
随着汽车智能化进程,人们的关注点已渐渐的从汽车的机械素质,转化为人与车之间更安全、高效、舒适的交互方式。
2021 年 WHO 发布的「世界预防交通伤害报告」 (World report on road traffic injury)显示,每年约有 130 万人因道路交通事故而丧生,而人为因素是事故的常见原因。
DMS(Drive Monitoring System)能够帮助判断驾驶员的开车状态,包括疲劳检测 、分心检测 、 危险动作检测、离岗检测、 摄像头遮挡检测等,可以有效避免 50% 以上由人为因素造成的交通事故,保护用户的人身和财产安全。OMS(Occupancy Monitoring System)乘客检测系统作为 DMS 的延伸,通过座舱内乘客的感知数据进一步优化汽车的安全性能。
此外,DMS 已成为了国内外法规的强制性要求:欧盟在 2019 年就已经将 DMS 中的疲劳检测、分心检测纳入了法规强制要求;欧洲新车评价标准机构 E-NCAP 也将车辆是否搭载 DMS 作为一个辅助驾驶模块下的评分项。同时,国内主流新车评价机构 C-NCAP、i-Vista 和中保研都计划在 2024 年将 DMS 加入到评测项目中。
早在 2019 年,绝影首发驾驶员分心检测和手势交互功能,并率先在行业主流品牌车型上实现量产。本文将向大家介绍,绝影 DMS 及 OMS 解决方案中的重要技术能力——视线检测及手势交互技术。
视线检测:
视线检测作为驾驶员分心检测的核心技术之一,其能够在用户无感的情况下进行,通过精确的眼球运动、注视点的检测,确定驾驶员眼神聚焦情况。
当前行业内主要存在以下视线检测方案:
- 眼动仪:眼动仪是一种常见的用于测量和记录眼球运动的设备,能够通过追踪瞳孔运动来确定人眼注视点。
- 计算机视觉技术:通过计算机视觉技术对图像信息进行处理,能够检测人眼位置和注视方向。这种方法通常使用摄像头捕捉人眼的图像,然后通过图像处理算法分析眼球的位置和运动。
- 深度学习和神经网络:通过使用卷积神经网络(CNN)等深度学习模型,从图像、视频中学习和提取图像特征(feature map),以实现对眼球位置和注视点的准确检测。
由于车舱环境的复杂和多样性,基于眼动仪的检测方案对硬件设备的要求高,不利于控制成本。基于图像处理算法的方案依赖人工设计的规则,在极端场景下鲁棒性差。
