

这个是最开始的数据:乱七八糟的,要取出其中的一些,类似这些

其中毫秒级的时间数据要转为时间戳
spark先过滤出要取的数据
package sparkj;
import java.text.SimpleDateFormat;
import java.util.Arrays;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
public class sp {
public static void main(String[] args) {
// TODO Auto-generated method stub
SparkConf sparkConf = new SparkConf().setAppName("PeopleInfoCalculator").setMaster("local[2]");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
JavaRDD<String> filedata=sc.textFile("file:///root/555.txt");
JavaRDD<String> data2=filedata.filter(f->f.matches("[0-9].*"))
.map(f->String2Date(f.split(" ")[0],f.split(" ")[1])+" "+f.split(" ")[2]+" "+f.split(" ")[3].split(":")[0]);
data2.foreach(f->System.err.println(f));
//data2.saveAsTextFile("file:///root/555copy.txt");
// JavaPairRDD<String,Integer> rdd6=filedata.mapToPair(f->new Tuple2<>(f.split(",")[1],1));
// JavaPairRDD<String,Integer> rdd7=rdd6.reduceByKey((x,y)->x+y);
//rdd7.foreach(f->System.err.println(f));
}
public static long String2Date(String date,String time) throws Exception{
String newdate = date + " " + time;
SimpleDateFormat s = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss,SSS");
return s.parse(newdate).getTime();
}
}
结果如下: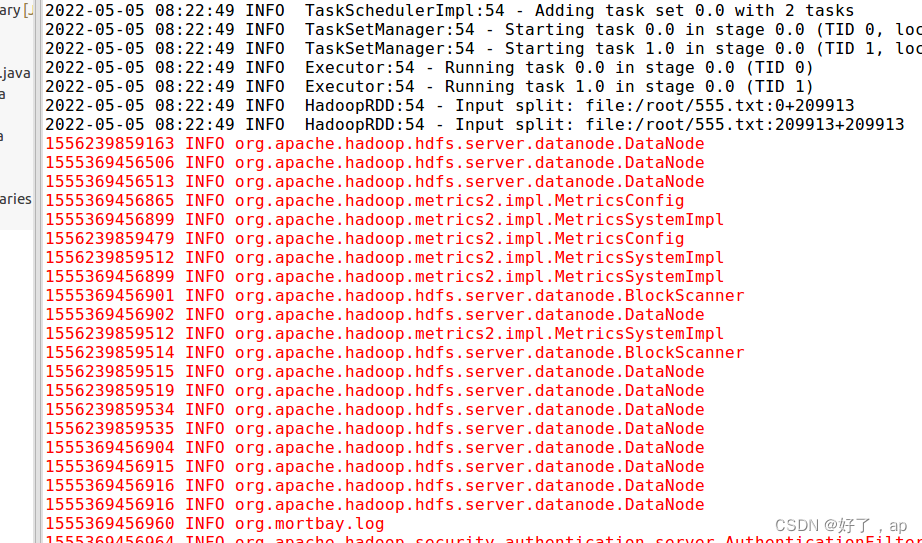
打开hbase,对hbase进行操作了,先start...,
root@master:/opt/hbase-1.3.3/bin# ./start-hbase.sh
starting master, logging to /opt/hbase-1.3.3/bin/../logs/hbase-root-master-master.out
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
root@master:/opt/hbase-1.3.3/bin# ./hbase shell
2022-05-05 07:21:22,172 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 1.3.3, ra75a458e0c8f3c60db57f30ec4b06a606c9027b4, Fri Dec 14 16:02:53 PST 2018
hbase(main):001:0> list
TABLE
hbase单词计数
单独的hbase写法
主函数:
package test1;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Scanner;
public class MainHB1 {
private static String getType(Object a) {
return a.getClass().toString();
}
public static void main(String[] args) throws Exception {
// try {
// HBaseOp ho = new HBaseOp();
// String tab = "logData1";
// String[] name = new String[1];
// name[0] = "log";
// ho.createTable(tab, name);
// System.out.println("ok");
// } catch (Exception e) {
// e.printStackTrace();
// }
try {
HBaseOp ho = new HBaseOp();
String tab = "logData1";
String[] name = new String[1];
name[0] = "log";
//ho.filterByRowFilter(tab, "class","info");
//ho.filterBySingleColumnValueFilter(tab, "log","level","");
System.out.println("ERROR一共是");
ho.filterBySingleColumnValueFilter(tab, "log","level","ERROR");
System.out.println("FATAL一共是");
ho.filterBySingleColumnValueFilter(tab, "log","level","FATAL");
System.out.println("ok");
} catch (Exception e) {
e.printStackTrace();
}
File file = new File("/root/555copy.txt");
System.out.println("插入数据成功");
System.out.println(" \\n" +
"\\\n" +
"");
BufferedReader br = new BufferedReader(new FileReader(file));
