
定量数据可以说出无穷无尽的故事!
每日收盘价告诉我们有关股市动态的信息,有关家庭能源消耗的小型智能电表,有关运动过程中人体活动的智能手表,以及有关某些人对某个话题的自我评估的调查 及时。不同类型的专家可以讲这些故事:金融分析师,数据科学家,体育科学家,社会学家,心理学家等等。他们的故事基于模型,例如回归模型,时间序列模型和ANOVA模型。
为什么需要数值评分指标?
这些模型在现实世界中有很多影响,从投资组合经理的决策到一天、一周和一年不同时间的电价。为了达到以下目的,需要数值评分指标:
- 选择最精确的模型
- 估计模型误差对现实世界的影响
在本文中,我们将描述数值预测模型的五个真实的用例,在每个用例中,我们从略微不同的角度度量预测精度。在一种情况下,我们衡量一个模型是否有系统偏差,而在另一种情况下,我们衡量一个模型的解释能力。本文最后回顾了数字评分指标,展示了计算它们的公式,并总结了它们的属性。
均方(根)误差,MSE(RMSE)
哪个模型能最好地捕捉动荡的股票市场的快速变化?
在下面的图1中,您可以看到LinkedIn收盘价从2011年到2016年的变化。在该时间段内,行为包括突然的峰值,突然的低点,更长的价值增加和减少时间以及一些稳定的时间段。预测这种不稳定行为具有挑战性,尤其是从长期预测。但是,对于LinkedIn的利益相关者来说这是非常有价值的。因此,我们更喜欢一个能够捕捉突然变化的预测模型,而不是一个在五年内平均表现良好的模型。
我们选择具有最低(均方根)误差的模型,因为与小误差相比,该指标对大误差的加权更大,并且偏向于能够对短期变化做出反应并节省利益相关者金钱的模型。

图1. 2011年至2016年LinkedIn每日股票市场收盘价:该数据几乎没有规律性,而许多突然变化却具有较低的可预测性。我们选择均方根误差最低的预测模型,因为它对较大的预测误差进行加权,并且偏向于可以捕获突然的峰值和低点的模型。
平均绝对误差,MAE
哪个模型能最好地估计长期的能源消耗?
在图2中,您可以看到2009年7月都柏林的每小时能源消耗值,这是从一组家庭和行业收集的。能源消耗呈现出相对规律,工作日和工作时间能耗较高,夜间和周末能耗较低。这种规律的行为可以相对准确地预测,为能源供应的长期规划提供了依据。因此,我们选择了平均绝对误差最小的预测模型。我们这样做是因为它对大小误差的权重相等,因此对异常值具有鲁棒性,并显示在整个时间段内哪个模型的预测精度最高。
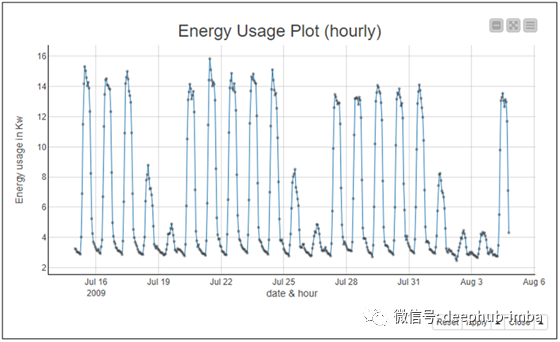
图2. 2009年6月在都柏林的每小时能源消耗值,该数据是从一系列家庭和行业中收集的。数据显示出相对规则的行为,因此可以长期预测。我们选择具有最低平均绝对误差的预测模型,因为该指标对异常值具有鲁棒性。
平均绝对百分比误差,MAPE
不同产品的销售预测模型是否同样准确?
在炎热的夏天,苏打水和冰淇淋的供应应该是有保证的!我们想检查预测这两种产品销售的两种预测模型是否同样准确。
这两种模型预测的是同一单位的商品销量,但规模不同,因为苏打水的销量要比冰淇淋大得多。在这种情况下,我们需要一个相对误差度量,并使用平均绝对百分比误差,它报告相对于实际值的误差。在图3中,在左侧的折线图中,可以看到2020年6月苏打水(紫色线)和冰淇淋(绿色线)的销量,以及这两种产品的预测销量(红色线)。与冰淇淋相比,气泡水的预测线似乎偏离得更多一些。然而,气泡水的实际值越大,可见比较就会产生偏差。实际上,预测模型对气泡水的效果比冰淇淋更好,正如MAPE值报告的那样,气泡水为0.191,冰淇淋为0.369。
但是,请注意,当实际值接近于0时,MAPE值可能会有偏差。例如,与夏季相比,冬季的冰淇淋销量相对较低,而牛奶的销量在全年都保持相当稳定。当我们通过MAPE值来比较牛奶和冰淇淋的预测模型的准确性时,冰淇淋销量中的小值使得冰淇淋的预测模型看起来比牛奶的预测模型差得离谱。
在图3中,在中间的折线图中,您可以看到牛奶(蓝色线)和冰淇淋(绿色线)的销售额,以及这两种产品的预测销售额(红色线)。如果我们看一下MAPE值,牛奶(MAPE = 0.016)的预测精度显然比冰淇淋(0.266)好得多。然而,这种巨大的差异是由于冰激凌在冬季的销售价值较低。图3中右边的直线图显示了冰淇淋和牛奶的实际和预测销售完全相同,冰淇淋的销售每月增加25件。在没有接近于零的偏差的情况下,冰淇淋(MAPE=0.036)和牛奶(MAPE=0.016)的预测精度现在更接近彼此。

