

Druid批量数据加载
Druid支持流式和批量两种方式的数据摄入,流式数据是指源源不断产生的数据,数据会一直产生不会停止。批量数据是指已经生产完成的数据。这两种数据都可以加载到Druid的dataSource中供OLAP分析使用。
一、Druid加载本地磁盘文件
1、使用webui加载本地数据
Druid可以加载本地磁盘数据文件。我们有一份用户订单数据,格式如下:
{"data_dt":"2021-07-01T08:13:23.000Z","uid":"uid001","loc":"北京","item":"衣服","amount":"100"}
{"data_dt":"2021-07-01T08:20:13.000Z","uid":"uid001","loc":"北京","item":"手机","amount":"200"}
{"data_dt":"2021-07-01T09:24:46.000Z","uid":"uid002","loc":"上海","item":"书籍","amount":"300"}
{"data_dt":"2021-07-01T09:43:42.000Z","uid":"uid002","loc":"上海","item":"书籍","amount":"400"}
{"data_dt":"2021-07-01T09:53:42.000Z","uid":"uid002","loc":"上海","item":"书籍","amount":"500"}
{"data_dt":"2021-07-01T12:19:52.000Z","uid":"uid003","loc":"天津","item":"水果","amount":"600"}
{"data_dt":"2021-07-01T14:53:13.000Z","uid":"uid004","loc":"广州","item":"生鲜","amount":"700"}
{"data_dt":"2021-07-01T15:51:45.000Z","uid":"uid005","loc":"深圳","item":"手机","amount":"800"}
{"data_dt":"2021-07-01T17:21:21.000Z","uid":"uid006","loc":"杭州","item":"电脑","amount":"900"}
{"data_dt":"2021-07-01T20:26:53.000Z","uid":"uid007","loc":"湖南","item":"水果","amount":"1000"}
{"data_dt":"2021-07-01T09:38:11.000Z","uid":"uid008","loc":"山东","item":"书籍","amount":"1100"}
将以上数据加载到Druid中,我们可以直接在页面上操作,操作步骤如下:
- 将以上数据上传到Druid各个Server节点上相同路径
这里将数据存放在Druid各个Server角色的/root/druid_data/目录下,必须是所有节点,这里就是node3、node4、node5节点。
- 进入http://node5:8888 查询主页面,点击load data标签
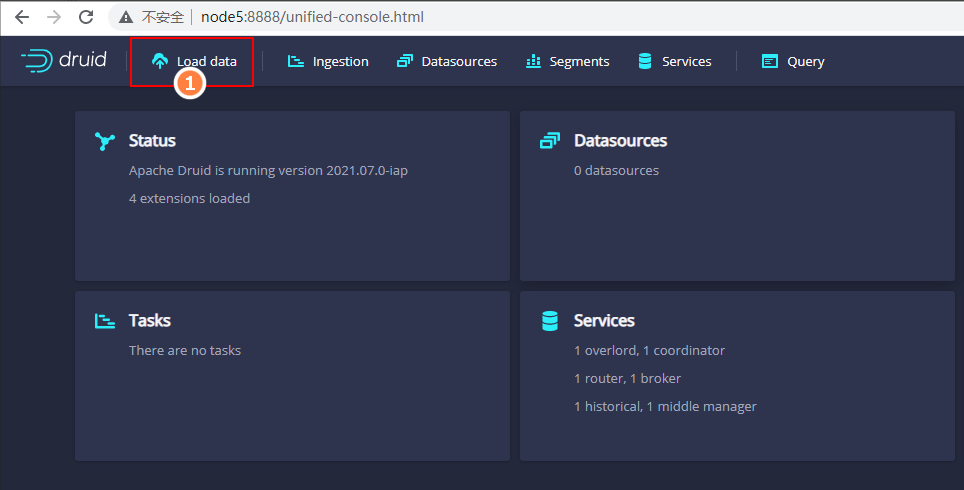
- 选择“Local disk”

