
一、快速入门
import findspark
from pyspark.sql import SparkSession
findspark.init()
spark = SparkSession.builder.getOrCreate()
# 无法同时运行多个SparkContext
sc = spark.sparkContext
类描述StructField(name, dataType[, nullable, metadata])定义表的字段StructType([fields])定义表的结构BinaryType()二进制ByteType()字节BooleanType()布尔NullType()空值FloatType()单精度浮点数DoubleType()双精度浮点数DecimalType([precision, scale])十进制浮点数ShortType()短整数IntegerType()整数LongType()长整数StringType()字符串DateType()日期,含年月日TimestampType()时间戳,含年月日和时分秒DayTimeIntervalType([startField, endField])时间间隔,含天数和时分秒ArrayType(elementType[, containsNull])数组(复合数据类型)MapType(keyType, valueType[, valueContainsNull])字典(复合数据类型)StructType([fields])表单(复合数据类型)
data = [
[1, "建国", 1, {'sex': '男', 'age': 17}, ['篮球', '足球'], {'ch': 92, 'en': 75}],
[2, "建军", 1, {'sex': '男', 'age': 16}, ['排球', '跑步', '爬山'], {'ch': 95, 'en': 78, 'math': 77}],
[3, "秀兰", 1, {'sex': '女', 'age': 20}, ['阅读', '音乐'], {'math': 81, 'ch': 87, 'en': 76}],
[4, "秀丽", 2, {'sex': '女', 'age': 18}, ['跳舞'], {'ch': 94, 'math': 90}],
[5, "翠花", 2, {'sex': '女', 'age': 18}, ['游泳', '瑜伽'], {'en': 70, 'math': 70}],
[6, "雪梅", 1, {'sex': '女', 'age': 17}, ['美食', '电影'], {'ch': 85, 'en': 83, 'math': 86}],
[7, "小美", 1, {'sex': '女', 'age': 20}, ['美术'], {'en': 75, 'math': 73}],
[8, "大山", 1, {'sex': '男', 'age': 18}, ['唱歌'], {'ch': 78, 'en': 71, 'math': 98}]]
定义表结构-方法1
from pyspark.sql.types import *
from pyspark.sql import types
id_ = StructField('id', LongType())
name = StructField('name', StringType())
class_ = StructField('class', IntegerType())
sex = StructField('sex', StringType())
age = StructField('age', IntegerType())
info = StructField('info', StructType([sex, age]))
interest = StructField('interest', ArrayType(StringType()))
score = StructField('score', MapType(StringType(), IntegerType()))
schema = StructType([id_, name, class_, info, interest, score])
df = spark.createDataFrame(data=data, schema=schema)
df.show()
'''
+---+----+-----+--------+------------------+--------------------+
| id|name|class| info| interest| score|
+---+----+-----+--------+------------------+--------------------+
| 1|建国| 1|{男, 17}| [篮球, 足球]|{ch -> 92, en -> 75}|
| 2|建军| 1|{男, 16}|[排球, 跑步, 爬山]|{en -> 78, math -...|
| 3|秀兰| 1|{女, 20}| [阅读, 音乐]|{en -> 76, math -...|
| 4|秀丽| 2|{女, 18}| [跳舞]|{ch -> 94, math -...|
| 5|翠花| 2|{女, 18}| [游泳, 瑜伽]|{en -> 70, math -...|
| 6|雪梅| 1|{女, 17}| [美食, 电影]|{en -> 83, math -...|
| 7|小美| 1|{女, 20}| [美术]|{en -> 75, math -...|
| 8|大山| 1|{男, 18}| [唱歌]|{en -> 71, math -...|
+---+----+-----+--------+------------------+--------------------+
'''
定义表结构-方法2
# long等价于bigint
# integer等价于int
schema = """
id long,
name string,
class integer,
info struct<sex:string, age:integer>,
interest array<string>,
score map<string,integer>
"""
df = spark.createDataFrame(data=data, schema=schema)
df.show()
'''
+---+----+-----+--------+------------------+--------------------+
| id|name|class| info| interest| score|
+---+----+-----+--------+------------------+--------------------+
| 1|建国| 1|{男, 17}| [篮球, 足球]|{ch -> 92, en -> 75}|
| 2|建军| 1|{男, 16}|[排球, 跑步, 爬山]|{en -> 78, math -...|
| 3|秀兰| 1|{女, 20}| [阅读, 音乐]|{en -> 76, math -...|
| 4|秀丽| 2|{女, 18}| [跳舞]|{ch -> 94, math -...|
| 5|翠花| 2|{女, 18}| [游泳, 瑜伽]|{en -> 70, math -...|
| 6|雪梅| 1|{女, 17}| [美食, 电影]|{en -> 83, math -...|
| 7|小美| 1|{女, 20}| [美术]|{en -> 75, math -...|
| 8|大山| 1|{男, 18}| [唱歌]|{en -> 71, math -...|
+---+----+-----+--------+------------------+--------------------+
'''
创建DataFrame
# 从行式列表中创建PySpark数据帧
from datetime import datetime, date
import pandas as pd
from pyspark.sql import Row
df = spark.createDataFrame([
Row(uid=1, name='tony', height=1.73, birth=date(2000, 1, 1), dt=datetime(2020, 1, 1, 12, 0)),
Row(uid=2, name='jack', height=1.78, birth=date(2000, 2, 1), dt=datetime(2020, 1, 2, 12, 0)),
Row(uid=3, name='mike', height=1.83, birth=date(2000, 3, 1), dt=datetime(2020, 1, 3, 12, 0))])
df.show()
'''
+---+----+------+----------+-------------------+
|uid|name|height| birth| dt|
+---+----+------+----------+-------------------+
| 1|tony| 1.73|2000-01-01|2020-01-01 12:00:00|
| 2|jack| 1.78|2000-02-01|2020-01-02 12:00:00|
| 3|mike| 1.83|2000-03-01|2020-01-03 12:00:00|
+---+----+------+----------+-------------------+
'''
# 使用显式架构创建PySpark数据帧
df = spark.createDataFrame([
(1, 'tony', 1.73, date(2000, 1, 1), datetime(2020, 1, 1, 12, 0)),
(2, 'jack', 1.78, date(2000, 2, 1), datetime(2020, 1, 2, 12, 0)),
(3, 'mike', 1.83, date(2000, 3, 1), datetime(2020, 1, 3, 12, 0))],
schema='uid long, name string, height double, birth date, dt timestamp')
df.show()
'''
+---+----+------+----------+-------------------+
|uid|name|height| birth| dt|
+---+----+------+----------+-------------------+
| 1|tony| 1.73|2000-01-01|2020-01-01 12:00:00|
| 2|jack| 1.78|2000-02-01|2020-01-02 12:00:00|
| 3|mike| 1.83|2000-03-01|2020-01-03 12:00:00|
+---+----+------+----------+-------------------+
'''
# 从panda数据帧创建PySpark数据帧
pandas_df = pd.DataFrame({
'uid': [1, 2, 3],
'name': ['tony', 'jack', 'mike'],
'height': [1.73, 1.78, 1.83],
'birth': [date(2000, 1, 1),
date(2000, 2, 1),
date(2000, 3, 1)],
'dt': [datetime(2020, 1, 1, 12, 0),
datetime(2020, 1, 2, 12, 0),
datetime(2020, 1, 3, 12, 0)]})
df = spark.createDataFrame(pandas_df)
df.show()
'''
+---+----+------+----------+-------------------+
|uid|name|height| birth| dt|
+---+----+------+----------+-------------------+
| 1|tony| 1.73|2000-01-01|2020-01-01 12:00:00|
| 2|jack| 1.78|2000-02-01|2020-01-02 12:00:00|
| 3|mike| 1.83|2000-03-01|2020-01-03 12:00:00|
+---+----+------+----------+-------------------+
'''
# 从包含元组列表的RDD创建PySpark数据帧
rdd = spark.sparkContext.parallelize([
(1, 'tony', 1.73, date(2000, 1, 1), datetime(2020, 1, 1, 12, 0)),
(2, 'jack', 1.78, date(2000, 2, 1), datetime(2020, 1, 2, 12, 0)),
(3, 'mike', 1.83, date(2000, 3, 1), datetime(2020, 1, 3, 12, 0))])
df = spark.createDataFrame(rdd, schema=['uid', 'name', 'height', 'birth', 'dt'])
df.show()
'''
+---+----+------+----------+-------------------+
|uid|name|height| birth| dt|
+---+----+------+----------+-------------------+
| 1|tony| 1.73|2000-01-01|2020-01-01 12:00:00|
| 2|jack| 1.78|2000-02-01|2020-01-02 12:00:00|
| 3|mike| 1.83|2000-03-01|2020-01-03 12:00:00|
+---+----+------+----------+-------------------+
'''
# 以上创建的数据帧具有相同的结果和架构
# Schema: 字段名称、数据类型、是否可空的
df.printSchema()
'''
root
|-- uid: long (nullable = true)
|-- name: string (nullable = true)
|-- height: double (nullable = true)
|-- birth: date (nullable = true)
|-- dt: timestamp (nullable = true)
'''
预览数据
df.show(1) # 预览1条数据
'''
+---+----+------+----------+-------------------+
|uid|name|height| birth| dt|
+---+----+------+----------+-------------------+
| 1|tony| 1.73|2000-01-01|2020-01-01 12:00:00|
+---+----+------+----------+-------------------+
only showing top 1 row
'''
# eagerEval, eager evaluation, 立即求值
# 立即打印DataFrame信息
spark.conf.set('spark.sql.repl.eagerEval.enabled', True)
df
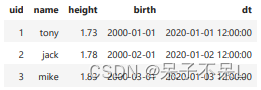
# vertical, 垂直显示
df.show(1, vertical=True)
'''
-RECORD 0---------------------
uid | 1
name | tony
height | 1.73
birth | 2000-01-01
dt | 2020-01-01 12:00:00
only showing top 1 row
'''
# 打印字段信息
df.columns
# ['uid', 'name', 'height', 'birth', 'dt']
# 打印架构信息, 类似pandas的df.info()
df.printSchema()
'''
root
|-- uid: long (nullable = true)
|-- name: string (nullable = true)
|-- height: double (nullable = true)
|-- birth: date (nullable = true)
|-- dt: timestamp (nullable = true)
'''
# describe, 统计描述
df.select('uid', 'name', 'height').describe().show()
'''
+-------+---+----+------------------+
|summary|uid|name| height|
+-------+---+----+------------------+
| count| 3| 3| 3|
| mean|2.0|null| 1.78|
| stddev|1.0|null|0.0500000000000001|
| min| 1|jack| 1.73|
| max| 3|tony| 1.83|
+-------+---+----+------------------+
'''
# collect, 预览所有数据
df.collect()
'''
[Row(uid=1, name='tony', height=1.73, birth=datetime.date(2000, 1, 1), dt=datetime.datetime(2020, 1, 1, 12,
0)),
Row(uid=2, name='jack', height=1.78, birth=datetime.date(2000, 2, 1), dt=datetime.datetime(2020, 1, 2, 12,
0)),
Row(uid=3, name='mike', height=1.83, birth=datetime.date(2000, 3, 1), dt=datetime.datetime(2020, 1, 3, 12,
0))]
'''
# take, 预览1行数据
df.take(1)
# [Row(uid=1, name='tony', height=1.73, birth=datetime.date(2000, 1, 1), dt=datetime.datetime(2020, 1, 1, 12,0))]
# 转换为pandas的df
df.toPandas()

选取和访问数据
# 选取name列并显示
df.select(df.name).show()
'''
+----+
|name|
+----+
|tony|
|jack|
|mike|
+----+
'''
from pyspark.sql.functions import upper
# 将name列转换为大写,并新增字段upper_name
df.withColumn('upper_name', upper(df.name)).show()
'''
+---+----+------+----------+-------------------+----------+
|uid|name|height| birth| dt|upper_name|
+---+----+------+----------+-------------------+----------+
| 1|tony| 1.73|2000-01-01|2020-01-01 12:00:00| TONY|
| 2|jack| 1.78|2000-02-01|2020-01-02 12:00:00| JACK|
| 3|mike| 1.83|2000-03-01|2020-01-03 12:00:00| MIKE|
+---+----+------+----------+-------------------+----------+
'''
# 筛选uid列等于1的数据
df.filter(df.uid == 1).show()
'''
+---+----+------+----------+-------------------+
|uid|name|height| birth| dt|
+---+----+------+----------+-------------------+
| 1|tony| 1.73|2000-01-01|2020-01-01 12:00:00|
+---+----+------+----------+-------------------+
'''
应用函数
**PySpark支持各种UDF和API,支持调用Python内置函数和Pandas函数 **
UDF, User defined function, 用户自定义函数
import pandas
from pyspark.sql.functions import pandas_udf
通过pandas_udf调用Pandas函数
@pandas_udf('long') # 申明返回值的数据类型
def pandas_func(col: pd.Series) -> pd.Series:
# 使用poandas的Series,每个元素*100
return col * 100
df.select(pandas_func(df.height)).show()
'''
+-------------------+
|pandas_func(height)|
+-------------------+
| 173|
| 178|
| 183|
+-------------------+
'''
通过mapInPandas调用Pandas函数
def pandas_func(DataFrame):
for row in DataFrame:
yield row[row.uid == 1]
df.mapInPandas(pandas_func, schema=df.schema).show()
'''
+---+----+------+----------+-------------------+
|uid|name|height| birth| dt|
+---+----+------+----------+-------------------+
| 1|tony| 1.73|2000-01-01|2020-01-01 12:00:00|
+---+----+------+----------+-------------------+
'''
分组聚合
df = spark.createDataFrame([
[1, 'red', 'banana', 10],
[2, 'blue', 'banana', 20],
[3, 'red', 'carrot', 30],
[4, 'blue', 'grape', 40],
[5, 'red', 'carrot', 50],
[6, 'black', 'carrot', 60],
[7, 'red', 'banana', 70],
[8, 'red', 'grape', 80]],
schema=['order_id', 'color', 'fruit', 'amount'])
df.show()
'''
+--------+-----+------+------+
|order_id|color| fruit|amount|
+--------+-----+------+------+
| 1| red|banana| 10|
| 2| blue|banana| 20|
| 3| red|carrot| 30|
| 4| blue| grape| 40|
| 5| red|carrot| 50|
| 6|black|carrot| 60|
| 7| red|banana| 70|
| 8| red| grape| 80|
+--------+-----+------+------+
'''
df.groupby('fruit').agg({'amount': 'sum'}).show()
'''
+------+-----------+
| fruit|sum(amount)|
+------+-----------+
| grape| 120|
|banana| 100|
|carrot| 140|
+------+-----------+
'''
通过applyInPandas调用Pandas函数
def pandas_func(pd_df):
pd_df['total'] = pd_df['amount'].sum()
return pd_df
schema = 'order_id long, color string, fruit string, amount long, total long'
# 以color分组对amount求和,并新增total字段
df.groupby('color').applyInPandas(pandas_func, schema=schema).show()
'''
+--------+-----+------+------+-----+
|order_id|color| fruit|amount|total|
+--------+-----+------+------+-----+
| 1| red|banana| 10| 240|
| 3| red|carrot| 30| 240|
| 5| red|carrot| 50| 240|
| 7| red|banana| 70| 240|
| 8| red| grape| 80| 240|
| 6|black|carrot| 60| 60|
| 2| blue|banana| 20| 60|
| 4| blue| grape| 40| 60|
+--------+-----+------+------+-----+
'''
df1 = spark.createDataFrame(
data=[(1, 'tony'),
(2, 'jack'),
(3, 'mike'),
(4, 'rose')],
schema=('id', 'name'))
df2 = spark.createDataFrame(
data=[(1, '二班'),
(2, '三班')],
schema=('id', 'class'))
def left_join(df_left, df_right):
# merge, 表关联
return pd.merge(df_left, df_right, how='left', on='id')
# cogroup, combine group, 分组合并
schema = 'id int, name string, class string'
df1.groupby('id') \
.cogroup(df2.groupby('id')) \
.applyInPandas(left_join, schema=schema).show()
'''
+---+----+-----+
| id|name|class|
+---+----+-----+
| 1|tony| 二班|
| 3|mike| null|
| 2|jack| 三班|
| 4|rose| null|
+---+----+-----+
'''
数据导入和导出
# CSV简单易用,Parquet和ORC是高性能的文件格式,读写速度更快
# PySpark中还有许多其他可用的数据源,如JDBC、text、binaryFile、Avro等
df.write.csv('fruit.csv', header=True)
spark.read.csv('fruit.csv', header=True).show()
'''
