
day1
用C语言的理论知识点去推断结果
**需求:让面试官知道你懂这个内容 **
一、C语言补充内容
【1】结构体补充内容:
1)结构体.等法
结构体.等法代码
#include <stdio.h>
struct student
{
int num;
float score;
char name[32];
};
int main(int argc, const char *argv[])
{
#if 0
struct student stu[3] = {1,99.9,"zhangsan",2,88.8,"lisi",3,98.9,"wangwu"};
#endif
#if 0
struct student stu[3]=
{
[0] = {
.num = 1,
.score = 99.9,
.name = "zhangsan",
},
[2] = {
.num = 3,
.score = 77.7,
.name = "lisi",
}
};
int i;
for(i = 0; i < sizeof(stu)/sizeof(struct student);i++)
{
printf("%d,%f,%s\n",stu[i].num,stu[i].score,stu[i].name);
}
#endif
struct student stu =
{
.num = 1,
.score = 99.9,
.name = "wangwu",
};
#if 0
stu.num = 1;
stu.score = 99.9;
#endif
printf("%d,%f,%s\n",stu.num,stu.score,stu.name);
return 0;
}
二、存储类型
存储类型决定变量的存储位置
数据类型决定变量所占空间大小
1、auto:自动型
- 修饰的变量存放在栈区
- 修饰的变量特点:初值随机(如果变量不赋初值)
- 栈区:由系统自动开辟与释放
2、static
static的特点(面试高频内容)(进程与线程的区别)
- static的本质是延长变量或函数的生命周期,同时限制其作用域。
- static声明的全局变量、函数,仅当前文件内可用,其他文件不能引用。
- static在函数内部声明的内部静态变量,只需初始化一次。
- 而且变量存储在全局数据段(静态存储区)中,而不是栈中,其生命周期持续到程序退出。
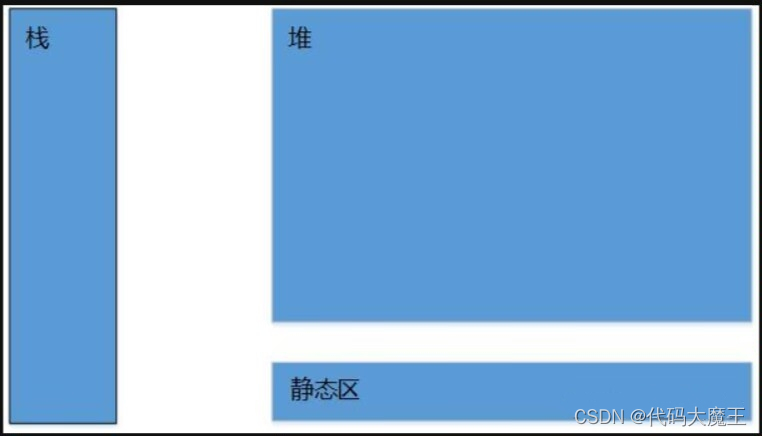
三、内存问题(内存图)
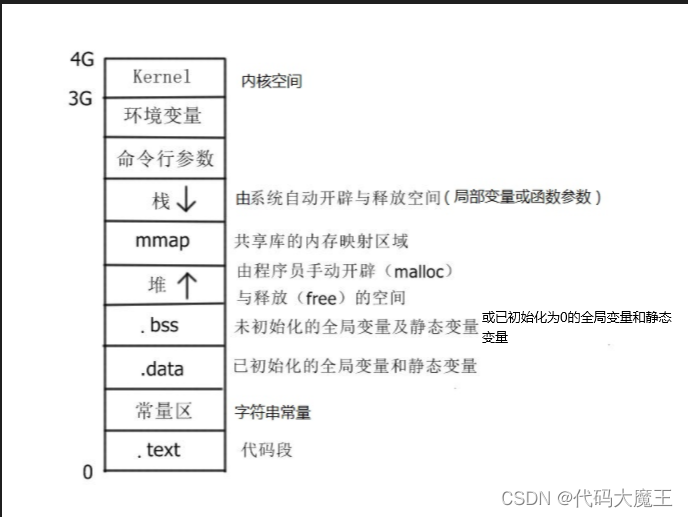
1、malloc、free
void *malloc(size_t size);
功能:手动申请空间,申请的空间在堆区
参数:申请的空间大小
返回值:任意类型指针(成功:返回的是申请空间的首地址,失败:返回:NULL)
void free(void *ptr);
功能:释放空间
参数:要释放的空间的首地址
返回值:无
ptr = NULL;
防止野指针(野狗)的产生;
2、函数值传递
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
void getMemory(char * p)
{
p = (char *)malloc(100);
}
void test(void)
{
char * str = NULL;
getMemory(str);
strcpy(str, "hello world!");
printf("%s\n", str);
}
int main()
{
test();
return 0;
}
结果为:Segmentation fault (core dumped)
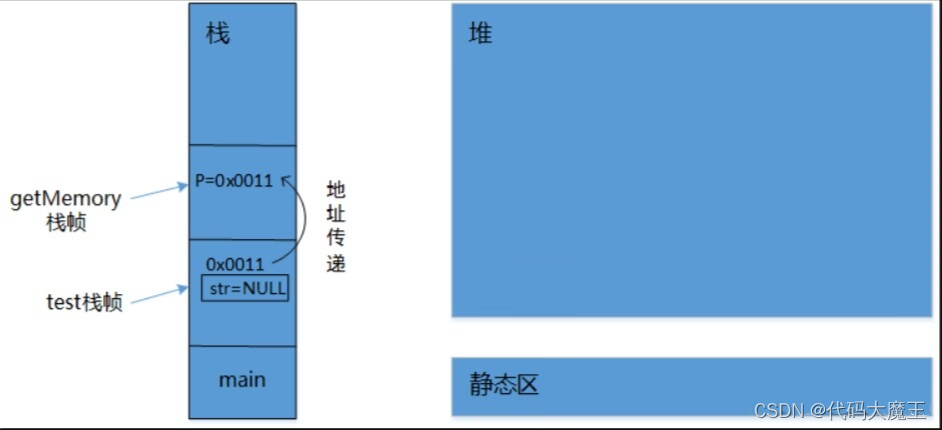
首先在main中调用test函数:
(1)在栈中创建一个指针变量str,设置为NULL,test中调用getMemory(),将str的值传递给形参p,p=NULL。

(2)在getMemory函数中,开辟100个字节的堆内存,并把起始地址赋给p。此时p中存的便是堆内存空间的地址。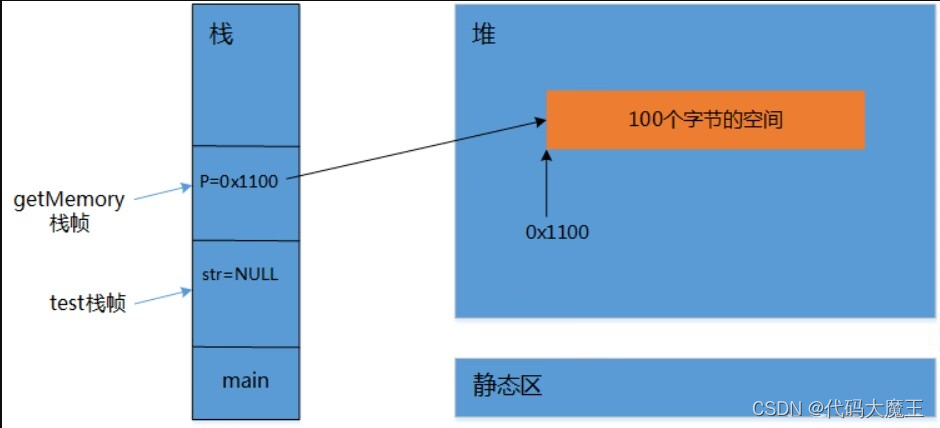
(3)当getMemory函数调用完毕,栈帧释放,局部变量p被回收,而此时test中的str还是NULL,没有指向任何空间,堆空间中开辟的100个字节便成了脱缰野马,无法管理,发生内存泄漏。

3、用学习的内存的知识点延长变量的声明周期
存储类型决定变量存储区域,存储区域不一样,变量的生命周期不一样