String s;
String[] column = new String[2];
column[0] = "level";
column[1] = "class";
int i = 0;
while ((s = br.readLine()) != null) {
String line[] = s.split(" ");
long t = Long.parseLong(line[0]);
String time = String.valueOf(Long.MAX_VALUE-t);
try {
HBaseOp ho = new HBaseOp();
String tab = "logData1";
String name = "log";
// ho.put(tab,time, name,column[0], line[1]);
// ho.put(tab,time, name,column[1], line[2]);
} catch (Exception e) {
e.printStackTrace();
}
}
System.out.println(i);
System.out.println("ok");
}
}
类的方法
package test1;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.BinaryComparator;
import org.apache.hadoop.hbase.filter.CompareFilter;
//import org.apache.hadoop.hbase.filter.CompareOp;
import org.apache.hadoop.hbase.filter.FilterList;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.filter.CompareFilter.CompareOp;
import org.apache.hadoop.hbase.util.Bytes;
public class HBaseOp {
class P{
String row;
String[] colum;
}
// TODO Auto-generated method stub
Configuration conf=HBaseConfiguration.create();
public void createTable(String strTab,String[] arrCf) throws Exception{
HBaseAdmin admin=new HBaseAdmin(conf);
if(admin.tableExists(strTab)) {
System.out.println("Table"+strTab+"exists.");
}
else {
HTableDescriptor fs=new HTableDescriptor(strTab);
for(String cf:arrCf) {
HColumnDescriptor ff=new HColumnDescriptor(cf);
ff.setTimeToLive(10000);
fs.addFamily(ff);
}
admin.createTable(fs);
}
admin.close();
}
public void deleteTable(String strTab)throws Exception
{
HBaseAdmin admin = new HBaseAdmin(conf);
if (!admin.tableExists(strTab)) {//判断表是否存在
System.out.println(strTab + "不存在");
}
else if(admin.isTableEnabled(strTab)) {//如果表处于disable
admin.disableTable(strTab);
admin.deleteTable(strTab);
System.out.println(strTab + " deleted");
}
else
{
admin.deleteTable(strTab);
System.out.println(strTab + " deleted");
}
admin.close();
}
//
public void mulPut() throws Exception {
HTable table = new HTable(conf,"scores");
// 创建一个列表用于存放Put实例
List<Put> puts = new ArrayList<Put>();
// 将第一个Put实例添加到列表
Put put1 = new Put(Bytes.toBytes("Tom"));
put1.add(Bytes.toBytes("grade"), Bytes.toBytes(""), Bytes.toBytes("1"));
put1.add(Bytes.toBytes("course"), Bytes.toBytes("math"), Bytes.toBytes("990"));
puts.add(put1);
// 将第2个Put实例添加到列表
Put put2 = new Put(Bytes.toBytes("John"));
put2.add(Bytes.toBytes("grade"), Bytes.toBytes(""), Bytes.toBytes("2"));
put2.add(Bytes.toBytes("course"), Bytes.toBytes("Chinese"), Bytes.toBytes("99"));
puts.add(put2);
// 将第3个Put实例添加到列表
Put put3 = new Put(Bytes.toBytes("gyy"));
put3.add(Bytes.toBytes("grade"), Bytes.toBytes(""), Bytes.toBytes("12"));
put3.add(Bytes.toBytes("course"), Bytes.toBytes("math"), Bytes.toBytes("1000"));
put3.add(Bytes.toBytes("course"), Bytes.toBytes("geo"), Bytes.toBytes("1000"));
put3.add(Bytes.toBytes("course"), Bytes.toBytes("语文"), Bytes.toBytes("1000"));
