
本博客地址:https://security.blog.csdn.net/article/details/126537766
一、前言
本篇我们会使用Python从HTTP流量中提取出图片文件,然后使用OpenCV对它们进行处理,尝试识别出带有人脸的图像,以此来锁定我们可能感兴趣的内容。至于流量数据包,可以百度搜索帅哥美女图片,有人脸的图片就会一抓一大把,再使用wireshark之类的工具来抓取等等,方式很多,就不介绍了。
对于这个需求,我们会分为两步来执行,第一步是从HTTP流量中提取图片,并将它们保存到磁盘上;第二步是分析每一张图片以判断里面是否会出现人脸,如果图片里面确实有人脸, 就用一个方框把其中的人脸圈出来,并单独保存(另存为)。
二、代码实例
代码中已有明确注释,因此不再做单独的逻辑解释。
第一段代码,提取图片,命名为:recapper.py
#!/usr/bin/python#-*- coding:utf8 -*-from scapy.allimport*import collections
import os
import re
import sys
import zlib
# 指定保存图片的目录和pcap文件的路径
OUTDIR ='/home/kali/D/pictures'
PCAPS ='/home/kali/D'# Response命名元组,数据包头header,载荷payload
Response = collections.namedtuple('Response',['header','payload'])# 获取数据包头(读取原始HTTP流量,将数据头单独切出来)defget_header(payload):try:# 从数据包开头往下找两个连续的\r\n,把这整段数据切出来
header_raw = payload[:payload.index(b'\r\n\r\n')+2]except ValueError:# 如果不存在就报异常,并输出符号“-”
sys.stdout.write('-')
sys.stdout.flush()returnNone# 如果没发生异常,就将HTTP头中的每一行以冒号分割,冒号左边是字段名,右边是字段值,然后存储在header字典中# 这里由于运行报错的原因(utf-8编码报错),使用了ISO-8859-1编码
header =dict(re.findall(r'(?P<name>.*?): (?P<value>.*?)\r\n', header_raw.decode('ISO-8859-1')))# 如果HTTP头中没有名为Content-Type的字段,就返回Noneif'Content-Type'notin header:returnNonereturn header
# 提取数据包内容,image是我们想提取的数据类型的名字defextract_content(Response, content_name ='image'):
content, content_type =None,None# 含有图片的响应包,数据头的Content-Type会有image标识if content_name in Response.header['Content-Type']:# 将数据头中指定的实际数据类型保存下来
content_type = Response.header['Content-Type'].split('/')[1]# 将HTTP头之后的全部数据保存下来
content = Response.payload[Response.payload.index(b'\r\n\r\n')+4:]# 如果数据被gzip或deflate之类的工具压缩过,就调用zlib来解压# 这里使用Content-Encoding报错,因此使用Accept-Encodingif'Accept-Encoding'in Response.header:# if Response.header['Content-Encoding'] == 'gzip':if Response.header['Accept-Encoding']=='gzip':