下面是Ubuntu12版本上面运行出来的:

打印不出来hello world原因:生命周期太短,用学习的内存的知识点延长变量的声明周期。
(1)将字符串存放在静态存储区,延长变量的生命周期

(2)将字符串存放在常量区,延长变量生命周期
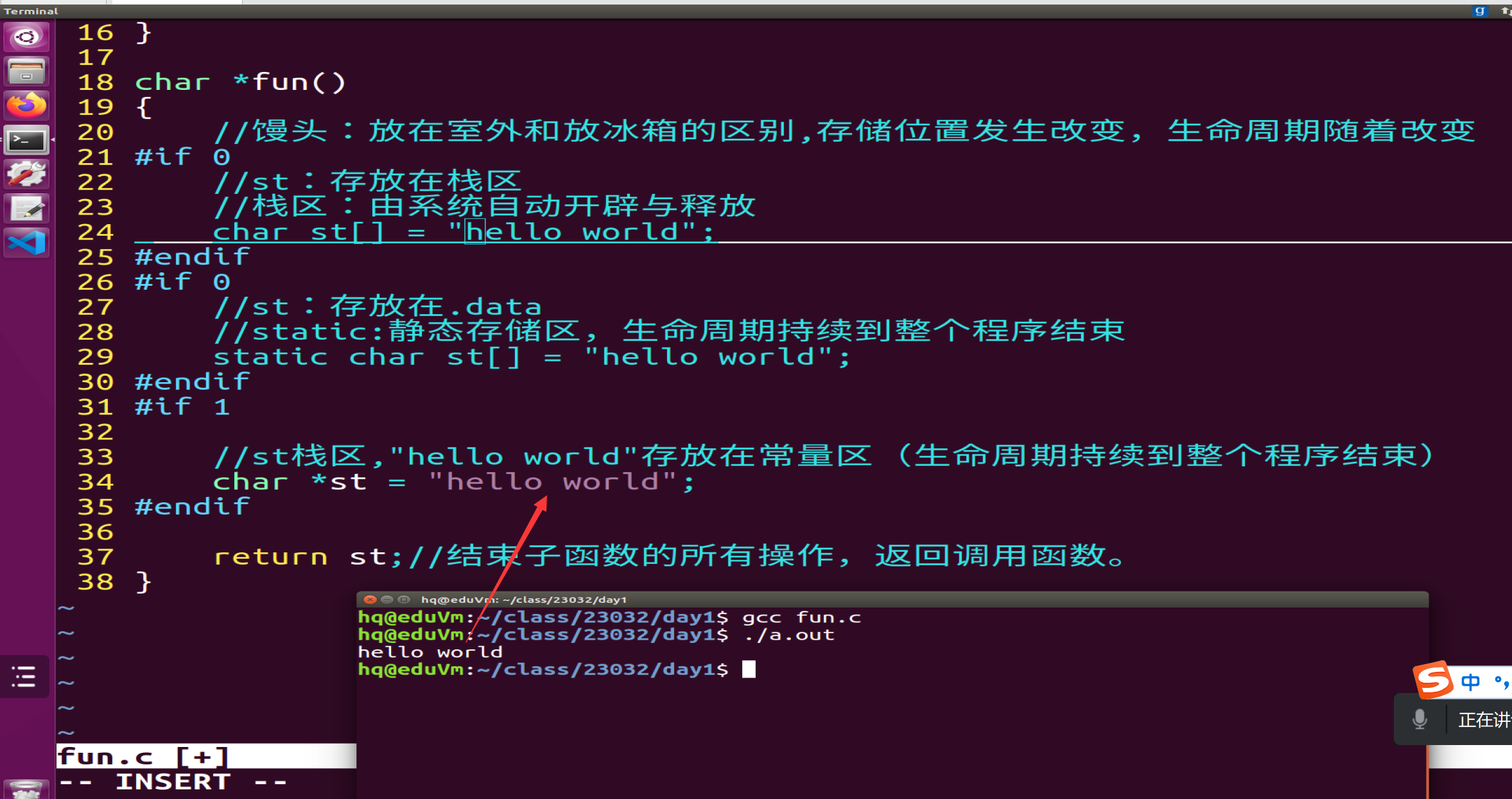
下面为char p[] = hello 与char *p在内存中存储形式
(3)将字符串存放在堆区,延长变量生命周期
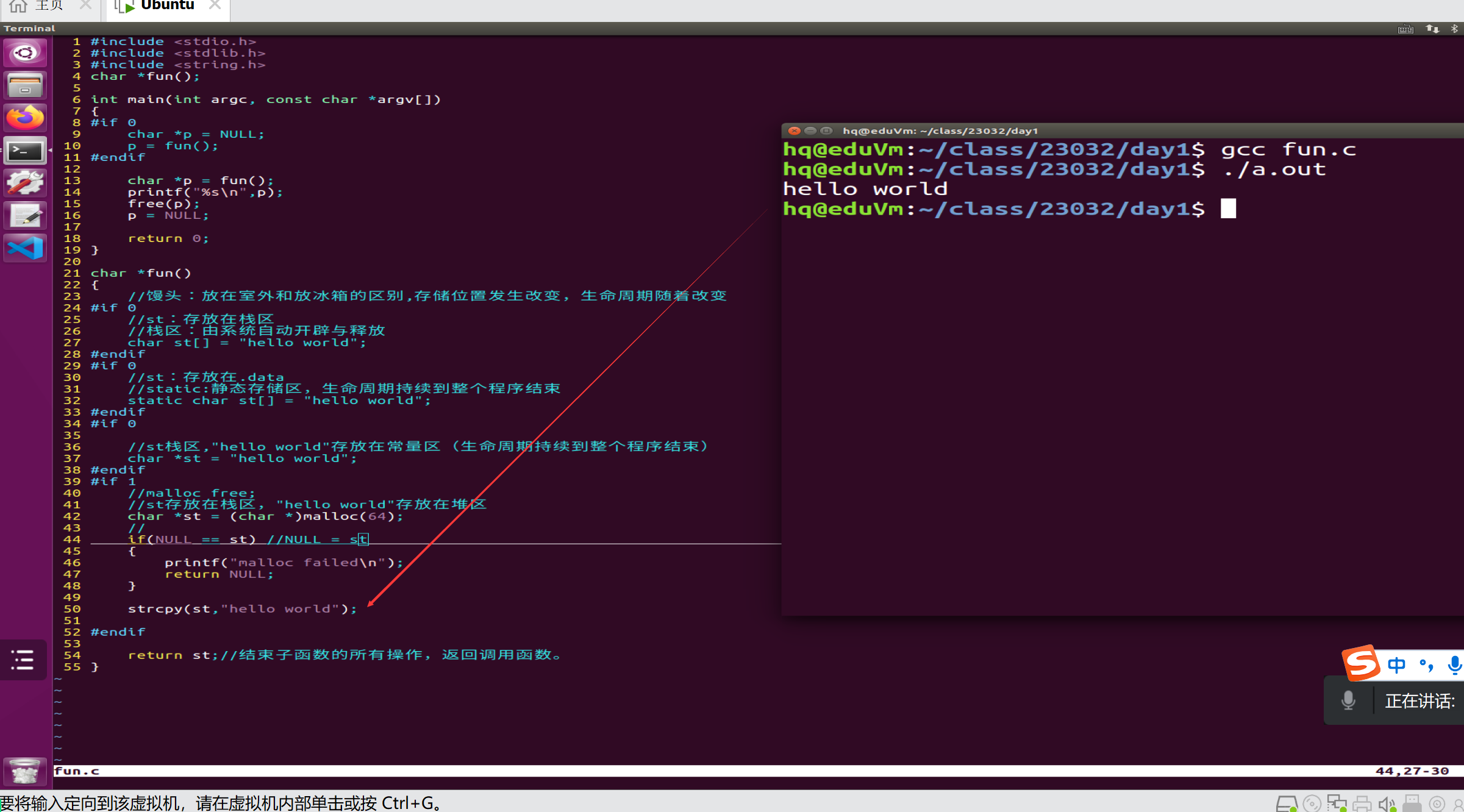
下面为所有的代码:
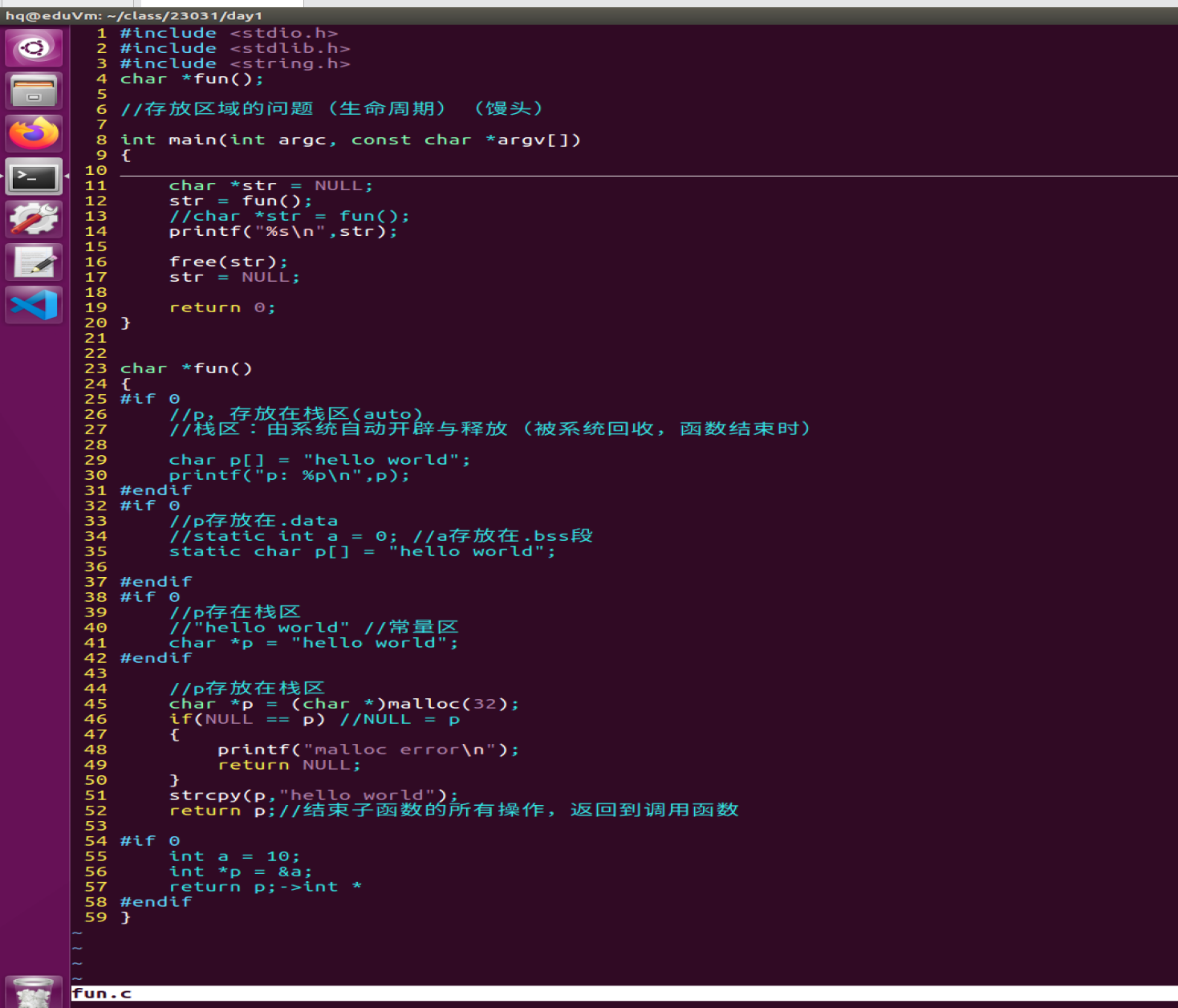
(4)置为全局变量
4、函数地址传递
既然是因为失去缰绳,无法控制,那就设法将缰绳再次掌握起来,p是一个临时变量,函数调用完就释放,那么就设法让test内的str也能掌控开辟的空间。要改变str的值,那么可以传递str的地址给getMemory,有了地址,就可以改变str里面的内容。使用二级指针。
(题目中包含考了:一级指针、二级指针)
void getMemory(char ** p)
{
*p = (char *)malloc(100);
}
void test(void)
{
char * str = NULL;
char ** pstr = &str;
getMemory(pstr);
strcpy(str, "hello world!");
printf("%s\n", str);
free(str);
str = NULL;
}
int main()
{
test();
return 0;
}
(1)将str这个指针变量的地址传递给p,pstr内是str的地址。
char ** p = pstr;
(2)*p = (char *)malloc(100);
// 等价于 str=(char *)malloc(100);
将str的内容赋值为开辟的堆空间的地址。这样,当getMemory调用完毕,释放空间之后,str中的地址指向开辟的空间,这样野马就相当于有了缰绳,便不再是野马,可以管理。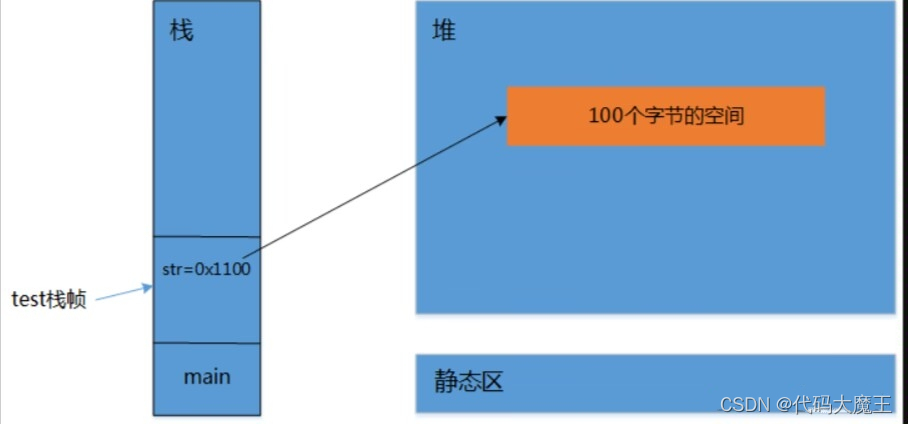
(3)当使用完之后,要及时使用free释放空间,并置str=NULL;
free(str);
str = NULL;
(4)test函数调用完释放栈帧,main结束释放栈帧。
三、LinuxC课程介绍
sl_3.03-16_i386.deb
软件名_版本号.次版本号-修订次数_架构.后缀
(一)离线安装操作指令(dpkg)
(1)sudo dpkg -i 完整的软件包名:安装软件
(2)sudo dpkg -r 软件名 :卸载
(3)sudo dpkg -s 软件名 :查看安装状态
(4)sudo dpkg -P 软件名 : 完全卸载
(5)sudo dpkg -L 软件名 :列出软件文件清单
(二)在线安装操作指令
1、软件包管理工具:apt-get 和apt-cache
特点:安装软件不需要软件的安装包存在,能从镜像站点获取软件包,能检测软件之间的依赖关系,安装需要网络。
apt-get:
(1)sudo apt-get install 软件名:下载安装软件
(2)sudo apt-get remove 软件名:卸载软件包
(3)sudo apt-get --purge remove 软件名 :完全卸载
(4)sudo apt-get update :更新软件源
(5)sudo apt-get upgrade :将所有的软件更新为最新版本
(6)sudo apt-get clean:清除下载的软件包
apt-cache命令:查看安装状态、依赖关系
- sudo apt-cache show 软件名:获取二进制软件包的详细描述信息
- sudo apt-cache policy 软件名:查看安装状态
- sudo apt-cache depends 软件名:我依赖的软件
- sudo apt-cache rdepends 软件名:那个软件依赖我
镜像站点:
(仓库)软件1 软件2 软件2 放到网上---》网址
百度(镜像站点源) 火狐 QQ--》浏览器(服务器
(三)安装失败时原因和网络调试
安装软件失败的原因:
1.虚拟机没有网络*****
1)检测虚拟机是否可以链接外网:ping 网址或ip地址
ping www.baidu.com
出现以下现象,能通网:
PING www.a.shifen.com (180.101.49.12) 56(84) bytes of data.
