
事件风暴从理论到落地
1. 什么是事件风暴
事件风暴是由 Alberto Brandolini 发明的一种轻量级,基于 DDD 概念的系统分析方法,EventStorming官网是这么说的:
事件风暴(EventStorming)是一种以
研讨会
(workshop,也有翻译为“工作坊”的)的形式开展的,用于
协作探索和研究业务领域
,特别是具有复杂流程的业务领域的
系统分析方法
。
它有不同的风格,可以在不同的场景中使用:
- 评估现有业务线的健康状况并发现最有效的改进领域;
- 探索新的业务模式的可行性;
- 设想新的服务,最大限度地为所有相关方带来积极成果;
- 设计整洁可维护的事件驱动型(Event-Driven)软件,以支持快速发展的业务。
事件风暴的自适应特性,决定了它允许有不同背景的项目干系人进行复杂的,跨学科的沟通交流,提供了一种跨越信息孤岛和专业界限的新型协作方式。
**事件风暴正是 DDD 战略设计中经常使用的一种方法,它可以快速分析和分解复杂的业务领域,完成
领域建模
。**
2. 准备工作
在开始事件风暴之前,需要准备好相关物料,邀请相关的参与人员,具体如下: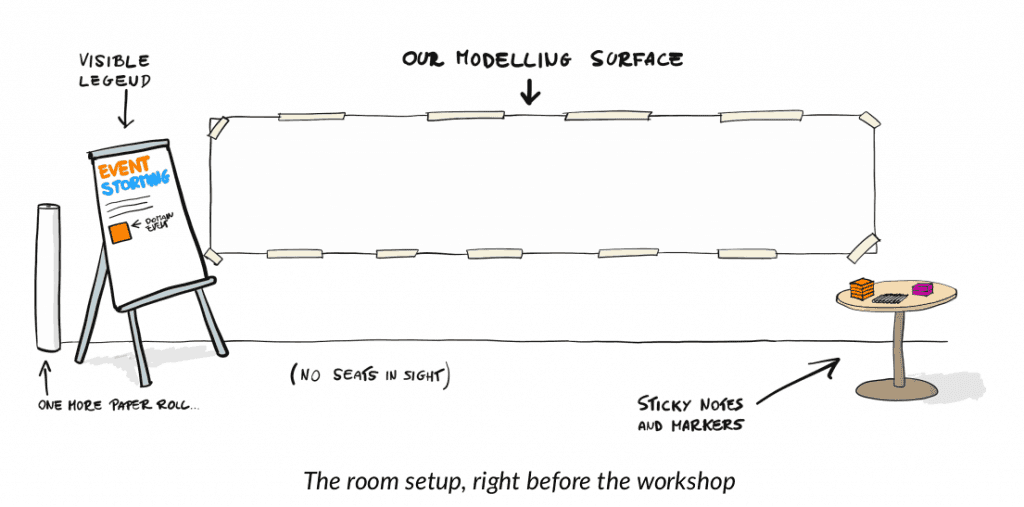
2.1 邀请参与者
事件风暴采用工作坊的方式,将项目团队和领域专家聚集在一起,通过可视化、高互动的方式一步一步将领域模型设计出来。领域专家是事件风暴中必不可少的核心参与者。领域专家可以是:业务人员、需求分析人员、产品经理或者在这个领域有多年经验的开发人员。