content = zlib.decompress(Response.payload, zlib.MAX_WBITS |32)elif Response.header['Accept-Encoding']=='deflate':
content = zlib.decompress(Response.payload)return content, content_type
# 重构在数据包中出现过的图片classRecapper:# 将要读取的pcap文件路径传给它def__init__(self,fname):
pcap = rdpcap(fname)# TCP数据流保存到字典里
self.sessions = pcap.sessions()
self.responses =list()# get_responses的作用是从pcap文件中遍历读取响应数据defget_responses(self):# 遍历整个sessions字典中的每个会话for session in self.sessions:
payload =b' '# 遍历每个会话中的每个数据包for packet in self.sessions[session]:try:# 过滤数据,只处理发往80或者从80端口接收的数据if packet[TCP].dport ==80or packet[TCP].sport ==80:# 把所有读取到的数据载荷做拼接# 相当于wireshark中右键单击一个数据包,点击“Follow TCP Stream”
payload +=bytes(packet[TCP].payload)except IndexError:# 如果报错就打印一个“x”
sys.stdout.write('x')
sys.stdout.flush()# 如果payload有数据,就将其交给get_header函数解析if payload:
header = get_header(payload)if header isNone:continue# 把构造出的response对象附加到responses列表中
self.responses.append(Response(header=header,payload=payload))# write的作用是把在响应数据中找到的图片写入到输出目录里defwrite(self,content_name):# 遍历所有responses响应for i,response inenumerate(self.responses):# 提取响应中的内容
content, content_type = extract_content(response,content_name)if content and content_type:
fname = os.path.join(OUTDIR,f'ex_{i}.{content_type}')print(f'Writing {fname}')# 将内容写到一个文件里withopen(fname,'wb')as f:
f.write(content)if __name__ =='__main__':
pfile = os.path.join(PCAPS,'test.pcap')
recapper = Recapper(pfile)
recapper.get_responses()
recapper.write('image')
第二段代码,分析图片,命名为:detector.py
#!/usr/bin/python#-*- coding:utf8 -*-import cv2
import os
