower全部参加集群选主的过程中。
**
最差的情况:举例即便在最差的情况下zk选举机制也能让所有通信正常的server参加选举。如上图假设只有node3节点发现leader挂了,那么node3说我要当leader便把自己相当leader的消息与Zxid,myid两个参数一并广播给其它所有的follower节点,node3自己肯定会投自己一票,其它节点根据Zxid和myid两个参数进行比较,如果发现其中节点node1比你牛逼,那么node3你当啥leader,你应该给我投票于是将该消息传回node3,node3修改选票投给node1,node1发现自己干过node3于是也想当ledaer也像node3当初一样广播给其它所有节点;如果node1发现自己干不过node3老老实实给node3投票。
**
通过上面的选举机制,只要有任何一个follower发现leader挂了,广播自己当leader的消息,一定会触发准ledaer(所有的follower中按Zxid和myid比较最大的节点为准leader)给自己投票并广播出去,由于投票中存在的纠正机制(即原本以为自己牛逼给自己投票广播自己,结果比你更牛逼的节点收到了你要当leader的消息,不服让你去纠正),最终一定会让其它所有节点投给准leader,准leader最终会收到所有的票数。
**
但实际上任何一个节点只要获得的票数过半,他就会直接成为leader且不需要通知,很迅速。也就是说准leader获得的票数过半就直接宣称自己是真正的新任leader。
**
3.5 zk集群不可用状态
zk集群进入不可用状态通常有以下两个原因:
- zk集群中server的数量不足总量的一半
- zk集群的leader挂了 如果server的数目不足集群总量server的一半,那么连leader都无法选举出来,集群自然进入不可用状态。
四:zk中的数据一致性协议ZAB
4.1 示例
图示:任何一个follower在接收到client的写事务时,会将该写事务交由leader处理,图示leader处理写事务时和follower之间的数据同步。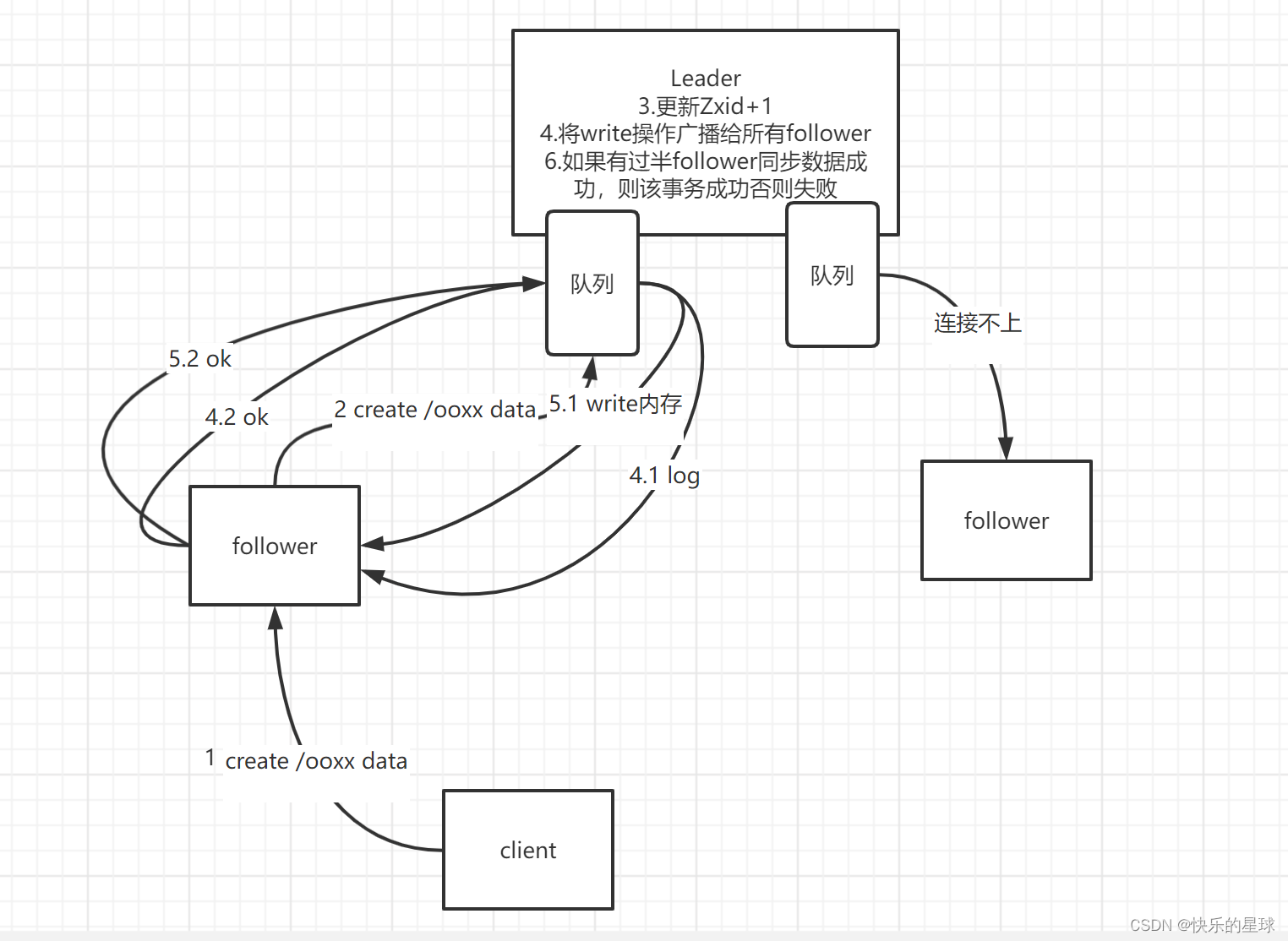
想要实现分布式数据一致性就需要先保证zk集群处理write操作时的原子性。