// 向HBase中存入多行多列数据
puts.add(put3);
table.put(puts);
table.close();
}
//
public void put(String tablename,String row,String cf,String column,String data) throws Exception{
HTable table=new HTable(conf,tablename);
Put p=new Put(Bytes.toBytes(row));
p.add(Bytes.toBytes(cf), Bytes.toBytes(column), Bytes.toBytes(data));
table.put(p);
table.close();
}
public void filterBySingleColumnValueFilter(String tablename, String strF, String strC, String strClass) throws Exception
{
HTable table = new HTable(conf, tablename);
Scan s = new Scan();
SingleColumnValueFilter sf =
new SingleColumnValueFilter(Bytes.toBytes(strF),
Bytes.toBytes(strC), CompareOp.EQUAL,
Bytes.toBytes(strClass));
s.setFilter(sf);
ResultScanner rs = table.getScanner(s);
HashMap<String, Integer> hashMap = new HashMap<>();
int i=0;
for (Result r : rs) {
i=i+1;
byte[] row = r.getRow();
byte[] value = r.getValue(Bytes.toBytes(strF), Bytes.toBytes(strC));
byte[] value2 = r.getValue(Bytes.toBytes(strF), Bytes.toBytes("class"));
if(!hashMap.containsKey(Bytes.toString(value2))) {
//集合中没有该单词,值定义为1
hashMap.put(Bytes.toString(value2), 1);
}else if(hashMap.containsKey(Bytes.toString(value2))) {
//集合中有该单词,值+1;key不变;
int b=hashMap.get(Bytes.toString(value2));
hashMap.put(Bytes.toString(value2), b+1);
}
// System.out.println("Filter: " + Bytes.toString(row) + " is in " + strC + " " + Bytes.toString(value)+", class " + Bytes.toString(value2));
}
System.out.println(hashMap);
// System.out.println( " ERROR一共是="+i);
System.out.println("出现最多的类是:"+getProcessCdByName(hashMap));
System.out.println(" FATAL一共是="+i);
rs.close();
table.close();
}
public static String getProcessCdByName(HashMap<String, Integer> processMap){//我找最大值对应的哪一个键
int max=0;
for (Integer in : processMap.values()) {
System.err.println(in);
max=Math.max(max, in);
}
String result = null;
Set<Map.Entry<String, Integer>> set = processMap.entrySet();
for(Map.Entry<String, Integer> entry : set){
if(entry.getValue()==max){
result = entry.getKey();
break;
}
}
return result;
}
public void filterBySingleColumnValueFilter(String tablename, String cf, String C) throws Exception
{
HTable table = new HTable(conf, tablename);
Scan s = new Scan();
SingleColumnValueFilter sf =
new SingleColumnValueFilter(Bytes.toBytes(cf),
Bytes.toBytes(C), CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes("ERROR")));
SingleColumnValueFilter sf2 =
new SingleColumnValueFilter(Bytes.toBytes(cf),
Bytes.toBytes(C), CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes("FATAL")));
FilterList lst= new FilterList(
FilterList.Operator.MUST_PASS_ONE);
lst.addFilter(sf);
lst.addFilter(sf2);
s.setFilter(lst);
ResultScanner rs = table.getScanner(s);
int i =0;
for (Result r : rs) {
byte[] row = r.getRow();
byte[] value = r.getValue(Bytes.toBytes(cf), Bytes.toBytes(C));
byte[] value2 = r.getValue(Bytes.toBytes(cf), Bytes.toBytes("class"));