因此,我们主要采用基于深度学习的方案来实现视线检测。相比于其他两种方案,这一方案无需额外的硬件投入,且能够从数据中自动挖掘更精准的规则,从而提高对极端场景的适应能力。
深度学习视线检测算法难点
采用深度学习方案主要面临以下难点:
- 小样本数据:视线检测的性能受到光照、背景噪音和其他环境条件的影响。在一些特定的场景中,可用于训练的数据可能非常有限,这可能导致模型的性能下降。例如小眼睛、特定遮挡、特定角度阴阳脸、过暗过曝等。除此之外,驾驶员还可能作出各种各样前期采集中未出现场景影响模型性能。
- 眼部特征易受干扰****:眼镜属于人脸的细粒度特征,易受到噪声干扰。在人头大角度、墨镜、眼镜反光等噪声场景下,无法做到准确定位。
- 相机自由移动:为实现车舱环境下的交互,研发过程通常需要将相机坐标系下的三维视线向量转换到车辆坐标系。部分 DMS 相机安装在管柱或者内后视镜位置,相机坐标系会随着管柱或内后视镜运动同步变化,提高坐标系转换难度。
绝影视线检测解决方案
1. 数据构建:「三合一」丰富数据分布****,应对极端、长尾场景
目前市场上主要通过相机阵列采集手段提高数据分布多样性,利用数据增强弥补部分小样本数据,在一定程度上减少数据标注难度、提高小样本数据量。但此类方案依旧难以获得大批量的数据集,同时,由于相机阵列仅能在实验室环境下进行部署,无法获得真实场景下的小样本数据,在长尾检测场景中的识别效果十分有限。
绝影采用创新「三合一」数据构建方案,包含:仿真渲染、实验室数据采集、实车数据采集。

光学实验室
基于人脸的三维建模和渲染技术,绝影建模 500 个虚拟人脸,构建稠密视线分布数据。通过算法减少渲染数据和实车数据之间的** DomainGap,快速的获得不同肤色、年龄、人种的数据,一天内就能针对特定维度生产 10万张以上的训练样本,**极大加速视线研发的迭代和优化。
量产合作车型数据积累
此外,为了获得真实场景数据,保证模型在车舱各相机位置下的泛化性,绝影团队搭建光学实验室,用于模拟各种光照强度以及光照方向下的视线数据。同时,还构建了实车数据采集方案用以提高实车效果,并积累实车过程中出现的 Bad Case,例如:女性驾驶员头发丝被风吹拂遮挡眼镜、驾驶员驾驶过程中喝水遮挡眼睛等现实生活中的常见场景。
通过不断总结新的场景维度、采集补充数据维度,积累极端场景数据质量与数量,最终,绝影智能车舱团队可减少甚至解决极端场景对实车效果的影响。