点击“Connect data”,在打开的页面中填写对应的数据目录:
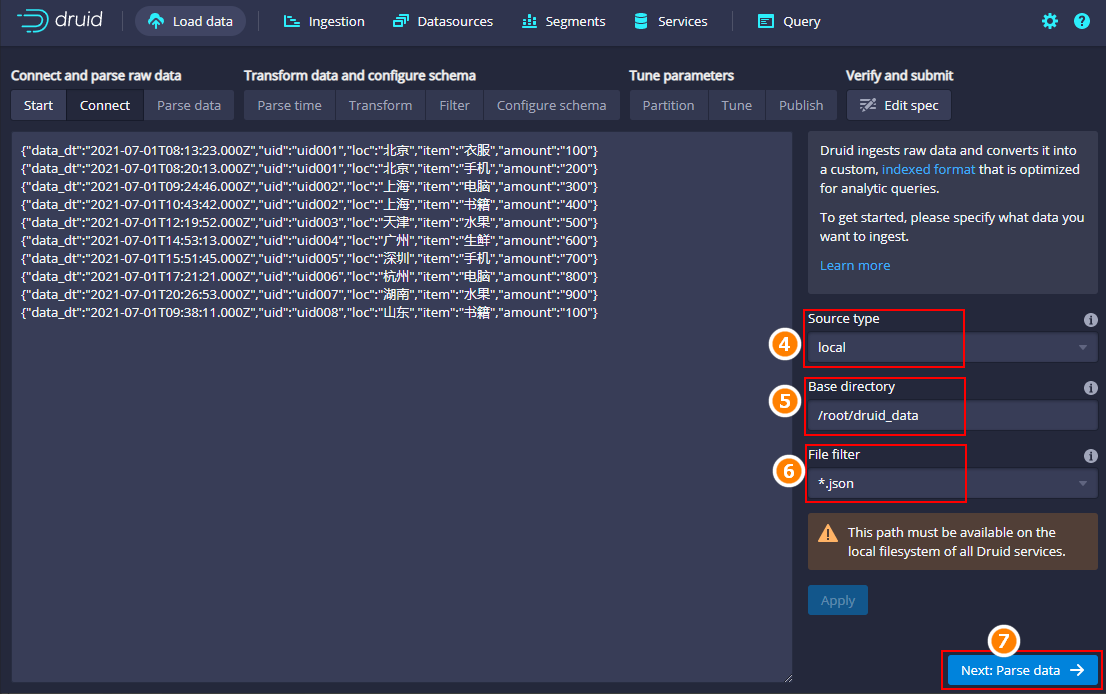
注意:为了演示聚合效果,后面图中显示数据与真实导入数据不一样,数据有改动,步骤都是一样的。
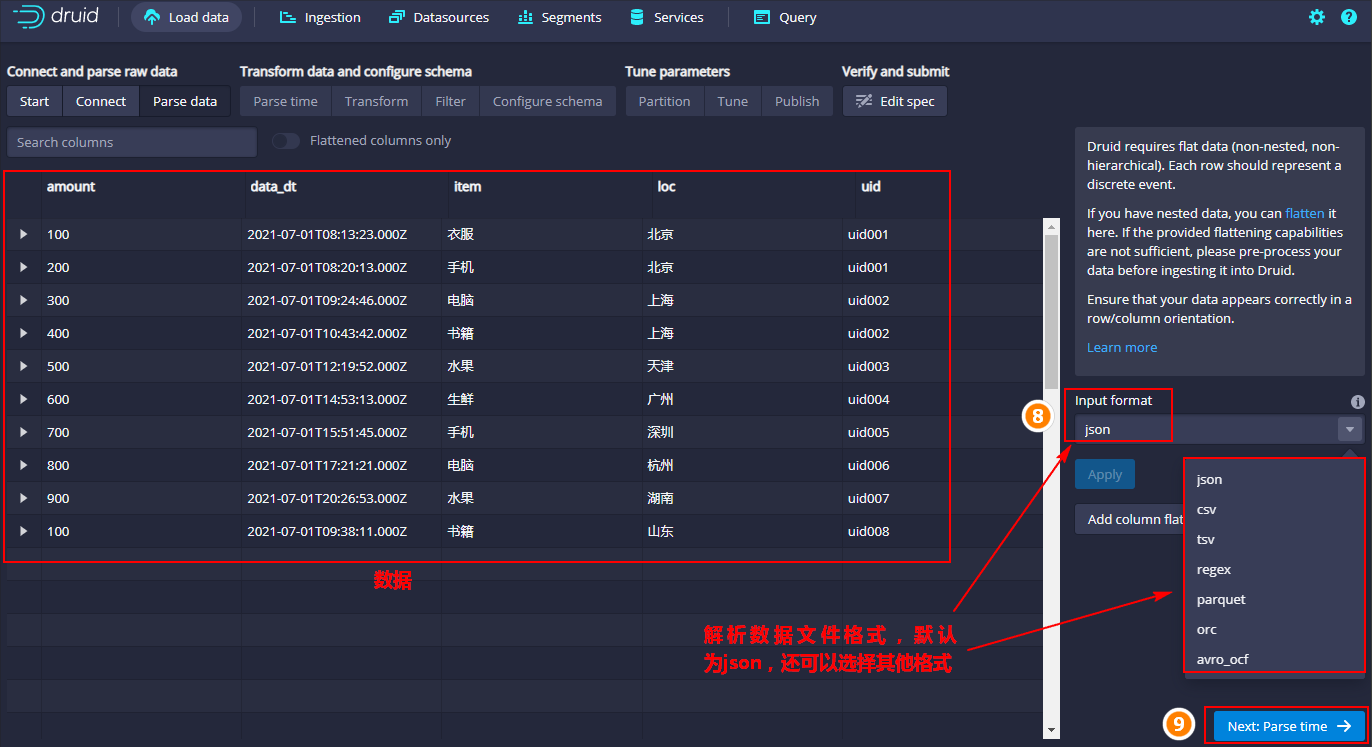
- 点击“Parse data”,解析数据,默认为json格式,此外还支持很多格式
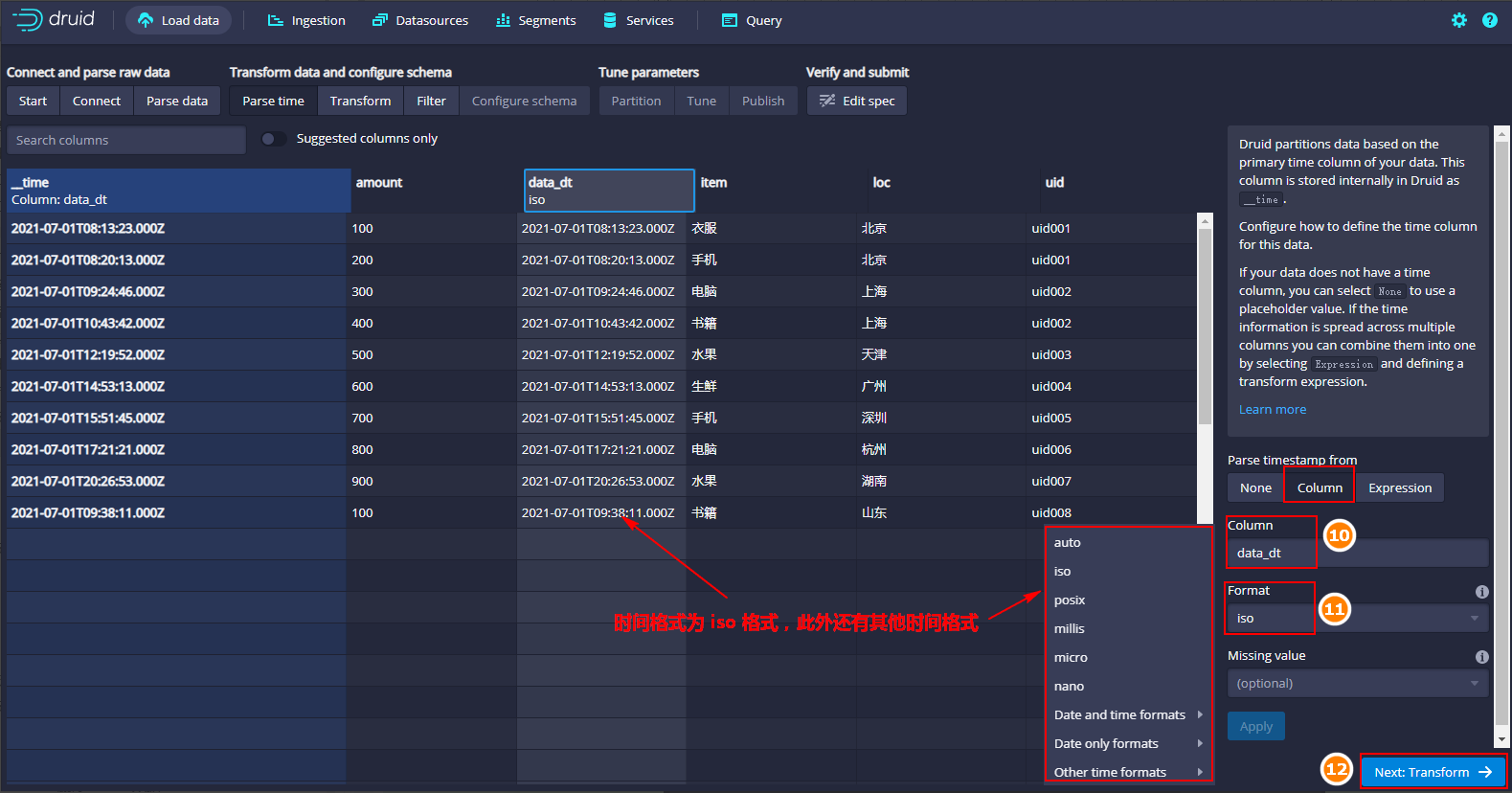
- 点击“Parse time”来指主时间戳列
在Druid中一般都需要一个时间戳列,这个时间戳列在内部存储为“_time”列,如果数据中没有时间戳列,可以选择“None”指定一个固定的时间当做时间列。
- 点击“Next Transform”,进行列转换
“列转换”可以根据已有列来合并生成新的列,这里没有需要我们直接点击“Next Filter”即可。
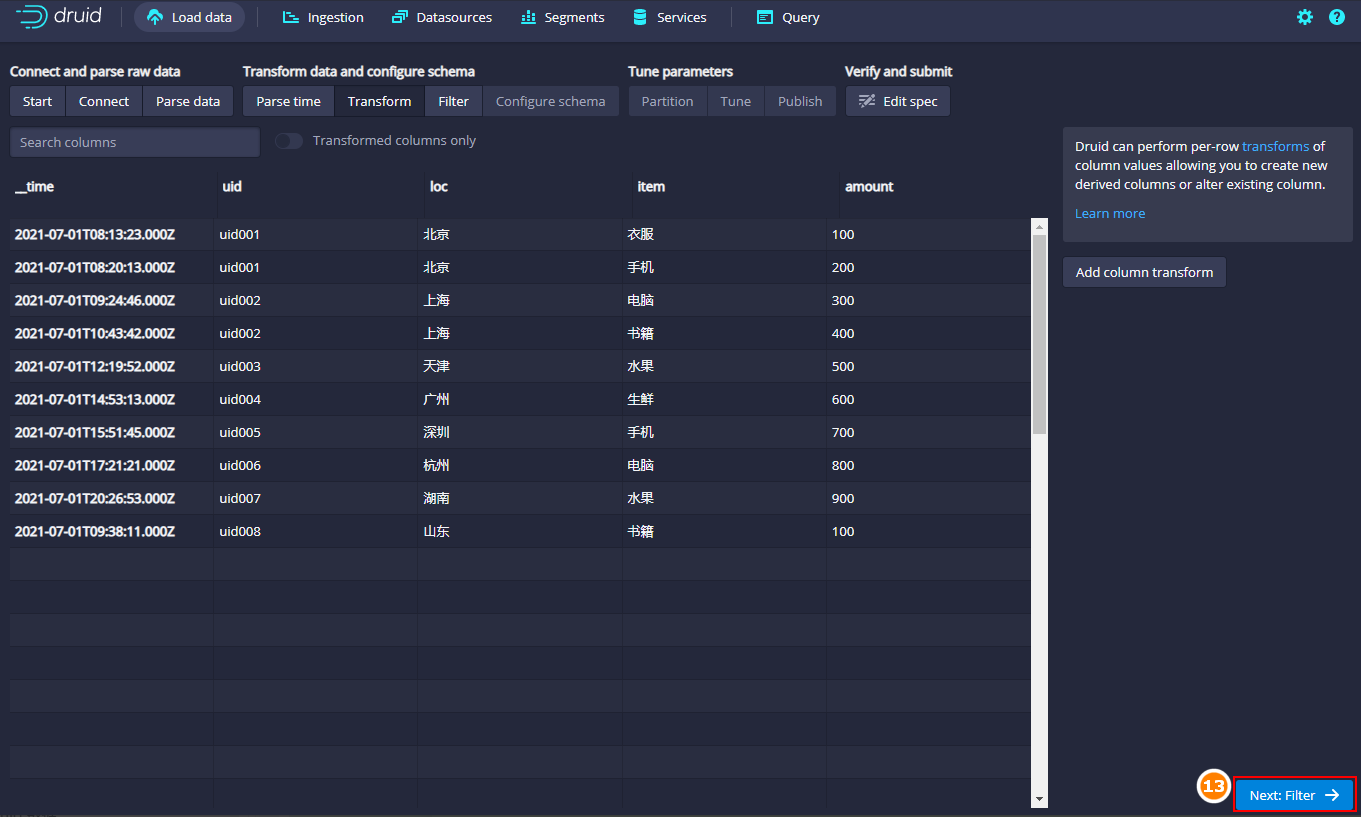