除了领域专家,事件风暴的其他参与者可以是 DDD 专家、架构师、产品经理、项目经理、开发人员、测试人员和UI设计师 等项目团队成员。
领域建模是统一团队语言的过程,因此项目团队应尽早地参与到领域建模中,这样才能高效建立起团队的通用语言。到了微服务建设时,领域模型也更容易和系统架构保持一致。
2.2 准备材料
事件风暴参与者会将自己的
想法
和
意见
写在即时贴上,并将贴纸贴在墙上的合适位置,我们
称这个过程是“
刷墙
”。

在这个过程中,我们要用不同颜色的贴纸
区分领域行为
。
当然,颜色并不固定,团队内统一才是重点。
2.3 准备场地
一面
足够大的墙
和
一块足够大的空间
,比如说大会议室。墙是用来贴纸的,大空间可以让人四处走动,方便合作。撤掉会议桌和椅子的事件风暴,你会发现参与者们的效率更高。
事件风暴的发明者曾经建议要准备八米长的墙,这样设计就不会受到空间的限制了。当然,这个不是必要条件,看各自的现实条件吧,不要让思维受限就好。

2.4 分析的关注点
在领域建模的过程中,我们需要重点关注这类业务的
语言
和
行为
。比如某些业务动作或行为(事件)是否会触发下一个业务动作,这个动作(事件)的输入和输出是什么?是谁(实体)发出的什么动作(命令),触发了这个动作(事件)… 我们可以从这些暗藏的词汇中,分析出领域模型中的事件、命令和实体等领域对象。

3. 事件风暴中的概念
