
安装jdk
安装hadoop
2 查看Linux是否安装java jdk
如果查询有其他java版本,则需要卸载
rpm -e --nodeps 查询的包名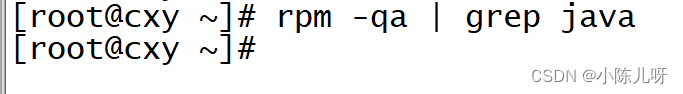
3.cd至上传目录
tar 指令解压:tar -zxvf jdk-8u361-linux-x64.tar.gz


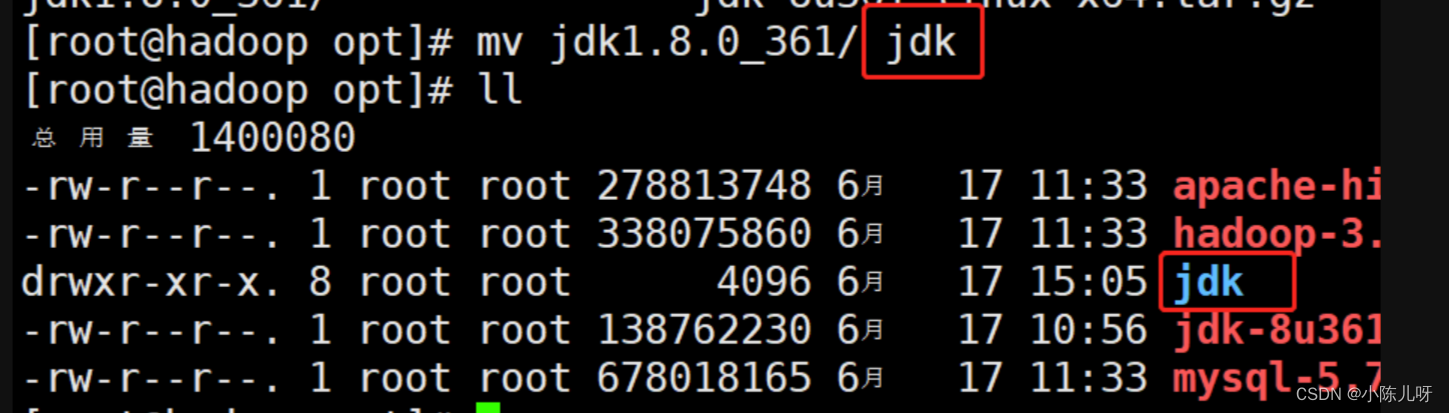
重命名为jdk(方便配置环境变量)
mv jdk1.8.0_361/ jdk
5.配置环境变量
vim /etc/profile
在这个文件最后换行添加如下三行:
JDK
export JAVA_HOME=/opt/jdk
export PATH=$JAVA_HOME/bin:$PATH

6 使这个配置文件生效
source /etc/profile
7 验证(查看java版本)
java -version

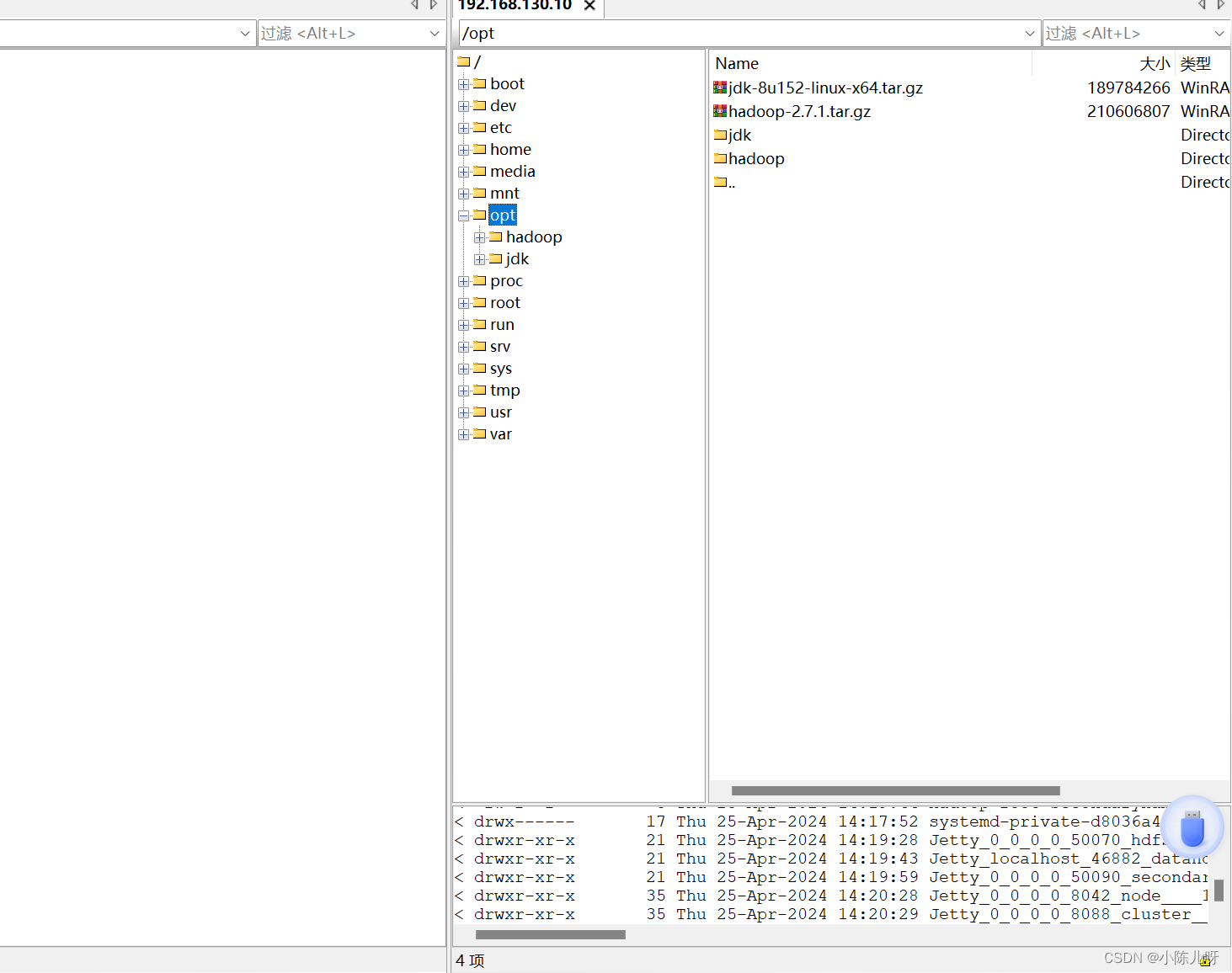
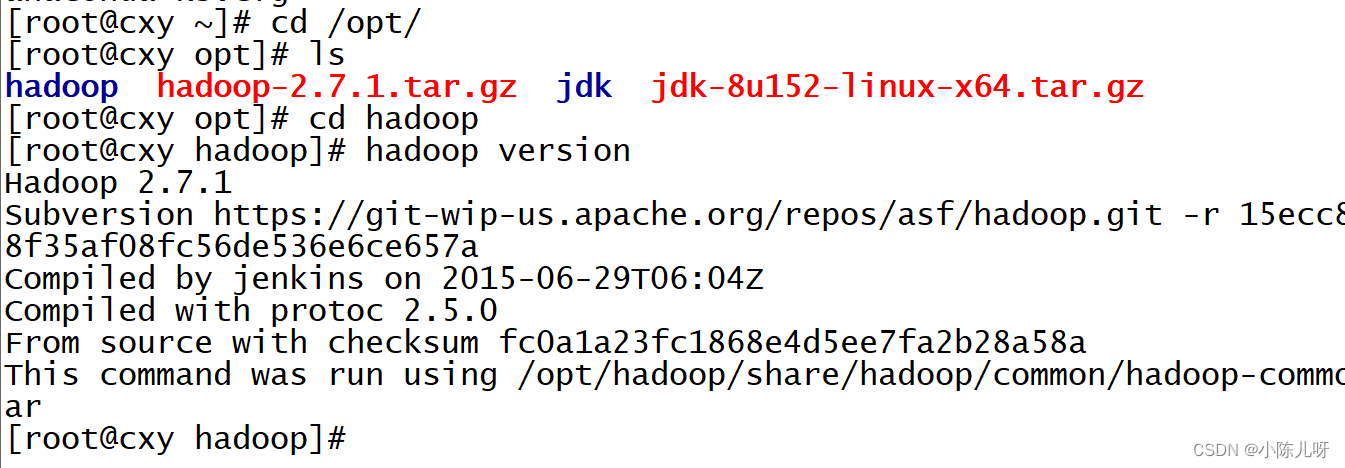
cd 至上传opt目录
