
一、简介
开源项目,文本提示的生成音频模型
https://github.com/suno-ai/bark
Bark是由Suno创建的基于变换器的文本到音频模型。Bark可以生成极为逼真的多语种演讲以及其他音频 - 包括音乐、背景噪音和简单的声音效果。该模型还可以产生非言语沟通,如笑声、叹息和哭声。为了支持研究社区,我们提供了预训练的模型检查点,可用于推断,并可供商业使用。
二、演示链接:
https://pan.baidu.com/s/1O9_la6TBar75NfI1yut4Lg?pwd=utqg 提取码: utqg
三、支持的语言
LanguageStatusEnglish (en)✅German (de)✅Spanish (es)✅French (fr)✅Hindi (hi)✅Italian (it)✅Japanese (ja)✅Korean (ko)✅Polish (pl)✅Portuguese (pt)✅Russian (ru)✅Turkish (tr)✅Chinese, simplified (zh)✅
显卡信息
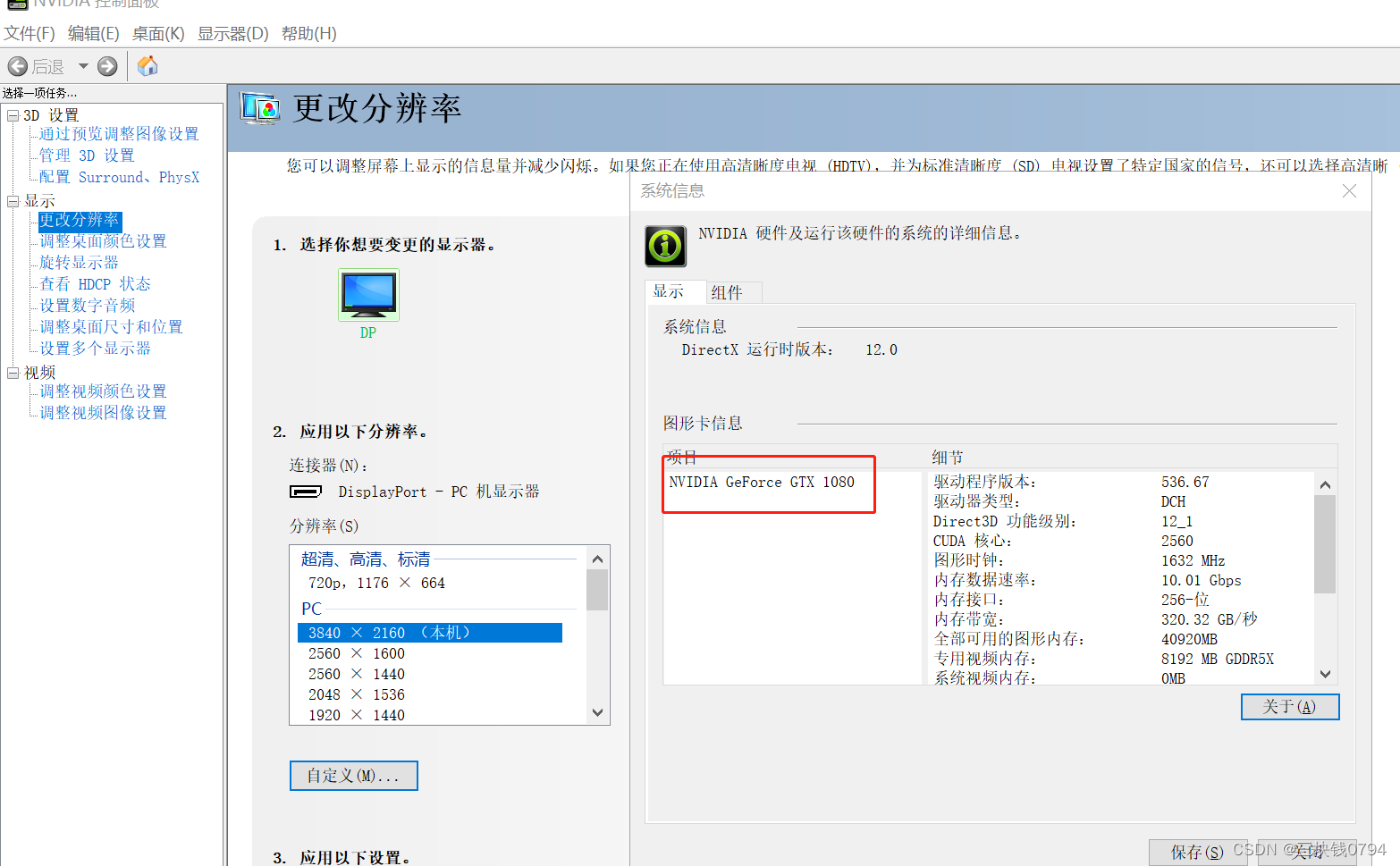
四、安装步骤
1.安装conda
2.安装python3.9
conda create --name brakAI python=3.9
3.激活brakAI环境
conda activate barkAI
4.安装 pytorc
conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.7 -c pytorch -c nvidia
5.查看了版本
import torch
print(torch.cuda.is_available())
print(torch.__version__)

6.克隆bark
git clone https://github.com/suno-ai/bark
cd bark && pip install .