+--------+-----+------+------+
|order_id|color| fruit|amount|
+--------+-----+------+------+
| 5| red|carrot| 50|
| 6|black|carrot| 60|
| 1| red|banana| 10|
| 2| blue|banana| 20|
| 3| red|carrot| 30|
| 4| blue| grape| 40|
| 7| red|banana| 70|
| 8| red| grape| 80|
+--------+-----+------+------+
'''
# Parquet
df.write.parquet('fruit.parquet')
spark.read.parquet('fruit.parquet').show()
'''
+--------+-----+------+------+
|order_id|color| fruit|amount|
+--------+-----+------+------+
| 5| red|carrot| 50|
| 6|black|carrot| 60|
| 1| red|banana| 10|
| 2| blue|banana| 20|
| 7| red|banana| 70|
| 8| red| grape| 80|
| 3| red|carrot| 30|
| 4| blue| grape| 40|
+--------+-----+------+------+
'''
# ORC
df.write.orc('fruit.orc')
spark.read.orc('fruit.orc').show()
'''
+--------+-----+------+------+
|order_id|color| fruit|amount|
+--------+-----+------+------+
| 7| red|banana| 70|
| 8| red| grape| 80|
| 5| red|carrot| 50|
| 6|black|carrot| 60|
| 1| red|banana| 10|
| 2| blue|banana| 20|
| 3| red|carrot| 30|
| 4| blue| grape| 40|
+--------+-----+------+------+
'''
SparkSQL
# DataFrame和Spark SQL共享同一个执行引擎,因此可以无缝地互换使用
# 可以将DataFrame注册为一个表,并运行SQL语句
df.createOrReplaceTempView('tableA')
spark.sql('select count(*) from tableA').show()
'''
+--------+
|count(1)|
+--------+
| 8|
+--------+
'''
# 可以在开箱即用的SQL中注册和调用UDF
@pandas_udf('float')
def pandas_func(col: pd.Series) -> pd.Series:
return col * 0.1
# register, 注册UDF函数
spark.udf.register('pandas_func', pandas_func)
spark.sql('select pandas_func(amount) from tableA').show()
'''
+-------------------+
|pandas_func(amount)|
+-------------------+
| 1.0|
| 2.0|
| 3.0|
| 4.0|
| 5.0|
| 6.0|
| 7.0|
| 8.0|
+-------------------+
'''
from pyspark.sql.functions import expr
# expr, expression, SQL表达式
df.selectExpr('pandas_func(amount)').show()
df.select(expr('pandas_func(amount)')).show()
'''
+-------------------+
|pandas_func(amount)|
+-------------------+
| 1.0|
| 2.0|
| 3.0|
| 4.0|
| 5.0|
| 6.0|
| 7.0|
| 8.0|
+-------------------+
+-------------------+
|pandas_func(amount)|
+-------------------+
| 1.0|
| 2.0|
| 3.0|
| 4.0|
| 5.0|
| 6.0|
| 7.0|
| 8.0|
+-------------------+
'''
词频统计
rdd = sc.textFile('./data/word.txt')
rdd.collect()
'''
['hello world',
'hello python',
'hello hadoop',
'hello hive',
'hello spark',
'spark and jupyter',
'spark and python',
'spark and pandas',
'spark and sql']
'''
rdd_word = rdd.flatMap(lambda x: x.split(' '))
rdd_one = rdd_word.map(lambda x: (x, 1))
rdd_count = rdd_one.reduceByKey(lambda x, y: x+y)
rdd_count.collect()
'''
[('world', 1),
('python', 2),
('hadoop', 1),
('hive', 1),
('jupyter', 1),
('pandas', 1),
('hello', 5),
('spark', 5),
('and', 4),
('sql', 1)]
'''
二、SparkSQL——创建DF
import pyspark
from pyspark.sql import SparkSession
import findspark
findspark.init()
spark = SparkSession \
.builder \
.appName("test") \
.master("local[*]") \
.enableHiveSupport() \
.getOrCreate()
sc = spark.sparkContext
1.通过toDF方法
- 将RDD转换为DataFrame
rdd = sc.parallelize(
[("jack", 20),
("rose", 18)])
df = rdd.toDF(schema=['name','age'])
df.show()
'''
+----+---+
|name|age|
+----+---+
|jack| 20|
|rose| 18|
+----+---+
'''
- 将DataFrame转换为RDD
rdd = df.rdd
rdd.collect()
# [Row(name='jack', age=20), Row(name='rose', age=18)]
2.通过createDataFrame方法
- 将Pandas的DataFrame转换为pyspark的DataFrame
import pandas as pd
pd_df = pd.DataFrame(
data=[("jack", 20),
("rose", 18)],
columns=["name", "age"])
pd_df.head()

df = spark.createDataFrame(pd_df)
df.show()
'''
+----+---+
|name|age|
+----+---+
|jack| 20|
|rose| 18|
+----+---+
'''
- 将pyspark的DataFrame转换为Pandas的DataFrame
pd_df = df.toPandas()
pd_df
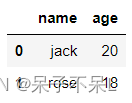
3.通过createDataFrame方法
- 将python的list转换为pyspark的DataFrame
data = [("jack", 20),
("rose", 18)]
df = spark.createDataFrame(data=data,schema=['name','age'])
df.show()
'''
+----+---+
|name|age|
+----+---+
|jack| 20|
|rose| 18|
+----+---+
'''
4.通过createDataFrame方法
- 指定rdd和schema创建DataFrame
from datetime import datetime
data = [("jack", 20, datetime(2001, 1, 10)),
("rose", 18, datetime(2003, 2, 20)),
("tom", 20, datetime(2004, 3, 30))]
rdd = sc.parallelize(data)
rdd.collect()
'''
[('jack', 20, datetime.datetime(2001, 1, 10, 0, 0)),
('rose', 18, datetime.datetime(2003, 2, 20, 0, 0)),
('tom', 20, datetime.datetime(2004, 3, 30, 0, 0))]
'''
schema = 'name string, age int, birth date'
df = spark.createDataFrame(data=rdd,schema=schema)
df.show()
'''
+----+---+----------+
|name|age| birth|
+----+---+----------+
|jack| 20|2001-01-10|
|rose| 18|2003-02-20|
| tom| 20|2004-03-30|
+----+---+----------+
'''
df.printSchema()
'''
root
|-- name: string (nullable = true)
|-- age: integer (nullable = true)
|-- birth: date (nullable = true)
'''
5.通过读取文件创建DataFrame
- 读取json文件,csv文件,txt文件,parquet文件,hive数据表,mysql数据表等
5.1.读取json文件
df = spark.read.json('./data/iris.json')
df.show(5)
'''
+-----+------------+-----------+------------+-----------+
|label|petal_length|petal_width|sepal_length|sepal_width|
+-----+------------+-----------+------------+-----------+
| 0| 1.4| 0.2| 5.1| 3.5|
| 0| 1.4| 0.2| 4.9| 3.0|
| 0| 1.3| 0.2| 4.7| 3.2|
| 0| 1.5| 0.2| 4.6| 3.1|
| 0| 1.4| 0.2| 5.0| 3.6|
+-----+------------+-----------+------------+-----------+
'''
df.printSchema()
'''
root
|-- label: long (nullable = true)
|-- petal_length: double (nullable = true)
|-- petal_width: double (nullable = true)
|-- sepal_length: double (nullable = true)
|-- sepal_width: double (nullable = true)
'''
5.2.读取csv文件
# inferSchema=True 推断字段的数据类型
df = spark.read.csv('./data/iris.csv', inferSchema=True, header=True)
df.show(5)
df.printSchema()
'''
+------------+-----------+------------+-----------+-----+
|sepal_length|sepal_width|petal_length|petal_width|label|
+------------+-----------+------------+-----------+-----+
| 5.1| 3.5| 1.4| 0.2| 0|
| 4.9| 3.0| 1.4| 0.2| 0|
| 4.7| 3.2| 1.3| 0.2| 0|
| 4.6| 3.1| 1.5| 0.2| 0|
| 5.0| 3.6| 1.4| 0.2| 0|
+------------+-----------+------------+-----------+-----+
only showing top 5 rows
root
|-- sepal_length: double (nullable = true)
|-- sepal_width: double (nullable = true)
|-- petal_length: double (nullable = true)
|-- petal_width: double (nullable = true)
|-- label: integer (nullable = true)
'''
5.3.读取txt文件
df = spark.read.csv('data/iris.txt',sep=',',inferSchema=True,header=True)
df.show(5)
df.printSchema()
'''
+------------+-----------+------------+-----------+-----+
|sepal_length|sepal_width|petal_length|petal_width|label|
+------------+-----------+------------+-----------+-----+
| 5.1| 3.5| 1.4| 0.2| 0|
| 4.9| 3.0| 1.4| 0.2| 0|
| 4.7| 3.2| 1.3| 0.2| 0|
| 4.6| 3.1| 1.5| 0.2| 0|
| 5.0| 3.6| 1.4| 0.2| 0|
+------------+-----------+------------+-----------+-----+
only showing top 5 rows
root
|-- sepal_length: double (nullable = true)
|-- sepal_width: double (nullable = true)
|-- petal_length: double (nullable = true)
|-- petal_width: double (nullable = true)
|-- label: integer (nullable = true)
'''
5.4.读取parquet文件
df = spark.read.parquet('data/iris.parquet')
df.show(5)
'''
+-----+------------+-----------+------------+-----------+
|label|petal_length|petal_width|sepal_length|sepal_width|
+-----+------------+-----------+------------+-----------+
| 0| 1.4| 0.2| 5.1| 3.5|
| 0| 1.4| 0.2| 4.9| 3.0|
| 0| 1.3| 0.2| 4.7| 3.2|
| 0| 1.5| 0.2| 4.6| 3.1|
| 0| 1.4| 0.2| 5.0| 3.6|
+-----+------------+-----------+------------+-----------+
only showing top 5 rows
'''
5.5.读取hive数据表
# 创建数据库
spark.sql('create database edu')
# 创建表
spark.sql(
'''
create table edu.course(
c_id int,
c_name string,
t_id int
)
row format delimited
fields terminated by ','
'''
)
# 加载本地数据到指定表
spark.sql("load data local inpath 'data/course.csv' into table edu.course")
# 读取数据(如果访问不了,可能需要修改 metastore_db 、spark-warehouse 文件权限为共享才能访问)
df = spark.sql('select * from edu.course')
df.show(5)
'''
+----+------+----+
|c_id|c_name|t_id|
+----+------+----+
| 1| 语文| 2|
| 2| 数学| 1|
| 3| 英语| 3|
| 4| 政治| 5|
| 5| 历史| 4|
+----+------+----+
only showing top 5 rows
'''
5.6.读取mysql数据表
- MySQL Connector版本必须一致
- 解压后将 mysql-connector-java-8.0.25\mysql-connector-java-8.0.25.jar
- 复制到spark环境的 Spark\jars\mysql-connector-java-8.0.25.jar
- MySQL :: Download MySQL Connector/J (Archived Versions)
# localhost:链接地址
# ?serverTimezone=GMT 设置时区;UTC代表的是全球标准时间 ,但是我们使用的时间是北京时区也就是东八区,领先UTC八个小时。
url = 'jdbc:mysql://localhost:3306/db?serverTimezone=GMT'
df = (
spark.read.format('jdbc')
.option('url', url)
.option('dbtable','order_info')
.option('user','root')
.option('password','root')
.load()
)
df.show(5)
'''
+----------+-------+----------+--------+------------+----------+-------------------+-------------------+
| order_id|user_id|product_id|platform|order_amount|pay_amount| order_time| pay_time|
+----------+-------+----------+--------+------------+----------+-------------------+-------------------+
|SYS1000001|U157213| P000064| App| 272.51| 272.51|2018-02-14 12:20:36|2018-02-14 12:31:28|
|SYS1000002|U191121| P000583| Wechat| 337.93| 0.0|2018-08-14 09:40:34|2018-08-14 09:45:23|
|SYS1000003|U211918| P000082| Wechat| 905.68| 891.23|2018-11-02 20:17:25|2018-11-02 20:31:41|
|SYS1000004|U201322| P000302| Web| 786.27| 688.88|2018-11-19 10:36:39|2018-11-19 10:51:14|
|SYS1000005|U120872| P000290| App| 550.77| 542.51|2018-12-26 11:19:16|2018-12-26 11:27:09|
+----------+-------+----------+--------+------------+----------+-------------------+-------------------+
only showing top 5 rows
'''
三、SparkSQL——导出DF
import pyspark
from pyspark.sql import SparkSession
import findspark
findspark.init()
spark = SparkSession \
.builder \
.appName("test") \
.master("local[*]") \
.enableHiveSupport() \
.getOrCreate()
sc = spark.sparkContext
1.读取csv文件
df = spark.read.csv(
path="data/iris.csv",
sep=',',
inferSchema=True,
header=True)
df.show(5)
'''
+------------+-----------+------------+-----------+-----+
|sepal_length|sepal_width|petal_length|petal_width|label|
+------------+-----------+------------+-----------+-----+
| 5.1| 3.5| 1.4| 0.2| 0|
| 4.9| 3.0| 1.4| 0.2| 0|
| 4.7| 3.2| 1.3| 0.2| 0|
| 4.6| 3.1| 1.5| 0.2| 0|
| 5.0| 3.6| 1.4| 0.2| 0|
+------------+-----------+------------+-----------+-----+
only showing top 5 rows
'''
- 保存为csv文件,txt文件,json文件,parquet文件,hive数据表
2.保存为csv文件
# 如果文件已存在则抛出异常
df.write.csv('data/df_csv')
# 会保存到文件夹中,csv文件命名随机
3.保存为txt文件
# 仅支持只有一列的df,且该列数据类型为字符串
# df.write.text('data/df_text')
df.rdd.saveAsTextFile('data/df_text')
4.保存为json文件
df.write.json('data/df_json')
5.保存为parquet文件
# 存储空间小,加载速度快
# 不分区,部分文件夹存储
df.write.parquet('data/df_parquet')
# 分区,分文件夹存储
df.write.partitionBy('label').format('parquet').save('data/df_parquet_par') # 按照'物种'字段分区存储
6.保存为hive数据表
df.show(5)
'''
+------------+-----------+------------+-----------+-----+
|sepal_length|sepal_width|petal_length|petal_width|label|
+------------+-----------+------------+-----------+-----+
| 5.1| 3.5| 1.4| 0.2| 0|
| 4.9| 3.0| 1.4| 0.2| 0|
| 4.7| 3.2| 1.3| 0.2| 0|
| 4.6| 3.1| 1.5| 0.2| 0|
| 5.0| 3.6| 1.4| 0.2| 0|
+------------+-----------+------------+-----------+-----+
only showing top 5 rows
'''
spark.sql('create database db') # 创建库
df.write.bucketBy(3, 'label').sortBy('sepal_length').saveAsTable('db.iris') # 按照label字段分桶,并且按照sepal_length字段排序,保存到db库的iris表中
四、SparkSQL——DF的API交互
1、数据预览
import pyspark
from pyspark.sql import SparkSession
import findspark
findspark.init()
spark = SparkSession \
.builder \
.appName("test") \
.master("local[*]") \
.enableHiveSupport() \
.getOrCreate()
sc = spark.sparkContext
1.读取数据
# inferSchema推断数据类型
df = spark.read.csv("data/order.csv", header=True, inferSchema=True)
2.行式预览数据
- 预览前1行
df.first()
# Row(order_id=10021265709, order_date='2010-10-13', region='华北', province='河北',product_type='办公用品', price=38.94, quantity=6, profit=-213.25)
- 预览前3行
df.head(3)
'''
[Row(order_id=10021265709, order_date='2010-10-13', region='华北', province='河北', product_type='办公用品', price=38.94, quantity=6, profit=-213.25),
Row(order_id=10021250753, order_date='2012-02-20', region='华南', province='河南', product_type='办公用品', price=2.08, quantity=2, profit=-4.64),
Row(order_id=10021257699, order_date='2011-07-15', region='华南', province='广东', product_type='家具产品', price=107.53, quantity=26, profit=1054.82)]
'''
df.show(3)
'''
+-----------+----------+------+--------+------------+------+--------+-------+
| order_id|order_date|region|province|product_type| price|quantity| profit|
+-----------+----------+------+--------+------------+------+--------+-------+