2. 眼部特征识别:时序网络提升识别准确性
视线检测属于眼部区域的细粒度特征识别,其成像效果会受到光照、眼镜、眼部状态、画质等多种因素影响,面对图像模糊、严重遮挡、过曝过暗等多种检测难点场景。
市面上常见的眼部特征识别算法普遍采用端到端的模型结构设计,在车舱环境光照变化剧烈,成像画质较低或难以得到理想的眼部图像时往往预测效果较差。
为了进一步提高视线检测精度,绝影创造性结合****时序网络让模型充分参考历史特征,帮助客户在极端场景下获得优秀的视线效果。
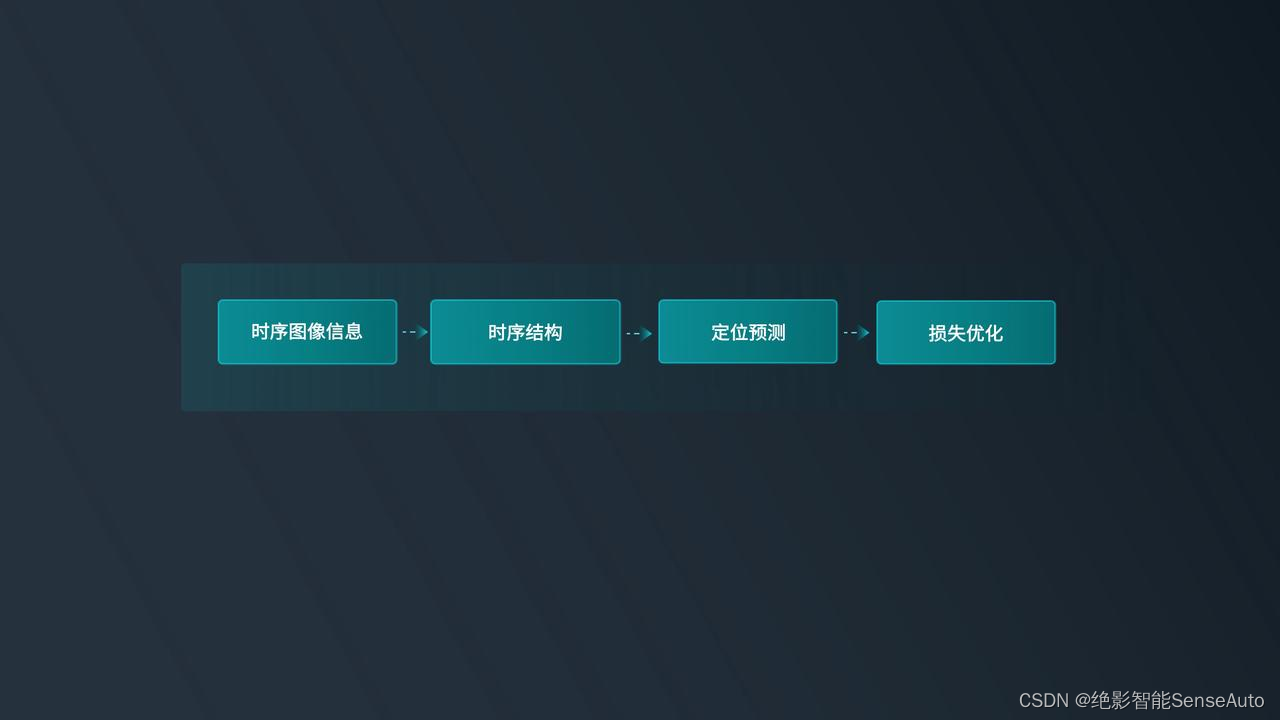
基于此方案,我们视线定位效果的准确性、鲁棒性相较普通检测方案都有极大的提升,在镜片光斑和眼部模糊场景下均具有优秀的感知能力。
3. 相机坐标系标定****:多模态信号融合方案
由于算法输出视线为当前相机坐标系下的空间视线向量,当相机安装在管柱或者内后视镜等位置时,相机会随管柱或内后视镜一起发生移动,需实时对相机变化进行标定,计算相机到车辆坐标系的变化矩阵。
目前常见的管柱自标定方案主要是通过检测相机移动前后的成像来推导出相机6DOF变换,该方案非常依赖相机成像效果以及车舱环境纹理特征数量,在相机画质较差,光照变换强烈场景下无法进行准确的定位。
考虑到市面上常见方案的局限性,我们创造性将车舱内的多模态信号进行融合,通过算法对多模态信号进行自适应滤波和权重分配,在优化自标定精度同时极大提升了算法针对极端场景的鲁棒性。
4.多模态交互:驾驶员分心检测
通过监测驾驶员的眼睛运动和注视点,能够判断驾驶员的注意力集中在何处,从而识别是否存在分心的情况。我们的产品在小眼睛、墨镜、阴阳脸、头发丝遮挡以及驾驶过程中可能出现的极端场景都有非常优秀的鲁棒性,已经落地的项目中几乎没有用户反馈因为误报带来的不良体验,为乘用车智能车舱建设提供坚实的技术支持,真正保证用户的驾驶安全。
提高驾驶安全性:分心功能检测系统能够监测驾驶员的行为,及时发现分心情况并采取措施,从而提高驾驶安全性,减少交通事故的发生可能性
改善驾驶体验:用户能够更加安心和放心地驾驶,知道车辆配备了分心功能检测,有助于改善驾驶体验。这对于长途驾驶或疲劳驾驶时尤为重要。
降低交通事故风险:用户通过使用配备分心功能检测的车辆,可以降低因为自身分心或疲劳导致交通事故的风险,保障自身和他人的安全。
