
目录
提前工作
服务器
我其实复现了2次,第一次是用的3070,第二次尝试了并行超算云服务器,里面有8张 A100。两个都是采用了本机远程ssh连接服务器跑。(超算云服务器跑ST-GCN的一些配置可以之前写的博客:并行超算云直连SSH,Pycharm运行ST-GCN_Eric加油学!的博客-CSDN博客)
本机环境
第一次完整复现过程是在win的vscode上,python3.8,torch版本有点忘了好像是1.10+cu113。(忽略即可)
第二次是macOS的Pycharm 2021.1.2 专业版。 python3.7.13,torch1.10.0+cu113
下面主要是将第二次的过程,其实过程步骤是一样的。
系统和IDE没什么关系,主要是python版本和torch的cuda版本最好要对应一下。
数据集
ST-GCN官方的数据集是用的Kinetics和NTU RGB+D,如果用Kinetics或者要跑那个demo的话,是需要提前安装配置好openpose的,我嫌太麻烦,就没配置,直接用NTU RGB+D,因为NTU里面自带有骨骼点的。好像也是可以用自建的数据集的,不过没尝试过,后续步骤反正是差不多的。
由于是远程ssh连接服务器,所以还需要提前把数据集和代码都拷到服务器当中,然后本机和服务器进行连接,中间的过程就不讲了,不懂得可以看我前面的blog或者网上帖子。
运行逻辑
一切就绪后,打开st-gcn代码,有库没导的自己导一下,我遇到的主要问题好像是torchlight那个库,比较麻烦,因为它是 from torchlight.io import xxxxxx 类似于这样子的方式,但是它那个文件夹里io、gpu等py文件有2层路径,所以需要改成 from torchlight.torchlight.io import xxxxx 就是再加一个torchlight包的路径。如果还有其他的一些小bug可以再看其他博主的经验贴。
如果知道ST-GCN输入终端命令后的各种调用逻辑,那运行起来有bug可以快速找到问题,如果不知道的也可以参考一些之前发的一个源码分析blog,里面有写一些调用逻辑 (比如 gpu设备是怎么调用的,参数是怎么解析的)ST-GCN源码分析_Eric加油学!的博客-CSDN博客_gcn源码
第一步 处理数据集
终端进入服务器配好的虚拟环境,然后cd到服务器st-gcn代码文件夹的位置

python tools/ntu_gendata.py --data_path <path to nturgbd+d_skeletons>
这个就是处理的终端命令,是执行tools包下的ntu_gendata.py文件来输出数据集的,data_path是通过参数解析你所输入的地址,如上图所示,data_path后面输入你数据集所在的整个路径,就可以开始处理数据集了。
这里遇到我犯了个超蠢的错误:
我一开始无论怎么解析我的地址,都显示找不到该文件夹,我一开始以为是字符串拼接的问题,比如 \ 和 \ 这种转义字符的问题,各种尝试都没用,后来我又尝试了不使用参数解析,我直接找到调用的那个文件,直接把参数解析注释掉,直接手动赋值为我的地址,也不起效果。
最后找到问题了,居然是 我解析的地址是我本机的数据集地址!!!我用的是服务器的环境,进入的是服务器的代码文件地址,结果居然解析我本机的地址,实在是太蠢了...
 命令输入完毕后,会开始处理数据集,分别是xsub的train和val 还有xview的train和val,最后如果你没有做其他更改的话,应该是在根目录下新建一个data包,保存到data/NTU-RGB-D/nturgb+d_skeletons.
命令输入完毕后,会开始处理数据集,分别是xsub的train和val 还有xview的train和val,最后如果你没有做其他更改的话,应该是在根目录下新建一个data包,保存到data/NTU-RGB-D/nturgb+d_skeletons.