64 bytes from 180.101.49.12: icmp_seq=1 ttl=52 time=18.0 ms
64 bytes from 180.101.49.12: icmp_seq=2 ttl=52 time=17.5 ms
2)没有网络,配置网络:(虚拟机-》物理机网卡)
1、选择虚拟机连网方式:桥接模式、Net模式、仅主机模式。 编辑-->虚拟机网络适配器:查看到的是三个模式桥接模式、nat模式 --》可以通外网。仅主机模式--》不通外网
2、配置自动获取ip或设置固定ip(0~255 ->0 1 254 255)
1.编辑--》虚拟网络适配器--》选择桥接模式(自动(不建议))/Net模式--》确定
2.虚拟机--》设置--》硬件--》网络适配器--》模式和前边对应--》确定
3.添加链接的网络:
自动获取ip:
右上角扇形点击--》Eit connections --》add --》name:auto
--》选择ip4 --》method :automatic --》确定
重启网络。
1、手动设置固定ip:
根据win的IP地址情况对虚拟机设置固定IP地址
右上角扇形点击--》Eit connections --》add --》name:manual
--》选择ip4 --》method :manual --》添加固定ip--》DNS--》确定。
重启网络。
当在后面干研发时,板子和电脑之间只用局域网时,可以将虚拟机的IP写固定,写时一般以winds作为参照去写:

查看win的IP地址,一种命令的方式,另外图形化的方式
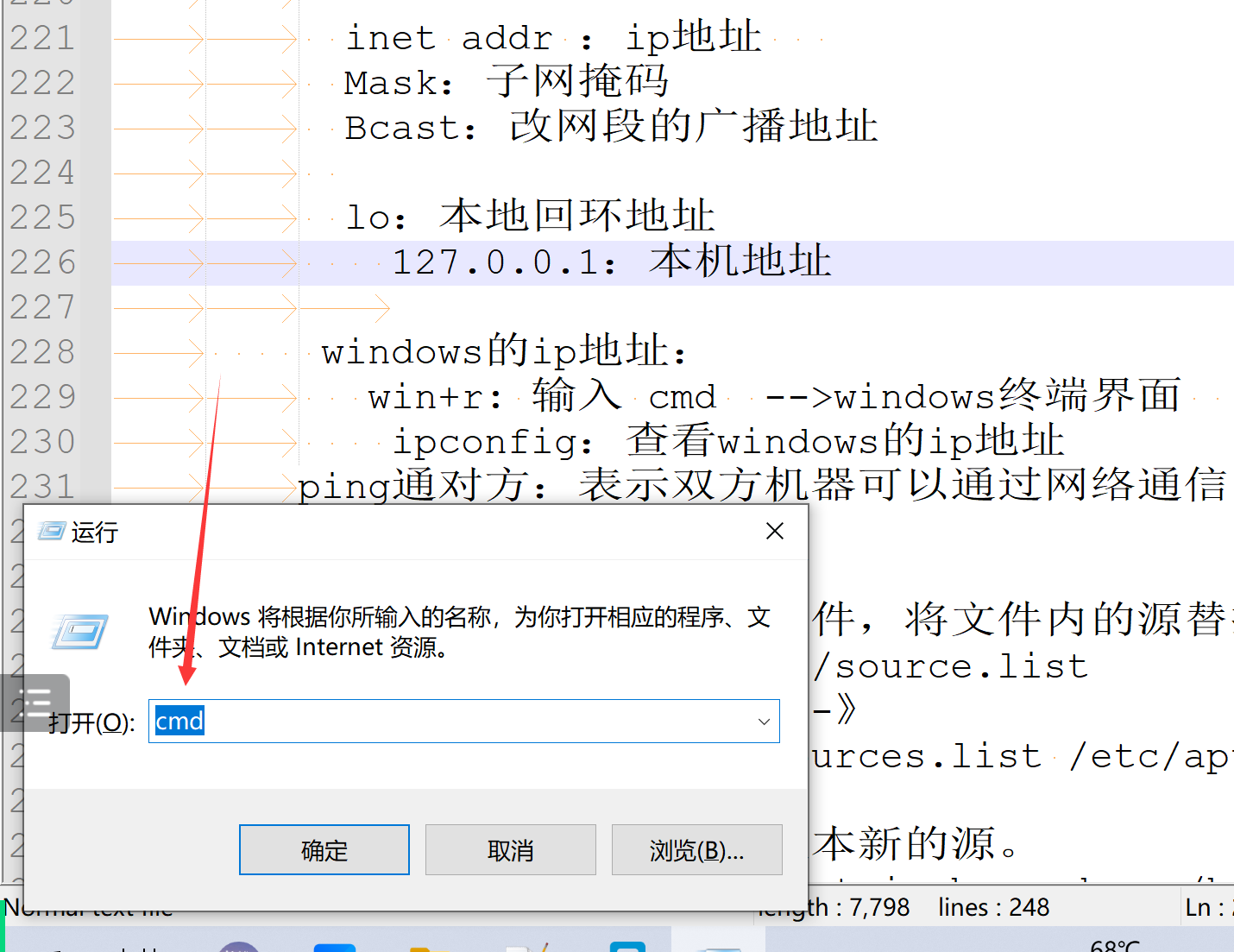
windows的ip地址:
win+r: 输入 cmd -->windows终端界面
ipconfig:查看windows的ip地址
ping通对方:表示双方机器可以通过网络通信(不借助第三方软件)
3.查看ip地址
虚拟机ip地址的查看:ifconfig
inet addr :ip地址
Mask:子网掩码
Bcast:改网段的广播地址
lo:本地回环地址
127.0.0.1:本机地址
DNS:域名解析器(解析网址的)
将网址解析为ip地址,进行通信,不同运营商,解析器的地址不同。