|10021265709|2010-10-13| 华北| 河北| 办公用品| 38.94| 6|-213.25|
|10021250753|2012-02-20| 华南| 河南| 办公用品| 2.08| 2| -4.64|
|10021257699|2011-07-15| 华南| 广东| 家具产品|107.53| 26|1054.82|
+-----------+----------+------+--------+------------+------+--------+-------+
only showing top 3 rows
'''
- 预览后3行
df.tail(3)
'''
[Row(order_id=10021249146, order_date='2012-11-15', region='华南', province='广东', product_type='数码电子', price=115.99, quantity=10, profit=-105.7),
Row(order_id=10021687707, order_date='2009-01-23', region='华南', province='广东', product_type='数码电子', price=73.98, quantity=18, profit=-23.44),
Row(order_id=10021606289, order_date='2011-05-27', region='华南', province='广东', product_type='办公用品', price=9.71, quantity=20, profit=-113.52)]
'''
- 预览所有行
df.collect()
3.表式预览数据
df.show(5) # 默认预览前面20行
'''
+-----------+----------+------+--------+------------+------+--------+--------+
| order_id|order_date|region|province|product_type| price|quantity| profit|
+-----------+----------+------+--------+------------+------+--------+--------+
|10021265709|2010-10-13| 华北| 河北| 办公用品| 38.94| 6| -213.25|
|10021250753|2012-02-20| 华南| 河南| 办公用品| 2.08| 2| -4.64|
|10021257699|2011-07-15| 华南| 广东| 家具产品|107.53| 26| 1054.82|
|10021258358|2011-07-15| 华北| 内蒙古| 家具产品| 70.89| 24|-1748.56|
|10021249836|2011-07-15| 华北| 内蒙古| 数码电子| 7.99| 23| -85.13|
+-----------+----------+------+--------+------------+------+--------+--------+
only showing top 5 rows
'''
4.查看架构信息
# 查看字段名称、数据类型、是否可空等,元数据
df.printSchema()
'''
root
|-- order_id: long (nullable = true)
|-- order_date: string (nullable = true)
|-- region: string (nullable = true)
|-- province: string (nullable = true)
|-- product_type: string (nullable = true)
|-- price: double (nullable = true)
|-- quantity: integer (nullable = true)
|-- profit: double (nullable = true)
'''
5.查看字段列表
df.columns
'''
['order_id',
'order_date',
'region',
'province',
'product_type',
'price',
'quantity',
'profit']
'''
6.查看字段数据类型
df.dtypes
'''
[('order_id', 'bigint'),
('order_date', 'string'),
('region', 'string'),
('province', 'string'),
('product_type', 'string'),
('price', 'double'),
('quantity', 'int'),
('profit', 'double')]
'''
7.查看行数
df.count()
# 8567
8.查看文件路径
df.inputFiles()
# ['file:///D:/桌面/PySpark/PySpark/data/order.csv']
2、类SQL的基本操作
- 对spark的df新增列,删除列,重命名,排序,删除重复值,删除缺失值等操作
df = spark.read.csv("data/order.csv", header=True, inferSchema=True)
df.show(5)
'''
+-----------+----------+------+--------+------------+------+--------+--------+
| order_id|order_date|region|province|product_type| price|quantity| profit|
+-----------+----------+------+--------+------------+------+--------+--------+
|10021265709|2010-10-13| 华北| 河北| 办公用品| 38.94| 6| -213.25|
|10021250753|2012-02-20| 华南| 河南| 办公用品| 2.08| 2| -4.64|
|10021257699|2011-07-15| 华南| 广东| 家具产品|107.53| 26| 1054.82|
|10021258358|2011-07-15| 华北| 内蒙古| 家具产品| 70.89| 24|-1748.56|
|10021249836|2011-07-15| 华北| 内蒙古| 数码电子| 7.99| 23| -85.13|
+-----------+----------+------+--------+------------+------+--------+--------+
only showing top 5 rows
'''
1.选取列
# df.select('*').show() # 读取所有字段
# 读取指定字段
# df.select('order_id','region','province','quantity').show(5)
# df['order_id','region','province','quantity'].show(5)
# df[['order_id','region','province','quantity']].show(5)
# df.select(df.order_id,df.region,df.province,df.quantity).show(5)
df.select(df['order_id'],df['region'],df['province'],df['quantity']).show(5)
'''
+-----------+------+--------+--------+
| order_id|region|province|quantity|
+-----------+------+--------+--------+
|10021265709| 华北| 河北| 6|
|10021250753| 华南| 河南| 2|
|10021257699| 华南| 广东| 26|
|10021258358| 华北| 内蒙古| 24|
|10021249836| 华北| 内蒙古| 23|
+-----------+------+--------+--------+
only showing top 5 rows
'''
# 正则表达式读取指定字段
df.select(df.colRegex('`order.*`')).show(5) # 正则表达式前后必须要写 `
'''
+-----------+----------+
| order_id|order_date|
+-----------+----------+
|10021265709|2010-10-13|
|10021250753|2012-02-20|
|10021257699|2011-07-15|
|10021258358|2011-07-15|
|10021249836|2011-07-15|
+-----------+----------+
only showing top 5 rows
'''
2.新增列
# 金额 = 价格 * 数量
df = df.withColumn('amount',df['price']*df['quantity'])
df.show(5)
'''
+-----------+----------+------+--------+------------+------+--------+--------+------------------+--------+
| order_id|order_date|region|province|product_type| price|quantity| profit| amount|discount|
+-----------+----------+------+--------+------------+------+--------+--------+------------------+--------+
|10021265709|2010-10-13| 华北| 河北| 办公用品| 38.94| 6| -213.25| 233.64| 0.5|
|10021250753|2012-02-20| 华南| 河南| 办公用品| 2.08| 2| -4.64| 4.16| 0.5|
|10021257699|2011-07-15| 华南| 广东| 家具产品|107.53| 26| 1054.82| 2795.78| 0.5|
|10021258358|2011-07-15| 华北| 内蒙古| 家具产品| 70.89| 24|-1748.56|1701.3600000000001| 0.5|
|10021249836|2011-07-15| 华北| 内蒙古| 数码电子| 7.99| 23| -85.13| 183.77| 0.5|
+-----------+----------+------+--------+------------+------+--------+--------+------------------+--------+
only showing top 5 rows
'''
# 折扣=0.5,该列的所有值为0.5
from pyspark.sql import functions as f
df = df.withColumn('discount',f.lit(0.5))
df.show(5)
'''
+-----------+----------+------+--------+------------+------+--------+--------+------------------+--------+
| order_id|order_date|region|province|product_type| price|quantity| profit| amount|discount|
+-----------+----------+------+--------+------------+------+--------+--------+------------------+--------+
|10021265709|2010-10-13| 华北| 河北| 办公用品| 38.94| 6| -213.25| 233.64| 0.5|
|10021250753|2012-02-20| 华南| 河南| 办公用品| 2.08| 2| -4.64| 4.16| 0.5|
|10021257699|2011-07-15| 华南| 广东| 家具产品|107.53| 26| 1054.82| 2795.78| 0.5|
|10021258358|2011-07-15| 华北| 内蒙古| 家具产品| 70.89| 24|-1748.56|1701.3600000000001| 0.5|
|10021249836|2011-07-15| 华北| 内蒙古| 数码电子| 7.99| 23| -85.13| 183.77| 0.5|
+-----------+----------+------+--------+------------+------+--------+--------+------------------+--------+
only showing top 5 rows
'''
# 计算折扣金额并预览结果
df.select('amount','discount',df['amount']*df['discount']).show(5)
'''
+------------------+--------+-------------------+
| amount|discount|(amount * discount)|
+------------------+--------+-------------------+
| 233.64| 0.5| 116.82|
| 4.16| 0.5| 2.08|
| 2795.78| 0.5| 1397.89|
|1701.3600000000001| 0.5| 850.6800000000001|
| 183.77| 0.5| 91.885|
+------------------+--------+-------------------+
only showing top 5 rows
'''
3.删除列
df.show(5)
'''
+-----------+----------+------+--------+------------+------+--------+--------+------------------+--------+
| order_id|order_date|region|province|product_type| price|quantity| profit| amount|discount|
+-----------+----------+------+--------+------------+------+--------+--------+------------------+--------+
|10021265709|2010-10-13| 华北| 河北| 办公用品| 38.94| 6| -213.25| 233.64| 0.5|
|10021250753|2012-02-20| 华南| 河南| 办公用品| 2.08| 2| -4.64| 4.16| 0.5|
|10021257699|2011-07-15| 华南| 广东| 家具产品|107.53| 26| 1054.82| 2795.78| 0.5|
|10021258358|2011-07-15| 华北| 内蒙古| 家具产品| 70.89| 24|-1748.56|1701.3600000000001| 0.5|
|10021249836|2011-07-15| 华北| 内蒙古| 数码电子| 7.99| 23| -85.13| 183.77| 0.5|
+-----------+----------+------+--------+------------+------+--------+--------+------------------+--------+
only showing top 5 rows
'''
df.drop('region','product_type').show(5)
'''
+-----------+----------+--------+------+--------+--------+------------------+--------+
| order_id|order_date|province| price|quantity| profit| amount|discount|
+-----------+----------+--------+------+--------+--------+------------------+--------+
|10021265709|2010-10-13| 河北| 38.94| 6| -213.25| 233.64| 0.5|
|10021250753|2012-02-20| 河南| 2.08| 2| -4.64| 4.16| 0.5|
|10021257699|2011-07-15| 广东|107.53| 26| 1054.82| 2795.78| 0.5|
|10021258358|2011-07-15| 内蒙古| 70.89| 24|-1748.56|1701.3600000000001| 0.5|
|10021249836|2011-07-15| 内蒙古| 7.99| 23| -85.13| 183.77| 0.5|
+-----------+----------+--------+------+--------+--------+------------------+--------+
only showing top 5 rows
'''
4.重命名列
# inplace=True (pandas 的 rename), spark没有该参数
df.withColumnRenamed('product_type','category').show(5) # 一次只能改一个
'''
+-----------+----------+------+--------+--------+------+--------+--------+------------------+--------+
| order_id|order_date|region|province|category| price|quantity| profit| amount|discount|
+-----------+----------+------+--------+--------+------+--------+--------+------------------+--------+
|10021265709|2010-10-13| 华北| 河北|办公用品| 38.94| 6| -213.25| 233.64| 0.5|
|10021250753|2012-02-20| 华南| 河南|办公用品| 2.08| 2| -4.64| 4.16| 0.5|
|10021257699|2011-07-15| 华南| 广东|家具产品|107.53| 26| 1054.82| 2795.78| 0.5|
|10021258358|2011-07-15| 华北| 内蒙古|家具产品| 70.89| 24|-1748.56|1701.3600000000001| 0.5|
|10021249836|2011-07-15| 华北| 内蒙古|数码电子| 7.99| 23| -85.13| 183.77| 0.5|
+-----------+----------+------+--------+--------+------+--------+--------+------------------+--------+
only showing top 5 rows
'''
# 重命名多个字段
df.toDF('订单编号','订单日期','区域','省份','产品类型','价格','数量','利润','金额','折扣').show(5)
'''
+-----------+----------+----+------+--------+------+----+--------+------------------+----+
| 订单编号| 订单日期|区域| 省份|产品类型| 价格|数量| 利润| 金额|折扣|
+-----------+----------+----+------+--------+------+----+--------+------------------+----+
|10021265709|2010-10-13|华北| 河北|办公用品| 38.94| 6| -213.25| 233.64| 0.5|
|10021250753|2012-02-20|华南| 河南|办公用品| 2.08| 2| -4.64| 4.16| 0.5|
|10021257699|2011-07-15|华南| 广东|家具产品|107.53| 26| 1054.82| 2795.78| 0.5|
|10021258358|2011-07-15|华北|内蒙古|家具产品| 70.89| 24|-1748.56|1701.3600000000001| 0.5|
|10021249836|2011-07-15|华北|内蒙古|数码电子| 7.99| 23| -85.13| 183.77| 0.5|
+-----------+----------+----+------+--------+------+----+--------+------------------+----+
only showing top 5 rows
'''
5.重命名表
df_new = df
df_new.show(5)
'''
+-----------+----------+------+--------+------------+------+--------+--------+------------------+--------+
| order_id|order_date|region|province|product_type| price|quantity| profit| amount|discount|
+-----------+----------+------+--------+------------+------+--------+--------+------------------+--------+
|10021265709|2010-10-13| 华北| 河北| 办公用品| 38.94| 6| -213.25| 233.64| 0.5|
|10021250753|2012-02-20| 华南| 河南| 办公用品| 2.08| 2| -4.64| 4.16| 0.5|
|10021257699|2011-07-15| 华南| 广东| 家具产品|107.53| 26| 1054.82| 2795.78| 0.5|
|10021258358|2011-07-15| 华北| 内蒙古| 家具产品| 70.89| 24|-1748.56|1701.3600000000001| 0.5|
|10021249836|2011-07-15| 华北| 内蒙古| 数码电子| 7.99| 23| -85.13| 183.77| 0.5|
+-----------+----------+------+--------+------------+------+--------+--------+------------------+--------+
only showing top 5 rows
'''
6.排序
- 一列排序
# sort 或 orderBy
df.sort(df['order_date'].desc()).show(5)
df.orderBy(df['region'].asc()).show(5)
'''
+-----------+----------+------+--------+------------+------+--------+------+------+--------+
| order_id|order_date|region|province|product_type| price|quantity|profit|amount|discount|
+-----------+----------+------+--------+------------+------+--------+------+------+--------+
|10021585147|2012-12-30| 华南| 广东| 办公用品| 7.28| 37|-18.66|269.36| 0.5|
|10021515764|2012-12-30| 华北| 内蒙古| 家具产品| 13.73| 45|-33.47|617.85| 0.5|
|10021338256|2012-12-30| 华东| 浙江| 办公用品| 1.48| 10| -1.29| 14.8| 0.5|
|10021340583|2012-12-30| 东北| 辽宁| 数码电子| 19.98| 31| 27.85|619.38| 0.5|
|10021673269|2012-12-30| 东北| 辽宁| 办公用品|832.81| 1|-745.2|832.81| 0.5|
+-----------+----------+------+--------+------------+------+--------+------+------+--------+
only showing top 5 rows
+-----------+----------+------+--------+------------+------+--------+-------+-----------------+--------+
| order_id|order_date|region|province|product_type| price|quantity| profit| amount|discount|
+-----------+----------+------+--------+------------+------+--------+-------+-----------------+--------+
|10021256099|2010-12-28| 东北| 辽宁| 办公用品| 6.54| 33| -55.11| 215.82| 0.5|
|10021268757|2009-06-13| 东北| 吉林| 数码电子| 85.99| 16|-172.55| 1375.84| 0.5|
|10021255969|2010-06-28| 东北| 辽宁| 数码电子|140.99| 47|1680.79|6626.530000000001| 0.5|
|10021253491|2011-07-15| 东北| 辽宁| 数码电子| 8.46| 15|-128.38| 126.9| 0.5|
|10021255756|2009-05-16| 东北| 辽宁| 办公用品| 5.4| 25|-136.25| 135.0| 0.5|
+-----------+----------+------+--------+------------+------+--------+-------+-----------------+--------+
only showing top 5 rows
'''
- 多列排序
# df.sort(df['region'].asc(),df['order_date'].desc()).show(5)
# df.orderBy(df['region'].asc(),df['order_date'].desc()).show(5)
df.orderBy(['region','order_date'],ascending=[True,False]).show(5)
