
专题:SQL使用技巧——实践是检验SQL函数的唯一标准
场景描述
场景一:员工信息表,根据某一员工编号查找其上级及上级的上级,直至最高权力者;或者下级及下级的下级,直至其管理下的最基层员工。
场景二:机构树,查询某一机构所对应的上级机构,直至最高机构;或者下级机构直至最末级机构
场景三:号码更换(银行卡换号不换卡),给出某一号码,查找该卡历史所有换号信息,给出的号码可能是历史的、也可能是最新的。
…
一.Orcale递归查询 start with
构建表并插入数据,orcale的insert into只能一条一条数据插入
droptableifexists tree_tb;createtable tree_tb(
employee int,
leader int,
levels varchar(10));insertinto tree_tb values(1001,1005,'L1');insertinto tree_tb values(1001,1005,'L1');insertinto tree_tb values(1002,1005,'L1');insertinto tree_tb values(1005,1008,'L2');insertinto tree_tb values(1008,1010,'L3');insertinto tree_tb values(1010,null,'L4');
执行第一个start with 递归查询
select*from tree_tb
startwith employee=1005connectby prior leader=employee
;
**递归的执行机制1:
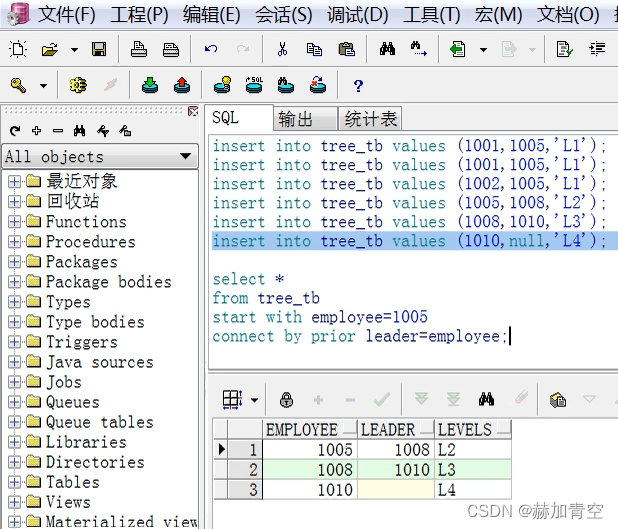
首先 from 表,然后 start with 执行筛选,得到开始的数据(例如employee=1005,leader=1008,levels=‘L2’);
第一次递归 connect by ,prior 的字段是 上一次查询的结果表 t1的leader=原表 t2的employee,即 1008=employee 执行查询得到结果(mployee=1008,leader=1010,levels=‘L3’);
第二次递归 connect by,同上,prior 的字段是 上一次查询的结果表 t2的leader=原表 t3的employee,即 1010=employee 执行查询得到结果(mployee=1010,leader=null,levels=‘L4’);
第三次递归 connect by,同上,prior 的字段是 上一次查询的结果表 t3的leader=原表 t4的employee,即 null=employee 执行查询未得到任何结果,至此递归结束;
所以,最终查询结果如下图
**
当 connect by 条件反过来时,递归方向发生变化,逻辑依然同上述过程,不赘述。
select*from tree_tb
startwith employee=1005connectby prior employee=leader
;
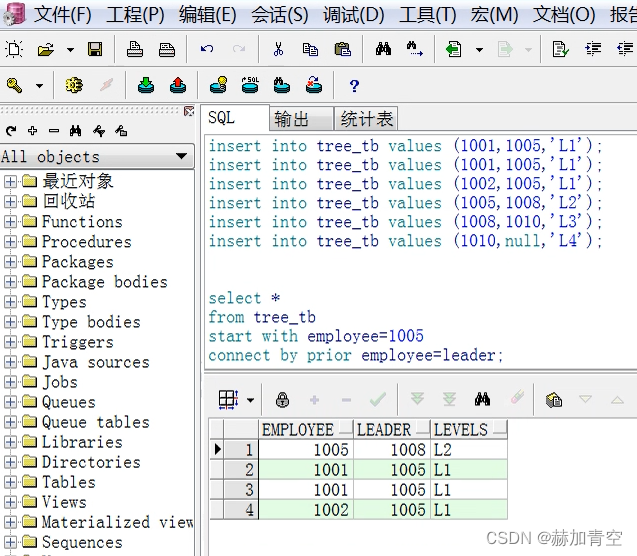
