
1、数仓
数据仓库是一个为数据分析而设计的企业级数据管理系统,它是一个系统,不是一个框架。可以独立运行的,不需要你参与,只要运行起来就可以自己运行。
数据仓库不是为了存储(但是能存),而是为了统计分析
数据仓库可集中、整合多个信息源的大量数据,借助数据仓库的分析能力,企业可从数据中获得宝贵的信息进而改进决策。
1、核心架构
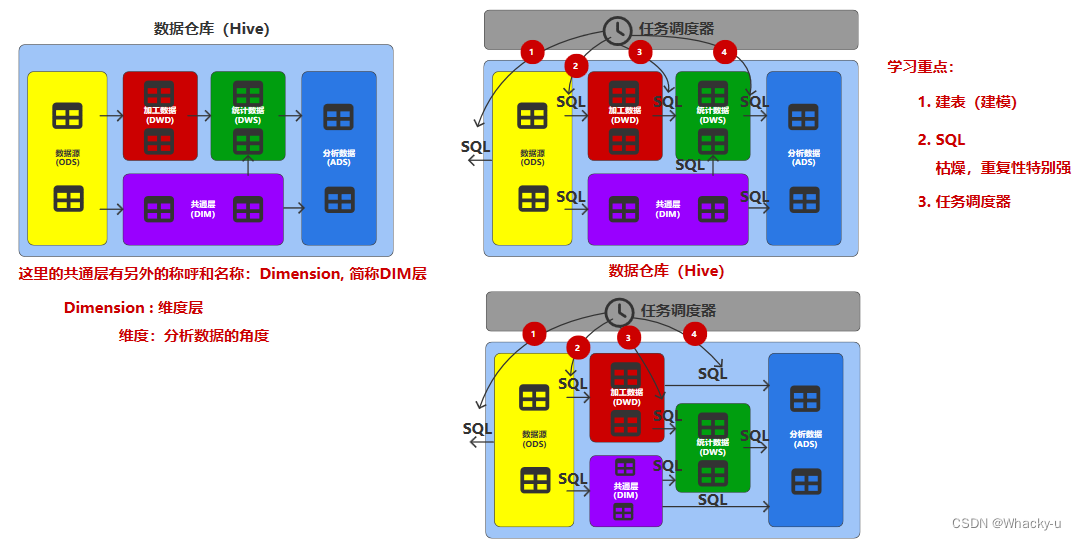
其中维度层,就是用不同的角度去研究需求任务,也可以用同一个维度或角度研究不同需求,比如研究不同性别下登录量的区别,或者是和订单喜好的关系
另外这个数据仓库系统其实就是涉及不同的层,每一层会有一些表,这样避免之后会重复工作,直接用之前可能处理好的表,所以数仓的任务其实不是说就写一个sql任务,出一个结果,是写一系列的sql得出一系列中间过程的表,然后去处理任务需求,最后得到结果

但是,需要注意的是,不同公司的数仓会有不同的层数,但是基本都有上述的几层
2、建模方法论
// 主要见第四个数据仓库系统讲义的第2-6页
1)ER模型
(1)实体关系模型
实体关系模型将复杂的数据抽象为两个概念——实体和关系。实体表示一个对象,例如学生、班级,关系是指两个实体之间的关系,例如学生和班级之间的从属关系。
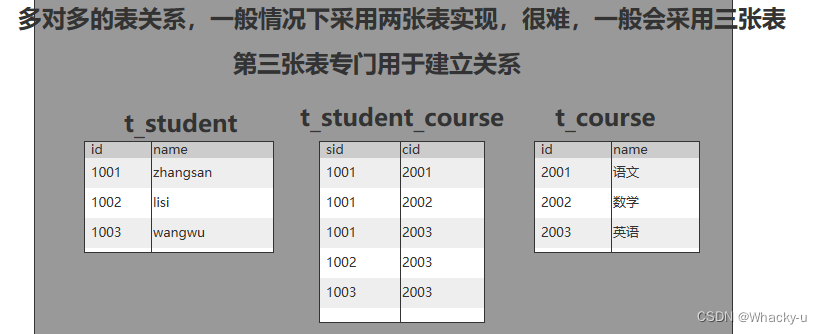
这个是说的比如一对多、多对一、一对一、多对多关系
其中强调一下一对一关系

(2) 数据库规范化
使用一系列范式设计数据库(通常是关系型数据库)的过程,其目的是减少数据冗余,增强数据的一致性。
这一系列范式就是指在设计关系型数据库时,需要遵从的不同的规范。关系型数据库的范式一共有六种,分别是第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF)。
遵循的范式级别越高,数据冗余性就越低。(也不能冗余性太低,太低的话性能也低,因为有时候重复性工作,就是前部分工作可能需要一些重复的表,这个工作用到了这个中间表,另外的工作也用到了这个中间表,所以还是需要一定的冗余性的)
基本上达到三范式即可
1、函数依赖
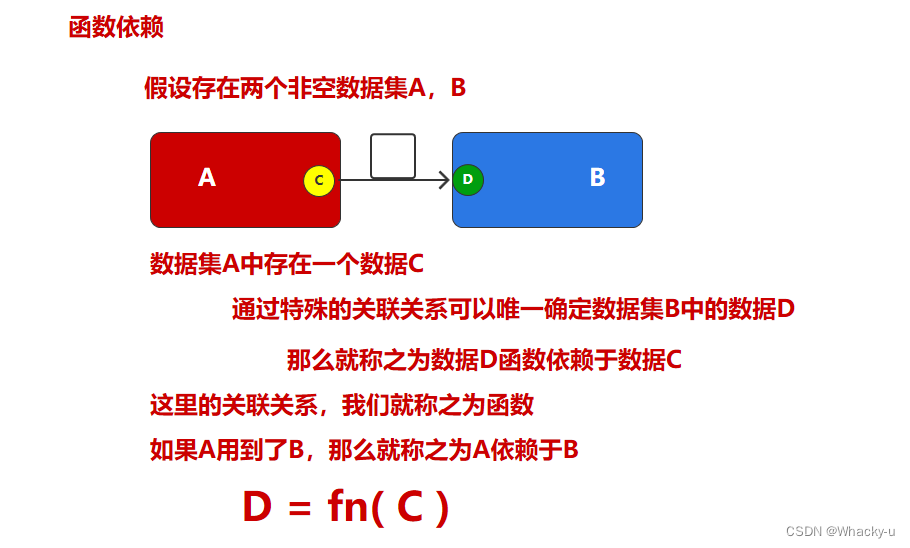
举几个例子
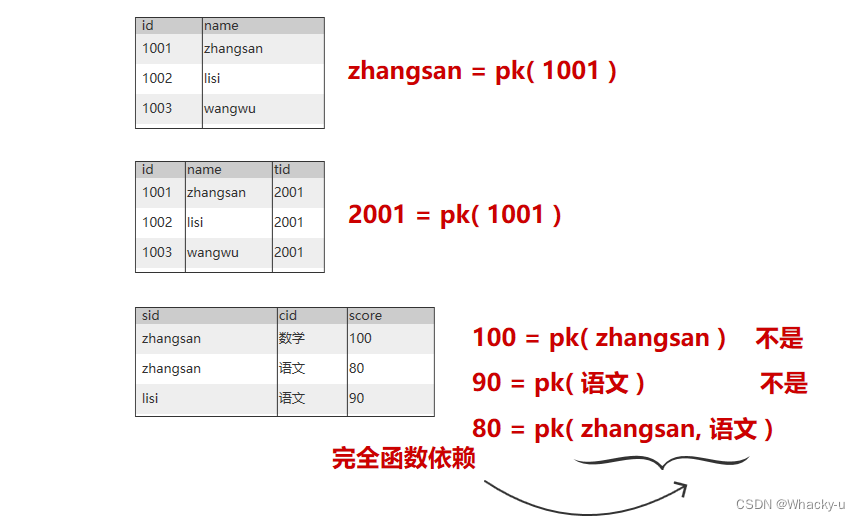
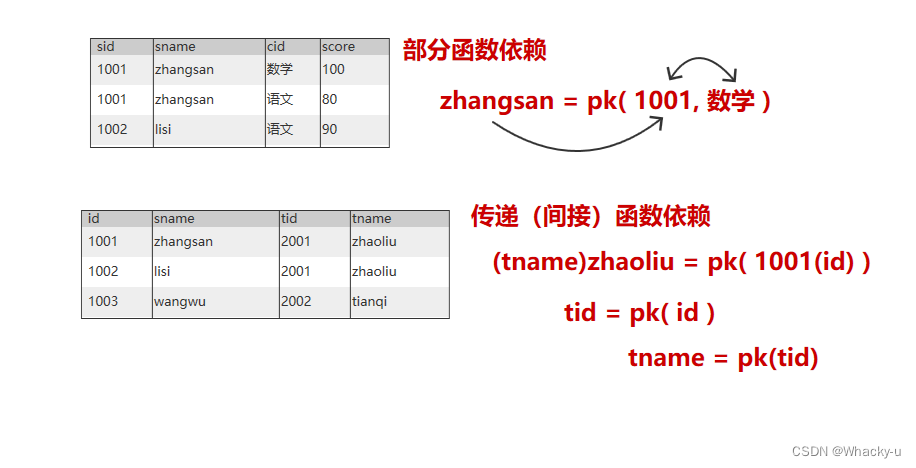
2、范式
- 第一范式:属性不可切割。【属性划分到最小,划分到不能再分割的地步】
- 第二范式:不能存在部分函数依赖
- 第三范式:不能存在传递函数依赖
3、分析优缺点(ER模型不适合用于数据仓库的建模和分析)
较为松散、零碎,物理表数量多。
这种建模方法的出发点是整合数据,其目的是将整个企业的数据进行组合和合并,并进行规范处理,减少数据冗余性,保证数据的一致性。这种模型并不适合直接用于分析统计。
2)维度模型
维度:分析数据的角度、一个角度一个表、还包括用于统计的数据,汇总起来就是一个表
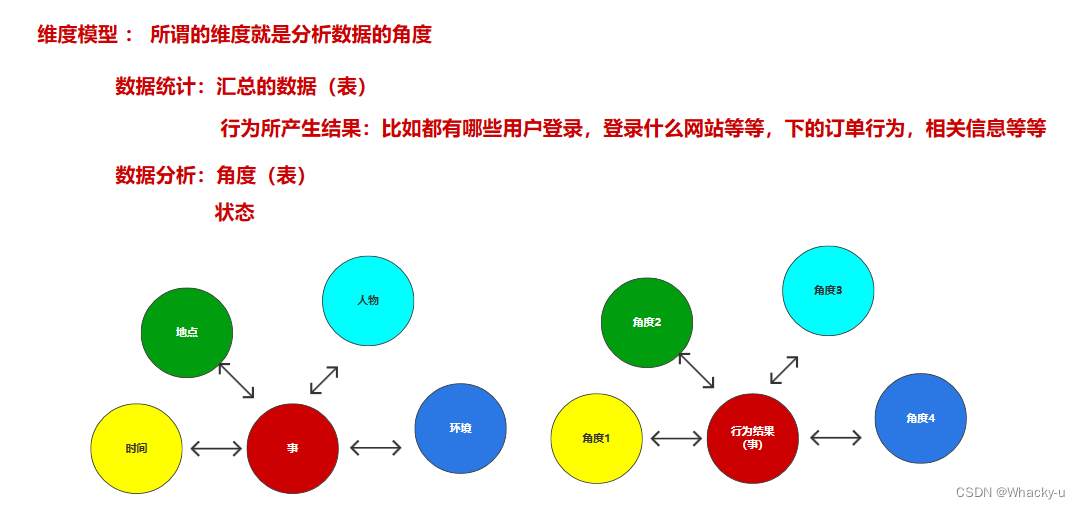
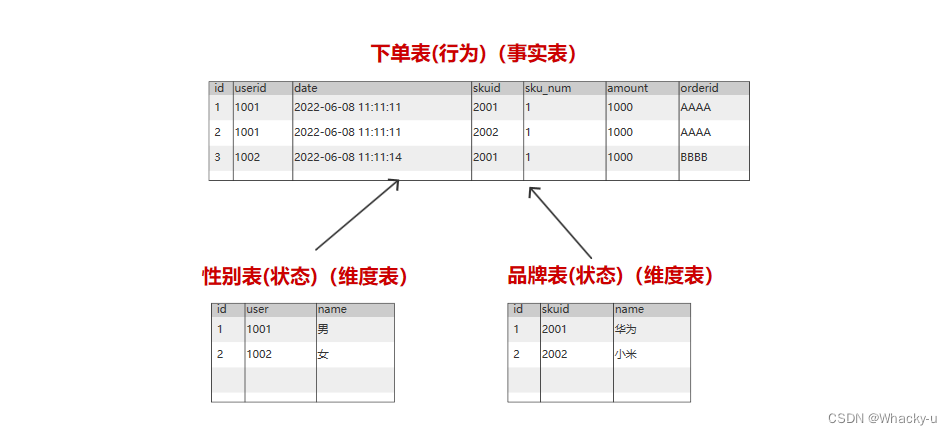
维度模型将复杂的业务通过事实和维度两个概念进行呈现。事实通常对应业务过程,而维度通常对应业务过程发生时所处的环境。
eg:站在省份的角度研究订单销量、站在性别的角度研究订单销量
3、环境搭建
1)运行环境
Hive环境搭建:
Hive on Spark:Hive既作为存储元数据又负责SQL的解析优化,语法是HQL语法,执行引擎变成了Spark,Spark负责采用RDD执行。
Spark on Hive : Hive只作为存储元数据,Spark负责SQL解析优化,语法是Spark SQL语法,Spark负责采用RDD执行。
1.Hive on Spark=>Hive解析SQL=>SparkRDD=>Jar=>Yarn2.Spark on Hive=> (SparkSQL)Spark解析SQL=>SparkRDD=>Jar=>Yarn//这是在Spark解析SQL后会有一些表,会存放在hive中,所以hive也可以当数据源
我们这里用的是Hive on Spark
// 具体安装流程见第四个数仓系统讲义第六节,也就是第21页往后
但是这里由于版本匹配问题,为了可以用到最新的spark,所以用到的hive为了兼容新一点的spark,是修改过的
需要在hive所在节点部署Spark纯净版
这是因为,yarn里面也有Hadoop,而spark如果不是纯净版里面也配置有Hadoop,就会引起版本冲突
向HDFS****上传Spark纯净版jar包**
- 说明1:采用Spark纯净版jar包,不包含hadoop和hive相关依赖,能避免依赖冲突。
- 说明2:Hive任务最终由Spark来执行,Spark任务资源分配由Yarn来调度,该任务有可能被分配到集群的任何一个节点。所以需要将Spark的依赖上传到HDFS集群路径,这样集群中任何一个节点都能获取到
2)开发环境
先启动Hadoop
启动hiveserver2
打开datagrip连接hive
4、模拟数据!!!!!!!!!!!!!!
