
数据源是尚硅谷的课件, 需要的话可以私信我
核心代码
importorg.apache.flink.api.common.serialization.SimpleStringSchema
importorg.apache.flink.configuration.Configuration
importorg.apache.flink.streaming.api.TimeCharacteristic
importorg.apache.flink.streaming.api.functions.KeyedProcessFunction
importorg.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}importorg.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
importorg.apache.flink.streaming.api.scala._
importorg.apache.flink.streaming.api.scala.function.ProcessWindowFunction
importorg.apache.flink.streaming.api.windowing.time.Time
importorg.apache.flink.streaming.api.windowing.windows.TimeWindow
importorg.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
importorg.apache.flink.util.Collector
importjava.sql.{Connection, DriverManager, PreparedStatement, Timestamp}importjava.text.SimpleDateFormat
importjava.util.Properties
// 每条数据/*
83.149.9.216 - - 17/05/2015:10:05:03 +0000 GET /presentations/logstash-monitorama-2013/images/kibana-search.png
83.149.9.216 - - 17/05/2015:10:05:43 +0000 GET /presentations/logstash-monitorama-2013/images/kibana-dashboard3.png
83.149.9.216 - - 17/05/2015:10:05:47 +0000 GET /presentations/logstash-monitorama-2013/plugin/highlight/highlight.js
*/// 输入样例类caseclass UVItem(url:String, ip:String, timestamp:Long)// 基于WindowEnd分组的样例类caseclass UVWindowEnd(url:String, WindowEnd:Long, Count:Long)// 目标 每五分钟统计这个1小时的每个页面的UV值object UniqueVisitor {def main(args: Array[String]):Unit={// 创建环境val env = StreamExecutionEnvironment.getExecutionEnvironment
// 设置时间特性为事件时间
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)// kafka消费数据/*
// 配置kafka
val properties = new Properties()
properties.put("bootstrap.server", "kafka的ip地址")
// 从kafka消费数据
val inputStream = env.addSource(new FlinkKafkaConsumer[String]("订阅主题",new SimpleStringSchema() ,properties))
*/// 读取resource的数据文件val inputStream = env.readTextFile(getClass.getResource("/apache.log").getPath)// 将每行数据用空格切割后 封装成样例类 数据乱序 并指定时间戳 设置Watermark为 30秒val dataStream = inputStream
.map(data=>{val arr = data.split(" ")val timestamp =new SimpleDateFormat("dd/MM/yyyy:HH:mm:ss").parse(arr(3)).getTime
// (url: String, ip:String, timestamp: Long)
UVItem(arr(6), arr(0), timestamp)}).assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[UVItem](Time.seconds(30)){overridedef extractTimestamp(t: UVItem):Long= t.timestamp
})
dataStream
.keyBy(_.url)// url作为key进行分组.timeWindow(Time.hours(1), Time.minutes(5))// 开滚动窗口 长度1小时 步长5分钟.process(new CountUVProcess())// 自定义类继承ProcessWindowFunction 对每个url进行统计 (url: String, WindowEnd: Long, Count: Long).keyBy(_.WindowEnd)// 窗口结束时间作为key进行分组.process(new windowEndProcess())// 对每个窗口的数据包装成要存到MySQL的元组 (Long, String, Long)(窗口结束时间, ip, 访问次数).addSink(new JDBCSink())// 往MySQL插入数据
env.execute()}}// 自定义RichSinkFunction往MySQL插入数据class JDBCSink extends RichSinkFunction[(Long,String,Long)]{// 定义连接和预处理器var conn:Connection = _
var insertStatement: PreparedStatement = _
// 在open函数初始化连接和预编译器overridedef open(parameters: Configuration):Unit={