点击“Next Filter”是进行数据过滤,这里我们导入所有数据,所以这里直接点击“Next Configure schema”,可以设置是否“Rollup”上卷,可以将原始数据在注入的时候就进行汇总处理。rollup上卷指的是按照相同维度的数据对度量字段进行聚合操作,可以做到减少存储空间大小。
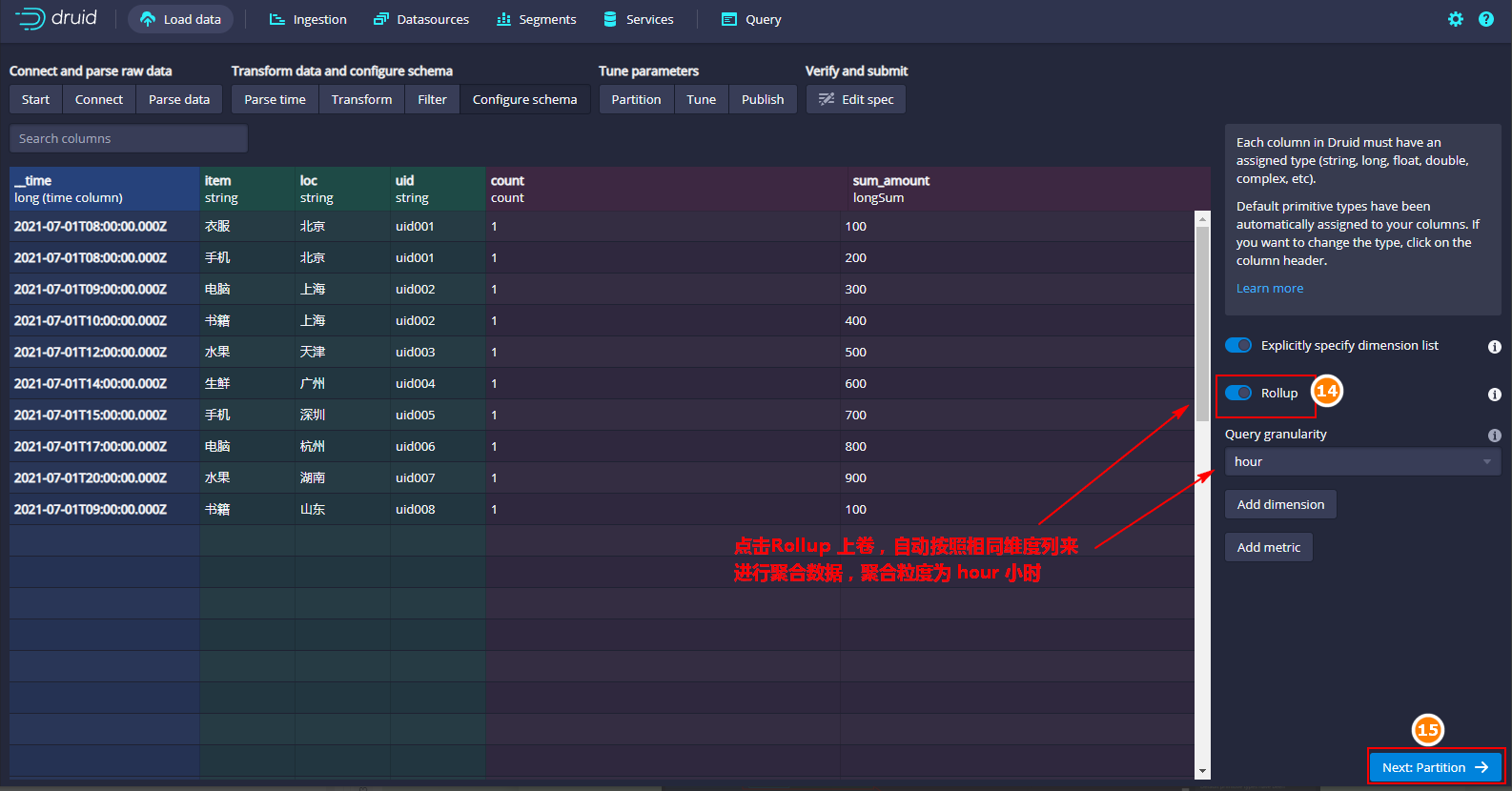
Druid中每列都有一个类型,可以点击某个列修改该列的类型,这里我们可以按照默认的类型处理,直接点击“Next:Partition”:
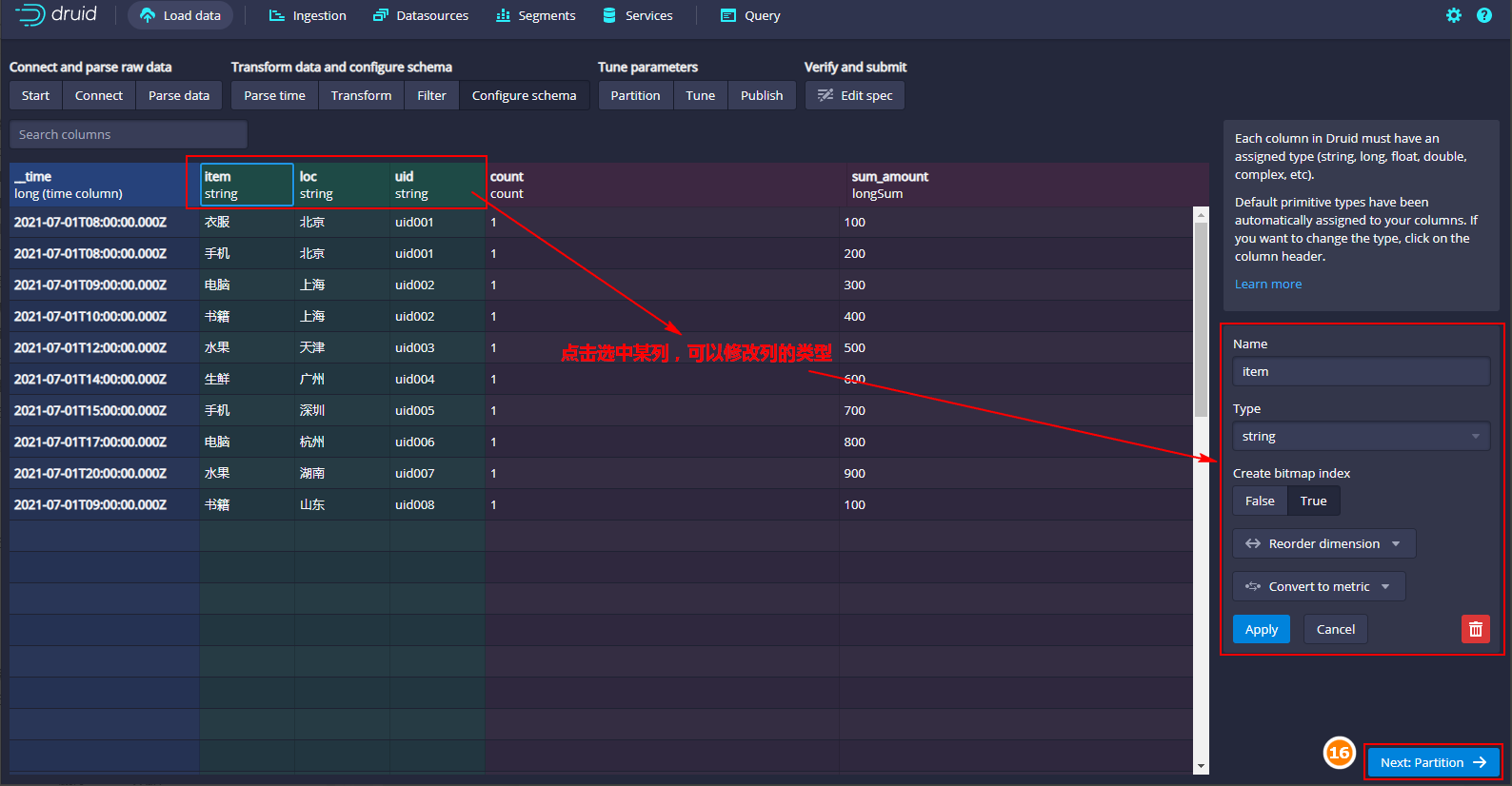
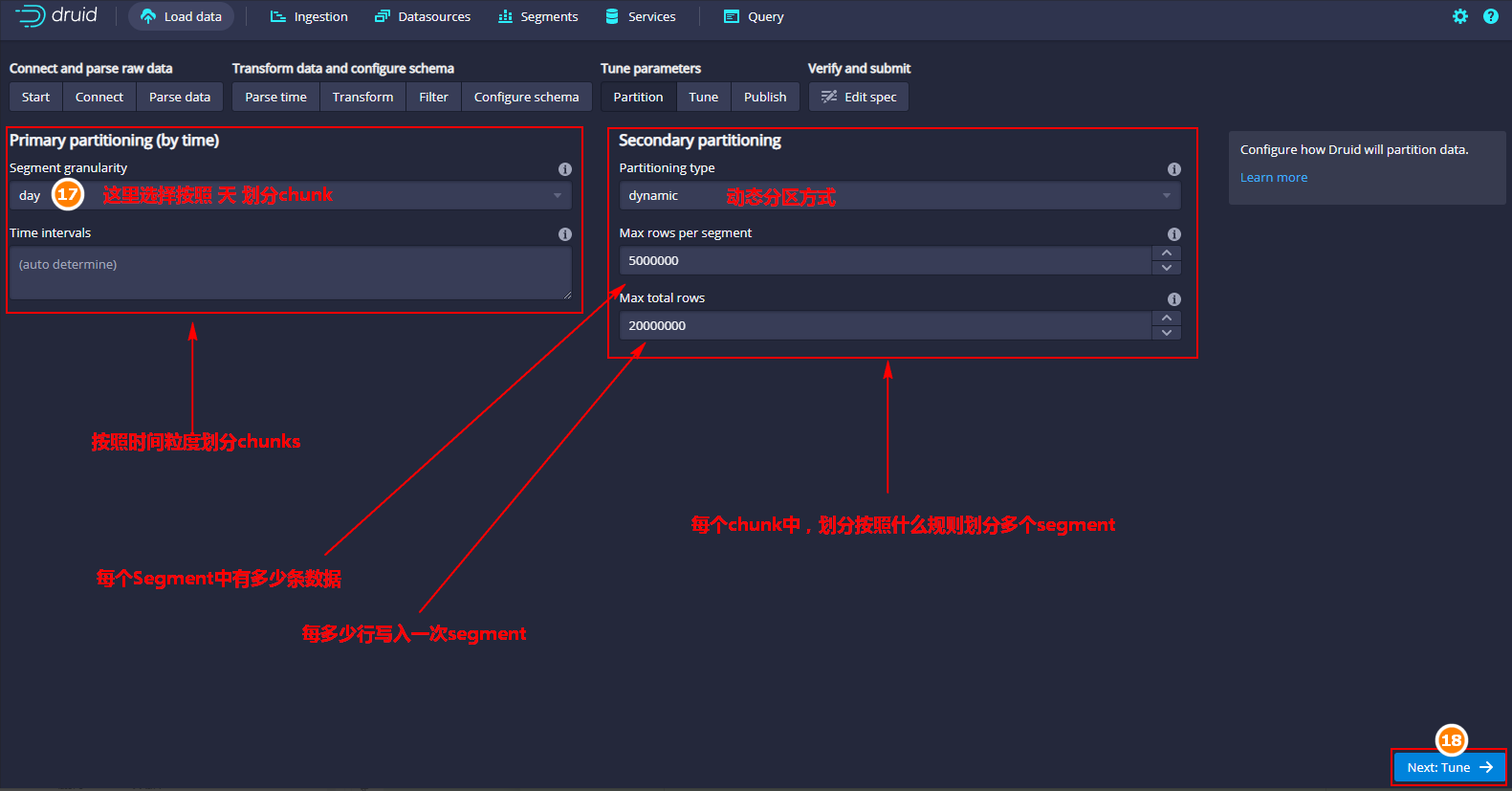
- 设置分区
在Druid中,segment的分区规则会对磁盘占用和性能产生重大影响。默认是按照时间列划分chunk,每个chunk中可以按照三种分区规则来进行分区:
dynamic:摄入速度最快,根据配置的每个segment行数来进行划分segment。
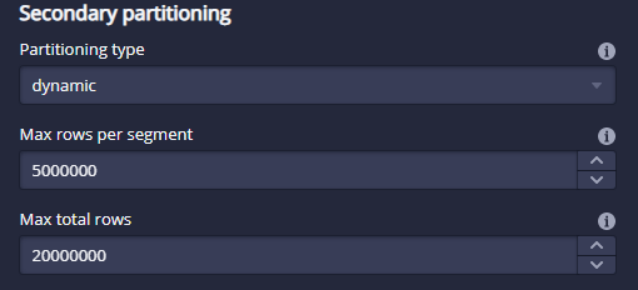
hashed:摄入速度中等,根据数据维度列的hash值进行分区,可以减少数据源大小和查询延迟。