这部分和采集不太一样,因为采集将数据模拟出来最后都传到了hdfs
而我们这部分只要保证hdfs有需要的数据即可
这部分其实就是利用之前的采集部分,将数据模拟好几天的数据然后利用采集通道传送到hdfs
通常企业在开始搭建数仓时,业务系统中会存在历史数据,一般是业务数据库存在历史数据,而用户行为日志无历史数据。
假定数仓上线的日期为2022-06-08,为模拟真实场景,需准备以下数据。
注:在执行以下操作之前,先将HDFS上/origin_data路径下之前的数据删除。
//所以总结就是:
先关掉maxwell!!
通过模拟生成数据的程序生成了2022-06-04到2022-06-07的数据和行为日志
但是删除了这几天已经通过采集通道流转到hdfs的行为日志数据,但是业务数据还在数据库gmall中的表里面
之后又通过程序生成了2022-06-08上线这个日期的数据,日志数据通过kafka流转到hdfs中
然后打开maxwell,通过脚本【是增值数据中首日的那部分】将2022-06-08的业务数据从mysql流转到kafka再流转到hdfs中
也就是说我们现在有8号的行为日志,和业务数据中增量表的首日8号增值数据,还有8号的全量表的全部数据
数据库gmall中有前几日的业务数据,不过没有传到hdfs中,数据库中存有历史数据,但是数仓只有上线这天的业务首日增值数据
应该这么说,hdfs中的inc文件中存有所有历史数据,从2022-06-04到2022-06-08,只不过我们在导到数仓ods层时候统一将业务数据的首日增值当作06-08的分区数据
之后只要maxwell开启着,gmall数据库一有变化,就可以监听到然后加到kafka中的增量数据中
而模拟程序可以模拟出来insert,update等操作,如果我们用脚本就可以记录到增量表的首日数据,如果不用脚本,只是开着maxwell,
运行一次lg.sh 模拟数据的程序,那就可以记录到增值表每日的增值数据,日志同样也是会记录到新的行为日志,全量数据通过脚本也可以记录到
全量表数据在从mysql导入到hdfs的时候,需要经过datax,这里会用脚本去执行命令,会输入需要同步的表的名字,以及日期
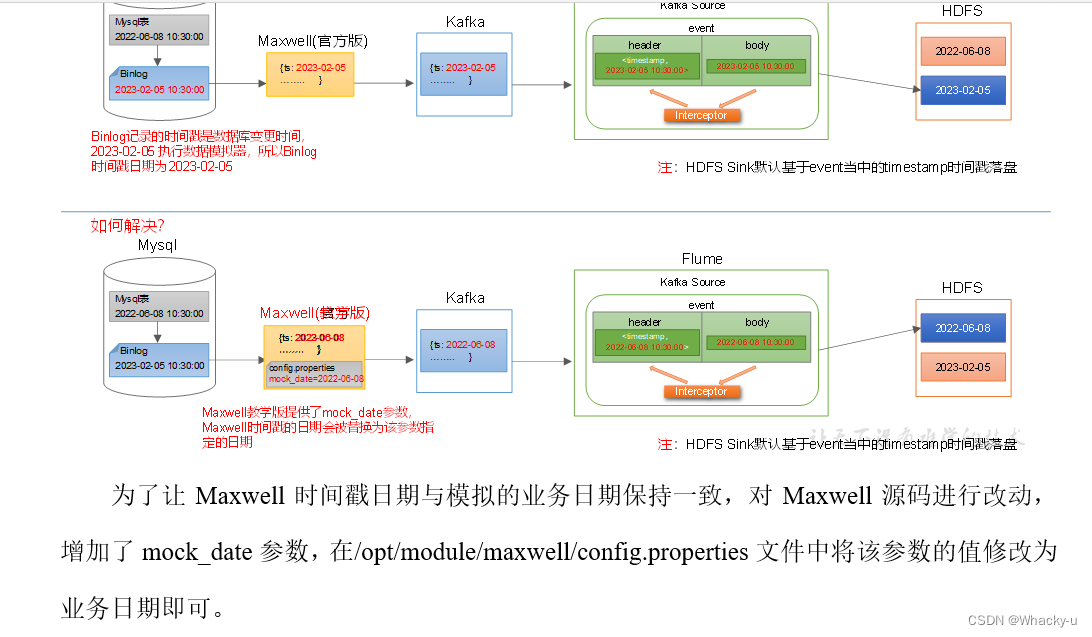
增量表的数据,需要打开Maxwell,然后在Maxwell中设置mock_date日期,因为我们是模拟别的日期,所以需要这样,但是实际开发中不用这样,他就会记录实际的日期。
更改模拟生成数据程序中的application中的日期【和mock_date日期一样】,数据生成到gmall数据库中后,我们Maxwell就会记录到,然后加载到kafka中,我们通过脚本,经过flume将kafka中的数据加载到hdfs中,这时候用到了拦截器,就是将mock date中的日期,当作时间文件名放到hdfs中,同时加上inc的文件名结尾
全量表
全量表每次更新都会记录全量数据,包括原全量数据和本次新增数据,即每个分区内的数据都是截至分区时间的全量总数据。注意:全量表中每个分区内都是截至分区时间的全量数据,原先分区的数据依然存在于表中,只是每次更新会在最新分区内再更新一遍全量数据。
增量表
首日:也是一样包括之前的历史数据,一起同步
这是时间戳的问题,就是mock date
5、ODS层(operate data store)
1、数据内容及格式
-- 1、存储从mysql业务数据库和日志服务器的日志文件中采集到的数据--日志数据-- 格式:JSON--业务数据-- 历史数据-- 格式:-- 全量:DataX: TSV (Tab分割的)-- 增量:Maxewell: JSON-- 2、汇总数据--希望用最少的资源存储最多的数据-- 压缩 :选择压缩率(空间的概念)高的,而压缩效率(时间的概念)相对没那么重要,压缩效率是影响计算速率-- 数据格式尽可能不变-- 压缩格式尽可能不变-- 3、命名规范--数据仓库中,表其实都是放置在一起的,从逻辑上进行区分,进行分层--表从名称上区分每一层-- 分层标记(ods_)+ 同步数据的表名称(一般全量是状态,增量是行为,但是有些表既可能是全量也可能是增量) +全量/增量 标识(full/inc)
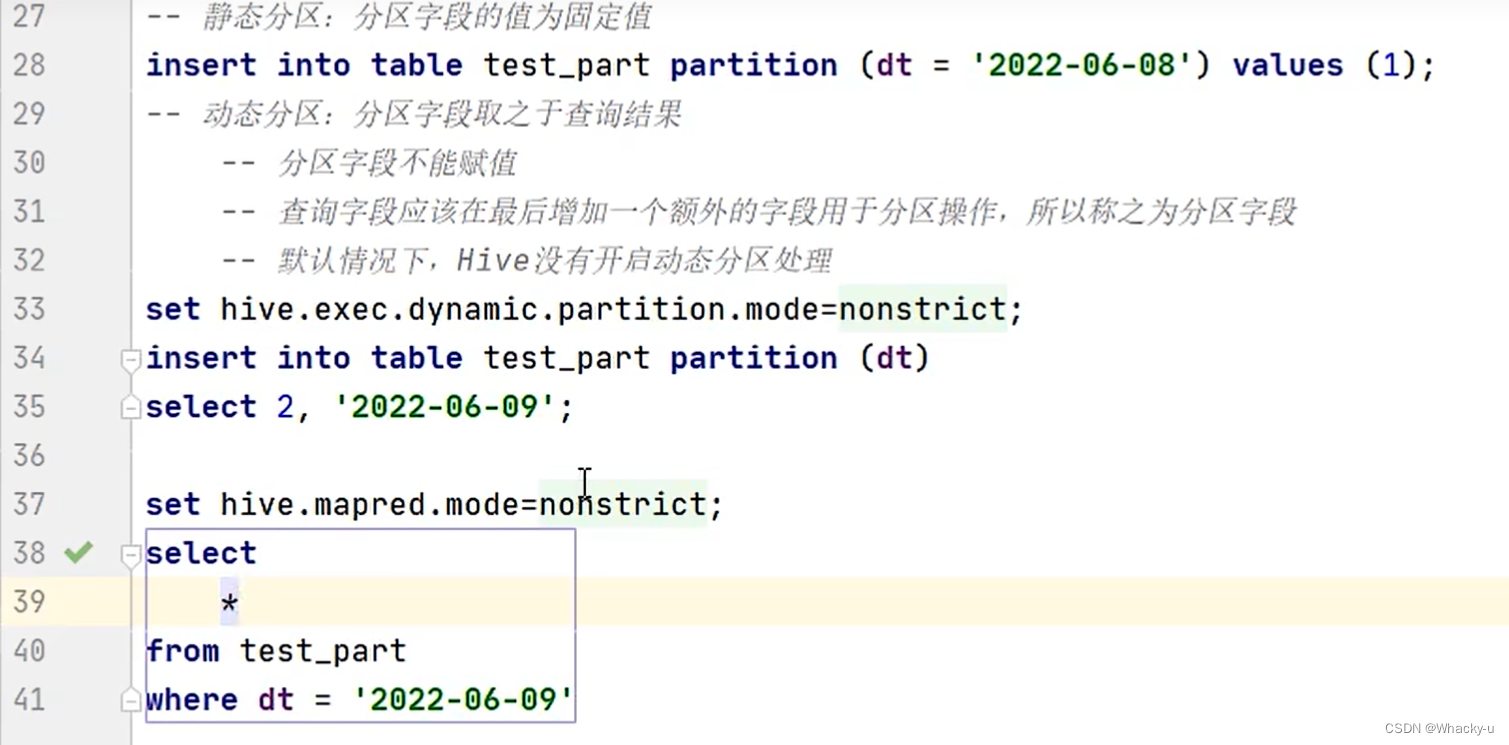
补充一个知识点:动态分区
就是通过查询到的结果用作插入数据,和分区需要的字段值。
这个需要设置允许动态分区,并且查询的时候需要设置一下严格查询,要不然select * 还是可以把所有分区的数据都查出来
-- 日志数据格式:--1、页面浏览日志--JSON中含有JSON--JSON表中的JSON数据如果存在嵌套的情况-- 一般会将最外层的json对象的属性名作为json表的字段-- 表的字段类型应该用特殊类型,因为这个每一个字段都是相当于一个对象,一个json对象--2、APP启动日志--JSON中含有JSON-- 但是上面两类日志数据,会有字段名一样的情况。-- 这样就保留最多的情况即可,比如页面浏览日志有a b c d 四个字段,APP启动日志有a b 两个字段-- 创建表的时候就创建a b c d 四个字段,在插入APP启动日志数据的时候,没有c d 数据就会默认是空了
// 补充一下:在电商数仓6.0视频中,第102-104节是讲解建表特殊类型。分别是array map struct
结构体那里,如果直接struct('a','b','c'),这样是直接赋值的属性值,属性名默认就是col1,col2,col3
如果是named_struct('a','b','c','d'),那就是成对的键值对,a就是属性名,b就是属性值,所以括号内的数据应该是成对出现
map和struct的区别
-- 泛型-- struct中的属性名称是固定的,只要约束好不能发生变化-- map中的key不是固定的,只要约束好不能发生变化,可以动态变化
因为map在定义的时候只用定义泛型,不需要定义属性名字
但是map定义好泛型后,插入的数据要不都是数据类型和泛型一直,要不就是都不是泛型的值,所有属性值的类型一致即可
struct就没有这方面的要求,可以不同属性值有不同的属性类型
2、流程
- 创建日志表
- 加载行为日志数据
- 编写每日日志数据装载脚本
hdfs_to_ods_log.sh 2022-06-08 - 创建业务表