2、镜像站点获取不到软件源
镜像站点获取不到软件源
解决镜像站点问题
1>找到虚拟机保存源的文件,将文件内的源替换新的源
sudo gedit /etc/apt/source.list
注:修改之前先备份--》
sudo cp /etc/apt/sources.list /etc/apt/sources.list.conf
2>网上查找对应ubuntu版本新的源。
ubuntu | 镜像站使用帮助 | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
3>更新源,新换的源生效
sudo apt-get update
day2
一、函数
1.定义
函数是一个完成特定功能的代码模块,
其程序代码独立
2.格式
(存储类型) 数据类型 函数名(形式参数)
{
函数体;
return 常量、变量或表达式;
}
int add(int a, int b)
{
return a + b;
}
3.调用
函数名(实参);
4.声明
数据类型 函数名(形式参数);
int add(int a, int b);
int add(int, int);
5.函数的传参
1)值传递:只是将值进行传递,对传递的值不会产生影响(复制传递)
2)地址传递:将地址进行传递,在子函数中改变地址中的内容时,会对主函数的变量的值产生影响
3)数组传递:int array(int a[], int n)
进行数组传递时,并没有将整个数组进行传递,而是传递的是数组的首地址
二、指针函数
指针函数
本质:函数,函数的返回值为指针
格式:数据类型 *函数名(参数)
{
return 地址;//return NULL;
//return 0;
//return -1;
}
void *malloc(size_t size);
功能:手动申请空间,申请的空间在堆区
参数:申请的空间大小
返回值:任意类型指针
void free(void *ptr);
功能:释放空间
参数:要释放的空间
返回值:无
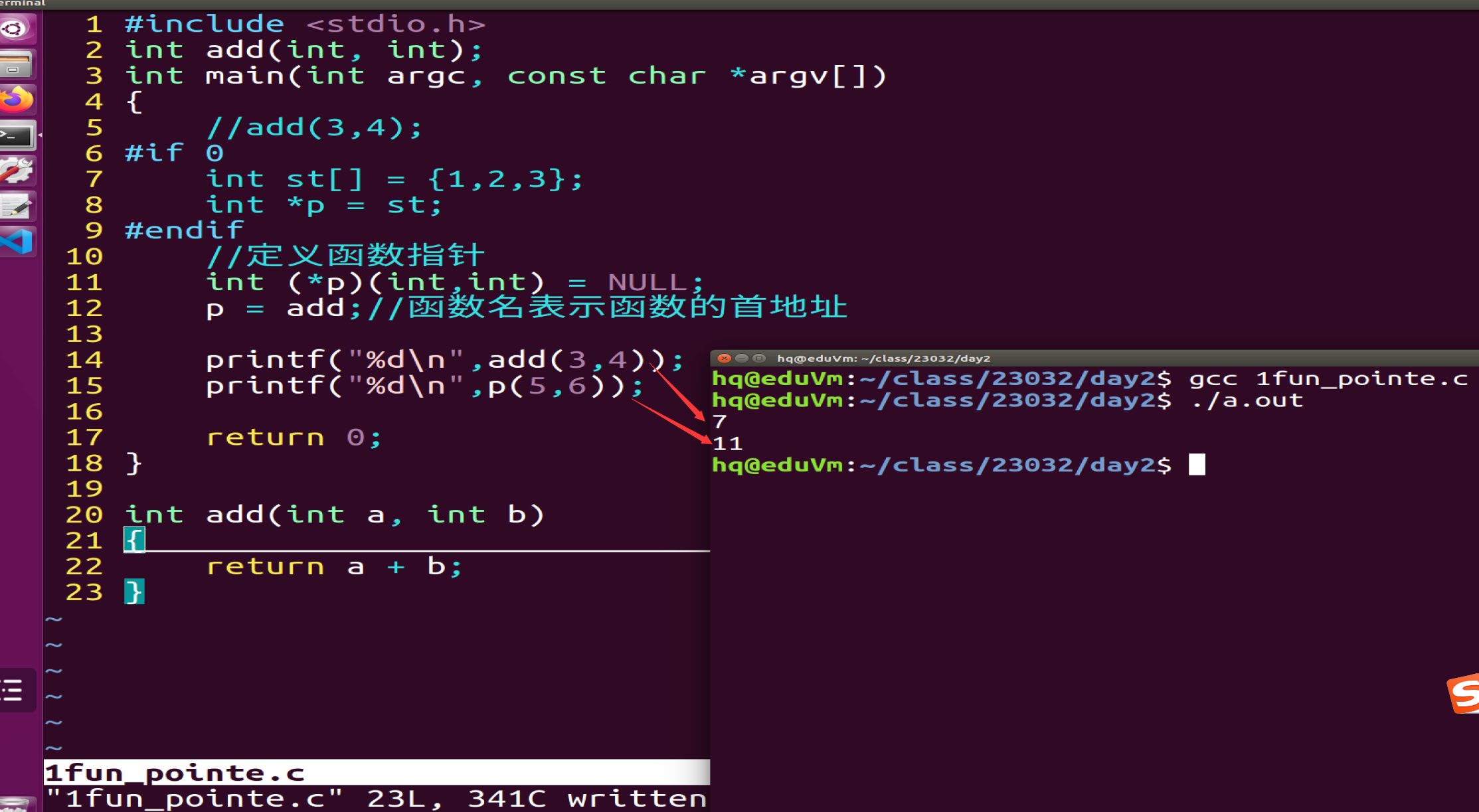
三、函数指针
函数指针的使用以及Linux下面代码展示以及效果呈现
- 本质:指针,指向函数的指针
