
笔记整理自 黑马程序员全面深入学习Java并发编程,从《Java并发编程的艺术》作为补充
文章目录
🔍为什么要使用ConcurrentHashMap
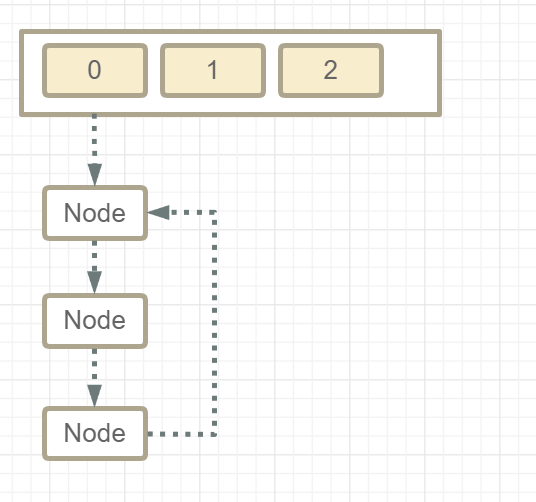
- ⚠️线程不安全的HashMapHashMap在并发执行put操作时会引起死循环,是因为多线程会导致HashMap的Entry链表 形成环形数据结构,一旦形成环形数据结构,Entry的next节点永远不为空,就会产生死循环获 取Entry。> hashmap形成死链⛓️⛓️的主要原因是在扩容是将元素加入链表头导致的,而在JDK 8 虽然将扩容算法做了调整,不再将元素加入链表头(而是保持与扩容前一样的顺序),但仍不意味着能 够在多线程环境下能够安全扩容,还会出现其它问题(如扩容丢数据)
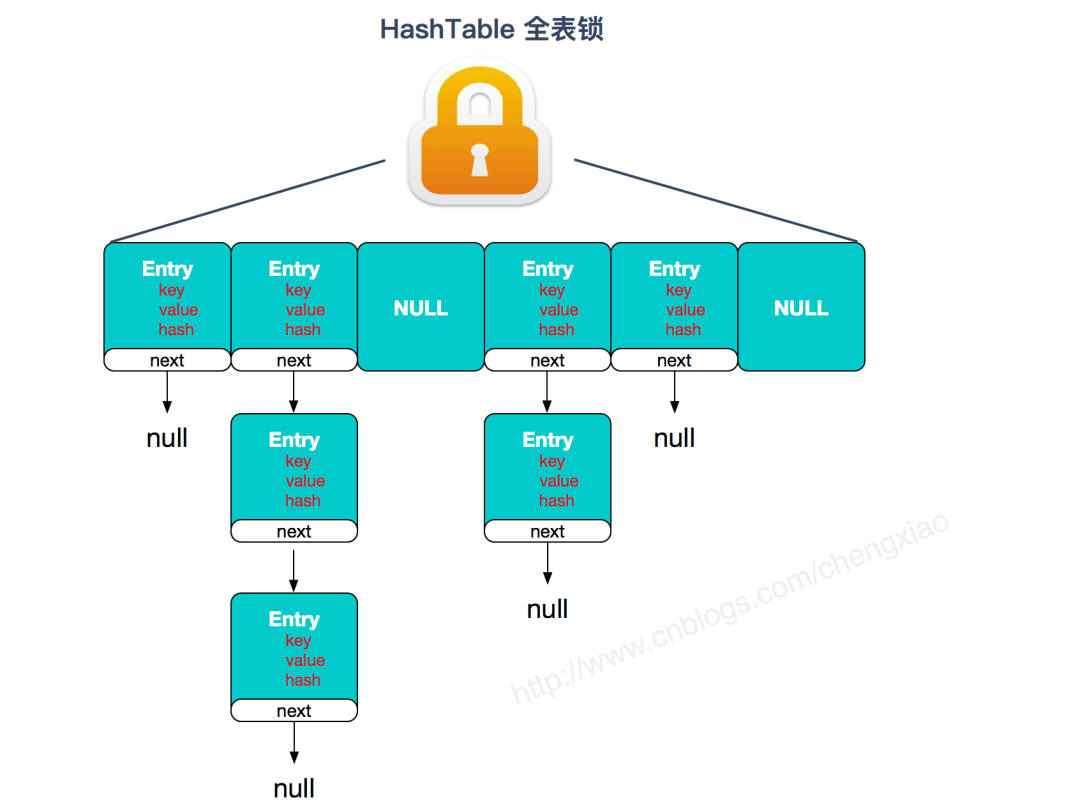
- 🦥效率低下的HashTableHashTable容器使用synchronized来保证线程安全,但在线程竞争激烈的情况下HashTable 的效率非常低下。因为当一个线程访问HashTable的同步方法,其他线程也访问HashTable的同 步方法时,会进入阻塞或轮询状态。
- ⏩ConcurrentHashMap的锁分段技术可有效提升并发访问率HashTable容器在竞争激烈的并发环境下表现出效率低下的原因是所有访问HashTable的 线程都必须竞争同一把锁假如容器里有多把锁🔐🔐🔐,每一把锁用于锁容器其中一部分数据,那么 当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效提高并 发访问效率,这就是ConcurrentHashMap所使用的锁分段技术。首先将数据分成一段一段地存 储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数 据也能被其他线程访问。> JDK1.7 的 ConcurrentHashMap:
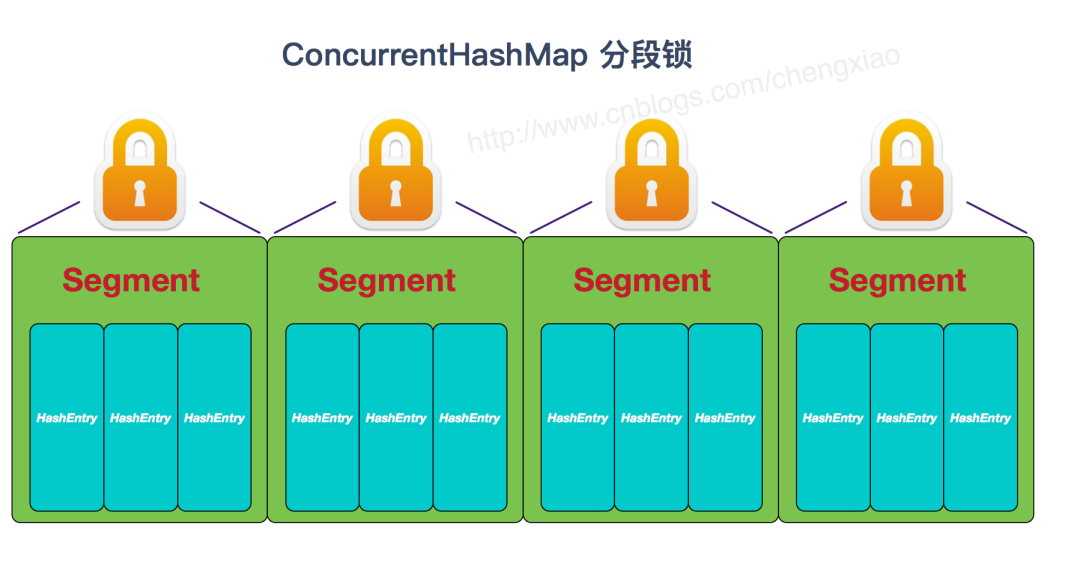
ConcurrentHashMap 结合了 HashMap 和 HashTable 二者的优势💪。HashMap 没有考虑同步,HashTable 考虑了同步的问题。但是 HashTable 在每次同步执行时都要锁住整个结构。ConcurrentHashMap 锁的方式是稍微细粒度的。
🎬原理解析
- JDK1.7首先将数据分为一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。在 JDK1.7 中,ConcurrentHashMap 采用 Segment + HashEntry 的数据结构,结构如下:一个 ConcurrentHashMap 里包含一个 Segment 数组。Segment 的结构和 HashMap 类似,是一种数组和链表结构,segment 继承了 ReentrantLock,一个 Segment 包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素。当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment 的锁。
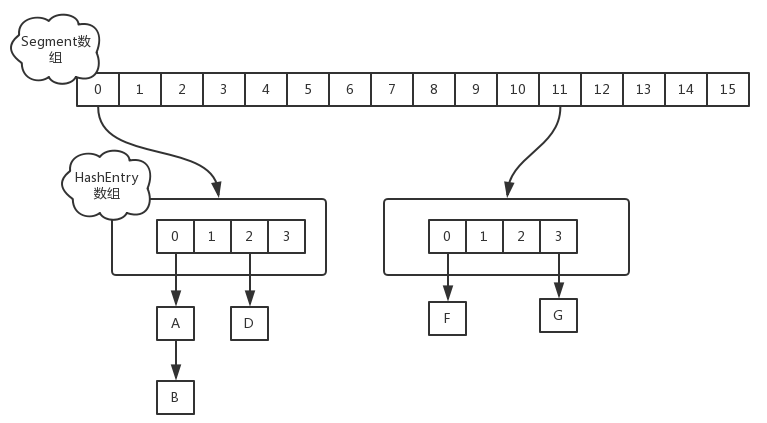
- 该类包含两个静态内部类 HashEntry 和 Segment ;前者用来封装映射表的键值对,后者用来充当锁的角色;
- Segment 是一种可重入的锁 ReentrantLock,每个 Segment 守护一个 HashEntry 数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment 锁。
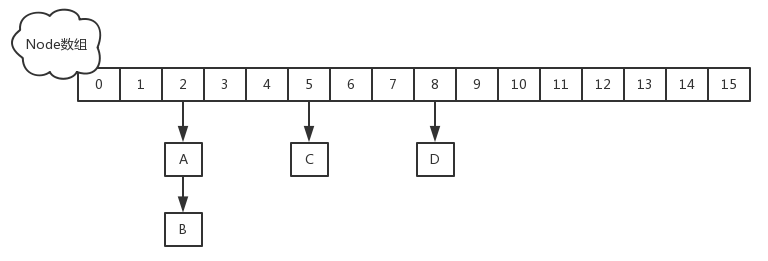
- JDK1.8💡在JDK1.8 中,放弃了 Segment 臃肿的设计,取而代之的是采用 Node + CAS + Synchronized 来保证并发安全,synchronized 只锁定当前链表或红黑二叉树的首节点,这样只要 hash 不冲突,就不会产生并发,效率又提升 N 倍。结构如下:
