
前言
flink安装部署有三种方式
- local:单机模式,尽量不使用
- standalone: flink自带集群,资源管理由flink集群管理,开发环境测试使用,不需要hadoop集群
- flink on yarn: 把资源管理交给yarn实现,计算机资源统一由Haoop YARN管理,生产环境测试,需要先启动hadoop集群。(这里分为可以继续细分三种方式 1.session mode 长久启动一个flink集群接收job,main 方法在客户端执行 2.per-job mode 每个任务启动一个flink集群,main 方法在客户端执行 3.application mode Application 模式为每个提交的应用程序创建一个集群,该集群可以看作是在特定应用程序的作业之间共享的会话集群,并在应用程序完成时终止 )
一、flink包选择以及下载
下载地址在下面
https://www.apache.org/dyn/closer.lua/flink/flink-1.17.0/flink-1.17.0-bin-scala_2.12.tgz
看flink适配的版本可以去看flink的版本说明,上flink官网
看这里的部署,yarn模式部署,这里可以看到要求hadoop最小的版本是多少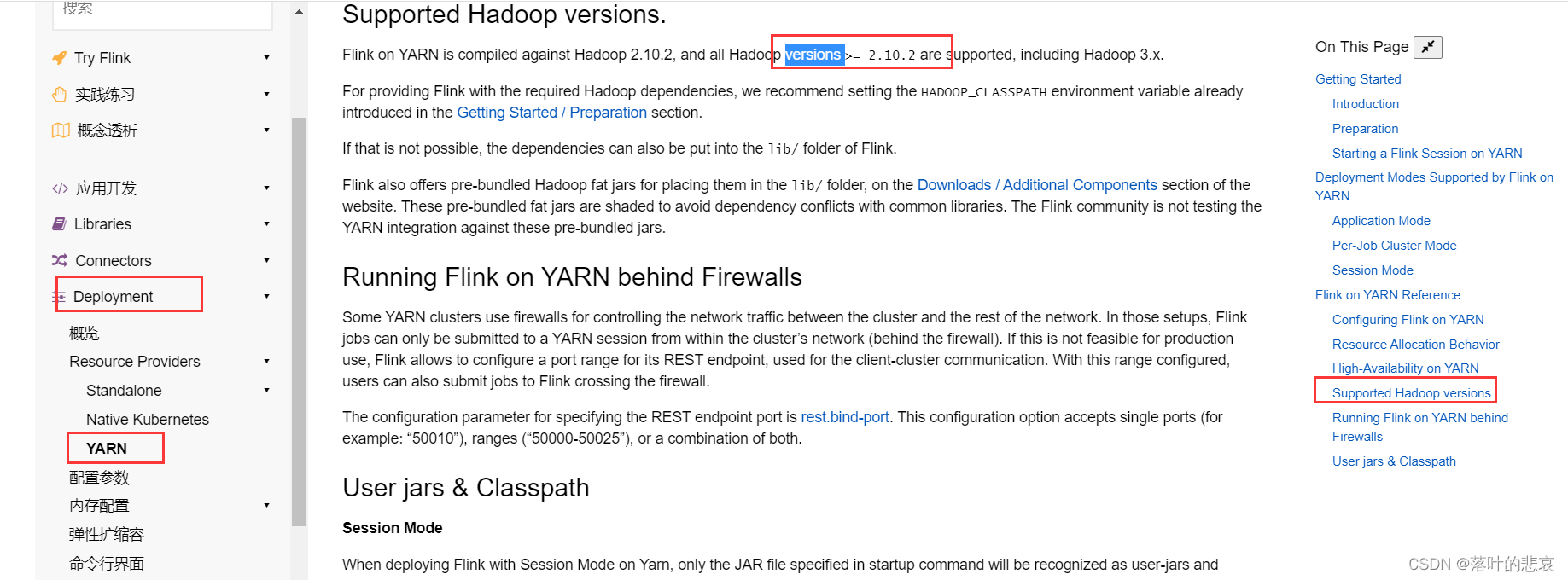
这里版本要求是大于2.10.2版本包括3.0版本,我的hadoop版本是满足要求的,直接安装这个最新的flink版本。
二、安装flink集群
