
& 什么是Spark?
Spark最初由美国加州伯克利大学(UCBerkeley)的AMP(Algorithms, Machines and People)实验室于2009年开发,是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。Spark在诞生之初属于研究性项目,其诸多核心理念均源自学术研究论文。2013年,Spark加入Apache孵化器项目后,开始获得迅猛的发展,如今已成为Apache软件基金会最重要的三大分布式计算系统开源项目之一(即Hadoop、Spark、Storm)
& 什么是Scala
Scala是一门多范式的编程语言,一种类似java的编程语言,设计初衷是实现可伸缩的语言 、并集成面向对象编程和函数式编程的各种特性。
二、数据准备(数据类型的转换)
将天气数据进行转换,csv转json文件,相关代码如下:
(使用的python,相对简单)
代码如下:
import csv
import json
import chardet
csvFilePath = 'weather.csv'
jsonFilePath = 'weather.json'
# 检测文件编码
with open(csvFilePath, 'rb') as file:
result = chardet.detect(file.read())
encoding = result['encoding']
# 读取 CSV 文件并处理非 UTF-8 字符
with open(csvFilePath, 'r', encoding=encoding, errors='replace') as csvFile:
csvDict = csv.DictReader(csvFile)
jsonData = json.dumps([row for row in csvDict], ensure_ascii=False)
# 将 JSON 数据写入文件
with open(jsonFilePath, 'w', encoding='utf-8') as jsonFile:
jsonFile.write(jsonData)
转后的数据如下(仅展示部分数据):

建类:
import java.io.Serializable;
public class Weather implements Serializable {
private String date;//日期
private String week;//星期
private String weather;//天气情况
private String min_temperature;//最低温度
private String max_temperature;//最高温度
private String wind_direction;//风向
private String wind_scale;//风力等级
public String getDate() {
return date;
}
public void setDate(String date) {
this.date = date;
}
public String getWeek() {