char st[] = "hello";
char *p = st;
用指针(p)代替st,st
什么类型的指针指向什么类型的数
int a;int *p;
char ch,char *q;
- 格式:数据类型 (*函数指针变量名)(参数);
- 用法:
1)当一个函数指针指向了一个函数,就可以通过这个指针来调用该函数,
2)函数指针可以将函数作为参数传递给其他函数调用。
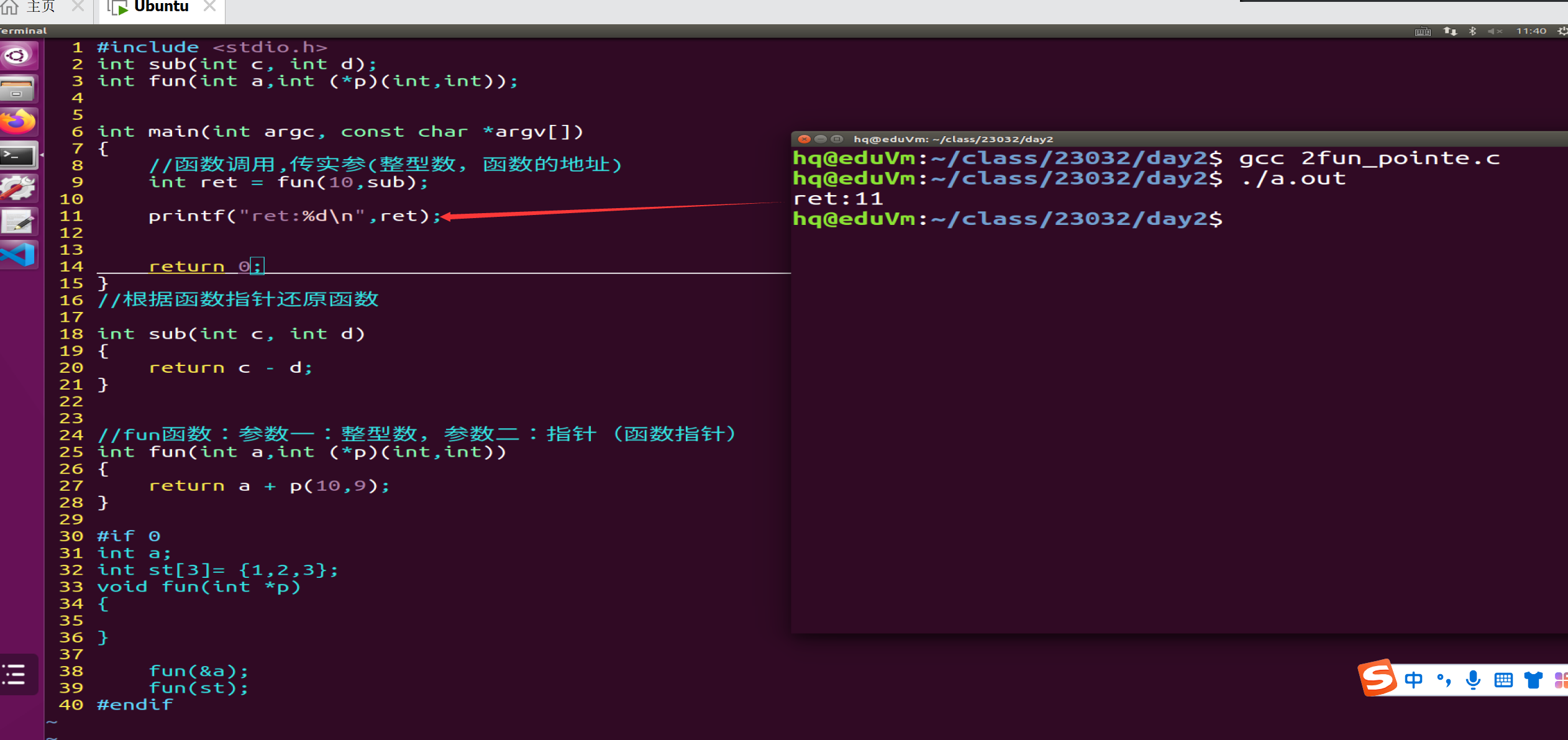
怎样使用函数指针
异步通信方式(进程之间)-》进程间通信方式
ctrl+c -》触发一个信号
Linux底层收到信号后,对进程进行一些动作(终止(杀死))。
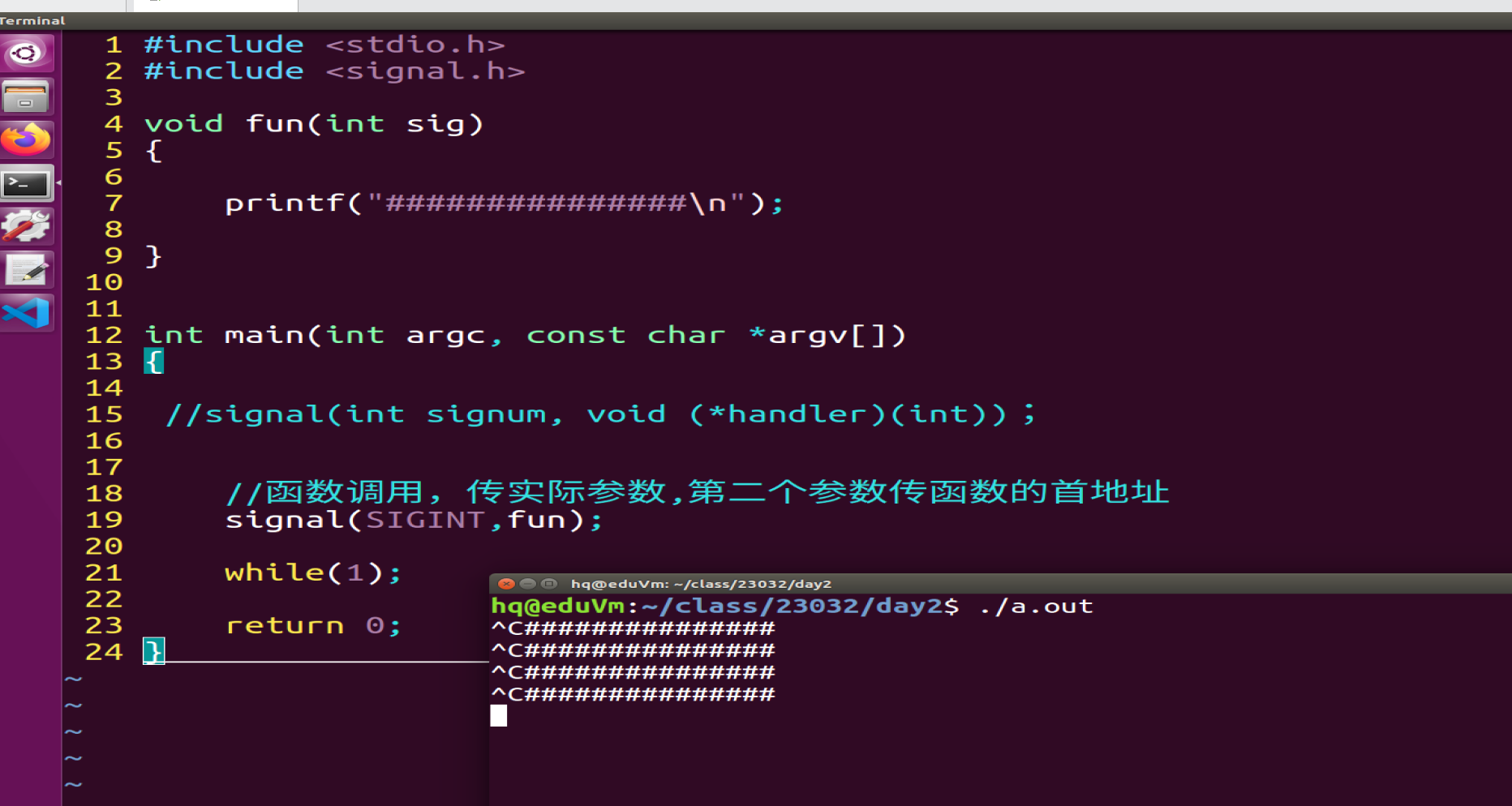
#define N 10;
signal(int signum, void (*handler)(int));
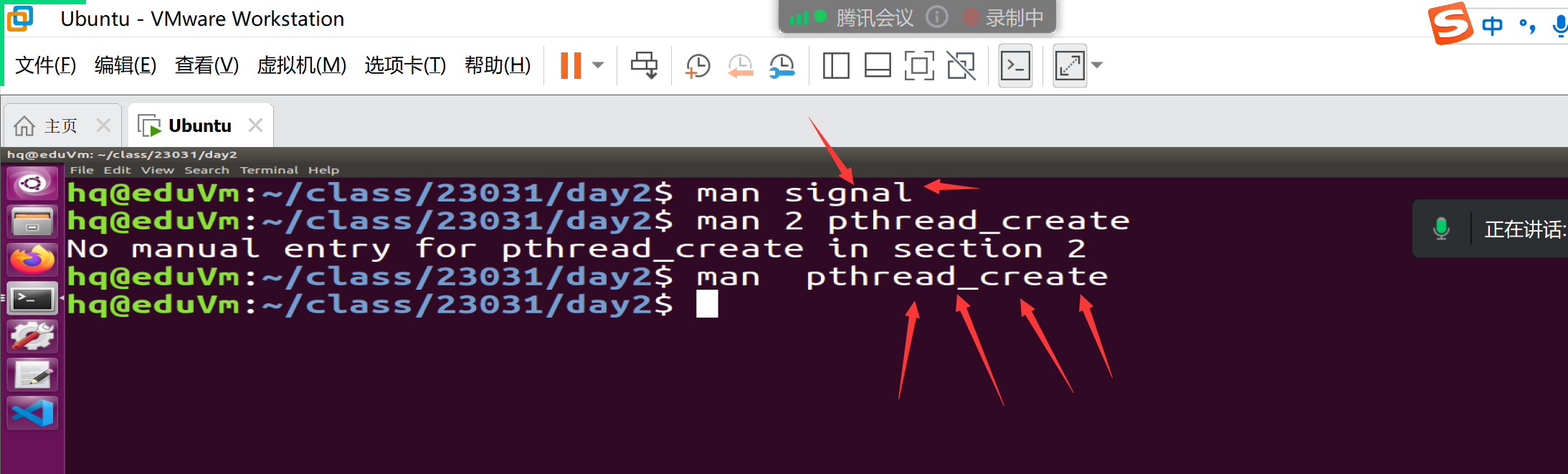
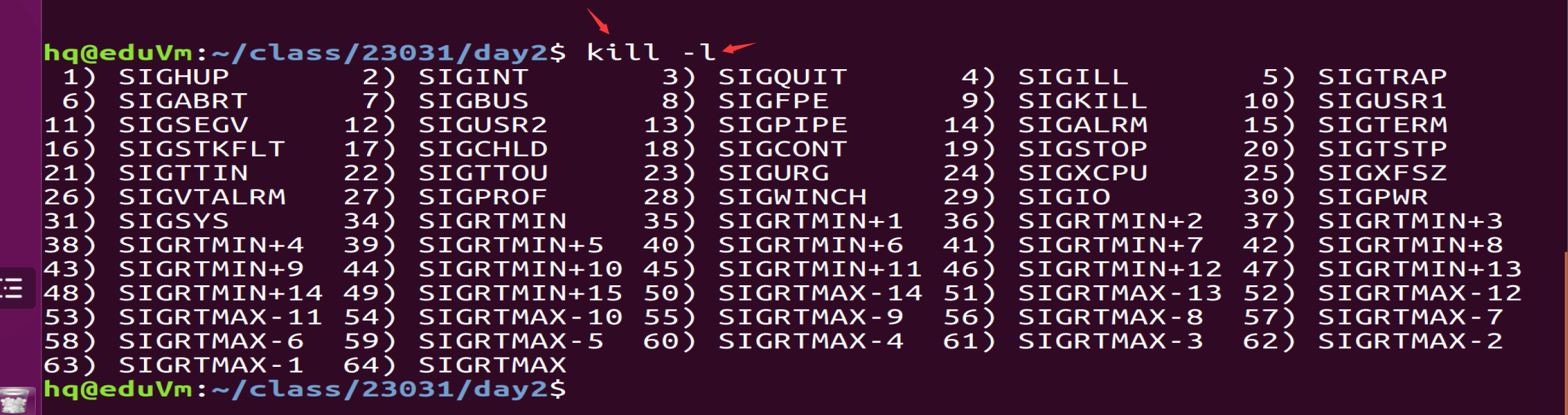
参数一:整型(kill -l)
参数二:函数指针(指向函数,指向的函数什么时候运行?)
功能:当参数一触发(signal收到了信号),执行参数2指向的函数
当按ctrl+c,signal收到了SIGINT,参数2指向的函数默认把进程终止了。

kill -l

异步通信方式;
指针函数和函数指针分别在什么地方用过?
当需要这个函数返回地址时,用指针函数。
函数指针:
signal函数参数 (信号处理函数)
pthread_create函数的参数 (线程的处理函数)
底层(file_operations结构体里成员())
要求:
1:知道函数指针,能倒退还原函数
2:有函数,要让指针指向这个函数,要能定义出函数指针
注意:数据类型(返回值的数据类型,参数的数据类型)
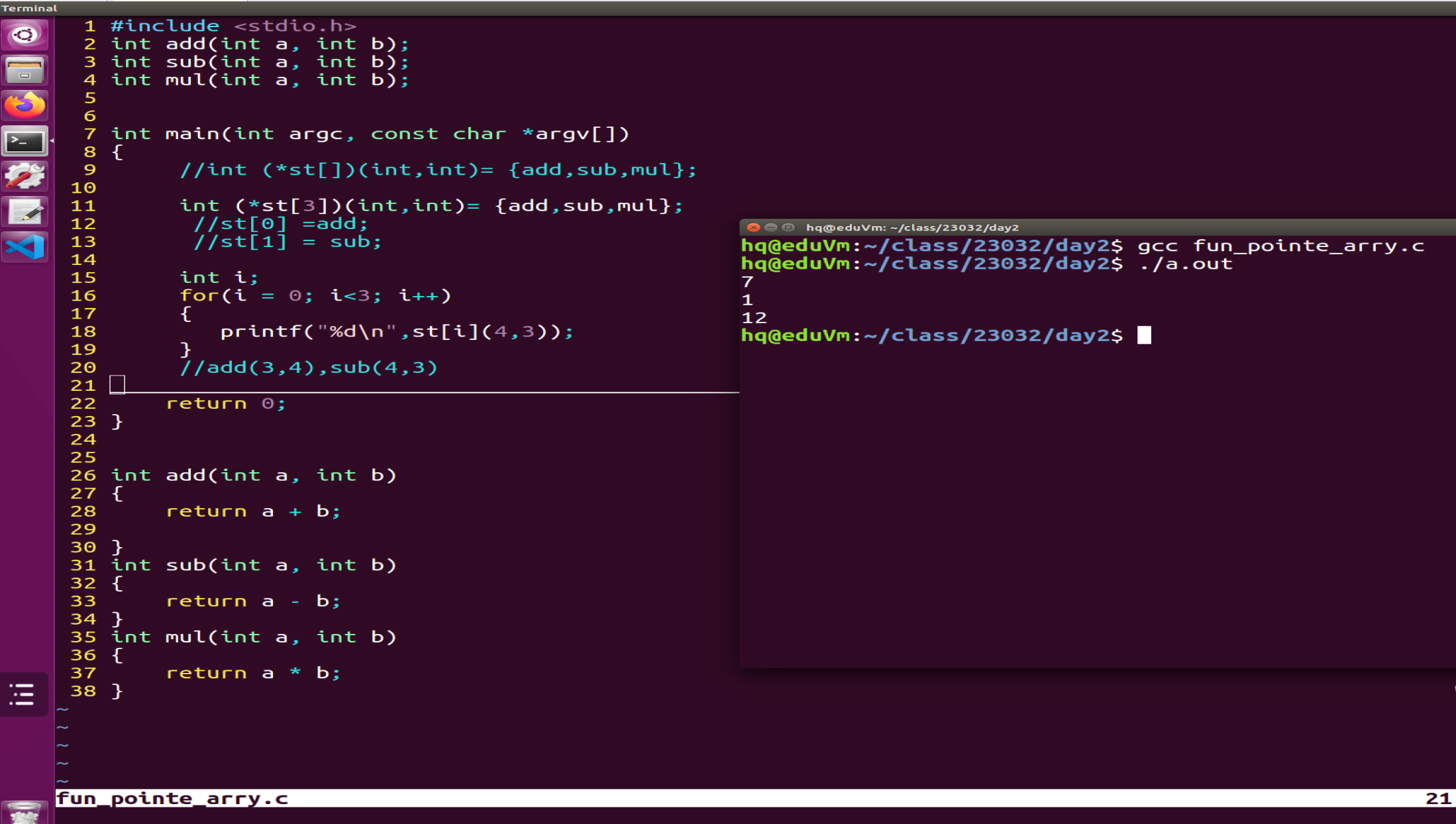
四、函数指针数组
函数指针数组的使用
- 本质:数组,数组的内容为函数指针
- 格式:数据类型 (*函数指针数组名[下标])(参数);
五、GDB解决问题
GDB调试方式:准确定位(行)
使用过的调试方式有哪些?
