
文章目录
一. Hudi集成Hive概述
Hudi 源表对应一份 HDFS数据,通过Spark,Flink组件或者Hudi CLI,可以将Hudi表的数据映射为Hive外部表,基于该外部表,Hive可以方便的进行实时视图,读优化视图以及增量的查询。
二. Hudi集成Hive步骤
以 Hive 3.1.2、hudi 0.12.0 为例。
2.1 拷贝jar包
2.1.1 拷贝编译好的hudi的jar包
将hudi-hive-sync-bundle-0.12.0.jar 和 hudi-hadoop-mr-bundle-0.12.0.jar 放到hive节点的lib目录下
cd /home/hudi-0.12.0/packaging/hudi-hive-sync-bundle/target
cp ./hudi-hive-sync-bundle-0.12.0.jar /home/apache-hive-3.1.2-bin/lib/
cd /home/hudi-0.12.0/packaging/hudi-hadoop-mr-bundle/target
cp ./hudi-hadoop-mr-bundle-0.12.0.jar /home/apache-hive-3.1.2-bin/lib/
2.1.2 拷贝Hive jar包到Flink lib目录
将Hive的lib拷贝到Flink的lib目录
cd $HIVE_HOME/lib
cp ./hive-exec-3.1.2.jar $FLINK_HOME/lib/
cp ./libfb303-0.9.3.jar $FLINK_HOME/lib/
https://nightlies.apache.org/flink/flink-docs-release-1.15/zh/docs/connectors/table/hive/overview/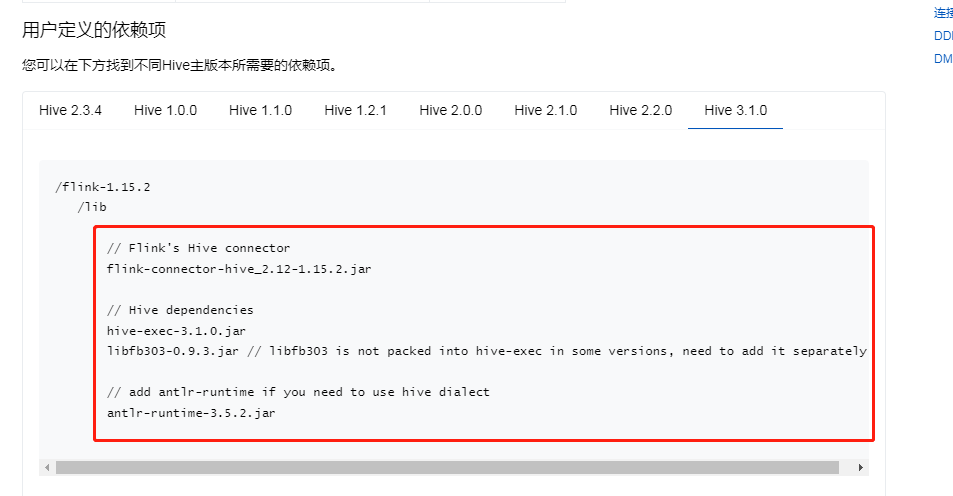