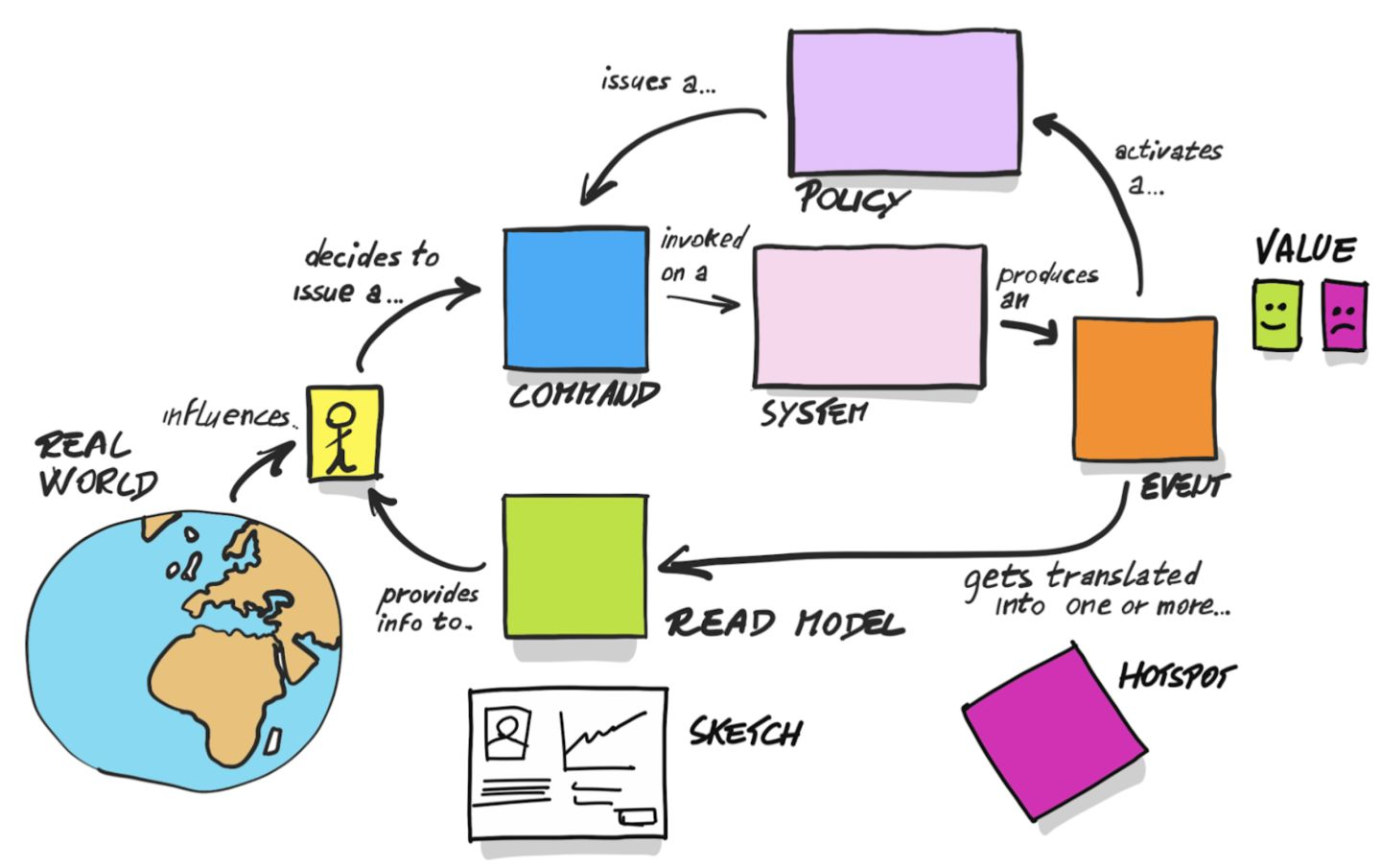
3.1 事件Event
领域事件(Domain Event):是领域专家关心的,在业务上真实发生的事件,这些事件对系统会产生重要的影响,如果没有这些事件的发生,整个业务逻辑和系统实现就不能成立。我们可以通过领域事件对过去发生的事情进行溯源,因为过去所发生的对业务有意义的信息都会通过某种形式保存下来。领域事件在技术实现过程中可以被实现为专门的事件类,便于实现事件驱动设计(Event Driven)。
注意:一般查询操作都不会触发事件的产生,所以查询操作不是事件,如点击了查询按钮显示了数据列表,一般情况下不会有类似于:数据已查询或列表已查询,这样的事件。事件是对系统产生了业务上的影响的动作,相对的,如果仅仅是数据查询操作,则只会对系统产生技术上的影响,如CPU上升或者内存上升等。
常见的影响有:
- 对内:产生了某种数据、触发了某种流程或事情状态发生了某种变化;
- 对外:发送了某些消息;
- 规则(Policy):是对分支条件或复杂业务规则的抽象,目的是通过降低分支复杂度聚焦主要业务流程,未来在技术实现时可能是一些分支条件,也可能应用适合的设计模式。
使用
正方形橘黄色
的贴纸表示,事件使用正方形橘黄色的贴纸表示,并且是过去式,如:商品已创建(Goods created),库存已增加(Inventory Increase)等。

3.2 热点Hotspot(IDEAS, RISKS)