原子性:要么失败要么成功,没有中间状态。如图leader在收到write操作后,广播给其它所有的follower最终必须要有过半的follower保存数据成功,否则事务将被撤销。
ZAB协议为了实现事务操作的有序性,即将一个事务中的指令按顺序放入队列中,最终这个事务将被有序的执行,能保证其有序性。
ZAB协议中的leader广播其它所有follower节点是不需要所有follower收到并给予反馈的,只要过半即可。正因为如此就可能会导致部分follower的Zxid版本偏低,在集群选主时会出现Zxid不同的现象,但实际生产环境中,很少会出现这种Zxid延后的情况,因为ZAB广播后,follower接收不到leader的消息,多半是因为网络通信问题。而如果运维人员连三五台机子的集群都会时常出现连接不上,就可以开了整个运维团队(太菜了)。而由于ZAB实现的是最终一致性,leader会把所有要让follow干的事放进队列中去,最终follower网络通信正常后会从队列中消费到leader让它干的事,最终完成数据一致性。
4.2 为啥leader挂了进入无主状态后要停止服务
**
讲到这里,不得不思考一个问题,在前面说了zk集群有不可用和可用两种状态,一旦leader挂了进入无主状态就之间停止对外的服务。那为什么集群的其它的follower和observer不能继续提供服务?
**
首先zookeeper是具有高可用且具有很高可靠性的提供分布式协调服务的框架。一旦leader挂了,就不能保证从follower和observer中取出的数据是正确的。因为zk是最终一致性,可能有部分follower和observer版本延后,其中储存的数据是旧的甚至是错误数据,而此时又不能向leader中要正确的数据,就会导致zookeeper集群连数据一致性都无法保证,自然需要对外停止服务。
**
clinet向zookeeper集群取数据时可以主动要求去leader中取真正正确的数据**
client向zk中取数据,zk server从机接收到取数据的请求,在自己的目录树中拿出数据返回给client,并提前声明我这里的数据不一定正确,如果你需要一定正确的数据,请等我一下我去leader同步数据,然后返回给你。也就是说client可以通过sync指令要求zk从机读数据时跟leader同步数据。那么一旦leader挂了,自然就无法确保数据一致性啦!
版权归原作者 快乐的星球 所有, 如有侵权,请联系我们删除。