1:GDB
2:printf打印
调试工具(GDB)段错误(地址非法操作,指针)
gdb调试:
(在用GDB调试之前确定你的代码没有语法错误。设置断点的时候,必须让主函数运行起来,第一次断点设置,设置在主函数当中的某一行,这样编译器才能从入口函数进来。在gcc编译选项中一定要加入‘-g’。只有在代码处于“运行”或“暂停”状态时才能查看变量值。设置断点后程序在指定行之前停止
先制造一个产生段错误的代码:
gcc -g test.c
gdb a.out
3)(gdb)l:列出源文件内容
4)(gdb)b 10:设置断点在第10行
5)(gdb)r :运行(设置断点后一定要先运行,才能进行单步调试往下)
6)(gdb)n:单步调试(断点行是不被运行的,n单步调试的时候不进子函数)
7)(gdb)s:单步运行(断点行是不被运行的,s单步调试的时候进子函数)
单步调试时:(s进入子函数,16版本的虚拟机有问题,想进入系统函数,12版本的正常)
- (gdb)p 变量名 :查看变量值
9)q:退出调试界面
day3
一、printf定位错误方式
1、printf("%s,%s,%d\n",FILE,func,LINE);
- 大概定位(缩小范围)
- 作用:定位错误,如果这一行打印了,那么引起错误的代码肯定在这一行之后,如果这一行没有打印,那么引起错误的代码肯定在这一行之前。
二、进程相关命令*(知道、会用)
32位操作系统
进程的定义和占的内存空间(了解)
- 进程:就是程序的一次执行过程。(动态) 程序:在磁盘空间上存放的可执行的二进制文件。(静态)
- 内核--》0-4G虚拟内存空间
0-4G虚拟内存空间:0-3G--》私有内存空间
3-4G:公用内核空间 (驱动,进程间通信)
进程操作指令(记住)
(一)进程的操作指令
1、ps -aux
查看进程的信息
用户 进程id TTY:运行是否依赖终端 状态 名称
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.2 25152 4308 ? Ss 2月13 0:06 /sbin/init splash
root 2 0.0 0.0 0 0 ? S 2月13 0:00 [kthreadd]
2、ps -ef
查看信息包含父进程的进程号 PPID
子进程使用的是父进程的资源(空间,库等)
3、ps -ajx
可以查看 (父进程id 组id 会话id)
多个进程可以组成一个组,多个组可以组成一个会话,多个会话可以组成一个会话组
4、./a.out &
将a.out在后台运行起来
5、Ctrl+z
将前台运行的进程暂停同时放到后台
6、bg 数字
(这里的数字为你按Ctrl+Z的时候前面中括号里面的数字):将后台暂停的进程在后台跑起来。
7、fg 数字
将后台运行的进程拉到前台运行
8、jobs
查看后台的进行
9、top
动态显示进程的状态 (动态看进程占用CPU)
shift + >
shift + <
PR :PR=NI+20
NI:优先级 ,值越小优先级越高,优先级的范围为-20~+19。
(二)进程的状态(了解)
man ps:
D uninterruptible sleep (usually IO) 不可中断睡眠
R running or runnable (on run queue) 运行
S interruptible sleep (waiting for an event to complete) 可中断睡眠
T stopped by job control signal 暂停
X dead (should never be seen) 死亡
Z defunct ("zombie") process, terminated but not reaped by its parent 僵尸
< high-priority (not nice to other users) 高优先级
N low-priority (nice to other users) 低优先级
L has pages locked into memory (for real-time and custom IO)
锁定到内存中
s is a session leader 会话组组长
l is multi-threaded (using CLONE_THREAD, like NPTL pthreads do)多线程
- is in the foreground process group 前台进程 D: 不可中断的进程 R: 正在执行中 S: 阻塞状态 T: 暂停执行 Z: 不存在但暂时无法消除 W: 没有足够的内存分页可分配 <: 高优先级的进程 N: 低优先级的进程 L: 有内存分页分配并锁在内存中
- +:在前台运行
(三)进程优先级问题(掌握)
1.nice
以指定优先级运行进程
sudo nice -num ./可执行程序 :以优先级为num运行程序
sudo nice --3 ./可执行程序 程序以-3优先级运行
2.renice
运行进程优先级修改
sudo renice num PID
sudo renice 3 PID PID对应的进程优先级改为3
sudo renice -3 PID PID对应的进程优先级改为-3
(四)kill相关内容(记住)
kill 给进程发送信号
kill -l :查看linux中的信号
2) SIGINT ctrl+c
9) SIGKILL 杀死进程信号
19) SIGSTOP 暂停
SIGINT 3) SIGQUIT 退出进程 4) SIGILL结束进程
SIGKILL杀死(不可忽略) 10) SIGUSR1未定义功能
SIGUSR2未定义功能 13) SIGPIPE管道破裂 14) SIGALRM定时信号
SIGCHLD子进程状态改变给父进程发 19) SIGSTOP暂停(不可忽略)
SIGUSR1 SIGUSR2 未定默认功能信号
项目异步方式(不阻塞等待)
智能家居-》传感器采集环境信息-》打印
3个传感器-》触发一个信号;打印;
数据上不来-》卡死

kill -信号编号 PID :给指定进程发送指定信号
killall a.out :杀死所有名字为a.out
三、解压和压缩 tar
选项和操作结果展示(三条指令记住)
选项:
-x : 释放归档文件
-c : 创建一个新的归档文件
-v : 显示归档和释放的过程信息
-f : 用户指定归档文件的文件名,否则使用默认名称; 后跟文件名
-j : 由tar生成归档,然后由bzip2压缩 .bz2
-z : 由tar生成归档,然后由gzip压缩 .gz
-J : 由tar生成归档,然后由xz压缩 .xz
注意:
1)具有归档功能,并通过参数可以进行压缩或解压
2)压缩或解压后源文件存在
3)需要写全压缩或解压的文件名格式:
格式:
tar 选项 压缩(解压)文件名 [要压缩的文件列表]
组合:
-cjf :以bz2的格式压缩文件
-czf :以gz的格式压缩文件
-cJf : 以xz的格式压缩文件
注意 : jz 在f 前; 压缩后源文件依然存在
-xvf : 解压一个压缩包; 解压后压缩包依然存在
eg: 压缩
tar -cvjf file.tar.bz2 *.c
tar -cvJf file.tar.xz *.c
tar -cvzf file.tar.gz *.c
注: tar -cvf file.tar *.c -->只归档不压缩
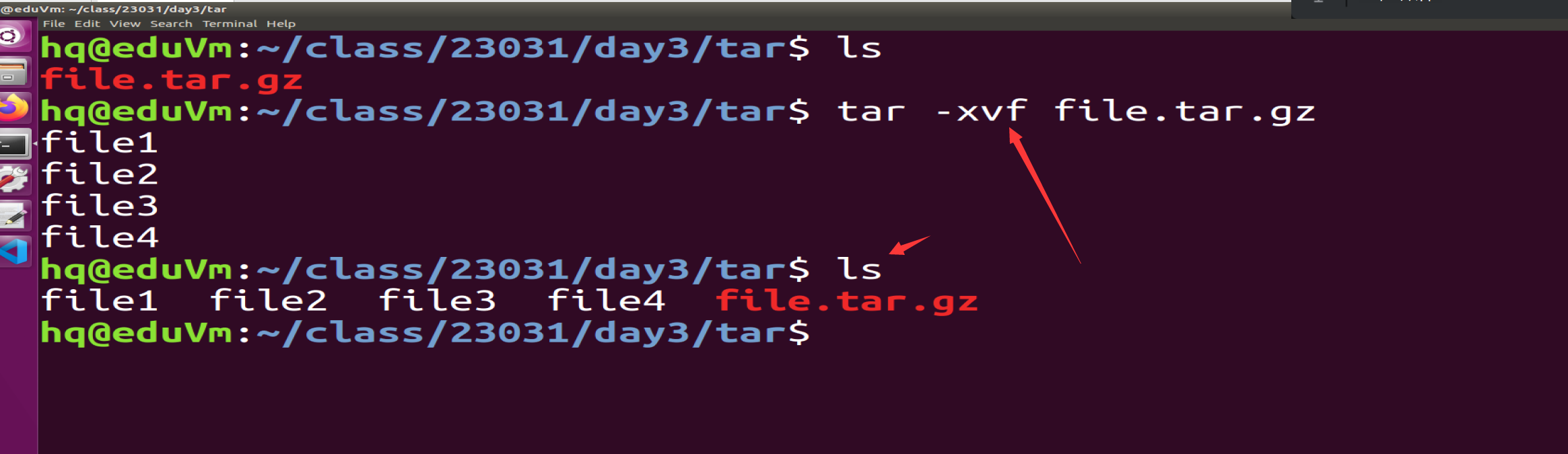
解压: tar -xvf xxxx.tar.gz
总结:
压缩: tar -cvzf file.tar.gz *.c

解压: tar -xvf xxxx.tar.gz
XXXX.zip
unzip XXXX.zip

四、认识shell
shell相关指令
1.命令行解析器。
2.shell解析器版本:sh、csh、ksh、bash
3.shell、内核、硬件、用户之间的关系:*****
1)用户从命令行提示终端输入命令或者按键,提交给shell。
2)shell将命令转换为内核可以识别的指令。
3)内核驱动硬件设备实现对应指令功能,将执行结果提交给shell。
4)shell将反馈的结果解释提交给用户识别。
- shell的特殊字符*****
(1)通配符
*:匹配任意长度字符
(2)管道 |
定义:将一个命令的输出作为另一个命令的输入
cat test.c | wc -l
cat -n test.c | grep "hello"
ps -aux | grep "a.out"
(3)wc
wc -l 文件名:查看文件的行数
wc -w 文件名:查看文件单词个数
wc -c 文件名:文件字符个数
wc -m 文件名:文件大小
(4)grep
查询文件中的字符串
grep “字符串” 文件名
grep -n “字符串” 文件名 :显示行号
printf man 3 printf
printk
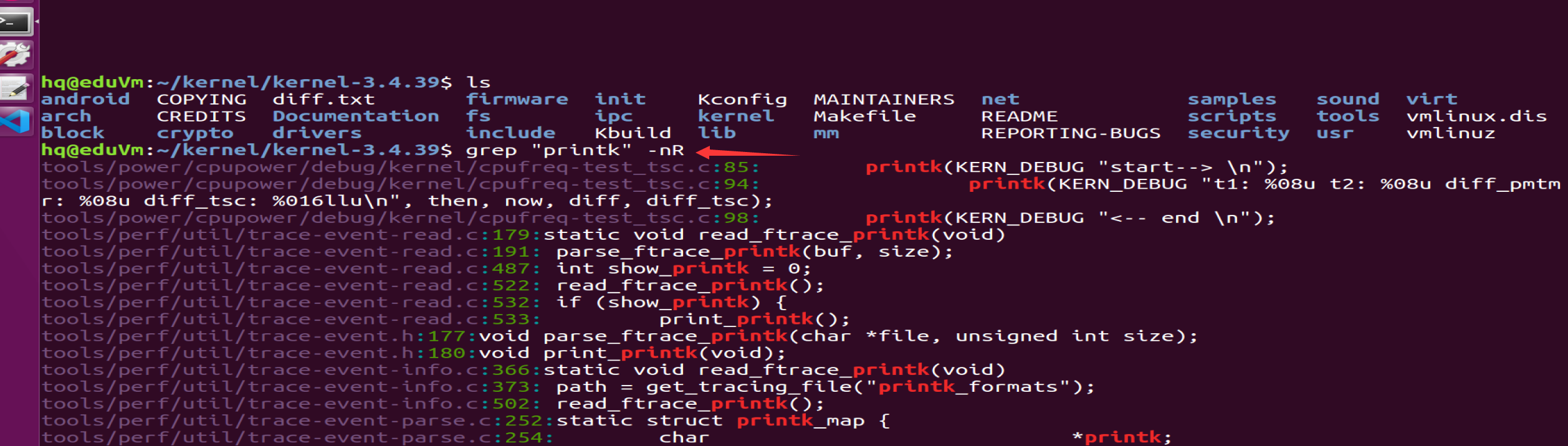
eg:grep "printk" * -nR
printf ->man 3 printf
printk ->在Linux内核里搜:grep "printk" * -nR
五、输入输出重定向
(1)> file
将file重定向为输出源,新建模式
.a.out >file
(2)2>file
将输出的信息重定向到file文件中(信息包含:错误信息)
gcc test.c 2>file
(3)>>file
将file重定向为输出源,追加模式
(4)< file
将file文件重定向为输入源
wc -l <file;
六、命令置换符 ``
在Esc键下(不是单引号), 将一个命令的输出作为另一个命令的参数。
如:
echo "user is whoami" 显示user is Linux
echo "Today is date" 显示Today is ......
(可以写成这样:echo "Today is $(date)")
echo $HOME
printenv:显示Linux下自带的环境变量,当命令行输入echo $HOME时候,就会出现/home/h.
七、Shell基本系统命令
(1)man
man man:查看man手册功能
第一章节:shell命令
第二章节:系统调用
第三章节:C库(库函数)
(2)sudo passwd 用户名
修改用户密码
(3)su 切换用户
su: 默认切换到root
Linux下面一切皆文件。
sudo su 用户名:切换到指定用户
exit :退出切换的用户
(4)date 查看系统的日期
八、文件系统命令
(1)文件系统类型
1)磁盘文件系统:硬盘、U盘
文件系统的格式有:
ext、ext2、ext3、ext4、vfat、fat32...