热点表示不确定的点、有风险的点或者需要特别注意的点,一般贴在事件旁边,代表这件事情值得特别关注。
使用
紫色
的贴纸表示。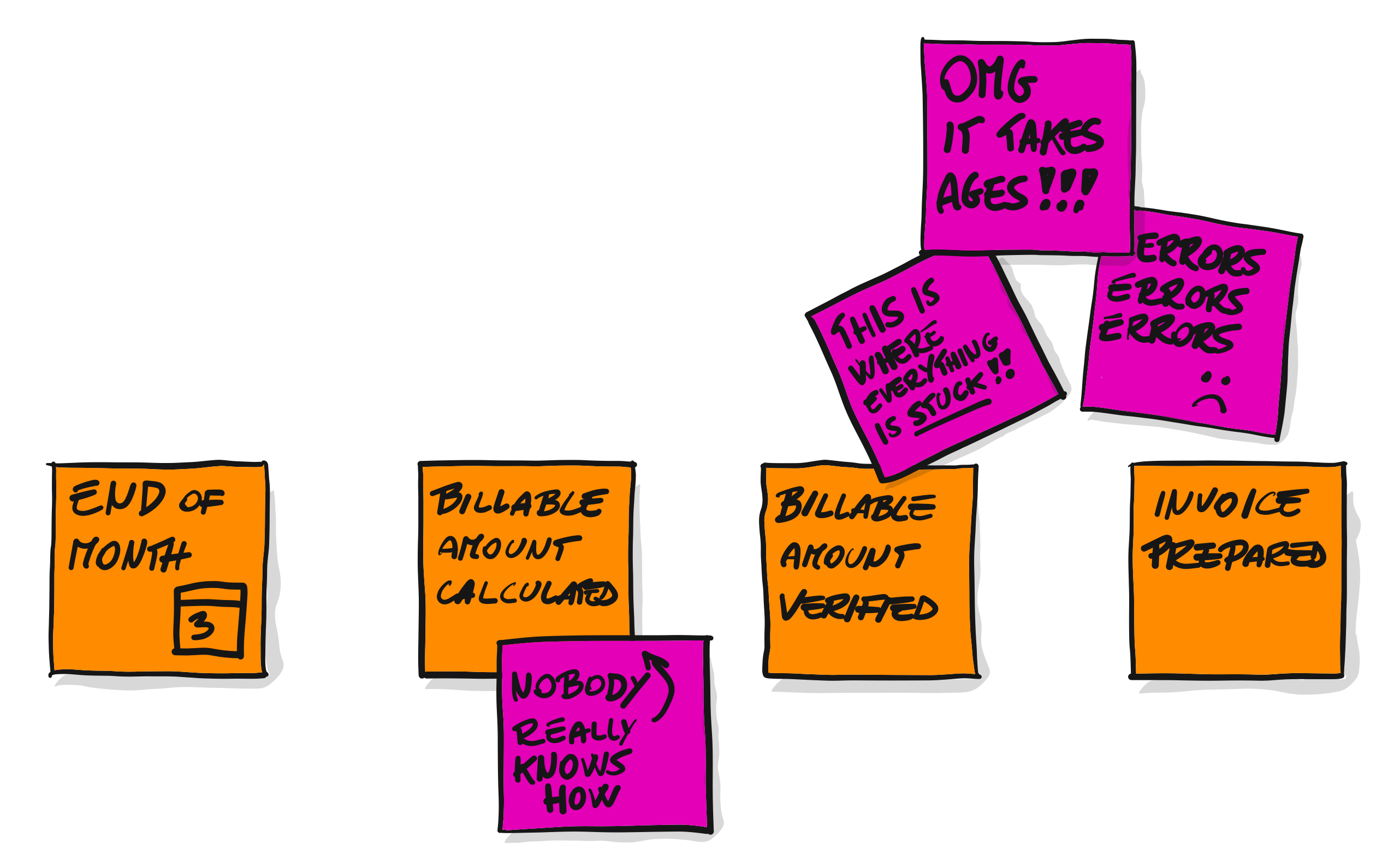
3.3 决策命令Command
决策命令产生了事件,可理解为产生事件的动作,与事件一一对应。如商品已创建(Goods created) 事件对应的决策命令就是添加商品(ADD Goods)。
决策命令用
正方形蓝色
贴纸表示,在实践中只需要将事件“反过来”就行了。

3.4 发起命令的参与者User/Actor
前面的决策命令一定是由某个人或系统来发起的。比如:前面的添加商品这个命令,是由运营人员这个Actor发起的,进而可以联想到可能整个系统中还会有客服、产品经理等。
注意:在Big-Picture Event Storming workshop的实践中,不将决策命令贴出来
使用
小长方形亮黄色
贴纸,结合Command和Event。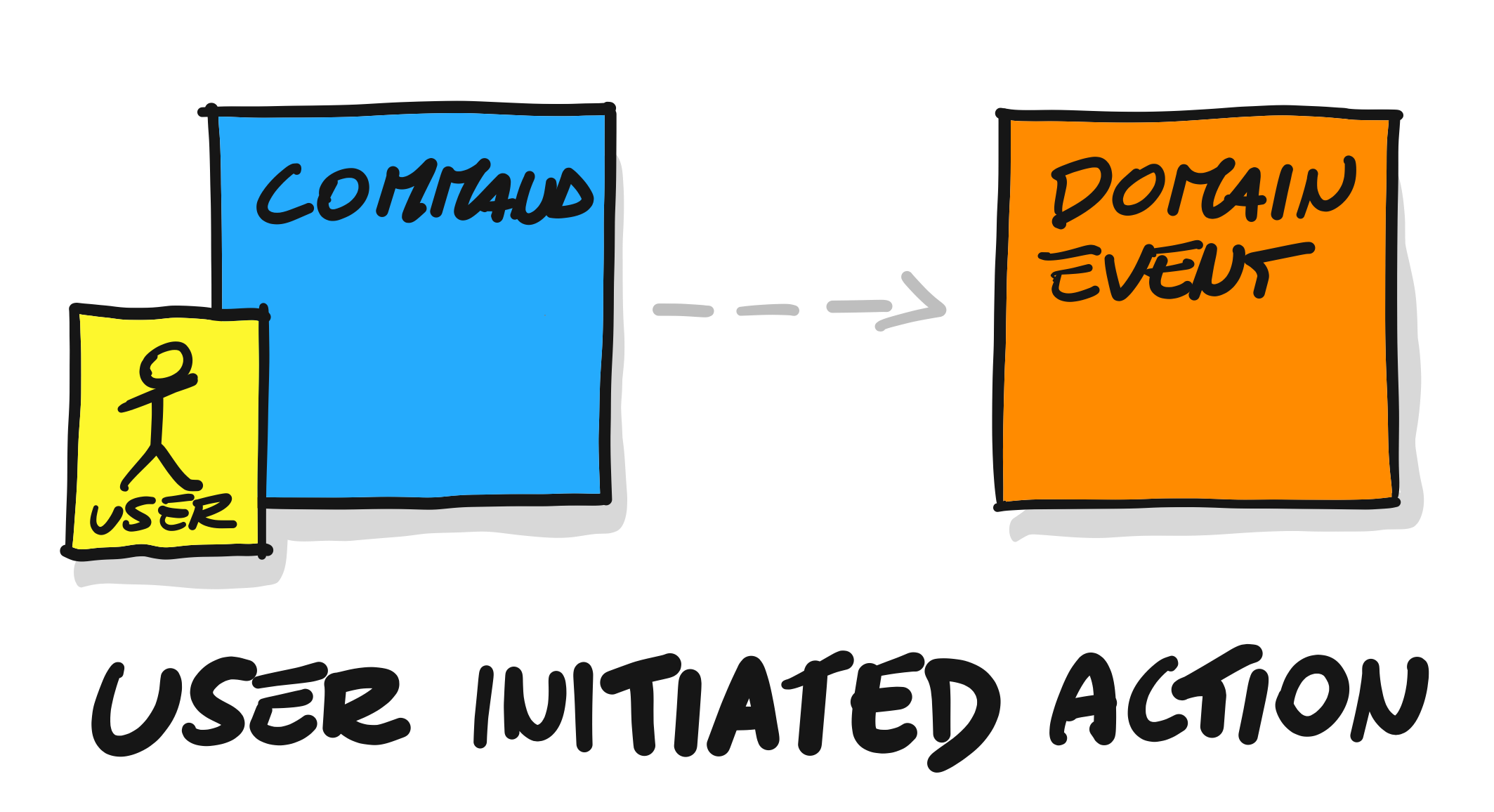
3.5 外部系统External System和规则Policy
Event不一定由前面所说的某个Actor触发Command而产生,也可能是由外部系统或者某种规则自动触发Command而产生。
外部系统使用
大长方形的粉红色
的贴纸表示,处理规则Policy使用
大长方形的紫色
的贴纸表示。

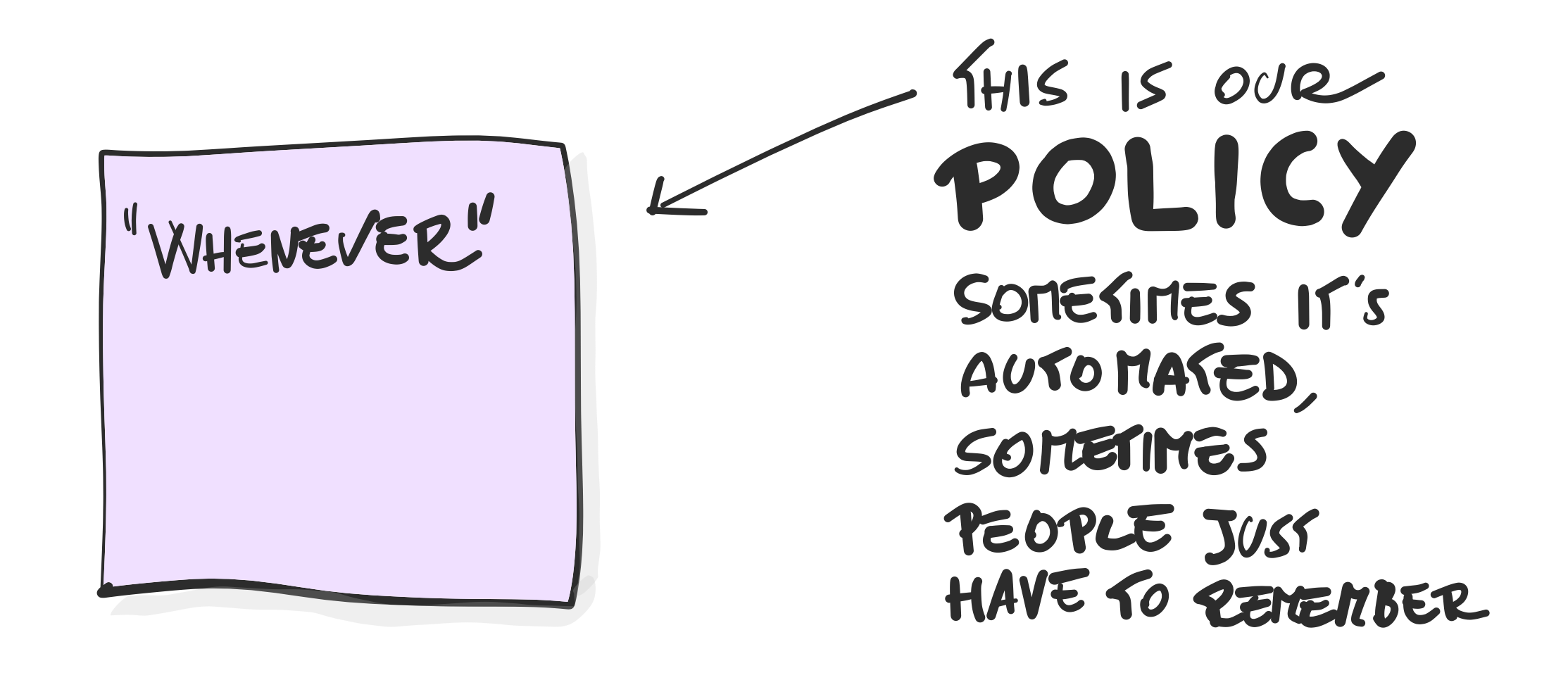