🖥️JDK7中源码分析
以下源码分析为Jdk7的ConcurrentHashMap
它维护了一个 segment 数组,每个 segment 对应一把锁
- 优点:如果多个线程访问不同的 segment,实际是没有冲突的,这与 jdk8 中是类似的
- 缺点:Segments 数组默认大小为16,这个容量初始化指定后就不能改变了,并且不是懒惰初始化
⚙️构造器分析
publicConcurrentHashMap(int initialCapacity,float loadFactor,int concurrencyLevel){if(!(loadFactor >0)|| initialCapacity <0|| concurrencyLevel <=0)thrownewIllegalArgumentException();//============= 分析 ===============> //segments数组的长度ssize是通过concurrencyLevel计算得出的。if(concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;// ssize 必须是 2^n, 即 2, 4, 8, 16 ... 表示了 segments 数组的大小int sshift =0;int ssize =1;while(ssize < concurrencyLevel){++sshift;
ssize <<=1;}//================================> //1、segmentShift用于定位参与散列运算的位数// segmentShift 默认是 32 - 4 = 28this.segmentShift =32- sshift;//2、segmentMask是散列运算的掩码// segmentMask 默认是 15 即 0000 0000 0000 1111this.segmentMask = ssize -1;//通过initialCapacity和loadFactor来初始话容量if(initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;int c = initialCapacity / ssize;if(c * ssize < initialCapacity)++c;//cap就是segment里HashEntry数组的长度int cap = MIN_SEGMENT_TABLE_CAPACITY;while(cap < c)
cap <<=1;// 创建 segments and segments[0]Segment<K,V> s0 =newSegment<K,V>(loadFactor,(int)(cap * loadFactor),(HashEntry<K,V>[])newHashEntry[cap]);Segment<K,V>[] ss =(Segment<K,V>[])newSegment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0);// ordered write of segments[0]this.segments = ss;}
👨🏫分析1:
segments数组的长度ssize是通过concurrencyLevel计算得出的。为了能通过按位与的散列算法来定位segments数组的索引,必须保证segments数组的长度是2的N次方(power-of-two size),所以必须计算出一个大于或等于concurrencyLevel的最小的2的N次方值来作为segments数组的长度。假如concurrencyLevel等于14、15或16,ssize都会等于16,即容器里锁的个数也是16。
构造完成,如下图所示
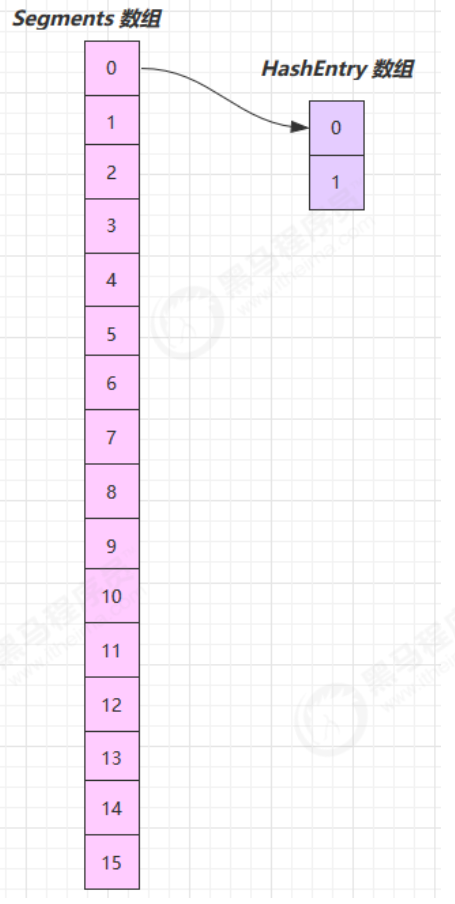
可以看到 ConcurrentHashMap 没有实现懒惰初始化,空间占用不友好
