
目录
一、背景
作为当下最流行的web UI自动化测试工具,selenium是很多测试同学入门接触自动化测试时学习的第一个工具。想要自动化操作页面上的内容,元素定位是首先必须要学习的核心知识。
因此本文主要介绍selenium的几种最常用的元素定位方法,掌握了这些方法,希望能帮助大家快速轻松定位到页面上的各类元素。如果对你有帮助,欢迎关注我的vx公众号:程序员杨叔。
二、浏览器定位元素
首先我们以最常见的百度首页为例,假设我们的操作是想要往搜索框内输入关键字,看看如何定位到搜索框。
先打开百度首页,然后F12调出浏览器调试台,然后如图中所示定位到搜索框:
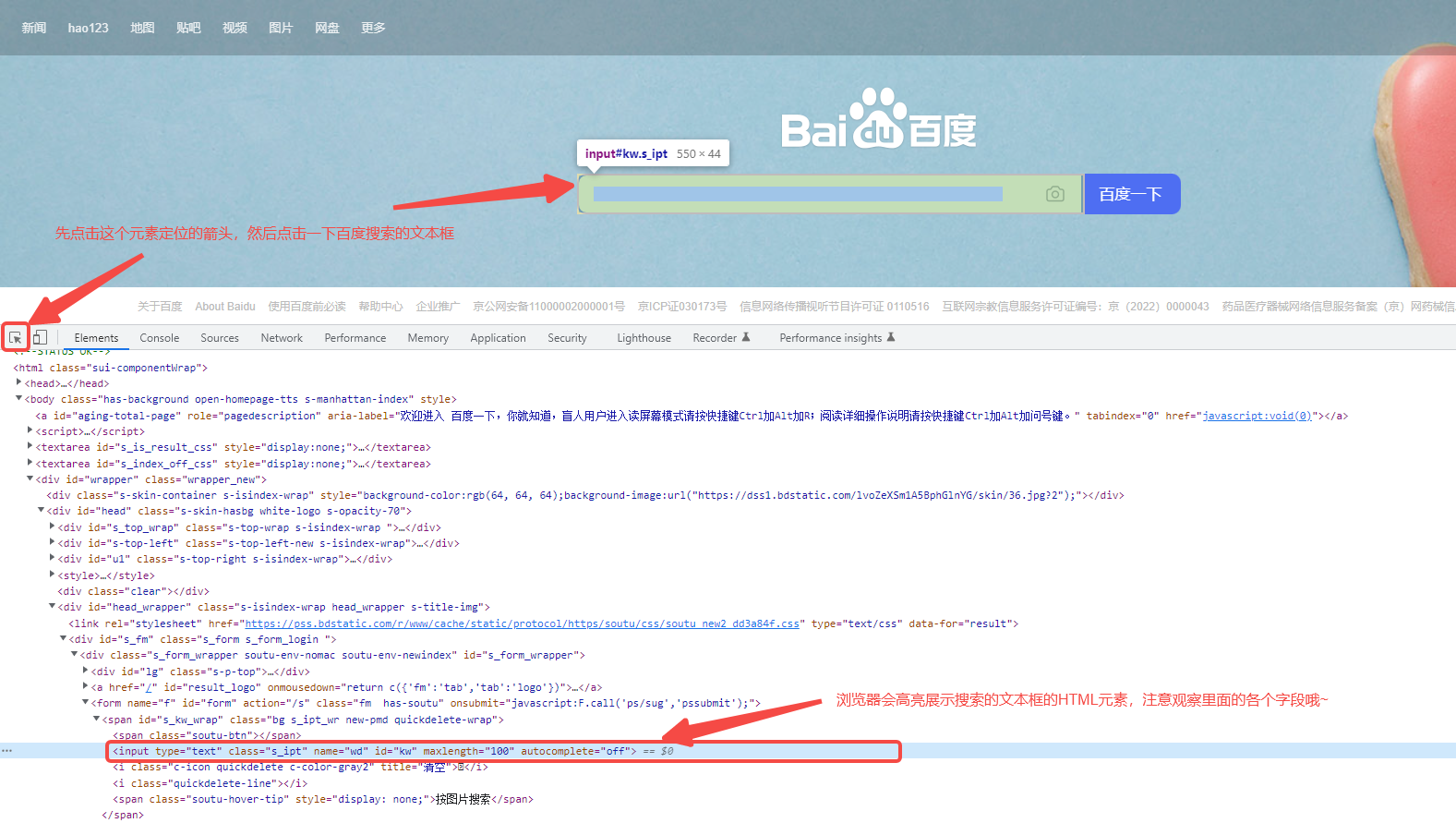
注意观察HTML元素的各个字段,接下来主要就依靠这些字段来定位到元素:
1. tagName:input
2. type:text
3. class:s_ipt
4. name: wd
5. id: kw
6. maxlength: 1007. autocomplete: off
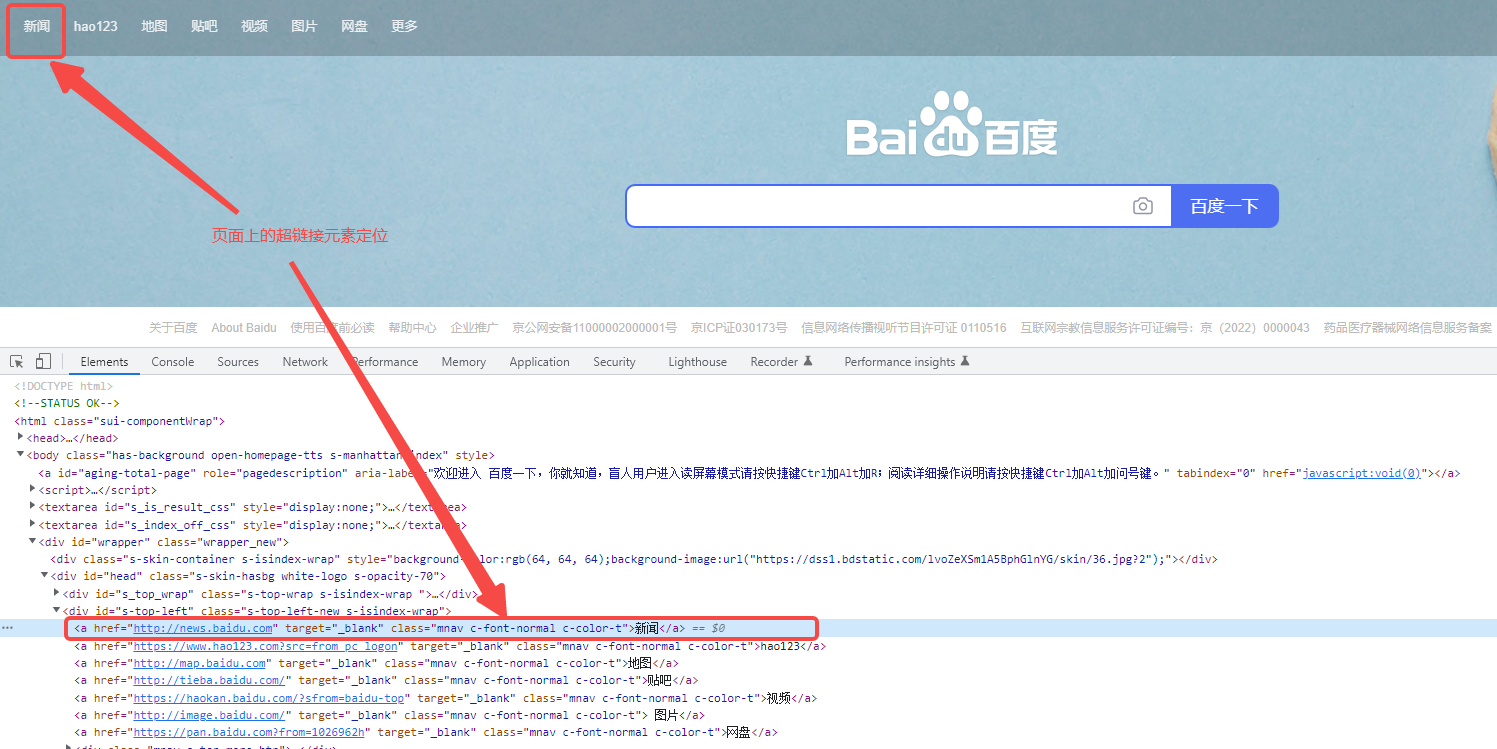
页面上的超链接元素定位:
三、Selenium元素定位代码
3.1 通过id定位
ele = driver.find_element_by_id("kw")