single_dim:摄入速度最慢,根据指定维度值来进行范围分区,查询速度最快。

这里我们选择默认的动态分区方式即可。
- “点击Next Tune”,优化设置,对Druid读取数据进行参数优化设置,这里按照默认即可,直接点击“Next Publish”即可。

- 点击“Next Publish”,配置对应的Datasource名称

- 点击“Next Edit spec”,确认配置

以上json配置是根据前面配置生成的json配置,没有问题直接点击“submit”生成任务导入数据即可。
- 提交任务后会自动生成个一个导入数据任务
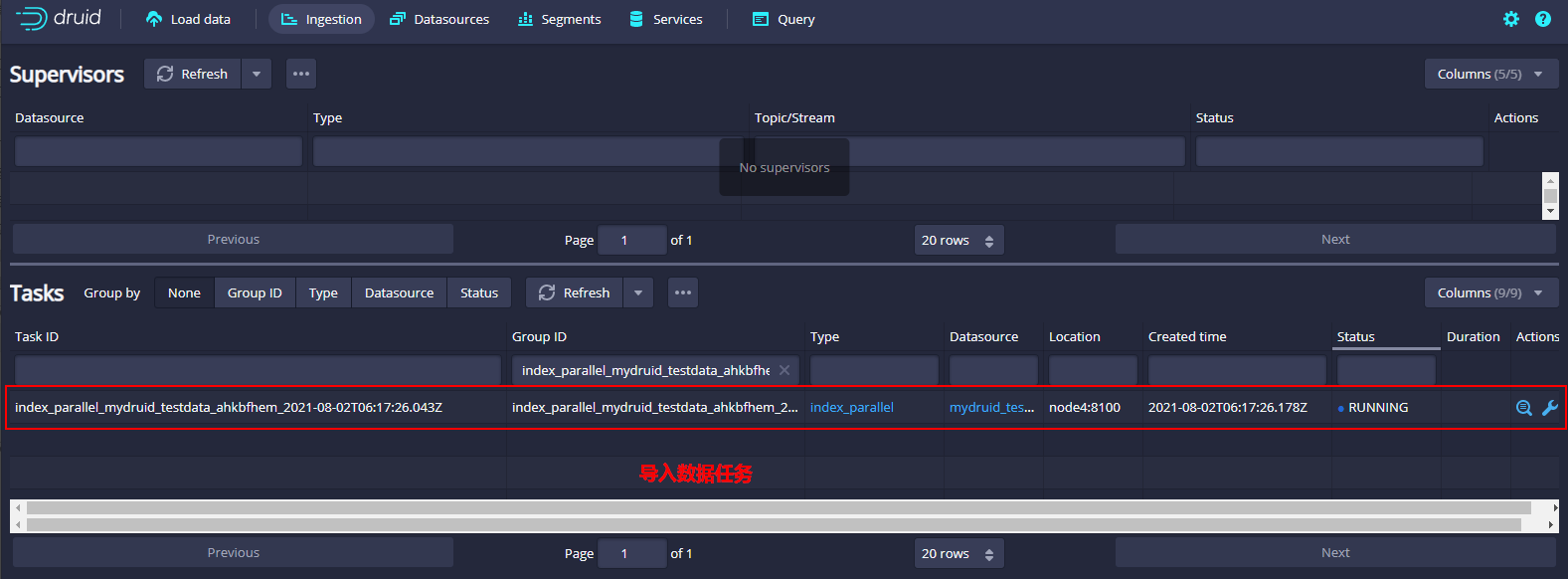
等待一会,导入数据任务完成之后,在主页面可以看到对应的datasource及segment。