第二步 训练网络
我先训练的是ntu-xsub ,readme里也有命令

python main.py recognition -c config/st_gcn/ntu-xsub/train.yaml
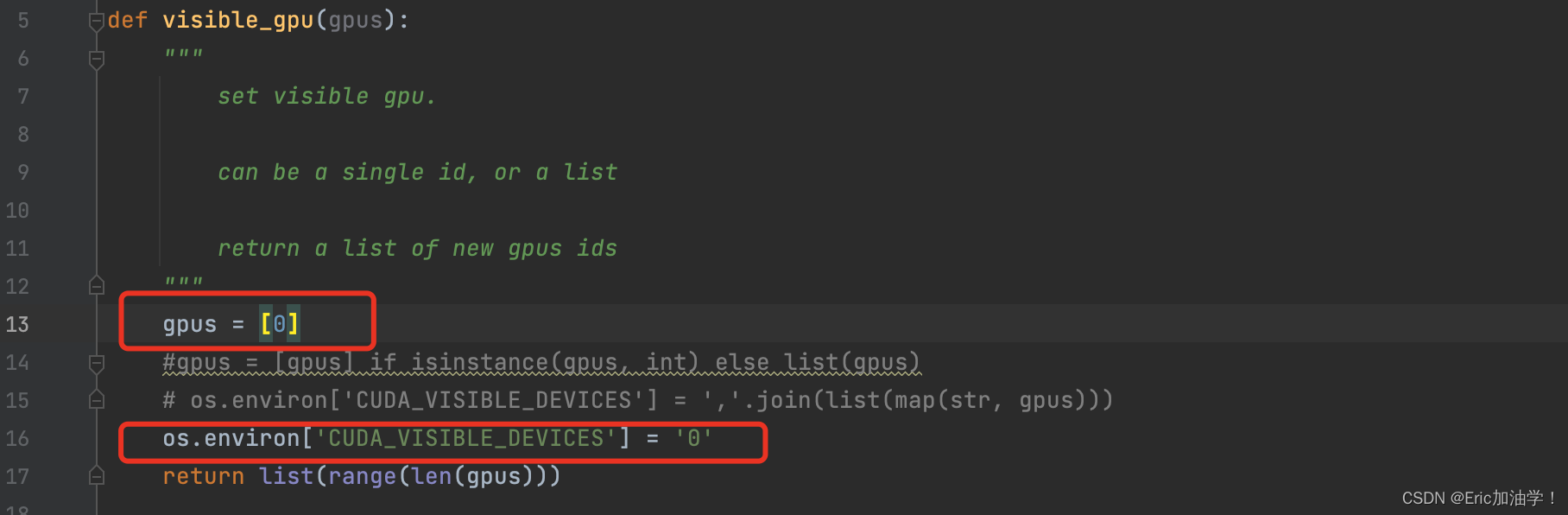
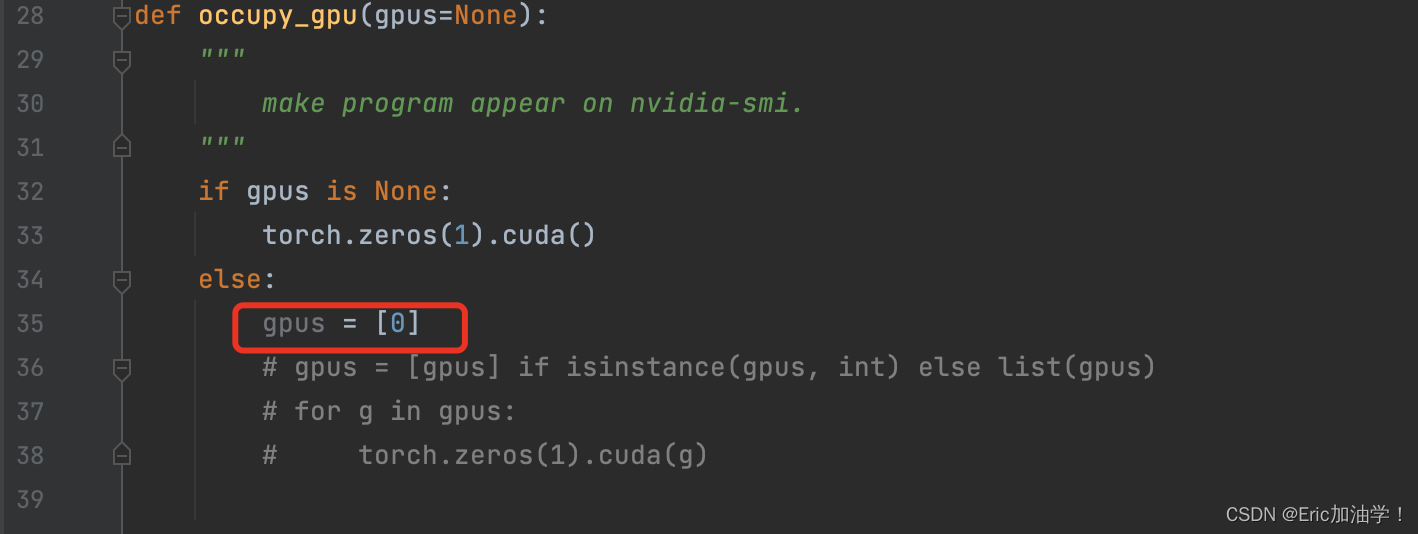
 一开始给我报错了,是cuda设备相关的问题,代码里是如果gpu个数大于1,可以设置并行运行,超算云服务器好像是有多张卡,但我不知道怎么处理多gpu问题,所以干脆直接设置gpu数量为1
一开始给我报错了,是cuda设备相关的问题,代码里是如果gpu个数大于1,可以设置并行运行,超算云服务器好像是有多张卡,但我不知道怎么处理多gpu问题,所以干脆直接设置gpu数量为1