7.测试
from bark import SAMPLE_RATE, generate_audio, preload_models
from scipy.io.wavfile import write as write_wav
from IPython.display import Audio
# download and load all models
preload_models()
# generate audio from text
text_prompt = """
CSDN是全球知名中文IT技术交流平台,创建于1999年,包含原创博客、精品问答、职业培训、技术论坛、资源下载等产品服务,提供原创、优质、完整内容的专业IT技术开发社区.。
"""
audio_array = generate_audio(text_prompt)
# save audio to disk
write_wav("bark_generation22.wav", SAMPLE_RATE, audio_array)
# play text in notebook
Audio(audio_array, rate=SAMPLE_RATE)
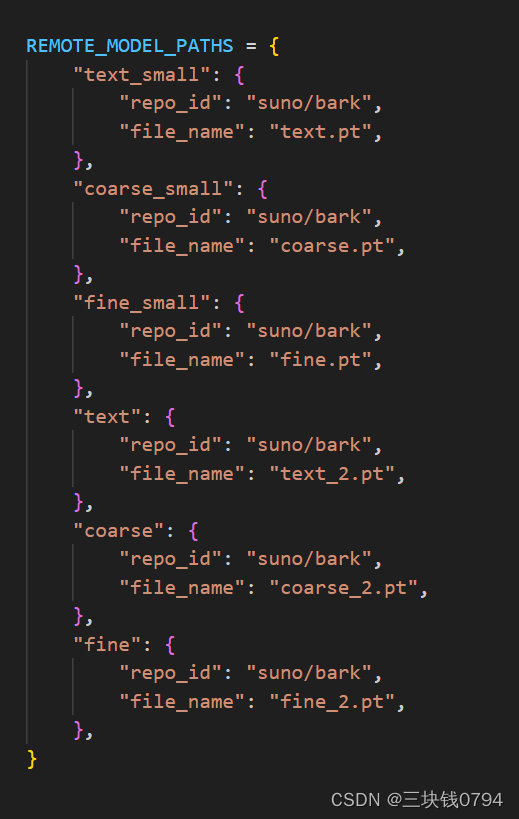
会自动下载模型文件text_2.pt,也可以自己下载suno/bark at main
模型路径 bark/generation.py
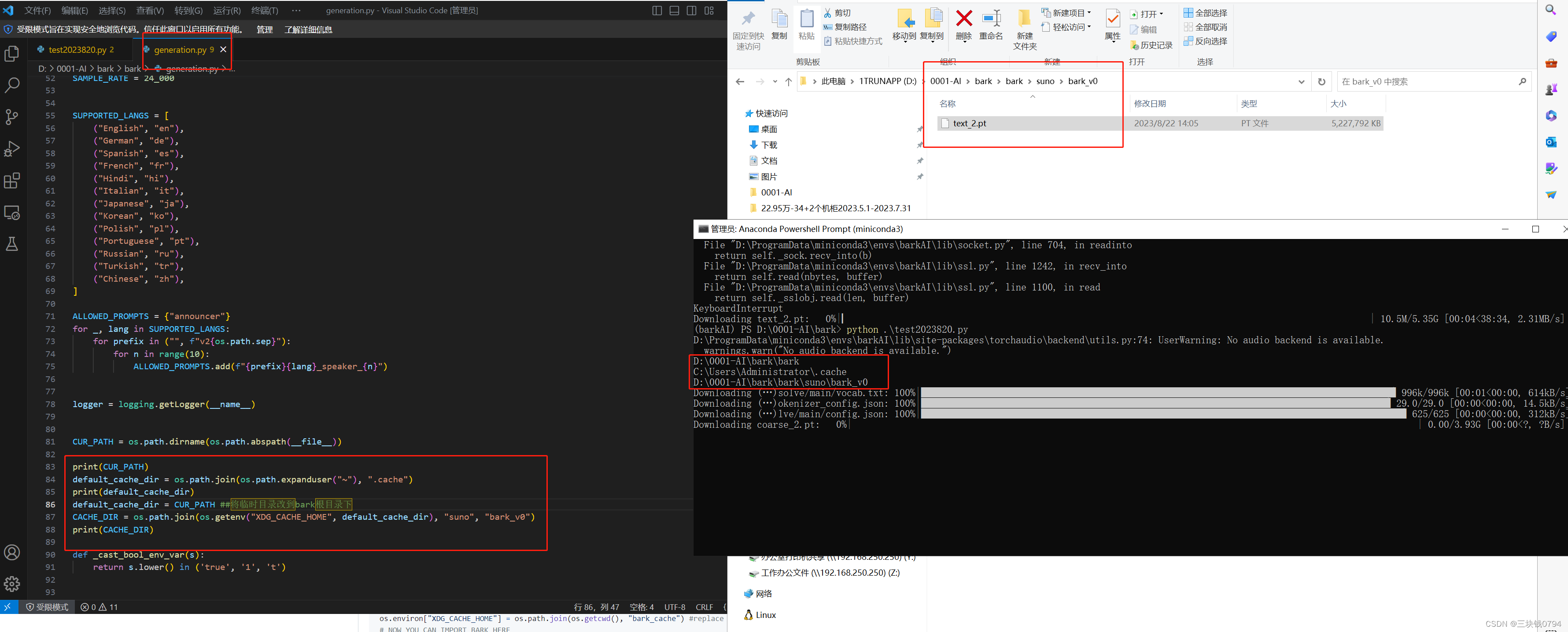
将临时目录改到bark 根目录,模型文件下载到这个目录下
五、网页版提供服务

后端main.pyp
# -*- coding: utf-8 -*-
from flask import Flask, request, send_file, render_template_string ,jsonify
from bark import SAMPLE_RATE, generate_audio, preload_models
from scipy.io.wavfile import write as write_wav
import tempfile
import time
import os
app = Flask(__name__)
# 下载和加载所有模型
preload_models()
@app.route('/')
def index():
return render_template_string(open('templates/index.html').read())
@app.route('/generate', methods=['POST'])
def generate():
text_prompt = request.form.get('text')
if text_prompt:
text_prompt = request.form['text']
audio_array = generate_audio(text_prompt)
timestamp = str(int(time.time()))
filename = timestamp + "times.wav"
filepath = os.path.join('wavfile', filename)
write_wav(filepath, SAMPLE_RATE, audio_array)
file_url = '/wavfile/' + filename
return jsonify({"file_url": file_url})
else:
return "No text provided!", 400
if __name__ == '__main__':
app.run(host='0.0.0.0' ,debug=True)
前端index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Text to Audio</title>
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/[email protected]/dist/css/bootstrap.min.css" integrity="sha384-Gn5384xqQ1aoWXA+058RXPxPg6fy4IWvTNh0E263XmFcJlSAwiGgFAW/dAiS6JXm" crossorigin="anonymous">
