
地址:https://github.com/jianchang512/ChatTTS-ui
》》》更多开源项目
ChatTTS webUI & API
一个简单的本地网页界面,直接在网页使用 ChatTTS 将文字合成为语音,支持中英文、数字混杂,并提供API接口。
Releases中可下载Windows整合包。
界面预览
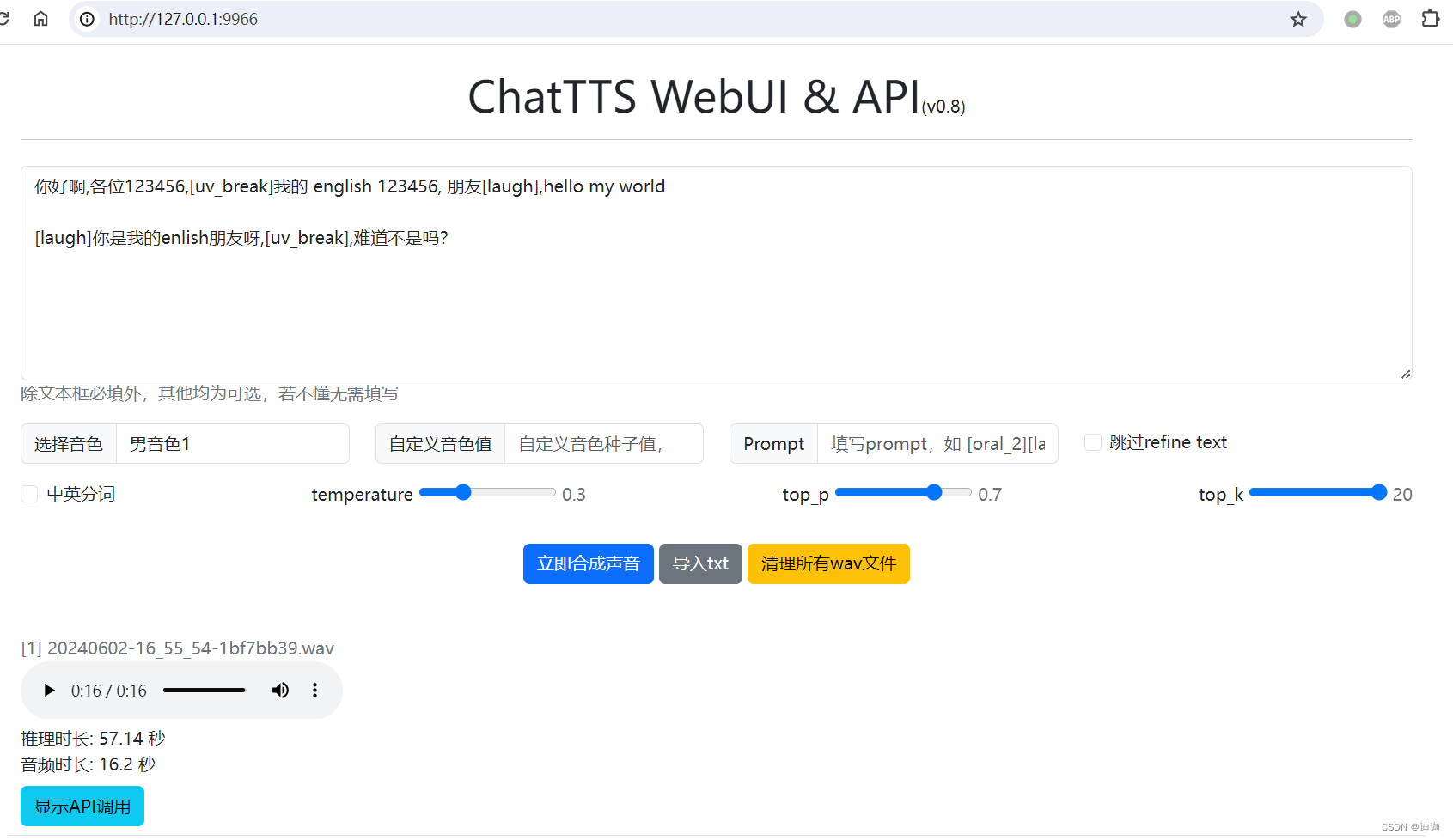
Windows预打包版
- 从 Releases中下载压缩包,解压后双击 app.exe 即可使用
Linux 下容器部署
安装
- 拉取项目仓库在任意路径下克隆项目,例如:
git clone https://github.com/jianchang512/ChatTTS-ui.git chat-tts-ui - 启动 Runner进入到项目目录:
cd chat-tts-ui启动容器并查看初始化日志:docker compose up -ddocker compose logs -f --no-log-prefix - 访问 ChatTTS WebUI
启动:['0.0.0.0', '9966'],也即,访问部署设备的IP:9966即可,例如:- 本机:http://127.0.0.1:9966- 服务器:http://192.168.1.100:9966
更新
- Get the latest code from the main branch:
git checkout maingit pull origin main - Go to the next step and update to the latest image:
docker compose downdocker compose up -d--builddocker compose logs -f --no-log-prefix
Linux 下源码部署
- 配置好 python3.9+环境
- 创建空目录
/data/chattts执行命令cd /data/chattts && git clone https://github.com/jianchang512/chatTTS-ui . - 创建虚拟环境
python3 -m venv venv - 激活虚拟环境
source ./venv/bin/activate - 安装依赖
pip3 install -r requirements.txt - 如果不需要CUDA加速,执行
pip3 install torch torchaudio如果需要CUDA加速,执行pip install torch torchaudio --index-url https://download.pytorch.org/whl/cu118 pip install nvidia-cublas-cu11 nvidia-cudnn-cu11另需安装 CUDA11.8+ ToolKit,请自行搜索安装方法 或参考 https://juejin.cn/post/7318704408727519270 - 执行
python3 app.py启动,将自动打开浏览器窗口,默认地址http://127.0.0.1:9966(注意:默认从 modelscope 魔塔下载模型,不可使用代理下载,请关闭代理)
MacOS 下源码部署
- 配置好 python3.9+环境,安装git ,执行命令
brew install git [email protected]继续执行export PATH="/usr/local/opt/[email protected]/bin:$PATH"source ~/.bash_profile source ~/.zshrc - 创建空目录
/data/chattts执行命令cd /data/chattts && git clone https://github.com/jianchang512/chatTTS-ui . - 创建虚拟环境