System.out.println("--------------------------");
System.out.println("Filter: " + Bytes.toString(row) + " is in " + C + " " + Bytes.toString(value)+", class " + Bytes.toString(value2));
i=i+1;
}
System.out.println(i);
rs.close();
table.close();
}
//public void filterBySingleColumnValueFilter(String tablename, String strF, String strC, String strClass) throws Exception
//{
// HTable table = new HTable(conf, tablename);
// Scan s = new Scan();
// SingleColumnValueFilter sf =
// new SingleColumnValueFilter(Bytes.toBytes(strF),
// Bytes.toBytes(strC), CompareOp.EQUAL,
// Bytes.toBytes(strClass));
// s.setFilter(sf);
//
// ResultScanner rs = table.getScanner(s);
//
// for (Result r : rs) {
// byte[] row = r.getRow();
// byte[] value = r.getValue(Bytes.toBytes(strF), Bytes.toBytes(strC));
// byte[] value2 = r.getValue(Bytes.toBytes(strF), Bytes.toBytes("class"));
// System.out.println("Filter: " + Bytes.toString(row) + " is in " + strC + " " + Bytes.toString(value)+", class " + Bytes.toString(value2));
// }
// rs.close();
// table.close();
//}
public void filterBySingleColumnValueFilter(String tablename, String strF, String strC, String strClass) throws Exception
{
HTable table = new HTable(conf, tablename);
Scan s = new Scan();
SingleColumnValueFilter sf =
new SingleColumnValueFilter(Bytes.toBytes(strF),
Bytes.toBytes(strC), CompareOp.EQUAL,
Bytes.toBytes(strClass));
s.setFilter(sf);
ResultScanner rs = table.getScanner(s);
HashMap<String, Integer> hashMap = new HashMap<>();
int i=0;
for (Result r : rs) {
i=i+1;
byte[] row = r.getRow();
byte[] value = r.getValue(Bytes.toBytes(strF), Bytes.toBytes(strC));
byte[] value2 = r.getValue(Bytes.toBytes(strF), Bytes.toBytes("class"));
if(!hashMap.containsKey(Bytes.toString(value2))) {
//集合中没有该单词,值定义为1
hashMap.put(Bytes.toString(value2), 1);
}else if(hashMap.containsKey(Bytes.toString(value2))) {
//集合中有该单词,值+1;key不变;
int b=hashMap.get(Bytes.toString(value2));
hashMap.put(Bytes.toString(value2), b+1);
}
// System.out.println("Filter: " + Bytes.toString(row) + " is in " + strC + " " + Bytes.toString(value)+", class " + Bytes.toString(value2));
}
System.out.println(hashMap);
System.out.println("i="+i);
rs.close();
table.close();
}
public void get(String tablename,String row,String info,String name) throws Exception{
HTable table=new HTable(conf,tablename);
Get g=new Get(Bytes.toBytes(row));
Result result = table.get(g);
byte[] val = result.getValue(Bytes.toBytes(info),Bytes.toBytes(name));
System.out.println(info+" "+name+" "+"Values =" + Bytes.toString(val));
}
public void scan(String tablename,String cf,String column) throws Exception{
HTable table=new HTable(conf,tablename);
Scan s=new Scan();
s.setStartRow(Bytes.toBytes("0"));
s.setStopRow(Bytes.toBytes("g"));
// s.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"));
ResultScanner res=table.getScanner(s);