ROOT ='/home/kali/D/pictures'
FACES ='/home/kali/D/faces'
TRAIN ='/home/kali/D/training'# 检查每张图片并确认里面是否有人脸,对于有人脸的图片# 在人脸周围画一个方框,然后存储为另一张新图片defdetect(srcdir=ROOT, tgtdir=FACES, train_dir=TRAIN):for fname in os.listdir(srcdir):# 图片可能是“JPG”、“PNG”、“JPEG”等,需要一类一类去验证ifnot fname.upper().endswith('.JPEG'):continue
fullname = os.path.join(srcdir, fname)
newname = os.path.join(tgtdir,fname)# 使用OpenCV的计算视觉库cv2来读取图片
img = cv2.imread(fullname)if img isNone:continue
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)# 加载人脸检测器的xml文件配置# 下载地址:http://eclecti.cc/files/2008/03/haarcascade_frontalface_alt.xml
training = os.path.join(train_dir,'haarcascade_frontalface_alt.xml')# 创建cv2的面部检测对象
cascade = cv2.CascadeClassifier(training)
rects = cascade.detectMultiScale(gray,1.3,5)try:# 如果包含人脸,就返回一个长方形的坐标,对应图片的人脸区域if rects.any():print(f'Got a face {fname}')# 人脸区域坐标
rects[:,2:]+= rects[:,:2]except AttributeError:continuefor x1, y1, x2, y2 in rects:# 在人脸周围画一圈绿色方框
cv2.rectangle(img,(x1, y1),(x2, y2),(127,256,0),2)# 将画了方框的新图片存储到指定目录中
cv2.imwrite(newname, img)if __name__ =='__main__':
detect()
三、运行测试
首先安装OpenCV(人脸识别算法所需的文件):
apt-get install libopencv-dev python3-opencv python3-numpy python3-scipy
其次下载人脸识别算法的训练文件:
wget http://eclecti.cc/files/2008/03/haarcascade_frontalface_alt.xml
运行代码前,我们需要仔细阅读代码,
尤其注意那几个文件路径
,将对应的文件放到对应的文件夹中,或者自行修改代码中的文件路径。
运行代码:
python recapper.py
可见已经将数据流量包的图片提取到pictures文件夹中了。
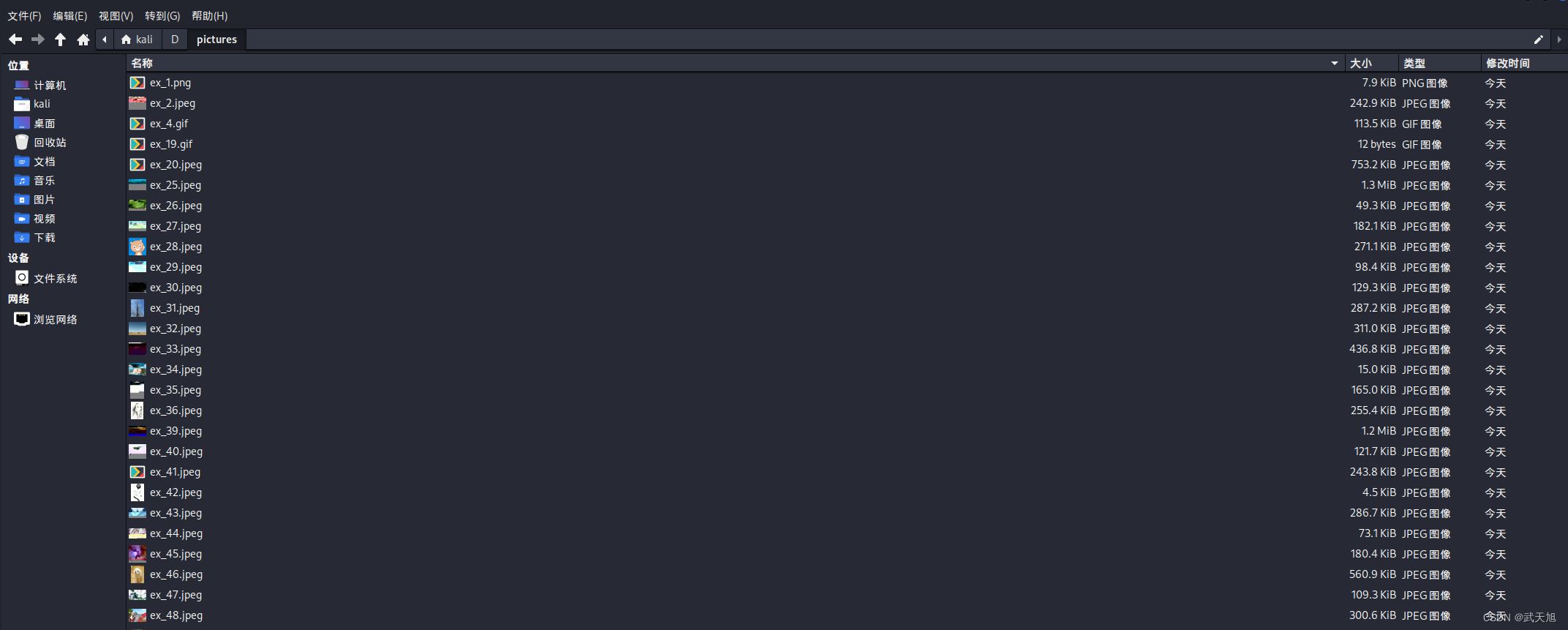
之后运行代码:
python detector.py
可见已经将人脸图片单独存储在faces文件夹中了。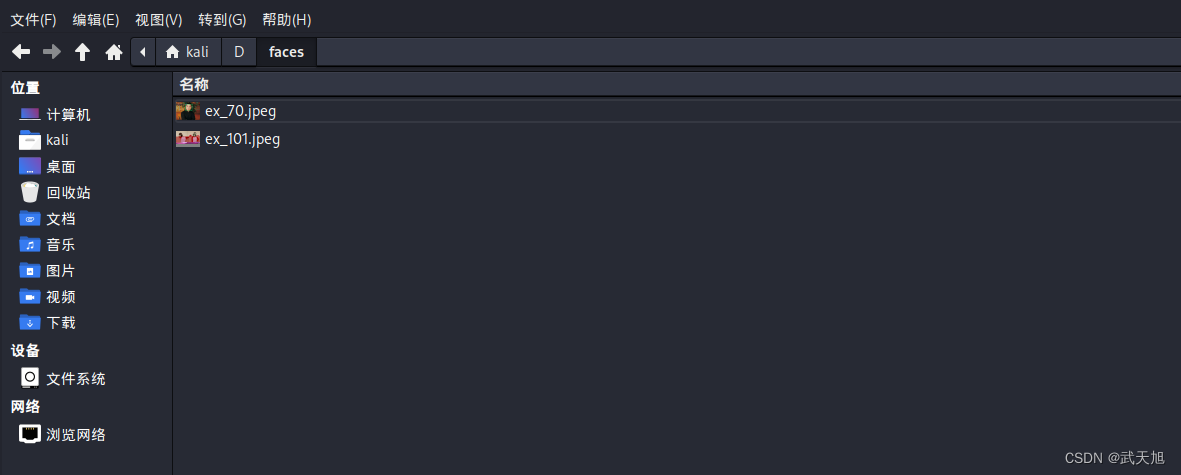
打开其中一个,可见已经额为人脸画了圈。
本文转载自: https://blog.csdn.net/wutianxu123/article/details/126537766
版权归原作者 武天旭 所有, 如有侵权,请联系我们删除。
版权归原作者 武天旭 所有, 如有侵权,请联系我们删除。