2)网络文件系统: (鼠标-》文件)
nfs服务、samba (socket)
3)虚拟文件系统: 用户 shell 内核
tmpfs
作用:tmpfs(临时)如果你的虚拟机出现
(2)file 文件名
查看文件的类型(源文件、可执行文件)
(3)rm -f
强制删除,文件存不存在都会删除
(4)cat 文件名
将文件内容输出到终端
cat -n 文件名:将文件内容及行号输出到终端
(5)head 文件名
默认输出文件内容前10行
head -num 文件名:将前num行内容输出到终端
(6)tail 文件名
默认输出文件内容最后的10行
tail -num 文件名 :将后num行内容输出到终端
(7)find 文件的查找
find 路径 -name “文件名”
find ./ -name “1.txt”
//从当前目录下搜索1.txt文件
(8)echo 字符串
把字符产输出到终端
echo -n 字符串 :不换行
(9)df -h
查看虚拟机硬盘空间使用情况
(10)lscpu
显示CPU信息
(11)free -g
显示内存的使用情况
day4
一、gcc 的编译步骤
(源码->可执行程序)
机器里面跑的是可执行程序
编译:gcc xxx.c
源码->可执行程序(四步)
(0 1)机器语言->汇编语言->高级语言
硬件+ 机器语言 + 汇编语言+ 高级语言;
1)预处理:处理与#号相关的代码(展开头文件)
gcc -E xxx.c -o xxx.i
2)编译:检查语法错误;如果语法有误则报错,如果语法没错则编译成汇编语言
gcc -S xxx.i -o xxx.s
3)汇编:将汇编语言解析成二进制文件(并非纯粹的二进制文件)
gcc -c xxx.s -o xxx.o
4)链接 :将目标文件链接库文件生成机器能够识别的二进制文件
gcc xxx.o -o xxx
gcc的选项
-c,只编译,不连接成为可执行文件,编译器只是由输入的.c等源代码文件生成.o为后缀的目标文件,
通常用于编译不包含主程序的子程序文件。
-o output_filename,确定输出文件的名称为output_filename,同时这个名称不能和源文件同名。
如果不给出这个选项,gcc就给出预设的可执行文件a.out。
-g,产生符号调试工具(GNU的gdb)所必要的符号资讯,
要想对源代码进行调试,我们就必须加入这个选项。
-O,对程序进行优化编译、连接,采用这个选项,整个源代码会在编译、
连接过程中进行优化处理,这样产生的可执行文件的执行效率可以提高,
但是,编译、连接的速度就相应地要慢一些。
-O2,比-O更好的优化编译、连接,当然整个编译、连接过程会更慢。
-Idirname,将dirname所指出的目录加入到程序头文件目录列表中,是在预编译过程中使用的参数。
-Ldirname,将dirname所指出的目录加入到程序函数档案库文件的目录列表中,
二、分文件
头文件包含内容
整个工程包含:
main.c -->main
xxxx.c -->多个.c(不同功能函数接口 .c、.c)
单独的文件中,只要调用(使用),就需要声明。
.h :头文件包含的内容:
1.包含其他头文件
2.函数声明
3.构造数据类型(构造结构体类型)
4.宏定义
5.重定义名
6.全局变量
引用头文件时<>和“”的区别
引用头文件:
- 库里头文件:
#include <stdio.h>
- 自定义头文件:
#include “add.h”
- C语言中include <> 和include“”的区别
include <> :引用的是编译器的类库路径里面的头文件,用于引用系统头文件。
include "":引用的是你程序目录的相对路径中的头文件,如果在程序目录没有找到引用的头文件则到编译器的类库路径的目录下找该头文件,用于引用用户头文件。
3.所以:引用系统头文件,两种形式都会可以,
include<>效率高,引用用户头文件,只能使用include ““
三、条件编译
编译器根据条件的真假决定是否编译相关的代码
一、根据宏是否定义,其语法如下:
#ifdef
……
#else
……
#endif
#include <stdio.h>
//#define IFDEF
int main(int argc, const char *argv[])
{
#ifdef IFDEF
printf("1");
#else
printf("2");
#endif
return 0;
}
二、根据宏的值是否为真,其语法如下:
#if
…
#else
…
#endif
#include <stdio.h>
int main(int argc, const char *argv[])
{
#if 1
printf("1");
#else
printf("2");
#endif
return 0;
}
三、防止头文件被重复包含
根据宏是否定义,作用:防止头文件重复包含
#ifndef <macro>
#define <macro>
....
#endif
#ifndef _ADD_H_
#define _ADD_H_ //add.h
struct stu{
int a;
char c;
};
int add(int a,struct stu st);
#endif
#include "add.h"
int add(int a,struct stu st ){ //add.c
return a;
}
#ifndef _CHENG_H_
#define _CHENG_H_
#include "add.h"
int cheng(int a,struct stu s); //cheng.h
#endif
#include "add.h"
int cheng(int a,struct stu s){ //cheng.c
return a;
}
#include <stdio.h>
#include "add.h"
#include "cheng.h"
int main(int argc, const char *argv[]) //main.c
{
struct stu d;
struct stu c;
printf("%d\n",add(40,d));
printf("%d\n",cheng(2,c));
return 0;
}
四、make工具
(一)Makefile理论内容
1.工程管理器,顾名思义,是指管理较多的文件 Make工程管理器也就是个“自动编译管理器”,这里的“自动”是指它能构根据文件时间戳自动发现更新过的文件而减少编译的工作量,同时,它通过读入Makefile文件文件的内容来执行大量的编译工作。
2.make工具的作用 当项目中包含多个c文件,但只对其中1个文件进行了修改,那用gcc编译会将所有的文件从头编译一遍,这样效率会非常低;所以通过make工具,可以查找到修改过的文件(根据文件时间戳),只对修改过的文件进行编译,这样大大减少了编译时间,提高编译效率。
3.Makefile是Make读入的唯一配置文件
(二) Makefile的第一种写法
- 4.Makefile的编写格式 格式为:
- 目标:依赖 命令
a.out:add.o main.o gcc add.o main.o -o a.outadd.o:add.c gcc -c add.c -o add.omain.o:main.c gcc -c main.c -o main.o.PHONY:cleanclean: rm *.o- 目标实现,需要通过依赖文件实现,可以只有目标没有依赖。
- make执行Makefile文件内的指令,执行"make"默认执行的是第一个目标对应的命令。若想执行剩余的目标,需要 "make 目标"执行。.PHONY:clean -->.PHONY声明一个伪命令。若之前的目标中有生成可知执行文件名为clean。执行“make clean”时,make会认为clean目标已实现。不执行clean目标对应的指令,用.PHONY声明后,make认为clean是一个指令,“make clean”时会执行clean指令对应的命令。
(三)Makefile的第二种写法
.变量
$HOME ($:表示取值)
HOME=/home/hq
1)预定义变量
CC 默认值为cc,与gcc同
RM 默认值为rm -f
CFLAGS 无默认值,一般为c编译器的选项
OBJS 一般为目标文件xx.o
CC=gcc
OBJS=add.o main.o
CFLAGS=-c -g -O
add:$(OBJS)
$(CC) $(OBJS) -o add
add.o:add.c
$(CC) $(CFLAGS) add.c -o add.o
main.o:main.c
$(CC) $(CFLAGS) main.c -o main.o
.PHONY:clean
clean:
rm *.o add
2)机器上面运行的是源码?还是可执行文件?
可执行文件
3)在虚拟机上面编写代码,在虚拟机上面执行代码
(编写代码和执行代码在同一个架构上)
4)架构:
win:X86
公司的产品:ARM架构;
5)在X86架构上编写和编译代码,在ARM架构上执行代码
交叉开发(编写代码、编译代码和执行代码的架构不一样)
编译代码的时候要使用交叉编译工具链去编译代码
gcc 交叉编译工具链->arm-none-linux-gnueabi-gcc
(四)Makefile的第三种写法
自动变量:
$< 第一个依赖文件的名称
$@ 目标文件的完整名称
$^ 所有不重复的目标依赖文件,以空格分开
%.o:%.c :表示所有的.o依赖与所有的.c
CC=gcc
OBJS=add.o main.o
CFLAGS=-c -g -O
add:$(OBJS)
$(CC) $(OBJS) -o $@
$(OBJS):%.o:%.c
$(CC) $(CFLAGS) $^ -o $@
.PHONY:clean
clean:
rm *.o add
学生管理系统要求
学生管理系统:(3个.c .h -》Makefile)
项目 ——》第一个项目(繁琐、乱、赘余等)
注意:自己完成
(提升项目管理思路)
作用:
1:综合知识点
2:提升代码逻辑思维
3:提升修改bug的能力
day5
一、嵌入式系统(把软件嵌入到硬件)
以计算机应用为中心,软硬件可裁剪(根据需求可修改),对功耗、体积、性能等都有一定要求的专用计算机系统。
手机:硬件+系统(安卓、鸿蒙、iOS)
安卓(Android):是一种基于Linux内核(不包含GNU组件)的自由及开放源代码的操作系统。
硬件+uboot+Linux内核+根文件系统(Linux)+ 应用层+app
电脑:
硬件+BIOS(裸机代码(小)初始化部分硬件:初始化USB作用)
+操作系统(系统(U盘) USB驱动(硬件在使用之前需要进行初始化)win10、win11)->(win内核+根文件系统+app)
32-》裸机
ARM-》带操作系统
硬件+uboot+Linux内核+根文件系统(Linux)+ 应用层+app
(系统移植)
不同操作系统的内核:
windows NT
android linux
macOs ios unix
ubuntu linux
redhat linux
二、linux 特点
- linux开源,免费使用,内核源码开源,针对商业非免费。
- linux多用户、多任务、分时操作系统,是软硬件可裁剪的操作系统。
- linux可以移植到不同的硬件设备上,支持的硬件比较多。
三、linux体系架构(内核结构)
linux体系架构(内核结构)
while(1); 命令行(ctrl+c:把正在运行的进程给杀死)
ctrl+c ->Linux底层知道(信号)
应用层:app shell命令
| |
c库 |shell解析器
| |
---------系统调用-------------------
内核层:五大功能
进程管理 ->ps aux
内存管理 ->内存图(static->.data ;.bss)
设备管理 ->Linux操作系统下一切皆文件(字符设备、块设备 -》open)(/dev/input/mouse1)
sudo cat mouse1:查看鼠标文件的移动
文件管理
/ -->根文件系统下的每个文件都有自己特定功能
网络管理 (网卡设备(socket))->7种(bcd-lsp)
硬件层:鼠标 键盘
硬件怎么能使用(必须要有驱动,驱动写在内核层)
四、硬链接和软连接
1. 软链接 (符号链接)
ln -s (符号链接) 利用文件的路径名来建立的,最好从绝对路径开始(增加可移植性)
格式: ln -s 被链接的文件(源文件) 生成的链接文件(目标文件)
ln -s /home/hq/Desktop/test/1.c softlink.txt
- 软链接的属性是l 相当于快捷方式
2)源文件删除,链接断开,建立源文件之后重新链接
3)软链接可以链接目录
4)双方修改内容都变化,互相影响
2.硬链接 ln
根据linux系统分配给文件的inode号(物理编号:inode)(物理地址、物理机)
(ls -i)进行建立的,没办法跨越文件系统
格式: ln 被链接的文件(源文件) 生成的链接文件(目标文件)
1)硬链接的属性是相当于生成一个副本 起别名
2)源文件删除链接依然存在
3)不能链接目录
4)修改内容都变化,互相影响
五、shell脚本编程
- shell-->解析器:sh ksh csh bash
- shell脚本:本质-->shell命令的有序集合
- shell脚本编程:
将shell命令按照一定的逻辑顺序实现指定功能,放到一个文件中文件叫脚本文件,后缀.sh,可以直接执行, 不用编译。
- shell脚本语言-->解释型语言
- 写一个shell脚本文件步骤:
1.创建一个脚本文件
touch xxx.sh
2.将脚本文件权限修改为可执行
chmod 777 xxx.sh
3.编辑脚本内容
vi xxx.sh
4.执行脚本文件
./xxx.sh 或者 bash xxx.sh
六、shell变量
shell中允许建立变量存储数据,但是不支持数据类型,(如:整型、字符、浮点类型),所有赋值给变量的值都解释为一串字符。
1、变量的定义格式
变量名=值
val=10
注:等号两边都不能有空格。
CC=gcc
取shell变量的值:$变量名
2、shell变量的分类
(1)环境变量 printenv 或 env
HOME=/home/hq
(2)用户自定义变量
在shell编程中通常定义的变量名用大写,变量的调用:
$变量名
Linux Shell/bash从右向左赋值
如:Y=yy
X=$Y
echo $X //输出yy
使用unset命令删除变量的赋值
如:X=xx
unset X
echo $X //没有任何输出
(3)位置变量或命令行参数
$0 执行的脚本名 argv[0] ->a.out argv[1] ->"hello"
$1-$9、${10}-${n} 命令行空格传的参数
$# 命令行参数个数,除$0
$@ $* 遍历输出命令行参数内容
(4)预定义变量
$? 获取的是上一句命令是否正确执行的结果, 0:真 非0:为假
$$ 获取进程pid
七、shell中的语句
1)说明性语句
以#号开始到该行结束,不被解释执行(注释)
#!/bin/bash
告诉操作系统使用哪种类型的shell执行此脚本文件
2)功能性语句
任意的shell命令、用户程序或其它shell程序。
3)结构性语句
条件测试语句、多路分支语句、循环语句、循环控制语句等
1、功能性语句
(1)read (类似c中scanf)
从终端获取值赋值给变量。
格式:read 变量名1 变量名2 ...