2.1.3 Flink以及Flink SQL连接Hive的jar包
wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-connector-hive_2.12/1.14.5/flink-connector-hive_2.12-1.14.5.jar
wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-hive-3.1.2_2.12/1.14.5/flink-sql-connector-hive-3.1.2_2.12-1.14.5.jar
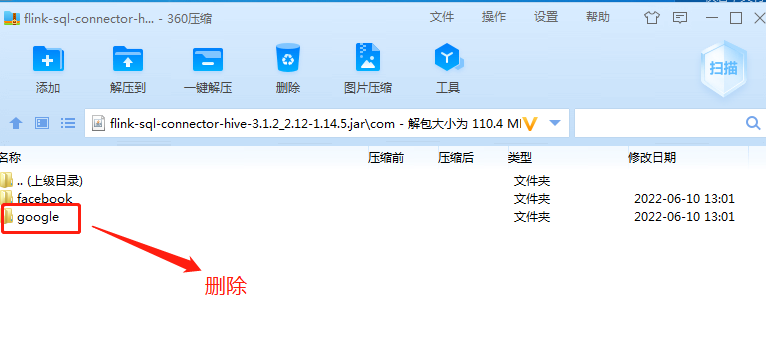
2.2 重启hive
拷贝jar包之后,需要重启hive
2.3 Flink访问Hive表
2.3.1 启动Flink SQL Client
# 启动yarn session(非root账户)
/home/flink-1.14.5/bin/yarn-session.sh -d 2>&1 &
# 在yarn session模式下启动Flink SQL
/home/flink-1.14.5/bin/sql-client.sh embedded -s yarn-session
2.3.2 创建hive catalog
CREATE CATALOG hive_catalog WITH (
'type' = 'hive',
'default-database' = 'default',
'hive-conf-dir' = '/home/apache-hive-3.1.2-bin/conf'
);

2.3.3 切换 catalog
use catalog hive_catalog;

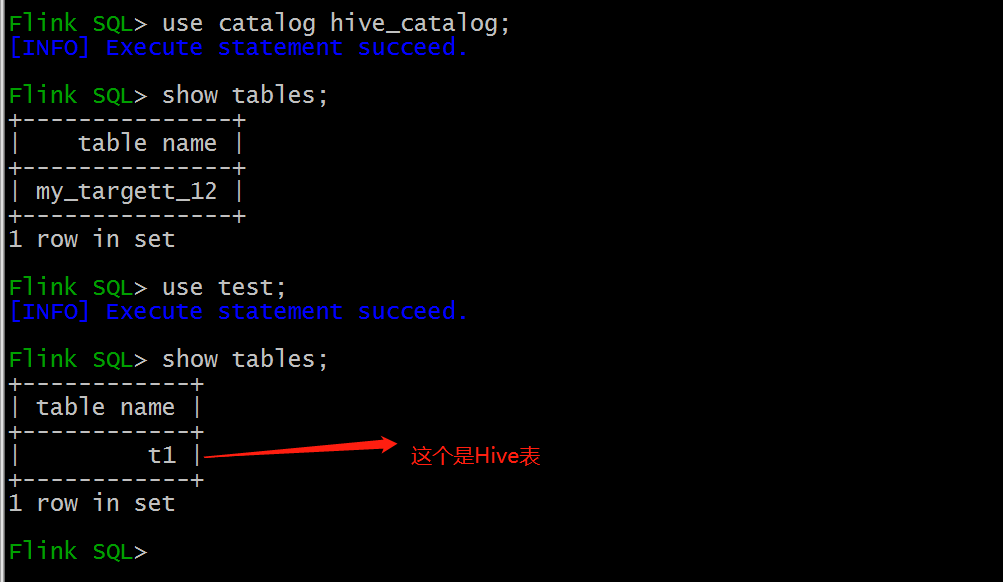
2.3.4 查询Hive表
use test;
show tables;