python3 -m venv venv - 激活虚拟环境
source ./venv/bin/activate - 安装依赖
pip3 install -r requirements.txt - 安装torch
pip3 install torch torchaudio - 执行
python3 app.py启动,将自动打开浏览器窗口,默认地址http://127.0.0.1:9966(注意:默认从 modelscope 魔塔下载模型,不可使用代理下载,请关闭代理)
Windows源码部署
- 下载python3.9+,安装时注意选中
Add Python to environment variables - 下载并安装git,https://github.com/git-for-windows/git/releases/download/v2.45.1.windows.1/Git-2.45.1-64-bit.exe
- 创建空文件夹
D:/chattts并进入,地址栏输入cmd回车,在弹出的cmd窗口中执行命令git clone https://github.com/jianchang512/chatTTS-ui . - 创建虚拟环境,执行命令
python -m venv venv - 激活虚拟环境,执行
.\venv\scripts\activate - 安装依赖,执行
pip install -r requirements.txt - 如果不需要CUDA加速,执行
pip install torch torchaudio如果需要CUDA加速,执行pip install torch torchaudio --index-url https://download.pytorch.org/whl/cu118另需安装 CUDA11.8+ ToolKit,请自行搜索安装方法或参考 https://juejin.cn/post/7318704408727519270 - 执行
python app.py启动,将自动打开浏览器窗口,默认地址http://127.0.0.1:9966(注意:默认从 modelscope 魔塔下载模型,不可使用代理下载,请关闭代理)
源码部署注意
- 源码部署启动后,会先从 modelscope下载模型,但modelscope缺少spk_stat.pt,会报错,请点击链接 https://huggingface.co/2Noise/ChatTTS/blob/main/asset/spk_stat.pt 下载 spk_stat.pt,将该文件复制到
项目目录/models/pzc163/chatTTS/asset/ 文件夹内 - 注意 modelscope 仅允许中国大陆ip下载模型,如果遇到 proxy 类错误,请关闭代理。如果你希望从 huggingface.co 下载模型,请打开
app.py查看大约第50行-60行的注释。 - 如果需要GPU加速,必须是英伟达显卡,并且安装 cuda版本的torch。
pip install torch torchaudio --index-url https://download.pytorch.org/whl/cu118
# 默认从 modelscope 下载模型,如果想从huggingface下载模型,请将以下3行注释掉
CHATTTS_DIR = snapshot_download('pzc163/chatTTS',cache_dir=MODEL_DIR)
chat = ChatTTS.Chat()
chat.load_models(source="local",local_path=CHATTTS_DIR)
# 如果希望从 huggingface.co下载模型,将以下注释删掉。将上方3行内容注释掉
#os.environ['HF_HUB_CACHE']=MODEL_DIR