'''
+-----------+----------+------+--------+------------+------+--------+------+------------------+--------+
| order_id|order_date|region|province|product_type| price|quantity|profit| amount|discount|
+-----------+----------+------+--------+------------+------+--------+------+------------------+--------+
|10021673269|2012-12-30| 东北| 辽宁| 办公用品|832.81| 1|-745.2| 832.81| 0.5|
|10021340583|2012-12-30| 东北| 辽宁| 数码电子| 19.98| 31| 27.85| 619.38| 0.5|
|10021280768|2012-12-24| 东北| 吉林| 办公用品| 6.81| 7|-21.38|47.669999999999995| 0.5|
|10021386342|2012-12-21| 东北| 辽宁| 数码电子|145.45| 17| 43.03|2472.6499999999996| 0.5|
|10021421171|2012-12-19| 东北| 辽宁| 办公用品| 6.23| 25|-91.28| 155.75| 0.5|
+-----------+----------+------+--------+------------+------+--------+------+------------------+--------+
only showing top 5 rows
'''
7.替换
df.show(5)
'''
+-----------+----------+------+--------+------------+------+--------+--------+------------------+--------+
| order_id|order_date|region|province|product_type| price|quantity| profit| amount|discount|
+-----------+----------+------+--------+------------+------+--------+--------+------------------+--------+
|10021265709|2010-10-13| 华北| 河北| 办公用品| 38.94| 6| -213.25| 233.64| 0.5|
|10021250753|2012-02-20| 华南| 河南| 办公用品| 2.08| 2| -4.64| 4.16| 0.5|
|10021257699|2011-07-15| 华南| 广东| 家具产品|107.53| 26| 1054.82| 2795.78| 0.5|
|10021258358|2011-07-15| 华北| 内蒙古| 家具产品| 70.89| 24|-1748.56|1701.3600000000001| 0.5|
|10021249836|2011-07-15| 华北| 内蒙古| 数码电子| 7.99| 23| -85.13| 183.77| 0.5|
+-----------+----------+------+--------+------------+------+--------+--------+------------------+--------+
only showing top 5 rows
'''
dct = {'办公用品':'办公','家具产品':'家具','数码电子':'数码'}
df.replace(to_replace=dct,subset='product_type').show(5)
'''
+-----------+----------+------+--------+------------+------+--------+--------+------------------+--------+
| order_id|order_date|region|province|product_type| price|quantity| profit| amount|discount|
+-----------+----------+------+--------+------------+------+--------+--------+------------------+--------+
|10021265709|2010-10-13| 华北| 河北| 办公| 38.94| 6| -213.25| 233.64| 0.5|
|10021250753|2012-02-20| 华南| 河南| 办公| 2.08| 2| -4.64| 4.16| 0.5|
|10021257699|2011-07-15| 华南| 广东| 家具|107.53| 26| 1054.82| 2795.78| 0.5|
|10021258358|2011-07-15| 华北| 内蒙古| 家具| 70.89| 24|-1748.56|1701.3600000000001| 0.5|
|10021249836|2011-07-15| 华北| 内蒙古| 数码| 7.99| 23| -85.13| 183.77| 0.5|
+-----------+----------+------+--------+------------+------+--------+--------+------------------+--------+
only showing top 5 rows
'''
# 将办公用品 和 家具产品 替换为 办公和家具
lst = ['办公用品','家具产品']
df.replace(to_replace=lst,value='办公和家具',subset='product_type').show(5)
'''
+-----------+----------+------+--------+------------+------+--------+--------+------------------+--------+
| order_id|order_date|region|province|product_type| price|quantity| profit| amount|discount|
+-----------+----------+------+--------+------------+------+--------+--------+------------------+--------+
|10021265709|2010-10-13| 华北| 河北| 办公和家具| 38.94| 6| -213.25| 233.64| 0.5|
|10021250753|2012-02-20| 华南| 河南| 办公和家具| 2.08| 2| -4.64| 4.16| 0.5|
|10021257699|2011-07-15| 华南| 广东| 办公和家具|107.53| 26| 1054.82| 2795.78| 0.5|
|10021258358|2011-07-15| 华北| 内蒙古| 办公和家具| 70.89| 24|-1748.56|1701.3600000000001| 0.5|
|10021249836|2011-07-15| 华北| 内蒙古| 数码电子| 7.99| 23| -85.13| 183.77| 0.5|
+-----------+----------+------+--------+------------+------+--------+--------+------------------+--------+
only showing top 5 rows
'''
8.删除空值
# df.na.drop()
# any 或
# 如两列均为空值删除整行 all 与
# df.dropna(how='all',subset=['region','province']).show(5)
# 如两列其中一列为空值,则删除整行
df.dropna(how='any',subset=['region','province']).show(5)
'''
+-----------+----------+------+--------+------------+------+--------+--------+------------------+--------+
| order_id|order_date|region|province|product_type| price|quantity| profit| amount|discount|
+-----------+----------+------+--------+------------+------+--------+--------+------------------+--------+
|10021265709|2010-10-13| 华北| 河北| 办公用品| 38.94| 6| -213.25| 233.64| 0.5|
|10021250753|2012-02-20| 华南| 河南| 办公用品| 2.08| 2| -4.64| 4.16| 0.5|
|10021257699|2011-07-15| 华南| 广东| 家具产品|107.53| 26| 1054.82| 2795.78| 0.5|
|10021258358|2011-07-15| 华北| 内蒙古| 家具产品| 70.89| 24|-1748.56|1701.3600000000001| 0.5|
|10021249836|2011-07-15| 华北| 内蒙古| 数码电子| 7.99| 23| -85.13| 183.77| 0.5|
+-----------+----------+------+--------+------------+------+--------+--------+------------------+--------+
only showing top 5 rows
'''
9.填充空值
# df.na.fill()
df.fillna(value=0,subset='profit').show(5)
'''
+-----------+----------+------+--------+------------+------+--------+--------+------------------+--------+
| order_id|order_date|region|province|product_type| price|quantity| profit| amount|discount|
+-----------+----------+------+--------+------------+------+--------+--------+------------------+--------+
|10021265709|2010-10-13| 华北| 河北| 办公用品| 38.94| 6| -213.25| 233.64| 0.5|
|10021250753|2012-02-20| 华南| 河南| 办公用品| 2.08| 2| -4.64| 4.16| 0.5|
|10021257699|2011-07-15| 华南| 广东| 家具产品|107.53| 26| 1054.82| 2795.78| 0.5|
|10021258358|2011-07-15| 华北| 内蒙古| 家具产品| 70.89| 24|-1748.56|1701.3600000000001| 0.5|
|10021249836|2011-07-15| 华北| 内蒙古| 数码电子| 7.99| 23| -85.13| 183.77| 0.5|
+-----------+----------+------+--------+------------+------+--------+--------+------------------+--------+
only showing top 5 rows
'''
10.删除重复值
# drop_duplicates 或者 dropDuplicates
df.drop_duplicates().show(5) # 根据所有字段,删除重复行
'''
+-----------+----------+------+--------+------------+------+--------+-------+-------+--------+
| order_id|order_date|region|province|product_type| price|quantity| profit| amount|discount|
+-----------+----------+------+--------+------------+------+--------+-------+-------+--------+
|10021278668|2010-01-26| 华北| 山西| 办公用品| 17.7| 47|-131.27| 831.9| 0.5|
|10021374233|2010-03-28| 东北| 辽宁| 家具产品|209.37| 47|-505.98|9840.39| 0.5|
|10021426866|2009-04-09| 华南| 广西| 数码电子| 40.98| 26|-127.11|1065.48| 0.5|
|10021256790|2010-03-05| 华北| 北京| 办公用品| 30.98| 15| 117.39| 464.7| 0.5|
|10021251867|2011-08-16| 西北| 宁夏| 数码电子| 50.98| 34| -82.16|1733.32| 0.5|
+-----------+----------+------+--------+------------+------+--------+-------+-------+--------+
only showing top 5 rows
'''
# 根据指定字段删除重复行
df.drop_duplicates(subset=['order_id','region']).show(5)
'''
+-----------+----------+------+--------+------------+------+--------+-------+-----------------+--------+
| order_id|order_date|region|province|product_type| price|quantity| profit| amount|discount|
+-----------+----------+------+--------+------------+------+--------+-------+-----------------+--------+
|10021248927|2010-08-02| 华南| 广东| 办公用品| 46.89| 12| 148.34|562.6800000000001| 0.5|
|10021248932|2010-10-02| 华北| 河北| 办公用品| 8.04| 23|-117.16| 184.92| 0.5|
|10021250042|2010-12-14| 华南| 广西| 数码电子| 20.95| 11| -68.76| 230.45| 0.5|
|10021251252|2012-08-01| 华南| 海南| 家具产品| 4.95| 34| -59.71| 168.3| 0.5|
|10021252488|2011-02-15| 华北| 山西| 数码电子|119.99| 39| 239.41| 4679.61| 0.5|
+-----------+----------+------+--------+------------+------+--------+-------+-----------------+--------+
only showing top 5 rows
'''
11.转换字段数据类型
- “价格”转换为整型,“数量”转换为浮点型
from pyspark.sql import functions as f
from pyspark.sql import types as t
df.show(3)
'''
+-----------+----------+------+--------+------------+------+--------+-------+-------+--------+
| order_id|order_date|region|province|product_type| price|quantity| profit| amount|discount|
+-----------+----------+------+--------+------------+------+--------+-------+-------+--------+
|10021265709|2010-10-13| 华北| 河北| 办公用品| 38.94| 6|-213.25| 233.64| 0.5|
|10021250753|2012-02-20| 华南| 河南| 办公用品| 2.08| 2| -4.64| 4.16| 0.5|
|10021257699|2011-07-15| 华南| 广东| 家具产品|107.53| 26|1054.82|2795.78| 0.5|
+-----------+----------+------+--------+------------+------+--------+-------+-------+--------+
only showing top 3 rows
'''
df.select(
df['price'].astype(t.IntegerType()),
df['quantity'].astype(t.FloatType())
).show(5)
# df.select(
# df['price'].cast(t.IntegerType()),
# df['quantity'].cast(t.FloatType())
# ).show(5)
# df.select(
# f.col('price').astype(t.IntegerType()),
# f.col('quantity').astype(t.FloatType())
# ).show(5)
'''
+-----+--------+
|price|quantity|
+-----+--------+
| 38| 6.0|
| 2| 2.0|
| 107| 26.0|
| 70| 24.0|
| 7| 23.0|
+-----+--------+
only showing top 5 rows
'''
12.转换DataFrame格式
- 将spark的df转换为pandas的df
pd_df = df.toPandas()
pd_df.head(5)
pd_df.groupby('region').agg({'price':'mean','quantity':'sum'}).reset_index()

- 将spark的df转换为json
# 如报错则再次运行
df.toJSON().take(1)
'''
['{"order_id":10021265709,"order_date":"2010-10-13","region":"华北","province":"河北","product_type":"办公用品","price":38.94,"quantity":6,"profit":-213.25,"amount":233.64,"discount":0.5}']
'''
- 将spark的df转换为python迭代器
it = df.toLocalIterator()
# 迭代器可以记住便利的位置,只能向前访问不能后退,直到所有元素访问完毕为止
import time
for row in it:
print(row)
time.sleep(3)
3、类SQL的统计操作
df = spark.read.csv("data/order.csv", header=True, inferSchema=True)
df.show(5)
'''
+-----------+----------+------+--------+------------+------+--------+--------+
| order_id|order_date|region|province|product_type| price|quantity| profit|
+-----------+----------+------+--------+------------+------+--------+--------+
|10021265709|2010-10-13| 华北| 河北| 办公用品| 38.94| 6| -213.25|
|10021250753|2012-02-20| 华南| 河南| 办公用品| 2.08| 2| -4.64|
|10021257699|2011-07-15| 华南| 广东| 家具产品|107.53| 26| 1054.82|
|10021258358|2011-07-15| 华北| 内蒙古| 家具产品| 70.89| 24|-1748.56|
|10021249836|2011-07-15| 华北| 内蒙古| 数码电子| 7.99| 23| -85.13|
+-----------+----------+------+--------+------------+------+--------+--------+
only showing top 5 rows
'''
1.聚合计算
# 整表聚合计算
df.agg({'price':'max','quantity':'sum'}).show()
# 聚合计算后重命名
df.agg({'price':'max','quantity':'sum'}).withColumnRenamed('sum(quantity)','sum_quantity').withColumnRenamed('max(price)','max_price').show()
'''
+-------------+----------+
|sum(quantity)|max(price)|
+-------------+----------+
| 218830| 6783.02|
+-------------+----------+
+------------+---------+
|sum_quantity|max_price|
+------------+---------+
| 218830| 6783.02|
+------------+---------+
'''
2.描述统计
df.show(3)
'''
+-----------+----------+------+--------+------------+------+--------+-------+
| order_id|order_date|region|province|product_type| price|quantity| profit|
+-----------+----------+------+--------+------------+------+--------+-------+
|10021265709|2010-10-13| 华北| 河北| 办公用品| 38.94| 6|-213.25|
|10021250753|2012-02-20| 华南| 河南| 办公用品| 2.08| 2| -4.64|
|10021257699|2011-07-15| 华南| 广东| 家具产品|107.53| 26|1054.82|
+-----------+----------+------+--------+------------+------+--------+-------+
only showing top 3 rows
'''
# describe
df.select('price','quantity','profit').describe().show()
# summary
df.select('price','quantity','profit').summary().show()
'''
+-------+------------------+------------------+------------------+
|summary| price| quantity| profit|
+-------+------------------+------------------+------------------+
| count| 8567| 8567| 8567|
| mean| 88.39652153612401| 25.54336407143691|180.81604062098822|
| stddev|279.10699118992653|14.488305686423686| 1180.476274473487|
| min| 0.99| 1| -14140.7|
| max| 6783.02| 50| 27220.69|
+-------+------------------+------------------+------------------+
+-------+------------------+------------------+------------------+
|summary| price| quantity| profit|
+-------+------------------+------------------+------------------+
| count| 8567| 8567| 8567|
| mean| 88.39652153612401| 25.54336407143691|180.81604062098822|
| stddev|279.10699118992653|14.488305686423686| 1180.476274473487|
| min| 0.99| 1| -14140.7|
| 25%| 6.48| 13| -83.54|
| 50%| 20.99| 26| -1.57|
| 75%| 89.83| 38| 162.11|
| max| 6783.02| 50| 27220.69|
+-------+------------------+------------------+------------------+
'''
3.频数统计
# 查看某字段超过指定频率的类别
# 频率超过60%的省份和销量
# df.stat.freqItems
df.freqItems(cols=['province','quantity'],support=0.6).show()
'''
+------------------+------------------+
|province_freqItems|quantity_freqItems|
+------------------+------------------+
| [广东]| [20]|
+------------------+------------------+
'''
4.分位数
# col 统计字段
# probabilities 概率, 0-1, 必须浮点数,求多个分位数时传递列表或元组
# relativeError 相对误差, 浮点数, 0.0表示精度计算
# df.stat.approxQuantile
df.approxQuantile('price', [0.0, 0.5, 1.0], 0.0) # 该函数返回列表
# [0.99, 20.99, 6783.02]
5.协方差

