
Flink 介绍
文章目录
1. 简介
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
Apache Flink是一个分布式处理引擎,用于在无界和有界数据流上进行有状态的计算。它在所有的通用集群环境中都可以运行,在任意规模下都可以达到内存级的计算速度。
1.1 背景
Apache Flink 最初由德国柏林工业大学的 Stratosphere 项目发展而来,该项目于 2010 年启动。最初,Stratosphere 是为了支持复杂的大规模数据分析任务而设计的。后来,Flink 项目作为 Stratosphere 的一个分支,在 2014 年成为 Apache 软件基金会的顶级项目。
1.2 用途
- 实时数据处理:Flink 可以处理实时数据流,使得企业能够实时地分析和处理数据,从而做出更快速的决策。
- 批处理:除了流处理,Flink 也支持批处理模式,可以处理大规模的批量数据,适用于需要离线处理的任务。
- 事件驱动应用:Flink 提供了灵活的事件驱动模型,可用于构建各种类型的实时应用程序,如监控、推荐系统、实时报警等。
- 数据湖计算:Flink 可以与现有的数据湖技术(如 Apache Hadoop、Apache Hive 等)无缝集成,为数据湖提供实时计算能力。
- 机器学习:Flink 提供了丰富的机器学习库和 API,可用于构建和训练机器学习模型。
总之,Apache Flink 是一个多功能的流式处理引擎,可以应用于各种实时数据处理和分析场景,是当前大数据处理领域的重要技术之一。
2. 核心概念
2.1 流(Stream)
流(Stream)是 Flink 中的基本数据模型,表示连续不断产生的数据序列。
流按照是否终止可以分为有界流(bounded stream)和无界流(unbounded stream)。

- 有界流:具有开始点和结束点,比如 2024 年 2 月份的天气数据形成的数据流,开始点为2024 年 2 月 1 日,结束点为 2024 年 2 月 28 日。
- 无界流:具有开始点,没有结束点,比如从 2024 年 2 月份开始的天气数据形成的数据流,开始点为 2024 年 2 月 1 日,没有结束点。
对应有界流和无界流这两种数据流,存在批处理和流处理两种处理方式。
- 批处理:一次性读取一批数据,进行离线的、一次性的处理,关注处理效率和吞吐量,用于离线数据分析、批量报表生成等。
- 流处理:对源源不断的数据流逐个事件进行处理,需要保证低延迟和高吞吐,用于实时监控、实时推荐等。
2.2 转换(Transformation)
转换(Transformation)是对流中的数据进行操作和处理的方法。
Flink 提供了丰富的转换操作符,包括 map、filter、flatmap、reduce、keyBy 等,用于对流数据进行转换、聚合和分组等操作。
转换操作符可以对单个数据元素或整个数据流进行操作,并且可以组合使用以构建复杂的处理逻辑。
2.3 窗口(Window)
窗口(Window)是用于对无限流进行有限范围的数据分割和处理的概念。
Flink 支持基于时间和基于数量的窗口,可以按照固定的时间间隔或固定数量的元素将流划分为不同的窗口。
窗口可以用于实现基于时间或基于事件数量的聚合和统计,例如计算滚动窗口的平均值、计数等。
2.4 状态(State)
状态(State)是 Flink 中用于存储和维护数据处理过程中的中间结果和状态信息的机制。
Flink 中的状态可以在转换(Transformation)操作中使用,用于跟踪和更新数据流的状态信息。
状态可以是键控状态(Keyed State)和操作符状态(Operator State),分别用于在分组操作和全局操作中管理状态。
3. 编程模型
Flink为开发流/批处理应用程序提供了不同层次的抽象和编程模型。从下到上,抽象层次更高,灵活性更低。

3.1 编程模型介绍
Stateful Stream Processing
- stateful stream processing是最低级别的抽象,只提供 stateful and timely 流处理。
- 它通过 Process Function 嵌入到 DataStream API 中。
- 它允许用户自由地处理来自一个或多个流的事件,并提供一致的容错状态。
- 此外,用户可以注册事件时间和处理时间回调,允许程序实现复杂的计算。
DataStream API
- DataStream API 用于处理有界/无界数据流,适用于实时流式处理场景。