其中 this.segmentShift 和 this.segmentMask 的作用是决定将 key 的 hash 结果匹配到哪个 segment
例如,根据某一 hash 值求 segment 位置,先将高位向低位移动 this.segmentShift 位

结果再与 this.segmentMask 做位于运算,最终得到 1010 即下标为 10 的 segment

以上就是一种散列算法,目的是减少散列冲突,使元素能够均匀地分布在不同的Segment上, 从而提高容器的存取效率。
⏳put 流程
publicVput(K key,V value){Segment<K,V> s;if(value ==null)thrownewNullPointerException();int hash =hash(key);// 计算出 segment 下标int j =(hash >>> segmentShift)& segmentMask;// 获得 segment 对象, 判断是否为 null, 是则创建该 segmentif((s =(Segment<K,V>)UNSAFE.getObject
(segments,(j << SSHIFT)+ SBASE))==null){// 这时不能确定是否真的为 null, 因为其它线程也发现该 segment 为 null,// 因此在 ensureSegment 里用 cas 方式保证该 segment 安全性
s =ensureSegment(j);}// 进入 segment 的put 流程return s.put(key, hash, value,false);}
segment 继承了可重入锁(ReentrantLock),它的 put 方法为
finalVput(K key,int hash,V value,boolean onlyIfAbsent){// 尝试加锁HashEntry<K,V> node =tryLock()?null:// 如果不成功, 进入 scanAndLockForPut 流程// 如果是多核 cpu 最多 tryLock 64 次, 进入 lock 流程// 在尝试期间, 还可以顺便看该节点在链表中有没有, 如果没有顺便创建出来scanAndLockForPut(key, hash, value);// 执行到这里 segment 已经被成功加锁, 可以安全执行V oldValue;try{HashEntry<K,V>[] tab = table;//定位插入位置int index =(tab.length -1)& hash;HashEntry<K,V> first =entryAt(tab, index);for(HashEntry<K,V> e = first;;){if(e !=null){// 更新K k;if((k = e.key)== key ||(e.hash == hash && key.equals(k))){
oldValue = e.value;if(!onlyIfAbsent){
e.value = value;++modCount;}break;}
e = e.next;}else{// 新增// 1) 之前等待锁时, node 已经被创建, next 指向链表头if(node !=null)
node.setNext(first);else// 2) 创建新 node
node =newHashEntry<K,V>(hash, key, value, first);int c = count +1;// 3) 扩容if(c > threshold && tab.length < MAXIMUM_CAPACITY)rehash(node);else// 将 node 作为链表头setEntryAt(tab, index, node);++modCount;
count = c;
oldValue =null;break;}}}finally{unlock();}return oldValue;}
👨🏫分析:
在插入元素前会先判断Segment里的HashEntry数组是否超过容量(threshold),如果超过阈 值,则对数组进行扩容。值得一提的是,Segment的扩容判断比HashMap更恰当,因为HashMap 是在插入元素后判断元素是否已经到达容量的,如果到达了就进行扩容,但是很有可能扩容 之后没有新元素插入,这时HashMap就进行了一次无效的扩容
rehash 流程,发生在 put 中,因为此时已经获得了锁,因此 rehash 时不需要考虑线程安全
privatevoidrehash(HashEntry<K,V> node){HashEntry<K,V>[] oldTable = table;int oldCapacity = oldTable.length;int newCapacity = oldCapacity <<1;
threshold =(int)(newCapacity * loadFactor);HashEntry<K,V>[] newTable =(HashEntry<K,V>[])newHashEntry[newCapacity];int sizeMask = newCapacity -1;for(int i =0; i < oldCapacity ; i++){HashEntry<K,V> e = oldTable[i];if(e !=null){HashEntry<K,V> next = e.next;int idx = e.hash & sizeMask;if(next ==null)// Single node on list
newTable[idx]= e;else{// Reuse consecutive sequence at same slotHashEntry<K,V> lastRun = e;int lastIdx = idx;// 过一遍链表, 尽可能把 rehash 后 idx 不变的节点重用for(HashEntry<K,V> last = next;
last !=null;
last = last.next){int k = last.hash & sizeMask;if(k != lastIdx){
lastIdx = k;
lastRun = last;}}
newTable[lastIdx]= lastRun;// 剩余节点需要新建for(HashEntry<K,V> p = e; p != lastRun; p = p.next){V v = p.value;int h = p.hash;int k = h & sizeMask;HashEntry<K,V> n = newTable[k];
newTable[k]=newHashEntry<K,V>(h, p.key, v, n);}}}}// 扩容完成, 才加入新的节点int nodeIndex = node.hash & sizeMask;// add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex]= node;// 替换为新的 HashEntry table
table = newTable;}
👨🏫分析:
在扩容的时候,首先会创建一个容量是原来容量两倍的数组,然后将原数组里的元素进 行再散列后插入到新的数组里。为了高效,ConcurrentHashMap不会对整个容器进行扩容,而只 对某个segment进行扩容
📌put操作过程如下:
- 如果没有初始化就先调用initTable()方法来进行初始化过程
- 如果没有hash冲突就直接CAS插入
- 如果还在进行扩容操作就先进行扩容
- 如果存在hash冲突,就加锁来保证线程安全,这里有两种情况,一种是链表形式就直接遍历到尾端插入,一种是红黑树就按照红黑树结构插入
- 最后一个如果该链表的数量大于阈值8,就要先转换成黑红树的结构,break再一次进入循环
- 如果添加成功就调用addCount()方法统计size,并且检查是否需要扩容
⏳get流程
🔓get 时并未加锁,用了 UNSAFE 方法保证了可见性,通过直接操作内存的方式来保证并发处理的安全性,使用的是硬件的安全机制。扩容过程中,get 先发生就从旧表取内容,get 后发生就从新 表取内容。