因为我前面已经安装了hadoop集群,这里直接选择flink on yarn的安装方式,模式选择了session-mode方式,实际生产中使用per-job和application的模式可能会比较多,但是操作基本差不太多,就直接使用这种方式安装了。以下的操作需要集群每台机器都操作下,我这里
只是测试在hadoop1:192.168.184.129、hadoop2:192.168.184.130、hadooop3:192.168.184.131三台机器上部署。
2.1.上传压缩包到linux上
解压到你需要安装的目录
我的安装目录为/root/tools,这个可以自己定,执行以下命令
tar -zxvf flink-1.17.0-bin-scala_2.12.tgz
解压完成后得到flink安装目录
/root/tools/flink-1.17.0
2.2 修改linux环境变量
修改 /etc/profile文件,在文件末尾加上
export HADOOP_CLASSPATH=`hadoop classpath`
export FLINK_HOME=/root/tools/flink-1.17.0
export PATH=$PATH:$FLINK_HOME/bin
刷新环境变量
进入hadoop安装目录执行脚本,这里的hadoop安装就不在这里说了
可以去文章看。hadoop集群安装
./hadoop.sh start
2.3 启动flink集群
进入
/root/tools/flink-1.17.0 目录执行以下指令
./bin/yarn-session.sh --detached
出现以下日志说明启动成功。
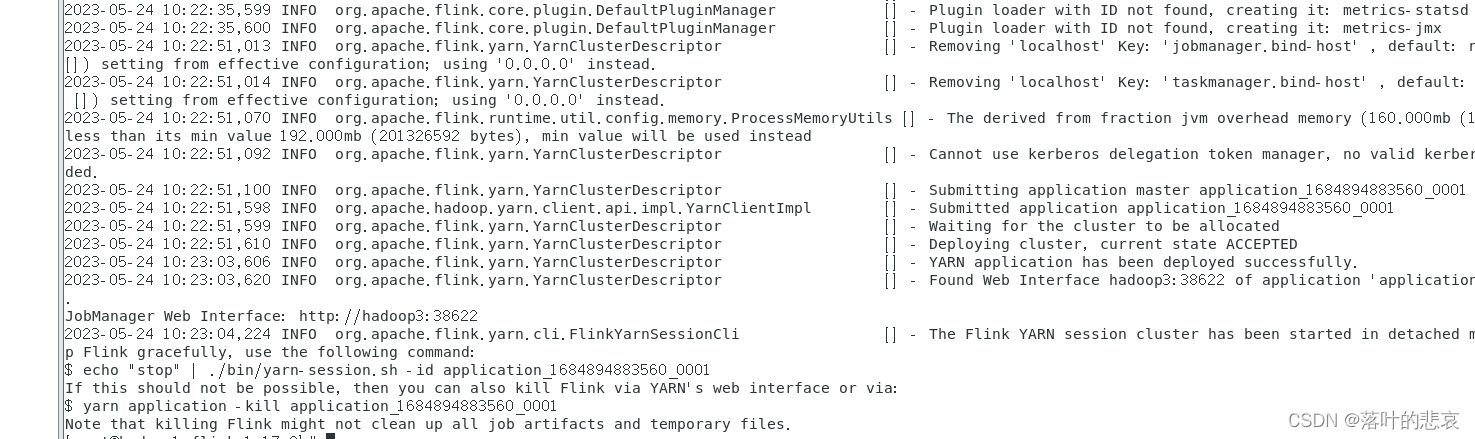