- 求数量与利润的协方差
# 如果x变大,y也变大,说明这两个变量为同向变化关系,则协方差为正数
# 如果x变大,y也变小,说明这两个变量为同向变化关系,则协方差为负数
# 如果x与y的协方差为零,那么两个变量无相关
# x\y\z
# x与y相关性强还是x与z相关性强?
# 如果x、y、z变量的量纲一致,那么可以通过他们之间的协方差来判断相关性强弱
# 如果x、y、z变量的量纲不一致,那么不可以通过他们之间的协方差来判断相关性强弱
pd_df = df.toPandas()
x = pd_df['quantity']
y = pd_df['profit']
n = len(pd_df) # 样本容量
x_dev = x - x.mean() # 与均值的偏差
y_dev = y - y.mean() # 与均值的偏差
# 样本协方差
cov = (x_dev * y_dev).sum() / (n - 1)
cov
# 3286.2303760108925
pd_df[['quantity','profit','price']].cov()

# pandas 方法求两个字段的协方差
pd_df['quantity'].cov(pd_df['profit'])
# 3286.230376010893
# spark 方法求两个字段的协方差
df.cov('quantity','profit')
# 3286.2303760108866
6.相关系数
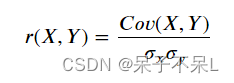
- 求数量与利润的相关系数
pd_df = df.toPandas()
x = pd_df['quantity']
y = pd_df['profit']
corr = x.cov(y) / (x.std() * y.std())
corr # 相关系数
corr = x.corr(y)
corr
# 0.19214236955780314
# pandas 方法求相关系数矩阵
pd_df[['quantity','profit','price']].corr()

# spark 方法求相关系数
df.corr('quantity','profit')
# 0.19214236955780292
7.集合运算
df1 = spark.createDataFrame(
data=[("a", 1),
("a", 1),
("a", 1),
("a", 2),
("b", 3),
("c", 4)],
schema=["C1", "C2"])
df2 = spark.createDataFrame(
data=[("a", 1),
("a", 1),
("b", 3)],
schema=["C1", "C2"])
- 差集
df1.exceptAll(df2).show() # 不去重
df1.subtract(df2).show() # 去重
'''
+---+---+
| C1| C2|
+---+---+
| a| 1|
| a| 2|
| c| 4|
+---+---+
+---+---+
| C1| C2|
+---+---+
| a| 2|
| c| 4|
+---+---+
'''
- 交集
df1.intersectAll(df2).show() # 不去重
df1.intersect(df2).show() # 去重
'''
+---+---+
| C1| C2|
+---+---+
| b| 3|
| a| 1|
| a| 1|
+---+---+
+---+---+
| C1| C2|
+---+---+
| b| 3|
| a| 1|
+---+---+
'''
- 并集
# unionALL 等价于 union
df1.unionAll(df2).show() # 不去重
df1.union(df2).show() # 不去重
df1.union(df2).distinct().show() # 去重
'''
+---+---+
| C1| C2|
+---+---+
| a| 1|
| a| 1|
| a| 1|
| a| 2|
| b| 3|
| c| 4|
| a| 1|
| a| 1|
| b| 3|
+---+---+
+---+---+
| C1| C2|
+---+---+
| a| 1|
| a| 1|
| a| 1|
| a| 2|
| b| 3|
| c| 4|
| a| 1|
| a| 1|
| b| 3|
+---+---+
+---+---+
| C1| C2|
+---+---+
| b| 3|
| a| 1|
| a| 2|
| c| 4|
+---+---+
'''
8.随机抽样
df.show(5)
'''
+-----------+----------+------+--------+------------+------+--------+--------+
| order_id|order_date|region|province|product_type| price|quantity| profit|
+-----------+----------+------+--------+------------+------+--------+--------+
|10021265709|2010-10-13| 华北| 河北| 办公用品| 38.94| 6| -213.25|
|10021250753|2012-02-20| 华南| 河南| 办公用品| 2.08| 2| -4.64|
|10021257699|2011-07-15| 华南| 广东| 家具产品|107.53| 26| 1054.82|
|10021258358|2011-07-15| 华北| 内蒙古| 家具产品| 70.89| 24|-1748.56|
|10021249836|2011-07-15| 华北| 内蒙古| 数码电子| 7.99| 23| -85.13|
+-----------+----------+------+--------+------------+------+--------+--------+
only showing top 5 rows
'''
# wsamplelacement 是否放回抽样
# fraction 抽样比例
# seed 随机种子
df.sample(fraction=0.5, seed=2).show(5)
'''
+-----------+----------+------+--------+------------+------+--------+--------+
| order_id|order_date|region|province|product_type| price|quantity| profit|
+-----------+----------+------+--------+------------+------+--------+--------+
|10021250753|2012-02-20| 华南| 河南| 办公用品| 2.08| 2| -4.64|
|10021257699|2011-07-15| 华南| 广东| 家具产品|107.53| 26| 1054.82|
|10021258358|2011-07-15| 华北| 内蒙古| 家具产品| 70.89| 24|-1748.56|
|10021253491|2011-07-15| 东北| 辽宁| 数码电子| 8.46| 15| -128.38|
|10021266565|2011-10-22| 东北| 吉林| 办公用品| 9.11| 30| 60.72|
+-----------+----------+------+--------+------------+------+--------+--------+
only showing top 5 rows
'''
9.随机拆分
# 7 3 开 ; 4 6 开
# 按照权重(比例)随即拆分数据,返回列表
df_split = df.randomSplit([0.3,0.7],seed=1)
df_split
'''
[DataFrame[order_id: bigint, order_date: string, region: string, province: string, product_type: string, price: double, quantity: int, profit: double],
DataFrame[order_id: bigint, order_date: string, region: string, province: string, product_type: string, price: double, quantity: int, profit: double]]
'''
df_split[0].show(5) # 第一部分数据 占比30%
df_split[1].show(5) # 第二部分数据 占比70%
'''
+-----------+----------+------+--------+------------+-----+--------+-------+
| order_id|order_date|region|province|product_type|price|quantity| profit|
+-----------+----------+------+--------+------------+-----+--------+-------+
|10021247897|2011-02-11| 西南| 四川| 家具产品| 8.75| 10| -16.49|
|10021247909|2010-05-19| 华南| 广东| 办公用品| 3.57| 46|-119.35|
|10021248082|2010-07-24| 华北| 山西| 办公用品| 5.98| 48|-193.48|
|10021248110|2012-02-15| 华东| 福建| 办公用品| 3.78| 28| 46.3|
|10021248134|2010-02-17| 华北| 山西| 办公用品| 4.98| 18| -33.4|
+-----------+----------+------+--------+------------+-----+--------+-------+
only showing top 5 rows
+-----------+----------+------+--------+------------+------+--------+-------+
| order_id|order_date|region|province|product_type| price|quantity| profit|
+-----------+----------+------+--------+------------+------+--------+-------+
|10021247874|2012-03-10| 华南| 河南| 家具产品|136.98| 14| 761.04|
|10021247876|2010-03-02| 华东| 安徽| 数码电子| 45.99| 29| 218.73|
|10021247974|2010-07-16| 华南| 河南| 数码电子|179.99| 35|1142.08|
|10021248074|2012-04-04| 华北| 山西| 家具产品| 7.28| 49|-197.25|
|10021248111|2009-02-12| 华北| 北京| 办公用品| 12.53| 1| -20.32|
+-----------+----------+------+--------+------------+------+--------+-------+
only showing top 5 rows
'''
df_split[0].count() # 第一部分数据量
# 2068
df_split[1].count() # 第二部分数据量
# 5959
4、类SQL的表操作
1.表查询
df = spark.read.csv("data/order.csv", header=True, inferSchema=True)
df.show(5)
'''
+-----------+----------+------+--------+------------+------+--------+--------+
| order_id|order_date|region|province|product_type| price|quantity| profit|
+-----------+----------+------+--------+------------+------+--------+--------+
|10021265709|2010-10-13| 华北| 河北| 办公用品| 38.94| 6| -213.25|
|10021250753|2012-02-20| 华南| 河南| 办公用品| 2.08| 2| -4.64|
|10021257699|2011-07-15| 华南| 广东| 家具产品|107.53| 26| 1054.82|
|10021258358|2011-07-15| 华北| 内蒙古| 家具产品| 70.89| 24|-1748.56|
|10021249836|2011-07-15| 华北| 内蒙古| 数码电子| 7.99| 23| -85.13|
+-----------+----------+------+--------+------------+------+--------+--------+
only showing top 5 rows
'''
- distinct去重
df.distinct().show(5)
df.distinct().count() # 8567
'''
+-----------+----------+------+--------+------------+-------+--------+-------+
| order_id|order_date|region|province|product_type| price|quantity| profit|
+-----------+----------+------+--------+------------+-------+--------+-------+
|10021285407|2009-04-02| 华北| 天津| 办公用品| 47.9| 11| 144.05|
|10021319881|2009-01-07| 华东| 浙江| 数码电子|6783.02| 7| 102.61|
|10021347280|2010-01-09| 西北| 甘肃| 数码电子| 500.98| 32|7176.12|
|10021377672|2010-06-08| 东北| 黑龙江| 办公用品| 15.67| 50| 353.2|
|10021293479|2011-04-20| 华北| 天津| 家具产品| 320.64| 12| 104.48|
+-----------+----------+------+--------+------------+-------+--------+-------+
only showing top 5 rows
'''
df.select('region').distinct().count()
# 6
- limit限制行数
df.select('order_id','order_date').limit(2).show()
'''
+-----------+----------+
| order_id|order_date|
+-----------+----------+
|10021265709|2010-10-13|
|10021250753|2012-02-20|
+-----------+----------+
'''
- where筛选
df.where("product_type='办公用品' and quantity > 10").show(5)
'''
+-----------+----------+------+--------+------------+-----+--------+------+
| order_id|order_date|region|province|product_type|price|quantity|profit|
+-----------+----------+------+--------+------------+-----+--------+------+
|10021266565|2011-10-22| 东北| 吉林| 办公用品| 9.11| 30| 60.72|
|10021251834|2009-01-19| 华北| 北京| 办公用品| 2.88| 41| 7.57|
|10021255693|2009-06-03| 华南| 广东| 办公用品| 1.68| 28| 0.35|
|10021253900|2010-12-17| 华南| 广东| 办公用品| 1.86| 48|-107.0|
|10021262933|2010-01-28| 西南| 四川| 办公用品| 2.89| 26| 28.24|
+-----------+----------+------+--------+------------+-----+--------+------+
only showing top 5 rows
'''
# pandas 写法
df.where((df['product_type']=='办公用品') & (df['quantity'] > 10)).show(5)
'''
+-----------+----------+------+--------+------------+-----+--------+------+
| order_id|order_date|region|province|product_type|price|quantity|profit|
+-----------+----------+------+--------+------------+-----+--------+------+
|10021266565|2011-10-22| 东北| 吉林| 办公用品| 9.11| 30| 60.72|
|10021251834|2009-01-19| 华北| 北京| 办公用品| 2.88| 41| 7.57|
|10021255693|2009-06-03| 华南| 广东| 办公用品| 1.68| 28| 0.35|
|10021253900|2010-12-17| 华南| 广东| 办公用品| 1.86| 48|-107.0|
|10021262933|2010-01-28| 西南| 四川| 办公用品| 2.89| 26| 28.24|
+-----------+----------+------+--------+------------+-----+--------+------+
only showing top 5 rows
'''
df.where("region in ('华南','华北') and price > 100").show(5)
'''
+-----------+----------+------+--------+------------+------+--------+-------+
| order_id|order_date|region|province|product_type| price|quantity| profit|
+-----------+----------+------+--------+------------+------+--------+-------+
|10021257699|2011-07-15| 华南| 广东| 家具产品|107.53| 26|1054.82|
|10021263127|2011-10-22| 华南| 湖北| 数码电子|155.99| 14| 48.99|
|10021248211|2011-03-17| 华南| 广西| 数码电子|115.79| 32| 1470.3|
|10021265473|2010-12-17| 华北| 北京| 数码电子|205.99| 46|2057.17|
|10021248412|2009-04-16| 华北| 北京| 数码电子|125.99| 37|1228.89|
+-----------+----------+------+--------+------------+------+--------+-------+
only showing top 5 rows
'''
df.where((df['region'].isin(['华南','华北'])) & (df['price'] > 100)).show(5)
'''
+-----------+----------+------+--------+------------+------+--------+-------+
| order_id|order_date|region|province|product_type| price|quantity| profit|
+-----------+----------+------+--------+------------+------+--------+-------+
|10021257699|2011-07-15| 华南| 广东| 家具产品|107.53| 26|1054.82|
|10021263127|2011-10-22| 华南| 湖北| 数码电子|155.99| 14| 48.99|
|10021248211|2011-03-17| 华南| 广西| 数码电子|115.79| 32| 1470.3|
|10021265473|2010-12-17| 华北| 北京| 数码电子|205.99| 46|2057.17|
|10021248412|2009-04-16| 华北| 北京| 数码电子|125.99| 37|1228.89|
+-----------+----------+------+--------+------------+------+--------+-------+
only showing top 5 rows
'''
# like 通配符筛选
df.where("province like '湖%'").show(5)
'''
+-----------+----------+------+--------+------------+------+--------+-------+
| order_id|order_date|region|province|product_type| price|quantity| profit|
+-----------+----------+------+--------+------------+------+--------+-------+
|10021263127|2011-10-22| 华南| 湖北| 数码电子|155.99| 14| 48.99|
|10021258830|2012-03-18| 华南| 湖北| 数码电子|155.99| 20| 257.76|
|10021248282|2011-08-20| 华南| 湖南| 数码电子| 65.99| 22|-284.63|
|10021264036|2011-03-04| 华南| 湖北| 办公用品| 34.58| 29| 109.33|
|10021250947|2012-06-20| 华南| 湖北| 家具产品|227.55| 48|1836.81|
+-----------+----------+------+--------+------------+------+--------+-------+
only showing top 5 rows
'''
df.where(df['province'].like('湖%')).show(5)
'''
+-----------+----------+------+--------+------------+------+--------+-------+
| order_id|order_date|region|province|product_type| price|quantity| profit|
+-----------+----------+------+--------+------------+------+--------+-------+
|10021263127|2011-10-22| 华南| 湖北| 数码电子|155.99| 14| 48.99|
|10021258830|2012-03-18| 华南| 湖北| 数码电子|155.99| 20| 257.76|
|10021248282|2011-08-20| 华南| 湖南| 数码电子| 65.99| 22|-284.63|
|10021264036|2011-03-04| 华南| 湖北| 办公用品| 34.58| 29| 109.33|
|10021250947|2012-06-20| 华南| 湖北| 家具产品|227.55| 48|1836.81|
+-----------+----------+------+--------+------------+------+--------+-------+
only showing top 5 rows
'''
# rlike 正则表达式筛选
df.where("province rlike '湖北|湖南'").show(5)
df.where(df['province'].rlike('湖北|湖南')).show(5)
'''
+-----------+----------+------+--------+------------+------+--------+-------+