publicVget(Object key){Segment<K,V> s;// manually integrate access methods to reduce overheadHashEntry<K,V>[] tab;int h =hash(key);//============= 分析 ===============> // u 为 segment 对象在数组中的偏移量long u =(((h >>> segmentShift)& segmentMask)<< SSHIFT)+ SBASE;// s 即为 segmentif((s =(Segment<K,V>)UNSAFE.getObjectVolatile(segments, u))!=null&&(tab = s.table)!=null){for(HashEntry<K,V> e =(HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab,((long)(((tab.length -1)& h))<< TSHIFT)+ TBASE);
e !=null; e = e.next){K k;if((k = e.key)== key ||(e.hash == h && key.equals(k)))return e.value;}}returnnull;}
分析:
定位HashEntry和定位Segment的散列算法虽然一样, 都与数组的长度减去1再相“与”,但是相“与”的值不一样,定位Segment使用的是元素的 hashcode通过再散列后得到的值的高位,而定位HashEntry直接使用的是再散列后的值。其目的 是避免两次散列后的值一样,虽然元素在Segment里散列开了,但是却没有在HashEntry里散列 开。
🧮size 计算流程
- 计算元素个数前,先不加锁计算两次,如果前后两次结果如一样,认为个数正确返回
- 如果不一样,进行重试,重试次数超过 3,将所有 segment 锁住,重新计算个数返回> ConcurrentHashMap是如何判断在统计的时候容器是否发生了变化呢?使用modCount 变量,在put、remove和clean方法里操作元素前都会将变量modCount进行加1,那么在统计size 前后比较modCount是否发生变化,从而得知容器的大小是否发生变化
publicintsize(){// Try a few times to get accurate count. On failure due to// continuous async changes in table, resort to locking.finalSegment<K,V>[] segments =this.segments;int size;boolean overflow;// true if size overflows 32 bitslong sum;// sum of modCountslong last =0L;// previous sumint retries =-1;// first iteration isn't retrytry{for(;;){if(retries++== RETRIES_BEFORE_LOCK){// 超过重试次数, 需要创建所有 segment 并加锁for(int j =0; j < segments.length;++j)ensureSegment(j).lock();// force creation}
sum =0L;
size =0;
overflow =false;for(int j =0; j < segments.length;++j){Segment<K,V> seg =segmentAt(segments, j);if(seg !=null){//使用modCount变量,在put、remove和clean方法里操作元素前都会将变量modCount进行加1,
sum += seg.modCount;int c = seg.count;if(c <0||(size += c)<0)
overflow =true;}}if(sum == last)break;