<script src="https://cdn.jsdelivr.net/npm/[email protected]/dist/js/bootstrap.min.js" integrity="sha384-JZR6Spejh4U02d8jOt6vLEHfe/JQGiRRSQQxSfFWpi1MquVdAyjUar5+76PVCmYl" crossorigin="anonymous"></script>
</head>
<body>
<div class="container mt-5">
<h1>Text to Audio Converter By 3yuan 2023.8.22 23.15.00</h1>
<div class="form-group">
<label for="text">Enter your text:</label>
<textarea class="form-control" id="text" rows="4" required></textarea>
</div>
<button id="convert" class="btn btn-primary">Convert</button>
<div class="mt-3"><a href="https://blog.csdn.net/jxyk2007/article/details/132425993?">Open Source TTS+gtx1080+cuda11.7+conda+python3.9 ,Beat Baidu TTS</a></div>
<img id="loading" class="img-responsive mt-3" src="{{ url_for('static', filename='loading.gif') }}" style="display: none;" alt="Loading...">
<div id="result" class="mt-3"></div>
<div id="result2" class="mt-3">
</div>
</div>
<script src="https://code.jquery.com/jquery-3.3.1.min.js"></script>
<script>
$("#convert").click(function() {
var text = $("#text").val();
if (text) {
$("#loading").show();
$.post("/generate", { text: text }, function(data) {
$("#loading").hide();
var link = $('<a href="' + data.file_url + '" download="' + data.file_url + '">Download the audio file</a>');
$("#result").html(link);
var link2 = $(" <video src="+ data.file_url +" data-canonical-src="+ data.file_url + " controls='controls' autoplay='autoplay' style='max-height:200px; min-height: 100px'></video>");
$("#result2").html(link2);
});
} else {
alert("Please enter some text!");
}
});
</script>
</body>
</html>
其他模型下载,文字转语言
Models - Hugging Face
标签:
conda
本文转载自: https://blog.csdn.net/jxyk2007/article/details/132425993
版权归原作者 三块钱0794 所有, 如有侵权,请联系我们删除。
版权归原作者 三块钱0794 所有, 如有侵权,请联系我们删除。