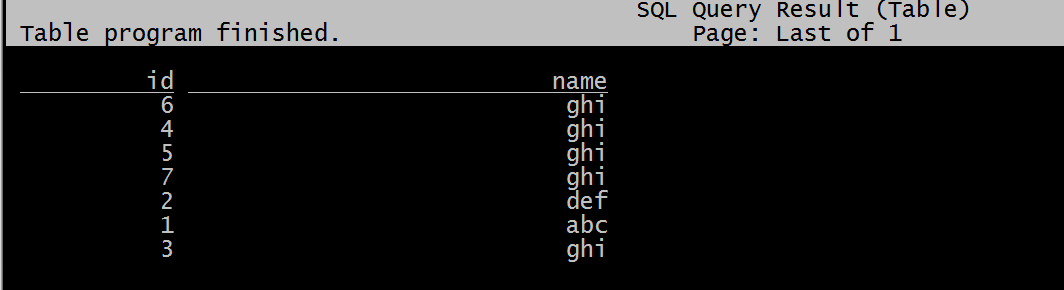
-- Flink可以直接读取hive表
select * from t1;
2.4 Flink 同步Hive
Flink hive sync 现在支持两种 hive sync mode,分别是 hms 和 jdbc 模式。 其中 hms 只需要配置 metastore uris; 而 jdbc模式需要同时配置 jdbc 属性和 metastore uris。
配置模板:
三. 实操案例(COW)
3.1 在内存中创建hudi表(不使用catalog)
代码:
-- 创建表
create table t_cow1 (
id int primary key,
num int,
ts int
)
partitioned by (num)
with (
'connector' = 'hudi',
'path' = 'hdfs://hp5:8020/tmp/hudi/t_cow1',
'table.type' = 'COPY_ON_WRITE',
'hive_sync.enable' = 'true',
'hive_sync.table' = 't_cow1',
'hive_sync.db' = 'test',
'hive_sync.mode' = 'hms',
'hive_sync.metastore.uris' = 'thrift://hp5:9083',
'hive_sync.conf.dir'='/home/apache-hive-3.1.2-bin/conf'
);
-- 只有在写数据的时候才会触发同步Hive表
insert into t_cow1 values (1,1,1);
测试记录:
Flink SQL运行记录: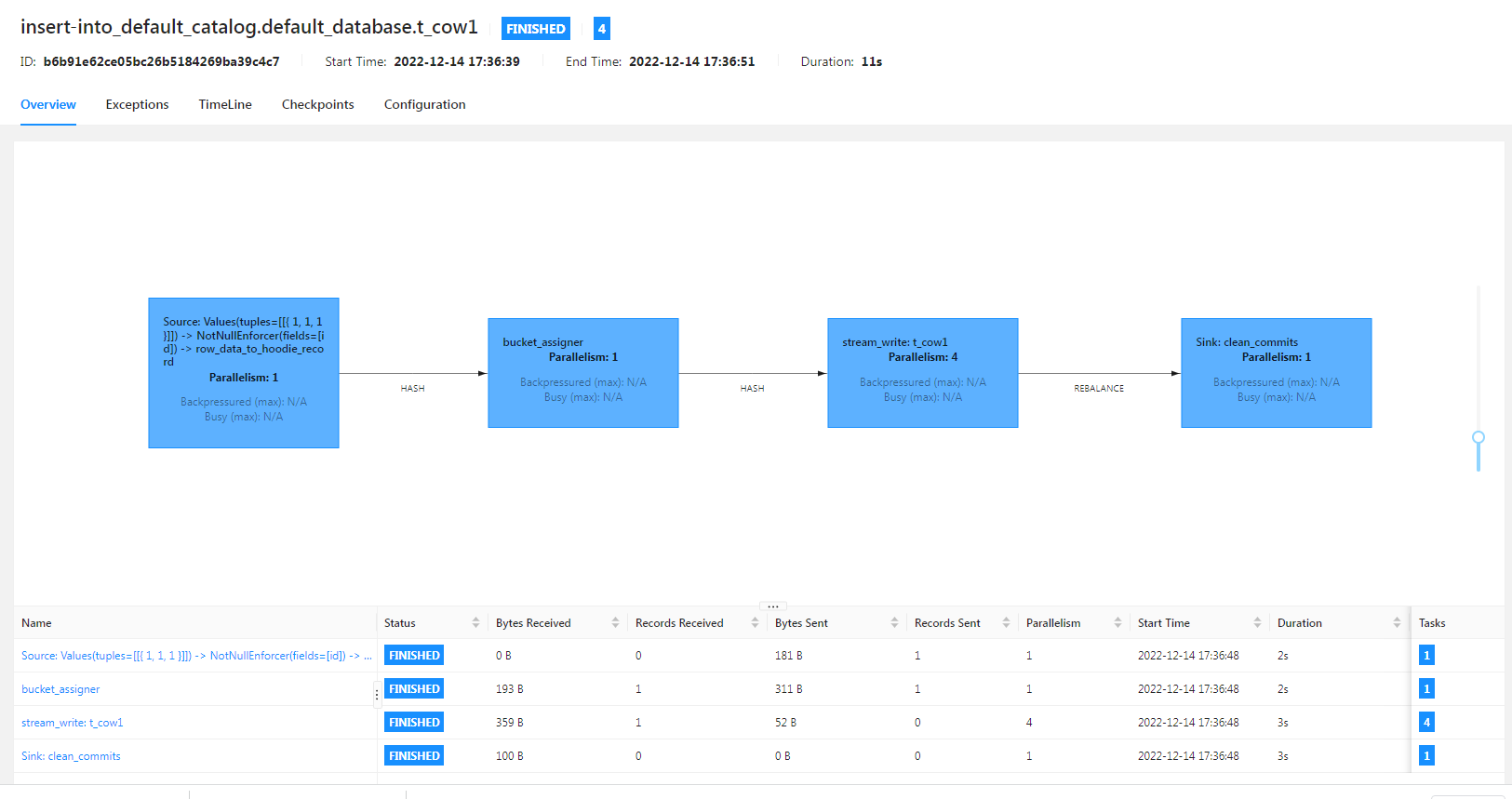