return week;
}
public void setWeek(String week) {
this.week = week;
}
public String getWeather() {
return weather;
}
public void setWeather(String weather) {
this.weather = weather;
}
public String getMin_temperature() {
return min_temperature;
}
public void setMin_temperature(String min_temperature) {
this.min_temperature = min_temperature;
}
public String getMax_temperature() {
return max_temperature;
}
public void setMax_temperature(String max_temperature) {
this.max_temperature = max_temperature;
}
public String getWind_direction() {
return wind_direction;
}
public void setWind_direction(String wind_direction) {
this.wind_direction = wind_direction;
}
public String getWind_scale() {
return wind_scale;
}
public void setWind_scale(String wind_scale) {
this.wind_scale = wind_scale;
}
}
三、Spark部分
1、使用Spark完成数据中的“风级”,“风向”、“天气情况”相关指标统计及筛选
指标:风级、风向
代码如下:
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import static org.apache.spark.sql.functions.*;
public class WeatherAnalysis {
public static void main(String[] args) {
SparkSession spark = SparkSession.builder()
.appName("WeatherAnalysis")
.master("local").getOrCreate();
SparkConf conf = new SparkConf().setAppName("Weather2").setMaster("local");
// 读取json数据
Dataset<Row> weatherData = spark.read().json("D:\\weather.json");
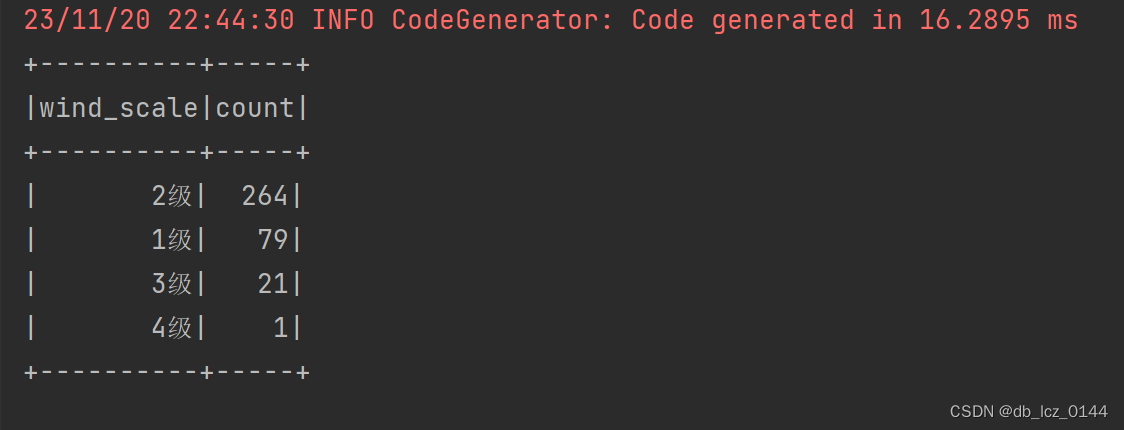
// 1. 统计出现次数最多的“风级“数量,降序,并输出控制台
