
1、添加POM依赖
Apache Flink 集成了通用的 Kafka 连接器,使用时需要根据生产环境的版本引入相应的依赖
<!-- 引入 kafka连接器依赖-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>1.17.1</version>
</dependency>
2、API使用说明
KafkaSink
可将数据流写入一个或多个 Kafka topic。
官网链接:官网链接

DataStream<String> stream = ...;
KafkaSink<String> sink = KafkaSink.<String>builder() // 泛型为 输入输入的类型
// TODO 必填项:配置 kafka 的地址和端口
.setBootstrapServers(brokers)
// TODO 必填项:配置消息序列化器信息 Topic名称、消息序列化器类型
.setRecordSerializer(KafkaRecordSerializationSchema.builder()
.setTopic("topic-name")
.setValueSerializationSchema(new SimpleStringSchema())
.build()
)
// TODO 必填项:配置容错保证级别 精准一次、至少一次、不做任何保证
.setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.build();
stream.sinkTo(sink);
3、序列化器
序列化器的作用是将flink数据转换成 kafka的ProducerRecord
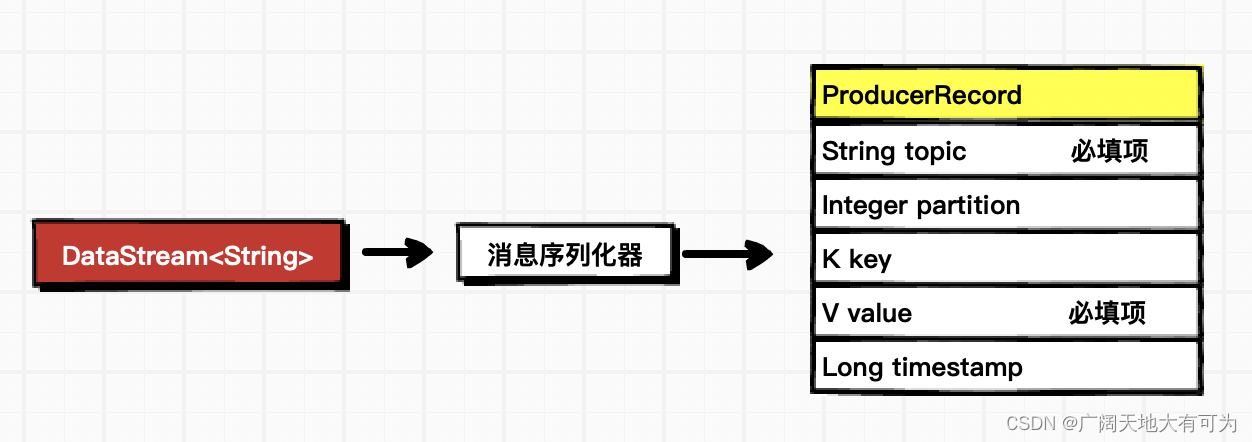
3.1 使用预定义的序列化器
功能:将 DataStream 数据转换为 Kafka消息中的value,key为默认值null,timestamp为默认值
// 初始化 KafkaSink 实例
KafkaSink<String> kafkaSink = KafkaSink.<String>builder()
// TODO 必填项:配置 kafka 的地址和端口
.setBootstrapServers("worker01:9092")
// TODO 必填项:配置消息序列化器信息 Topic名称、消息序列化器类型
.setRecordSerializer(
KafkaRecordSerializationSchema.<String>builder()
.setTopic("20230912")
.setValueSerializationSchema(new SimpleStringSchema())
.build()
)
.build();
3.2 使用自定义的序列化器
功能:可以对 kafka消息的key、value、partition、timestamp进行赋值
/**
* 如果要指定写入kafka的key,可以自定义序列化器:
* 1、实现 一个接口,重写 序列化 方法
* 2、指定key,转成 字节数组
* 3、指定value,转成 字节数组
* 4、返回一个 ProducerRecord对象,把key、value放进去
*/
// 初始化 KafkaSink 实例 (自定义 KafkaRecordSerializationSchema 实例)
KafkaSink<String> kafkaSink = KafkaSink.<String>builder()
// TODO 必填项:配置 kafka 的地址和端口
.setBootstrapServers("worker01:9092")
// TODO 必填项:配置消息序列化器信息 Topic名称、消息序列化器类型
.setRecordSerializer(
new KafkaRecordSerializationSchema<String>() {
@Nullable
@Override
public ProducerRecord<byte[], byte[]> serialize(String element, KafkaSinkContext context, Long timestamp) {
String[] datas = element.split(",");
byte[] key = datas[0].getBytes(StandardCharsets.UTF_8);
byte[] value = element.getBytes(StandardCharsets.UTF_8);
Long currTimestamp = System.currentTimeMillis();
Integer partition = 0;
return new ProducerRecord<>("20230913", partition, currTimestamp, key, value);
}
}
)
.build();
4、容错保证级别
KafkaSink
总共支持三种不同的语义保证(
DeliveryGuarantee
)
DeliveryGuarantee.NONE不提供任何保证 - 消息有可能会因 Kafka broker 的原因发生丢失或因 Flink 的故障发生重复DeliveryGuarantee.AT_LEAST_ONCE至少一次 - sink 在 checkpoint 时会等待 Kafka 缓冲区中的数据全部被 Kafka producer 确认。- 消息不会因 Kafka broker 端发生的事件而丢失,但可能会在 Flink 重启时重复,因为 Flink 会重新处理旧数据。DeliveryGuarantee.EXACTLY_ONCE 精确一次 - 该模式下,Kafka sink 会将所有数据通过在 checkpoint 时提交的事务写入。- 因此,如果 consumer 只读取已提交的数据(参见 Kafka consumer 配置isolation.level),在 Flink 发生重启时不会发生数据重复。- 然而这会使数据在 checkpoint 完成时才会可见,因此请按需调整 checkpoint 的间隔。- 请确认事务 ID 的前缀(transactionIdPrefix)对不同的应用是唯一的,以保证不同作业的事务 不会互相影响!此外,强烈建议将 Kafka 的事务超时时间调整至远大于 checkpoint 最大间隔 + 最大重启时间,否则 Kafka 对未提交事务的过期处理会导致数据丢失。