-- 业务表--全量表:datax-- TSV--增量表:Maxwell-- JSON这里需要注意TSV就是用 /t序列化,而json就是用json的序列化 - 加载业务数据,也是用的脚本,这里是
hdfs_to_ods_db.sh all 2022-06-08有两个参数,一个是表的名字(可以是all,表示所有业务表,全量和增量同时更新);第二个参数就是时间日期
6、DIM层(Dimension)
1、需要注意的点及框架
-- DIM层--Dimension : 维度--维度层保存的表其实就是分析数据的角度表-- 维度层保存维度表,所以建模理论应该遵循维度建模理论--维度层中的维度表,主要用于统计分析--数据存储方式应该为列式存储 : orc--压缩格式:为了统计分析,这里就需要时间越少越好,所以重视压缩效率,而不是压缩率(和ods反过来了),就是snappy--数据源--ODS层的数据为整个数据仓库做准备--DIM层数据源就是ODS层--命名规范--分层标记(dim_)_维度名称_全量/拉链(标记)-- 全量:维度表的全部数据-- 状态数据为了避免数据出现问题,最好的方式,就是每一天都保存全部数据-- 绝大多数的维度表都是全量表,特殊情况采用拉链的方式--拉链:--建模理论--ER模型--ODS,因为相当于直接把mysql中的表拿过来-- 维度模型【事实表用来做统计[计算]的,维度表用来分析[属性]的】--维度(状态)表--事实(行为)表
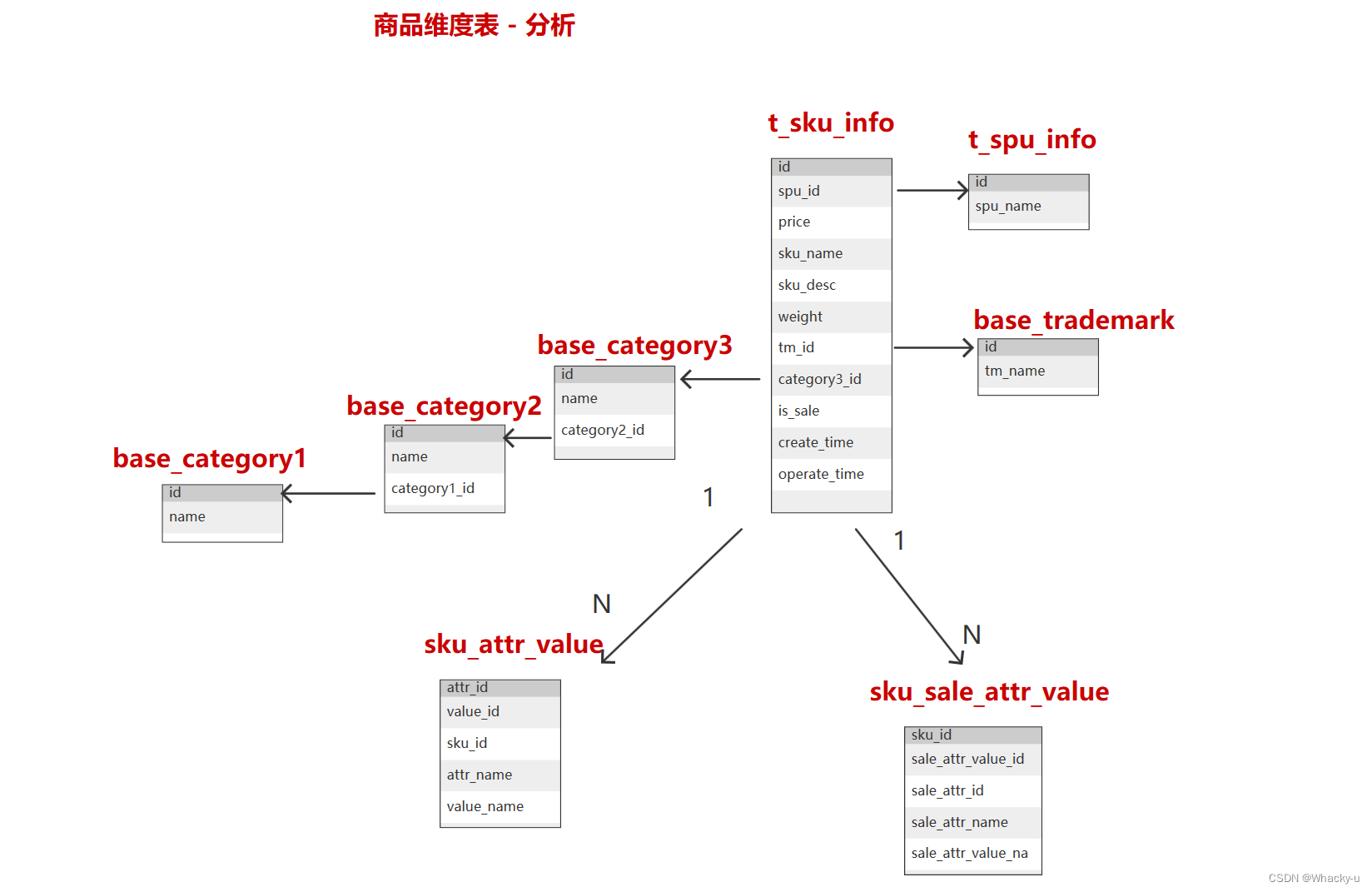
2、维度表说明
-- 维度表--表-- 维度(角度),一个维度就是一张表--t_order, t_sex , t_age-- 从实践来讲,一般会将有关联性的维度设置为一张表,不同的维度就是这张表的(维度)字段--t_order, t_user(sex , age)--t_order, t_sku(tm , category)-- 如果维度特别简单,特别独立,只在特殊场合用。其实这个表可以不用创建,可以在事实表中直接使用,而不用单独创建-- t_payment_type : 微信支付,支付宝支付,银联支付--字段--维度:只要等用来进行分析【重点是分析两字】的维度,都是字段-- 就是只有分析价值的属性才可以用作维度表的字段-- 数据(字段)来源:参考业务数据库的表字段--主维表:业务数据库中主要用于分析维度字段的表--相关维表:业务数据库中相关用于分析维度字段的表--维度字段的确定:-- 尽可能生成丰富的维度属性 : 字段越多越好,选择性越多-- !!!!!!!!编码和字段共存!!!!!!!!【因为只有别的属性id的话不知道是什么意思,需要添加配置id相对应的名字】-- 沉淀出(计算)通用的维度属性
3、创建表思路
划分需要的维度表,然后去业务数据库找到相关的表
找到主维表和相关维表,之后从主维表看起,一行一行的分析,需要别的表的信息就找出来,但是只留下相关联,且有分析价值的属性
另外如果是一对多关系的,那个关联上的表的字段用array< struct<> > 数组嵌套结构体方式
比如:
4、数据装载
这里有两个问题:
- 一个是需要注意我们这里的数据源不是mysql,而是ods中的表
- 另外一个是新创建的表,是经过整合的,并不能由单独的ods中一个表数据通过查询语句加载到新创建的表。并且查询的时候是 ods.表名字!!!!!!!!!!
所以需要补全数据:
(1) 一对一的情况,就是主维表一对一相关维表中的属性,或者类似上图再分析主维表中有些属性id,需要找到相关联的表中的id对应的name
- 补全行:union
- 补全列:join。有left join、join、right join等等****考虑到出现丢数据的情况,实际开发中在left join和join结果一致的情况,用left join,与主维表看齐
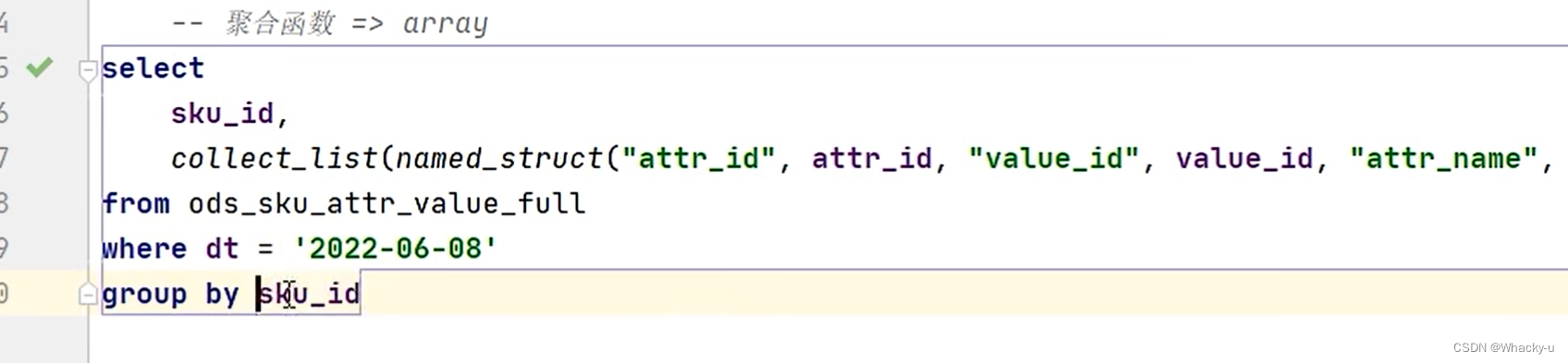
(2)一对多,这种复杂情况
- 先要将查询结果变成,需要的结果,就此例子来说,需要先变成结构体用的是named_struct(“名字”,属性值,“名字“…)
- 然后再将N个结构体变成数组array可以用collect_list(col),用作聚合函数,返回值是数组array,这个是去重的
(3)新关联的表,增加的属性需要加名字,就是主维表中所需要的名字
5、几个需要注意的表信息
补充一下一些需要注意的表信息:
(1) 活动表
与其他的不一样的点是
-- 活动维度表-- 这里主维表不是activity_info,而是activity_rule,因为我们主要分析的是规则,而不是活动本身
(2) 日期维度表
通常情况下,时间维度表的数据并不是来自于业务系统,而是手动写入,并且由于时间维度表数据的可预见性,无须每日导入,一般可一次性导入一年的数据。
没有分区、并且表名最后没有加上full的关键字
`date_id` STRING COMMENT'日期ID',`week_id` STRING COMMENT'周ID,一年中的第几周',`week_day` STRING COMMENT'周几',`day` STRING COMMENT'每月的第几天',`month` STRING COMMENT'一年中的第几月',`quarter` STRING COMMENT'一年中的第几季度',`year` STRING COMMENT'年份',`is_workday` STRING COMMENT'是否是工作日',`holiday_id` STRING COMMENT'节假日'-- 除了最后两行需要上传特定的信息文件,但是这里需要注意,-- 文件的数据格式是行式存储还是列式,因为我们现在表的结构是列式存储
所以可以建一个中间表,中间表是行式存储的,数据是行式存储的也没事了,最后再将中间表数据insert插入目标表中
-- 剩下就是前面所有行,这些都是可以看日期直接知道的
(3) 用户表 [拉链表]
用户注册人数基数会很大,我们又需要每日统计表全量数据
所以数据会很庞大,需要换种方式
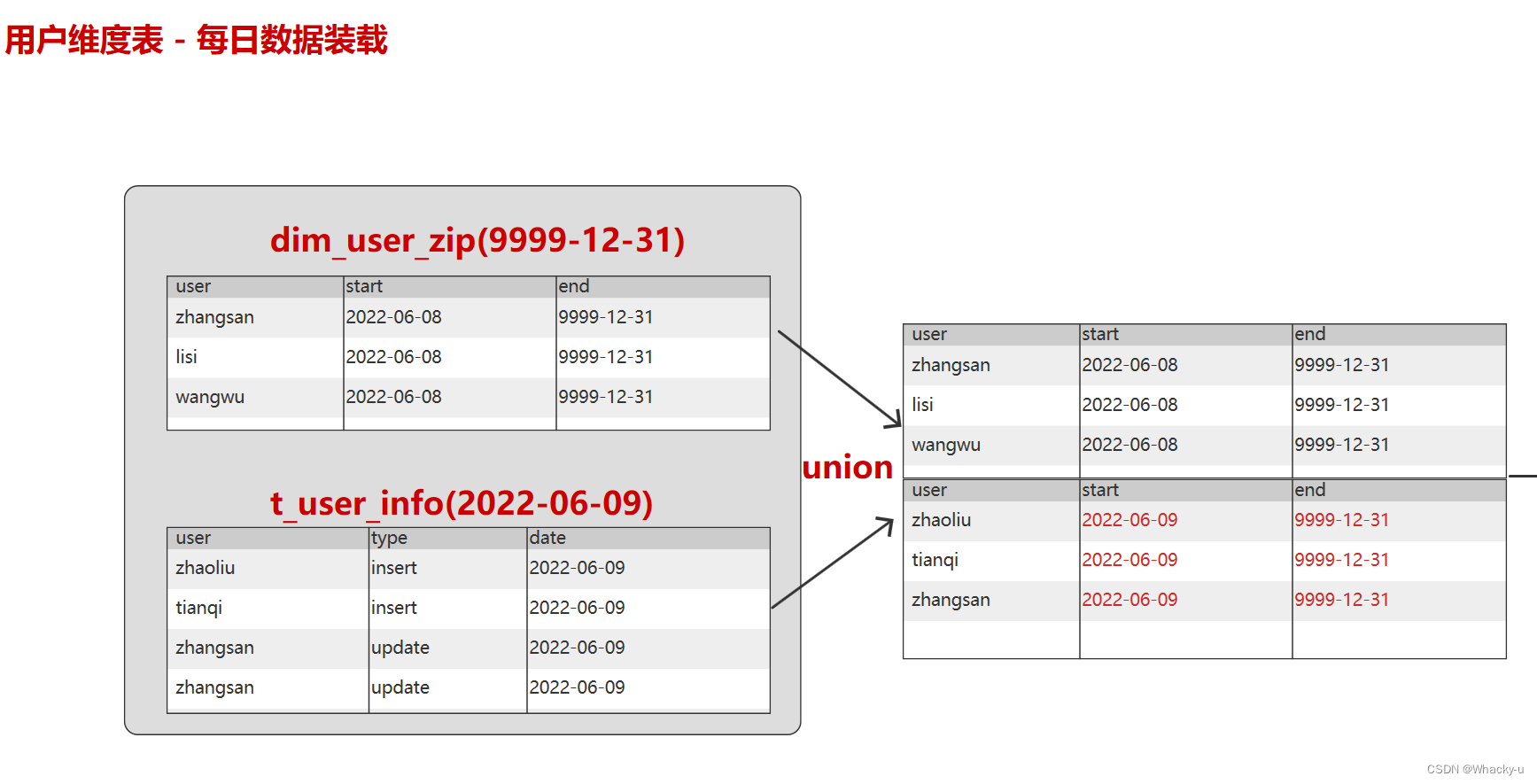
-- 所以我们不去每天同步一份全部的数据,而是将数据状态的变化记录下来,而不是全部数据,而是指定时间范围(start,end)-- 在表的设计中,需要增加两个额外的字段,用于表示时间范围(start,end)-- 表设计为拉链表(zip)-- 一般情况下,拉链表中截止到今天依然有效的状态的结束时间,为了不修改,所以设置为时间极大值9999-12-31
