
WaitGroup
可以解决一个 goroutine 等待多个 goroutine 同时结束的场景,这个比较常见的场景就是例如 后端 worker 启动了多个消费者干活,还有爬虫并发爬取数据,多线程下载等等。
我们这里模拟一个 worker 的例子
package main
import("fmt""sync")funcworker(i int){
fmt.Println("worker: ", i)}funcmain(){var wg sync.WaitGroup
for i :=0; i <10; i++{
wg.Add(1)gofunc(i int){defer wg.Done()worker(i)}(i)}
wg.Wait()}
问题: 反过来支持多个 goroutine 等待一个 goroutine 完成后再干活吗? 看我们接下来的源码分析你就知道了
type WaitGroup struct{
noCopy noCopy
// 64-bit value: high 32 bits are counter, low 32 bits are waiter count.// 64-bit atomic operations require 64-bit alignment, but 32-bit// compilers do not ensure it. So we allocate 12 bytes and then use// the aligned 8 bytes in them as state, and the other 4 as storage// for the sema.
state1 [3]uint32}
WaitGroup
结构十分简单,由
nocopy
和
state1
两个字段组成,其中
nocopy
是用来防止复制的
type noCopy struct{}// Lock is a no-op used by -copylocks checker from `go vet`.func(*noCopy)Lock(){}func(*noCopy)Unlock(){}
由于嵌入了
nocopy
所以在执行
go vet
时如果检查到
WaitGroup
被复制了就会报错。这样可以一定程度上保证
WaitGroup
不被复制,对了直接 go run 是不会有错误的,所以我们代码 push 之前都会强制要求进行 lint 检查,在 ci/cd 阶段也需要先进行 lint 检查,避免出现这种类似的错误。
~/project/Go-000/Week03/blog/06_waitgroup/02 main*
❯ go run ./main.go
~/project/Go-000/Week03/blog/06_waitgroup/02 main*
❯ go vet .
# github.com/mohuishou/go-training/Week03/blog/06_waitgroup/02./main.go:7:9: assignment copies lock value to wg2: sync.WaitGroup contains sync.noCopy
state1
的设计非常巧妙,这是一个是十二字节的数据,这里面主要包含两大块,counter 占用了 8 字节用于计数,sema 占用 4 字节用做信号量
可以看出 state1 是一个元素个数为 3 个数组,且每个元素都是 占 32 bits
在 64 位系统里面,64位原子操作需要64位对齐
那么高位的 32 bits 对应的是 counter 计数器,用来表示目前还没有完成任务的协程个数
低 32 bits 对应的是 waiter 的数量,表示目前已经调用了 WaitGroup.Wait 的协程个数
那么剩下的一个 32 bits 就是 sema 信号量的了(后面的源码中会有体现)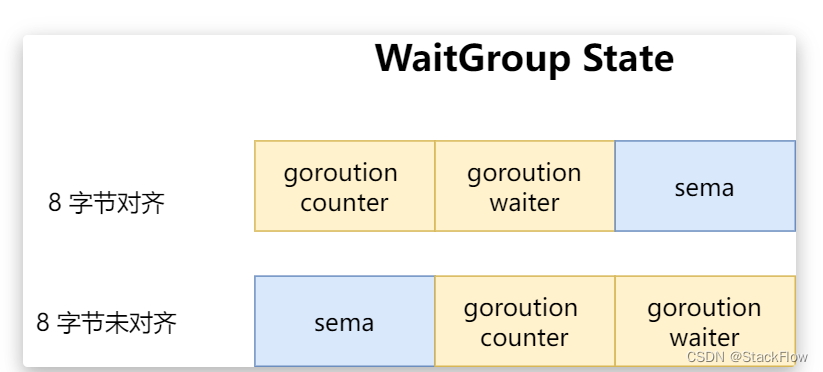
为什么要这么搞呢?直接用两个字段一个表示 counter,一个表示 sema 不行么?
不行,我们看看注释里面怎么写的。
// 64-bit value: high 32 bits are counter, low 32 bits are waiter count. > // 64-bit atomic operations require 64-bit alignment, but 32-bit > // compilers do not ensure it. So we allocate 12 bytes and then use > // the aligned 8 bytes in them as state, and the other 4 as storage > // for the sema.