4.1 至少一次 的配置
DataStream<String> stream = ...;
// 初始化 KafkaSink 实例
KafkaSink<String> kafkaSink = KafkaSink.<String>builder()
// TODO 必填项:配置 kafka 的地址和端口
.setBootstrapServers("worker01:9092")
// TODO 必填项:配置消息序列化器信息 Topic名称、消息序列化器类型
.setRecordSerializer(
KafkaRecordSerializationSchema.<String>builder()
.setTopic("20230912")
.setValueSerializationSchema(new SimpleStringSchema())
.build()
)
// TODO 必填项:配置容灾保证级别设置为 至少一次
.setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.build();
stream.sinkTo(sink);
4.2
精确
一次 的配置
// 如果是精准一次,必须开启checkpoint
env.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE);
DataStream<String> stream = ...;
KafkaSink<String> sink = KafkaSink.<String>builder() // 泛型为 输入输入的类型
// TODO 必填项:配置 kafka 的地址和端口
.setBootstrapServers(brokers)
// TODO 必填项:配置消息序列化器信息 Topic名称、消息序列化器类型
.setRecordSerializer(KafkaRecordSerializationSchema.builder()
.setTopic("topic-name")
.setValueSerializationSchema(new SimpleStringSchema())
.build()
)
// TODO 必填项:配置容灾保证级别设置为 精准一次
.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
// 如果是精准一次,必须设置 事务的前缀
.setTransactionalIdPrefix("flink-")
// 如果是精准一次,必须设置 事务超时时间: 大于checkpoint间隔,小于 max 15分钟
.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, "6000")
.build();
stream.sinkTo(sink);
5、这是一个完整的入门案例
需求:Flink实时读取 socket数据源,将读取到的数据写入到Kafka (要保证不丢失,不重复)
开发语言:java1.8
flink版本:flink1.17.0
package com.baidu.datastream.sink;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.kafka.clients.producer.ProducerConfig;
// TODO flink 数据输出到kafka
public class SinkKafka {
public static void main(String[] args) throws Exception {
// 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
// 如果是精准一次,必须开启checkpoint
env.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE);
// 2.指定数据源
DataStreamSource<String> streamSource = env.socketTextStream("localhost", 9999);
// 3.初始化 KafkaSink 实例
KafkaSink<String> kafkaSink = KafkaSink.<String>builder()
// TODO 必填项:配置 kafka 的地址和端口
.setBootstrapServers("worker01:9092")
// TODO 必填项:配置消息序列化器信息 Topic名称、消息序列化器类型
.setRecordSerializer(
KafkaRecordSerializationSchema.<String>builder()
.setTopic("20230912")
.setValueSerializationSchema(new SimpleStringSchema())
.build()
)
// TODO 必填项:配置容灾保证级别设置为 精准一次
.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
// 如果是精准一次,必须设置 事务的前缀
.setTransactionalIdPrefix("flink-")
// 如果是精准一次,必须设置 事务超时时间: 大于checkpoint间隔,小于 max 15分钟
.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, "6000")
.build();
streamSource.sinkTo(kafkaSink);
// 3.触发程序执行
env.execute();
}
}
本文转载自: https://blog.csdn.net/weixin_42845827/article/details/132854512
版权归原作者 广阔天地大有可为 所有, 如有侵权,请联系我们删除。
版权归原作者 广阔天地大有可为 所有, 如有侵权,请联系我们删除。