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/pv_uv","root","123456")
insertStatement = conn.prepareStatement("insert into unique_visitor value(?, ? ,?)")}// 在close函数关闭连接和预编译器overridedef close():Unit={
conn.close()
insertStatement.close()}// 在invoke函数指定预处理器的数据和执行插入语句overridedef invoke(value:(Long,String,Long), context: SinkFunction.Context[_]):Unit={// 指定预编译器的数据
insertStatement.setTimestamp(1,new Timestamp(value._1))
insertStatement.setString(2, value._2)
insertStatement.setInt(3, value._3.toInt)// 执行预编译器
insertStatement.execute()}}// 基于WindowEnd分组后 在该Process中返回要插入数据库的元祖Tupleclass windowEndProcess()extends KeyedProcessFunction[Long, UVWindowEnd,(Long,String,Long)]{overridedef processElement(i: UVWindowEnd, context: KeyedProcessFunction[Long, UVWindowEnd,(Long,String,Long)]#Context, collector: Collector[(Long,String,Long)]):Unit={// 返回(窗口结束时间, 页面路径, 访问次数)
collector.collect((i.WindowEnd, i.url, i.Count))}}// 基于url分组并开窗后 在该Process中统计UV值class CountUVProcess()extends ProcessWindowFunction[UVItem, UVWindowEnd,String, TimeWindow]{overridedef process(key:String, context: Context, elements: Iterable[UVItem], out: Collector[UVWindowEnd]):Unit={// 用Set集合可以去重的特性 一个ip计为一次访问var userIpSet = Set[String]()for(item <- elements){
userIpSet += item.ip
}// 返回(访问的url, 窗口结束时间, 访问次数)
out.collect(UVWindowEnd(key, context.window.getEnd, userIpSet.size))}}
MySQL创建表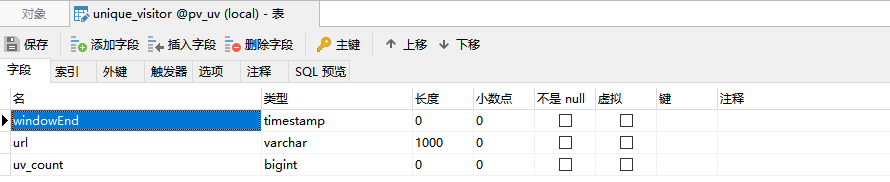
插入数据后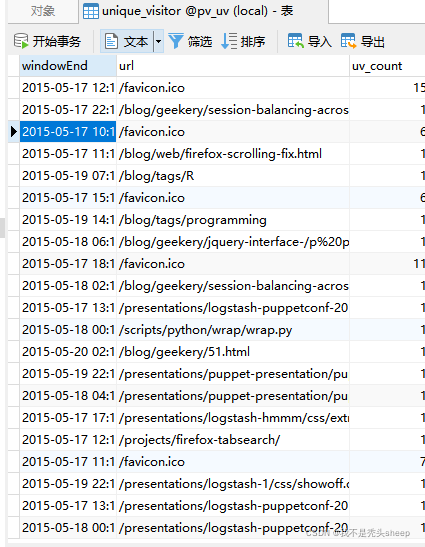
依赖
<dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.12</artifactId><version>1.10.1</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-scala_2.11</artifactId><version>1.10.2</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-scala_2.11</artifactId><version>1.10.2</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka-0.11_2.11</artifactId><version>1.10.2</version></dependency><dependency><groupId>org.apache.bahir</groupId><artifactId>flink-connector-redis_2.11</artifactId><version>1.0</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.25</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-statebackend-rocksdb_2.12</artifactId><version>1.10.1</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner_2.11</artifactId><version>1.10.1</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner-blink_2.11</artifactId><version>1.10.1</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-scala-bridge_2.11</artifactId><version>1.10.1</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-csv</artifactId><version>1.10.1</version></dependency></dependencies><build><plugins><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.4.6</version><executions><execution><goals><goal>compile</goal></goals></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.0.0</version><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build>
本文转载自: https://blog.csdn.net/weixin_44864260/article/details/122310704
版权归原作者 我不是秃头sheep 所有, 如有侵权,请联系我们删除。
版权归原作者 我不是秃头sheep 所有, 如有侵权,请联系我们删除。