手势交互
手势识别功能的快速向前发展,从最初控制车内信息娱乐系统,包括接挂电话、调整音量、控制导航系统等功能,发展到控制车身硬件以及安全系统,如车窗、天窗、遮阳帘的开启关闭及车门关闭等功能。
技术难点
手势算法主要分为 3 个模块:手追踪、静态手势、动态手势,其算法涉及检测、预测、匹配、骨骼点、分类、动作识别等多个领域,同时也存在着以下的识别难点:
I.)手跟踪困难:手是车舱场景运动最快的物体,动态手势中的一次动作持续时间甚至小于 0.3 秒,且有时移动幅度较大,移动方向存在瞬时变化的可能,如:从手抬起到向左挥手、运动方向由垂直转为水平等。在芯片平台算力有限的情况下,需要严格控制检测帧率;
II.)静态手势识别:由于手的姿态变化多样,静态手势除了在 yaw、roll、pitch 三种角度上发生变化,手本身的姿态也会变化多端,如有握拳、比 V 等手势。手势场景繁多且时常存在严重的自遮挡;
III.)动态手势识别:在动态手势中,有很多细节需要准确识别、区分。如在手指旋转中,需要区分食指与中指的旋转、手伸直旋转与手完全旋转等手指不同弯曲程度的差异;又如,在挥手手势中,需要区分五指挥手与四指挥手等相似手势的差异等。同时,由于手运动较快,往往伴随较为严重的运动模糊,对动作识别算法方案的设计有着十分苛刻的要求。
绝影算法解决方案
百万级数据库构建
目前,绝影积累的大量手势相关数据,手检测数据超过 500 万,静态手势分类数据 400 万以上,动态手势样本数 40 万以上,支持 CPU、DSP、Cadence 等多种计算平台,整体推理速度不超过 15 ms。百万级的数据库构建,也让其在各种场景下均有稳定表现,更好的应对行驶过程中的 corner case。
手势识别算法
手跟踪:光流预测提高关键点检测效率
进行车舱内乘员手势识别时,往往由于手运动速度较快或过曝等画质问题导致手跟踪丢失,进而直接影响下游静态手势和动态手势召回。
目前最直接的解决方法是逐帧检测手,最大程度减少漏检,但会带来极大的资源占用,且实时性难以保证。
针对此,我们的解决方案是:通过光流或滤波方法****进行检测,结合历史帧手的位置、运动趋势,预测出当前帧手的位置。为避免光线变化、其他手干扰、肤色相近部位等对手位置预测的影响,我们还通过辅助方案对手位置进行矫正,最终使得手追踪效果稳定。