这段话的关键点在于,在做 64 位的原子操作的时候必须要保证 64 位(8 字节)对齐,如果没有对齐的就会有问题,但是 32 位的编译器并不能保证 64 位对齐所以这里用一个 12 字节的 state1 字段来存储这两个状态,然后根据是否 8 字节对齐选择不同的保存方式。
此处我们可以看到 , state 函数是 返回存储在 wg.state1 中的状态和 sema字段 的指针
这里需要重点注意 state() 函数的实现,有 2 种情况
第 1 种 情况是,在 64 位系统下面,返回 sema字段 的指针取的是 &wg.state1[2] ,说明 64 位系统时,state1 数据排布是 : counter , waiter,sema
第 2 种情况是,32 位系统下面,返回 sema字段 的指针取的是 &wg.state1[0] ,说明 64 位系统时,state1 数据排布是 : sema ,counter , waiter
在 32 位机器上,uint64 类型的变量通常会被编译器按照 4 字节对齐,而不是 8 字节对齐。因此,如果 uint64
类型的变量没有按照 4 字节对齐,就可能会导致原子操作失败。在 32 位机器上,64 位原子操作需要使用两个 32 位的寄存器来完成,如果 uint64 类型的变量没有按照 4字节对齐,那么在读取或者写入 uint64 类型变量时,就可能会跨越两个 32位寄存器,从而导致原子操作失败。这种情况下,编译器可能会将多个 32 位读写操作组合成一个 64 位操作,或者使用特殊的汇编指令来实现原子性,但这样会增加代码的复杂度和性能开销。
为了避免这种问题,sync.WaitGroup 在 32 位机器上使用了一个包含 3 个 uint32
元素的数组来表示状态,其中前两个元素占用了 8 字节,可以按照 uint64 对齐,从而可以使用 64
位原子操作来保证状态的原子性。这种设计方式既可以在 32 位机器上保证状态的原子性,也可以在 64 位机器上提高程序的性能。
这个操作巧妙在哪里呢?
- 如果是 64 位的机器那肯定是 8 字节对齐了的,所以是上面第一种方式
- 如果在 32 位的机器上 - 如果恰好 8 字节对齐了,那么也是第一种方式取前面的 8 字节数据- 如果是没有对齐,但是 32 位 4 字节是对齐了的,所以我们只需要后移四个字节,那么就 8 字节对齐了,所以是第二种方式
所以通过 sema 信号量这四个字节的位置不同,保证了 counter 这个字段无论在 32 位还是 64 为机器上都是 8 字节对齐的,后续做 64 位原子操作的时候就没问题了。
这个实现是在
state
方法实现的
golang 这样用,主要原因是 golang 把 counter 和 waiter 合并到一起统一看成是 1 个 64位的数据了,因此在不同的操作系统中
由于字节对齐的原因,64位系统时,前面 2 个 32 位数据加起来,正好是 64 位,正好对齐
对于 32 位系统,则是 第 1 个 32 位数据放 sema 更加合适,后面的 2 个 32 位数据就可以统一取出,作为一个 64 位变量
为什么要counter和waiter合一起?不能用三个变量吗
- 在并发编程中,多个 goroutine可能会同时访问共享的变量,这种并发访问可能会导致竞态条件,从而导致程序出现意料之外的结果。为了保证并发程序的正确性,需要使用同步原语来协调不同
- 首先,sync.WaitGroup 的状态包含两个值:计数器和等待的 goroutine 数量。在并发程序中,对于这两个值的修改必须是原子的,否则会导致竞态条件。如果使用两个单独的 uint32 变量来表示这两个值,那么在对它们进行增减操作时,必须使用互斥锁或原子操作来保证它们的原子性。而使用一个 uint32 数组,则可以使用原子操作来同时修改这两个值,从而避免了互斥锁的开销。
- goroutine 的访问,其中原子操作是一种常用的同步原语。 原子操作是一种基本的操作,它可以在一个步骤内完成读取和修改操作,从而保证了操作的原子性。在 Go 中,原子操作主要通过 sync/atomic 包提供。
sync/atomic 包提供了一系列原子操作,包括原子读写、原子增减、原子比较交换等等。这些原子操作可以被多个 goroutine
并发调用,而不会导致竞态条件。在底层实现上,sync/atomic 包使用了 CPU 提供的原子指令,通过锁总线或者其他硬件机制来保证多个
CPU 同时访问一个共享变量时的原子性。
func(wg *WaitGroup)state()(statep *uint64, semap *uint32){ifuintptr(unsafe.Pointer(&wg.state1))%8==0{return(*uint64)(unsafe.Pointer(&wg.state1)),&wg.state1[2]}else{return(*uint64)(unsafe.Pointer(&wg.state1[1])),&wg.state1[0]}}