3.2 通过class定位
ele = driver.find_element_by_class_name("s_ipt")
3.3 通过name定位
ele = driver.find_element_by_name("name")
3.4 通过tagname定位
ele = driver.find_element_by_tag_name("input")
一个页面中所有的文本框的tagname都是input,太不唯一,所以一般不会用
3.5 通过link_text定位
ele = driver.find_element_by_link_text("新闻")
只能是超链接标签的文本才能查,精准匹配
3.6 通过partial_link_text定位
ele = driver.find_element_by_partial_link_text("新")
只能是超链接标签的文本才能查,模糊匹配
3.7 通过css选择器定位
1、单一属性定位:
1. 通过id属性定位(#号表示通过id属性定位):
driver.find_element_by_css_selector('#kw')2. 通过class属性定位(.表示通过class属性定位):
driver.find_element_by_css_selector('.s_ipt')3. 通过其他属性定位([]表示通过其他属性定位):
driver.find_element_by_css_selector("[name='wd']")
driver.find_element_by_css_selector("[type='text']")
2、组合属性定位:
1. id组合属性定位
driver.find_element_by_css_selector("input#kw")2. class组合属性定位
driver.find_element_by_css_selector("input.s_ipt")3. 其他属性组合定位
driver.find_element_by_css_selector("input[name='wd']")4. 两个其他属性组合定位
driver.find_element_by_css_selector("[name='wd'][autocomplete='off']")
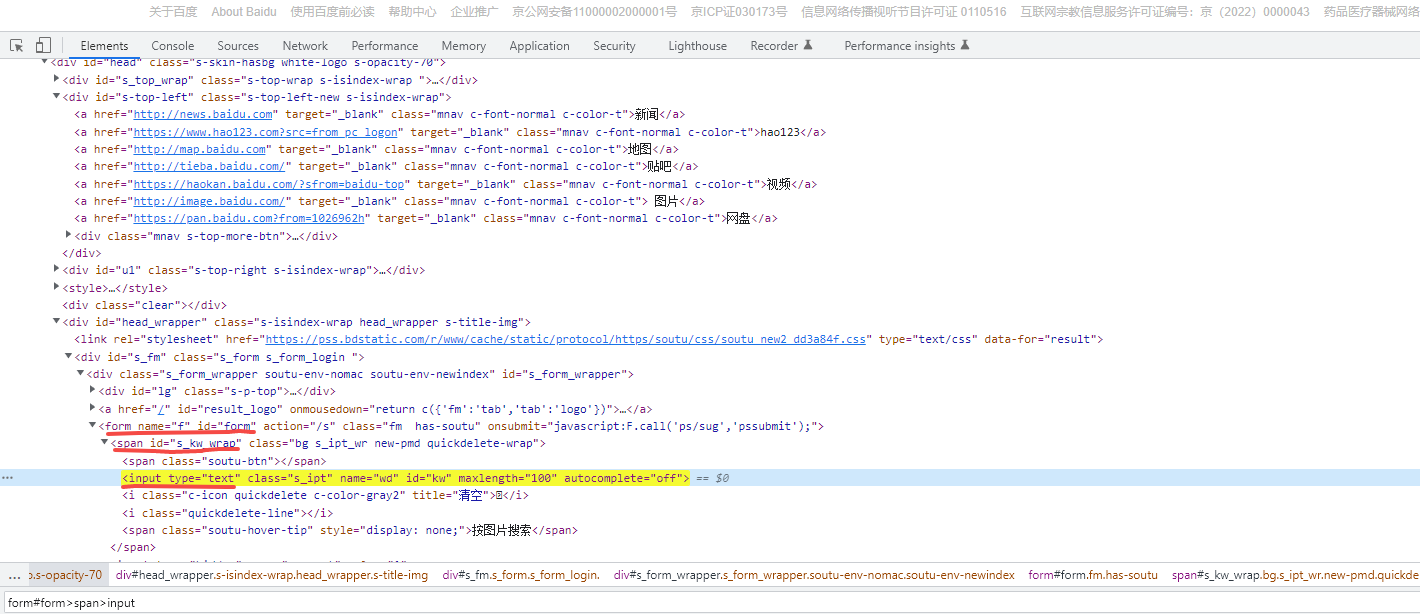
3、通过层级定位:
#id是form的form下面的span下面的input
driver.find_element_by_css_selector('form#form>span>input')