flink集群关闭可以使用指令
./bin/yarn-session.sh -id application_1684894883560_0001
如果上面的停不了使用指令,id在hadoop上有显示,copy下就行。
yarn application -kill application_1684894883560_0001
2.4 查看集群
http://hadoop2:8088/cluster/nodes
登录hadoop集群管理页面,可以看到启动的flink集群。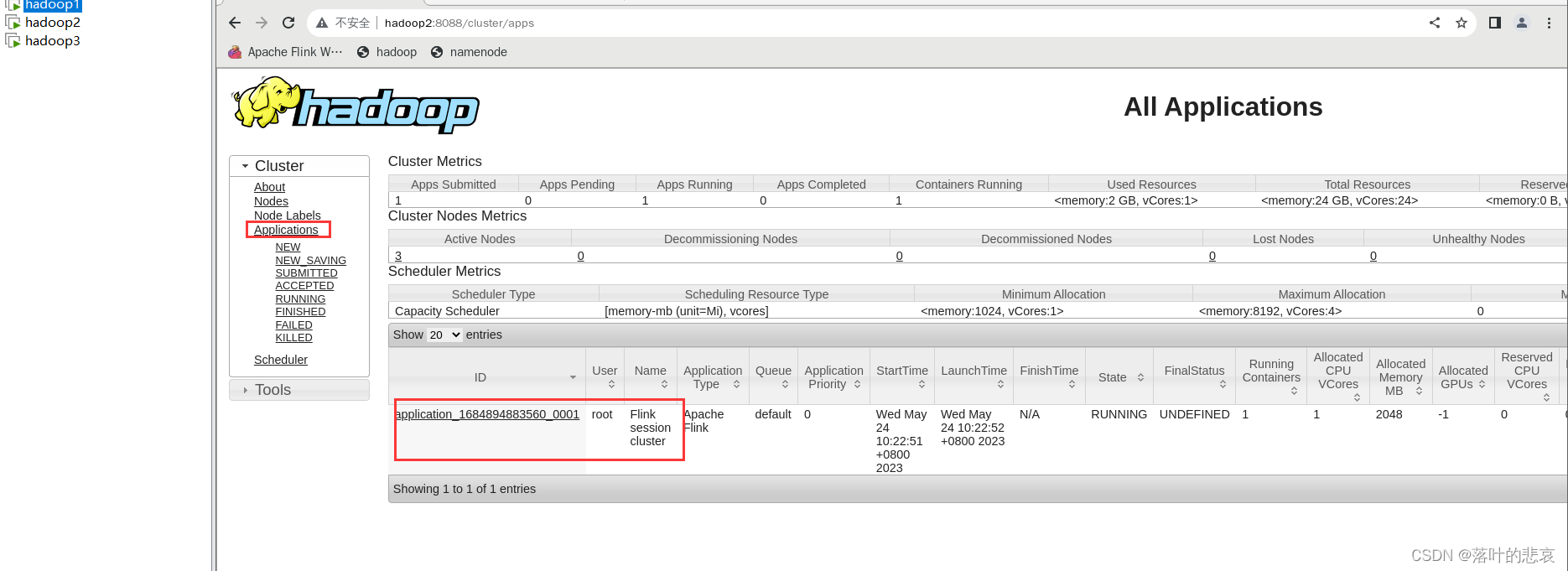
点击右边的flink集群管理界面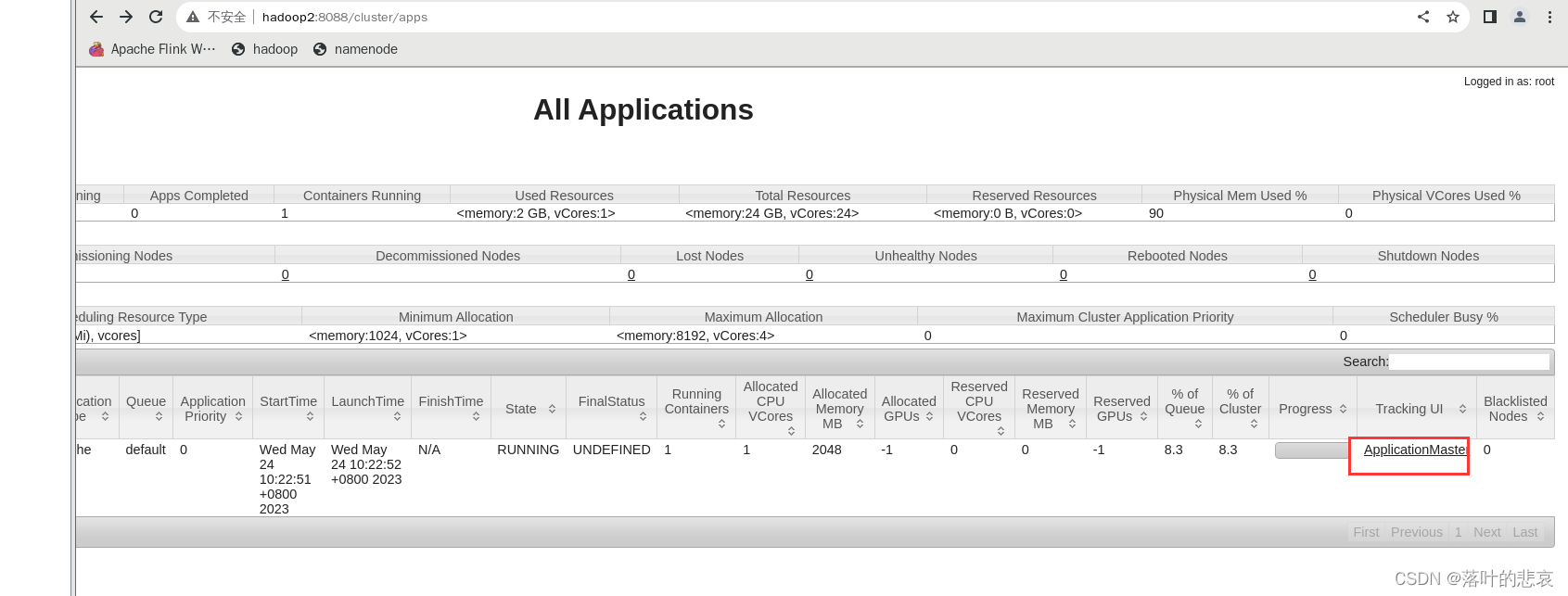
