
MapReduce 运行原理
MapReduce简介
MapReduce是一种分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题。
MapReduce分成两个部分:Map(映射)和Reduce(归纳)。
- 当你向MapReduce框架提交一个计算作业时,它会首先把计算作业拆分成若干个Map任务,然后分配到不同的节点上去执行,每一个Map任务处理输入数据中的一部分。
- 当Map任务完成后,它会生成一些中间文件,这些中间文件将会作为Reduce任务的输入数据。Reduce任务的主要目标就是把前面若干个Map的输出汇总并输出
MapReduce 基本模式和处理思想
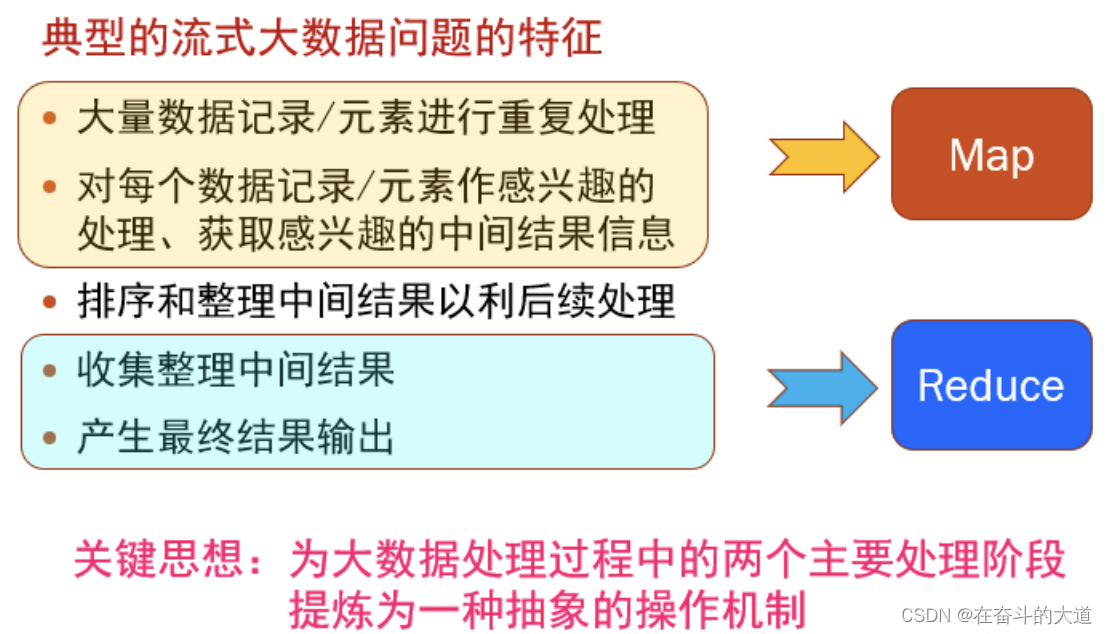
大规模数据处理时,MapReduce在三个层面上的基本构思:
1、对付大数据处理:分而治之
对相互之间不具有计算依赖关系的大数据,实现并行最自然的办法就是采取分而治之的策略。
2、上升到抽象模型:Mapper与Reduce
MPI等并行计算方法缺少高层并行编程模型,程序员需要自行指定存储,计算,分发等任务,为了克服这一缺陷,MapReduce借鉴了Lisp函数式语言中的思想,用Map和Reduce两个函数提供了高层的并发编程模型抽象。
3、上升到架构:统一架构,为程序员隐藏系统层细节
MPI等并行计算方法缺少统一的计算框架支持,程序员需要考虑数据存储、划分、分发、结果收集、错误恢复等诸多细节;为此,MapReduce设计并提供了同意的计算框架,为程序员隐藏了绝大多数系统层面的处理系统。
大数据处理:分而治之

建立Map和Reduce抽象模型
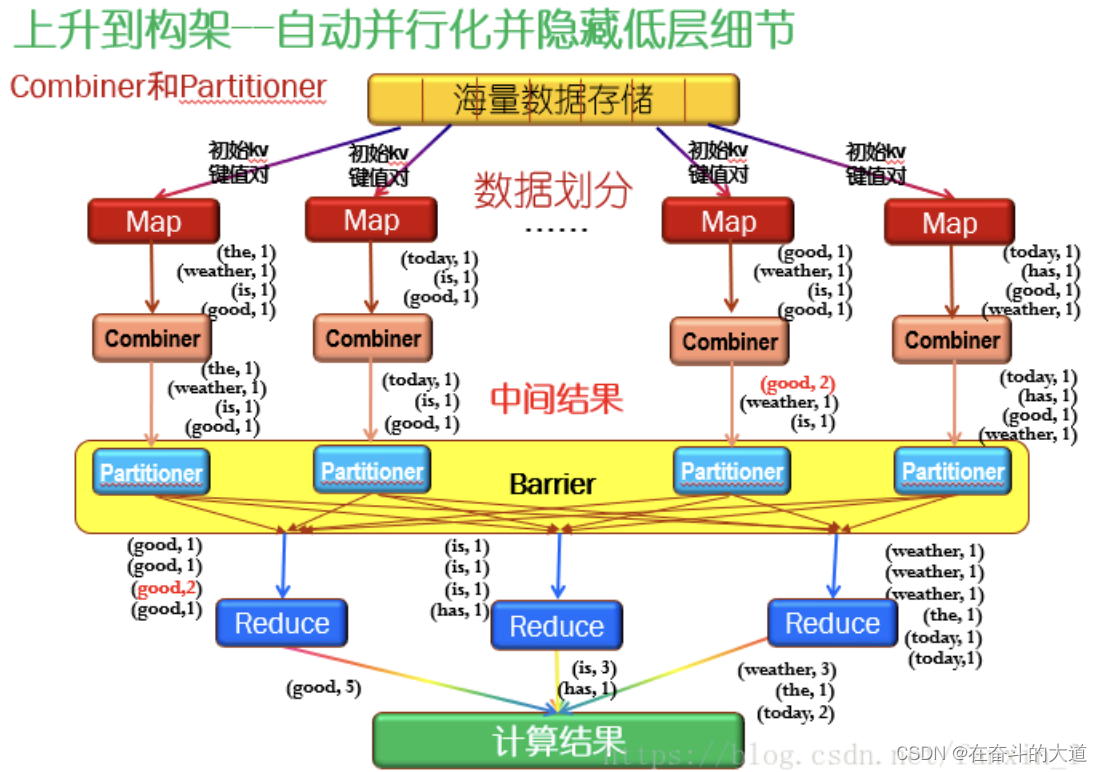
借鉴函数式程序设计语言Lisp中的思想,定义了Map和Reduce两个抽象的操作函数:
Map:(k1:v1)->[(k2:v2)]
Reduce:(k2:[v2])->[(k3:v3)]
每个map都处理结构、大小相同的初始数据块,也就是(k1:v1),其中k1是主键,可以是数据块索引,也可以是数据块地址;
v1是数据。经过Map节点的处理后,生成了很多中间数据集,用[]表示数据集的意思。而Reduce节点接收的数据是对中间数据合并后的数据,也就是把key值相等的数据合并在一起了,即(k2:[v2]);再经过Reduce处理后,生成处理结果。
