
hadoop、spark、storm、flink如何选择
- hadoop和spark是更偏向于对大量离线数据进行批量计算,提高计算速度
- storm和flink适用于实时在线数据,即针对源源不断产生的数据进行实时处理。至于storm和flink之间的区别在于flink的实时性和吞吐量等要比storm高。
上述四个组件的实时性高低顺序如下:
hadoop < spark < storm < flink
hadoop、hdfs、hive、hbase如何选择
hdfs是hadoop的文件存储系统,存储csv/txt等各种格式的文件,但是对于hive和hbases就比较陌生,今天顺便一起看了一下这二者的区别和适用场景。
- hive是对hdfs中的文件数据进行处理和计算的工具,数据还是存放在hdfs中,hive只是一个操作hdfa中文件数据的工具,其本身并不存储数据,并且没有索引查询速度比较慢。
- hbase是会将数据存储在内存中,用于海量数据实时查询。
批计算和流计算区别
1. 数据时效性不同:流式计算具有实时、低延迟等特点;批量计算则是非实时、高延迟的。
2. 数据特征不同:流式计算的数据一般是动态的、没有边界的,数据像水流一样源源不断、你不知道什么时候会结束;而批量计算的数据则是静态的,每次处理的数据量是已知的。
3. 应用场景不同:流式计算应用在实时场景,或者说时效性要求比较高的场景,比如实时推荐、业务监控等等;而批量计算一般也说成是批处理,应用在实时性要求不高、离线计算的场景下,比如数据分析、离线报表等等。
4. 运行方式不同:流式计算的任务是持续进行的,来了就立刻处理;批量计算的任务则是一次性完成,可以理解为将数据先积攒起来,达到一定规模之后再一次性处理。
所以概念还是很好理解的,比如批量计算就是将数据一批一批的处理,但如果每一批的这个量非常非常小,那么是不是就变成流计算了呢。像 Spark Streaming 就是这么做的,虽然 Spark Streaming 也可以做流处理,但它的实时性达不到 Flink 这个级别,就是因为它本质还是批处理,只不过它的每次处理的批(batch)非常小罢了。因此 Spark Streaming 是伪实时的,只不过对于很多场景还是可以接收的,因此仍被广泛使用。但如果对实时性要求特别严苛的话,那么就需要使用 Flink 了。
因此批计算本身就是一种特殊的流计算,批和流本身是相辅相成的,当批小到可以忽略不计的时候就就变成流了。
为什么流式计算将成为主流
数据的实时性要求越来越高,越来越多的业务更加强调时效性,比如实时推荐、风控等业务,这些业务促使数据处理技术像流式计算慢慢普及。
流计算技术日趋成熟,像 Spark Streaming、Flink 等一系列流式计算引擎变得越来越稳定、同时也越来越容易上手。因此越来越多的用户选择流处理技术,来处理自身的一些业务。