Hive的test库下面多了一个t_cow1 表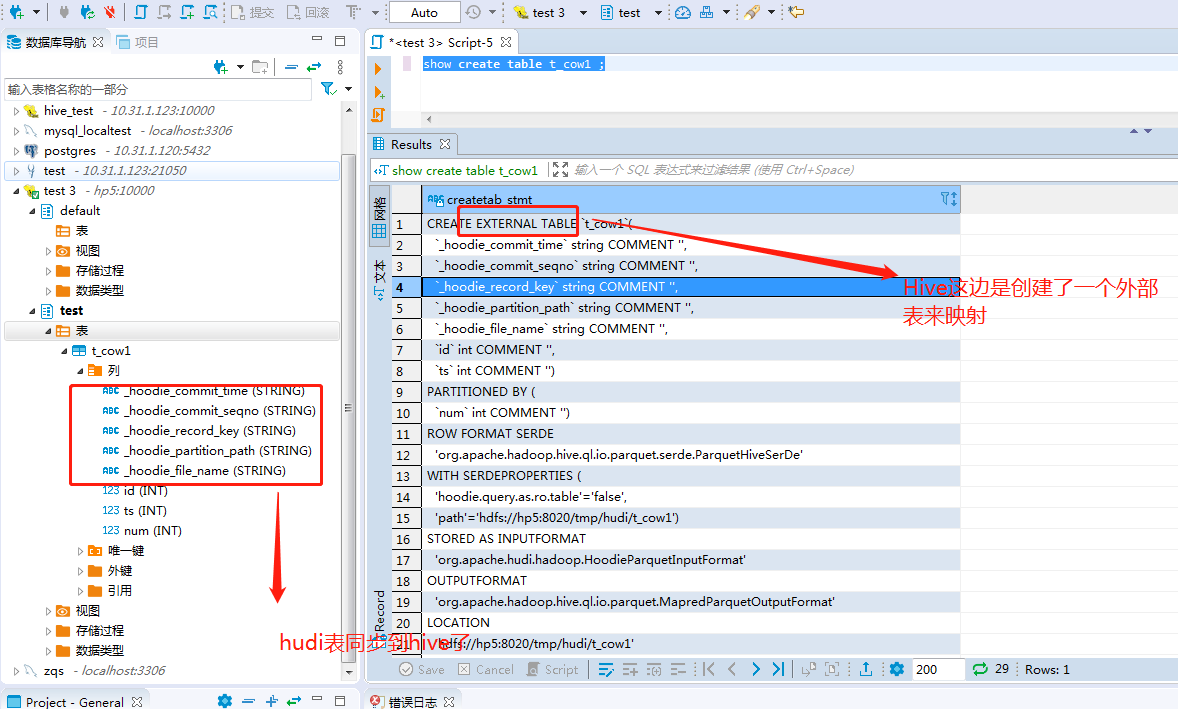
Hive端查询数据:
3.2 在catalog中创建hudi表
3.2.1 指定到hive目录之外
代码:
-- 创建目录
CREATE CATALOG hive_catalog WITH (
'type' = 'hive',
'default-database' = 'default',
'hive-conf-dir' = '/home/apache-hive-3.1.2-bin/conf'
);
-- 进入目录
USE CATALOG hive_catalog;
use test;
-- 创建表
create table t_catalog_cow1 (
id int primary key,
num int,
ts int
)
partitioned by (num)
with (
'connector' = 'hudi',
'path' = 'hdfs://hp5:8020/tmp/hudi/t_catalog_cow1',
'table.type' = 'COPY_ON_WRITE',
'hive_sync.enable' = 'true',
'hive_sync.table' = 't_catalog_cow1',
'hive_sync.db' = 'test',
'hive_sync.mode' = 'hms',
'hive_sync.metastore.uris' = 'thrift://hp5:9083',
'hive_sync.conf.dir'='/home/apache-hive-3.1.2-bin/conf'
);
insert into t_catalog_cow1 values (1,1,1);
测试记录:
Flink SQL 这边是可以查看到表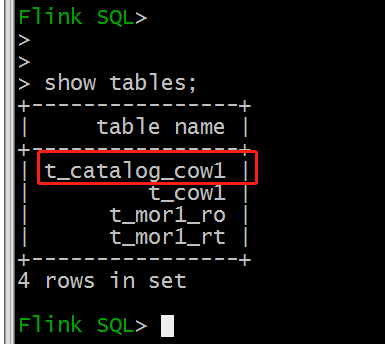
Flink SQL查询数据也没问题
