
研究爬虫的时候用马蜂窝网页端的数据进行实验。操作包括翻页、点击等操作。爬取到的数据放到json文件中,如果想要存入数据库或者excel文件的的,把存取部分的代码改一下即可,爬取部分的代码一样。可能有些地方不足,敬请斧正。
项目开始之前确保已经安装了scrapy库及selenium库
1.创建爬虫项目。
- cmd命令行输入: scrapy startproject 项目名。我的项目名称是scrap_mfw,所以我的命令就是scrapy startproject scrap_mfw,项目名自己定。如下图,成功创建项目。

- 命令行输入cd scrap_mfw/spiders 进入爬虫目录
- 命令行输入:scrapy genspider mfw_test www.mafengwo.cn【mfw_test为爬虫名称,编写xpath和正则表达式的地方,www.mafengwo.cn为允许的域名】
- 完成之后,就可以在pycharm打开创建的scrap_mfw项目。
** 2.文件介绍**
目录结构如下:
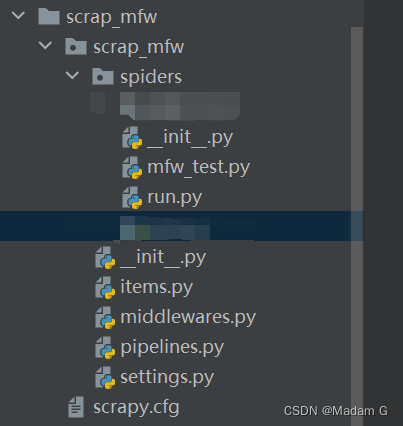
爬虫的代码在mfw_test.py里面写。run.py文件是自己建的,以后右击运行run.py就可以开始爬虫了,不用在cmd窗口敲命令行。run.py文件里面写以下代码:
cmdline.execute("scrapy crawl mfw_test".split())
mfw_test是爬虫名字。
settings.py是对爬虫的配置。用户代理请求头(USER_AGENT)伪装一下。
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36 Edg/88.0.705.68'
DOWNLOAD_DELAY = 3 # 下载延时
ROBOTSTXT_OBEY = False # 可以忽略或者不遵守robots协议
FEED_EXPORT_ENCODING = "gbk" #解决保存CSV文件乱码
# 激活自定义的下载器中间件组件
DOWNLOADER_MIDDLEWARES = {
'scrap_mfw.middlewares.ScrapMfwDownloaderMiddleware': 543,
}
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
CONCURRENT_REQUEST = 32 # 默认16个并行
LOG_LEVEL='ERROR' #只有程序出现错误的情况下,才显示日志文件
pipelines.py文件所写代码如下
class ScrapMfwPipeline:
def __init__(self):
self.f = open("bytedance.json", "w", encoding='utf-8')
def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii=False) + '\n'
self.f.write(content)
return item
def close_spider(self, spider):
self.f.close()
在mfw_test.py里面的Spider类里面写:
def start_requests(self):
# 想通过控制offset来决定是否翻页
offset = 1
url = "".join(self.start_urls)
yield Request(url=url, callback=self.parse, meta={'offset': offset}, dont_filter=True) # 在这去中间件
# 返回request的时候需要把dont_filter=True加上,不然scrapy会自动过滤掉已经请求过的网页。
def parse(self, response):
# 在这里先跳到第一个景点
self.page = 1 # 控制评论翻页
self.num = 0 # 控制跳转下一个景点
# 拿到每个景点url
web_urls = response.xpath('//*[@id="container"]/div[5]/div/div[@class="bd"]/ul/li/a/@href').extract() # print(web_urls) 是一个列表
self.urls = [] # 景点链接
# 每个景点加入
for web_url in web_urls:
web_url = "https://www.mafengwo.cn" + str(web_url).strip("'") # 拿到连接
self.urls.append(web_url)
print(self.urls)
yield scrapy.Request(self.urls[0], callback=self.parse_reviews,
meta={'offset': 1, 'url': web_url, 'page': self.page, 'list': self.urls, 'num': self.num},
dont_filter=True)
def parse_reviews(self, response):
self.page += 1 # 控制翻页
p = response.xpath('//*[@class="m-pagination"]/span[@class="count"]/span[1]/text()').extract()
p = str(p).strip('[').strip(']').strip("'")
p = int(p) + 1 # 评论页数
# 抓取评论
url = response.meta.get('url')
item = ScrapMfwItem()
# 景点名称
item['Title'] = response.xpath('//*[@class="row row-top"]/div/div[3]/h1/text()').extract()
# 景点评论
# 在这里先测试前五页 ,要修改的地方
string = ""
reviews = response.xpath('//*[@class="container"]/div[@id="commentlist"]/div/div/div[4]/div/ul/li')
for review in reviews:
string = string + str(review.xpath('.//p/text()').extract()).strip("\xa0").strip(" ").strip('\n')
item['Reviews'] = string # 拿到了拿到了
# 回调自己
if self.page < p: # 控制只5页,这样就不会抛出异常了
yield scrapy.Request(url, callback=self.parse_reviews,
meta={'offset': 2, 'url': url, 'page': self.page}, dont_filter=True)
if self.page == p and self.num < 14: # 如果已经翻够5页,跳到下一个景点
self.page = 1 # 重置页数
self.num = self.num + 1
next_step = self.urls[self.num].strip("'")
yield scrapy.Request(next_step, callback=self.parse_reviews,
meta={'offset': 1, 'url': next_step, 'page': self.page}, dont_filter=True)
yield item
middlewares.py文件在DownloaderMiddleware类下面添加:
def __init__(self):
# 实例化对象
option = ChromeOptions()
# 不加载图片
# 因为只需要爬取文本文件,所以不加载图片,这样不用等图片的响应效率更快。
prefs = {'profile.managed_default_content_settings.images': 2}
option.add_experimental_option('prefs', prefs)
option.add_experimental_option('excludeSwitches', ['enable-automation']) # 开启实验性功能
# 去除特征值
option.add_argument("--disable-blink-features=AutomationControlled")
# 以上是新添加的!加上去之后状态代码就不是521了!就不反爬虫了!
self.driver = webdriver.Chrome(options=option)
self.driver.maximize_window()
self.wait = WebDriverWait(self.driver, 10)
def process_request(self, request, spider):
# 想如果offset是1的话,就正常返回,如果是2的话,就执行点击下一页操作
offset = request.meta.get('offset', 1) # 会随着mfw_test.py变化
if offset == 1:
self.driver.get(request.url) # 在这里模拟浏览器的网址栏有响应
time.sleep(2) # 给他一点加载时间不然521
return scrapy.http.HtmlResponse(url=request.url, body=self.driver.page_source.encode('utf-8'),
encoding='utf-8', request=request,
status=200) # Called for each request that goes through the downloader
# return给调用的函数
if offset == 2:
url = request.meta.get('url')
time.sleep(3)
self.driver.find_element(By.XPATH, './/*[@class="pi pg-next"]').click()
return scrapy.http.HtmlResponse(url, body=self.driver.page_source.encode('utf-8'),
encoding='utf-8', request=request,
status=200) # Called for each request that goes through the downloader
def process_response(self, request, response, spider):
return response
但是我的爬虫只能爬出来4页的东西,虽然每一页都点到了。
本文转载自: https://blog.csdn.net/JoeySnow/article/details/130682605
版权归原作者 Madam G 所有, 如有侵权,请联系我们删除。
版权归原作者 Madam G 所有, 如有侵权,请联系我们删除。