
目录
Spark Streaming的核心是DStream
一、DStream简介
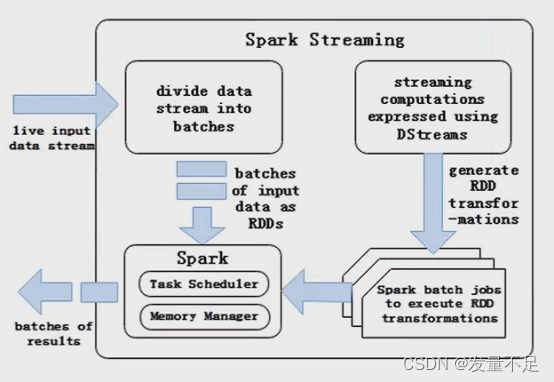
1.Spark Streaming提供了一个高级抽象的流,即DStream(离散流)。
2.DStream的内部结构是由一系列连续的RDD组成,每个RDD都是一小段由时间分隔开来的数据集。
二.DStream编程模型
三.DStream转换操作
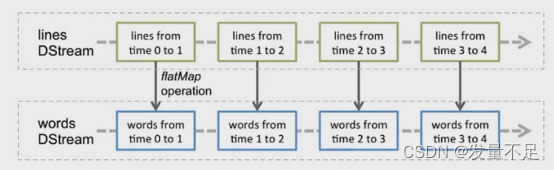
transform()
1.在3个节点启动zookeeper集群服务
$ zkServer.sh start
2.启动kafka(3个节点都要)
****$ ****/opt/module/kafka/bin/kafka-server-start.sh /opt/module/kafka/config/server.properties
3.克隆会话,jps查看是否有Kafka(3个节点)****
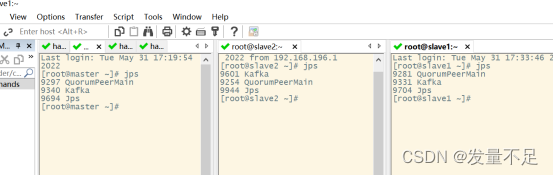
4.进入/etc/resolv.conf加入如下内****
vi resolv.conf
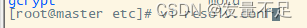
Nameserver 114.114.114.114
5.下载nc****
$**** yum install nc****

6.启动服务端且监听Socket服务,并输入I**** am learning spark streaming now
$**** nc -lk 9999****
I** am learning spark streaming **now(回车)

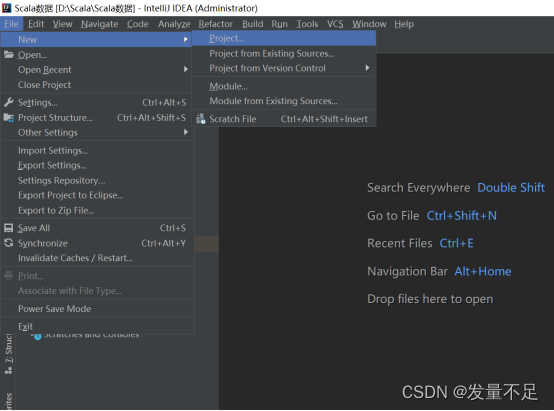
7.创建Maven项目, 打开右上角的Fileànewàproject****