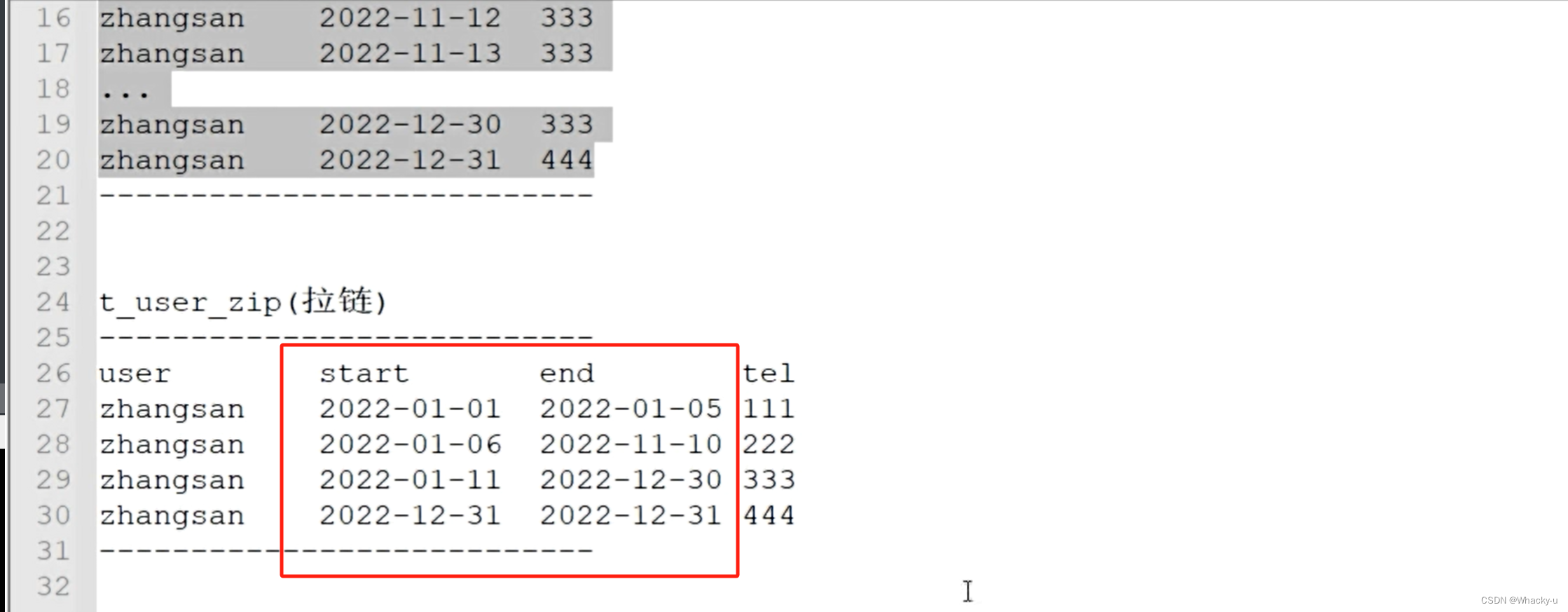
由于表的设计多了时间范围的两个字段(start,end)
所以单纯的insert通过查询语句插入,是不可以的
1、并且我们的数据源,不是ods层的全量表,而是ods层的增量表,但是增量表中的数据是json同步过来的,所以ods层中的增量表里面属性其实都是复杂数据类型,需要注意
2、同时那两个新增字段,需要分别讨论两种情况,是首日增量,和每日增量
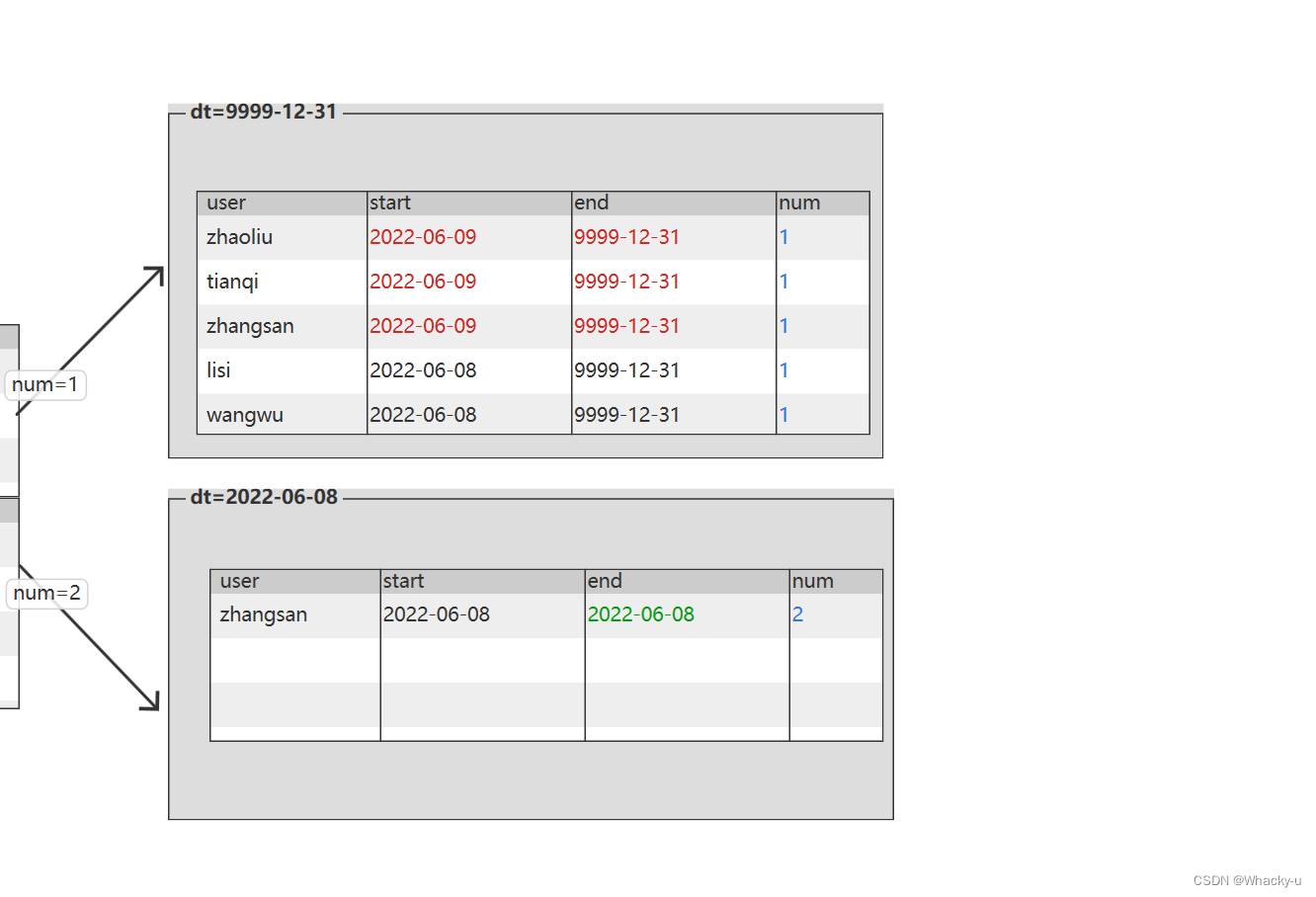
--拉链表的数据源应该是ods层增量表--增量表--Maxwell--数据格式:json--同步方式-- 首日:bootstrap(select)-- 每日:insert,update,delete(binlog)-- 所以首日全量表,和每日增量表也应该不一样-- 首日:全量--2022-06-08 : 数仓上线首日:user_info all--首日获取的全量数据只要用户的最新状态数据,不存在历史数据,所以无法判断状态的开始-- 所以折中的认为首日就是当前最新状态的开始日期-- 将最新状态的结束时间设为时间极大值9999-12-31--拉链表的分区策略--将数据存储到哪一个分区,更方便我们的查询--假设将用户数据保存到用户的开始日期的分区中:可能出现当天状态改变,就会和别的用户不统一,不知道这个日期是新还是旧--假设将用户数据保存到用户的结束日期的分区中--所以,最后分区应该将数据存储到结束时间所在分区

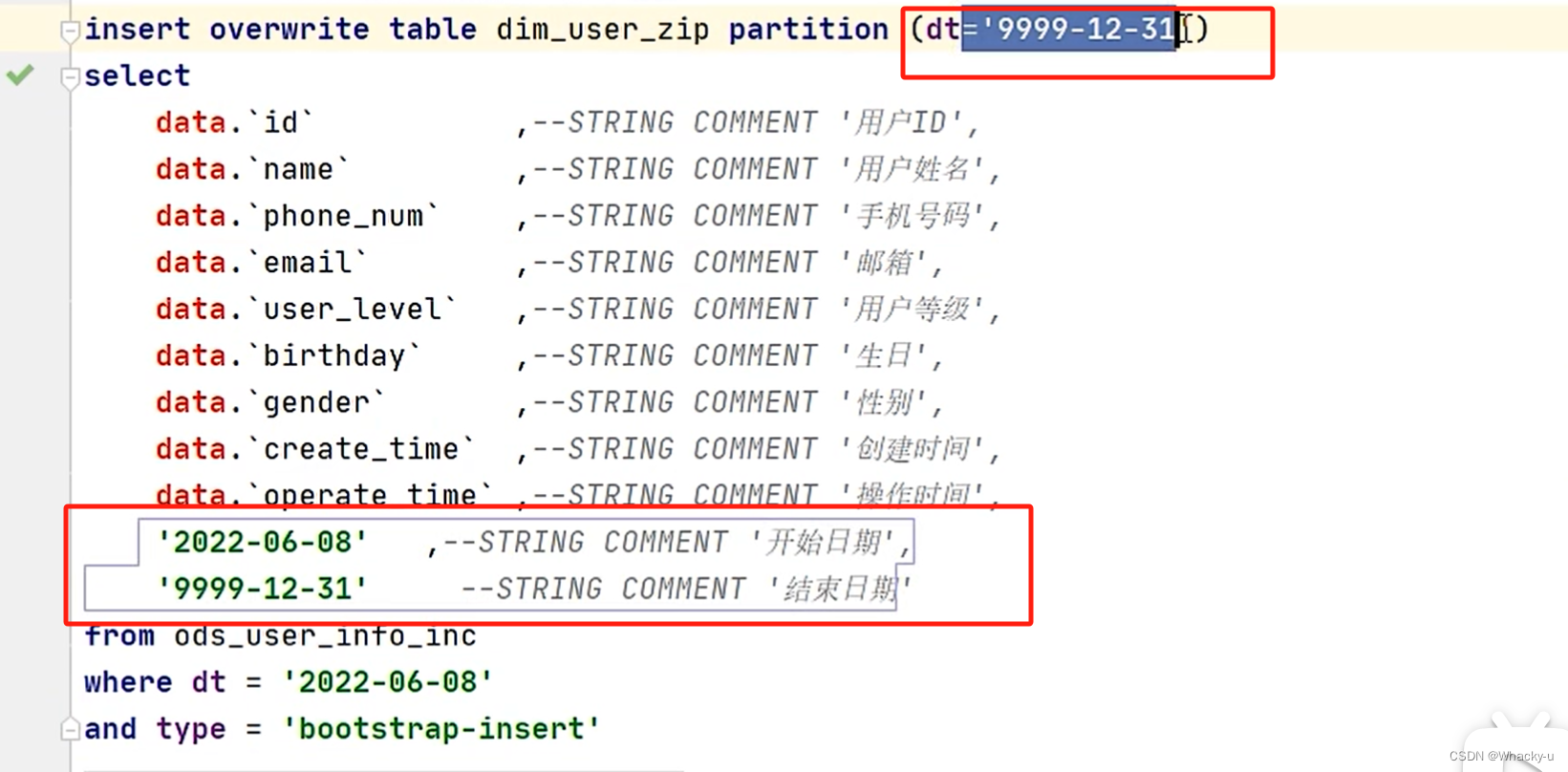
注意上面查询中,是type为bootstrap-insert,而不是insert
--每日:增量--获取的数据-- 增加的用户信息type : insertstart : 当天(2022-06-09)
end : 9999-12-31partition : 9999-12-31-- 修改的用户信息--修改后type : updatestart : 当天(2022-06-09)
end : 9999-12-31partition : 9999-12-31--修改前
dim_user_zip(dt=9999-12-31)start : 同原表的startend : 9999-12-31->2022-06-08partition : 9999-12-31->2022-06-08
这里修改,不用update,效率太低了,更改数据的时候,通过insertinsert overwrite table xxx
select'2022-06-08' dt
fromselect'9999-12-31' dt
) t
思路
-- 如果不明白,可以重新看一下视频126、127
最后这一步涉及到的是动态分区,但是默认是关的
需要打开一下:
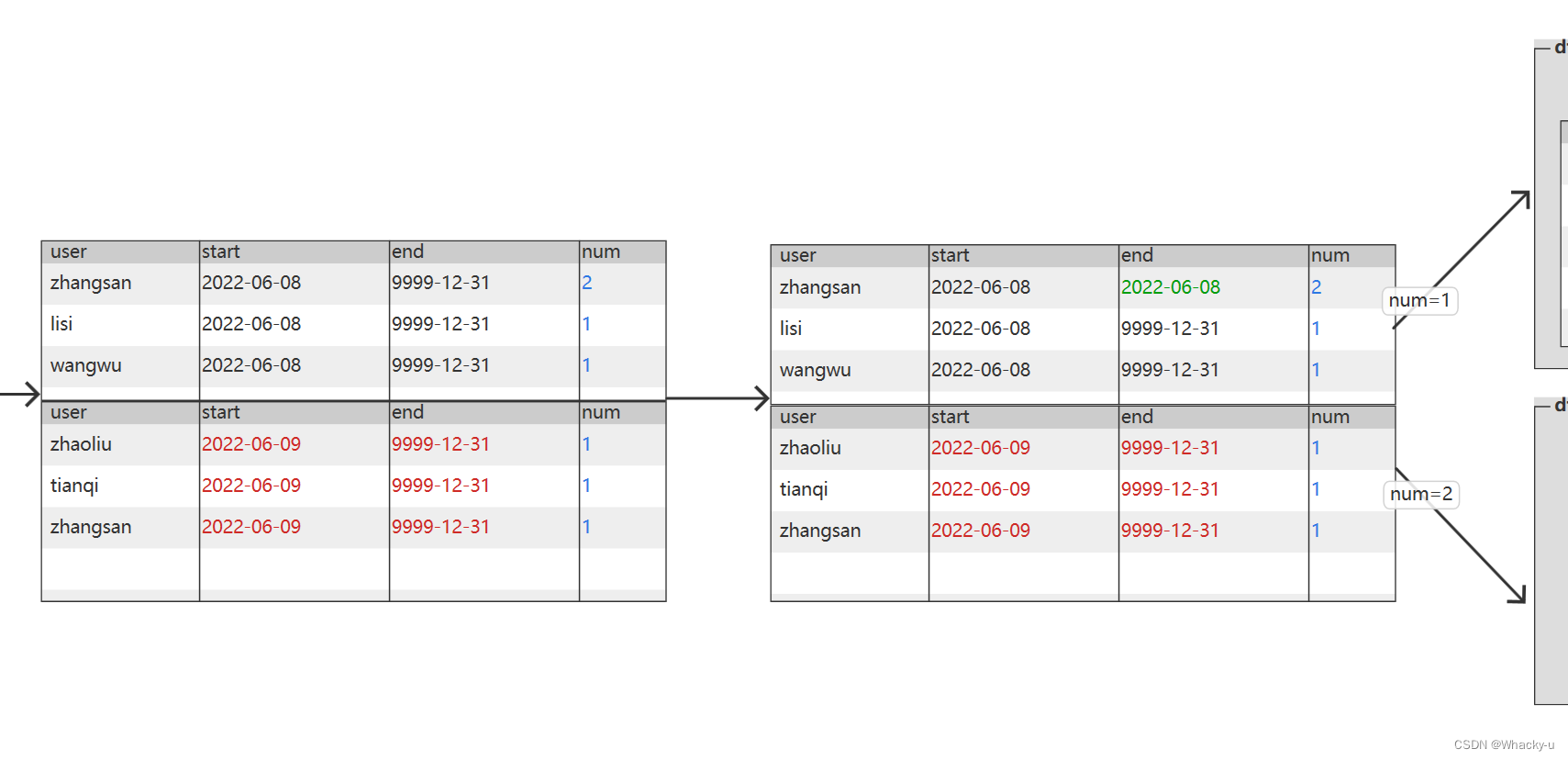
set hive.exec.dynamic.partition.mode=nistrict;-- 另外需要注意,我们这里因为是按天统计的,所以我们只要获取同一用户当天最晚的一次操作就可以获取其最新状态。-- 也就是说,我们在写sql的时候需要只留下前一天最后修改的数据,每一个用户只留下一条数据即可,通过开窗函数row_number即可做到from(selectdata.id,data.name,data.phone_num,data.email,data.user_level,data.birthday,data.gender,data.create_time,data.operate_time,
row_number()over(partitionbydata.id orderby ts desc) rn
from ods_user_info_inc
where dt ='2022-06-09') t1
where rn =1
6、数据装载脚本
需要区分首日装载脚本和每日装载脚本
首日:人工
每日:自动化
1)首日装载脚本
ods_to_init.sh
需要两个参数:表名/all , 时间日期
2)每日装载脚本
ods_to_dim.sh
需要两个参数:表名/all , 时间日期
但是如果没有日期参数,就自动去计算前一天日期,将此日期放入
7、DWD层(data warehouse detail)
1、主要内容及框架
// 如果不知道如何区分理解事实表,状态表。也就是DWD层和DIM层的区别// 可以看电商数仓6.0的第140节课程讲解
--DWD层--data warehouse detail--detail:详细,明细--加工数据,为统计分析做准备--对ODS层的数据进行加工,为后续的统计分析做准备--DIM层主要功能其实是分析数据:面向状态,所以大部分都是全量表--DWD层主要功能其实是统计数据:面向行为,大部分是增值表--DWD层的表主要保存的就是业务行为数据,表的设计需要遵循建模理论 -维度建模 -事实(行为)表-- 数据的存储格式:列式存储【因为是为了统计分析】-- 压缩方式:snappy--命名规范-- 分层标记(dwd_) + 数据域(分类:比如交易域、流量域、用户域等等) + 行为 + 全量 / 增量-- 原则上来讲,所有的行为都应该是增量数据-- 特殊情况下,会采用全量方式实现行为统计【周期快照事实表】
2、事实表
事实表分类:事务事实表、周期快照事实表累计快照事实表
事实类型【度量值类型】:
1、可加事实:度量值可加
2、半可加事实:度量值在某些场景可加,在某些场景不可加
3、不可加事实:比率
--事实表--包含维度、--维度越多,行为越详细,维度越少,行为越简单--包含度量值-- 所有的行为必须可以用于统计,这里用于统计的值(字段)就是度量值!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!--事实表分类--事务事实表-- 绝大多数的事实表都是事务型事实表--事务:原子性--原子操作:独立行为,不能再被切分了。-- 比如登录行为就不是,因为登录失败和登录成功是两种流程,所以就不能将登录行为当作一种行为--所以行为可以不定义说登录,而是登录成功,这就具备原子性了--下单这这种行为是只可能是系统或者网络等原因的,不是由于用户本身失败的,所以也可以理解成是独立行为--粒度:行为描述的详细程序,称之为粒度--描述的越详细,粒度越细,称之为细粒度--维度越多,粒度越细--描述的越简单,粒度越粗,称之为细粒度--维度越少,粒度越粗--周期快照事实表--累计快照事实表