Hive端可以看到表,但是查询不到数据:
Hive端查看建表语句: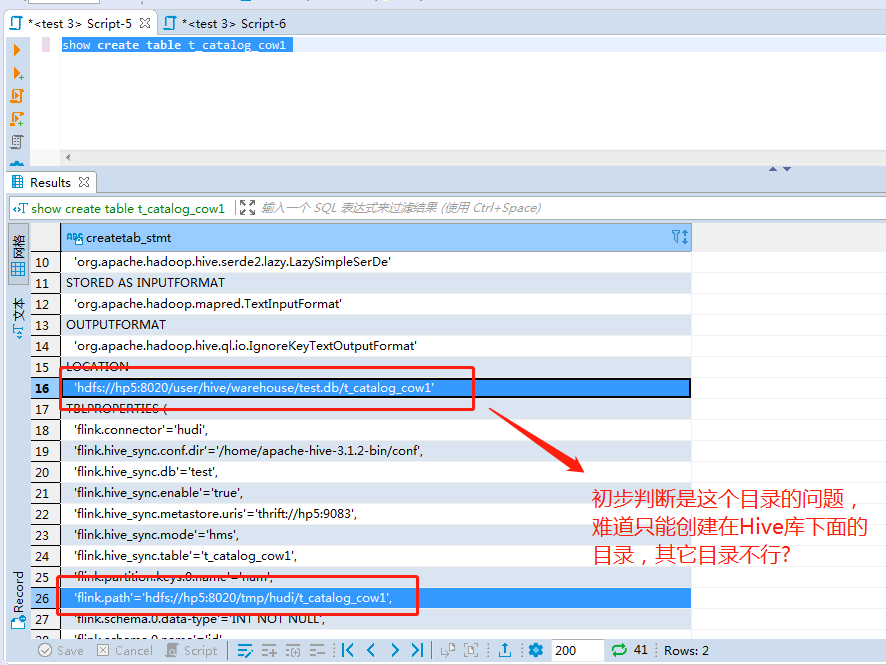
发现问题:
COW的表从hudi同步过来之后,直接少了partition字段。
也就是相当于在使用hive catalog的情况下,通过FLink创建的Hudi表自动同步到Hive这边是存在一定的问题的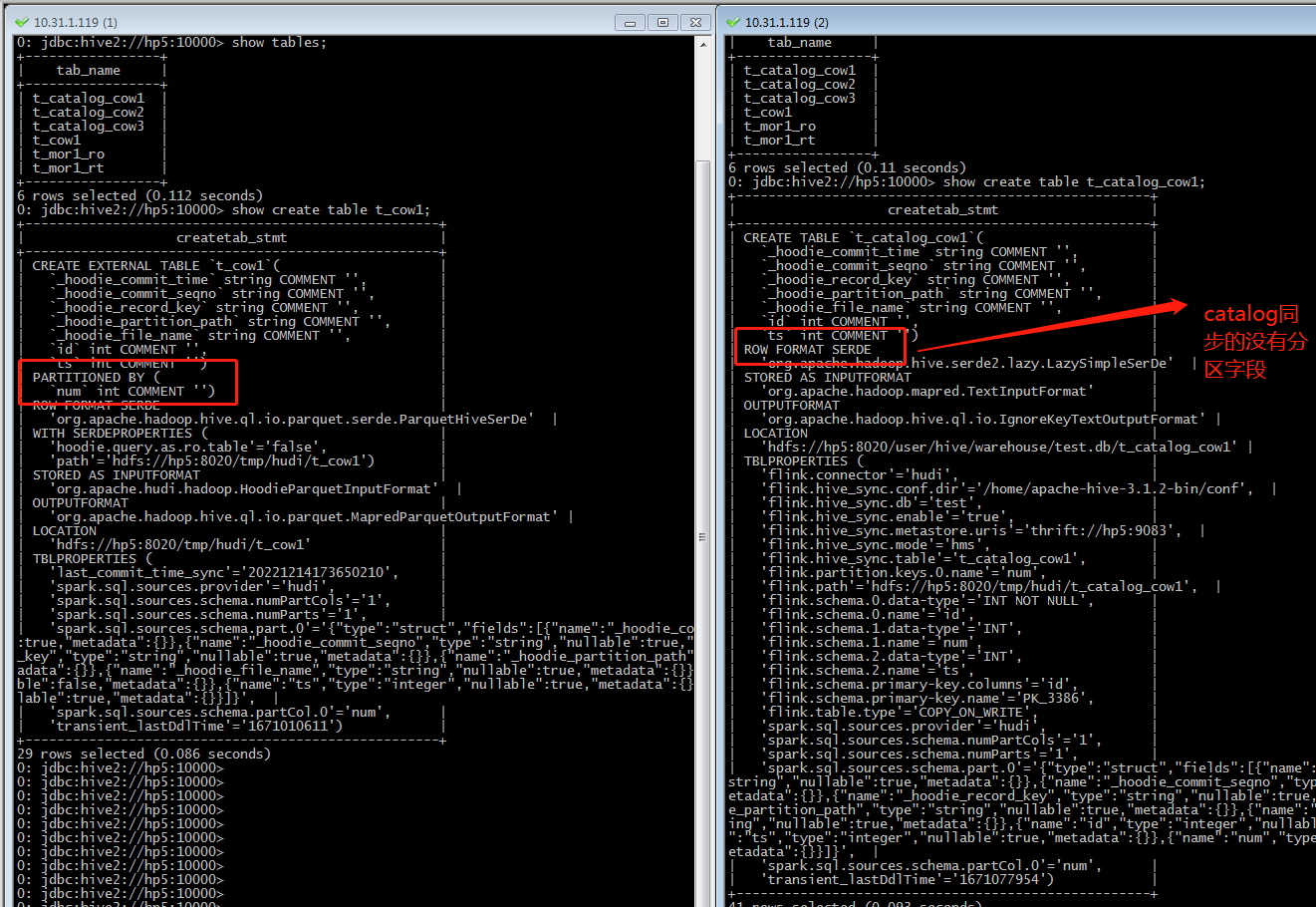
3.2.2 指定到hive目录之内
代码:
-- 创建目录
CREATE CATALOG hive_catalog WITH (
'type' = 'hive',
'default-database' = 'default',
'hive-conf-dir' = '/home/apache-hive-3.1.2-bin/conf'
);
-- 进入目录
USE CATALOG hive_catalog;
use test;
-- 创建表
create table t_catalog_cow2 (
id int primary key,
num int,
ts int
)
partitioned by (num)
with (
'connector' = 'hudi',
'path' = 'hdfs://hp5:8020/user/hive/warehouse/test.db/t_catalog_cow2',
'table.type' = 'COPY_ON_WRITE',
'hive_sync.enable' = 'true',
'hive_sync.table' = 't_catalog_cow2',
'hive_sync.db' = 'test',
'hive_sync.mode' = 'hms',
'hive_sync.metastore.uris' = 'thrift://hp5:9083',