flink集群管理界面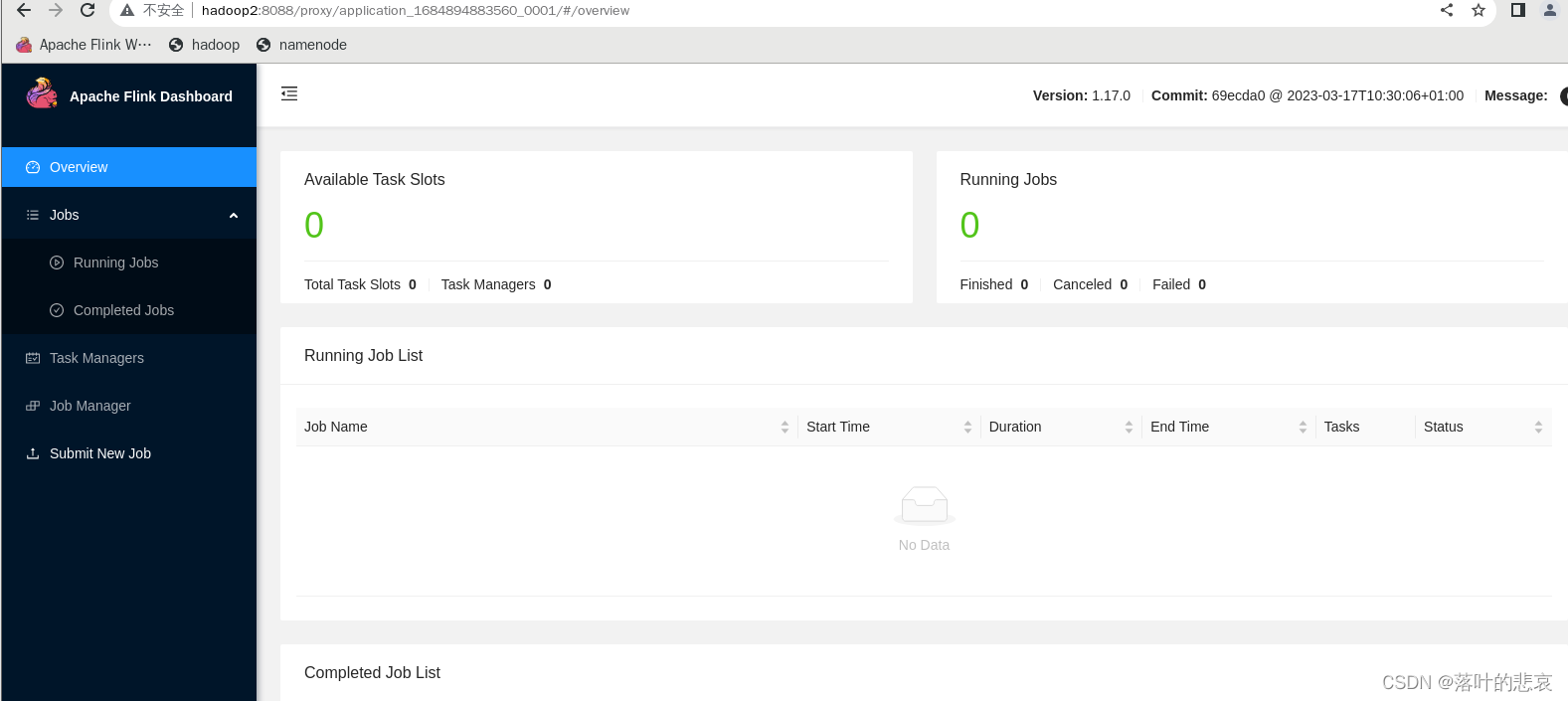
三、测试
3.1 提交flink的测试job看看结果
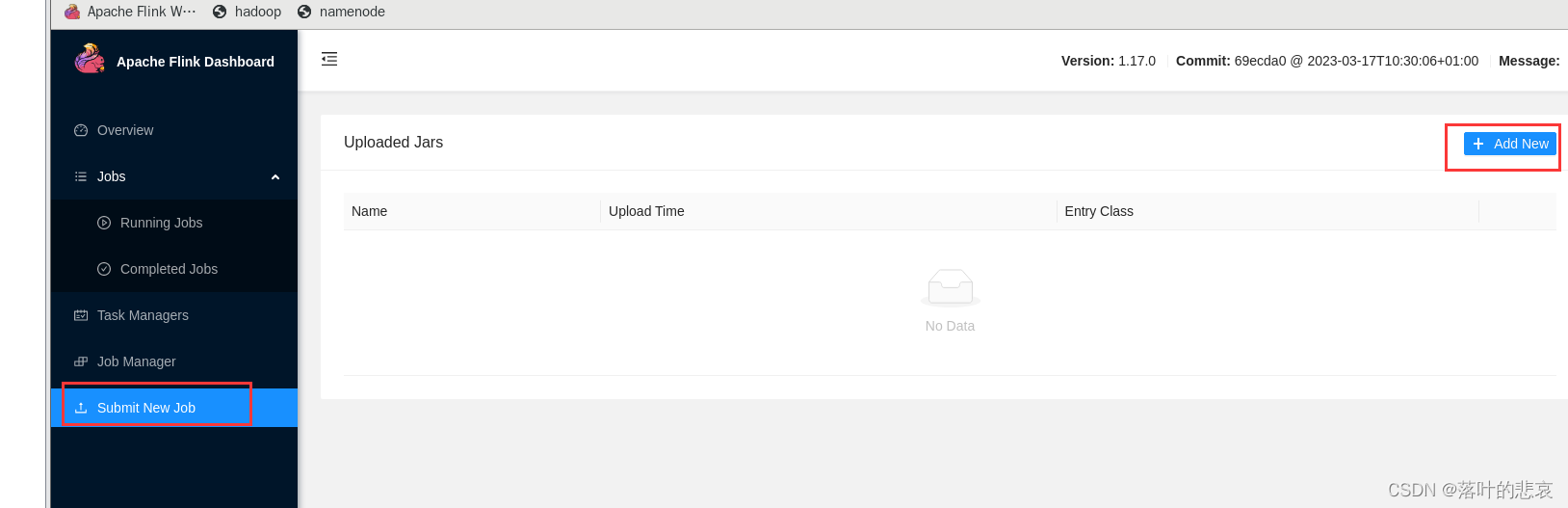
选择到wordcount.jar看看执行结果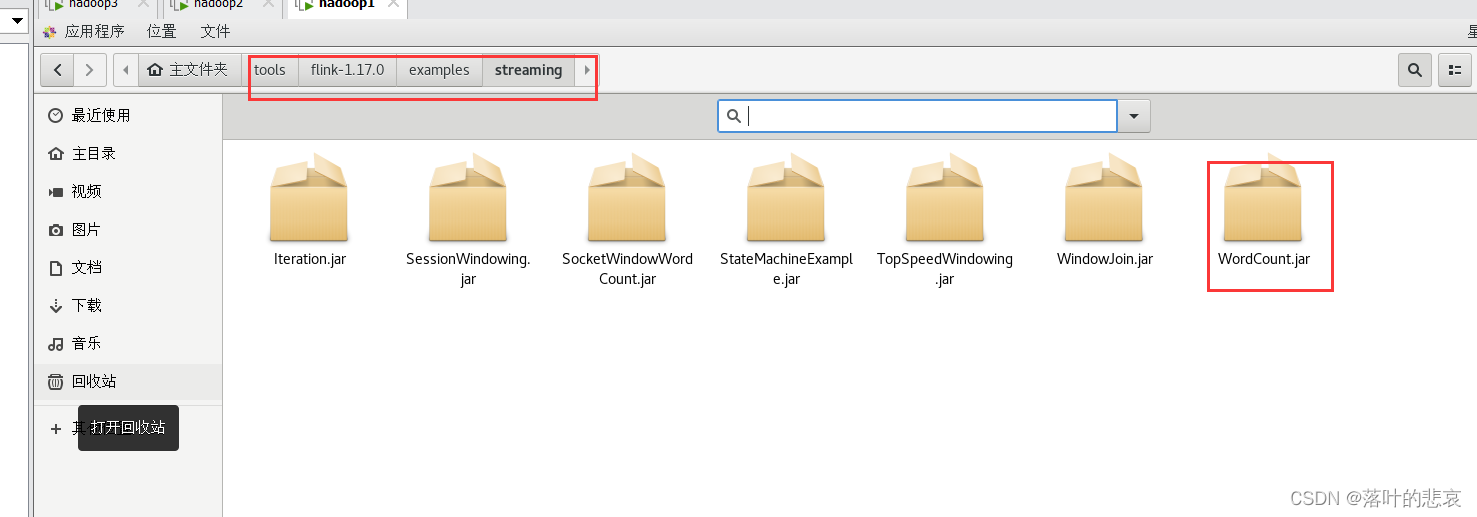
提交任务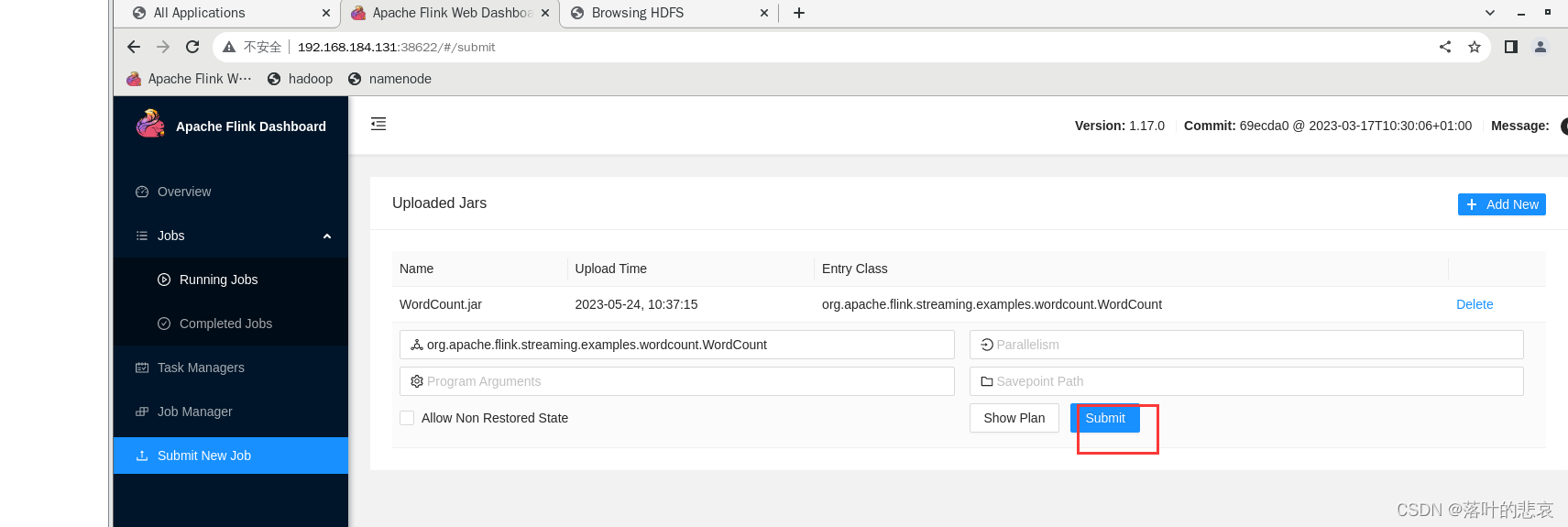
查看任务执行情况。

这里可以看到任务已经执行完毕了,这里的例子没找到输出在哪看,下个博客自己弄一个jar去测试下。
总结
实践了下,hadoop集成flink,操作不难,不对的可以指出,一起进步。
版权归原作者 落叶的悲哀 所有, 如有侵权,请联系我们删除。