1)事务事实表
1、举个例子
创建步骤:
-- 选择业务过程 : 确定创建什么表-- 声明粒度 :确定行,确定一行数据的描述了什么-- 确认维度 :确定列-- 确认事实 :确定度量值,必须有字段可以用于统计
举个例子:
--交易域加购事务事实表--交易域--加购--购物车中没有这个商品,新增商品--购物车中有这个商品,增加购买商品的数量--事务事实表--表 :dwd_trade_add_cart_inc--行 :用户 + 时间 + 商品 + 商品数量--列 :user + date + sku + num--度量值 :num + 加购次数-- 建表DROPTABLEIFEXISTS dwd_trade_cart_add_inc;CREATE EXTERNAL TABLE dwd_trade_cart_add_inc
(`id` STRING COMMENT'编号',`user_id` STRING COMMENT'用户ID',`sku_id` STRING COMMENT'SKU_ID',`date_id` STRING COMMENT'日期ID',-- 这个时间是和维度相关的,所以加上的,如果需要和时间分析,需要时间维度表`create_time` STRING COMMENT'加购时间',-- 这个时间是和行为相关的`sku_num`BIGINTCOMMENT'加购物车件数')COMMENT'交易域加购事务事实表'
PARTITIONED BY(`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/gmall/dwd/dwd_trade_cart_add_inc/'
TBLPROPERTIES ('orc.compress'='snappy');
数据装载
-- 数据装载-- 数据源还是ods层的增量数据中获取需要的数据 -- 数据格式:json。所以获取属性值的时候需要data.id等等,加一个data -- 首日 :全量 --包括历史数据(4、5、6、7好几天的数据)--无法判断行为》 比如加购的商品数量,根本不知道是加购的数量,还是减量后的数量--折中地认为,当前数据全部都是新增购物(加购)-- 每日 :增量--当天新增及变化-- 分区策略:-- 哪一天的行为数据就存放到哪一天的分区中-- 首日的数据需要动态分区,因为首日数据,是全量数据,包括历史数据,包括历史的那些create_time,所以只能用create—_time作为分区字段-- 每日的数据,就只有一天的,就不需要动态分区了
所以在装载的时候需要分清楚首日和每日
在通过select查询insert的时候,where语句中的type需要时bootstrap-insert还是insert等等
在每日的数据加载时候,如果是insert,那时间应该是create时间,如果是update操作,那时间应该是对应的operate时间
2、需要注意的事项!!!!!!!!
- 创建表的时候要保证行为的原子性,比如支付行为,我们单独写支付成功,而不是支付
- 创建表在确定字段的时候,要保证有可以用于统计的度量值,类似交易金额之类
- 由于我们在创建表的时候是关于行为的,所以基本都是基于行为数据,也就是增量表,所以在装载数据的时候需要区分首日装载和每日装载,这两类行为的type需要注意,是不一样的,在where条件里面
- 并且由于增量表都是json数据,所以在select的时候属性,应该是data.属性名字
- 另外首日装载,因为ods首日数据的inc里面包括历史数据,所以我们需要动态分区。首日数据是ods保存到了6-08,但是里面包括4号到8号的所有历史数据,很多的create_time,所以需要动态分区,哪一天create的,就分区到哪一天的分区。但是每日装载就不需要动态分区了
- 在装载数据的时候,join需要注意,因为我们需要的是原子性行为,有时候还是left的话就会忽略,还有一些购物行为,会具有零点漂移问题,比如十二点前加入的订单,但是12点后才支付成功,这就是两个时间了,没法直接join,需要更改一下where条件。这个都在交易域支付成功事务事实表例子中可以看到
- 由于事务事实表create的时候必须要度量值字段,但是有些时候也可能有隐藏的统计度量值,就是没有可以写在表的创建过程中,但是也可以统计,并且日志数据没有历史数据,而且不是maxwell获取的,所以不会需要划分首日和每日。比如:
-- 工具域优惠券使用(支付)事务事实表--用户 + 时间 + 订单 + 优惠券 + 次数(隐藏的度量值,并不会在建表语句中) - 在每日装载的时候,需考虑数据库gmall原本数据的逻辑,有的数据只有insert【比如收藏表】,有的数据只有update【比如支付表】,明确这些后再去写每日装载的sql语句
- 有时候数据装载的时候,不一定都是从业务数据库中找,也可能是行为日志中去获取。同时数据加载时也需要考虑拿页面浏览日志还是APP启动日志,这个是通过where筛选列的属性名字区分的。因为在生成ods中的log表时候,是将两个日志的列属性一起放进去的,而app启动日志是没有page属性值的,也就是说page属性值是空的那一行数据就是属于APP启动日志的,where dt=‘2022-06-08’ and page is not null; 这么筛选就可以
-- 流量域页面浏览事务事实表--流量域--页面浏览-- 用户 + 时间 + 上一个页面 + 当前页面 +(次数,是隐藏度量值,一行数据代表一次) + 停留时间(也可以当作度量值)/* 由于页面不属于电商的业务,所以不能在业务数据中找到,要去日志数据中找 */-- 数据装载--日志的数据分为两大类--页面浏览日志--APP启动日志--只需要页面浏览日志``````// 会话的概念可以看看视频的第150节一个用户很久不用,会话会中断,再次使用的时候相当于连接了一个新的会话而计算机就是针对会话进行统计的哪怕是同一个用户,但是由于一些原因,分成两个会话,也会被计算机看作是两个操作,两个人 - 注册一个概念:
--页面浏览日志,离开页面的时候--怎么才算注册成功:必须浏览了注册页面,并且生成了uid,并且在业务数据库中的业务表中增加了用户信息-- page.page_id='register'-- and common.uid is not null - 登录和注册不一样,登录可能不需要每次都登陆,但是默认登录了【比如是十天免登录这种选项,但是注册不会这样】会话内第一个uid不为null的页面就对应一次登录操作【但是不同公司不同处理方式】。其实就是找每一个会话中的第一个uid【通过开窗函数】
2)周期快照表
一些图书的需求,不需要特殊的计算,或者关联表,因为效率太低,可以直接从业务数据中获取特殊字段(存量)[比如商品库存,账户余额等]
特殊字段不需要进行多张表的关联计算,直接从业务数据库中周期性地获取即可
比如购物车商品数量,不用非得加购 - 减购,直接就有sku_num, 表示当前购物车中商品剩余数量
可以直接
DROPTABLEIFEXISTS dwd_trade_cart_full;CREATE EXTERNAL TABLE dwd_trade_cart_full
(`id` STRING COMMENT'编号',`user_id` STRING COMMENT'用户ID',`sku_id` STRING COMMENT'SKU_ID',`sku_name` STRING COMMENT'商品名称',`sku_num`BIGINTCOMMENT'现存商品件数')COMMENT'交易域购物车周期快照事实表'
PARTITIONED BY(`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/gmall/dwd/dwd_trade_cart_full/'
TBLPROPERTIES ('orc.compress'='snappy');
数据加载的时候应该用全量表的数据,因为需要定期 完整的去记录需要的数据
3)累积快照事实表
特殊的需求:下单到支付时间间隔的平均值
把多个行为状态数据累积在一张表中,但是这些行为状态数据最好是有关系的。
将一个流程中的多个行为累积到一个表中
举个例子
DROPTABLEIFEXISTS dwd_trade_trade_flow_acc;CREATE EXTERNAL TABLE dwd_trade_trade_flow_acc
(`order_id` STRING COMMENT'订单ID',`user_id` STRING COMMENT'用户ID',`province_id` STRING COMMENT'省份ID',`order_date_id` STRING COMMENT'下单日期ID',`order_time` STRING COMMENT'下单时间',`payment_date_id` STRING COMMENT'支付日期ID',`payment_time` STRING COMMENT'支付时间',`finish_date_id` STRING COMMENT'确认收货日期ID',`finish_time` STRING COMMENT'确认收货时间',`order_original_amount`DECIMAL(16,2)COMMENT'下单原始价格',`order_activity_amount`DECIMAL(16,2)COMMENT'下单活动优惠分摊',`order_coupon_amount`DECIMAL(16,2)COMMENT'下单优惠券优惠分摊',`order_total_amount`DECIMAL(16,2)COMMENT'下单最终价格分摊',`payment_amount`DECIMAL(16,2)COMMENT'支付金额')COMMENT'交易域交易流程累积快照事实表'
PARTITIONED BY(`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/gmall/dwd/dwd_trade_trade_flow_acc/'
TBLPROPERTIES ('orc.compress'='snappy');
需要注意这里的数据加载:
-- 分区策略:因为这里涉及到了三个时间,所以需要好好考虑用什么时间进行分区--哪天的数据就存放到哪天分区--如果表中存在多个和业务相关的时间字段,一般会选择其中的一个业务时间作为分区字段-- 一般选择时间靠后的字段作为分区字段-- 存在一个问题,最后一个时间字段可能没值,一般不会采用null,所以采用极大值9999-12-31
-- 分区策略--查询的数据如何存储到表的分区中--查询数据的效率,数据有效--ODS层--一天采集到的数据就存储到表的一天的分区--DIM层--全量:每天一份全量数据存放到一天的分区中--拉链:会采用结束时间作为分区字段--DWD层--事务性事实表:一天的业务数据就存储到表的一天的分区--周期性快照事实表:将每一天的全部状态数据保存到一天的分区--累积型快照事实表:将业务流程中最后的那个时间字段作为分区字段
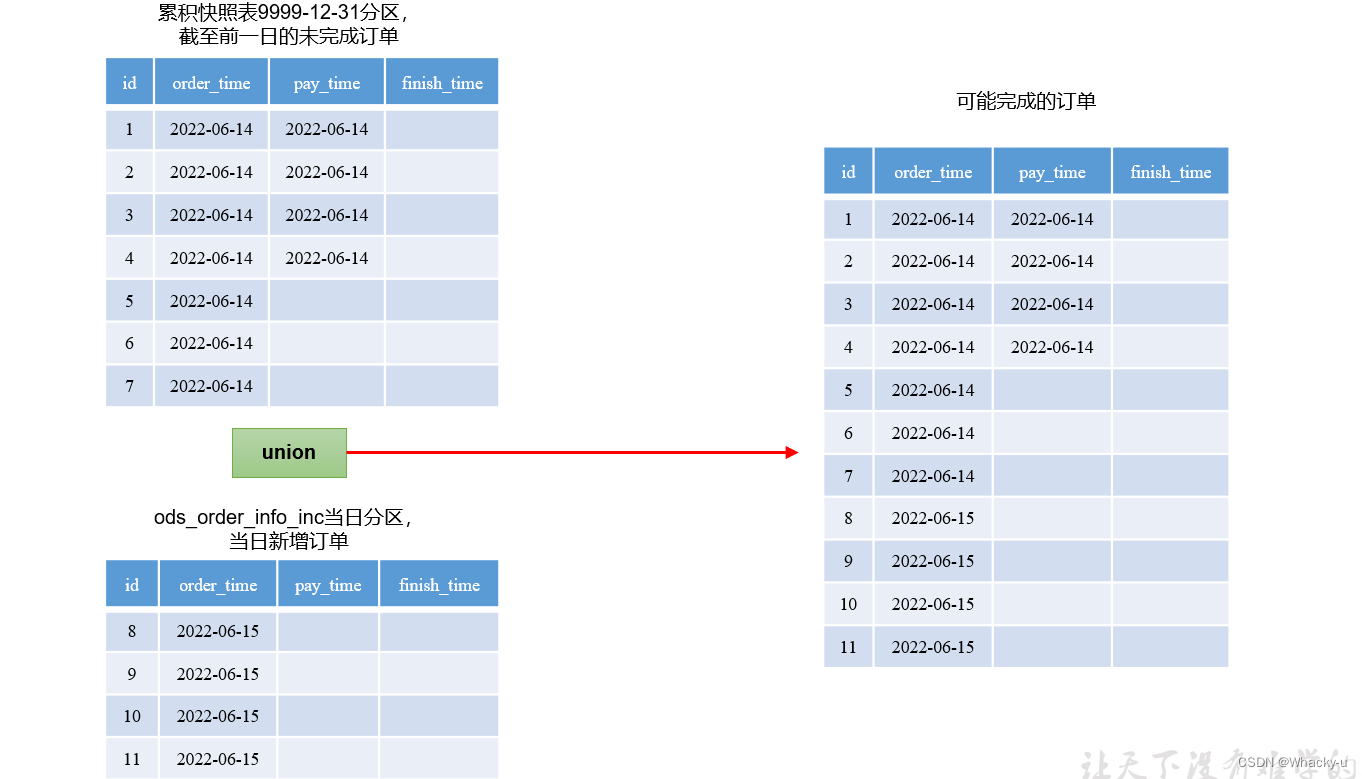
交易流程累积快照表中的首日加载和每日加载是不一样的
因为每日加载的时候支付表和收货信息需要对比新订单和旧订单,
由于我们在下订单的时候会自动增加支付信息的,而且如果没有收货的话会被统一划分到极大值9999-12-31分区,这就不知道到底支付没有,只能说确认收货的一定是支付了的,但是没有收货的不知道有没有支付
然后每日新增数据,这时候的支付表中,可能含有历史订单中在今日支付的,所以需要统一union起来一起对比判断
3、装载脚本
1、首日装载
// ods_to_dwd_init.sh
两个参数
第一个是表名字/all,第二个是日期
2、每日装载
// ods_to_dwd.sh
两个参数
第一个是表名字/all,第二个是日期
// 不过每日装载的数据,可以提供日期,也可以不提供,不提供的话就是取前一天的日期
8、数据上线日期偏差问题
// 主要看视频的第154节
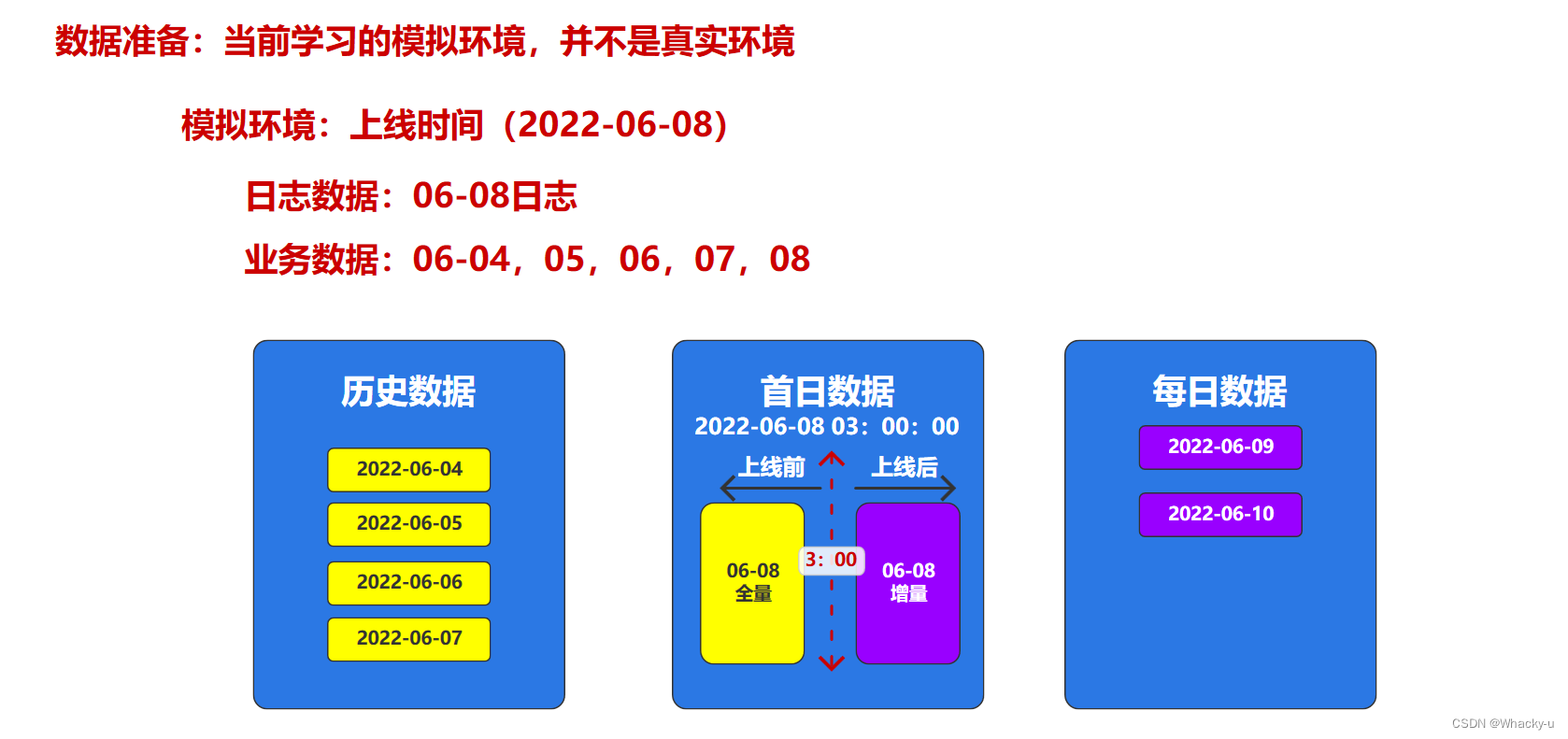
之所以在8号会划分两段,是因为数据通道打通需要一定的时间,****所以肯定没办法0点整准时打通
9、DWS层(Data Warehouse Summary)
这一层可以看出数仓设计能力强不强!!!!