#os.environ['HF_ASSETS_CACHE']=MODEL_DIR
#chat = ChatTTS.Chat()
#chat.load_models()
常见问题与报错解决方法
修改http地址
默认地址是
http://127.0.0.1:9966
,如果想修改,可打开目录下的
.env
文件,将
WEB_ADDRESS=127.0.0.1:9966
改为合适的ip和端口,比如修改为
WEB_ADDRESS=192.168.0.10:9966
以便局域网可访问
使用API请求 v0.5+
请求方法: POST
请求地址: http://127.0.0.1:9966/tts
请求参数:
text: str| 必须, 要合成语音的文字
voice: int| 可选,默认 2222, 决定音色的数字, 2222 | 7869 | 6653 | 4099 | 5099,可选其一,或者任意传入将随机使用音色
prompt: str| 可选,默认 空, 设定 笑声、停顿,例如 [oral_2][laugh_0][break_6]
temperature: float| 可选, 默认 0.3
top_p: float| 可选, 默认 0.7
top_k: int| 可选, 默认 20
skip_refine: int| 可选, 默认0, 1=跳过 refine text,0=不跳过
custom_voice: int| 可选, 默认0,自定义获取音色值时的种子值,需要大于0的整数,如果设置了则以此为准,将忽略
voice
返回:json数据
成功返回:
{code:0,msg:ok,audio_files:[dict1,dict2]}
其中 audio_files 是字典数组,每个元素dict为 {filename:wav文件绝对路径,url:可下载的wav网址}
失败返回:
{code:1,msg:错误原因}
# API调用代码
import requests
res = requests.post('http://127.0.0.1:9966/tts', data={
"text": "若不懂无需填写",
"prompt": "",
"voice": "3333",
"temperature": 0.3,
"top_p": 0.7,
"top_k": 20,
"skip_refine": 0,
"custom_voice": 0
})
print(res.json())
#ok
{code:0, msg:'ok', audio_files:[{filename: E:/python/chattts/static/wavs/20240601-22_12_12-c7456293f7b5e4dfd3ff83bbd884a23e.wav, url: http://127.0.0.1:9966/static/wavs/20240601-22_12_12-c7456293f7b5e4dfd3ff83bbd884a23e.wav}]}
#error
{code:1, msg:"error"}
在pyVideoTrans软件中使用
升级 pyVideoTrans 到 1.82+ https://github.com/jianchang512/pyvideotrans
- 点击菜单-设置-ChatTTS,填写请求地址,默认应该填写 http://127.0.0.1:9966
- 测试无问题后,在主界面中选择
ChatTTS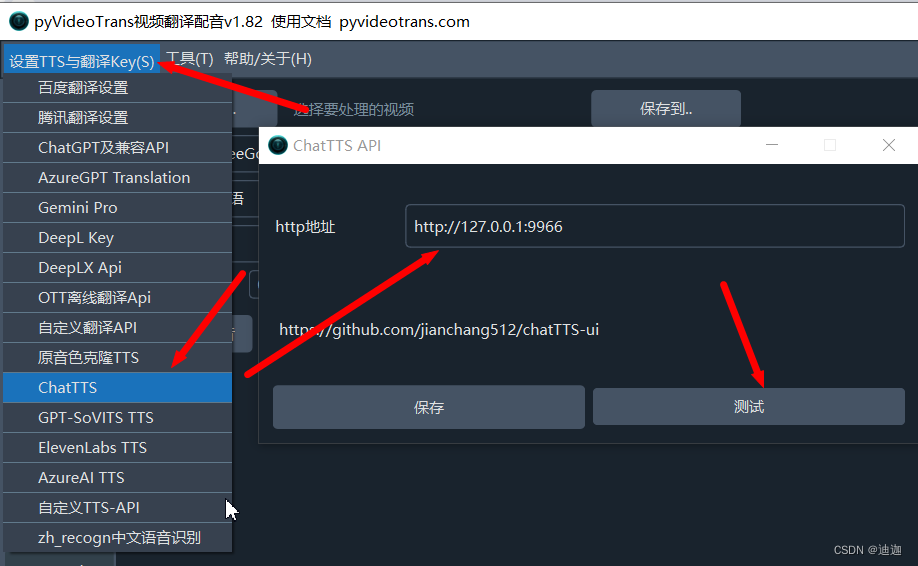
本文转载自: https://blog.csdn.net/2303_76218115/article/details/139402720
版权归原作者 迪迦 所有, 如有侵权,请联系我们删除。
版权归原作者 迪迦 所有, 如有侵权,请联系我们删除。