
1,什么是cdc
CDC 的全称是 Change Data Capture ,在广义的概念上,只要是能捕获数据变更的技术,我们都可以称之为 CDC 。目前通常描述的 CDC 技术主要面向数据库的变更,是一种用于捕获数据库中数据变更的技术.
2,cdc的种类
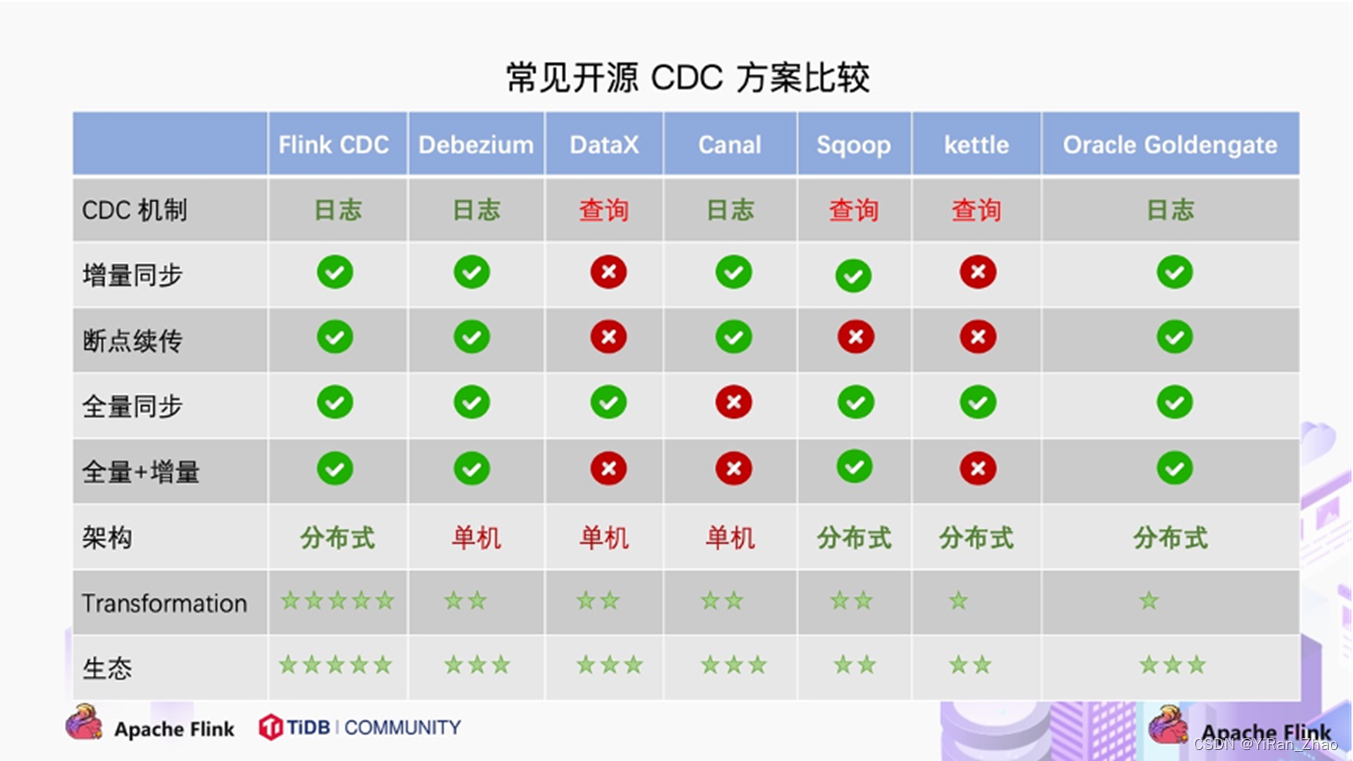
**CDC **的技术方案非常多,目前业界主流的实现机制可以分为两种:
基于查询的 CDC:
◆离线调度查询作业,批处理。把一张表同步到其他系统,每次通过查询去获取表中最新的数据;
◆无法保障数据一致性,查的过程中有可能数据已经发生了多次变更;
◆不保障实时性,基于离线调度存在天然的延迟。
基于日志的 CDC:
◆实时消费日志,流处理,例如 MySQL 的 binlog日志完整记录了数据库中的变更,可以把 binlog文件当作流的数据源;