| order_id|order_date|region|province|product_type| price|quantity| profit|
+-----------+----------+------+--------+------------+------+--------+-------+
|10021263127|2011-10-22| 华南| 湖北| 数码电子|155.99| 14| 48.99|
|10021258830|2012-03-18| 华南| 湖北| 数码电子|155.99| 20| 257.76|
|10021248282|2011-08-20| 华南| 湖南| 数码电子| 65.99| 22|-284.63|
|10021264036|2011-03-04| 华南| 湖北| 办公用品| 34.58| 29| 109.33|
|10021250947|2012-06-20| 华南| 湖北| 家具产品|227.55| 48|1836.81|
+-----------+----------+------+--------+------------+------+--------+-------+
only showing top 5 rows
+-----------+----------+------+--------+------------+------+--------+-------+
| order_id|order_date|region|province|product_type| price|quantity| profit|
+-----------+----------+------+--------+------------+------+--------+-------+
|10021263127|2011-10-22| 华南| 湖北| 数码电子|155.99| 14| 48.99|
|10021258830|2012-03-18| 华南| 湖北| 数码电子|155.99| 20| 257.76|
|10021248282|2011-08-20| 华南| 湖南| 数码电子| 65.99| 22|-284.63|
|10021264036|2011-03-04| 华南| 湖北| 办公用品| 34.58| 29| 109.33|
|10021250947|2012-06-20| 华南| 湖北| 家具产品|227.55| 48|1836.81|
+-----------+----------+------+--------+------------+------+--------+-------+
only showing top 5 rows
'''
# 广播变量筛选
bc = sc.broadcast(['华南','华北'])
df.where(df['region'].isin(bc.value)).show(5)
# 过滤掉 华南 华北
df.where(~df['region'].isin(bc.value)).show(5)
'''
+-----------+----------+------+--------+------------+------+--------+--------+
| order_id|order_date|region|province|product_type| price|quantity| profit|
+-----------+----------+------+--------+------------+------+--------+--------+
|10021265709|2010-10-13| 华北| 河北| 办公用品| 38.94| 6| -213.25|
|10021250753|2012-02-20| 华南| 河南| 办公用品| 2.08| 2| -4.64|
|10021257699|2011-07-15| 华南| 广东| 家具产品|107.53| 26| 1054.82|
|10021258358|2011-07-15| 华北| 内蒙古| 家具产品| 70.89| 24|-1748.56|
|10021249836|2011-07-15| 华北| 内蒙古| 数码电子| 7.99| 23| -85.13|
+-----------+----------+------+--------+------------+------+--------+--------+
only showing top 5 rows
+-----------+----------+------+--------+------------+-----+--------+-------+
| order_id|order_date|region|province|product_type|price|quantity| profit|
+-----------+----------+------+--------+------------+-----+--------+-------+
|10021253491|2011-07-15| 东北| 辽宁| 数码电子| 8.46| 15|-128.38|
|10021266565|2011-10-22| 东北| 吉林| 办公用品| 9.11| 30| 60.72|
|10021269741|2009-06-03| 西北| 甘肃| 家具产品|30.93| 42| 511.69|
|10021262933|2010-01-28| 西南| 四川| 办公用品| 2.89| 26| 28.24|
|10021263989|2012-05-07| 华东| 福建| 办公用品|18.97| 29| 71.75|
+-----------+----------+------+--------+------------+-----+--------+-------+
only showing top 5 rows
'''
- filter筛选
# filter 等价于 where
df.filter("product_type='办公用品' and quantity > 10").show(5)
'''
+-----------+----------+------+--------+------------+-----+--------+------+
| order_id|order_date|region|province|product_type|price|quantity|profit|
+-----------+----------+------+--------+------------+-----+--------+------+
|10021266565|2011-10-22| 东北| 吉林| 办公用品| 9.11| 30| 60.72|
|10021251834|2009-01-19| 华北| 北京| 办公用品| 2.88| 41| 7.57|
|10021255693|2009-06-03| 华南| 广东| 办公用品| 1.68| 28| 0.35|
|10021253900|2010-12-17| 华南| 广东| 办公用品| 1.86| 48|-107.0|
|10021262933|2010-01-28| 西南| 四川| 办公用品| 2.89| 26| 28.24|
+-----------+----------+------+--------+------------+-----+--------+------+
only showing top 5 rows
'''
# pandas 写法
df.filter((df['product_type']=='办公用品') & (df['quantity'] > 10)).show(5)
'''
+-----------+----------+------+--------+------------+-----+--------+------+
| order_id|order_date|region|province|product_type|price|quantity|profit|
+-----------+----------+------+--------+------------+-----+--------+------+
|10021266565|2011-10-22| 东北| 吉林| 办公用品| 9.11| 30| 60.72|
|10021251834|2009-01-19| 华北| 北京| 办公用品| 2.88| 41| 7.57|
|10021255693|2009-06-03| 华南| 广东| 办公用品| 1.68| 28| 0.35|
|10021253900|2010-12-17| 华南| 广东| 办公用品| 1.86| 48|-107.0|
|10021262933|2010-01-28| 西南| 四川| 办公用品| 2.89| 26| 28.24|
+-----------+----------+------+--------+------------+-----+--------+------+
only showing top 5 rows
'''
- 字段与常量的运算
df.show(5)
'''
+-----------+----------+------+--------+------------+------+--------+--------+
| order_id|order_date|region|province|product_type| price|quantity| profit|
+-----------+----------+------+--------+------------+------+--------+--------+
|10021265709|2010-10-13| 华北| 河北| 办公用品| 38.94| 6| -213.25|
|10021250753|2012-02-20| 华南| 河南| 办公用品| 2.08| 2| -4.64|
|10021257699|2011-07-15| 华南| 广东| 家具产品|107.53| 26| 1054.82|
|10021258358|2011-07-15| 华北| 内蒙古| 家具产品| 70.89| 24|-1748.56|
|10021249836|2011-07-15| 华北| 内蒙古| 数码电子| 7.99| 23| -85.13|
+-----------+----------+------+--------+------------+------+--------+--------+
only showing top 5 rows
'''
# alias 对应 SQL 的 as
# alias 等价于 name
df.select('order_id','price',(df['price']*1.2).alias('price_new')).show(5)
'''
+-----------+------+------------------+
| order_id| price| price_new|
+-----------+------+------------------+
|10021265709| 38.94|46.727999999999994|
|10021250753| 2.08| 2.496|
|10021257699|107.53| 129.036|
|10021258358| 70.89| 85.068|
|10021249836| 7.99| 9.588|
+-----------+------+------------------+
only showing top 5 rows
'''
- 字段与字段的运算
df.select('order_id','price',(df['price']*df['quantity']).alias('amount')).show(5)
'''
+-----------+------+------------------+
| order_id| price| amount|
+-----------+------+------------------+
|10021265709| 38.94| 233.64|
|10021250753| 2.08| 4.16|
|10021257699|107.53| 2795.78|
|10021258358| 70.89|1701.3600000000001|
|10021249836| 7.99| 183.77|
+-----------+------+------------------+
only showing top 5 rows
'''
- 条件判断
# when otherwise 类似于 SQL 的 case when
from pyspark.sql import functions as f
df.select(
'order_id',
'profit',
f.when(df['profit'] > 0, '盈利').when(df['profit'] == 0, '持平').otherwise('亏损').name('state')
).show(5)
from pyspark.sql import functions as f
df.select(
'order_id',
'profit',
f.when(df['profit'] > 0, '盈利').when(df['profit'] == 0, '持平').otherwise('亏损').alias('state')
).show(5)
'''
+-----------+--------+-----+
| order_id| profit|state|
+-----------+--------+-----+
|10021265709| -213.25| 亏损|
|10021250753| -4.64| 亏损|
|10021257699| 1054.82| 盈利|
|10021258358|-1748.56| 亏损|
|10021249836| -85.13| 亏损|
+-----------+--------+-----+
only showing top 5 rows
+-----------+--------+-----+
| order_id| profit|state|
+-----------+--------+-----+
|10021265709| -213.25| 亏损|
|10021250753| -4.64| 亏损|
|10021257699| 1054.82| 盈利|
|10021258358|-1748.56| 亏损|
|10021249836| -85.13| 亏损|
+-----------+--------+-----+
only showing top 5 rows
'''
2.表连接
- 员工表
people = spark.read.csv("data/people.csv", header=True, inferSchema=True)
people.show(5)
'''
+---+------+---+---+
| id| name|sex|age|
+---+------+---+---+
| 1|孙尚香| 女| 29|
| 2| 曹操| 男| 21|
| 4|司马懿| 男| 21|
| 5| 貂蝉| 女| 28|
| 7| 大乔| 女| 21|
+---+------+---+---+
only showing top 5 rows
'''
- 薪资表
salary = spark.read.csv("data/salary.csv", header=True, inferSchema=True)
salary.show(5)
'''
+---+------+-----+------+
| id| name|level|salary|
+---+------+-----+------+
| 2| 曹操| 1| 15K|
| 3| 荀彧| 2| 10K|
| 4|司马懿| 2| 10K|
| 5| 貂蝉| 3| 5K|
| 6| 孙权| 3| 5K|
+---+------+-----+------+
only showing top 5 rows
'''
- inner内连接
people.join(salary, on='id', how='inner').show() # 默认就是内连接
people.join(salary, on=['id','name'], how='inner').show()
'''
+---+------+---+---+------+-----+------+
| id| name|sex|age| name|level|salary|
+---+------+---+---+------+-----+------+
| 2| 曹操| 男| 21| 曹操| 1| 15K|
| 4|司马懿| 男| 21|司马懿| 2| 10K|
| 5| 貂蝉| 女| 28| 貂蝉| 3| 5K|
| 7| 大乔| 女| 21| 大乔| 3| 5K|
+---+------+---+---+------+-----+------+
+---+------+---+---+-----+------+
| id| name|sex|age|level|salary|
+---+------+---+---+-----+------+
| 2| 曹操| 男| 21| 1| 15K|
| 4|司马懿| 男| 21| 2| 10K|
| 5| 貂蝉| 女| 28| 3| 5K|
| 7| 大乔| 女| 21| 3| 5K|
+---+------+---+---+-----+------+
'''
- left左连接
people.join(salary, on='id', how='left').show()
'''
+---+------+---+---+------+-----+------+
| id| name|sex|age| name|level|salary|
+---+------+---+---+------+-----+------+
| 1|孙尚香| 女| 29| null| null| null|
| 2| 曹操| 男| 21| 曹操| 1| 15K|
| 4|司马懿| 男| 21|司马懿| 2| 10K|
| 5| 貂蝉| 女| 28| 貂蝉| 3| 5K|
| 7| 大乔| 女| 21| 大乔| 3| 5K|
| 8|诸葛亮| 男| 22| null| null| null|
| 10|邢道荣| 男| 29| null| null| null|
+---+------+---+---+------+-----+------+
'''
- right右连接
people.join(salary, on='id', how='right').show()
'''
+---+------+----+----+------+-----+------+
| id| name| sex| age| name|level|salary|
+---+------+----+----+------+-----+------+
| 2| 曹操| 男| 21| 曹操| 1| 15K|
| 3| null|null|null| 荀彧| 2| 10K|
| 4|司马懿| 男| 21|司马懿| 2| 10K|
| 5| 貂蝉| 女| 28| 貂蝉| 3| 5K|
| 6| null|null|null| 孙权| 3| 5K|
| 7| 大乔| 女| 21| 大乔| 3| 5K|
| 9| null|null|null| 小乔| 2| 10K|
+---+------+----+----+------+-----+------+
'''
- outer外连接
people.join(salary, on='id', how='outer').show()
people.join(salary, on='id', how='full').show()
'''
+---+------+----+----+------+-----+------+
| id| name| sex| age| name|level|salary|
+---+------+----+----+------+-----+------+
| 1|孙尚香| 女| 29| null| null| null|
| 6| null|null|null| 孙权| 3| 5K|
| 3| null|null|null| 荀彧| 2| 10K|
| 5| 貂蝉| 女| 28| 貂蝉| 3| 5K|
| 9| null|null|null| 小乔| 2| 10K|
| 4|司马懿| 男| 21|司马懿| 2| 10K|
| 8|诸葛亮| 男| 22| null| null| null|
| 7| 大乔| 女| 21| 大乔| 3| 5K|
| 10|邢道荣| 男| 29| null| null| null|
| 2| 曹操| 男| 21| 曹操| 1| 15K|
+---+------+----+----+------+-----+------+
+---+------+----+----+------+-----+------+
| id| name| sex| age| name|level|salary|
+---+------+----+----+------+-----+------+
| 1|孙尚香| 女| 29| null| null| null|
| 6| null|null|null| 孙权| 3| 5K|
| 3| null|null|null| 荀彧| 2| 10K|
| 5| 貂蝉| 女| 28| 貂蝉| 3| 5K|
| 9| null|null|null| 小乔| 2| 10K|
| 4|司马懿| 男| 21|司马懿| 2| 10K|
| 8|诸葛亮| 男| 22| null| null| null|
| 7| 大乔| 女| 21| 大乔| 3| 5K|
| 10|邢道荣| 男| 29| null| null| null|
| 2| 曹操| 男| 21| 曹操| 1| 15K|
+---+------+----+----+------+-----+------+
'''
- cross交叉连接
people.join(salary, how='cross').show()
'''
+---+------+---+---+---+------+-----+------+
| id| name|sex|age| id| name|level|salary|
+---+------+---+---+---+------+-----+------+
| 1|孙尚香| 女| 29| 2| 曹操| 1| 15K|
| 1|孙尚香| 女| 29| 3| 荀彧| 2| 10K|
| 1|孙尚香| 女| 29| 4|司马懿| 2| 10K|
| 1|孙尚香| 女| 29| 5| 貂蝉| 3| 5K|
| 1|孙尚香| 女| 29| 6| 孙权| 3| 5K|
| 1|孙尚香| 女| 29| 7| 大乔| 3| 5K|
| 1|孙尚香| 女| 29| 9| 小乔| 2| 10K|
| 2| 曹操| 男| 21| 2| 曹操| 1| 15K|
| 2| 曹操| 男| 21| 3| 荀彧| 2| 10K|
| 2| 曹操| 男| 21| 4|司马懿| 2| 10K|
| 2| 曹操| 男| 21| 5| 貂蝉| 3| 5K|
| 2| 曹操| 男| 21| 6| 孙权| 3| 5K|
| 2| 曹操| 男| 21| 7| 大乔| 3| 5K|
| 2| 曹操| 男| 21| 9| 小乔| 2| 10K|
| 4|司马懿| 男| 21| 2| 曹操| 1| 15K|
| 4|司马懿| 男| 21| 3| 荀彧| 2| 10K|
| 4|司马懿| 男| 21| 4|司马懿| 2| 10K|
| 4|司马懿| 男| 21| 5| 貂蝉| 3| 5K|
| 4|司马懿| 男| 21| 6| 孙权| 3| 5K|
| 4|司马懿| 男| 21| 7| 大乔| 3| 5K|
+---+------+---+---+---+------+-----+------+
only showing top 20 rows
'''
people.crossJoin(salary).show()
'''
+---+------+---+---+---+------+-----+------+
| id| name|sex|age| id| name|level|salary|
+---+------+---+---+---+------+-----+------+
| 1|孙尚香| 女| 29| 2| 曹操| 1| 15K|
| 1|孙尚香| 女| 29| 3| 荀彧| 2| 10K|
| 1|孙尚香| 女| 29| 4|司马懿| 2| 10K|
| 1|孙尚香| 女| 29| 5| 貂蝉| 3| 5K|
| 1|孙尚香| 女| 29| 6| 孙权| 3| 5K|
| 1|孙尚香| 女| 29| 7| 大乔| 3| 5K|
| 1|孙尚香| 女| 29| 9| 小乔| 2| 10K|
| 2| 曹操| 男| 21| 2| 曹操| 1| 15K|
| 2| 曹操| 男| 21| 3| 荀彧| 2| 10K|
| 2| 曹操| 男| 21| 4|司马懿| 2| 10K|
| 2| 曹操| 男| 21| 5| 貂蝉| 3| 5K|
| 2| 曹操| 男| 21| 6| 孙权| 3| 5K|
| 2| 曹操| 男| 21| 7| 大乔| 3| 5K|
| 2| 曹操| 男| 21| 9| 小乔| 2| 10K|
| 4|司马懿| 男| 21| 2| 曹操| 1| 15K|
| 4|司马懿| 男| 21| 3| 荀彧| 2| 10K|
| 4|司马懿| 男| 21| 4|司马懿| 2| 10K|
| 4|司马懿| 男| 21| 5| 貂蝉| 3| 5K|