3.6 读模型Read Model
某个Actor做出决策Command的前提是需要看到某些信息,或者说,支撑Actor更容易做出决策命令Command的信息。读模型一般是通过Web页面(UI/UX)来展示更多的信息,以让用户更容易做出决策。
读模型用
绿色正方形
的贴纸来表示。
3.7 聚合Aggregate
某个Actor在某个聚合调用某种Command产生了某个Event。比如前面的商品已创建事件,是由 运营人员 在 商品管理 上调用 添加商品 这个命令而产生。
聚合使用
大长方形的黄色
的贴纸表示。
下面看一个非常简单的聚合:
3.8 整体解释
一个 Actor 根据看到的 Query Model/Information,决定对External System 或者 Aggregate 执行一个 Command/Action,进而产生了某种 Domain Event。此 Domain Event 可能触发了某种 Policy,此 Policy 可能又对 External System 或者 Aggregate 执行一个 Command/Action。此 Domain Event 也可能会导致 Query Model/Information 发生变化,从而给 Actor 提供更多信息以进行其他操作。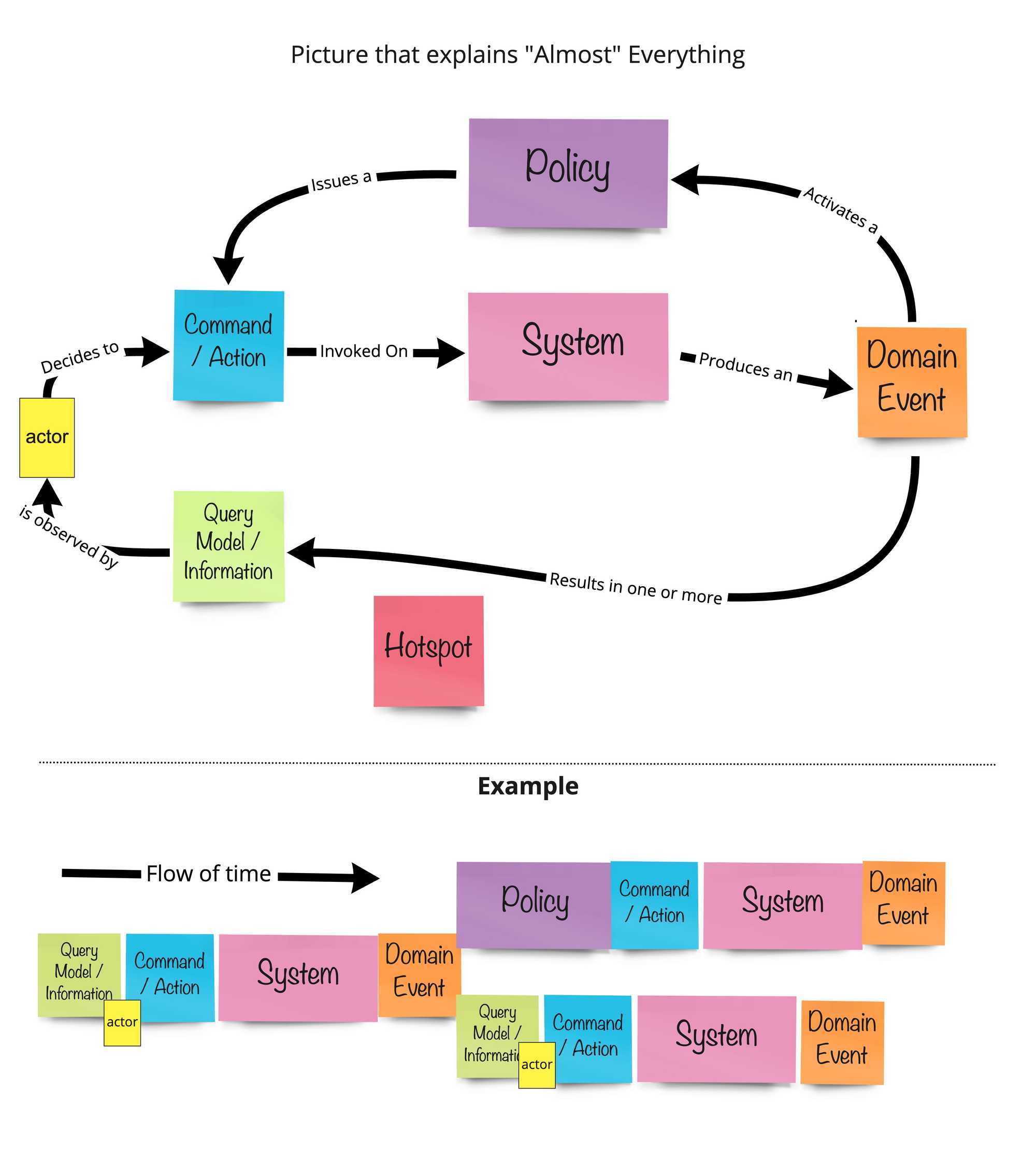
4. 如何用事件风暴构建领域模型?