加提示语句:read -p “提示字符串” 变量名1 变量名2 ...
注:把终端读入空格隔开的第一个单词赋值给第一个变量,第二个单词赋值给第二个变量,依次类推赋值,剩余所有单词赋值给最后一个变量。
#!/bin/bash
//read -p "please input:" a b c //read不能自动换行
echo "please input:"
read a b c
echo $a //echo可以自动换行
echo $b
echo $c
(2)expr
算术运算命令expr主要用于进行简单的整数运算,
包括加(+)、减(-)、乘(*)、整除(/)和求模(%)等操作
如:expr ( 12 + 3 ) * 2
NUM=expr 12 + 3 :将运算的结果赋值给变量
注意:
1)运算符左右两侧必须有空格
2)*和()必须加转义字符,* 、 ( )
3)expr语句可以直接输出运算结果
#!/bin/bash
expr \( 12 + 3 \) \* 5
NUM=`expr \( 12 + 3 \) \* 5`
echo $NUM
输出结果
75
75
(3)let
在运算中不能有空格、运算结果需要赋给一个变量、变量参与运算的过程不用加$取值
如:
Let NUM=(a+b)*c
#!/bin/bash
read a b c
let NUM=(a+b)*c
echo $NUM
Let r+=1 // ((r++))
(4)test
test语句可测试三种对象:
字符串 整数 文件属性
每种测试对象都有若干测试操作符
1)字符串的测试:(等号两边加空格)
s1 = s2 测试两个字符串的内容是否完全一样
真为0,假为1
echo $?
#!/bin/bash
A="hello"
B="hello"
test $A = $B //注意等号两边的空格
echo $?
s1 != s2 测试两个字符串的内容是否有差异
-z s1 测试s1 字符串的长度是否为0
-n s1 测试s1 字符串的长度是否不为0
2)整数的测试:
a -eq b 测试a 与b 是否相等
a -ne b 测试a 与b 是否不相等
a -gt b 测试a 是否大于b
a -ge b 测试a 是否大于等于b
a -lt b 测试a 是否小于b
a -le b 测试a 是否小于等于b
3)文件属性的测试;
-d name 测试name 是否为一个目录
-f name 测试name 是否为普通文件
-e name 测试文件是否存在
#!/bin/bash
test -d ./1.sh
echo $?
test -f ./1.sh
echo $?
test -e ./1.sh
echo $?
输出结果:
1
0
0
2、结构性语句
(1)if…then…fi
1)基本结构:
if 表达式
then
命令表
fi
如果表达式为真, 则执行命令表中的命令; 否则退出if语句, 即执行fi后面的语句。
if和fi是条件语句的语句括号, 必须成对使用; 命令表中的命令可以是一条, 也可以是若干条。
例如:
#!/bin/bash
if test -e $1 或者if [ -e $1 ] //注意括号内空格
then
echo $1 exist
else
echo $1 inexist
fi
输入:./1.sh a.out
输出:a.out exist
输入:./1.sh a.out1
输出:a.out inexist
2)分层结构1:
if 表达式
then
命令表1
else
命令表2
fi
例如:vi if2.sh
if [ $# -ne 1]
then
echo "ne"
exit
fi
分层结构2:
if 表达式1
then
命令表1
elif 表达式2
then
命令表2
elif 表达式3
then
命令表3
else
命令表4
fi
#!/bin/bash
read a b
if [ $a -eq 1 ]
then
echo $a
elif [ $b -eq 2 ]
then
echo $b
else
echo other
fi
3)嵌套结构:
if 表达式
then
命令表1
else
if 表达式
then
命令表
fi
fi
注意:
如果表达式为真, 则执行命令表中的命令; 否则退出if语句, 即执行fi后面的语句。
if和fi是条件语句的语句括号, 必须成对使用;命令表中的命令可以是一条, 也可以是若干条。
练习1:利用if语句实现找出三个数中最大的数
#!/bin/bash
read a b c
if [ $a -gt $b ]
then
if [ $a -gt $c ]
then
echo $a is max
fi
elif [ $b -gt $c ]
then
echo $b is max
else
echo $c is max
fi
(2)case...esac
case 字符串变量 in
模式1)
命令表1
;;(相当于C语言中的break)
模式2)
命令表2
;;
……
*)
命令表n
;;
esac
注意:
1)case语句只能检测字符串变量
2)命令表以单独的双分号行结束,退出case语句
3)模式 n常写为字符* 表示所有其它模式
4)case匹配项中可以存在多个模式,每种模式之间用|隔开
例如:
vi case1.sh
#!/bin/bash
echo "please choose (yes|no)?"
read R
case $R in
yes|y)
echo "yes"
;;
no)
echo "no"
;;
*)(相当于C语言中的default,所以下面的两个分号可以去掉
(C语言中的default中的break也是可以省略的。))
echo "wrong"
;;
esac
当多种放一起的时候,只需要输出一条提示语句时候,这样写:
#!/bin/bash
echo -n "please choose (yes|no)?"
read R
case $R in
yes | Yes | y |Y )(当多种放一起的时候,只需要输出一条提示语句时候)
echo "yes"
;;
no)
echo "no"
;;
*)
echo "other"
;;
esac
#!/bin/bash
read R
case $R in
yes|y)
echo $R
;;
no|n)
echo $R
;;
*)
echo other
;;
esac
补充:
逻辑运算符的书写格式:
|| :逻辑或
[ 表达式1 ] || [ 表达式2 ]
[ 表达式1 -o 表达式2 ]
&& :逻辑与
[ 表达式1 ] && [ 表达式2 ]
[ 表达式1 -a 表达式2 ]
! :逻辑非
[ ! 表达式 ]
练习:学生成绩管理系统,用shell中的case实现
90-100:A
80-89:B
70-79:C
60-69:D
<60:不及格
#!/bin/bash
read R
if [ $R -lt 0 -o $R -gt 100 ]
then
echo erro
exit
fi
let n=($R/10) // n=`expr $R / 10'
case $n in
9|10)
echo A
;;
8)
echo B
;;
7)
echo C
;;
6)
echo D
;;
*)
echo bujige
;;
esac
(3)for..do..done
格式:
for 变量名 in 单词表
do
命令表
done
变量依次取单词表中的各个单词,每取一次单词, 就执行一次循环体中的命令.
循环次数由单词表中的单词数确定. 命令表中的命令可以是一条, 也可以是由分号或换行符分开的多条。
for语句的几种书写格式:
1)for i in 1 2 3 4 do....done :
变量i从单词表中取值
例如:
一:
for I in 1 3 5 7 9 // for I in seq 1 2 10
(1是起始数字,10是终止数字,2是增加的数字,及两个数之间差值为2)
do
echo "$I"
done
这样就打印出了1 3 5 7 9
2)for i do...done:
变量i从命令行取值,可以省略in 单词表
3)for i in {1..10} do...done:
(大括号和数字之间不加空格)
变量i从1~10
4)for ((i = 0; i < 10; i++)) do...done
do
echo "I=$I"
done
#!/bin/bash
#for i in 1 2 3 4
#for i in `seq 1 3 10`
#for i in {1..10}
for ((i=0;i<10;i++))
do
echo $i
done
练习:
求1到100的和。
#!/bin/bash
sum=0;
for ((i=1;i<101;i++))
do
let sum=(sum+i)
done
echo $sum
shell脚本的死循环
(1) for((;;))
do
echo "for"
done
(2)
while true
do
echo "while"
done
(4)while..do..done
格式:
while 命令或表达式
do
命令表
done
while语句首先测试其后的命令或表达式的值,如果为真,就执行一次
然后再测试该命令或表达式的值,执行循环体,直到该命令或表达式为假时退出循环。写while的表达式时候,表达式与中括号之间加空格
#!/bin/bash
I=0
while [ $I -lt 5 ]
do
I='expr $I + 1'
echo "$I"
done
while [$I -lt 5]//改成while true 就是死循环了。
#!/bin/bash
i=0
while [ $i -lt 5 ]
do
let i=(i+1)
echo $i
done
#!/bin/bash
i=0
while [ $i -lt 5 ]
do
i=`expr $i + 1`
echo $i
done
练习二:1-10求和运算,用while写
1 #!/bin/bash
2 i=1
3 sum=0
4 while [ $i -lt 101 ]
5 do
6 let sum=(sum+i)
7 let i=(i+1)
8 done
9 echo $sum
版权归原作者 代码大魔王ㅤ 所有, 如有侵权,请联系我们删除。