
在大数据开发领域,用户留存是一个关键指标,它反映了产品吸引并保留用户的能力。
留存率的计算不仅有助于评估产品的健康状况,还能为产品优化和市场策略提供重要依据。
本文将详细介绍如何在大数据开发中计算用户留存,并附带具体的SQL示例。
目录
留存的定义与意义

留存是指用户在某一时间点(如注册日、首次使用日)后,在后续特定时间段内继续使用该产品的行为。留存率则是这些留存用户占初始用户的比例。留存率越高,说明产品越能吸引并保持用户的兴趣。
留存的意义在于:
- 评估产品吸引力:留存率高的产品通常意味着用户对产品有较高的满意度和忠诚度。
- 指导产品优化:通过分析不同时间段的留存率,可以识别产品改进的方向,如用户体验、功能设计等。
- 制定市场策略:根据留存数据,可以制定更有针对性的营销策略,提高用户粘性和活跃度。
留存率的计算公式

留存率的计算公式通常为:
留存率
=
基准日后第n天活跃用户数
基准日用户数
×
100
%
\text{留存率} = \frac{\text{基准日后第n天活跃用户数}}{\text{基准日用户数}} \times 100\%
留存率=基准日用户数基准日后第n天活跃用户数×100%
其中,基准日可以是用户注册日、首次使用日等,n可以是1天、7天、30天等,具体取决于分析需求。
SQL示例:计算次日留存率
以下是一个使用SQL计算次日留存率的示例。假设我们有一个用户行为日志表
user_log
,包含字段
user_id
(用户ID)、
login_time
(登录时间)等。
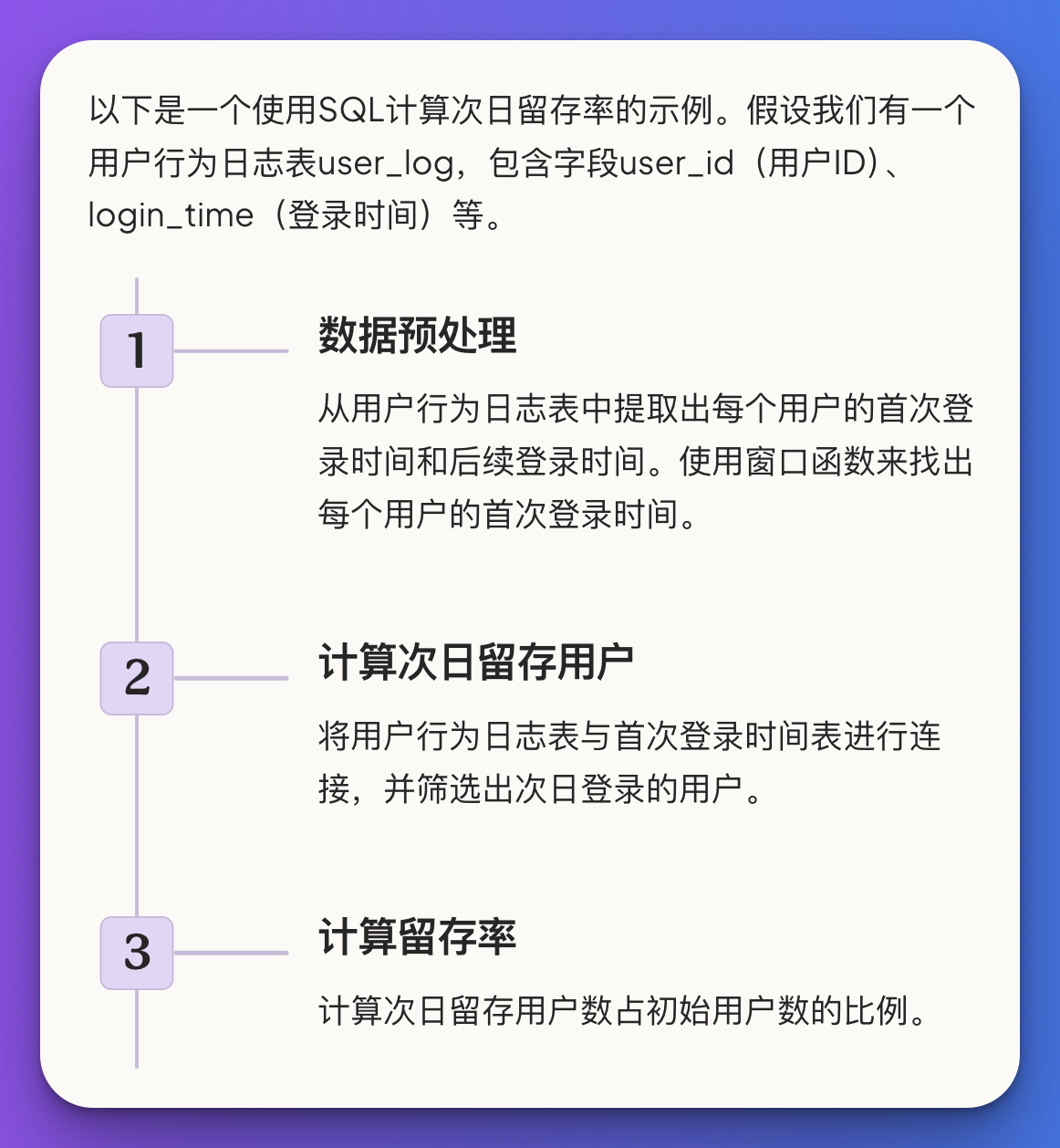
第一步:数据预处理
首先,我们需要从用户行为日志表中提取出每个用户的首次登录时间和后续登录时间。这里我们使用窗口函数来找出每个用户的首次登录时间。
WITH first_login AS(SELECT
user_id,MIN(login_time)AS first_login_time
FROM
user_log
GROUPBY
user_id
)
第二步:计算次日留存用户
接下来,我们将用户行为日志表与首次登录时间表进行连接,并筛选出次日登录的用户。
, retention_users AS(SELECT
a.user_id,
a.login_time,
DATE_ADD(b.first_login_time,INTERVAL1DAY)AS expected_next_day
FROM
user_log a
JOIN
first_login b ON a.user_id = b.user_id
WHEREDATE(a.login_time)=DATE(expected_next_day))
第三步:计算留存率
最后,我们计算次日留存用户数占初始用户数的比例。
SELECTCOUNT(DISTINCT r.user_id)AS next_day_retention_users,COUNT(DISTINCT f.user_id)AS initial_users,ROUND(COUNT(DISTINCT r.user_id)/COUNT(DISTINCT f.user_id)*100,2)AS next_day_retention_rate