| 4|司马懿| 男| 21| 6| 孙权| 3| 5K|
| 4|司马懿| 男| 21| 7| 大乔| 3| 5K|
+---+------+---+---+---+------+-----+------+
only showing top 20 rows
'''
- semi左半连接
# 类似于内连接,但区别在于只返回做表字段不返回右表字段
# 相当于按链接条件筛选左表的数据
people.join(salary, on='id', how='semi').show()
people.join(salary, on='id', how='inner').show()
'''
+---+------+---+---+
| id| name|sex|age|
+---+------+---+---+
| 2| 曹操| 男| 21|
| 4|司马懿| 男| 21|
| 5| 貂蝉| 女| 28|
| 7| 大乔| 女| 21|
+---+------+---+---+
+---+------+---+---+------+-----+------+
| id| name|sex|age| name|level|salary|
+---+------+---+---+------+-----+------+
| 2| 曹操| 男| 21| 曹操| 1| 15K|
| 4|司马懿| 男| 21|司马懿| 2| 10K|
| 5| 貂蝉| 女| 28| 貂蝉| 3| 5K|
| 7| 大乔| 女| 21| 大乔| 3| 5K|
+---+------+---+---+------+-----+------+
'''
- anti左反连接
# 返回左表存在而右表不存在的数据
# 只返回左表字段不返回右表字段
people.join(salary, on='id', how='anti').show()
people.join(salary, on='id', how='full').show()
'''
+---+------+---+---+
| id| name|sex|age|
+---+------+---+---+
| 1|孙尚香| 女| 29|
| 8|诸葛亮| 男| 22|
| 10|邢道荣| 男| 29|
+---+------+---+---+
+---+------+----+----+------+-----+------+
| id| name| sex| age| name|level|salary|
+---+------+----+----+------+-----+------+
| 1|孙尚香| 女| 29| null| null| null|
| 6| null|null|null| 孙权| 3| 5K|
| 3| null|null|null| 荀彧| 2| 10K|
| 5| 貂蝉| 女| 28| 貂蝉| 3| 5K|
| 9| null|null|null| 小乔| 2| 10K|
| 4|司马懿| 男| 21|司马懿| 2| 10K|
| 8|诸葛亮| 男| 22| null| null| null|
| 7| 大乔| 女| 21| 大乔| 3| 5K|
| 10|邢道荣| 男| 29| null| null| null|
| 2| 曹操| 男| 21| 曹操| 1| 15K|
+---+------+----+----+------+-----+------+
'''
- 复杂连接
salary_new = salary.withColumnRenamed('id','number')
# 表关联键的名称不一致,且为多个关联键,连接条件包含不等值判断
people.join(
salary_new
, on=(people['id']==salary_new['number']) & (people['name']==salary_new['name']) & (people['age'] >= 25)
).show()
'''
+---+----+---+---+------+----+-----+------+
| id|name|sex|age|number|name|level|salary|
+---+----+---+---+------+----+-----+------+
| 5|貂蝉| 女| 28| 5|貂蝉| 3| 5K|
+---+----+---+---+------+----+-----+------+
'''
- 纵向合并(并集)
# union 等价于 unionAll
people.union(people).show() # 不去重
people.union(people).distinct().show() # 去重
'''
+---+------+---+---+
| id| name|sex|age|
+---+------+---+---+
| 1|孙尚香| 女| 29|
| 2| 曹操| 男| 21|
| 4|司马懿| 男| 21|
| 5| 貂蝉| 女| 28|
| 7| 大乔| 女| 21|
| 8|诸葛亮| 男| 22|
| 10|邢道荣| 男| 29|
| 1|孙尚香| 女| 29|
| 2| 曹操| 男| 21|
| 4|司马懿| 男| 21|
| 5| 貂蝉| 女| 28|
| 7| 大乔| 女| 21|
| 8|诸葛亮| 男| 22|
| 10|邢道荣| 男| 29|
+---+------+---+---+
+---+------+---+---+
| id| name|sex|age|
+---+------+---+---+
| 10|邢道荣| 男| 29|
| 1|孙尚香| 女| 29|
| 4|司马懿| 男| 21|
| 7| 大乔| 女| 21|
| 5| 貂蝉| 女| 28|
| 2| 曹操| 男| 21|
| 8|诸葛亮| 男| 22|
+---+------+---+---+
'''
# unionByName, 按对应字段纵向合并
people_new = people.select('age','sex','name','id')
people_new.show()
'''
+---+---+------+---+
|age|sex| name| id|
+---+---+------+---+
| 29| 女|孙尚香| 1|
| 21| 男| 曹操| 2|
| 21| 男|司马懿| 4|
| 28| 女| 貂蝉| 5|
| 21| 女| 大乔| 7|
| 22| 男|诸葛亮| 8|
| 29| 男|邢道荣| 10|
+---+---+------+---+
'''
people.unionByName(people_new).show()
'''
+---+------+---+---+
| id| name|sex|age|
+---+------+---+---+
| 1|孙尚香| 女| 29|
| 2| 曹操| 男| 21|
| 4|司马懿| 男| 21|
| 5| 貂蝉| 女| 28|
| 7| 大乔| 女| 21|
| 8|诸葛亮| 男| 22|
| 10|邢道荣| 男| 29|
| 1|孙尚香| 女| 29|
| 2| 曹操| 男| 21|
| 4|司马懿| 男| 21|
| 5| 貂蝉| 女| 28|
| 7| 大乔| 女| 21|
| 8|诸葛亮| 男| 22|
| 10|邢道荣| 男| 29|
+---+------+---+---+
'''
3.分组聚合
df = spark.read.csv("data/order.csv", header=True, inferSchema=True)
df.show(5)
'''
+-----------+----------+------+--------+------------+------+--------+--------+
| order_id|order_date|region|province|product_type| price|quantity| profit|
+-----------+----------+------+--------+------------+------+--------+--------+
|10021265709|2010-10-13| 华北| 河北| 办公用品| 38.94| 6| -213.25|
|10021250753|2012-02-20| 华南| 河南| 办公用品| 2.08| 2| -4.64|
|10021257699|2011-07-15| 华南| 广东| 家具产品|107.53| 26| 1054.82|
|10021258358|2011-07-15| 华北| 内蒙古| 家具产品| 70.89| 24|-1748.56|
|10021249836|2011-07-15| 华北| 内蒙古| 数码电子| 7.99| 23| -85.13|
+-----------+----------+------+--------+------------+------+--------+--------+
only showing top 5 rows
'''
- groupBy
- 以区域分组,对数量求和
df.groupBy('region').sum('quantity').show()
df.groupBy('region').agg({'quantity':'sum'}).show()
'''
+------+-------------+
|region|sum(quantity)|
+------+-------------+
| 华东| 38872|
| 西北| 16958|
| 华南| 82102|
| 华北| 42515|
| 东北| 31951|
| 西南| 6432|
+------+-------------+
+------+-------------+
|region|sum(quantity)|
+------+-------------+
| 华东| 38872|
| 西北| 16958|
| 华南| 82102|
| 华北| 42515|
| 东北| 31951|
| 西南| 6432|
+------+-------------+
'''
from pyspark.sql import functions as f
df.groupBy('region').agg(f.sum('quantity').name('quantity_sum')).show()
'''
+------+------------+
|region|quantity_sum|
+------+------------+
| 华东| 38872|
| 西北| 16958|
| 华南| 82102|
| 华北| 42515|
| 东北| 31951|
| 西南| 6432|
+------+------------+
'''
- groupBy+agg
- 以区域分组,统计单价的均值,合并产品类型
# collect_list 不去重;collect_set 去重
# mean 等价于 avg
from pyspark.sql import functions as f
df.groupBy('region').agg(
# f.avg('price').name('price_avg')
f.mean('price').name('price_avg')
, f.collect_set('product_type').alias('product_set')
).show()
# 上面的等价写法
df.groupBy('region').agg(
f.expr('avg(price) as price_avg')
, f.expr('collect_set(product_type) as product_set')
).show()
'''
+------+-----------------+------------------------------+
|region| price_avg| product_set|
+------+-----------------+------------------------------+
| 华东|98.88595469255712|[数码电子, 办公用品, 家具产品]|
| 西北|92.77338368580075|[数码电子, 办公用品, 家具产品]|
| 华南|86.23637962962982|[数码电子, 办公用品, 家具产品]|
| 华北|92.05539156626534|[数码电子, 办公用品, 家具产品]|
| 东北| 73.0615702479338|[数码电子, 办公用品, 家具产品]|
| 西南|89.90359999999998|[数码电子, 办公用品, 家具产品]|
+------+-----------------+------------------------------+
+------+-----------------+------------------------------+
|region| price_avg| product_set|
+------+-----------------+------------------------------+
| 华东|98.88595469255712|[数码电子, 办公用品, 家具产品]|
| 西北|92.77338368580075|[数码电子, 办公用品, 家具产品]|
| 华南|86.23637962962982|[数码电子, 办公用品, 家具产品]|
| 华北|92.05539156626534|[数码电子, 办公用品, 家具产品]|
| 东北| 73.0615702479338|[数码电子, 办公用品, 家具产品]|
| 西南|89.90359999999998|[数码电子, 办公用品, 家具产品]|
+------+-----------------+------------------------------+
'''
- groupBy+agg
- 以区域和省份分组,统计销售金额(单价*数量)
from pyspark.sql import functions as f
df.withColumn('amount', df['price']*df['quantity']).groupBy('region','province').agg(f.sum('amount').name('amount')).show()
'''
+------+--------+------------------+
|region|province| amount|
+------+--------+------------------+
| 华北| 河北|365382.67999999993|
| 华南| 河南| 679270.2199999999|
| 西北| 甘肃|507529.73000000033|
| 东北| 吉林| 554975.2899999995|
| 华南| 广东| 2499042.95|
| 西北| 新疆| 120412.68|
| 华北| 北京| 650718.85|
| 华东| 浙江|1280734.0600000003|
| 华北| 山西| 786083.3999999999|
| 西南| 四川|200752.48999999993|
| 西北| 青海|31500.249999999993|
| 华北| 天津| 511124.1199999998|
| 西北| 陕西| 315693.5299999999|
| 华北| 内蒙古| 860658.1999999998|
| 华东| 福建|171204.19000000015|
| 华南| 湖南|269664.09999999986|
| 华东| 安徽| 585314.3999999994|
| 西南| 重庆| 63724.83|
| 华东| 山东|260602.88000000006|
| 西南| 贵州|102337.31000000001|
+------+--------+------------------+
only showing top 20 rows
'''
- groupBy+pivot
- 数据透视表,行:区域,列:产品类型,值:数量,计算类型:求和
df.groupBy('region').pivot('product_type').sum('quantity').show()
'''
+------+--------+--------+--------+
|region|办公用品|家具产品|数码电子|
+------+--------+--------+--------+
| 华东| 20525| 8775| 9572|
| 西北| 9796| 3123| 4039|
| 华南| 45635| 16457| 20010|
| 华北| 24213| 8333| 9969|
| 东北| 17286| 6880| 7785|
| 西南| 3154| 1537| 1741|
+------+--------+--------+--------+
'''
- crosstable
- 交叉表统计频数,行:区域,列:产品类型
df.crosstab('region','product_type').show()
'''
+-------------------+--------+--------+--------+
|region_product_type|办公用品|家具产品|数码电子|
+-------------------+--------+--------+--------+
| 华东| 832| 330| 383|
| 华南| 1775| 660| 805|
| 华北| 939| 327| 394|
| 东北| 647| 266| 297|
| 西南| 127| 56| 67|
| 西北| 373| 130| 159|
+-------------------+--------+--------+--------+
'''
- 窗口函数
- 提取各产品类型首次交易的订单信息
from pyspark.sql import Window
from pyspark.sql import functions as f
# row_number() over()
window = Window.partitionBy('product_type').orderBy(df['order_date'].asc()).rowsBetween(Window.unboundedPreceding,Window.currentRow)
# Window.partitionBy 分区(分组)字段
# Window.orderBy 排序字段
# Window.rowsBetween 按行的窗口范围
# Window.rangeBetween 按数值的窗口范围
# Window.unboundedFollowing 尾行
# Window.unboundedPreceding 首行
# Window.currentRow 当前行
# Window.rowsBetween(-3, 3) 当前行的前三行(-3)与后三行(3)
df.select('order_id','order_date','product_type').withColumn('rn', f.row_number().over(window)).where('rn=1').show()
# 上面的等价写法
df.selectExpr('order_id','order_date','product_type','row_number() over(partition by product_type order by order_date asc) as rn').where('rn=1').show()
'''
+-----------+----------+------------+---+
| order_id|order_date|product_type| rn|
+-----------+----------+------------+---+
|10021269291|2009-01-03| 数码电子| 1|
|10021350632|2009-01-01| 办公用品| 1|
|10021454566|2009-01-02| 家具产品| 1|
+-----------+----------+------------+---+
+-----------+----------+------------+---+
| order_id|order_date|product_type| rn|
+-----------+----------+------------+---+
|10021269291|2009-01-03| 数码电子| 1|
|10021350632|2009-01-01| 办公用品| 1|
|10021454566|2009-01-02| 家具产品| 1|
+-----------+----------+------------+---+
'''
- 增强聚合
- 以区域和产品类型分组对数量求和
# rollup 从左往右按层次分类聚合,无产品类型的小计
df.rollup('region','product_type').sum('quantity').orderBy('region','product_type').show()
# cube
df.cube('region','product_type').sum('quantity').orderBy('region','product_type').show()
'''
+------+------------+-------------+
|region|product_type|sum(quantity)|
+------+------------+-------------+
| null| null| 218830|
| 东北| null| 31951|
| 东北| 办公用品| 17286|
| 东北| 家具产品| 6880|
| 东北| 数码电子| 7785|
| 华东| null| 38872|
| 华东| 办公用品| 20525|
| 华东| 家具产品| 8775|
| 华东| 数码电子| 9572|
| 华北| null| 42515|
| 华北| 办公用品| 24213|
| 华北| 家具产品| 8333|
| 华北| 数码电子| 9969|
| 华南| null| 82102|
| 华南| 办公用品| 45635|
| 华南| 家具产品| 16457|
| 华南| 数码电子| 20010|
| 西北| null| 16958|
| 西北| 办公用品| 9796|
| 西北| 家具产品| 3123|
+------+------------+-------------+
only showing top 20 rows
+------+------------+-------------+
|region|product_type|sum(quantity)|
+------+------------+-------------+
| null| null| 218830|
| null| 办公用品| 120609|
| null| 家具产品| 45105|
| null| 数码电子| 53116|
| 东北| null| 31951|
| 东北| 办公用品| 17286|
| 东北| 家具产品| 6880|
| 东北| 数码电子| 7785|
| 华东| null| 38872|
| 华东| 办公用品| 20525|
| 华东| 家具产品| 8775|
| 华东| 数码电子| 9572|
| 华北| null| 42515|
| 华北| 办公用品| 24213|
| 华北| 家具产品| 8333|
| 华北| 数码电子| 9969|
| 华南| null| 82102|
| 华南| 办公用品| 45635|
| 华南| 家具产品| 16457|
| 华南| 数码电子| 20010|
+------+------------+-------------+
only showing top 20 rows
'''
4.分组抽样
- “办公用品”抽取10%,“家具产品”抽取20%,“数码电子”抽取30%
dct = {'办公用品':0.1,'家具产品':0.2,'数码电子':0.3}
sample = df.sampleBy(col='product_type',fractions=dct,seed=1)
df.groupBy('product_type').count().show() # 抽样前
sample.groupBy('product_type').count().show() # 抽样后
'''
+------------+-----+
|product_type|count|
+------------+-----+
| 数码电子| 2105|
| 办公用品| 4693|
| 家具产品| 1769|
+------------+-----+
+------------+-----+
|product_type|count|
+------------+-----+
| 数码电子| 656|
| 办公用品| 480|
| 家具产品| 361|
+------------+-----+
'''
5.调用自定义函数
- 求“订单日期”的距今天数
- selectExpr()调用自定义函数
from pyspark.sql import functions as f
from pyspark.sql import types as t
import datetime
def get_days(date:str) -> int:
end_date = datetime.datetime.now()
start_date = datetime.datetime.strptime(date,'%Y-%m-%d')
days = (end_date - start_date).days