Dataset<Row> windScaleCount = weatherData.groupBy("wind_scale")
.count().sort(desc("count"));
windScaleCount.show();
// 2. 统计出现次数最多的“风向“数量,降序,并输出控制台
Dataset<Row> windDirectionCount = weatherData.groupBy("wind_direction")
.count().sort(desc("count"));
windDirectionCount.show();
// 3. 筛选出风级等于2级且风向为“西北风” 的天气数据,并输出控制台
weatherData.where(" wind_scale = '2级' and wind_direction = '西北风'").show();
}
}
运行结果如下:

指标:天气情况
代码如下:
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.api.java.JavaSparkContext;
import static org.apache.spark.sql.functions.*;
public class Weather2 {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("Weather2").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
SparkSession spark = SparkSession.builder().appName("Weather2").master("local").getOrCreate();
// 读取json数据
Dataset<Row> weatherDF = spark.read().json("D:\\weather.json");
//4、统计一年的各种“天气“情况出现频数,并输出控制台
Dataset<Row> windDirectionCount = weatherDF.groupBy("weather")
.count().sort(desc("count"));
windDirectionCount.show();
// 5. 统计一年的“天气“情况为”晴“的出现天数,并输出控制台。
long sunnyDays = weatherDF.filter(col("weather").equalTo("晴")).count();
System.out.println("一年的“天气“情况为”晴“的天数有: \n" + sunnyDays + "天");
}
}
运行结果如下:


四、Scala部分
1、使用Scala统计某月、全年的温差、平均气温以及最值等相关的指标
指标:温差、平均温、最值
代码如下:
kage scala_weather
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