主要修改的是torchlight包下的gpu.py文件:
然后再输入运行的命令,就开始跑了,batch-size设置的64,epoch为80(之前3070跑的时候batchsize只能设到8,大了跑不动)
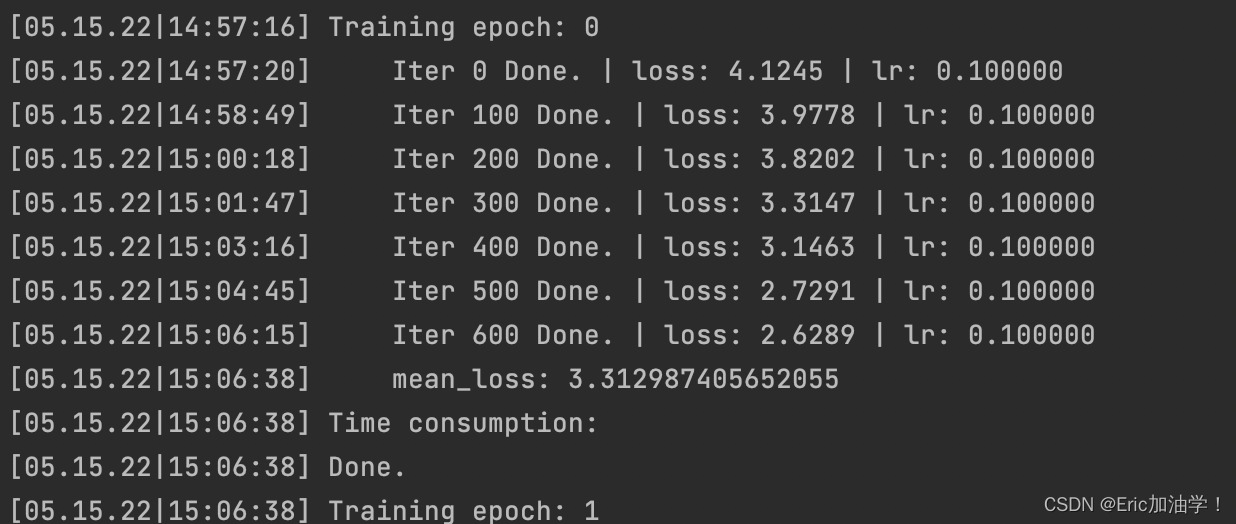 这个跑的还挺快的,一个epoch用时9分钟左右吧,之前3070一个epoch好像要13分钟左右。(感觉如果用多gpu并行会跑的巨快,听说超算云里面有8张卡)
这个跑的还挺快的,一个epoch用时9分钟左右吧,之前3070一个epoch好像要13分钟左右。(感觉如果用多gpu并行会跑的巨快,听说超算云里面有8张卡)
第三步 测试
训练模型时,每10个epoch会保存一次模型,在model包下,训练完毕时使用test命令.