上升到架构:统一架构,为程序员隐藏系统层细节
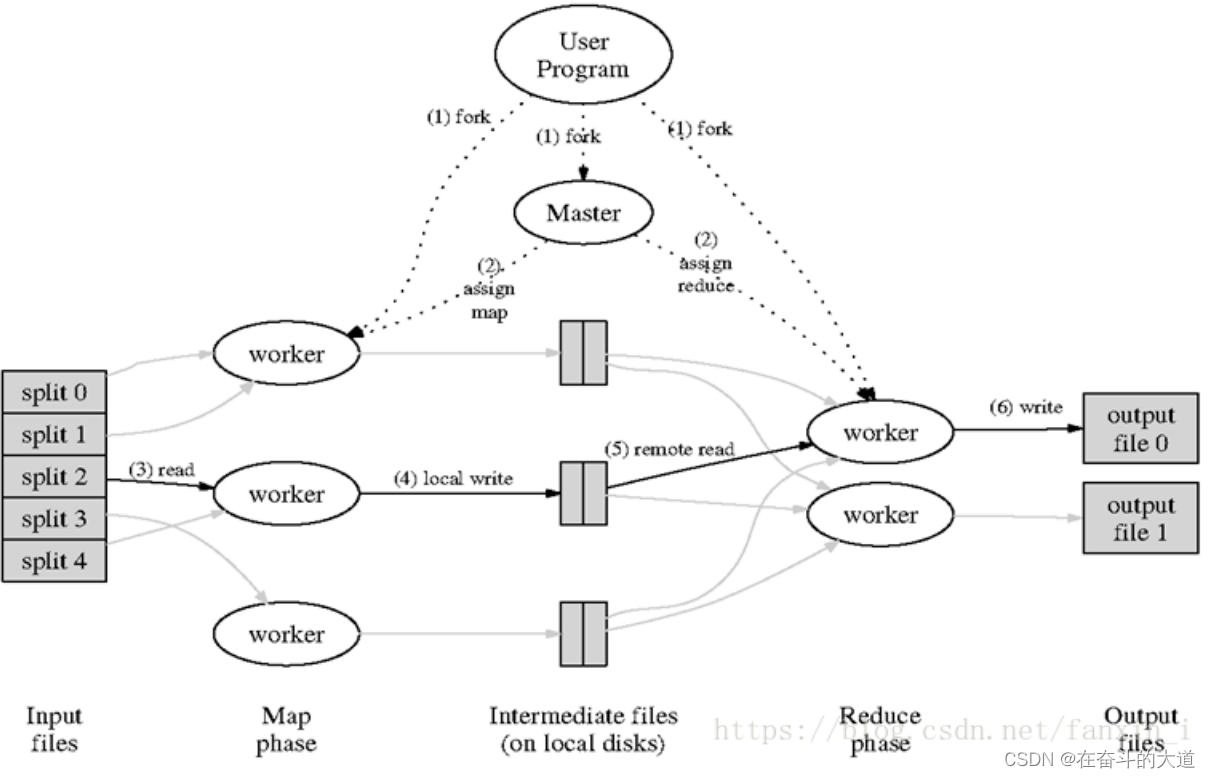
核心流程说明:
1.有一个待处理的大数据,被划分成大小相同的数据库(如64MB),以及与此相应的用户作业程序。
2.系统中有一个负责调度的主节点(Master),以及数据Map和Reduce工作节点(Worker).
3.用户作业提交个主节点。
4.主节点为作业程序寻找和配备可用的Map节点,并将程序传送给map节点。
5.主节点也为作业程序寻找和配备可用的Reduce节点,并将程序传送给Reduce节点。
6.主节点启动每一个Map节点执行程序,每个Map节点尽可能读取本地或本机架的数据进行计算。(实现代码向数据靠拢,减少集群中数据的通信量)。
7.每个Map节点处理读取的数据块,并做一些数据整理工作(combining,sorting等)并将数据存储在本地机器上;同时通知主节点计算任务完成并告知主节点中间结果数据的存储位置。
8.主节点等所有Map节点计算完成后,开始启动Reduce节点运行;Reduce节点从主节点所掌握的中间结果数据位置信息,远程读取这些数据。
9.Reduce节点计算结果汇总输出到一个结果文件,即获得整个处理结果。
Python 实现 MapReduce
Python MapReduce 代码
使用python写MapReduce的“诀窍”是利用Hadoop流的API,通过STDIN(标准输入)、STDOUT(标准输出)在Map函数和Reduce函数之间传递数据。
我们唯一需要做的是**利用Python的sys.stdin读取输入数据,并把我们的输出传送给sys.stdout。**Hadoop流将会帮助我们处理别的任何事情。
Map阶段
PyCharm 功能测试代码:
# _*_ coding : UTF-8_*_
# 开发者 : zhuozhiwengang
# 开发时间 : 2023/8/14 15:38
# 文件名称 : pythonMap_2
# 开发工具 : PyCharm
import sys
for line in sys.stdin:
line = line.strip()
words = line.split()