批计算会带来一些计算和存储上的成本,以往对于离线做大数据处理来讲,数据需要先存储在分布式文件系统当中,然后再基于这些数据进行分析,这就导致我们的一个存储成本相对较高。
适合流计算的场景
交通工具、工业设备和农业机械上的传感器就会将数据发送到流处理应用程序,该应用程序会监控性能,从而提前检测潜在的缺陷。
金融机构实时跟踪市场波动,计算风险价值,然后根据股票价格变动自动重新平衡投资组合。
房地产网站跟踪客户移动设备中的部分数据,然后根据其地理位置实时建议应走访的房产。
当然除了以上之外场景还有很多,比如电商的推荐系统,就是最让人反感的 "猜你喜欢",还有天气预测、流量统计等等,场景非常多。
主流的流式计算引擎
Storm:
最早使用的流处理框架,社区比较成熟支持原生流处理,即单事件来处理数据流,所有记录一个接一个处理延迟性低,在毫秒级但是消息保障能力弱,消息传输可能会出现重复,但是不会丢失吞吐量比较低
Spark Streaming:
Spark Streaming 属于 Spark API 的一个扩展以固定间隔(如几秒钟)处理一段段的批处理作业,即微批处理延迟性较高,在秒级消息保障能力强,能保证消息传输既不会丢失也不会重复具有非常高的吞吐
Spark Streaming 实际上就是将数据转成一个个的微批,然后交给 Spark Engine 处理完毕之后再发送给下游。所以如果对实时性要求不是特别高,对延迟的容忍度比较大的话,那么采用 Spark Streaming 是一个非常不错的选择。
Flink:
真正的流处理框架,底层采用的数据模型是 DataFlow Model和 Storm 一样,延迟不超过毫秒级消息能够既不丢失也不重复具有非常高的吞吐原生支持流处理
所以 Flink 无疑是最优的,因为选择一个流处理框架我们主要从四个方面考虑:
而能够同时满足以上四点的只有 Flink,其它的都有相应的缺点。比如:Storm 不能保证高吞吐、以及不支持 SQL;Spark Streaming 延迟相对较高,不能做到真正的实时,只能是伪实时。因此,Flink 是我们的最终选择。
Flink集群的基本架构
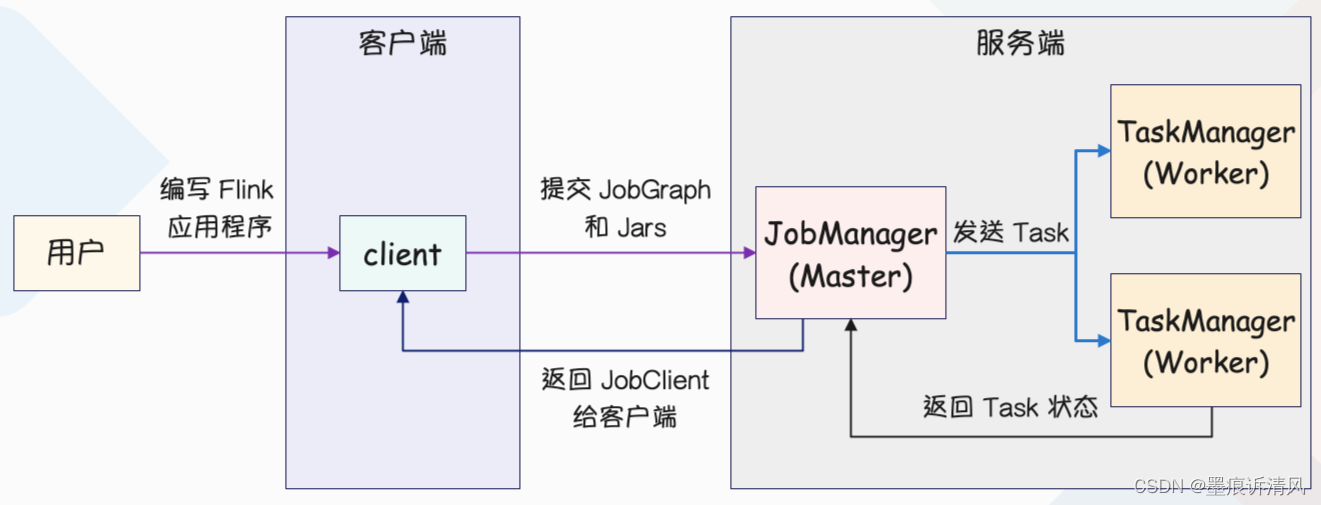
整个 Flink 集群遵循 Master Worker 这样的一个架构模式,其中 JobManager 为管理节点,TaskManager 为工作节点,它们的功能如下。
- JobManager:简称 JM,它是管理节点,负责管理整个集群的计算资源、Job 的调度与执行,以及 CheckPoint 的协调。
- TaskManager:简称 TM,它是工作节点,可以有很多个,每个 TM 一般部署在不同的节点上。JM 会将整个作业(Job)切分成多个 Task,然后分别发送到不同的 TM 上面,再由 TM 提供计算资源来对任务进行处理。