python main.py recognition -c config/st_gcn/<dataset>/test.yaml
<dataset> 改成要测试的就行了 比如 ntu-xsub
如果训练的model没有放在model包下,放在了work_dir下,也可以手动添加 --weights <path to model weights> 或者直接在test.yaml文件里第一行把weights的值改成你要的路径,然后输入上面的指令即可。
比如我这次只训练了40个epoch被中断了,然后model放在了work_dir下的recognition下,我就可以直接用训练好的40个epoch的先去测试。
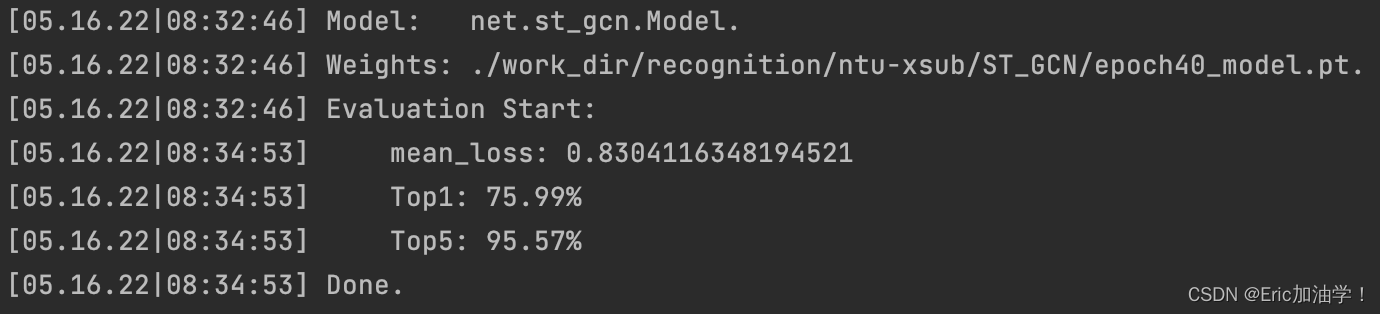
这里我之前在3070上跑的时候,训练到70多个epoch,因为网断了,由于远程连接的,所以训练也直接中断了。我天真的以为不能用训练好的先去测试,就直接删了重跑了。其实那时候可以用70epoch的模型先测试的。
远程连接的话,最好是要保证网络的稳定,笔记本最好也设一个不锁屏或者锁屏后不会取消后台的运行。好像也可以加入一些什么代码防止训练中断,下一次可以接着上次保存的model接下去训练。(这个可以查一查经验贴)
总的来说,这个就复现结束了。
总结的问题
主要的运行流程就是 处理数据集,训练,测试
遇到的一些问题就是:
- 远程连接服务器要记得把代码,数据集拷到服务器里,执行的路径是服务器的路径
- pycharm的同步好像有点小问题,明明设置了总是同步,但是就是不及时,所以总是要去服务器上看生成的一些文件夹。(看别人的经验贴好像说vscode会比较好,因为可以直接操作服务器的代码,然后下载个插件直接保存到本地就行)
- 保证好网络的稳定,考虑一下电脑熄屏后会不会中断训练。代码里有每10epoch自动保存,可以尝试加入下次训练接着上次保存的模型继续train的代码,或者中断了也可以用保存的model先test。
- 如果有多张gpu可以尝试下并行执行,我这里利用率就很低,只设了单gpu运行。(写完再去尝试下怎么运行多gpu的)
版权归原作者 Eric加油学! 所有, 如有侵权,请联系我们删除。