
Kafka的高性能如何实现
kafka的高性能可从分区、缓存页、网络开销以及压缩几个方面实现。
1.分区
分区partition可以提高kafka的并发度。
- 一个主题topic可以有多个partition。
- 消费者端根据partition的数量启动多个消费者线程进行消费,提高并发能力,消费者数量视分区而定,分区少消费者多,会导致部分消费者拿不到分区,造成消费者资源浪费,分区多消费者少,会导致一个消费者负责多个分区,可能会造成消息消费不及时,出现消息积压。建议分区数量与消费者数量相等,比如10个分区10个消费者线程,提高性能。
- 站在生产者的角度,不同的partition可以位于不同的机器(比如kafka的集群leader和follower位于不同的机器),同时可以让数据落到不同的磁盘上。(通过修改server.properties文件指定log.dirs文件位置,如log.dirs=/tmp/kafka-logs,/test/kafka-logs)
2.缓存页
充分利用操作系统的page cache
Kafka消息是持久化在磁盘上的,从磁盘读取文件是有IO的,会影响性能。从操作系统的角度而言,磁盘读取数据是按块读取的,将数据加载到内存的page cache,磁盘与内存之间的交互是以页为单位的,也就是缓存页page cache(4K),page cache是由操作系统内核来维护的。首次读取数据时将数据放到page cache,再次读取的时候直接从page cache直接获取,向磁盘写数据时也是先写page cache,当page cache达到阈值后将dirty数据(脏数据)写到磁盘,此时磁盘与缓存页数据就一致了。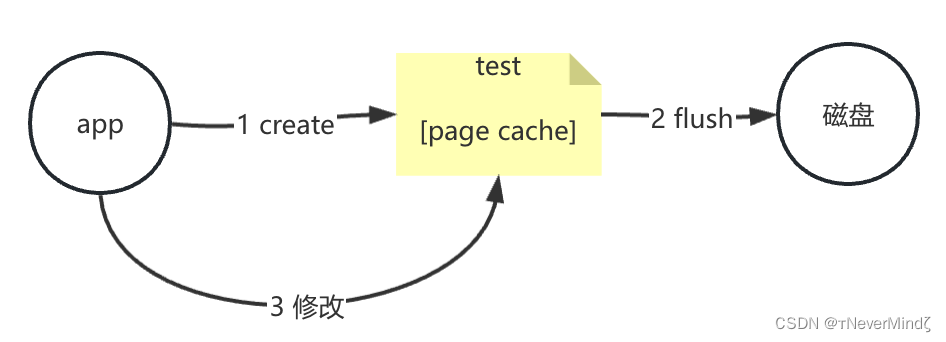
dirty数据的解释:
1.程序创建后就是dirty;
2.当缓存页page cache达到阈值后将dirty数据写到磁盘,恢复到正常状态;
3.程序修改后会再次变成dirty。
可通过修改内核关于脏数据的参数,减少硬盘IO,提升性能。
sysctl-a|grep dirty #查看脏数据
vm.dirty_background_ratio =10#后台脏数据的百分比#适当的调小(比如5),提升性能#1.避免大的阻塞,把大的IO变成多个小的IO操作#2.内存很大,磁盘性能比较差
vm.dirty_ratio =30#直接填充脏数据的百分比#建议适当调大,通过后台线程处理,而不是通过操作系统主线程来处理
vm.dirty_expire_centisecs =3000#脏数据能存活的时间#建议适当调小,尽快将数据刷到磁盘中
vm.dirty_writeback_centisecs =500#建议适当调小
3.网络开销
每次请求后响应会有很多RTT,kafka默认实现批处理。
生产者producer在发送send的时候,先将消息放到缓冲区,按批次进行处理,可通过调整参数batch.size与linger.ms来减少网络开销。
- batch.size,该参数指定一个批次可以使用的内存大小,当批次内存填满后,批次里的消息会被发送出去。
- linger.ms,该参数指定生产者在发送批次前等待更多消息加入批次的时间,也就是延迟时间,默认为0(没有延迟),它和batch.size谁先到就以哪个为准,也就是batch.size满了不管延时时间到没到都会立即发送。例如设定linger.ms=5,将会减少请求数量,但会增加5ms的延迟,也会提升消息的吞吐量。
4.压缩
通过配置参数compression.type来控制是否压缩。不论是单条还是批量发送,都可以进行压缩后传输,提升效率。
- 压缩比:一个批次中重复的数据越多,压缩比越高,数据传输效率更高;
- Broker接收到压缩消息后,并不是直接解压,消息以压缩后的形式持久化到磁盘;
- 消费者Consumer拉取消息fetch的时候,数据再解压。
5.高效的序列化
生产者producer在发送消息时会经过序列化器,默认的有jdk字符串的序列化StringSerializer,也可使用高效的序列化工具Protocol Buffer进行消息的序列化。
本文转载自: https://blog.csdn.net/anhuiwangjj/article/details/140163871
版权归原作者 τNeverMindζ 所有, 如有侵权,请联系我们删除。
版权归原作者 τNeverMindζ 所有, 如有侵权,请联系我们删除。