下方分别添加 and prior 和 where 并展示了查询结果。
**递归的执行机制2:
and prior 同第一个 prior一样,将上次查询的结果用来做匹配,避免多匹多造成的结果错误(下方星环TDH的案例中添加了company字段,能够更好的说明多个and prior的必要性);
where 是对结果值做最后的筛选,执行在语句的最后,由结果可以看出这一点
**
insertinto tree_tb values(1005,1006,'L2');select*from tree_tb
startwith employee=1005connectby prior leader=employee
and prior levels=levels
;select*from tree_tb
where levels <>'L3'startwith employee=1005connectby prior leader=employee
;
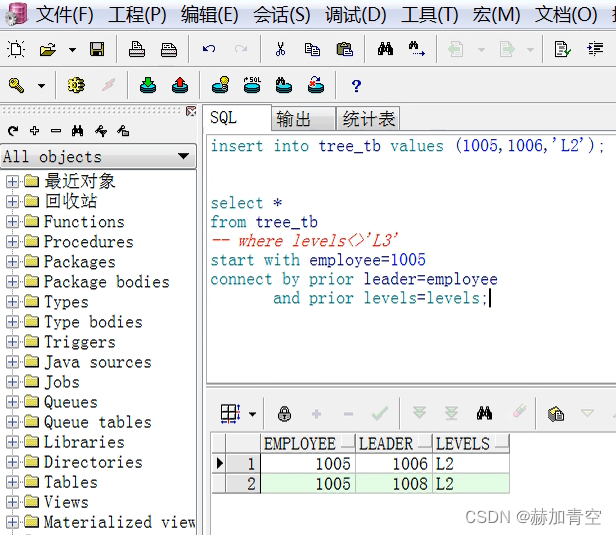
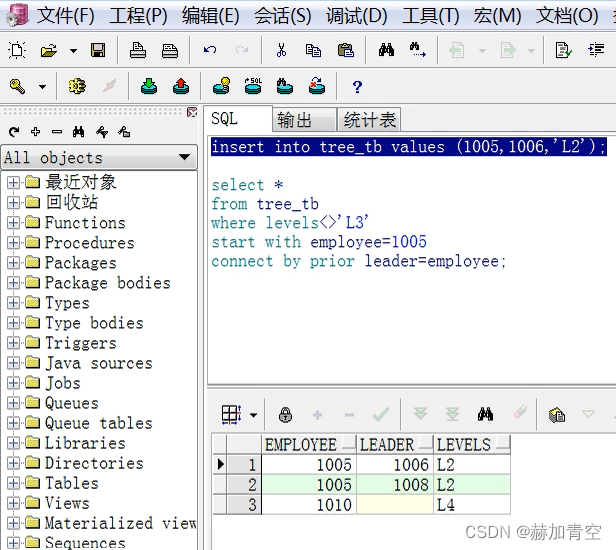
二.Hive递归查询
Hive并没有直接支持递归查询的函数,但是Hive支持Orcale语法(腾讯TDW和星环TDH)时,可以直接使用start with来实现递归查询。下方以星环TDH为例做介绍。
三.星环TDH递归查询 start with
小插曲
星环TDH不能insert into table values()插入数据,会报错
[Hive Error]: Query returned non-zero code: 10, cause: FAILED: Error in semantic analysis: Only allow to single insert into Hyperbase/Transaction Orc/Holodesk, other data destination not allowed。
(亲测hive中并无此限制),TDH中即使改成了orc也不可以,因此采用下方insert into table select…完成数据插入。
为了更好的展示 and prior 的重要性和理解start with的查询机制,这次的数据添加了 company 字段,下方案例将进一步说明递归的机制。
droptableifexists tree_tb;createtable tree_tb(
employee int,
leader int,
levels varchar(10),
company varchar(10));insertinto tree_tb
select1001,1005,'L1','百度'from system.dual
unionallselect1002,1005,'L1','百度'from system.dual
unionallselect1005,1006,'L2','百度'from system.dual
unionallselect1005,1008,'L2','百度'from system.dual
unionallselect1008,1010,'L3','百度'from system.dual