静态手势识别:****多任务神经网络算法
在静态手势的识别上,我们采用多任务处理方案:输入手关键点序列信息,进行手追踪和动态手势识别,同时也能够承担静态手势的识别。而根据各任务分支的特点和遇到的高频问题,我们通过手形态监督训练、对比学习****、数据增强等方式进行了针对性的训练优化。
与基于规则的动态手势算法不同,基于深度学习的算法具有较好的泛化性,易扩展、易维护。
我们首先根据业务需求采集了大量的动作样本、进行标注,以此搭建关键点序列训练集。
动态手势识别:融合时序信息的深度学习算法方案
针对动态手势识别,我们将基于规则的算法方案升级为基于深度学习的算法方案。在模型训练过程中,我们也考虑了不同动作之间的特征差异(如平均持续时长等)带来的影响,并根据差异引导模型提取最有效的特征(如部分动作更关注食指和拇指关键点变化),从而提升模型识别能力:
I.)通过加入关键点时序信息,深度学习识别算法能够提升整体预测精度和算法鲁棒性,且在项目研发过程中基于深度学习的算法方案更易于扩展和维护。
II.)基于规则的动态手势算法只能覆盖十分「标准」的手势动作,泛化性较差;基于深度学习的动态手势算法,在大量数据集上学习之后,泛化性较好,可以覆盖大多用户实际使用场景。
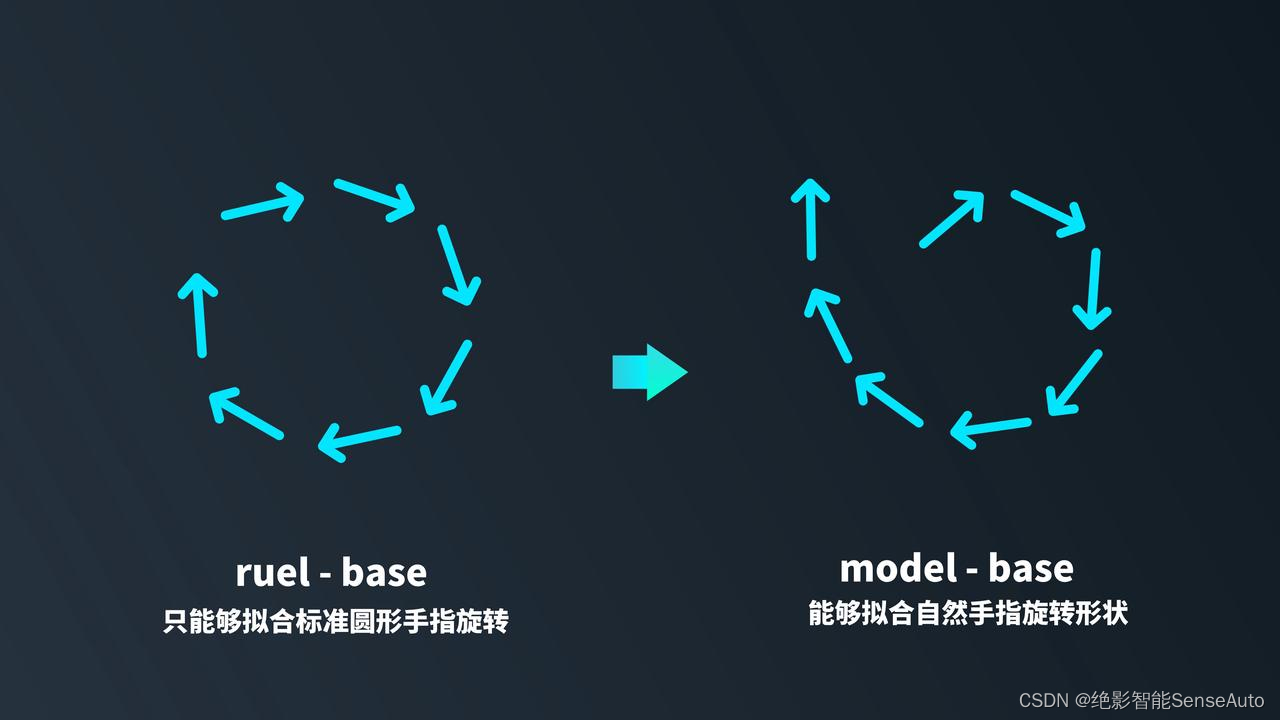
3.绝影智能车舱手势交互功能应用
目前应用的功能&识别效果:
我们在小目标检测、运动模糊下的关键点检测、较快运动下的手跟踪、关键点抖动性、较大角度下的手势识别等问题上均取得了较大进展,使得手势整体效果满足用户需求: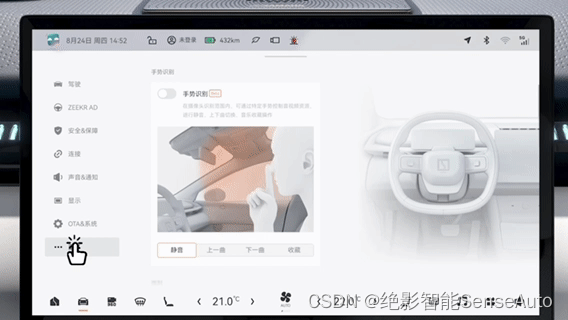
为了提升用户的交互体验,降低学习难度和记忆难度,未来,我们会朝着更自然、更符合人体工程学的方向不断优化算法能力。手势交互感知模块,将通过 2D 升级 3D 手势交互,提供微动作识别能力,如 Tap(模拟单击动作)等,不断提升用户操作的便捷性和操作精度。

随着智能化的逐步发展,智能座舱逐渐从「单点功能」向「多模态」迈入。未来,绝影将持续以敏锐的智舱感知能力为基础,以「车舱大脑」为核心,不断探索,让智能座舱成为暖心懂你的可靠管家,为人们提供更好的驾乘体验。
版权归原作者 绝影智能SenseAuto 所有, 如有侵权,请联系我们删除。