解压安装包到/opt目录
tar -zxvf hadoop-3.1.3.tar.gz
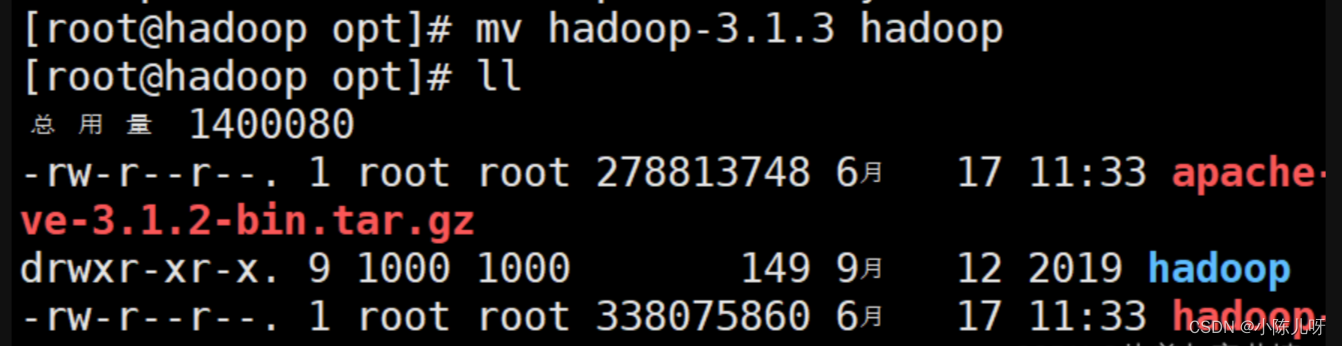
4.配置环境变量
vim /etc/profile
在这个文件最后换行添加如下三行:
#HADOOP
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
6 使这个配置文件生效
source /etc/profile
7 验证(查看hadoop版本)
hadoop version
Hadoop集群伪分布模式
一、配置免密登录
进行免密登录需要安装ssh
安装ssh服务:
1.查看是否安装ssh
rpm -qa | grep ssh
如果有openssh-clients、openssh-server,则不需要安装
如果没有,则需要安装,安装命令如下:
yum install -y openssh-clients openssh-server
2.启动ssh服务
service sshd start|stop|restart|status
配置免密登录
作用举例:启动yarn服务需要输入系统密码(节省时间)