'hive_sync.conf.dir'='/home/apache-hive-3.1.2-bin/conf'
);
insert into t_catalog_cow2 values (1,1,1);
测试记录:
问题依旧存在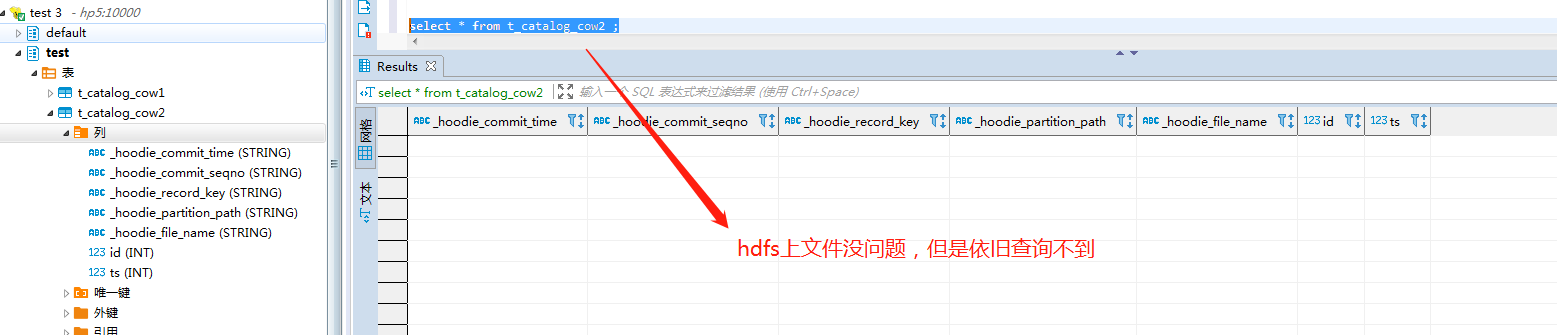
3.2.3 使用参数指定hudi表分区
代码:
create table t_catalog_cow4 (
id int primary key,
num int,
ts int
)
partitioned by (num)
with (
'connector' = 'hudi',
'path' = 'hdfs://hp5:8020/tmp/hudi/t_catalog_cow4',
'table.type' = 'COPY_ON_WRITE',
'hive_sync.enable' = 'true',
'hive_sync.table' = 't_catalog_cow4',
'hive_sync.db' = 'test',
'hoodie.datasource.write.keygenerator.class' = 'org.apache.hudi.keygen.ComplexAvroKeyGenerator',
'hoodie.datasource.write.recordkey.field' = 'id',
'hoodie.datasource.write.hive_style_partitioning' = 'true',
'hive_sync.mode' = 'hms',
'hive_sync.metastore.uris' = 'thrift://hp5:9083',
'hive_sync.conf.dir'='/home/apache-hive-3.1.2-bin/conf',
'hive_sync.partition_fields' = 'dt',