图3.三个线图显示了冰淇淋和苏打水的实际和预测值(左侧的线图)以及冰淇淋和牛奶的实际值和预测值(中间和右侧的线图)。在右侧的线图中,冰淇淋销售价值按比例增加了25,以避免实际值过小的绝对绝对误差造成偏差。
均值差异 Mean Signed Difference
是否提供不切实际的期望?
智能手表可以连接到一个跑步应用程序上,该应用程序可以估算10公里的跑步时间。作为一种激励因素,这款应用估算的时间可能比实际预期的要低。
为了测试这一点,我们从一组跑步者那里收集了六个月的估计和实现的完成时间,并在图4中的线图中绘制平均值。正如您所看到的,在这6个月里,实际完成的时间(橙色线)比预计完成的时间(红色线)减少得更慢。我们通过计算实际完成时间和估计完成时间之间的平均符号差来确认估计中的系统偏差。它是负的(-2.191),所以这个应用程序确实提高了不切实际的期望!但是,请注意,这个度量并不能说明误差的大小,因为如果有跑步者跑得比预期的时间快,这个正误差会补偿负误差的一部分。

图4.在六个月的时间内进行10,000次运行时的估计(红线)和已实现(橙色线)完成时间。估计的时间向下偏移,也由平均有符号差的负值表示。
r方 R-squared
通过阅读可以等价于我们多少年教育?
在图5中,您可以看到总体样本中家中自学(x轴)和受教育年限(y轴)之间的关系。对数据拟合一条线性回归线,以建立这两个变量之间的关系模型。为了衡量线性回归模型的拟合度,我们使用r方。

图5.r方表示模型所解释的目标列(教育年限)的方差。根据模型的r平方值,0.76,获得文献解释了受教育年限中76%的方差。
五个数字评分指标的总结
上面介绍的数字评分指标如图6所示。列出了这些指标以及用于计算它们的公式以及每个指标的一些关键属性。在公式中,yi为实际值,f(xi)为预测值。

在本文中,我们介绍了最常用的错误指标以及它们对模型性能的影响。
通常建议您查看多个数字评分指标,以全面了解模型的性能。例如,通过查看均值符号差,您可以查看模型是否存在系统偏差,而通过研究(均方根)均方根误差,则可以查看哪种模型最能捕捉突然的波动。可视化(例如折线图)补充了模型评估。
作者:Rosaria Silipo
原文地址:https://towardsdatascience.com/numeric-scoring-metrics-acd3896c5eff
deephub翻译组