这一层没有理论,能想到就设计出来,还会有一些问题容易注意不到,所以很看重能力
1、主要内容及框架
主要是用于最后计算中用到的中间表
提前把中间计算结果记录下来,进行预聚合,多个需求中都可以用到
(1)DWS层的设计参考指标体系。
(2)DWS层的数据存储格式为orc列式存储+snappy压缩。
(3)DWS层表名的命名规范为dws_数据域_统计粒度_业务过程_统计周期(1d/nd/td)。
注:1d表示最近1日,nd表示最近n日,td表示历史至今。
需要注意的:
DWS层表的字段再预统计时,如果字段可以跨越天【比如统计近七天每天下单数和下单人数,可能近七天都是同一个人下的订单,那下单人数就应该是1,而不是每天的这个下单人数1,进行求和】,那么就不能再每天中统计
因为最终统计需要指定的字段,但是提前聚合不能对这个字段做统计,所以为了避免数据丢失
需要在表中增加这个字段,而不是统计这个字段【就比如上面那下单人数的问题,解决办法就是把user_id放到表中】
主要内容
--DWS--Data Warehouse Summary-- Data Warehouse : 数据仓库-- Summary : 汇总(预聚合)-- 用于讲DIM,DWD的数据进行提前统计,将统计结果保存到当前的表中--所以当前的表不是最终的统计结果表-- 数据量就可能有点多,表的设计中应该添加分区--当前表需要进一步的聚合处理,所以表设计中应该是列式存储,snappy压缩-- 表的分类:根据数据范围进行分类--1d : 1天的数据的统计--数据来源为DIM、DWD--Nd : N天的数据的统计--数据来源为1d表--td : 所有数据的统计--首日+每日最好是这样用于统计,比较快,不要把之前所有天一点点累加--数据来源可以为1d表,也可以是DIM、DWD--表的设计-- 参考ADS层表的设计--指标体系:-- 原子指标(拆分指标)--行为,统计字段,统计逻辑-- 派生指标(增加指标)--统计周期(范围) + 业务限定(筛选条件) + 统计粒度(分组维度)-- 衍生指标(比例关系)--表名--(分层标记)dws_数据域_统计粒度_业务过程_统计周期(1d/nd/td)--指标:客户想要的一个统计结果(数值)--业务过程相同:数据来源相同--统计周期相同:数据范围相同--统计粒度相同:一行数据表示的含义相同
2、具体实现思路【重要!!!!!!!!】
- 确定需要的表,由于交易域用户商品粒度订单最近1日汇总表涉及的行为是下单行为【dwd_trade_order_detail_inc】,并且需要用到商品的信息【dim_sku_full】
- 进行表之间的连接
- 思考是先统计,还是先补全,如果需要统计的属性不需要补全就可以,那就先统计,反之,先补全
- 确定需要统计的派生指标,从上面确定的表中进行挑选数据
- 然后去写where筛选数据,并且确定统计时间范围
- 最后加上group by,以及具体的统计逻辑【就是一些分组函数】去实现统计粒度的实现
- 最后需要检查分组使用的属性是否会出现问题,不要冲突。另外就是看看避免统计重复,因为如果不是一天的话,而是近几天的情况,基于1d的表统计时,可能会出现重复统计的问题。比如每一天就一个用户下单,还都是同一个用户,那统计近7天的时候就会每一天都是这个用户,就会当作是7个不同的,但实际只是同一个人,这样就会出现问题
- 另外,就是分区问题,有些数据统计的时候因为全量表的首日,和增量的首日中都是包括历史数据,所以我们不能单纯的直接就写一个日期用作分区。而需要动态分区
- 但是加的属性,要么是常量,要么就是聚合函数,要么就是分组字段,因为不是这些的话,使用group by就会报错
上面是解决思路下面是代码思路:【很重要!!!!!!!!!!!!!】-- 一般都是由浅入深--1、先补全数据,就是补全我们建表语句中用到的属性,然后再去进行写聚合函数这些进行统计【效率低】 => 逻辑简单(缺什么,补什么)--2、先统计数据,然后再去优化(连接之前减少数据) 【效率高】=> 之所以可以进行优化,是因为统计的结果和补全数据没有任何的关系但是如果统计的结果和补全数据有关系,则需要先补全再统计- 一般1d的表由于首日涉及到之前的数据,所以需要分为首日数据加载,和每日数据加载。首日数据加载是动态分区,而每日的就直接用业务日期分区即可
- 而td表也需要分为首日和每日数据加载
-- 需要注意的是,td表,就是历史至今表的数据装载一般为了考虑效率,会分成首日装载和每日装载-- 首日装载 : 直接获取所有的数据做聚合-- 每日装载 : 装载的数据只比前一天多了一天的数据,而前一天的数据已经统计过了,所以就存在重复计算--改善装载的思路:获取昨天的统计结果 + 今天的新数据 =》 做进一步的聚合 - 上面说的那种就是利用union,不过在最外层可能还需要重新根据统计粒度用一次 group by
3、具体表:举个例子
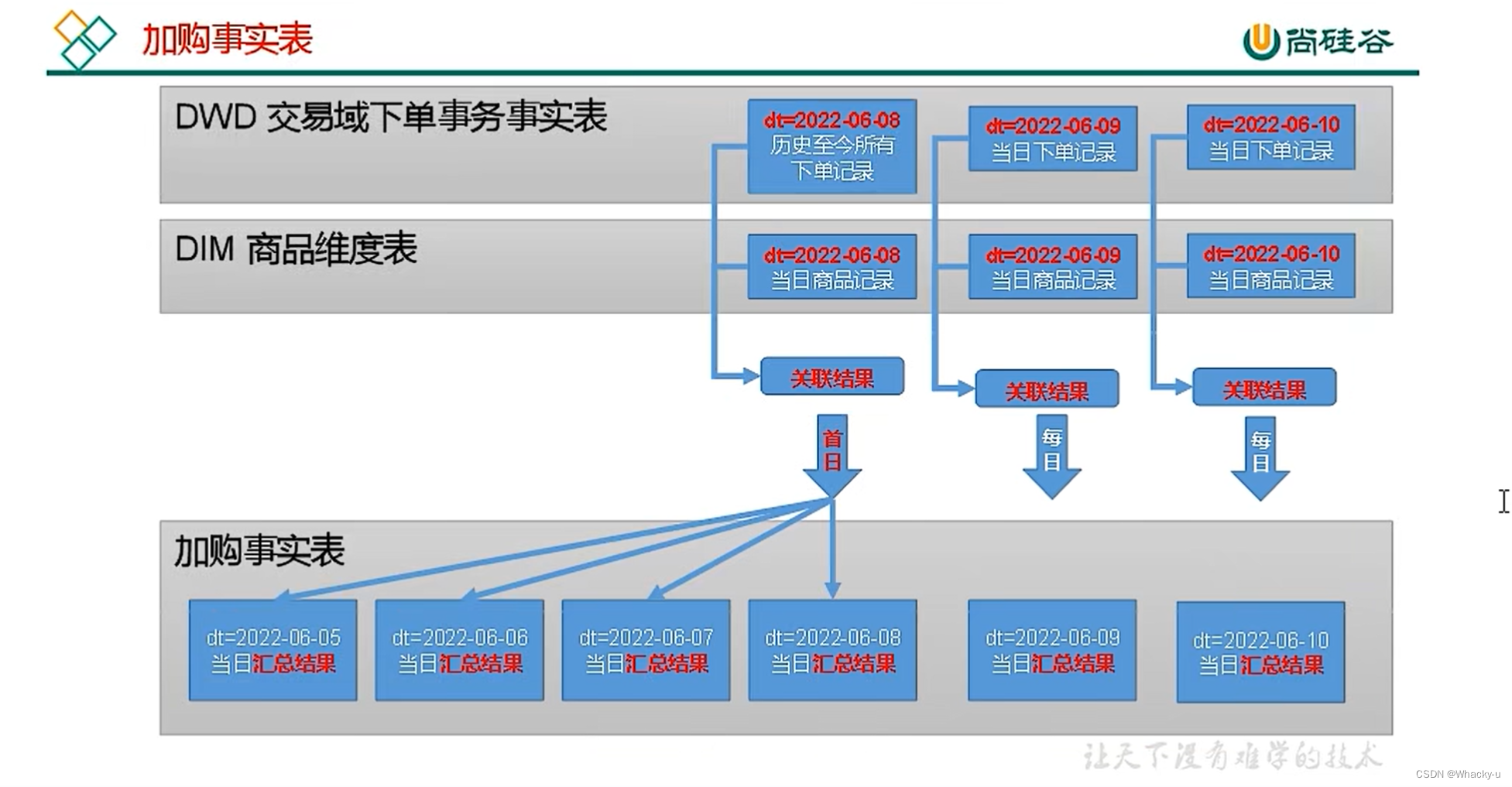
交易域用户商品粒度订单最近1日汇总表
1d表的数据装载,分为首日装载和每日装载
-- 首日装载:包含历史数据-- 每日装载:包含当前数据
代码
--首日set hive.exec.dynamic.partition.mode=nonstrict;-- Hive的bug:对某些类型数据的处理可能会导致报错,关闭矢量化查询优化解决set hive.vectorized.execution.enabled =false;insert overwrite table dws_trade_user_sku_order_1d partition(dt)select......
dt
from(select
dt,
user_id,
sku_id,count(*) order_count_1d,sum(sku_num) order_num_1d,sum(split_original_amount) order_original_amount_1d,sum(nvl(split_activity_amount,0.0)) activity_reduce_amount_1d,sum(nvl(split_coupon_amount,0.0)) coupon_reduce_amount_1d,sum(split_total_amount) order_total_amount_1d
from dwd_trade_order_detail_inc
groupby dt,user_id,sku_id
)od
leftjoin(select
id,
sku_name,
category1_id,
category1_name,
category2_id,
category2_name,
category3_id,
category3_name,
tm_id,
tm_name
from dim_sku_full
where dt='2022-06-08')sku
on od.sku_id=sku.id;-- 矢量化查询优化可以一定程度上提升执行效率,不会触发前述Bug时,应打开set hive.vectorized.execution.enabled =true;
4、统计粒度的变化
1)如果统计粒度减少,然后需求分别是针对减少的统计粒度进行统计,或者是针对其他字段进行统计
2)当需求的统计粒度发生变化,不属于表中任何一个统计粒度,此时必须判重
对其他字段进行进一步统计,需要聚合数据
3)粒度没有变化,可以直接将中间表的数据获取后使用
4)粒度变粗,数据需要进一步聚合
-- 在ads中,看讲义的商品主题中的,最近30日各品牌复购率-- 涉及到了粒度转换的应用,需要赚了两次粒度
5、数据装载脚本
nd表的只有每日装载脚本,1d和td都是首日和每日两类脚本
不过这里有个顺序问题!!!!!!!,因为1d和nd,还有td三类都有脚本
先执行1d表,然后再执行nd和td表
1、首日装载
1d表: dwd_to_dws_1d_init.sh
nd表: 无
td表: dws_1d_to_dws_td_init.sh
同样是all + 日期
2、每日装载
1d表: dwd_to_dws_1d.sh
nd表: dws_1d_to_dws_nd.sh
td表: dws_1d_to_dws_td.sh
同样是all + 日期
10、ADS层(Application data service)
1、主要内容及框架
--ADS层--Application : (数据仓库)应用--Data : 用户需求的统计结果数据--service : 对外服务--1、ADS层保存的数据是最终的统计结果,无需做进一步的计算-- 因为不需要再计算了,所以不需要列式存储,也不需要snappy压缩--2、统计结果的目的是对外提供服务,所以表不是最终数据的存储位置-- 需要将表中的数据同步发哦第三方存储(MySQL)--由于MySQL是行式存储,所以ADS层的表最好是行市存储,不选json,orc,最好选tsv(DataX)--压缩格式采用gzip--3、统计结果的数据量不会很多,因为这是想要展示给用户看的。-- ADS层的表无需分区设计【数据比较少,没必要分区】--4、表的设计--ODS层 : 表的结构依托于数据源的数据结构(ER模型)--DIM层 : 遵循维度模型的维度表的设计理念(维度越丰富越好)--DWD层 : 遵循维度模型的事实表的设计理念(粒度越细越好)--ADS层 : 客户要啥你加啥,不要额外添加--基础概念--维度:分析数据的角度--粒度:描述数据的详细程度-- 统计周期 : 统计的时候,数据统计时间范围--【统计日期:以获取数据的那一天为准(包含数据的那一天,比如我要统计8号最近一周,但是程序可能是9号开始跑的)】--2022-06-08(统计最近一周):02 03 04 05 06 07 08--2022-06-09(统计最近一周):03 04 05 06 07 08 09-- 统计粒度 : 分析数据的具体角度(根据需求,具体的分析角度),称之为统计粒度(站在哪一个角度分析)
这个需要看看统计粒度和数据源粒度是不是一样的!!!!!!不一样的话根据之前的笔记《统计粒度的变化》进行sql的编写!!!!
-- 指标 : 客户想要的一个结果数值
比如,下面举个例子:
2、举个例子
-- 各品牌商品下单统计-- 统计的行为:下单-- 分析的角度:品牌-- 指标: 下单数量,下单人数--统计日期:以获取数据的那一天为准(包含数据的那一天,比如我要统计8号最近一周,但是程序可能是9号开始跑的)DROPTABLEIFEXISTS ads_order_stats_by_tm;CREATE EXTERNAL TABLE ads_order_stats_by_tm
(`dt` STRING COMMENT'统计日期',`recent_days`BIGINTCOMMENT'最近天数,1:最近1天,7:最近7天,30:最近30天',`tm_id` STRING COMMENT'品牌ID',`tm_name` STRING COMMENT'品牌名称',`order_count`BIGINTCOMMENT'下单数',`order_user_count`BIGINTCOMMENT'下单人数')COMMENT'各品牌商品下单统计'ROW FORMAT DELIMITED FIELDSTERMINATEDBY'\t'
LOCATION '/warehouse/gmall/ads/ads_order_stats_by_tm/';
数据加载
首先举个例子,然后再给出上面建表语句实际的数据加载语句
--数据加载--统计指标分析--将复杂的指标分解成小的,简单的指标-- 1、原子指标(最基础的统计指) --业务过程(行为) + 度量值 + 聚合逻辑(求和还是求平均值之类的)--下单 + 次数 + count()selectcount(distinct order_id)from dwd_trade_order_detail_inc
-- 2、派生指标--基于原子指标,增加其他的条件,角度之类--派生指标 = 原子指标 + 统计周期(最近7天) + 业务限定 + 统计粒度--统计周期和业务限定都是数据的筛选条件,但是不一样--业务限定一般指的是数据约束条件(数据字段的过滤,过滤文件)--统计周期一般指的是数据时间范围(分区字段的过滤,过滤文件夹)selectcount(distinct order_id)--原子指标from dwd_trade_order_detail_inc
where dt >= date_sub('2022-06-08',6)and dt <='2022-06-08'--统计周期anduser.sex ='男'--业务限定groupby 品牌 --统计粒度-- 3、衍生指标--将多个派生指标进行计算
实际加载的时候,本来需要考虑到首日每日装载,由于不分区,每日装载如果还用insert overwrite,就会覆盖之前的数据
所以这里有一个技巧,就是不用写两份首日和每日装载sql,先查询一下这个表的数据,然后和本次的sql语句进行union,不是union all,就还可以overwrite
还有取全量表数据时候,尽管是需要2号到8号,但是只取8号就够了【这样就避免重复取数据】,因为是全量表,没有删除操作【具体情况具体分析,电商设计的是没有直接删除的,就是标记一下这个数据被删了】,只有逻辑删除,就是标记一下,但是如果计算数量的话,那个数据还是存在的
具体的解释可以看第158节视频的最后
insert overwrite table ads_order_stats_by_tm
select*from ads_order_stats_by_tm -- 关键步骤!!!!!!!!! 多union了一个表的自己unionselect......
