
在部署Hadoop HA的过程时,当进行到hdfs namenode -format格式化这一步骤时显示
org.apache.hadoop.hdfs.qjournal.client.QuorumException: Unable to check if JNs are ready for formatting. 1 exceptions thrown:拒绝连接
查阅多篇文章分析可知其原因是节点之间无法通信,所以无法建立连接
解决方法
1.首先查看配置文件hdfs中dfs.namenode.shared.edits.dir是否出错
2.查看zk集群是否启动,其次查看master和slave1上的journalnode是否启动
3.查阅其他博客有博主建议添加core-site.xml中的一个配置参数为:
<!--修改core-site.xml中的ipc参数,防止出现连接journalnode服务ConnectException-->
<property>
<name>ipc.client.connect.max.retries</name>
<value>100</value>
<description>Indicates the number of retries a client will make to establish a server connection.</description>
</property>
<property>
<name>ipc.client.connect.retry.interval</name>
<value>10000</value>
<description>Indicates the number of milliseconds a client will wait for before retrying to establish a server connection.</description>
</property>
来解决问题是否出在服务已经启动但是连接超时的的原因,但是我试了这种方法还是不行。
4.最后在不懈查找下终于找到问题所在:原来还要查看zk集群和journalnode的启动状态和启动顺序:先启动zk集群,再启动journalnode
我之前就一直出现这个报错,然后突然发现我的journalnode服务就一直没有关闭,所以如果你的zookeeper没有打开,但是你的journalnode已经启动了,那你先要关闭journalnode
而我的问题在于我在启动zk之前就启动了journalnode而且master的journalnode还不能停止?!所以最后我直接重启虚拟机,按照步骤先启动zk集群,再启动journalnode,最后把namenode重启就OK了(整个过程不需要启动namenode)
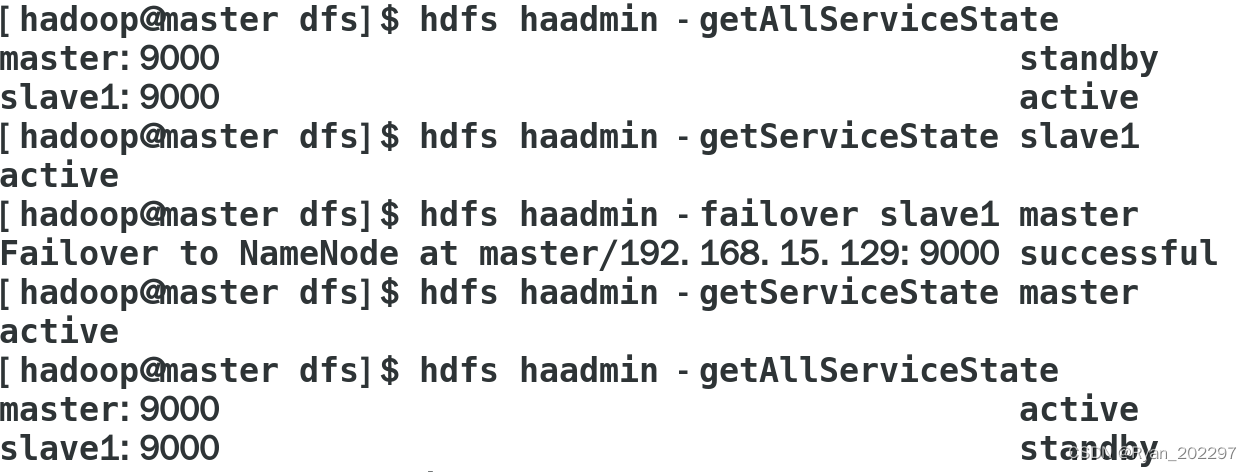
运行结果:

后续问题
启动集群后又发现slave1,slave2的datanode又没了......查看日志发现namenode的CID和两个datanode的CID不一样,所以问题出在format namenode次数过多,导致namenode和datanode的CID不一样

恢复datanode解决方法
首先把master和slave1中/usr/local/hadoop/tmp/dfs/jn/中的文件清空(避免下次format namenode时jn文件夹不为空导致再次失败),然后将slave1和slave2中/usr/local/hadoop/tmp/dfs/data 删除,之后再格式化namenode,再start-all.sh就OK了
Jps结果:

恢复备节点namenode解决方法
Jps正常之后,正常的查看了所有namenode的高可用状态,和具体master的高可用状态,然而就在切换namenode的主备状态时,发现日志报错slave1拒绝连接,再次在slave1中jps发现slave1中的namenode挂了?!查看日志发现

原来是第一次格式化后,主namenode和备namenode的version版本不一样
于是按照csdn中standby节点挂掉的恢复方法进行恢复:
1、将slave1和master中/usr/local/hadoop/tmp/dfs中name文件夹中的文件和文件夹全部删除
2、stop-all.sh将集群停止后,重新将namenode格式化,之后再重启集群Jps后又发现slave1和slave2中的datanode又挂了...........啊啊啊
不用想肯定是namenode格式化次数太多导致两个datanode的CID与namenode的CID又不同了,所以重新按步骤恢复:
同时恢复备节点namenode和datanode完整步骤
1、分别将三个节点中/usr/local/hadoop/tmp/dfs路径下core-site.xml中存放的路径目录清空,如name,data,然后把jn文件夹存放的文件也删除
2、stop-all.sh停止集群
3、在master节点中进行hdfs namenode -format格式化namenode 显示successful formatted后start-all.sh启动集群
4、启动集群后进入slave1中执行hdfs namenode -bootstrapStandby把主机namenode的ID和集群ID copy给slave1中的namenode
5、重启集群,大功告成!Jps显示正常,同时也可以正常切换namenode的主备状态!
真是一场酣畅淋漓的恢复啊!!
版权归原作者 写代码写的头好晕 所有, 如有侵权,请联系我们删除。