'hive_sync.partition_extractor_class' = 'org.apache.hudi.hive.HiveStylePartitionValueExtractor'
);
insert into t_catalog_cow4 values (1,1,1);
测试记录: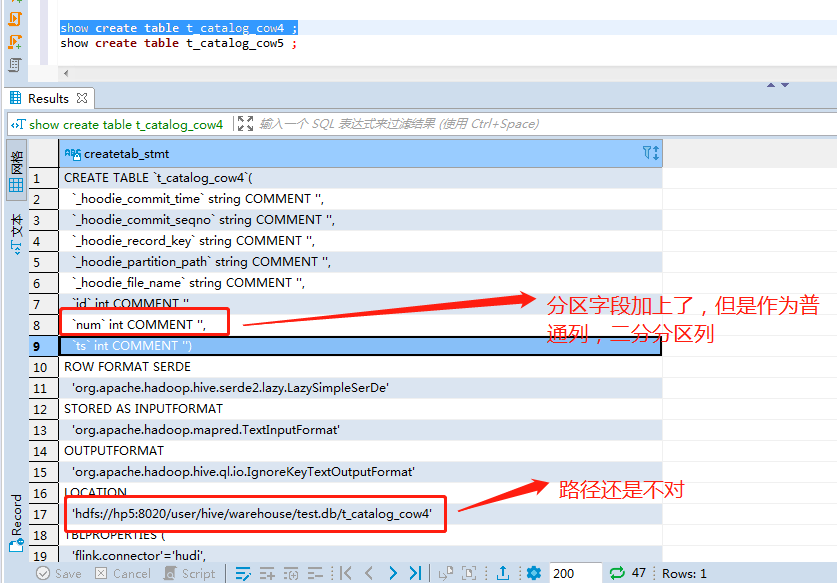
四. 实操案例(MOR)
4.1 在内存中创建hudi表(不使用catalog)
代码:
-- 创建表
create table t_mor1 (
id int primary key,
num int,
ts int
)
partitioned by (num)
with (
'connector' = 'hudi',
'path' = 'hdfs://hp5:8020/tmp/hudi/t_mor1',
'table.type' = 'MERGE_ON_READ',
'hive_sync.enable' = 'true',
'hive_sync.table' = 't_mor1',
'hive_sync.db' = 'test',
'hive_sync.mode' = 'hms',
'hive_sync.metastore.uris' = 'thrift://hp5:9083',
'hive_sync.conf.dir'='/home/apache-hive-3.1.2-bin/conf'
);
-- 只有在写数据的时候才会触发同步Hive表
-- Hive只能读取Parquet的数据,MOR的表不会立马生成Parquet文件,需要多录入几条数据,或者使用Spark-SQL再多录入几条数据
insert into t_mor1 values (1,1,1);
测试记录:
HDFS:
只有log,没有Parquet文件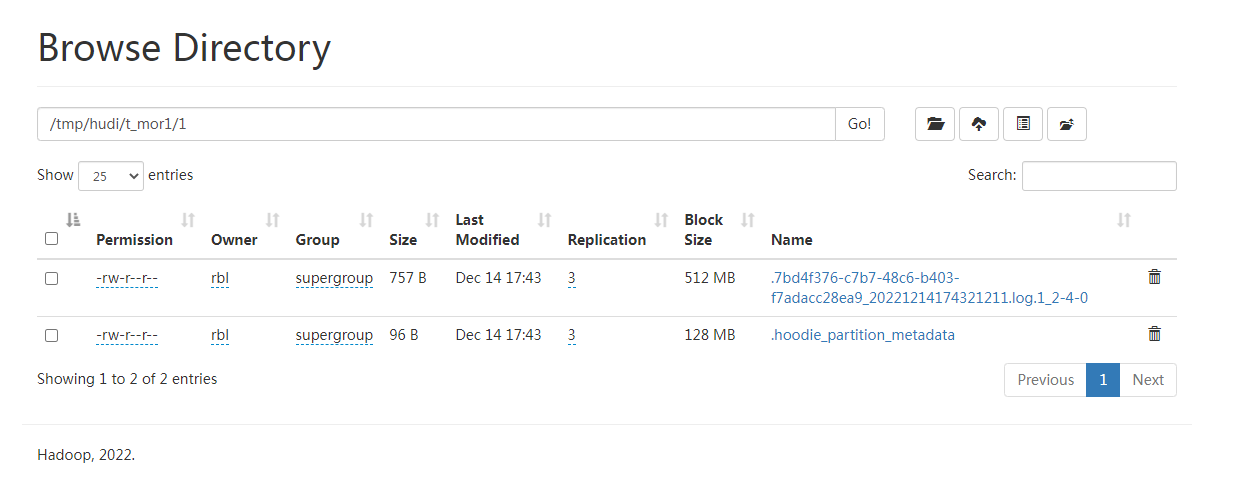