4、模糊匹配属性值定位:

1. 匹配属性值以xx字符串开头的方法:
driver.find_element_by_css_selector("input[class^='s']")2. 匹配属性值以xx字符串结尾的方法:
driver.find_element_by_css_selector("input[class$='ipt']")
3.8 通过xpath表达式查找
表达式描述/绝对路径,从根节点选取。严格按照路径、同级元素的位置来定位,缺点:页面一动,基本崩溃//相对路径,根据表达式匹配页面中有还是没有符合表达式的元素,缺点:可能有多个符合的元素.选取当前节点…选取当前节点的父节点@选取属性[ ]表示进一步的表达式通配符描述*匹配任何元素节点@*匹配任何属性节点node()匹配任何类型的节点。
1、利用标签内属性进行定位:
xpath ="//标签名[@属性='属性值']"
查找span标签的下级标签为input的并且属性id为kw的元素:
1. xpath = driver.find_element_by_xpath("//input[@id= 'kw' ]")
属性判断条件:最常见为id,name,class等等,属性的类别没有特殊限制,只要能够唯一标识一个元素即可。当某个属性不足以唯一区别某一个元素时,也可以采取多个条件组合的方式,如下:
1. xpath ="//input[@type='text' and @name='wd']"
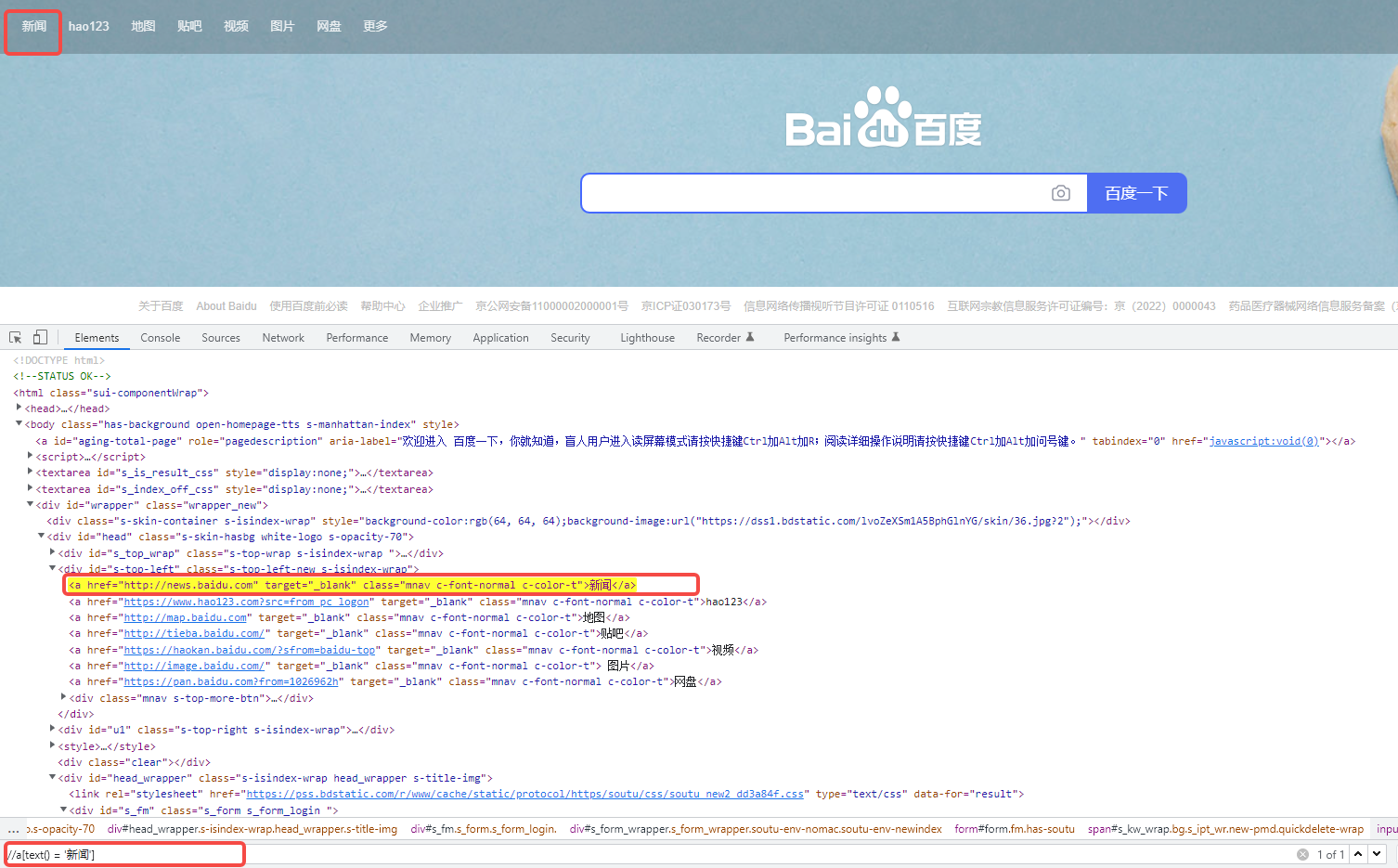
2、利用text()方法文本定位:
//a[text()='新闻']
//a[text()='新闻'][1] :表示使用找到的第一个,索引从1开始,不是0
3、利用contains()方法定位,也叫模糊定位:
xpath ="//标签名[contains(@属性, '属性值')]"1. 例:文本包含“新”
xpath = //a[contains(text(),'新')]2. class属性包含kd的
xpath = //a[contains(@class,'kd')]3. 通过下一级查找上一级:
xpath = //input[@id='kw']/.. :表示查找他的上一层
xpath = //input[@id='kw']/.. /.. :表示查找上两层
4. 如果一个元素无法通过自身属性直接定位到,则可以先定位它的父(或父的父)元素,然后再找下一级即可
xpath = //form[@id='form']/span[@class='bg s_ipt_wr new-pmd quickdelete-wrap']/input