领域模型是对领域内的概念类或现实世界中对象的可视化表示。又称概念模型、领域对象模型、分析对象模型。它专注于分析问题领域本身,发掘重要的业务领域概念,并建立业务领域概念之间的关系。 @百科
事件风暴的核心流程就是由用户执行了命令,从而产生了事件。基于这个事件的结果,与之前相同或是其他的用户会执行另一个命令,产生新类型的事件,以此类推。而顺序是按照业务逻辑而定的。
4.1 识别领域事件
事件风暴是一项团队活动,首先:领域专家和项目成员都聚集在大会议室里,准备好贴纸和水笔,通过头脑风暴的形式把领域中的领域事件(业务行为)都贴到墙上,形成最终的
领域事件
集合。
以电商为例我们得到以下领域事件集合:
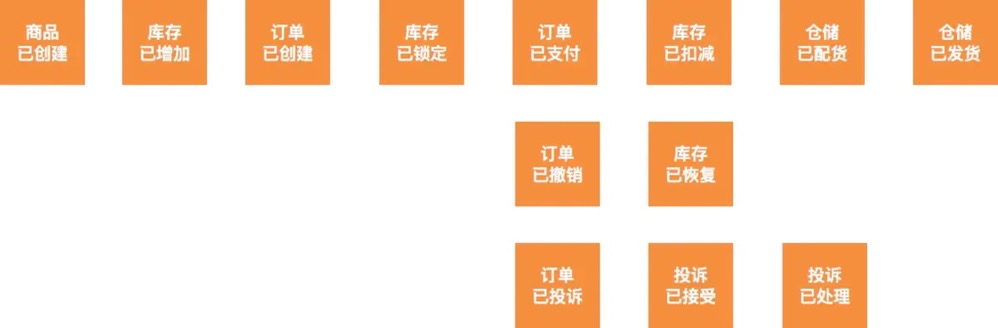
PS:使用
主语+定语
的
正方形橘黄色
贴纸来描述领域事件,如“订单已创建”。
4.2 识别命令
在 4.1 中,我们已经识别出了部分领域事件,那么这些事件是谁触发的呢?触发的动作又是什么?这就是下一步动作:
识别命令
。
命令可以理解为不同角色用户在界面上面的操作,比如“添加商品”,“编辑库存”,“提交订单”等; 有些命令可能产生多个事件,可以将他们用箭头联系起来:
PS:
蓝色
贴纸来标识命令,
黄色
贴纸来标识角色。
4.3 提取领域对象(实体)
从命令和领域事件中提取产生这些业务行为的业务对象,即实体。一个简单的做法是把领域事件中的名词都提取出来,如“商品已创建”中的“商品”、“订单已创建”中的“订单”、“库存已锁定”中的“库存”等都是
领域对象
:

PS:
黄色
贴纸来标识这些实体。
实体(Entity)和值对象(Value Object)是DDD中非常重要的基础领域对象:
实体(Entity):拥有唯一标识符,并且它们的标识符在历经各种状态变更后仍能保持一致,对这些对象而言,重要的不是属性,而是其延续性和标识,这种对象的延续性和标识会跨越甚至超出软件的生命周期,这样的对象就是实体对象。例如:订单 - 有作为唯一标识的订单号。
值对象(Value Object):值对象是通过对象属性值来识别的对象,它将多个相关属性组合为一个概念整体,用于描述领域的某个特定方面,并且是一个没有标识符的对象。例如:订单中的收货地址 - 有姓名、电话、省市区、详细地址等属性字段,被订单这个实体引用。