last = sum;}}finally{if(retries > RETRIES_BEFORE_LOCK){for(int j =0; j < segments.length;++j)segmentAt(segments, j).unlock();}}return overflow ?Integer.MAX_VALUE : size;}
💻JDK8中源码分析
以下源码分析为Jdk8的ConcurrentHashMap
🚦重要属性和内部类
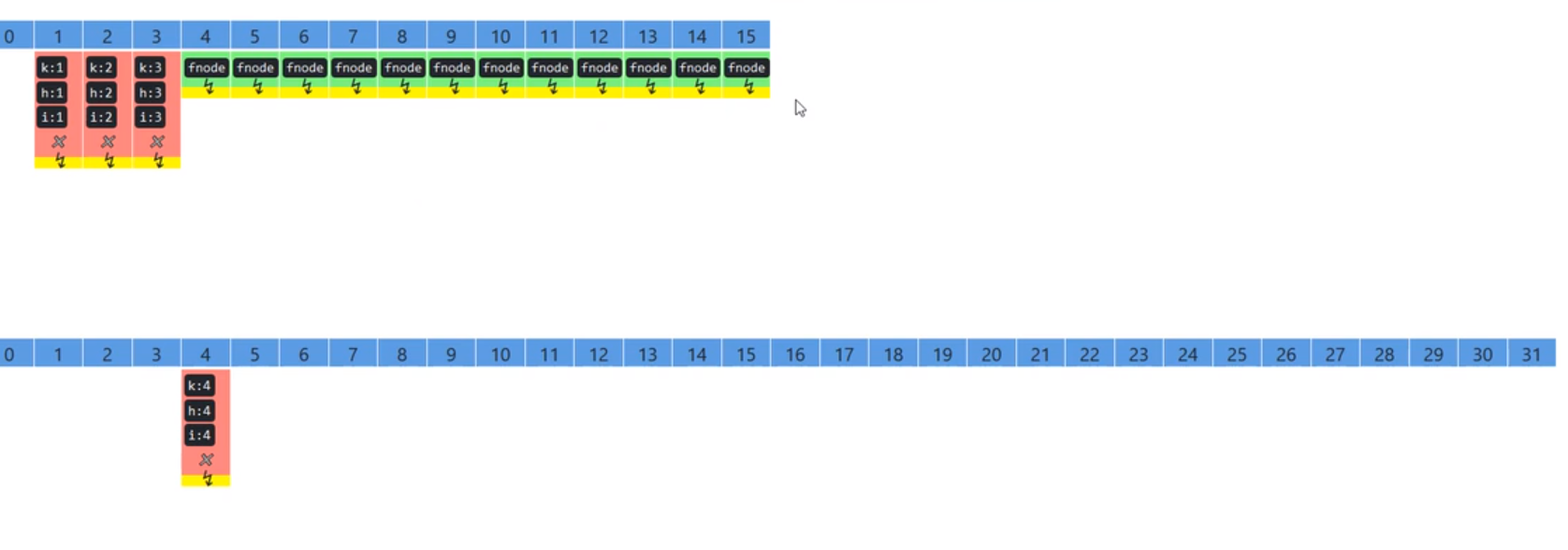
// 默认为 0// 当初始化时, 为 -1// 当扩容时, 为 -(1 + 扩容线程数)// 当初始化或扩容完成后,为 下一次的扩容的阈值大小privatetransientvolatileint sizeCtl;// 整个 ConcurrentHashMap 就是一个 Node[]staticclassNode<K,V>implementsMap.Entry<K,V>{}// hash 表transientvolatileNode<K,V>[] table;// 扩容时的 新 hash 表privatetransientvolatileNode<K,V>[] nextTable;// 扩容时如果某个 bin 迁移完毕, 用 ForwardingNode 作为旧 table bin 的头结点staticfinalclassForwardingNode<K,V>extendsNode<K,V>{}// 用在 compute 以及 computeIfAbsent 时, 用来占位, 计算完成后替换为普通 NodestaticfinalclassReservationNode<K,V>extendsNode<K,V>{}// 作为 treebin 的头节点, 存储 root 和 firststaticfinalclassTreeBin<K,V>extendsNode<K,V>{}// 作为 treebin 的节点, 存储 parent, left, rightstaticfinalclassTreeNode<K,V>extendsNode<K,V>{}
扩容时如果某个 bin 迁移完毕, 用 ForwardingNode 作为旧 table bin 的头结点
🚥重要方法
// 获取 Node[] 中第 i 个 Nodestaticfinal<K,V>Node<K,V>tabAt(Node<K,V>[] tab,int i)// cas 修改 Node[] 中第 i 个 Node 的值, c 为旧值, v 为新值staticfinal<K,V>booleancasTabAt(Node<K,V>[] tab,int i,Node<K,V> c,Node<K,V> v)// 直接修改 Node[] 中第 i 个 Node 的值, v 为新值staticfinal<K,V>voidsetTabAt(Node<K,V>[] tab,int i,Node<K,V> v)
⚙️构造器分析
可以看到实现了懒惰初始化,在构造方法中仅仅计算了 table 的大小,以后在第一次使用时才会真正创建
publicConcurrentHashMap(int initialCapacity,float loadFactor,int concurrencyLevel){if(!(loadFactor >0.0f)|| initialCapacity <0|| concurrencyLevel <=0)thrownewIllegalArgumentException();if(initialCapacity < concurrencyLevel)// Use at least as many bins
initialCapacity = concurrencyLevel;// as estimated threadslong size =(long)(1.0+(long)initialCapacity / loadFactor);// tableSizeFor 仍然是保证计算的大小是 2^n, 即 16,32,64 ... int cap =(size >=(long)MAXIMUM_CAPACITY)?