8.选择mavenànext****
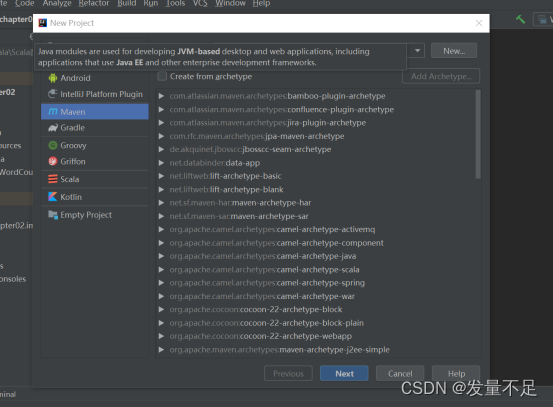
9.填写groupld、artifctldànext****
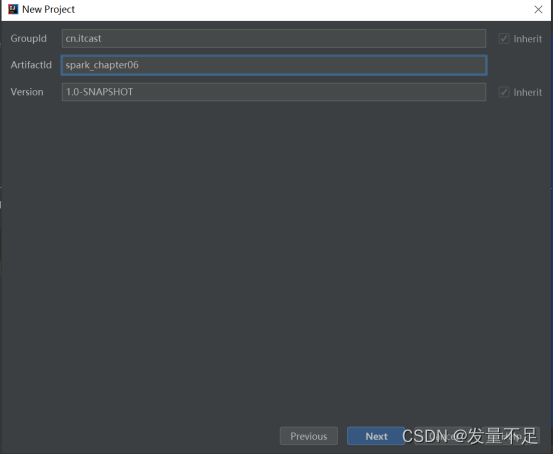
10.添加依赖****
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.8</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.0.2</version>
</dependency>
<!--引入sparkStreaming依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.0.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
<!--引入sparkstreaming整合kafka的依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>2.0.2</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
</build>
*11 在main目录下创建scala文件,右击à*newàdirectory,命名为Scala
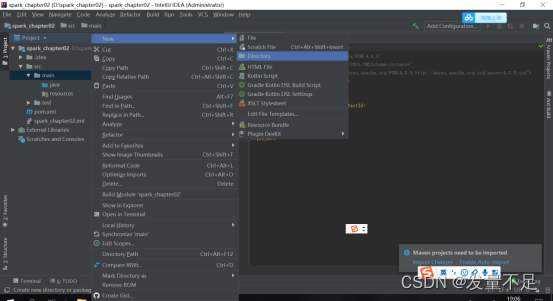
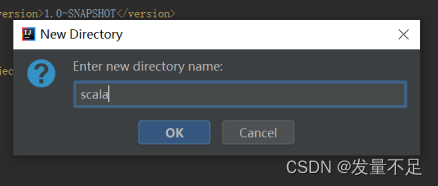
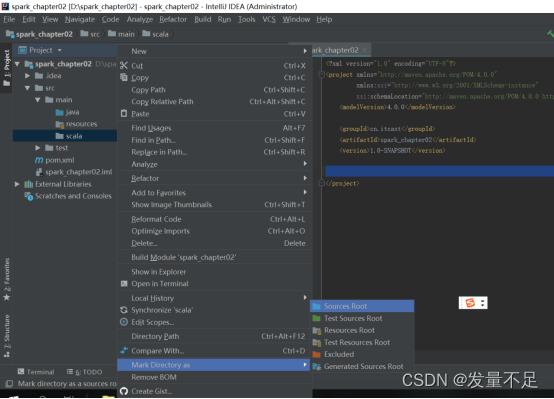
12 右击Scala文件,选择【Mark Directory**** as】à【sources root】表示将文件夹标记为资源文件夹类型(存放项目源码文件)