object Weather1 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("WeatherAnalysis")
.master("local")
.getOrCreate()
// 读取json数据
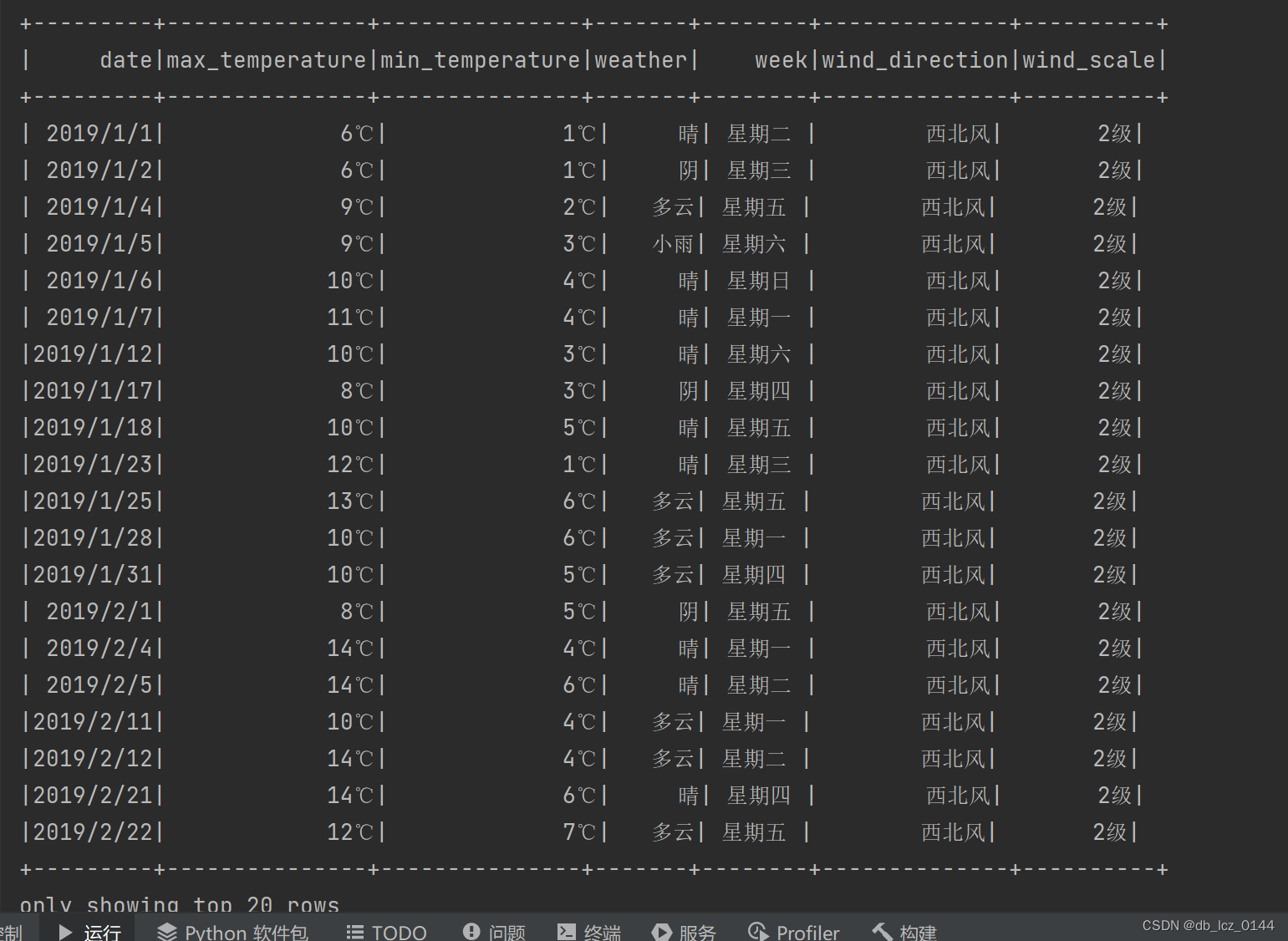
val weatherDF = spark.read.json("D:\\weather.json")
weatherDF.show()
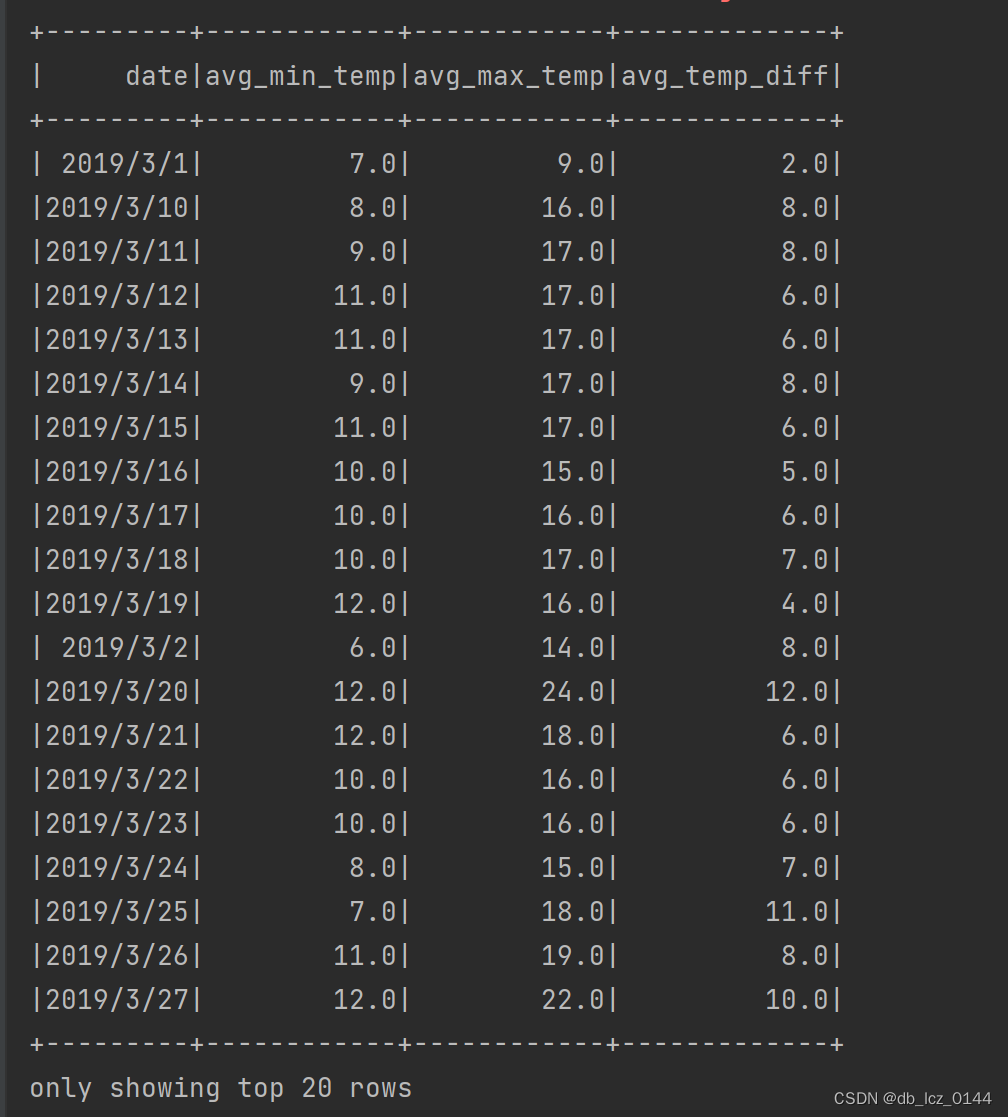
// 6. 统计3月份每天的温差,以及平均温度
val marchWeatherDF = weatherDF.filter(month(to_date(col("date"), "yyyy/MM/dd")) === 3)
val marchWeatherDiffDF = marchWeatherDF
.withColumn("min_temp", regexp_replace(col("min_temperature"), "℃", "").cast(DoubleType))
.withColumn("max_temp", regexp_replace(col("max_temperature"), "℃", "").cast(DoubleType))
.withColumn("temp_diff", col("max_temp") - col("min_temp"))
.groupBy("date")
.agg(round(avg("min_temp"), 2).alias("avg_min_temp"), round(avg("max_temp"), 2).alias("avg_max_temp"), round(avg("temp_diff"), 2).alias("avg_temp_diff"))
.orderBy("date")
println("3月份每天的温差以及平均温度:")
marchWeatherDiffDF.show()
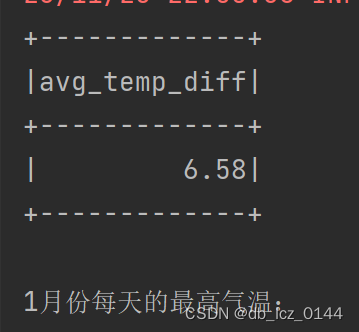
// 7. 统计全年的温差
val yearWeatherDiffDF = weatherDF
.withColumn("min_temp", regexp_replace(col("min_temperature"), "℃", "").cast(DoubleType))
.withColumn("max_temp", regexp_replace(col("max_temperature"), "℃", "").cast(DoubleType))
.withColumn("temp_diff", col("max_temp") - col("min_temp"))
.agg(round(avg("temp_diff"), 2).alias("avg_temp_diff"))
println("全年的温差平均值:")
yearWeatherDiffDF.show()
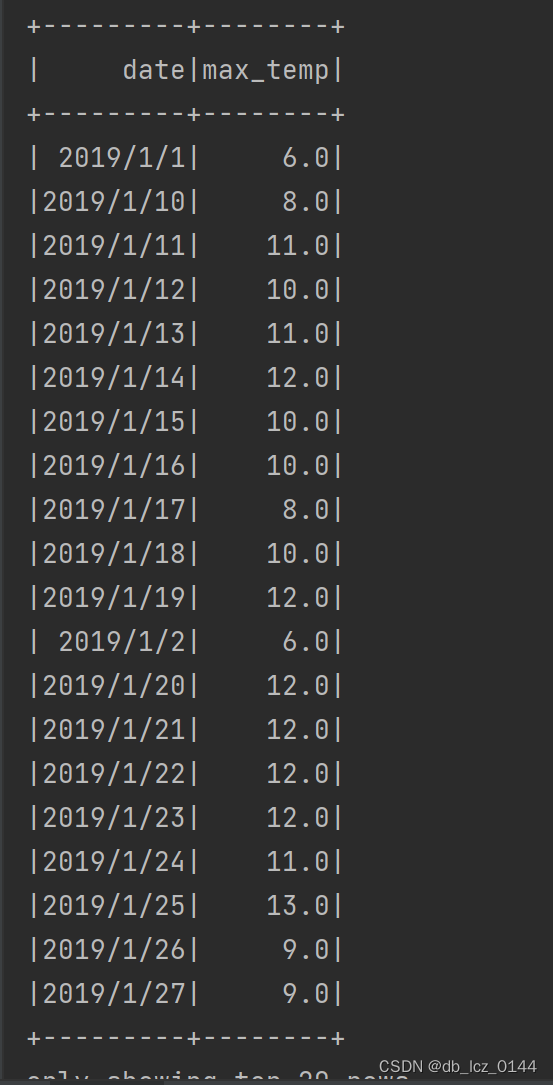