2、查询Druid数据
点击“Query”,查询数据,我们可以看到数据中按照指定的小时,所有维度相同的数据自动进行了聚合操作,这里datasource“mydruid_testdata”中存储的数据是预聚合之后的数据,如果有相同维度数据,原来“原子性”数据查询不到了。如果不希望预聚合,可以在步骤中将“rollup”设置关闭。
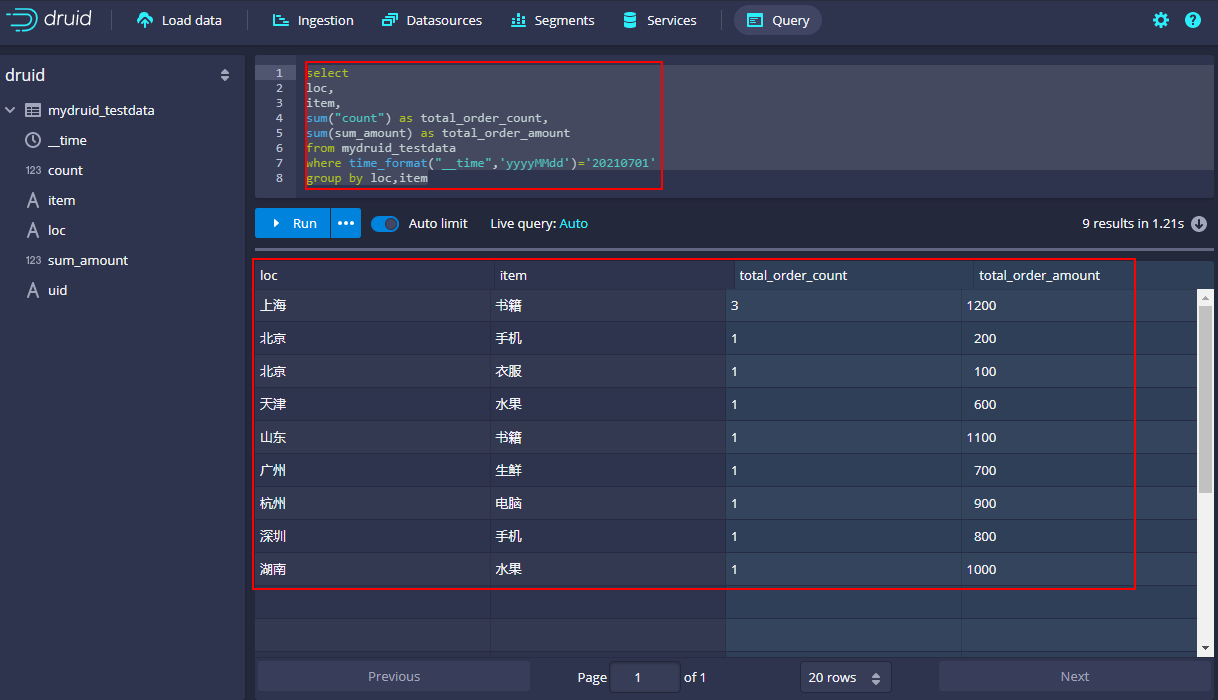
查询地区物品销售订单数量及销售总金额:
#注意:Druid SQL中关键字使用双引号引起来,时间yyyyMMdd 使用单引号引起来。
select
loc,
item,
sum("count") as total_order_count,
sum(sum_amount) as total_order_amount
from mydruid_testdata
where time_format("__time",'yyyyMMdd')='20210701'
group by loc,item
3、删除Druid数据
永久删除Druid数据分为两个步骤,第一:将要删除的segment标记为“unused”,可以在webui中操作。第二:提交新的任务将数据在Deep Storage中彻底删除。下面我们将datasource“mydruid_testdata”中数据彻底删除,步骤如下:
- 将segment标记为“unused”
在“segment”标签下,选中要删除的segment,点击“Drop segment(disable)”:

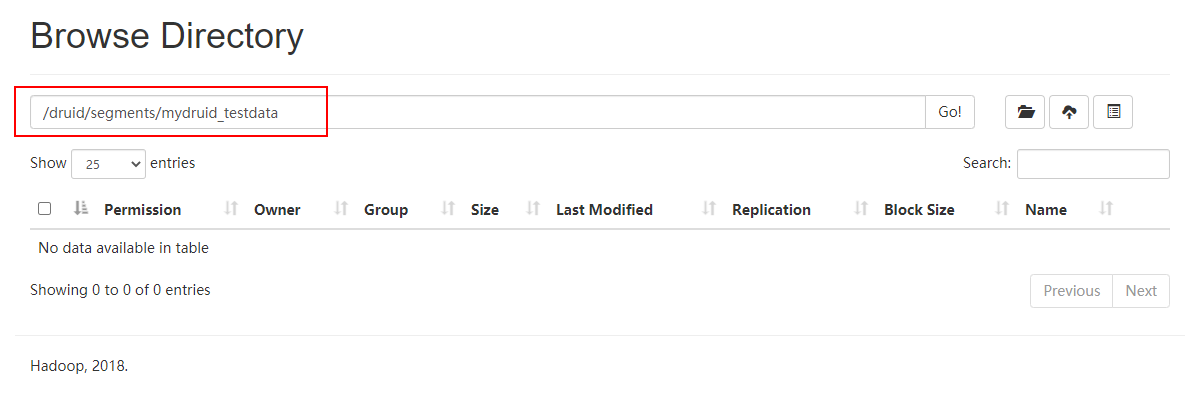
这里删除后,只是将datasource与此segment的映射关系切断,真实存在deep storage中的数据没有被删除,可以查看HDFS数据:

- 打开postman 发送post请求彻底删除segment数据
postman发送请求地址:http://node3:8081/druid/indexer/v1/task
pstman请求Row中json数据如下:
{"type":"kill","dataSource":"mydruid_testdata","interval":"2021-07-01/2021-08-01"}
postman 执行发送请求:

在Druid中对应的会生成删除任务task:

HDFS中对应dataSource下的Segment被清空:
如果想要彻底删除当前Datasource所有数据除了以上这种post发送请求外,还可以直接在Druid webui中做彻底删除操作,步骤如下:
- 点击“Datasource”标签,将对应的DataSource所有segment标记unused