4.4 构建聚合
实体和值对象都只是个体化的业务对象,它们所表现出来的是个体的行为和能力。在领域模型中我们需要一个这样的组织,将这些紧密关联的个体对象聚集在一起,按照组织内统一的业务规则共同完成特定的业务功能,因此就有了
聚合
的概念。
在DDD中,聚合是一组紧密相关的领域对象,其目的**是要确保业务规则在边界内的不变性,保证
数据的一致性
,聚合根具有全局标识,所有对聚合内对象的修改,都只能通过聚合根进行,聚合帮助我们简化了复杂的对象网络,逐步做到微服务的“
高内聚,低耦合
**”。
从技术的角度可以这么理解,聚合是由业务和逻辑紧密关联的实体和值对象组合而成的。聚合内数据的修改必须由聚合根统一组织,以确保每次数据修改都是按照聚合内统一的业务规则来完成,聚合是数据修改和持久化的基本单元,每一个聚合对应一个仓储,实现 **
数据的持久化
** 。
比如订单是个聚合,它是由订单基本信息、商品信息、地址信息、发票信息等多个实体组成的,在订单聚合内每次修改商品数据时,它们都必须符合订单聚合的业务规则:“订单总金额等于所有商品明细金额之和”,违反了这个规则就会出现聚合数据不一致等诸多问题。
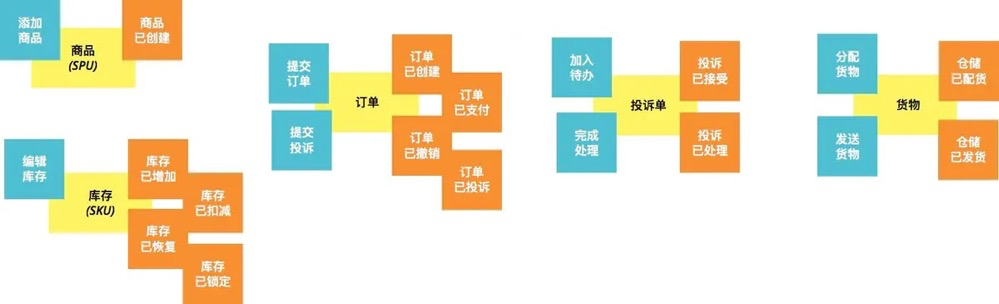
4.5 划定边界上下文
限界上下文
(Boundary Context),是业务上下文的边界,在该边界内,当我们去交流某个业务概念时,不会产生理解和认知上的歧义(二义性),限界上下文是统一语言的重要保证。
一个聚合可能是最小颗粒度的界限上下文,同时,我们常合并业务相关性很高的聚合。
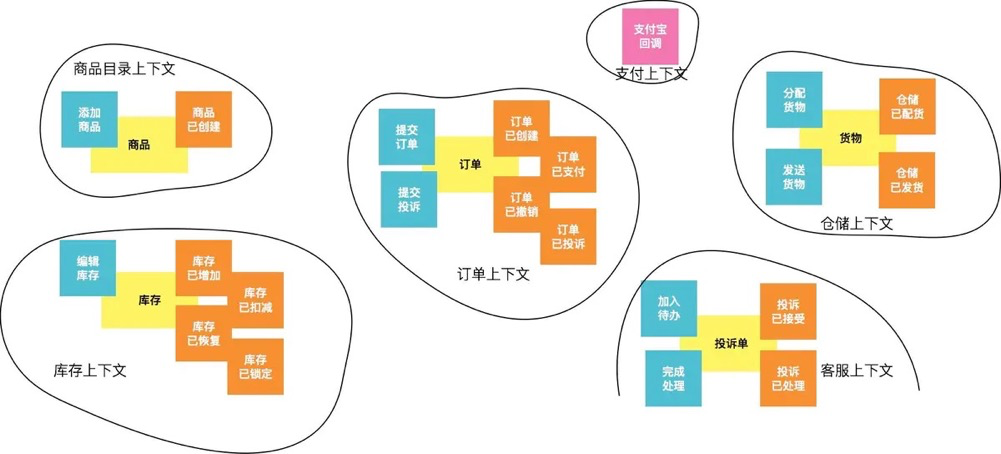
在未来的技术实现中,应当尽可能避免两个在概念上容易混淆的限界上下文内的业务需求,被同一个团队开发和维护。
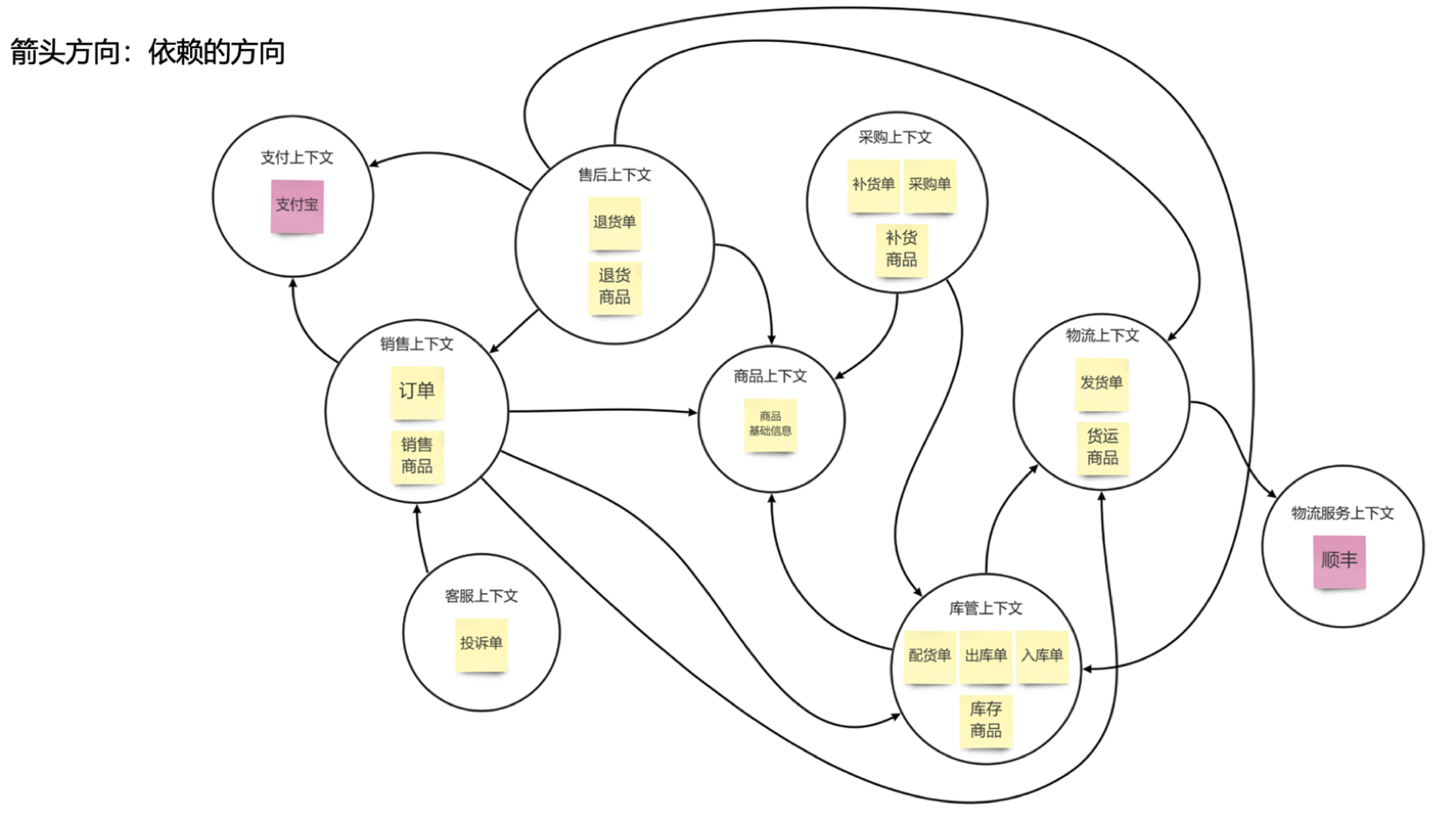
4.6 梳理限界上下文依赖关系
通过分析依赖关系,提前识别依赖矛盾,减少低级设计错误的手段。每一个限界上下文都不会带有全量信息,那么补充信息的来源方向就是依赖方向,或者叫“知道(known)”的方向(我需要知道它的存在)。