- DataStream API 提供了丰富的操作符和转换函数,用于对数据流进行各种操作和处理。
- 开发者可以使用 DataStream API 来定义数据流的源、对数据流进行转换、进行窗口操作、进行状态管理等。
- DataStream API 支持事件时间和处理时间两种时间语义,并提供了丰富的窗口操作符用于基于时间和基于事件数量的窗口操作。
- DataStream API 的编程模型更加灵活和动态,可以实现实时数据流的复杂处理逻辑。
DataSet API
- DataSet API 用于处理有限数据集,适用于批处理场景。
- DataSet API 提供了类似于标准集合操作的接口,如 map、filter、reduce、groupByKey 等,可以对数据集进行各种转换和操作。
- 开发者可以使用 DataSet API 来定义数据集的源、对数据集进行转换和聚合、进行分组操作、进行连接和关联等。
- DataSet API 支持静态数据集和动态数据集的处理,适用于离线数据分析和批处理任务。
- DataSet API 的编程模型更加静态和声明式,适合处理大规模的批量数据和离线任务。
Table API
- Table API是一个以表为中心的声明性DSL,它可以是动态更改的表(当表示流时)。
- Table API遵循(扩展的)关系模型:表附带一个模式(类似于关系数据库中的表),API提供类似的操作,如 select、project、join、group-by、aggregate等。
- Table API程序声明性地定义应该执行的逻辑操作,而不是精确地指定操作代码。
- 尽管Table API可以通过各种类型的用户定义函数进行扩展,但它的表达能力不如Core API,而且使用起来更简洁(编写的代码更少)。
- 此外,Table API程序在执行前还会经过一个应用优化规则的优化器。
- 可以在 Table 和 DataStream/DataSet 之间无缝转换,允许程序将 Table API与 DataStream/DataSet API混合使用。
SQL
- Flink提供的最高级别抽象是SQL。
- 这种抽象在语义和表达性上都类似于Table API,但将程序表示为SQL查询表达式。
- SQL抽象与Table API密切交互,SQL查询可以在Table API中定义的表上执行。
这些分层 API 提供了不同抽象层次和编程模型,可以满足不同类型和规模的数据处理需求。开发者可以根据实际场景和需求选择合适的 API,并结合使用它们来构建复杂的数据处理应用。
3.2 程序示例
编写 Flink 应用程序通常涉及以下步骤:数据输入、转换和输出。下面将介绍如何进行这些步骤:
数据输入
- Flink 支持多种数据源作为输入,包括 Kafka、文件系统、Socket、自定义数据源等。
- 在 Flink 应用程序中,你可以使用相应的 Source 函数来定义数据源,并将其连接到 Flink 程序中。
- 例如,如果要从 Kafka 主题读取数据,可以使用 FlinkKafkaConsumer,如果要从文件中读取数据,可以使用 TextInputFormat。
数据转换
- 数据转换是 Flink 应用程序中最核心的部分,它包括对数据进行各种操作、处理和转换。
- 你可以使用 Flink 提供的丰富的转换函数和操作符来对数据进行处理,如 map、filter、flatMap、reduce、groupBy、window 等。
- 使用这些操作符可以实现数据的清洗、过滤、聚合、分组、窗口操作等功能,以满足实际的业务需求。
数据输出
- 数据输出是将处理后的数据写入到外部系统或存储介质中的过程。
- Flink 支持将处理后的数据输出到多种目标,包括 Kafka、文件系统、Socket、自定义数据接收器等。
- 你可以使用相应的 Sink 函数来定义数据输出目标,并将数据流连接到 Sink 中。
- 例如,如果要将数据写入到 Kafka 主题中,可以使用 FlinkKafkaProducer,如果要将数据写入到文件中,可以使用 TextOutputFormat。
下面是一个简单的示例,展示了如何编写一个简单的 Flink 应用程序,从 Kafka 主题中读取数据,对数据进行转换,并将处理后的数据写入到文件中:
importorg.apache.flink.streaming.api.datastream.DataStream;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;importorg.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;importorg.apache.flink.streaming.util.serialization.SimpleStringSchema;publicclassKafkaToTextFileExample{publicstaticvoidmain(String[] args)throwsException{// 设置执行环境StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();// 定义 Kafka 数据源Properties props =newProperties();
props.setProperty("bootstrap.servers","localhost:9092");
props.setProperty("group.id","test-group");FlinkKafkaConsumer<String> kafkaConsumer =newFlinkKafkaConsumer<>("input-topic",newSimpleStringSchema(), props);// 从 Kafka 主题读取数据DataStream<String> inputStream = env.addSource(kafkaConsumer);// 数据转换:将每行数据转换为大写DataStream<String> outputStream = inputStream.map(String::toUpperCase);// 将处理后的数据写入到文件中
outputStream.writeAsText("output-file");// 执行任务
env.execute("Kafka to TextFile Example");}}
在这个示例中,我们使用 FlinkKafkaConsumer 从 Kafka 主题读取数据,然后使用 map 操作符将每行数据转换为大写,最后使用 writeAsText 将处理后的数据写入到文件中。
4. 部署
4.1 集群架构
Apache Flink 的集群架构如下图:

Flink Client:
- Client端负责构建、配置和提交Flink应用程序。
- 它提供了用于编写和管理应用程序的API和工具,包括DataStream API和DataSet API等。
JobManager:
- JobManager是Flink集群中的主节点,负责协调整个作业的执行。
- JobManager接收由Client端提交的应用程序,并将其转换为作业图(JobGraph),然后进行调度和执行。
- JobManager负责整个作业的生命周期管理,包括作业的启动、调度、监控、容错等。
TaskManager:
- TaskManager是Flink集群中的工作节点,负责实际的任务执行。
- TaskManager负责执行JobManager分配给它的任务,包括数据处理、状态管理、结果计算等。
- TaskManager通过插槽(Slot)的方式来执行任务,每个插槽可以执行一个或多个任务,根据系统的配置和资源情况动态分配。
4.2 集群资源管理
Apache Flink 支持多种集群资源管理方式,可以根据用户的需求和场景选择合适的方式。以下是一些常见的资源管理方式:
Standalone 模式:
- Standalone 模式是最简单的部署方式,适用于单机或开发测试环境。
- 在 Standalone 模式下,Flink 在单个进程内运行,包括一个 JobManager 和一个或多个 TaskManager。
- 这种部署方式不需要额外的集群管理工具,适合快速开发和测试。
Apache Mesos:
- Apache Mesos 是一个通用的集群管理框架,Flink 可以作为 Mesos 上的一个框架进行部署。
- 在 Mesos 上部署 Flink 可以实现资源的动态分配和共享,提高资源利用率和集群的灵活性。
Apache YARN:
- Apache YARN 是 Hadoop 生态系统中的资源管理框架,Flink 可以作为 YARN 上的一个应用程序进行部署。
- 在 YARN 上部署 Flink 可以利用 Hadoop 集群的资源,并与其他 Hadoop 生态系统集成。
Kubernetes:
- Kubernetes 是一个开源的容器编排引擎,Flink 可以作为 Kubernetes 上的一个容器化应用程序进行部署。