insert into t_mor1 values (2,1,2);
insert into t_mor1 values (3,1,3);
insert into t_mor1 values (4,1,4);
insert into t_mor1 values (5,1,5);
Flink WEB: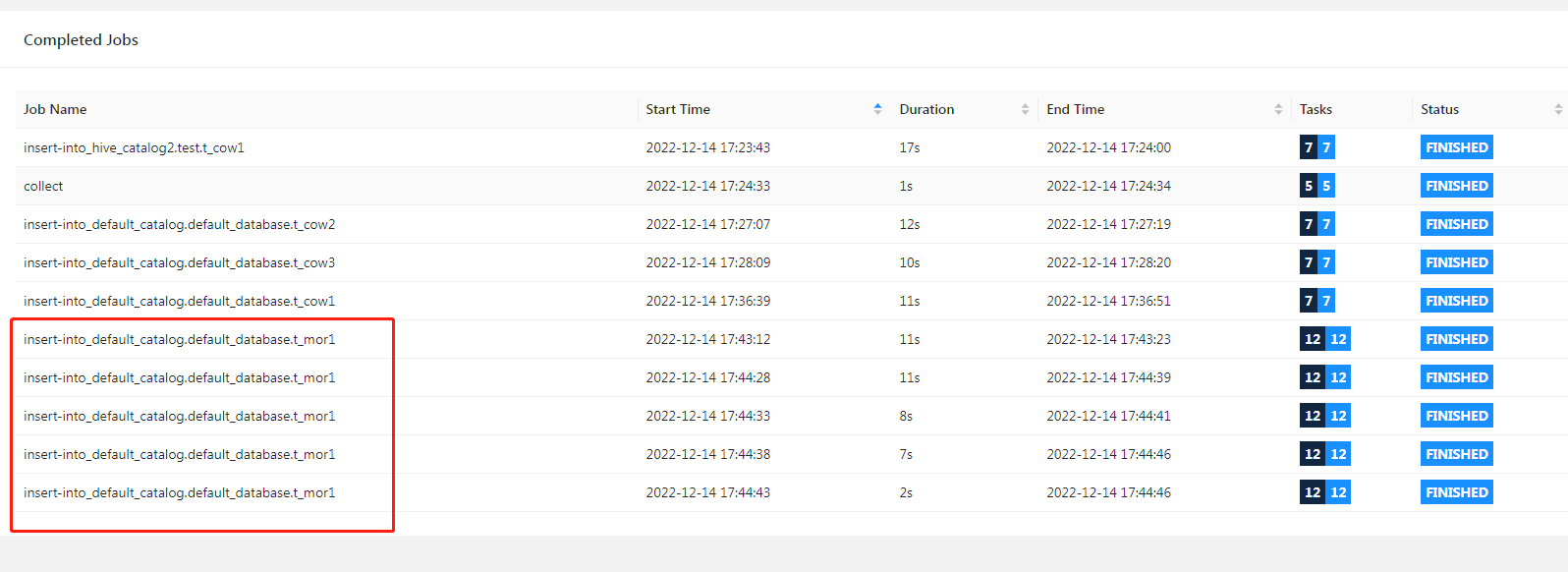
多了几个表:
t_mor1 是hudi表,通过Flink可以进行读写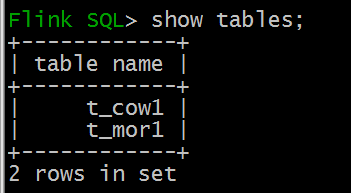
t_mor1_ro、t_mor1_rt hive表,可以通过Hive、Spark进行操作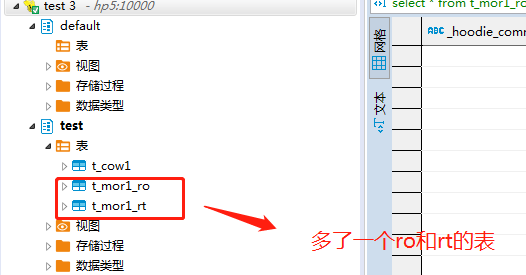
Hive端查看数据:
因为没有parquet文件,所以没有数据生成
加入了很多的测试数据,结果依旧是log文件而没有parquet文件…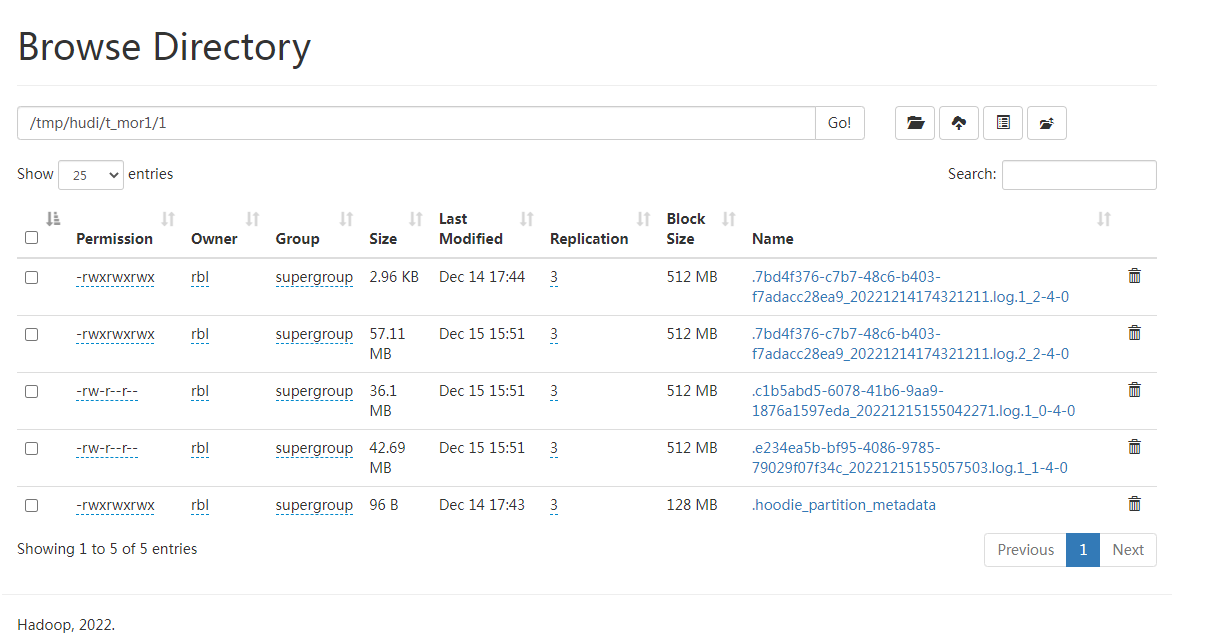
退出重新登陆:
Flink SQL 客户端这边 看不到之前的表了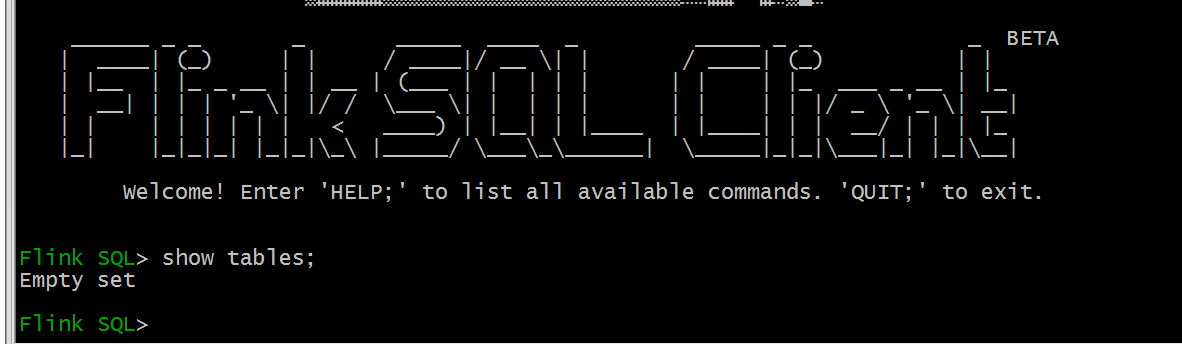
Hive这边,退出重新登陆,依旧是存在的。
FAQ:
FAQ1: NoClassDefFoundError ParquetInputFormat
问题描述:
在Flink SQL客户端查询COW表的时候报错
[ERROR] Could not execute SQL statement. Reason:
java.lang.NoClassDefFoundError: org/apache/parquet/hadoop/ParquetInputFormat

解决方案:
找到hudi编译时候的parquet的包,拷贝到flink的lib目录
参考:
版权归原作者 只是甲 所有, 如有侵权,请联系我们删除。