3、需要中间表
td表,就是历史至今表:dws_first_order_td
创建表
首日装载
每日装载,用到了union,避免数据重复,相当于在首日的基础上,进行去重union
nd表,就是最近n日汇总表
// 视频的159-161,dws层中也会讲
4、数据装载脚本
dws_to_ads.sh
两个参数,表名,命令执行日期
11、【总结】数仓构建流程
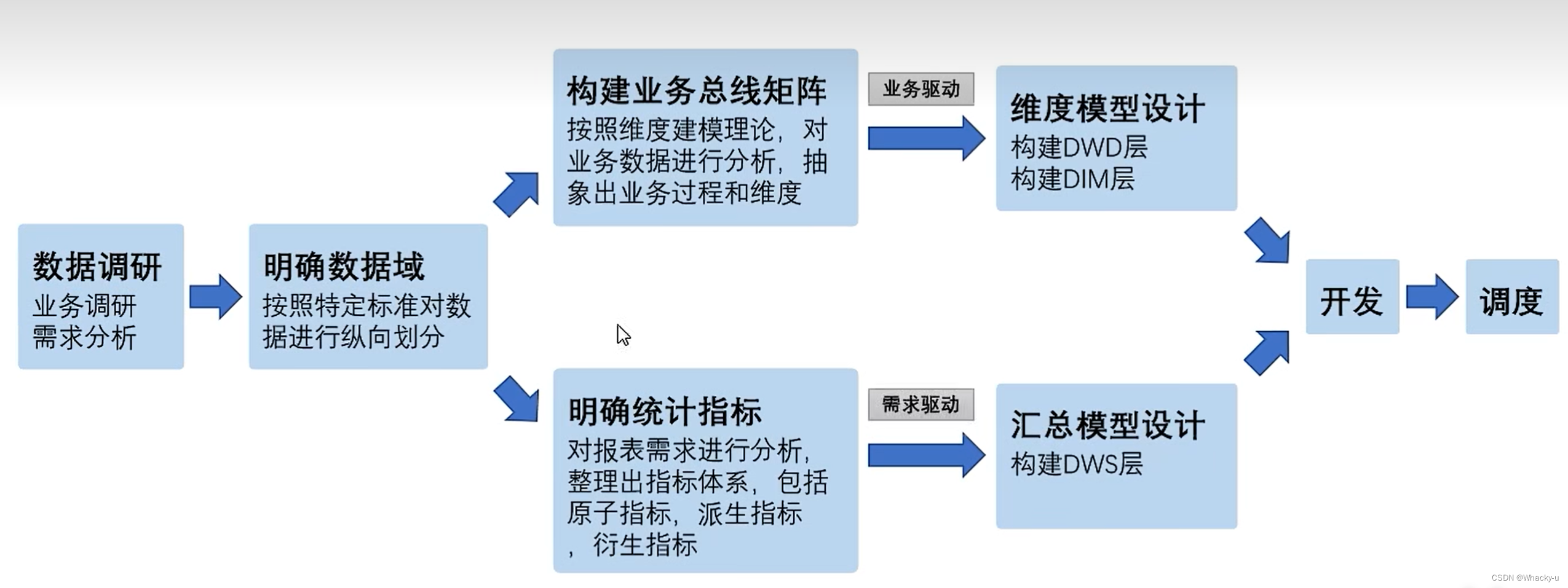
其中业务总线矩阵,就像是一个分析的笔记.后面还会有各个属性值和度量值的统计等
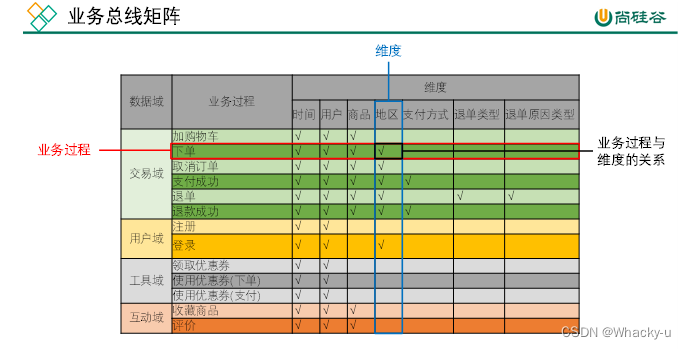
// 见讲义中第四个讲义数仓的第5章
12、报表数据导出
为方便报表应用使用数据,需将ads各指标的统计结果导出到MySQL数据库中。
1、新建数据库
使用mysql,创建数据库gmall_report,用来存放记录数仓输出数据。
2、数据导出
数据导出工具选用DataX,选用HDFSReader和MySQLWriter
这里导出ads数据的dataX
也是用的生成器,去生成DataX的配置文件
修改生成器需要的配置文件

执行命令
java -jar datax-config-generator-1.0-SNAPSHOT-jar-with-dependencies.jar
3、编写每日导出脚本
hdfs_to_mysql.sh all
其实all表示的含义是,命令 + 配置文件 + 需要导出保存到的地址
13、数据仓库工作流调度 【任务调度器:DolphinScheduler】
Apache DolphinScheduler是一个分布式、易扩展的可视化DAG工作流任务调度平台。致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。
解压安装包后,并不像其他工具一样,可以直接使用
而是还需要安装才能使用
1、安装配置
- 更改配置文件install_config
- 初始化数据库,拷贝MySQL驱动到DolphinScheduler的解压目录下的lib中,要求使用 MySQL JDBC Driver 8.0.31。
- 命令行输入初始化脚本。数据库初始化脚本位于DolphinScheduler解压目录下的script目录中,script/create-dolphinscheduler.sh
- 一键部署【安装】:先启动zookeeper,然后在文件夹目录下执行命令行:./install.sh
- 访问UI:DolphinScheduler UI地址为http://hadoop106:12345/dolphinscheduler初始用户的用户名为:admin,密码为why20000615
- 在页面的安全中心,创建租户【因为脚本执行需要权限,而admin是没有权限的,只是管理账户】,执行这个的时候需要启动hdfs,而租户其实就是why_hadoop
- 点击用户管理,创建用户名字why_hadoop 密码why20000615。admin用户是做管理的,why_hadoop用户是做业务的。这样就可以退出页面,重新登录这个创建的用户即可
- 平常的DolphinScheduler启停命令DolphinScheduler的启停脚本均位于其安装目录的bin目录下
-- 1)一键启停所有服务./bin/start-all.sh./bin/stop-all.sh注意同Hadoop的启停脚本进行区分。-- 这里需要注意 !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!可能在一键启停所有服务的之后,还需要单独启停 Master !!!!!!!!!!2)启停 Master./bin/dolphinscheduler-daemon.sh start master-server./bin/dolphinscheduler-daemon.sh stop master-server3)启停 Worker./bin/dolphinscheduler-daemon.sh start worker-server./bin/dolphinscheduler-daemon.sh stop worker-server4)启停 Api./bin/dolphinscheduler-daemon.sh start api-server./bin/dolphinscheduler-daemon.sh stop api-server5)启停 Logger./bin/dolphinscheduler-daemon.sh start logger-server./bin/dolphinscheduler-daemon.sh stop logger-server6)启停 Alert./bin/dolphinscheduler-daemon.sh start alert-server./bin/dolphinscheduler-daemon.sh stop alert-server``````//DolphinScheduler 界面使用,可以看视频197、198节!!!!//平常工作流也都需要先点击,上线,然后再运行// 主要看怎么设置定时,需要点击任务的上线,以及定时的上线// 还有传参//DolphinScheduler 参数的优先级从低到高为:上游任务传递的参数<全局参数<本地参数。2、任务调度
2、任务调度
课程中由于内存问题,最后用到的是单机模式
首先需要理清楚脚本的先后顺序
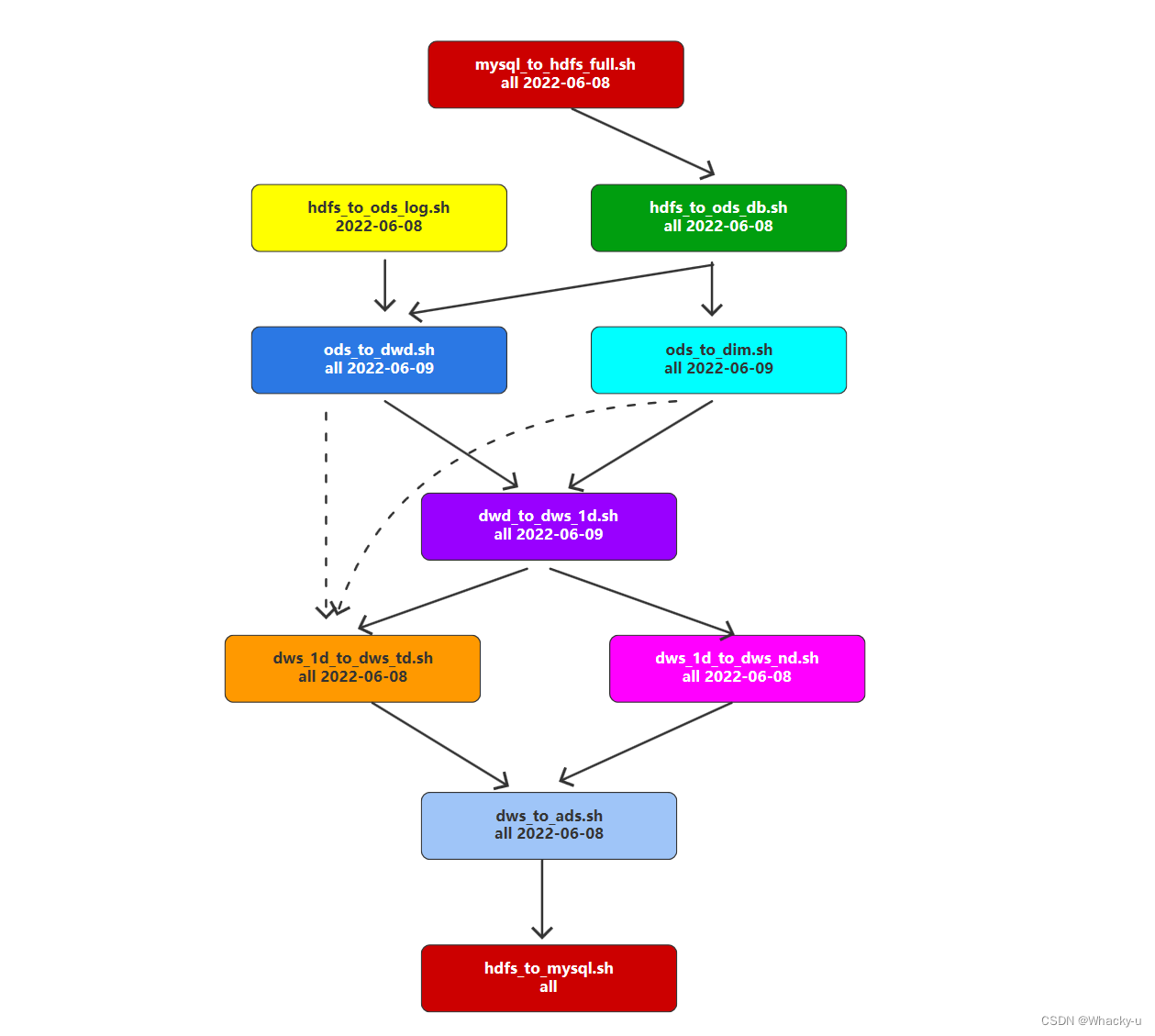
然后在admin管理员账户里面在安全中心中的环境管理里面创建环境,将需要用到的组件环境配置复制进去
之后登录用户账户,在资源中心创建文件夹,里面存放脚本文件
在项目管理中点击创建项目,创建工作流,按照脚本先后顺序,创建shell先后顺序,并且设置好脚本及参数
最后保存的时候,需要注意!!选择租户,【【因为脚本执行需要权限,而admin是没有权限的,只是管理账户】,执行这个的时候需要启动hdfs,而租户其实就是之前创建的why_hadoop】
并且设置全局参数:【其中这个2022-06-09也可以设置成内置参数,就是自动取前一天的日期等等】
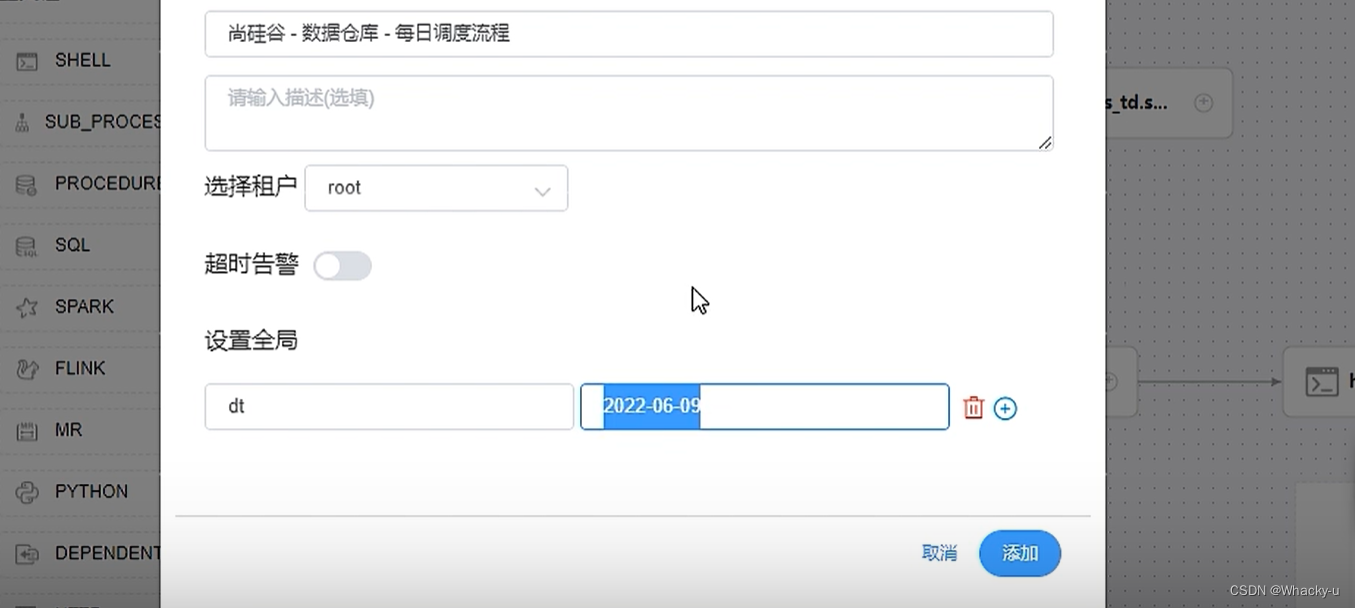
设置工作流这个的定时,上线定时,然后上线工作流,并且运行
14、可视化用的是superset
// 可以看最后一份讲义
版权归原作者 Whacky-u 所有, 如有侵权,请联系我们删除。