- 彻底删除所有segment
再次点击“工具”,点击“issue kill task”,会将所有segment在Deep Storage中彻底删除。
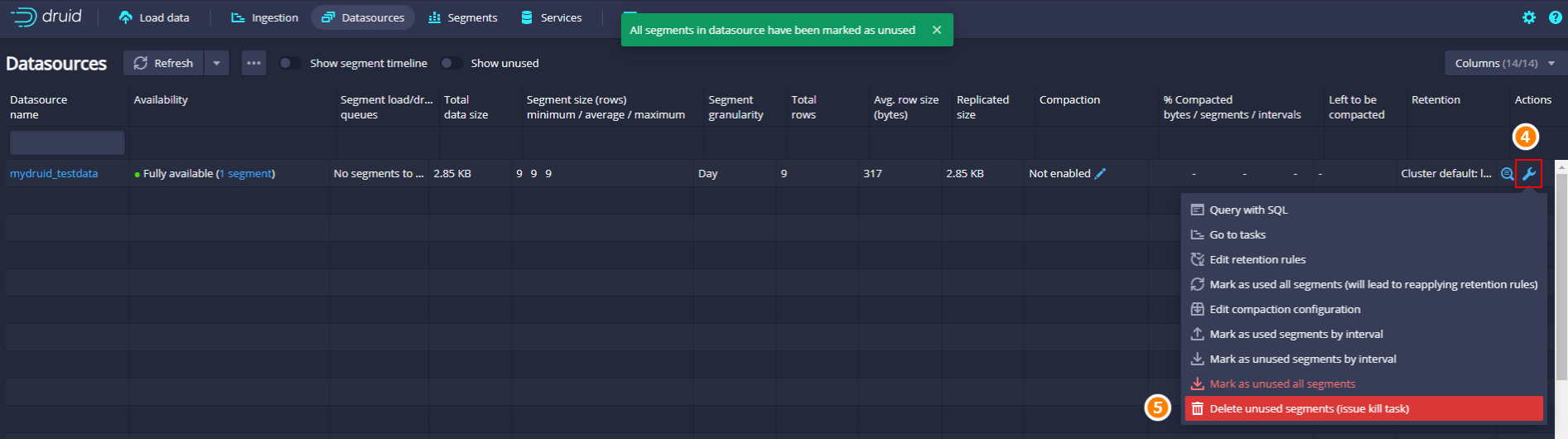
注意:这种方式删除时,动作要快,不然第一步操作完成后,datasource隔一段时间自动会清除,这样就无法执行第二步。
4、使用post方式加载本地数据
除了以上可以在页面上提交导入数据操作以外,我们还可以使用命令向Druid中导入数据,步骤如下:
- 首先准备配置文件
这里的配置文件,就是在前面页面操作提交任务之前根据配置生成的json配置文件,如下:
{
"type": "index_parallel",
"spec": {
"dataSchema": {
"dataSource": "mydruid_testdata",
"timestampSpec": {
"column": "data_dt",
"format": "iso",
"missingValue": null
},
"dimensionsSpec": {
"dimensions": [
{
"type": "string",
"name": "item",
"multiValueHandling": "SORTED_ARRAY",
"createBitmapIndex": true
},
{
"type": "string",
"name": "loc",
"multiValueHandling": "SORTED_ARRAY",
"createBitmapIndex": true
},
{
"type": "string",
"name": "uid",
"multiValueHandling": "SORTED_ARRAY",
"createBitmapIndex": true
}
],
"dimensionExclusions": [
"data_dt",
"amount",
"sum_amount",
"count"
]
},
"metricsSpec": [
{
"type": "count",
"name": "count"
},
{
"type": "longSum",
"name": "sum_amount",
"fieldName": "amount",
"expression": null
}
],
"granularitySpec": {
"type": "uniform",
"segmentGranularity": "DAY",
"queryGranularity": "HOUR",
"rollup": true,
"intervals": null
},
"transformSpec": {
"filter": null,
"transforms": []
}
},
"ioConfig": {
"type": "index_parallel",
"inputSource": {
"type": "local",
"baseDir": "/root/druid_data",
"filter": "*.json",
"files": []
},
"inputFormat": {
"type": "json",
"flattenSpec": {
"useFieldDiscovery": true,
"fields": []
},
"featureSpec": {}
},
"appendToExisting": false
},
"tuningConfig": {
"type": "index_parallel",
"maxRowsPerSegment": 5000000,
"appendableIndexSpec": {
"type": "onheap"
},
"maxRowsInMemory": 1000000,
"maxBytesInMemory": 0,
"maxTotalRows": null,
"numShards": null,
"splitHintSpec": null,
"partitionsSpec": {
"type": "dynamic",
"maxRowsPerSegment": 5000000,
"maxTotalRows": null
},
"indexSpec": {
"bitmap": {
"type": "roaring",
"compressRunOnSerialization": true
},
"dimensionCompression": "lz4",
"metricCompression": "lz4",
"longEncoding": "longs",
"segmentLoader": null
},
"indexSpecForIntermediatePersists": {
"bitmap": {
"type": "roaring",
"compressRunOnSerialization": true
},
"dimensionCompression": "lz4",
"metricCompression": "lz4",
"longEncoding": "longs",
"segmentLoader": null
},
"maxPendingPersists": 0,
"forceGuaranteedRollup": false,
"reportParseExceptions": false,
"pushTimeout": 0,
"segmentWriteOutMediumFactory": null,
"maxNumConcurrentSubTasks": 1,
"maxRetry": 3,
"taskStatusCheckPeriodMs": 1000,
"chatHandlerTimeout": "PT10S",
"chatHandlerNumRetries": 5,
"maxNumSegmentsToMerge": 100,
"totalNumMergeTasks": 10,
"logParseExceptions": false,
"maxParseExceptions": 2147483647,
"maxSavedParseExceptions": 0,
"maxColumnsToMerge": -1,
"buildV9Directly": true,
"partitionDimensions": []
}
}
}
将以上json配置命名,名称自定义,这里命名:“ingest_local_disk_data.json”。
- 使用postman发送以下post请求
postman发送请求地址:http://node3:8081/druid/indexer/v1/task,在Body中选择“Row”,填写以上json配置,并发送post请求,生成提交数据任务。

在Druid task页面中会有对应的提交任务task任务:
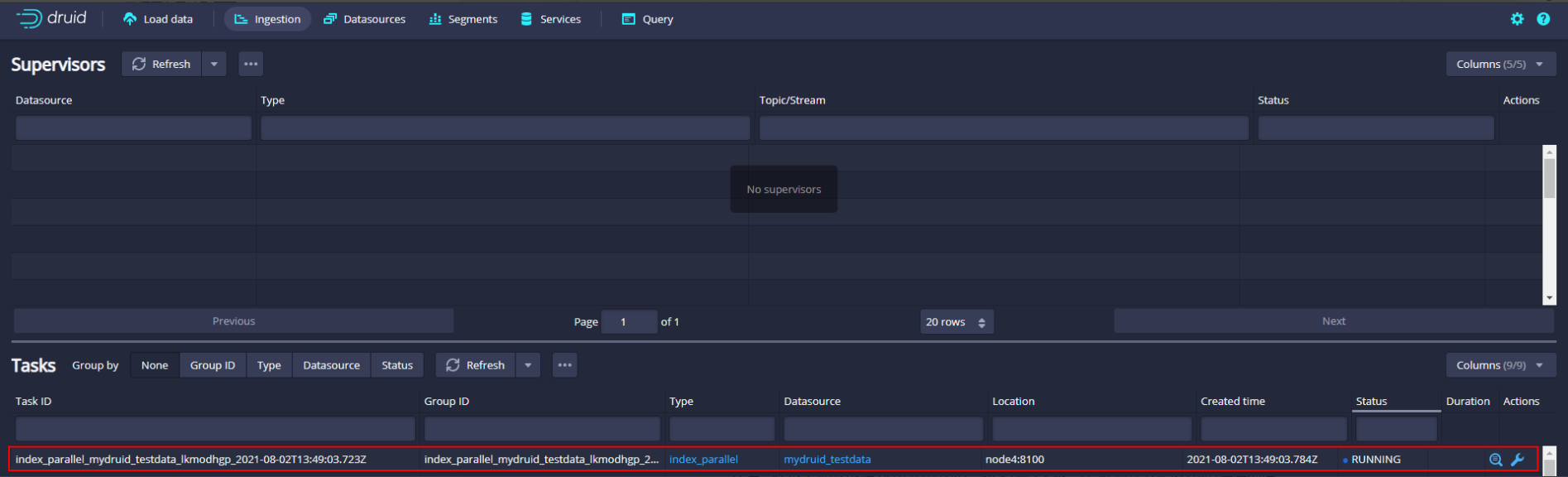
注意:在以上加载数据到Druid中时,如果执行失败,在webui中看不到错误详细信息,可以进入到对应的服务节点上查看日志:
- coordinator-overlord节点日志路径:
/software/apache-druid-0.21.1/var/sv/coordinator-overlord.log
- historical服务日志路径:
/software/apache-druid-0.21.1/var/sv/historical.log
- middleManager服务日志路径:
/software/apache-druid-0.21.1/var/sv/middleManager.log
- broker服务日志路径:
/software/apache-druid-0.21.1/var/sv/broker.log
- router服务日志路径:
/software/apache-druid-0.21.1/var/sv/router.log
二、Druid与HDFS整合
1、使用webui加载HDFS文件数据
与加载本地文件类似,这里加载的数据是HDFS中的数据,操作步骤如下:
- 将文件“fact_data.txt”上传至HDFS目录“/testdata”下
[root@node3 ~]# hdfs dfs -mkdir /testdata/
[root@node3 ~]# hdfs dfs -put /root/druid_data/fact_data.txt /testdata/
- 在Druid webui中配置加载HDFS数据
进入http://node5:8888,点击“Load data”加载数据:
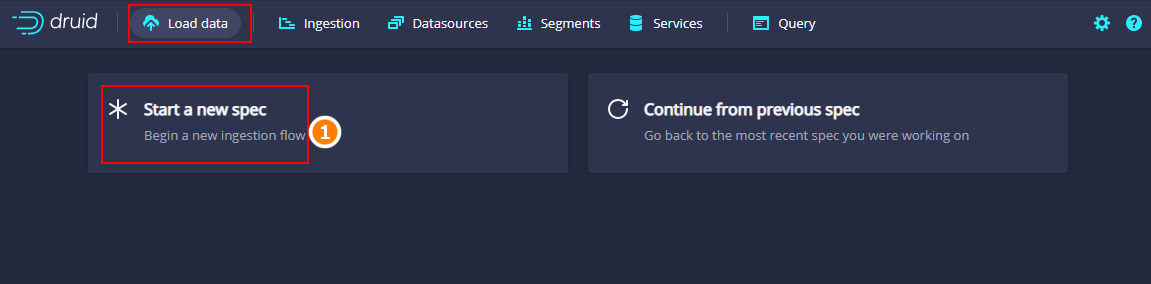
选择“Start a new spec”:

选择“HDFS”,点击“Connect data”:
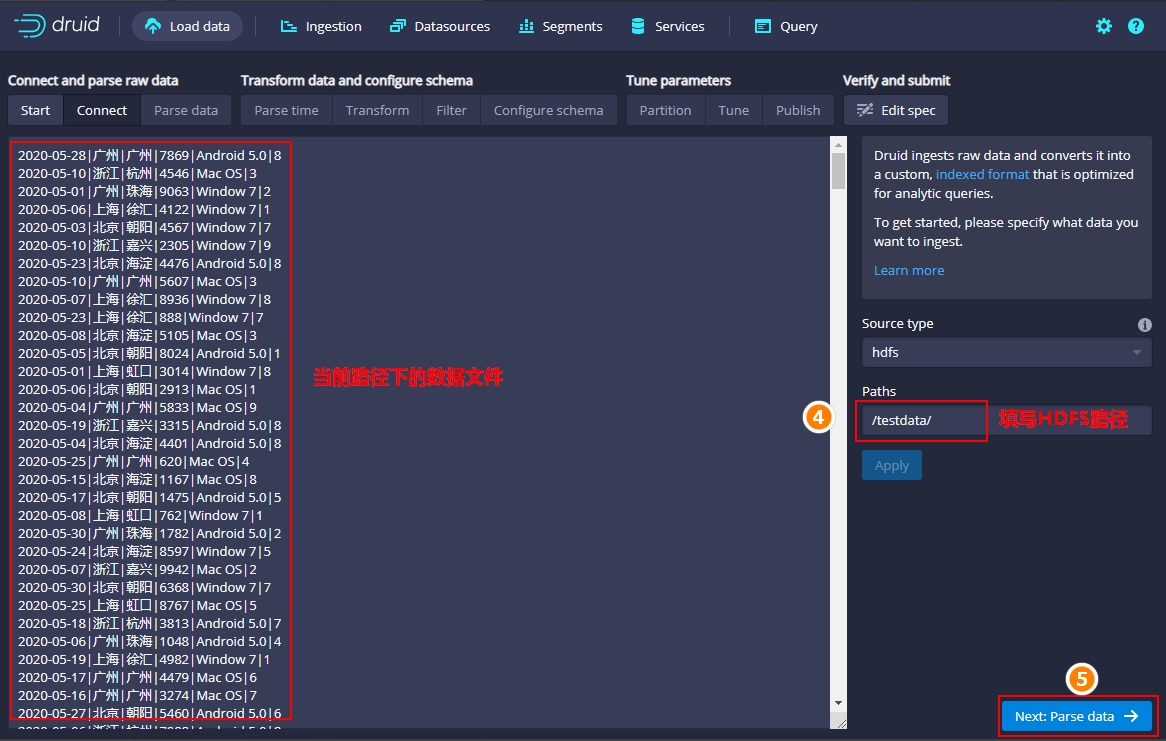
填写HDFS路径,选择“Parse data”:
 配置文本文件为tsv,分割符为“|”,点击“Parse time”:
配置文本文件为tsv,分割符为“|”,点击“Parse time”:

点击“Transform”,这里没有需要转换的列,直接点击“Filter”即可:
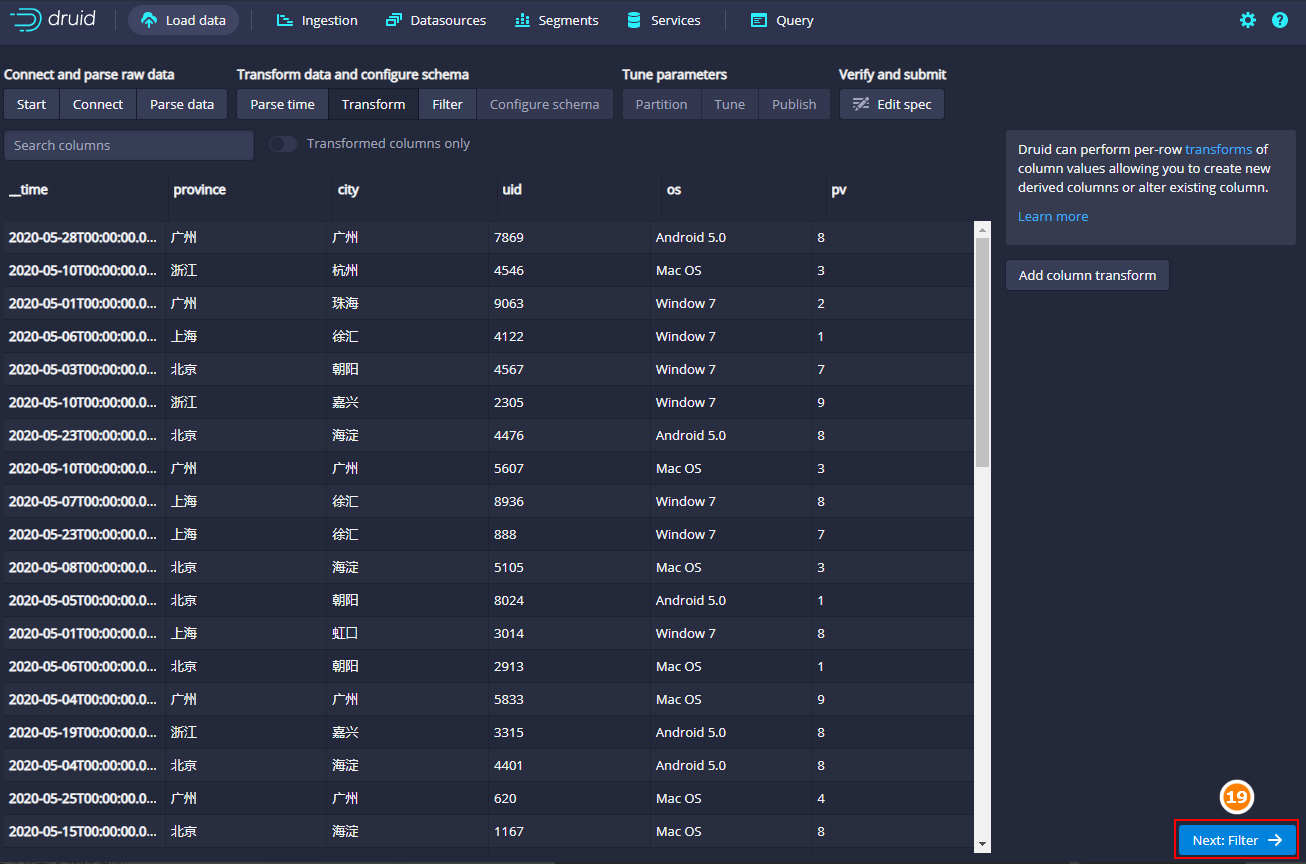
这里也没有需要过滤的数据,直接点击“Configure schema”下一步即可:

这里也不再“roll up”,将“uid”列改成string类型,然后点击“Partition”:

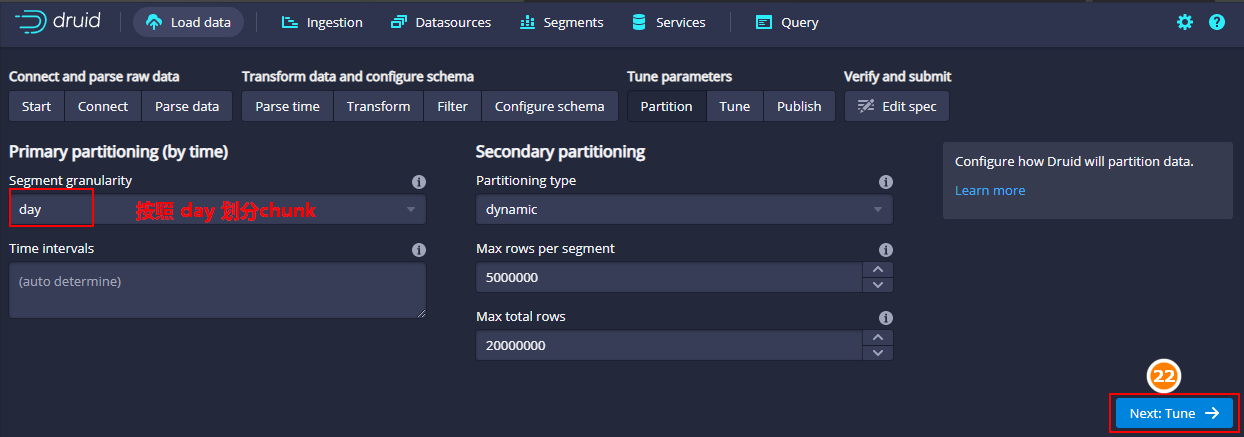
按照“day”划分chunk,点击“Tune”优化,这里也不再设置任何优化,直接点击“publish”,设置Datasource名称为“login_data”:


2、查询Druid中的数据
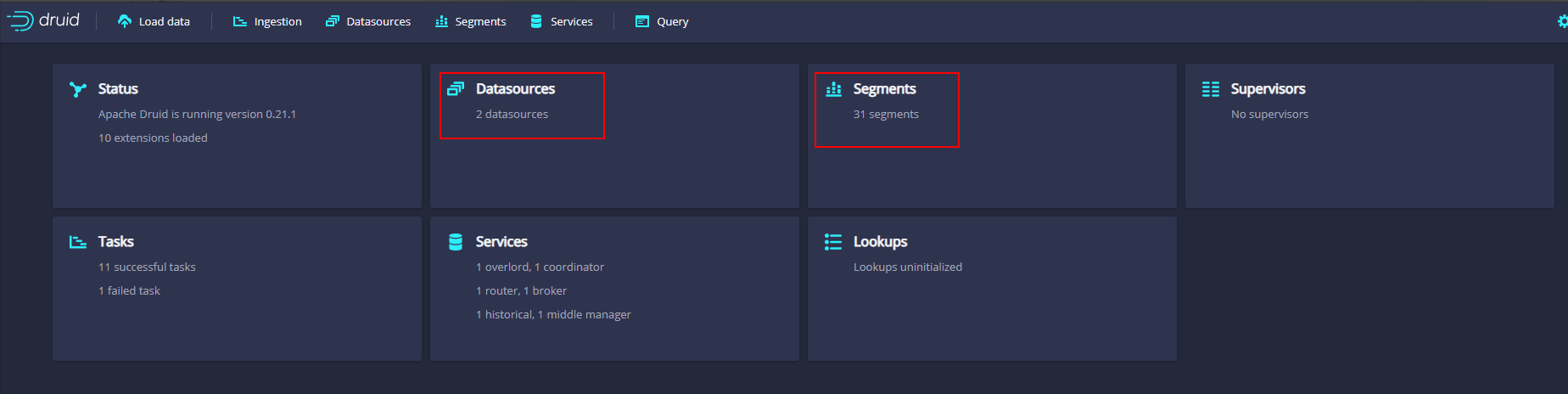
当点击“submit”后,等待大约1分钟后,可以在Druid主页面中看到有2个DataSource,以及对应的按照天生成的Segment:
在”Query”中查询SQL如下:
select count(*) from login_data

#聚合查询
select province,city,count(pv) as total_pv from login_data group by province,city order by total_pv

3、删除Druid中的数据
在Druid webui中彻底删除“login_data”中的数据。


4、使用post方式加载HDFS文件数据
准备json配置,这里的json配置就是在前面页面配置生成的json配置,如下:
{
"type": "index_parallel",
"spec": {
"dataSchema": {
"dataSource": "login_data",
"timestampSpec": {
"column": "dt",
"format": "auto",
"missingValue": null
},
"dimensionsSpec": {
"dimensions": [
{
"type": "string",
"name": "province",
"multiValueHandling": "SORTED_ARRAY",
"createBitmapIndex": true
},
{
"type": "string",
"name": "city",
"multiValueHandling": "SORTED_ARRAY",
"createBitmapIndex": true
},
{
"type": "string",
"name": "uid",
"multiValueHandling": "SORTED_ARRAY",
"createBitmapIndex": true
},
{
"type": "string",
"name": "os",
"multiValueHandling": "SORTED_ARRAY",
"createBitmapIndex": true
},
{
"type": "long",
"name": "pv",
"multiValueHandling": "SORTED_ARRAY",
"createBitmapIndex": false
}
],
"dimensionExclusions": [
"dt"
]
},
"metricsSpec": [],
"granularitySpec": {
"type": "uniform",
"segmentGranularity": "DAY",
"queryGranularity": {
"type": "none"
},
"rollup": false,
"intervals": null
},
"transformSpec": {
"filter": null,
"transforms": []
}
},
"ioConfig": {
"type": "index_parallel",
"inputSource": {
"type": "hdfs",
"paths": [
"/testdata/"
]
},
"inputFormat": {
"type": "tsv",
"columns": [
"dt",
"province",
"city",
"uid",
"os",
"pv"
],
"listDelimiter": null,
"delimiter": "|",
"findColumnsFromHeader": false,
"skipHeaderRows": 0
},
"appendToExisting": false
},
"tuningConfig": {
"type": "index_parallel",
"maxRowsPerSegment": 5000000,
"appendableIndexSpec": {
"type": "onheap"
},
"maxRowsInMemory": 1000000,
"maxBytesInMemory": 0,
"maxTotalRows": null,
"numShards": null,
"splitHintSpec": null,
"partitionsSpec": {
"type": "dynamic",
"maxRowsPerSegment": 5000000,
"maxTotalRows": null
},
"indexSpec": {
"bitmap": {
"type": "roaring",
"compressRunOnSerialization": true
},
"dimensionCompression": "lz4",
"metricCompression": "lz4",
"longEncoding": "longs",
"segmentLoader": null
},
"indexSpecForIntermediatePersists": {
"bitmap": {
"type": "roaring",
"compressRunOnSerialization": true
},
"dimensionCompression": "lz4",
"metricCompression": "lz4",
"longEncoding": "longs",
"segmentLoader": null
},
"maxPendingPersists": 0,
"forceGuaranteedRollup": false,
"reportParseExceptions": false,
"pushTimeout": 0,
"segmentWriteOutMediumFactory": null,
"maxNumConcurrentSubTasks": 1,
"maxRetry": 3,
"taskStatusCheckPeriodMs": 1000,
"chatHandlerTimeout": "PT10S",
"chatHandlerNumRetries": 5,
"maxNumSegmentsToMerge": 100,
"totalNumMergeTasks": 10,
"logParseExceptions": false,
"maxParseExceptions": 2147483647,
"maxSavedParseExceptions": 0,
"maxColumnsToMerge": -1,
"buildV9Directly": true,
"partitionDimensions": []
}
}
}
使用postman 来发送请求,将HDFS中的数据导入到Druid中,postman请求url:http://node3:8081/druid/indexer/v1/task,在row中写入以上json配置数据提交即可,执行之后可以在Druid页面中看到对应的Datasource。

- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
版权归原作者 Lansonli 所有, 如有侵权,请联系我们删除。