◆保障数据一致性,因为 binlog文件包含了所有历史变更明细;
◆保障实时性,因为类似 binlog的日志文件是可以流式消费的,提供的是实时数据。
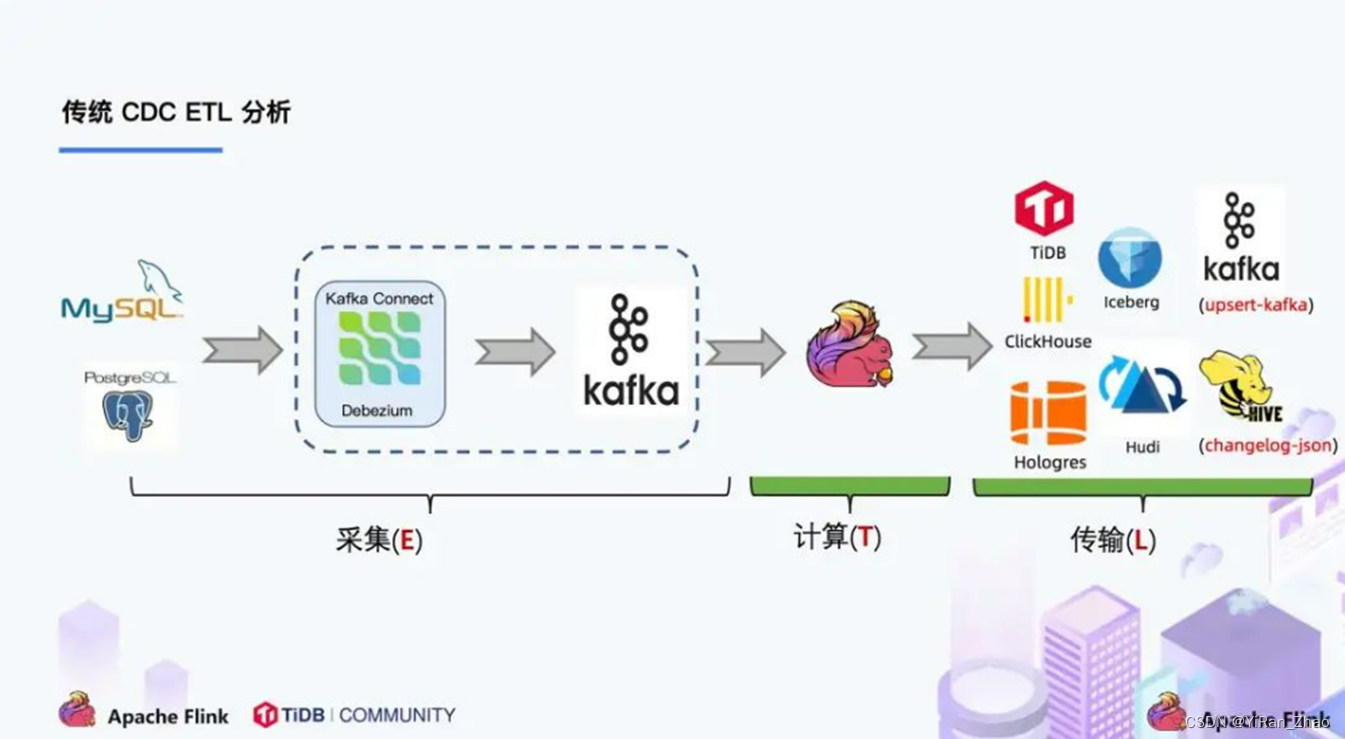
3,传统的cdc和flink的cdc
传统的cdc
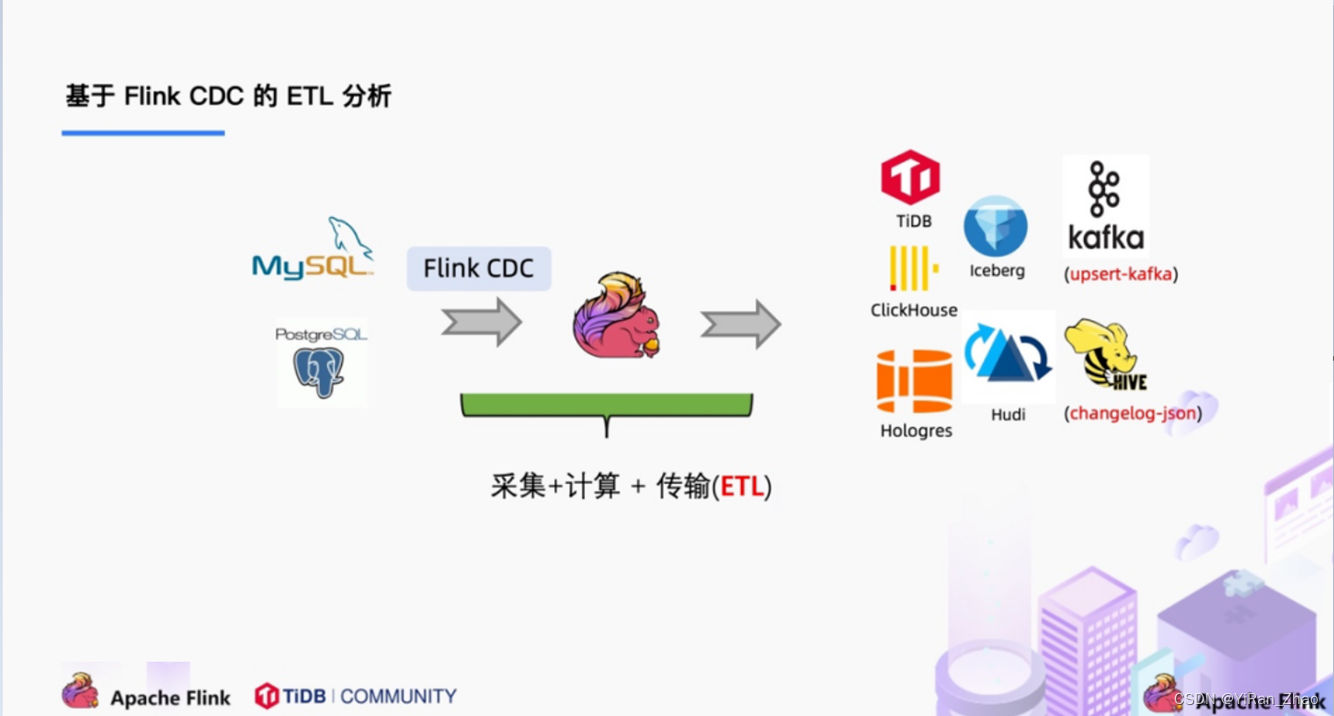
** flink 的cdc**
4,flink cdc 发展史

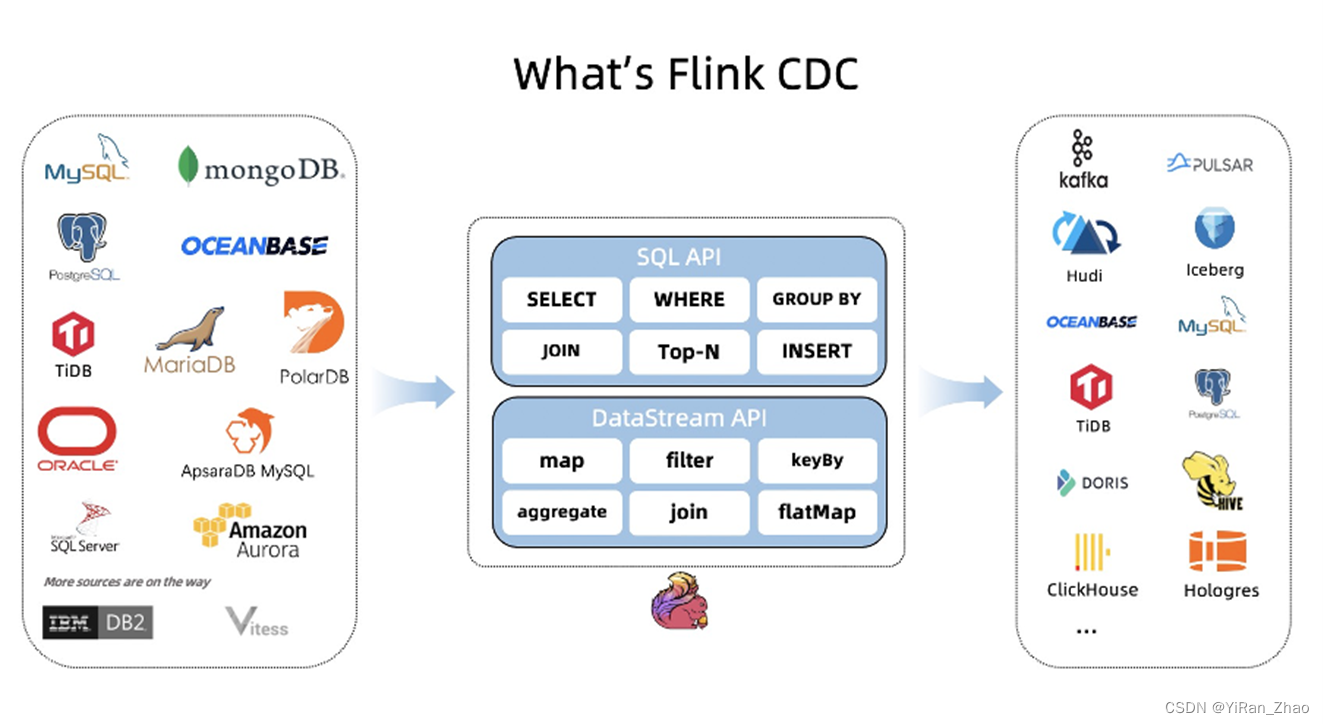
5,Flink CDC Connectors
Connectors — Flink CDC documentation
Flink CDC Connectors 是 Flink的一组 Source 连接器,是 Flink CDC 