return days
spark.udf.register('get_days',get_days,t.IntegerType()) # 将函数注册到spark中
df.selectExpr(
'order_id'
, 'order_date'
, 'get_days(order_date) as get_days'
).show(5)
'''
+-----------+----------+--------+
| order_id|order_date|get_days|
+-----------+----------+--------+
|10021265709|2010-10-13| 4389|
|10021250753|2012-02-20| 3894|
|10021257699|2011-07-15| 4114|
|10021258358|2011-07-15| 4114|
|10021249836|2011-07-15| 4114|
+-----------+----------+--------+
only showing top 5 rows
'''
df.selectExpr(
'order_id'
, 'order_date'
, 'datediff(current_date(),order_date) as datediff'
).show(5)
'''
+-----------+----------+--------+
| order_id|order_date|datediff|
+-----------+----------+--------+
|10021265709|2010-10-13| 4389|
|10021250753|2012-02-20| 3894|
|10021257699|2011-07-15| 4114|
|10021258358|2011-07-15| 4114|
|10021249836|2011-07-15| 4114|
+-----------+----------+--------+
only showing top 5 rows
'''
- 筛选“区域”为华南或华北,且“价格”大于100的数据,并按“价格”降序
- transform()调用自定义函数
def filter_sort(df):
# spark语法
df1 = df.where("region in ('华北','华南') and price > 100")
df2 = df1.orderBy(df1['price'].desc())
return df2
df.transform(filter_sort).show(5)
'''
+-----------+----------+------+--------+------------+-------+--------+--------+
| order_id|order_date|region|province|product_type| price|quantity| profit|
+-----------+----------+------+--------+------------+-------+--------+--------+
|10021415235|2012-05-21| 华南| 广东| 数码电子|6783.02| 8| 3852.19|
|10021396651|2009-03-21| 华北| 山西| 数码电子|6783.02| 13|27220.69|
|10021249830|2011-11-27| 华北| 内蒙古| 数码电子|6783.02| 3|-11984.4|
|10021263833|2009-07-28| 华北| 北京| 数码电子|3502.14| 4| -6923.6|
|10021349573|2010-01-18| 华南| 湖南| 数码电子|3502.14| 3|-8389.47|
+-----------+----------+------+--------+------------+-------+--------+--------+
only showing top 5 rows
'''
6.调用Pandas函数
- 求“价格”与其均值的偏差
- pandas_udf()调用Pandas函数
- User defined function:用户自定义函数
import pandas as pd
from pyspark.sql import types as t
from pyspark.sql.functions import pandas_udf
# pandas_udf 装饰器函数
@pandas_udf(t.FloatType()) # 必须定义函数返回值的数据类型(spark)
def dev_udf(s:pd.Series) -> pd.Series:
return s - s.mean()
df.withColumn('dev', dev_udf('price')).show(5)
'''
+-----------+----------+------+--------+------------+------+--------+--------+----------+
| order_id|order_date|region|province|product_type| price|quantity| profit| dev|
+-----------+----------+------+--------+------------+------+--------+--------+----------+
|10021265709|2010-10-13| 华北| 河北| 办公用品| 38.94| 6| -213.25| -49.45652|
|10021250753|2012-02-20| 华南| 河南| 办公用品| 2.08| 2| -4.64| -86.31652|
|10021257699|2011-07-15| 华南| 广东| 家具产品|107.53| 26| 1054.82| 19.133478|
|10021258358|2011-07-15| 华北| 内蒙古| 家具产品| 70.89| 24|-1748.56|-17.506521|
|10021249836|2011-07-15| 华北| 内蒙古| 数码电子| 7.99| 23| -85.13|-80.406525|
+-----------+----------+------+--------+------------+------+--------+--------+----------+
only showing top 5 rows
'''
- 筛选“区域”为东北且“利润”大于零的数据
- mapInPandas()调用Pandas函数
def filter_func(iterator):
for pr_df in iterator:
# 含 yield 关键字的函数称为生成器
# 生成器函数的返回值为迭代器
yield pd_df.query(' region == "东北" and profit > 0 ')
# schema 为函数返回的 df 的架构信息
# schema = '字段1 数据类型,字段2 数据类型'
df.mapInPandas(filter_func,df.schema).show(5)
'''
+-----------+----------+------+--------+------------+------+--------+-------+
| order_id|order_date|region|province|product_type| price|quantity| profit|
+-----------+----------+------+--------+------------+------+--------+-------+
|10021266565|2011-10-22| 东北| 吉林| 办公用品| 9.11| 30| 60.72|
|10021255969|2010-06-28| 东北| 辽宁| 数码电子|140.99| 47|1680.79|
|10021261550|2012-01-12| 东北| 辽宁| 办公用品| 9.9| 43| 175.54|
|10021265879|2011-06-17| 东北| 黑龙江| 办公用品| 42.76| 22| 127.7|
|10021256317|2012-11-30| 东北| 吉林| 家具产品| 14.34| 41| 163.81|
+-----------+----------+------+--------+------------+------+--------+-------+
only showing top 5 rows
'''
7.设置缓存
# 设置缓存: 当某个 df 经常被调用时
df.cache()
# 数据处理过程
# ......
# 释放缓存:当某个 df 已经不需要再调用时
df.unpersist()
# 查看是否设置缓存
df.is_cached
五、SparkSQL——DF的SQL交互
import pyspark
from pyspark.sql import SparkSession
import findspark
findspark.init()
spark = SparkSession \
.builder \
.appName("test") \
.master("local[*]") \
.enableHiveSupport() \
.getOrCreate()
sc = spark.sparkContext
1.读取数据
df = spark.read.csv("data/order.csv", header=True, inferSchema=True)
df.show(5)
'''
+-----------+----------+------+--------+------------+------+--------+--------+
| order_id|order_date|region|province|product_type| price|quantity| profit|
+-----------+----------+------+--------+------------+------+--------+--------+
|10021265709|2010-10-13| 华北| 河北| 办公用品| 38.94| 6| -213.25|
|10021250753|2012-02-20| 华南| 河南| 办公用品| 2.08| 2| -4.64|
|10021257699|2011-07-15| 华南| 广东| 家具产品|107.53| 26| 1054.82|
|10021258358|2011-07-15| 华北| 内蒙古| 家具产品| 70.89| 24|-1748.56|
|10021249836|2011-07-15| 华北| 内蒙古| 数码电子| 7.99| 23| -85.13|
+-----------+----------+------+--------+------------+------+--------+--------+
only showing top 5 rows
'''
2.创建临时视图
2.1.创建局部的临时视图
# 当前 SparkSession(Spark会话) 有效
df.createOrReplaceTempView('order')
spark.sql('select * from order').show(5)
'''
+-----------+----------+------+--------+------------+------+--------+--------+
| order_id|order_date|region|province|product_type| price|quantity| profit|
+-----------+----------+------+--------+------------+------+--------+--------+
|10021265709|2010-10-13| 华北| 河北| 办公用品| 38.94| 6| -213.25|
|10021250753|2012-02-20| 华南| 河南| 办公用品| 2.08| 2| -4.64|
|10021257699|2011-07-15| 华南| 广东| 家具产品|107.53| 26| 1054.82|
|10021258358|2011-07-15| 华北| 内蒙古| 家具产品| 70.89| 24|-1748.56|
|10021249836|2011-07-15| 华北| 内蒙古| 数码电子| 7.99| 23| -85.13|
+-----------+----------+------+--------+------------+------+--------+--------+
only showing top 5 rows
'''
# 新的 SparkSession(Spark会话) 不可查询,会报错
spark.newSession().sql('select * from order').show(5)
2.2.创建全局的临时视图
# 整个 Spark 应用程序(所有spark会话)有效
df.createOrReplaceGlobalTempView('global_order')
spark.sql('select * from global_temp.global_order').show(5)
'''
+-----------+----------+------+--------+------------+------+--------+--------+
| order_id|order_date|region|province|product_type| price|quantity| profit|
+-----------+----------+------+--------+------------+------+--------+--------+
|10021265709|2010-10-13| 华北| 河北| 办公用品| 38.94| 6| -213.25|
|10021250753|2012-02-20| 华南| 河南| 办公用品| 2.08| 2| -4.64|
|10021257699|2011-07-15| 华南| 广东| 家具产品|107.53| 26| 1054.82|
|10021258358|2011-07-15| 华北| 内蒙古| 家具产品| 70.89| 24|-1748.56|
|10021249836|2011-07-15| 华北| 内蒙古| 数码电子| 7.99| 23| -85.13|
+-----------+----------+------+--------+------------+------+--------+--------+
only showing top 5 rows
'''
# 新的 SparkSession(Spark会话) 可查询,不会报错
spark.newSession().sql('select * from global_temp.global_order').show(5)
'''
+-----------+----------+------+--------+------------+------+--------+--------+
| order_id|order_date|region|province|product_type| price|quantity| profit|
+-----------+----------+------+--------+------------+------+--------+--------+
|10021265709|2010-10-13| 华北| 河北| 办公用品| 38.94| 6| -213.25|
|10021250753|2012-02-20| 华南| 河南| 办公用品| 2.08| 2| -4.64|
|10021257699|2011-07-15| 华南| 广东| 家具产品|107.53| 26| 1054.82|
|10021258358|2011-07-15| 华北| 内蒙古| 家具产品| 70.89| 24|-1748.56|
|10021249836|2011-07-15| 华北| 内蒙古| 数码电子| 7.99| 23| -85.13|
+-----------+----------+------+--------+------------+------+--------+--------+
only showing top 5 rows
'''
3.对Hive表增删改查等
3.1.创建数据库
spark.sql('create database if not exists test')
3.2.删除数据表
# 建表
spark.sql('create table if not exists test.tmp_table(id int, name string)')
# 删除表
spark.sql('drop table if exists test.tmp_table')
3.3.创建内部表
- 读取本地数据
df = spark.read.csv('data/student.csv', inferSchema=True).toDF('id','name','birth','sex','class')
df.show(5)
'''
+---+----+----------+---+-----+
| id|name| birth|sex|class|
+---+----+----------+---+-----+
| 1|赵雷|1990-01-01| 男| 1|
| 2|钱电|1990-12-21| 男| 1|
| 3|孙风|1990-12-20| 男| 1|
| 6|吴兰|1991-01-01| 女| 1|
| 7|郑竹|1991-01-01| 女| 1|
+---+----+----------+---+-----+
only showing top 5 rows
'''
- 创建内部表
sqlquery='''
create table if not exists test.student_v1(
id int,
name string,
birth string,
sex string,
class int
)
row format delimited
fields terminated by ","
'''
spark.sql(sqlquery)
3.4.写入内部表
- 先执行建表语句再插入数据
# 追加数据
df.write.mode('append').format('hive').saveAsTable('test.student_v1')
spark.sql('select * from test.student_v1').show(5)
'''
+---+----+----------+---+-----+
| id|name| birth|sex|class|
+---+----+----------+---+-----+
| 1|赵雷|1990-01-01| 男| 1|
| 2|钱电|1990-12-21| 男| 1|
| 3|孙风|1990-12-20| 男| 1|
| 6|吴兰|1991-01-01| 女| 1|
| 7|郑竹|1991-01-01| 女| 1|
+---+----+----------+---+-----+
only showing top 5 rows
'''
# 覆盖数据
df.write.mode('overwrite').format('hive').saveAsTable('test.student_v1')
- 直接插入数据而不需要执行建表语句
# 如果表不存在则新建,如果表存在则报错
df.writeTo('test.student_v2').create()
spark.sql('select * from test.student_v2').show(5)
'''
+---+----+----------+---+-----+
| id|name| birth|sex|class|
+---+----+----------+---+-----+
| 1|赵雷|1990-01-01| 男| 1|
| 2|钱电|1990-12-21| 男| 1|
| 3|孙风|1990-12-20| 男| 1|
| 6|吴兰|1991-01-01| 女| 1|
| 7|郑竹|1991-01-01| 女| 1|
+---+----+----------+---+-----+
only showing top 5 rows
'''
3.2.创建分区表
sqlquery = """
create table if not exists test.student_p(
id int,
name string,
birth string,
sex string)
partitioned by (class int)
row format delimited
fields terminated by ','
"""
spark.sql(sqlquery)
3.3.动态写入分区表
# 读取本地数据
df = spark.read.csv('data/student.csv', inferSchema=True) \
.toDF('id', 'name', 'birth', 'sex', 'class')
df.show(1)
'''
+---+----+----------+---+-----+
| id|name| birth|sex|class|
+---+----+----------+---+-----+
| 1|赵雷|1990-01-01| 男| 1|
+---+----+----------+---+-----+
only showing top 1 row
'''
# 设置动态分区模式, 非严格模式
spark.conf.set('hive.exec.dynamic.partition.mode', 'nonstrict')
df.write.mode('overwrite').format('hive') \
.partitionBy('class').saveAsTable('test.student_p')
spark.sql('select * from test.student_p').show(1)
'''
+---+----+----------+---+-----+
| id|name| birth|sex|class|
+---+----+----------+---+-----+
| 1|赵雷|1990-01-01| 男| 1|
+---+----+----------+---+-----+
only showing top 1 row
'''
3.4.静态写入分区表
df_one = spark.createDataFrame(
data=[(66, '大山', '2000-01-01', '男', 1)],
schema=['id', 'name', 'birth', 'sex', 'class'])
df_one.show()
'''
+---+----+----------+---+-----+
| id|name| birth|sex|class|
+---+----+----------+---+-----+
| 66|大山|2000-01-01| 男| 1|
+---+----+----------+---+-----+
'''
# 创建局部临时视图
df_one.createOrReplaceTempView('df_one')
sqlquery = """
insert into table test.student_p partition(class=1)
select id, name, birth, sex from df_one
"""
spark.sql(sqlquery)
spark.sql('select * from test.student_p').show()
'''
+---+----+----------+---+-----+
| id|name| birth|sex|class|
+---+----+----------+---+-----+
| 1|赵雷|1990-01-01| 男| 1|
| 2|钱电|1990-12-21| 男| 1|
| 3|孙风|1990-12-20| 男| 1|
| 6|吴兰|1991-01-01| 女| 1|
| 7|郑竹|1991-01-01| 女| 1|
| 13|孙七|1992-06-01| 女| 1|
| 66|大山|2000-01-01| 男| 1|
| 4|李云|1990-12-06| 男| 2|
| 9|张三|1992-12-20| 女| 2|
| 5|周梅|1991-12-01| 女| 2|
| 12|赵六|1990-06-13| 女| 2|
| 17|陈三|1991-10-10| 男| 2|
| 14|郑双|1993-06-01| 女| 3|
| 15|王一|1992-05-01| 男| 3|
| 16|冯二|1990-01-02| 男| 3|
| 10|李四|1992-12-25| 女| 3|
| 11|李四|1991-06-06| 女| 3|
| 8|梅梅|1992-06-07| 女| 3|
+---+----+----------+---+-----+
'''
本文转载自: https://blog.csdn.net/qq_52421831/article/details/127383624
版权归原作者 呆子不呆X 所有, 如有侵权,请联系我们删除。
版权归原作者 呆子不呆X 所有, 如有侵权,请联系我们删除。