1.本机生成公钥、私钥和验证文件
ssh-keygen -t rsa
回车三次即可
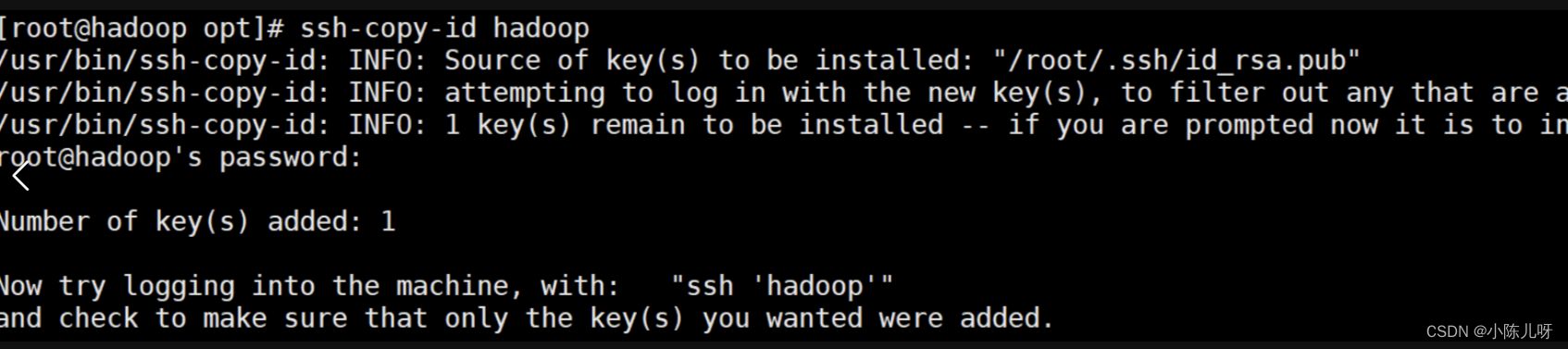
2.将登录信息复制到验证文件
ssh-copy-id hadoop 根据自己主机名写
hadoop为主机名
注意:输入该指令后需要自行输入登录密码
输入时系统输入栏密码不显示(正常输入回车即可)
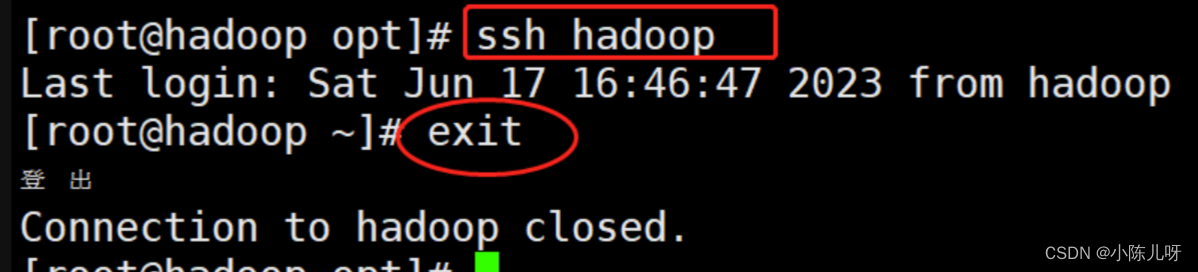
可以尝试ssh登录命令查看是否配置成功:
ssh hadoop
二、HDFS的配置
1.进入Hadoop配置目录:
cd /opt/hadoop/etc/hadoop/
(1)配置hadoop-env.sh
vim hadoop-env.sh
在这个配置文件最后换行添加
export JAVA_HOME=/opt/jdk
(2)配置core-site.xml
vi core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop/tmp/</value> </property> </configuration>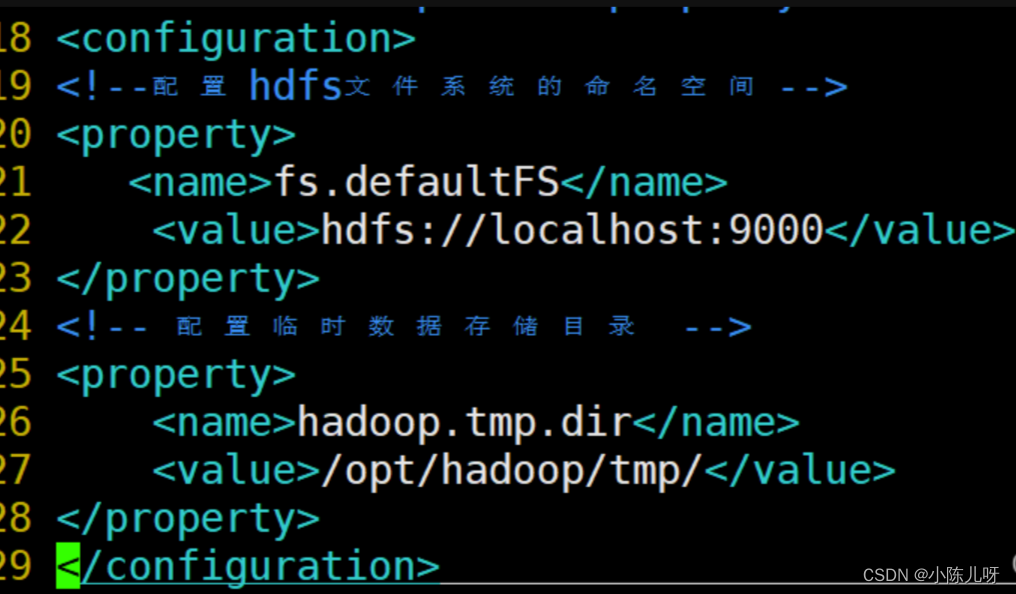