state
方法返回 counter 和信号量,通过
uintptr(unsafe.Pointer(&wg.state1))%8 == 0
来判断是否 8 字节对齐
func(wg *WaitGroup)Add(delta int){// 先从 state 当中把数据和信号量取出来
statep, semap := wg.state()// 在 waiter 上加上 delta 值
state := atomic.AddUint64(statep,uint64(delta)<<32)// 取出当前的 counter
v :=int32(state >>32)// 取出当前的 waiter,正在等待 goroutine 数量
w :=uint32(state)// counter 不能为负数if v <0{panic("sync: negative WaitGroup counter")}// 这里属于防御性编程// w != 0 说明现在已经有 goroutine 在等待中,说明已经调用了 Wait() 方法// 这时候 delta > 0 && v == int32(delta) 说明在调用了 Wait() 方法之后又想加入新的等待者// 这种操作是不允许的if w !=0&& delta >0&& v ==int32(delta){panic("sync: WaitGroup misuse: Add called concurrently with Wait")}// 如果当前没有人在等待就直接返回,并且 counter > 0if v >0|| w ==0{return}// 这里也是防御 主要避免并发调用 add 和 waitif*statep != state {panic("sync: WaitGroup misuse: Add called concurrently with Wait")}// 唤醒所有 waiter,看到这里就回答了上面的问题了*statep =0for; w !=0; w--{runtime_Semrelease(semap,false,0)}}
Add 函数主要功能是将 counter +delta ,增加等待协程的个数:
我们可以看到 Add 函数,通过 state 函数获取到 上述 64位的变量(counter 和 waiter) 和 sema 信号量后,通过 atomic.AddUint64 函数 将 delta 数据 加到 counter 上面
这里为什么是 delta 要左移 32 位呢?
上面我们有说到嘛, state 函数拿出的 64 位变量,高 32 bits 是 counter,低 32 bits 是waiter,此处的 delta 是要加到 counter 上,因此才需要 delta 左移 32 位
wait 主要就是等待其他的 goroutine 完事之后唤醒
func(wg *WaitGroup)Wait(){// 先从 state 当中把数据和信号量的地址取出来
statep, semap := wg.state()for{// 这里去除 counter 和 waiter 的数据
state := atomic.LoadUint64(statep)
v :=int32(state >>32)
w :=uint32(state)// counter = 0 说明没有在等的,直接返回就行if v ==0{// Counter is 0, no need to wait.return}// waiter + 1,调用一次就多一个等待者,然后休眠当前 goroutine 等待被唤醒if atomic.CompareAndSwapUint64(statep, state, state+1){runtime_Semacquire(semap)if*statep !=0{panic("sync: WaitGroup is reused before previous Wait has returned")}return}}}
这个只是 add 的简单封装
func(wg *WaitGroup)Done(){
wg.Add(-1)}
WaitGroup可以用于一个 goroutine 等待多个 goroutine 干活完成,也可以多个 goroutine 等待一个 goroutine 干活完成,是一个多对多的关系 - 多个等待一个的典型案例是 singleflight,这个在后面将微服务可用性的时候还会再讲到,感兴趣可以看看源码Add(n>0)方法应该在启动 goroutine 之前调用,然后在 goroution 内部调用Done方法WaitGroup必须在Wait方法返回之后才能再次使用Done只是Add的简单封装,所以实际上是可以通过一次加一个比较大的值减少调用,或者达到快速唤醒的目的。
版权归原作者 StackFlow 所有, 如有侵权,请联系我们删除。