unionallselect1010,null,'L4','百度'from system.dual
unionallselect1001,1005,'L1','腾讯'from system.dual
unionallselect1005,1006,'L1','腾讯'from system.dual
unionallselect1005,1008,'L2','腾讯'from system.dual
unionallselect1008,1010,'L3','腾讯'from system.dual
unionallselect1010,null,'L4','腾讯'from system.dual
;
递归的执行机制:上述orcale中已明确,不再赘述
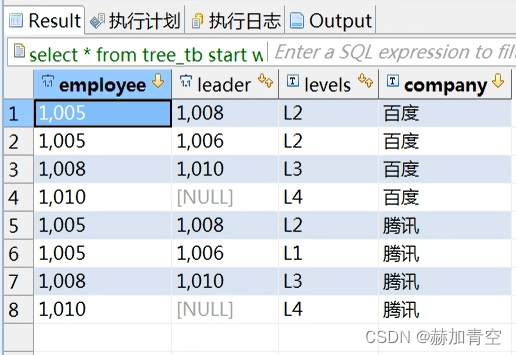
-- 不加 and prior company=company 会出现多匹多select*from tree_tb
startwith employee=1005connectby prior leader=employee
and prior company=company
;
结果可以看出,当添加了 and prior company=company 条件,数据可以正确提出,否则会出现数据翻倍和逻辑错误。
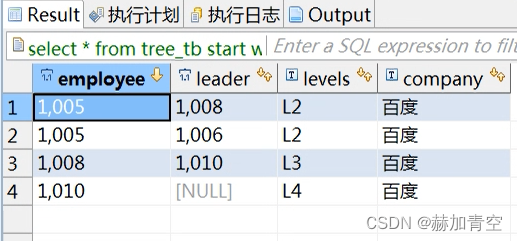
start with 可以增加 and 条件完成初次取数,这个条件只能加在这里,不能加在where中,因为where的条件是最后执行的
-- start with 可以加初始查询条件select*from tree_tb
startwith employee=1005and company='百度'connectby prior leader=employee
and prior company=company
;
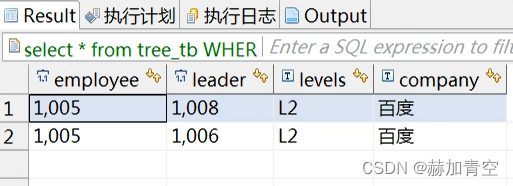
where的条件是最后执行的,用来限制最后的查询结果符合条件。
-- where 执行在最后,按照条件过滤结果数据select*from tree_tb
where levels='L2'startwith employee=1005and company='百度'connectby prior leader=employee
and prior company=company
;
四.帆软配置递归查询
帆软递归的语法实现,主要由连接的数据库决定,例如这里使用的是星环TDH,写法如下。当配置库为Postgresql时,见SQL使用技巧(3.1)递归层次查询Postgresql,更多数据库使用方法同理。
帆软前台的配置方法见下方两篇文章,不再赘述。
SQL使用技巧(3.1)递归层次查询Postgresql
FineReport帆软报表使用入门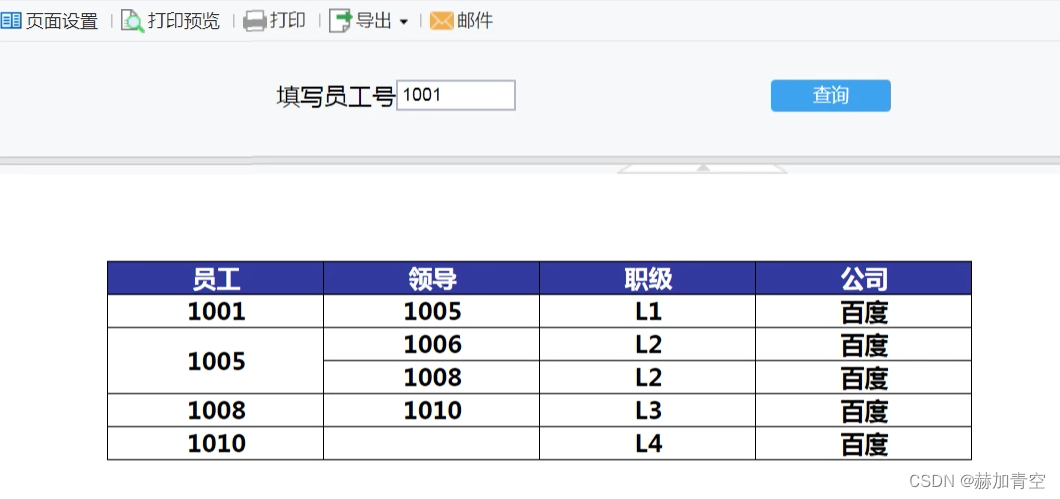
声明:本文所载信息不保证准确性和完整性。文中所述内容和意见仅供参考,不构成实际商业建议,如有雷同纯属巧合。
版权归原作者 赫加青空 所有, 如有侵权,请联系我们删除。