当一个 Job 被提交到 Flink 集群时,它会被分解成多个 Task,并且每个 Task 会被分配到不同的 TaskManager 上执行。Flink 会根据数据源、数据的分区方式以及 Job 的算子等信息来进行任务的划分和调度,以实现最佳的性能和吞吐量。在任务执行期间,Flink 会对 Task 的状态进行管理和监控,以便在出现故障或异常情况时进行恢复或重试。
JM 会将 Task 发送到 TM 上,TM 内部会有一个 Task Scheduling,这个 Task Scheduling 可以理解成一个线程池,而 TM 就是整个进程。当 JM 提交 Task 到 TM 的时候,就会从线程池内部取出一个线程来负责执行任务,而执行任务的线程就是 Task Slot(任务资源槽)。
- Client:客户端,它负责接收用户提交的应用程序(包含代码文件、Application Jar 等等),然后在本地内部产生一个 JobGraph 对象(也就是我们上面说的 Job)。接着通过 RPC 的方式将 JobGraph 对象提交到 JobManager 上面,如果成功提交,那么 JM 会给客户端返回一个 JobClient,客户端通过 JobClient 可以和 JM 进行通信,获取 Job 的执行状态。
客户端接收用户发来的应用程序,然后在内部生成对应的 JobGraph,然后通过 RPC 的方式发给 JM。
用户可以使用 Java、Scala、Python、SQL 等语言编写 Flink 应用程序,然后发送给客户端 Client,再由 Client 提交到集群。而客户端在接收应用程序的时候,会在本地启动一个相应的 Client 进程,该进程负责解析用户提交的应用程序。解析的时候会将应用程序里面的 main 方法拿出来在自己的进程里面执行,执行的主要目的就是生成对应的 JobGraph 对象。
JobGraph
在 Client 里面还有几个核心的概念,比如说 Context Environment,它表示上下文环境,实际上 Client 第一步就会创建 Context Environment,然后在 Context Environment 中执行 main 方法。当生成 JobGraph 对象时,会将它和依赖的一些 jar 包一块提交到 JM 上、即 Job Submit,当然这个过程也是通过 RPC 的方式。
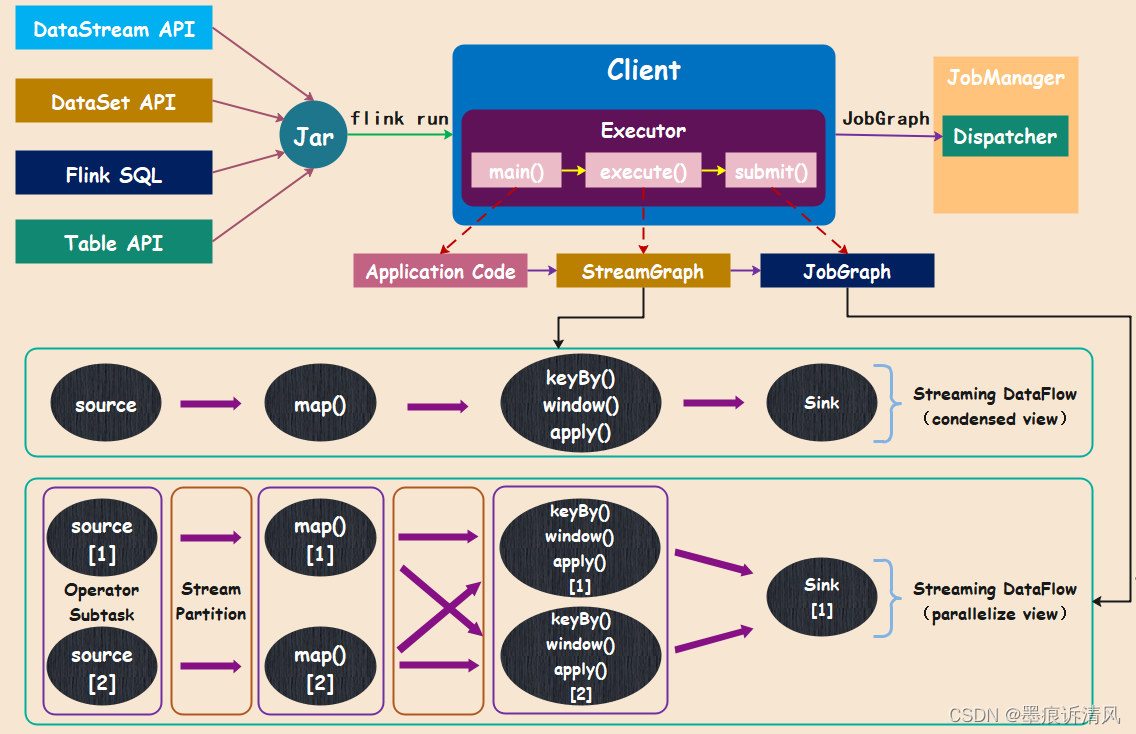