操作步骤:
- 集体分析和讨论,并利用带箭头的实线,以依赖方向为箭头方向,绘制不同限界上下文间的依赖关系。
- 若出现以下依赖关系,需要思考是否存在未澄清的问题:
(1)双向依赖:上下文之间缺少一层未被澄清的上下文,或者两个上下文其实可被合为一个;
(2)循环依赖:任何一个上下文发生变更,依赖链条上的上下文均需要改变;
(3)过长的依赖:自身依赖的信息不能直接从依赖者获取到,需要通过依赖者从其依赖的上下文获取并传递,依赖链路过长,依赖链条上的任何一个上下文发生变更,其链条后的任何一个上下文均可能需要改变。
4.7 划分问题子域建立服务地图
步骤:
- 根据 “每一个问题子域负责解决一个有独立业务价值的业务问题” 的视角出发,可以通过疑问句的方式来澄清和分析子域需要解决的业务问题,例如“如何进行库存管理?(英文描述类似 How to…?)”。
- 利用虚线,将解决同一个业务问题的限界上下文以切割图像的方式划在一起,并以 “XXX子域” 的形式对每个子域进行命名。
- 根据三种类型的子域定义,共同结合业务实际(或者参考设计思维中的电梯演讲),确定每个子域的子域类型。
PS:
- 问题子域和限界上下文是完全不同的两个维度,问题子域解决的是问题澄清和优先级排序问题,限界上下文解决的是业务边界识别和统一语言的问题,所以在概念上其实不存在先后关系和包含关系,将两张图放在一起,是为了能够方便设和分析,可以理解为两张图的“叠加”或“映射”。
- 对于问题子域和限界上下文的映射关系,业内存在争论(是一对多关系还是多对多关系),经过大量的实践,结合可操作性和理解上的便易性,我们刻意地选择和约定以下的映射关系:
(1)一个子域可以包含多个限界上下文
(2)一个限界上下文不应跨越多个子域 对于子域类型的判断,会随着视角的切换而有所变化,例如从全局视角识别的支撑域,从该支撑域所负责开发的团队视 角来看,该域则属于这个团队的核心域。
- 可以先识别核心域,再识别通用域,这样的话最后剩下的就全都是支撑域。
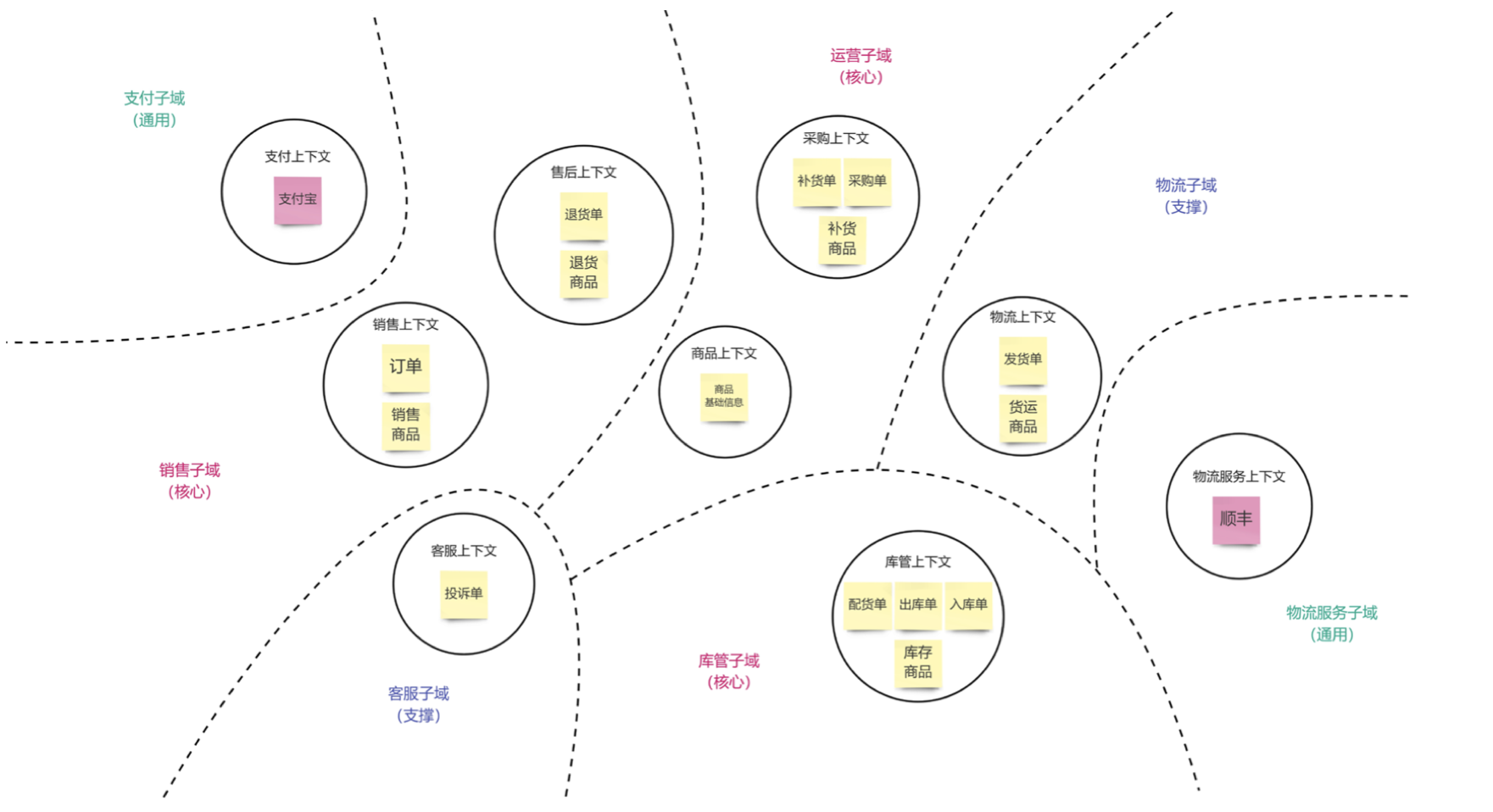
至此,我们就完成了电商领域模型的构建了。
案例来源:事件风暴
版权归原作者 没对象的指针 所有, 如有侵权,请联系我们删除。