的核心组件,这些连接器负责从 MySQL、PostgreSQL、Oracle、MongoDB等数据库读取存量历史数据和增量变更数据
6,flink cdc对应flink的版本支持


7,cdc的版本介绍
Flink** cdc1.x**

- 全量 + 增量读取的过程需要保证所有数据的一致性,因此需要通过加锁保证,但是加锁在数据库层面上是一个十分高危的操作。底层 Debezium 在保证数据一致性时,需要对读取的库或表加锁,全局锁可能导致数据库锁住,表级锁会锁住表的读,DBA 一般不给锁权限。
- 不支持水平扩展,因为 Flink CDC 底层是基于 Debezium,起架构是单节点,所以Flink CDC 只支持单并发。在全量阶段读取阶段,如果表非常大 (亿级别),读取时间在小时甚至天级别,用户不能通过增加资源去提升作业速度。
- 全量读取阶段不支持 checkpoint:CDC 读取分为两个阶段,全量读取和增量读取,目前全量读取阶段是不支持 checkpoint 的,因此会存在一个问题:当我们同步全量数据时,假设需要 5 个小时,当我们同步了 4 小时的时候作业失败,这时候就需要重新开始,再读取 5 个小时。
Flink** cdc2.x**
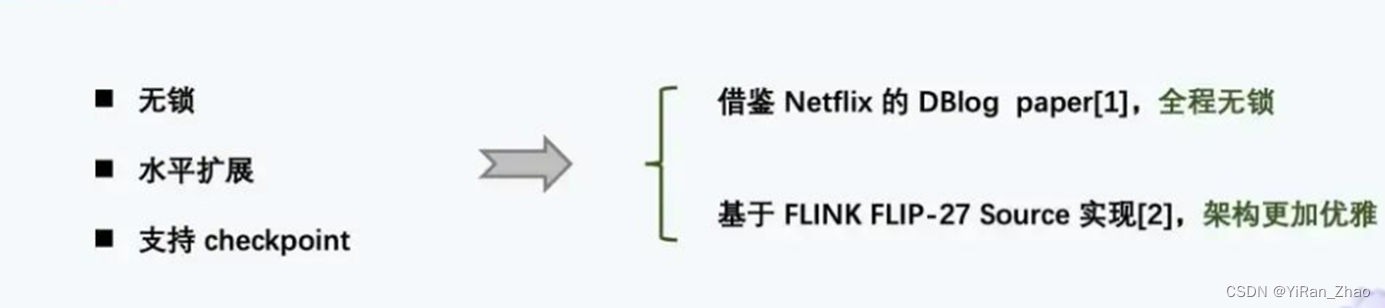
[1] DBLog - 无锁算法论文:https://arxiv.org/pdf/2010.12597v1.pdf
[2] Flink FLIP-27 设计文档:https://cwiki.apache.org/confluence/display/FLINK/FLIP-27%3A+Refactor+Source+Interface
版权归原作者 YiRan_Zhao 所有, 如有侵权,请联系我们删除。