MAXIMUM_CAPACITY :tableSizeFor((int)size);this.sizeCtl = cap;}
⏳get流程
publicVget(Object key){Node<K,V>[] tab;Node<K,V> e, p;int n, eh;K ek;// spread 方法能确保返回结果是正数int h =spread(key.hashCode());if((tab = table)!=null&&(n = tab.length)>0&&(e =tabAt(tab,(n -1)& h))!=null){// 如果头结点已经是要查找的 keyif((eh = e.hash)== h){if((ek = e.key)== key ||(ek !=null&& key.equals(ek)))return e.val;}// hash 为负数表示该 bin 在扩容中 或是 treebin, 这时调用 find 方法来查找elseif(eh <0)return(p = e.find(h, key))!=null? p.val :null;// 正常遍历链表, 用 equals 比较while((e = e.next)!=null){if(e.hash == h &&((ek = e.key)== key ||(ek !=null&& key.equals(ek))))return e.val;}}returnnull;}
⏳put流程
以下数组简称(table),链表简称(bin)
publicVput(K key,V value){returnputVal(key, value,false);}finalVputVal(K key,V value,boolean onlyIfAbsent){if(key ==null|| value ==null)thrownewNullPointerException();// 其中 spread 方法会综合高位低位, 具有更好的 hash 性int hash =spread(key.hashCode());int binCount =0;for(Node<K,V>[] tab = table;;){// f 是链表头节点// fh 是链表头结点的 hash// i 是链表在 table 中的下标Node<K,V> f;int n, i, fh;// 要创建 tableif(tab ==null||(n = tab.length)==0)// 初始化 table 使用了 cas, 无需 synchronized 创建成功, 进入下一轮循环
tab =initTable();// 要创建链表头节点elseif((f =tabAt(tab, i =(n -1)& hash))==null){// 添加链表头使用了 cas, 无需 synchronizedif(casTabAt(tab, i,null,newNode<K,V>(hash, key, value,null)))break;}// 帮忙扩容elseif((fh = f.hash)== MOVED)// 帮忙之后, 进入下一轮循环
tab =helpTransfer(tab, f);else{V oldVal =null;// 锁住链表头节点synchronized(f){// 再次确认链表头节点没有被移动if(tabAt(tab, i)== f){// 链表if(fh >=0){
binCount =1;// 遍历链表for(Node<K,V> e = f;;++binCount){K ek;// 找到相同的 keyif(e.hash == hash &&((ek = e.key)== key ||(ek !=null&& key.equals(ek)))){
oldVal = e.val;// 更新if(!onlyIfAbsent)
e.val = value;break;}Node<K,V> pred = e;// 已经是最后的节点了, 新增 Node, 追加至链表尾if((e = e.next)==null){
pred.next =newNode<K,V>(hash, key,
value,null);break;}}}// 红黑树elseif(f instanceofTreeBin){Node<K,V> p;
binCount =2;// putTreeVal 会看 key 是否已经在树中, 是, 则返回对应的 TreeNodeif((p =((TreeBin<K,V>)f).putTreeVal(hash, key,
value))!=null){
oldVal = p.val;if(!onlyIfAbsent)
p.val = value;}}}// 释放链表头节点的锁}if(binCount !=0){if(binCount >= TREEIFY_THRESHOLD)// 如果链表长度 >= 树化阈值(8), 进行链表转为红黑树treeifyBin(tab, i);if(oldVal !=null)return oldVal;break;}}}// 增加 size 计数addCount(1L, binCount);returnnull;}privatefinalNode<K,V>[]initTable(){Node<K,V>[] tab;int sc;while((tab = table)==null|| tab.length ==0){if((sc = sizeCtl)<0)Thread.yield();// 尝试将 sizeCtl 设置为 -1(表示初始化 table)elseif(U.compareAndSwapInt(this, SIZECTL, sc,-1)){// 获得锁, 创建 table, 这时其它线程会在 while() 循环中 yield 直至 table 创建try{if((tab = table)==null|| tab.length ==0){int n =(sc >0)? sc : DEFAULT_CAPACITY;Node<K,V>[] nt =(Node<K,V>[])newNode<?,?>[n];