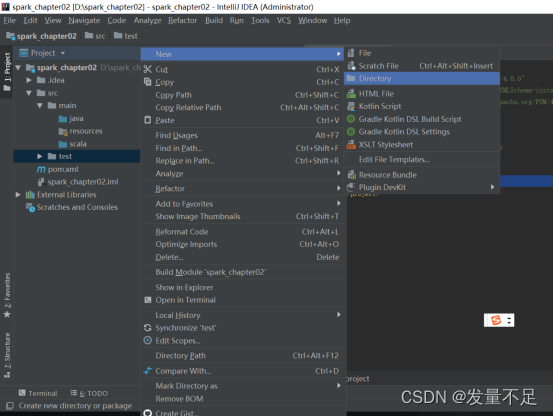
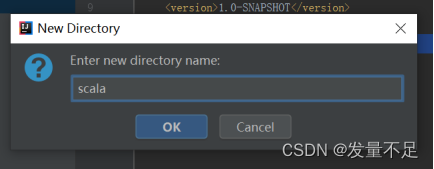
*13 同样在test目录下创建scala文件,右击à*newàdirectory******,命名为Scala ******
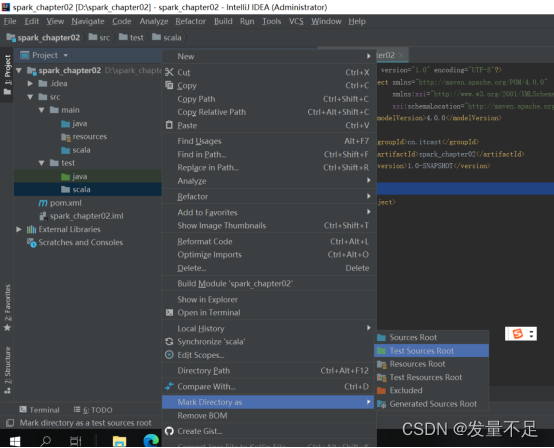
14 右击Scala文件,选择【Mark Directory**** as】à【test sources root】表示将文件夹标记为测试资源文件夹类型(存放开发中测试的源码文件)
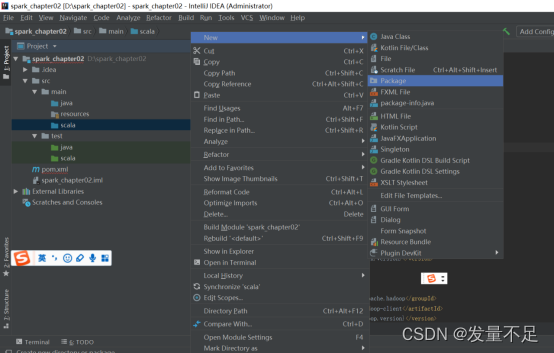
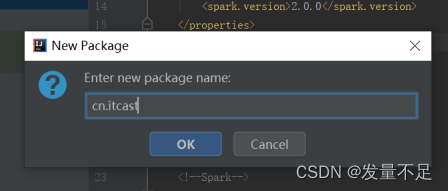
******15 右击main下的Scala文件先创建一个package并命名为cn.**itcast ****
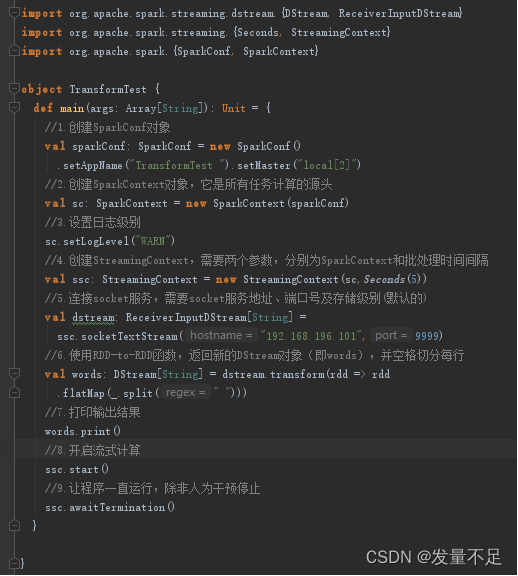
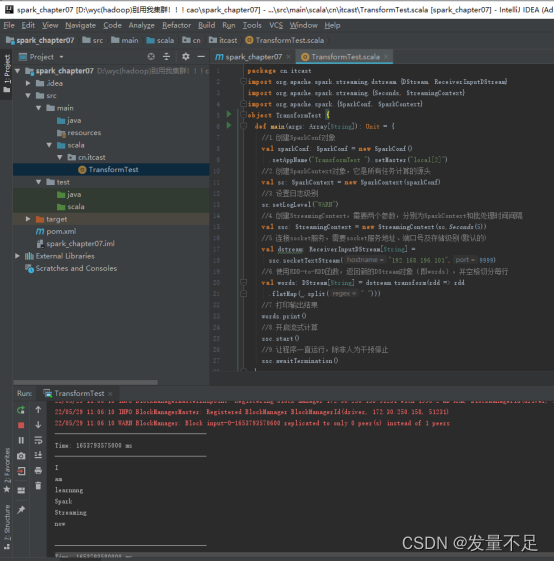
1**6 **编写TransformTest.Scala
注意红框内容!!!
1**7 **运行程序,可以看到控制台输出结果
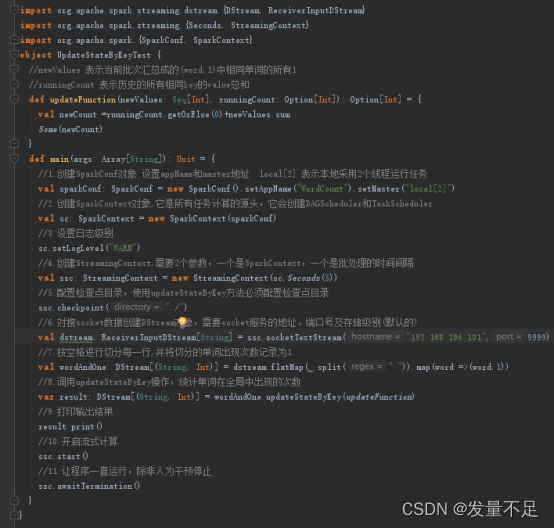
UpdateStateKey()****
1 编写UpdateStateKeyTest.scala****
注意红框内容!!!
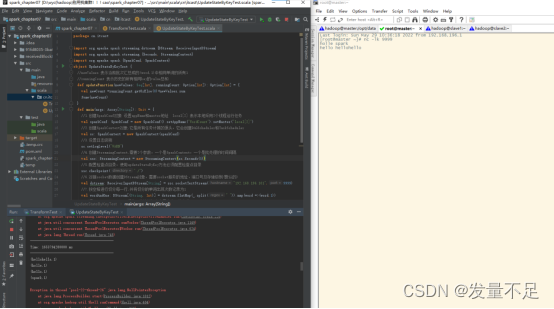
******2 ********运行程序并在master ********9999 **端口不断输入单词,观察到控制台输出内容
$ nc -lk 9999
Hadoop spark itcast(回车)
Spark itcast
版权归原作者 发量不足 所有, 如有侵权,请联系我们删除。