FROM
first_login f
LEFTJOIN
retention_users r ON f.user_id = r.user_id;
完成SQL
这个示例假设你有一个名为
user_log
的表,其中包含
user_id
(用户ID)和
login_time
(登录时间)字段。
-- 计算次日留存率WITH FirstLogin AS(-- 找出每个用户的首次登录时间SELECT
user_id,MIN(login_time)AS first_login_time
FROM
user_log
GROUPBY
user_id
),
RetentionUsers AS(-- 找出次日登录的用户SELECT
a.user_id,
a.login_time,
DATE_ADD(b.first_login_time,INTERVAL1DAY)AS expected_next_day
FROM
user_log a
JOIN
FirstLogin b ON a.user_id = b.user_id
WHEREDATE(a.login_time)=DATE(expected_next_day))-- 计算留存率SELECTCOUNT(DISTINCT RetentionUsers.user_id)AS next_day_retention_users,COUNT(DISTINCT FirstLogin.user_id)AS initial_users,ROUND(COUNT(DISTINCT RetentionUsers.user_id)/COUNT(DISTINCT FirstLogin.user_id)*100,2)AS next_day_retention_rate
FROM
FirstLogin
LEFTJOIN
RetentionUsers ON FirstLogin.user_id = RetentionUsers.user_id;
这个SQL查询首先使用
WITH
子句创建了两个临时表:
FirstLogin
和
RetentionUsers
。
FirstLogin
表包含每个用户的首次登录时间,而
RetentionUsers
表包含那些在首次登录后的次日也登录了的用户。最后,主查询计算了次日留存用户数、初始用户数以及次日留存率。
其他留存率计算方法
除了次日留存率,我们还可以计算3日留存率、7日留存率等。这些计算方法的思路与次日留存率类似,只是在筛选条件中将
INTERVAL 1 DAY
改为相应的天数即可。
总结
用户留存率是衡量产品健康度和用户粘性的重要指标。
在大数据开发中,我们可以通过SQL等工具高效地计算留存率,为产品优化和市场策略提供有力支持。
本文介绍了留存的定义、意义以及具体的SQL示例,希望能对大数据开发人员有所帮助。
版权归原作者 数据小羊 所有, 如有侵权,请联系我们删除。