table = tab = nt;
sc = n -(n >>>2);}}finally{
sizeCtl = sc;}break;}}return tab;}// check 是之前 binCount 的个数privatefinalvoidaddCount(long x,int check){CounterCell[] as;long b, s;if(// 已经有了 counterCells, 向 cell 累加(as = counterCells)!=null||// 还没有, 向 baseCount 累加!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)){CounterCell a;long v;int m;boolean uncontended =true;if(// 还没有 counterCells
as ==null||(m = as.length -1)<0||// 还没有 cell(a = as[ThreadLocalRandom.getProbe()& m])==null||// cell cas 增加计数失败!(uncontended =U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))){// 创建累加单元数组和cell, 累加重试fullAddCount(x, uncontended);return;}if(check <=1)return;// 获取元素个数
s =sumCount();}if(check >=0){Node<K,V>[] tab, nt;int n, sc;while(s >=(long)(sc = sizeCtl)&&(tab = table)!=null&&(n = tab.length)< MAXIMUM_CAPACITY){int rs =resizeStamp(n);if(sc <0){if((sc >>> RESIZE_STAMP_SHIFT)!= rs || sc == rs +1||
sc == rs + MAX_RESIZERS ||(nt = nextTable)==null||
transferIndex <=0)break;// newtable 已经创建了,帮忙扩容if(U.compareAndSwapInt(this, SIZECTL, sc, sc +1))transfer(tab, nt);}// 需要扩容,这时 newtable 未创建elseif(U.compareAndSwapInt(this, SIZECTL, sc,(rs << RESIZE_STAMP_SHIFT)+2))transfer(tab,null);
s =sumCount();}}}
🧮size 计算流程
size 计算实际发生在 put,remove 改变集合元素的操作之中
- 没有竞争发生,向 baseCount 累加计数
- 有竞争发生,新建 counterCells,向其中的一个 cell 累加计数- counterCells 初始有两个 cell- 如果计数竞争比较激烈,会创建新的 cell 来累加计数
publicintsize(){long n =sumCount();return((n <0L)?0:(n >(long)Integer.MAX_VALUE)?Integer.MAX_VALUE :(int)n);}finallongsumCount(){CounterCell[] as = counterCells;CounterCell a;// 将 baseCount 计数与所有 cell 计数累加long sum = baseCount;if(as !=null){for(int i =0; i < as.length;++i){if((a = as[i])!=null) sum += a.value;}}return sum;}
👩🏫整体分析
Java 8 数组(Node) +( 链表 Node | 红黑树 TreeNode ) 以下数组简称(table),链表简称(bin)
- 初始化,使用 cas 来保证并发安全,懒惰初始化 table
- 树化,当 table.length < 64 时,先尝试扩容,超过 64 时,并且 bin.length > 8 时,会将链表树化,树化过程 会用 synchronized 锁住链表头
- put,如果该 bin 尚未创建,只需要使用 cas 创建 bin;如果已经有了,锁住链表头进行后续 put 操作,元素 添加至 bin 的尾部
- get,无锁操作仅需要保证可见性,扩容过程中 get 操作拿到的是 ForwardingNode 它会让 get 操作在新 table 进行搜索
- 扩容,扩容时以 bin 为单位进行,需要对 bin 进行 synchronized,但这时妙的是其它竞争线程也不是无事可 做,它们会帮助把其它 bin 进行扩容,扩容时平均只有 1/6 的节点会把复制到新 table 中
- size,元素个数保存在 baseCount 中,并发时的个数变动保存在 CounterCell[] 当中。最后统计数量时累加 即可
🔗参考链接:
版权归原作者 一定会去到彩虹海的麦当 所有, 如有侵权,请联系我们删除。