- 在 Kubernetes 上部署 Flink 可以实现资源的动态调度和弹性扩展,支持快速部署和管理。
Amazon EMR:
- Amazon EMR 是亚马逊提供的弹性 MapReduce 服务,支持在云中部署和管理 Flink 集群。
- 在 Amazon EMR 上部署 Flink 可以方便地利用云资源,实现按需扩展和灵活计费。
Docker Compose:
- Docker Compose 是一个用于定义和运行多容器 Docker 应用程序的工具,可以使用 Docker Compose 部署 Flink 集群。
- 使用 Docker Compose 可以快速部署本地开发环境或小规模集群。
自定义部署:
- 用户也可以根据自己的需求和环境,自定义部署 Flink 集群。
- 可以选择其他的集群管理工具,如Apache Ambari、Cloudera Manager等。
总之,Apache Flink 支持多种部署方式,用户可以根据自己的需求和环境选择合适的部署方式,实现灵活、高效的数据处理和分析。
4.3 部署模式
Flink 应用有以下三种部署模式:
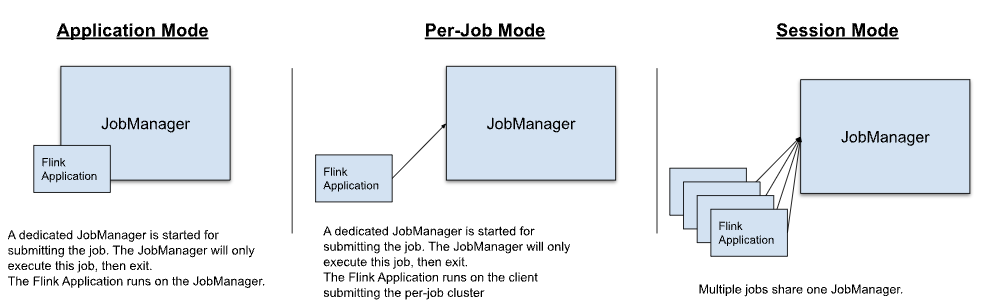
不同部署模式的主要区别在于以下两点:
- 集群生命周期和资源隔离保证
- 应用程序运行在客户端(client)还是在集群(JobManager)上
Application Mode:
- 为每个提交的作业启动一个集群,集群包含 JobManager,当作业完成时,集群资源被释放。
- Flink应用运行在集群的JobManager上。
- 支持在应用程序中多次调用execute/executeAsync。
Per-Job Mode:
- 为每个提交的作业启动一个集群,集群包含 JobManager,当作业完成时,集群资源被释放。
- Flink应用运行在客户端上。
- 注意:Per-Job 模式只被YARN支持,在Flink 1.15中已被弃用。
Session Mode:
- 存在一个已有的集群,集群包含 JobManager,所有提交的作业共享同一个JobManager。
- Flink 应用运行在客户端上。
5. 运维
Flink 应用的运维涉及多个方面,包括部署管理、监控调优、故障处理等任务。以下是常见的 Flink 运维任务以及相应的工具:
5.1 部署管理
- 集群部署:负责搭建和管理 Flink 集群,可以使用 Apache Mesos、Apache YARN、Kubernetes 等集群管理工具。
- 版本管理:负责管理 Flink 的版本升级和回退,保证集群中的所有节点都在相同的版本上运行。
- 资源调配:负责动态调整和分配集群资源,以满足不同作业的需求,可以使用集群管理工具或 Flink 自带的资源管理器。
5.2 监控调优
- job监控:可以使用Flink提供的Web UI监控 Flink 集群和应用程序的状态和指标。
- 性能监控:监控 Flink 应用的性能指标,包括吞吐量、延迟、状态大小等,可以使用指标监控系统如 Prometheus、Grafana。
- 日志分析:分析 Flink 应用的日志,及时发现异常和问题,可以使用ELK等日志监控工具。
- 调优优化:根据性能监控和日志分析结果,调整应用程序的配置参数,优化算子的并行度、窗口大小等,提高应用程序的性能和稳定性。
5.3 故障处理
- 容错机制:配置检查点、状态后端、重启策略等参数,保证应用程序在发生故障时能够恢复到正确的状态并继续运行。
- 异常处理:处理任务失败、节点宕机等异常情况,可以通过监控系统实时监控,或者配置告警系统及时发现并处理异常。
5.4 版本管理和升级
- 版本管理:管理 Flink 应用的代码版本,包括代码的提交、分支管理、版本发布等。
- 升级策略:规划 Flink 的版本升级策略,保证升级过程顺利进行并且不影响现有的业务运行。
5.5 安全管理
- 认证授权:配置访问控制和权限管理,保护集群资源和数据安全。
- 加密通信:使用 SSL/TLS 加密协议保障 Flink 集群之间的通信安全。
5.6 资源管理和优化
- 资源利用:监控集群资源的利用率,优化资源分配策略,避免资源浪费和瓶颈。
- 动态调度:根据作业的资源需求和优先级,动态调度任务和容器,提高资源利用率和集群的弹性。
6. 生态系统
Apache Flink 作为一个流处理框架,与其他开源项目和工具的整合非常紧密,构成了一个丰富多彩的生态系统。以下是一些与 Flink 相关的其他项目和工具:
Apache Beam:Apache Beam 是一个用于编写、管理和执行大规模数据处理流水线的统一编程模型。它提供了一种统一的编程接口,使得开发者可以编写一次代码,并在多个流处理引擎上运行,包括 Apache Flink、Apache Spark、Google Cloud Dataflow 等。
Apache Kafka:Apache Kafka 是一个分布式流处理平台,用于构建实时数据管道和流式应用程序。Flink 与 Kafka 集成紧密,可以直接从 Kafka 主题读取数据,也可以将处理后的数据写入 Kafka 主题。
Apache Hadoop:Apache Hadoop 是一个分布式计算框架,用于存储和处理大规模数据集。Flink 可以与 Hadoop 生态系统集成,如与 HDFS 进行交互读写数据,与 HBase 进行交互进行实时数据访问等。
Apache Spark:Apache Spark 是一个通用的大数据处理框架,支持批处理和流处理。Flink 与 Spark 集成,可以在同一个应用中使用两者的特性,实现更丰富的数据处理和分析功能。
Apache Airflow:Apache Airflow 是一个用于编排、调度和监控工作流的平台。Flink 可以与 Airflow 集成,实现更灵活和可靠的任务调度和管理。
Presto:Presto 是一个用于交互式查询和分析的分布式 SQL 查询引擎。Flink 可以与 Presto 集成,实现对实时流数据和批量数据的交互式查询和分析。
Elasticsearch:Elasticsearch 是一个分布式实时搜索和分析引擎。Flink 可以与 Elasticsearch 集成,将处理后的数据写入到 Elasticsearch 中,实现实时数据分析和可视化。
Debezium:Debezium 是一个开源的 CDC(Change Data Capture)工具,用于监控数据库的变更并将变更数据流式传输到目标系统。Flink 可以与 Debezium 集成,实时处理数据库的变更数据并进行相应的处理和分析。
以上是一些与 Flink 相关的其他项目和工具,通过与这些项目和工具的整合,可以实现更丰富和强大的数据处理和分析功能。
7. 应用场景
Apache Flink 是一个强大的流式计算框架,适用于多种实时数据处理和分析场景。以下是一些适合使用 Flink 的应用场景:
实时数据分析:Flink 可以处理实时产生的大量数据,并实时进行数据分析和统计,用于监控、报警、实时指标计算等场景。例如,实时交易监控、实时用户行为分析、实时广告投放分析等。
实时数据清洗和转换:Flink 提供丰富的转换函数和操作符,可以对实时数据进行清洗、转换和加工,用于数据质量控制和数据格式转换。
例如,实时数据清洗、格式转换、字段提取等。
实时推荐系统:Flink 可以实时处理用户行为数据,并根据实时数据生成个性化的推荐结果,用于实时推荐系统和内容推荐场景。例如,实时个性化推荐、实时热门排行榜、实时新闻推荐等。
实时欺诈检测:Flink 可以实时监控交易数据和用户行为数据,检测异常和欺诈行为,用于金融行业的实时风险控制和反欺诈场景。例如,实时交易欺诈检测、实时信用卡盗刷监控等。
实时事件处理:Flink 可以处理实时产生的事件流数据,并实时进行事件处理和响应,用于物联网、智能监控等实时事件处理场景。例如,实时传感器数据处理、实时设备监控、实时异常检测等。
实时日志分析:Flink 可以实时处理大规模的日志数据,并实时进行日志分析和监控,用于系统运维、性能监控等场景。例如,实时日志监控、实时异常检测、实时日志搜索等。
实时机器学习:Flink 可以与机器学习库集成,实现实时机器学习模型的训练和预测,用于实时个性化推荐、实时智能客服等场景。例如,实时用户行为预测、实时图像识别、实时文本分类等。
总之,Apache Flink 适用于各种实时数据处理和分析场景,能够帮助企业构建实时、可靠、高性能的数据处理系统,并实现更智能化的业务应用。
总结
总的来说,Flink 是一个高性能的流数据计算引擎,具有如下特性:
- 支持流批一体
- 支持事件时间(event time)、接入时间(ingest time)、处理时间(processing time)时间概念
- 支持基于轻量级分布式快照的容错
- 支持有状态计算(stateful)
- 支持高度灵活的窗口(window)操作
- 带反压的数据流模型
- 提供多层 API
- 语言支持:支持 Java, Scala和Python语言
- 支持多种部署方式
版权归原作者 程序员白总 所有, 如有侵权,请联系我们删除。