首先我们可以采用不同的 API 编写应用程序,比如:DataStream、DataSet、Flink SQL、Table 等等。不管采用哪种方式,编写的出的应用程序最终都要打成相应的 Jar 包,当然这也不是唯一的方式,比如 SQL Client 模式可以直接向客户端提交一些 SQL 脚本,但是绝大部分情况都是打成一个可执行的 Jar 包,再调用 flink run 命令执行。
而在客户端中我们看到有一个 Exectuor,也就是执行器,当然执行器也分为几种类型,比如本地执行器、远程执行器、On Yarn 执行器,执行器后面会详细说,先来看看它的通用功能。首先会通过反射的方式调用应用程序里面的 main 方法,对应 Application Code 的执行;然后调用应用程序的 Execute 方法,将应用程序转成 StreamGraph,从图中可以看出这个 Streamgraph 只是描述了一个转换的大概逻辑,仅仅只是一个 DataFlow,但没有体现出算子的并行度;接下来再将 StreamGraph 转成 JobGraph,此时会对每一个算子进行拆解、指定相应的并行度;最后再调用 submit 将生成的 JobGraph(一个有向无环图)提交到 JM 中,而 DAG 里面算子的执行,则依赖 JM 将任务调度到 TM 上。
因此 JobGraph 就是应用程序对应的一个 DAG,也就是通过有向无环图的方式去表达应用程序,而且不同接口的应用程序最终都会生成 JobGraph,此时也具备统一性,也就是不管采用什么样的 API 最终提交给 JM 的都是相同标准的 JobGraph。
Flink 集群运行模式以及资源管理器
但是问题来了,首先生成 JobGraph 是需要消耗 CPU 资源的,任务多的话会导致客户端压力增大。而且生成 Jobgraph 是同步的,任务一多的话也可能会造成阻塞,加上 JobGraph 和依赖的 Jar 包的提交也需要时间,如果 Jar 包比较大的话,会非常依赖带宽,更何况这些依赖每次都要上传。而对于流平台而言重要的就是实时,不能陷入等待。因此后来就有人提出,能不能把生成 JobGraph 这一步从客户端移到 JM 上,这样可以释放本地客户端的压力。最终在客户端里,只需要负责命令的提交、下发,以及等待 Job 的运行结果即可。
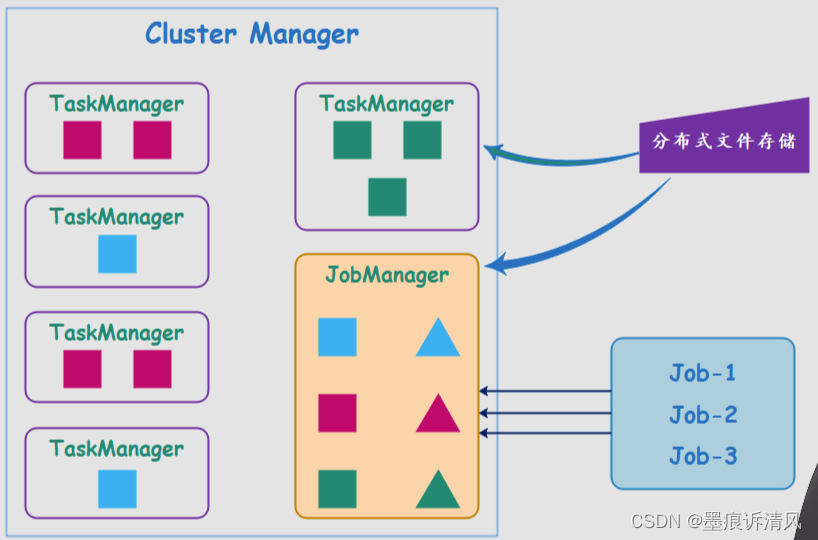
可以看到 JM 首先会去分布式文件存储系统中拉取依赖的包,然后根据应用程序生成 JobGraph 对象,然后执行、调度,整个过程都是在 JM 当中进行的。这样做的好处就是,客户端不需要再每一次都将 Jar 包提交到 JM 上,从而避免网络传输上的消耗、以及客户端的负载。而且 Application Mode 也实现了资源隔离,虽然所有的 Job 共享一个 JM,但是在 JM 内部又在 Application 层面实现了资源隔离。
版权归原作者 墨痕诉清风 所有, 如有侵权,请联系我们删除。