四、总结
4.1 推荐的定位方式的优先级
- 优先级最高:ID
- 优先级其次:name
- 优先级再次:CSS selector
- 优先级再次:Xpath
4.2 css选择器和xpath的各自优劣势
- css是配合html来工作,它实现的原理是匹配对象的原理,而xpath是配合xml工作的,它实现的原理是遍历的原理,所以两者在设计上,css性能更优秀(ps:css选择器表达式在chrome、firefox解析速度快一些,xpath在ie浏览器解析速度快一些)
- 针对id或者name能够直接定位到的元素,css选择器表达式比xpath表达式更加简洁
- css选择器不支持文本搜索,但是xpath支持
- 当查找的元素比较简单时,使用css,复杂时使用xpath
4.3 通过浏览器快捷获取元素的css/xpath
浏览器也提供了快捷获取xpath的方式,可以方便快捷的获取到xpath,如下图所示:
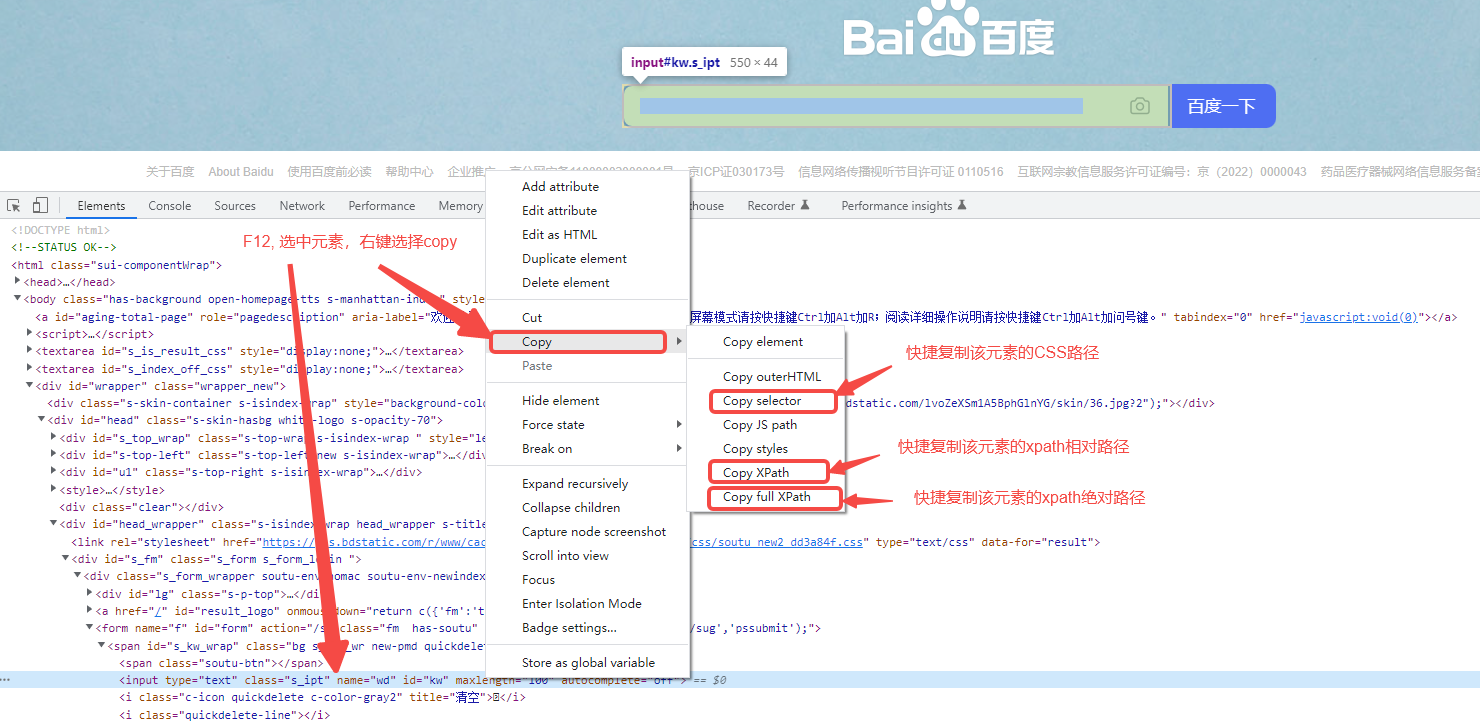
以上就是本次的全部内容,如果对你有帮助,欢迎关注我的vx公众号:程序员杨叔,各类文章都会第一时间在上面发布,持续分享全栈测试知识干货,你的支持就是作者更新最大的动力~
版权归原作者 程序员杨叔 所有, 如有侵权,请联系我们删除。