for(Result r:res) {
byte[] row=r.getRow();
byte[] val=r.getValue(Bytes.toBytes(cf), Bytes.toBytes(column));
System.out.println("Scan:"+Bytes.toString(row)
+" values is "+Bytes.toString(val));
}
res.close();
table.close();
}
public void delete(String tablename,String row,String cf,String column,String data) throws Exception{
HTable table=new HTable(conf,tablename);
List<Delete> ls=new ArrayList<Delete>();
Delete p=new Delete(Bytes.toBytes(row));
ls.add(p);
//p.add(Bytes.toBytes(cf), Bytes.toBytes(column), Bytes.toBytes(data));
table.delete(ls);
table.close();
}
}
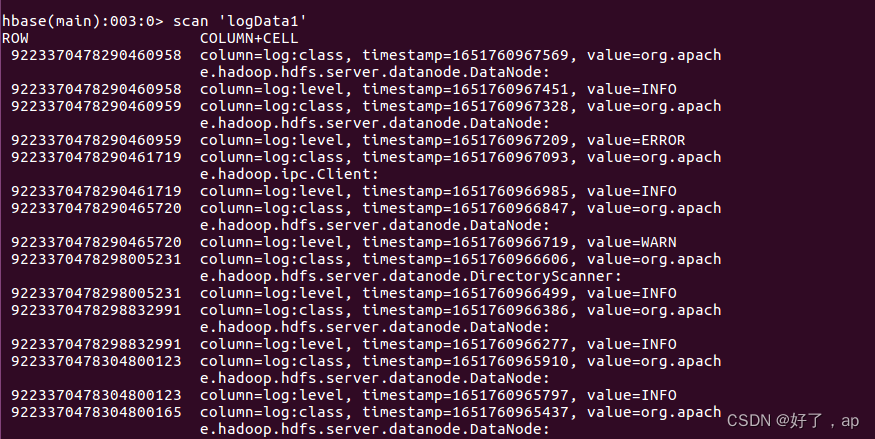
插进表里面这种数据貌似是对的

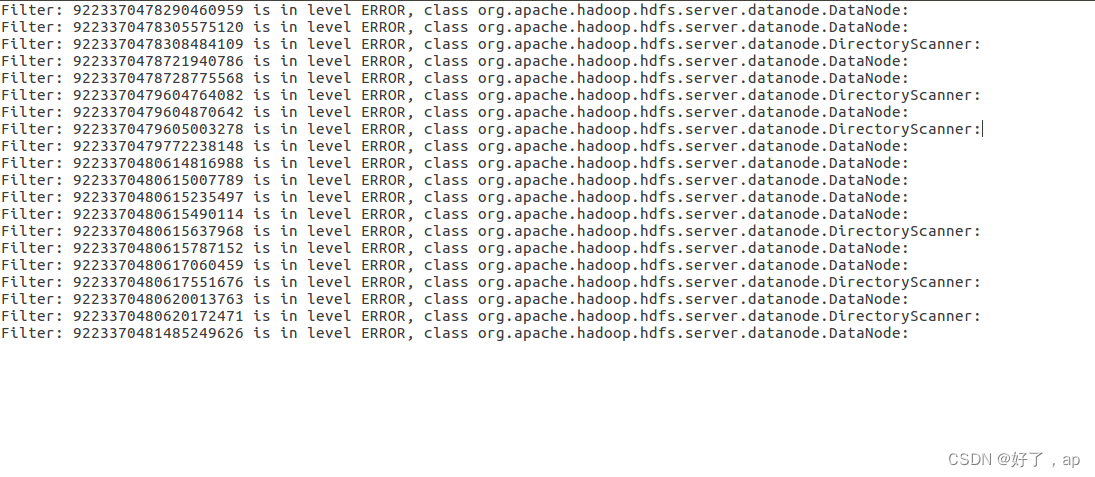
或者直接用spark简单粗暴过滤这个,这个是这一句直接来的
先hbase主函数这个:
ho.filterBySingleColumnValueFilter(tab, "log","level","ERROR");
会有一个数据产生,把数据拷贝到一个文件里面,再spark单词计数哈哈哈
方法类这样:
public void filterBySingleColumnValueFilter1(String tablename, String strF, String strC, String strClass) throws Exception
{
HTable table = new HTable(conf, tablename);
Scan s = new Scan();
SingleColumnValueFilter sf =
new SingleColumnValueFilter(Bytes.toBytes(strF),
Bytes.toBytes(strC), CompareOp.EQUAL,
Bytes.toBytes(strClass));
s.setFilter(sf);ResultScanner rs = table.getScanner(s); for (Result r : rs) { byte[] row = r.getRow(); byte[] value = r.getValue(Bytes.toBytes(strF), Bytes.toBytes(strC)); byte[] value2 = r.getValue(Bytes.toBytes(strF), Bytes.toBytes("class")); System.out.println("Filter: " + Bytes.toString(row) + " is in " + strC + " " + Bytes.toString(value)+", class " + Bytes.toString(value2)); } rs.close(); table.close();}
package sparkj;
import java.text.SimpleDateFormat;
import java.util.Arrays;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
public class sp {
public static void main(String[] args) {
// TODO Auto-generated method stub
SparkConf sparkConf = new SparkConf().setAppName("PeopleInfoCalculator").setMaster("local[2]");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
JavaRDD<String> filedata=sc.textFile("file:///root/555.txt");
// JavaRDD<String> data2=filedata.filter(f->f.matches("[0-9].*"))
// .map(f->String2Date(f.split(" ")[0],f.split(" ")[1])+" "+f.split(" ")[2]+" "+f.split(" ")[3].split(":")[0]);
//
// data2.foreach(f->System.err.println(f));
// data2.saveAsTextFile("file:///root/555copy.txt");
JavaPairRDD<String,Integer> rdd6=filedata.mapToPair(f->new Tuple2<>(f.split(",")[1],1));
JavaPairRDD<String,Integer> rdd7=rdd6.reduceByKey((x,y)->x+y);
rdd7.foreach(f->System.err.println(f));
}
public static long String2Date(String date,String time) throws Exception{
String newdate = date + " " + time;
SimpleDateFormat s = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss,SSS");
return s.parse(newdate).getTime();
}
}
最后结果
本文转载自: https://blog.csdn.net/m0_53291740/article/details/124600044
版权归原作者 好了,ap 所有, 如有侵权,请联系我们删除。
版权归原作者 好了,ap 所有, 如有侵权,请联系我们删除。