//8. 统计1月份每天的最高气温
val januaryWeatherDF = weatherDF.filter(month(to_date(col("date"), "yyyy/MM/dd")) === 1)
val januaryMaxTempDF = januaryWeatherDF
.withColumn("max_temp", regexp_replace(col("max_temperature"), "℃", "").cast(DoubleType))
.select("date","max_temp")
.orderBy("date","max_temp")
.orderBy("date")
println("1月份每天的最高气温:")
januaryMaxTempDF.show()
spark.stop()
}
}
运行结果如下:
五、遇到的问题:
1、json文件转换成功,但是使用ider进行数据的读取时,返回显示无法解析的错误
(使用了3种方法进行文件的转换。。。以下展示2种文件格式对比)
解决:
// 1 ider可以解析的json文件的样式:
[{"date": "2019/1/1", "week": " 星期二 ", "weather": "晴", "min_temperature": "1℃", "max_temperature": "6℃", "wind_direction": "西北风", "wind_scale": "2级"}
// 2 无法解析的json文件样式:(看着样式和上面的区别不大,但是我运行时提示无法解析。。。不太懂。。。可能空格问题?)
[
{
"weather": "晴",
"date": "2019/1/1",
"week": " 星期二 ",
"min_temperature": "1℃",
"max_temperature": "6℃",
"wind_scale": "2级",
"wind_direction": "西北风"
},
2、尝试读取json文件时,返回文件路径不存在的问题(使用相对路径,绝对路径均无用)
解决:我把json文件移动到根目录下,就成功读取到了。。。
3、当创建Scala类时,找不到创建Scala类或者Scala项目的选项(Scala已经安装并已完全部署好、插件、包均已导入)
解决:打开“文件”--->“项目结构”--->“平台设置”---->“全局库”,把Scala包再重新导入就可以啦
4、 编写Scala代码来统计气温的时候,使用 "$" 符号,提示 $不是StringContext的成员(插件已经安装,Scala包也已经导入)
解决:将 "$" 换成col,再将字段()起来就可以啦
六、总结
学习Spark和Scala编程可以帮助我们处理大规模数据,进行数据分析。使用Spark和Scala编写程序可以提高数据处理的效率和灵活性,同时还能够充分发挥分布式计算的优势。通过学习这两门技术,我们可以更好地理解数据处理的流程和原理,并且可以应用到实际的数据分析和统计工作中。总而言之,学习Spark和Scala编程是提升数据处理能力和数据分析技能的重要途径。
版权归原作者 db_lcz_2014 所有, 如有侵权,请联系我们删除。