for word in words:
print("%s\t%s" % (word, 1))
效果截图:

Reduce阶段
PyCharm 功能测试代码:
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin:
line = line.strip()
word, count = line.split('\t', 1)
try:
count = int(count)
except ValueError: # count如果不是数字的话,直接忽略掉
continue
if current_word == word:
current_count += count
else:
if current_word:
print("%s\t%s" % (current_word, current_count))
current_count = count
current_word = word
if word == current_word: # 不要忘记最后的输出
print("%s\t%s" % (current_word, current_count))
效果截图:

Hadoop Streaming
Hadoop streaming是Hadoop的一个工具, 它帮助用户创建和运行一类特殊的map/reduce作业。
实例:我们可以用Python来编写脚本:mapper.py和reducer.py。
语法:
$HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/hadoop-streaming.jar \
-input myInputDirs \
-output myOutputDir \
-mapper mapper.py \
-reducer reducer.py
Hadoop Streaming工具会创建一个Map/Reduce作业,并把它发送给合适的集群,同时监视这个作业的整个执行过程。所以,面向具体任务,重点是我们该怎么编写python脚本呢?
总结:一、编写的代码要遵从标准输入输出流;
二、因为程序是要上传到集群上执行的,一些Python库可能是不受支持的,应要注意这点。
操作实例
待补充
版权归原作者 在奋斗的大道 所有, 如有侵权,请联系我们删除。