
并行度
一个Flink程序由多个Operator组成(source、transformation和 sink)。
一个Operator由多个并行的Task(线程)来执行, 一个Operator的并行Task(线程)数目就被称为该Operator(任务)的并行度(Parallel)
并行度可以有如下几种指定方式
1.Operator Level(算子级别)(可以使用)
一个算子、数据源和sink的并行度可以通过调用 setParallelism()方法来指定

2.Execution Environment Leel(Env级别)(可以使用)
执行环境(任务)的默认并行度可以通过调用setParallelism()方法指定。为了以并行度3来执行所有的算子、数据源和data sink, 可以通过如下的方式设置执行环境的并行度:
执行环境的并行度可以通过显式设置算子的并行度而被重写

3.Client Level(客户端级别,推荐使用)(可以使用)
并行度可以在客户端将job提交到Flink时设定。
对于CLI客户端,可以通过-p参数指定并行度
./bin/flink run -p 10 WordCount-java.jar
4.System Level(系统默认级别,尽量不使用)
在系统级可以通过设置flink-conf.yaml文件中的parallelism.default属性来指定所有执行环境的默认并行度
示例

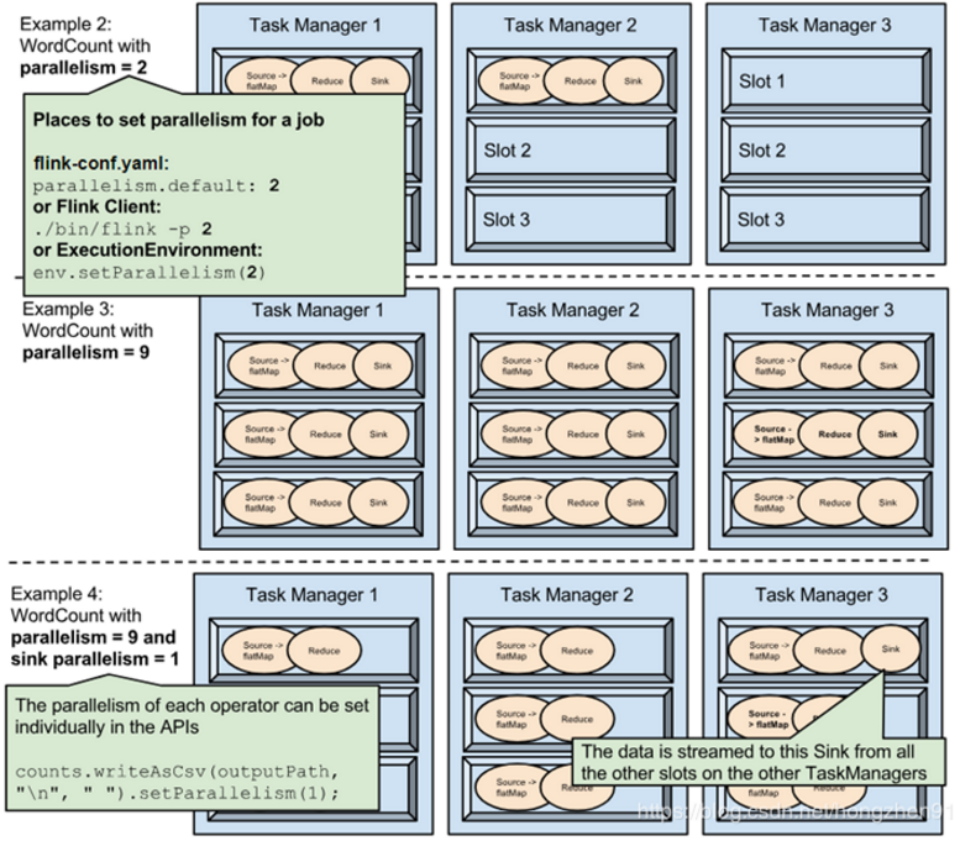
说明
Example1
在fink-conf.yaml中 taskmanager.numberOfTaskSlots 默认值为1,即每个Task Manager上只有一个Slot ,此处是3
Example1中,WordCount程序设置了并行度为1,意味着程序 Source、Reduce、Sink在一个Slot中,占用一个Slot
Example2
通过设置并行度为2后,将占用2个Slot
Example3
通过设置并行度为9,将占用9个Slot
Example4
通过设置并行度为9,并且设置sink的并行度为1,则Source、Reduce将占用9个Slot,但是Sink只占用1个Slot
注意
- 并行度的优先级:算子级别 > env级别 > Client级别 > 系统默认级别 (越靠前具体的代码并行度的优先级越高)
- 如果source不可以被并行执行,即使指定了并行度为多个,也不会生效
- 尽可能的规避算子的并行度的设置,因为并行度的改变会造成task的重新划分,带来shuffle问题,
- 推荐使用任务提交的时候动态的指定并行度
- slot是静态的概念,是指taskmanager具有的并发执行能力; parallelism是动态的概念,是指程序运行时实际使用的并发能力
本文转载自: https://blog.csdn.net/weixin_45427648/article/details/130181370
版权归原作者 程序员无羡 所有, 如有侵权,请联系我们删除。
版权归原作者 程序员无羡 所有, 如有侵权,请联系我们删除。