(3)配置hdfs-site.xml
vi etc/hadoop/hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.http.address</name> <value>hadoop:50070</value> </property> </configuration>(4)格式化HDFS
格式化命令:
hdfs namenode -format

格式化成功!
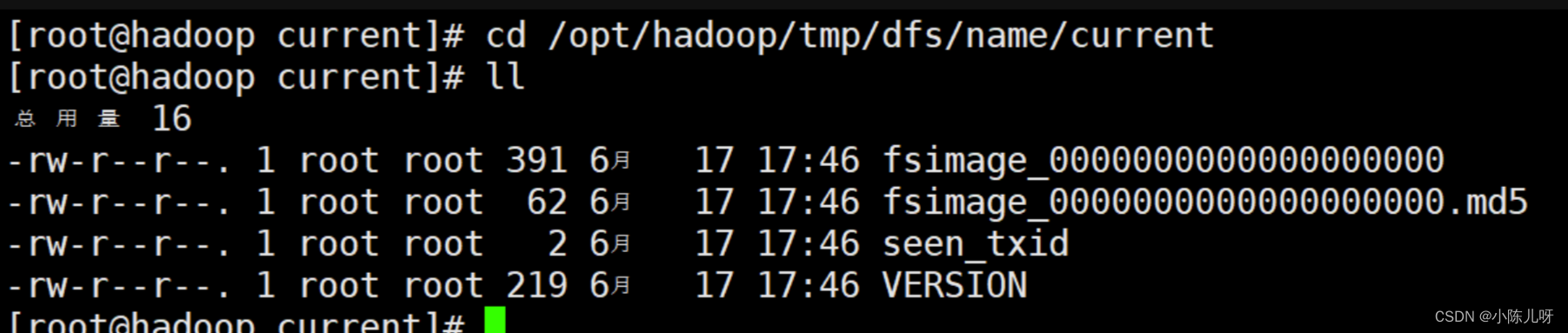
格式化成功后,会在hadoop.tmp.dir配置的/opt/hadoop/tmp目录生成目录dfs/name/current/,里面包含几个文件如下:
cd /opt/hadoop/tmp/dfs/name/current
二、YARN的配置
1.进入Hadoop配置目录:cd /opt/hadoop/etc/hadoop/
(1)配置yarn-site.xml
vim yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.hostsname</name> <value>hadoop</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
(2)配置mapred-site.xml
vim mapred-site.xml
<configuration> <property><name>mapreduce.framework.name</name>
<value>yarn</value>
</property> </configuration>
三、启动服务用户定义
vim /etc/profile
HADOOP_USER
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root

启动hdfs或yarn服务
start-dfs.sh
启动yarn服务
start-yarn.sh
同时启动或停止所有服务
启动命令:
start-all.sh
查看结果:
jps
如果没有缺少节点则配置成功
缺少节点则查验节点的配置文件
停止命令:
stop-all.sh
版权归原作者 小陈儿呀 所有, 如有侵权,请联系我们删除。