
文章目录
前言
通常在生产环境中,Kafka都是用来应对整个项目中最高峰的流量的。这种极高的请求流量,对任何服务都是一个很大的负担,因此如果在生产环境中部署Kafka,也可以从以下几个方面进行一些优化。
觉得不错的同学可以加我公众号,会经常分享一些技术干货,以及热点AI和科技新闻
一、搭建Kafka监控平台
生产环境通常会对Kafka搭建监控平台。而Kafka-eagle就是一个可以监控Kafka集群整体运行情况的框架,在生产环境经常会用到。官网地址:https://www.kafka-eagle.org/ 以前叫做Kafka-eagle,现在用了个简写,EFAK(Eagle For Apache Kafka)
1.1 环境准备
在官网的DownLoad页面可以下载EFAK的运行包,efak-web-3.0.2-bin.tar.gz。
另外,EFAK需要依赖的环境主要是Java和数据库。其中,数据库支持本地化的SQLLite以及集中式的MySQL。生产环境建议使用MySQL。在搭建EFAK之前,需要准备好对应的服务器以及MySQL数据库。
略过MySQL服务搭建过程。
数据库不需要初始化,EFAK在执行过程中会自己完成初始化。
1.2 安装过程
以Linux服务器为例。
1、将efak压缩包解压。
tar -zxvf efak-web-3.0.2-bin.tar.gz -C /app/kafka/eagle
2、修改efak解压目录下的conf/system-config.properties。 这个文件中提供了完整的配置,下面只列出需要修改的部分。
######################################
# multi zookeeper & kafka cluster list
# Settings prefixed with 'kafka.eagle.' will be deprecated, use 'efak.' instead
######################################
# 指向Zookeeper地址
efak.zk.cluster.alias=cluster1
cluster1.zk.list=zkworker1:2181,zkworker2:2181,zkworker3:2181
######################################
# zookeeper enable acl
######################################
# Zookeeper权限控制
cluster1.zk.acl.enable=false
cluster1.zk.acl.schema=digest
#cluster1.zk.acl.username=test
#cluster1.zk.acl.password=test
######################################
# kafka offset storage
######################################
# offset选择存在kafka中。
cluster1.efak.offset.storage=kafka
#cluster2.efak.offset.storage=zk
######################################
# kafka mysql jdbc driver address
######################################
#指向自己的MySQL服务。库需要提前创建
efak.driver=com.mysql.cj.jdbc.Driver
efak.url=jdbc:mysql://mysqlworker1:3306/db?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
efak.username=root
efak.password=root
3、配置EFAK的环境变量
vi ~/.bash_profile
-- 配置KE_HOME环境变量,并添加到PATH中。
export KE_HOME=/app/kafka/eagle/efak-web-3.0.2
PATH=$PATH:#KE_HOME/bin:$HOME/.local/bin:$HOME/bin--让环境变量生效
source ~/.bash_profile
4、启动EFAK
配置完成后,先启动Zookeeper和Kafka服务,然后调用EFAK的bin目录下的ke.sh脚本启动服务
./ke.sh start
5、访问EFAK管理页面
接下来就可以访问EFAK的管理页面。http://192.168.123.123:8048。默认的用户名是admin ,密码是123456
关于EFAK更多的使用方式,比如EFAK服务如何集群部署等,可以参考官方文档。https://docs.kafka-eagle.org/
二、合理规划Kafka部署环境
机械硬盘:对于准备部署Kafka服务的服务器,建议配置大容量机械硬盘。Kakfa顺序读写的实现方式不太需要SSD这样高性能的磁盘。同等容量SSD硬盘的成本比机械硬盘要高出非常多,没有必要。将SSD的成本投入到MySQL这类的服务更合适。
大内存:在Kafka的服务启动脚本bin/kafka-start-server.sh中,对于JVM内存的规划是比较小的,可以根据之前JVM调优专题中的经验进行适当优化。
脚本中的JVM内存参数默认只申请了1G内存。
$ cat kafka-server-start.sh
......if["x$KAFKA_HEAP_OPTS" = "x"]; then
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi
......
对于主流的16核32G服务器,可以适当扩大Kafka的内存。例如:
export KAFKA_HEAP_OPTS="‐Xmx16G ‐Xms16G ‐Xmn10G ‐XX:MetaspaceSize=256M ‐XX:+UseG1GC ‐XX:MaxGCPauseMillis=50 ‐XX:G1HeapRegionSize=16M"
高性能网卡:Kafka本身的服务性能非常高,单机就可以支持百万级的TPS。在高流量冲击下,网络非常有可能优先于服务,成为性能瓶颈。并且Kafka集群内部也需要大量同步消息。因此,对于Kafka服务器,建议配置高性能的网卡。成本允许的话,尽量选择千兆以上的网卡。
三、合理优化Kafka集群配置
合理配置Partition数量: Kafka的单个Partition读写效率是非常高的,但是,Kafka的Partition设计是非常碎片化的。如果Partition文件过多,很容易严重影响Kafka的整体性能。
控制Partition文件数量主要有两个方面:
1、尽量不要使用过多的Topic,通常不建议超过3个Topic。过多的Topic会加大索引Partition文件的压力。
2、每个Topic的副本数不要设置太多。大部分情况下,将副本数设置为2就可以了。
至于Partition的数量,最好根据业务情况灵活调整。partition数量设置多一些,可以一定程度增加Topic的吞吐量。但是过多的partition数量还是同样会带来partition索引的压力。因此,需要根据业务情况灵活进行调整,尽量选择一个折中的配置。
Kafka提供了一个生产者的性能压测脚本,可以用来衡量集群的整体性能。
# num-record表示要发送100000条压测消息,# record-size表示每条消息大小1KB,# throughput表示限流控制,设置为小于0表示不限流。# properducer-props用来设置生产者的参数。
$ ./kafka-producer-perf-test.sh --topic test --num-record 1000000 --record-size 1024 --
四、合理对数据进行压缩
在生产者的ProducerConfig中,有一个配置 COMPRESSION_TYPE_CONFIG,是用来对消息进行压缩的。
/** <code>compression.type</code> */publicstaticfinalStringCOMPRESSION_TYPE_CONFIG="compression.type";privatestaticfinalStringCOMPRESSION_TYPE_DOC="The compression type for all data generated by the producer. The default is none (i.e. no compression). Valid "+" values are <code>none</code>, <code>gzip</code>, <code>snappy</code>, <code>lz4</code>, or <code>zstd</code>. "+"Compression is of full batches of data, so the efficacy of batching will also impact the compression ratio (more batching means better compression).";
生产者配置了压缩策略后,会对生产的每个消息进行压缩,从而降低Producer到Broker的网络传输,也降低了Broker的数据存储压力。
从介绍中可以看到,Kafka的生产者支持四种压缩算法。这几种压缩算法中:
- zstd算法具有最高的数据压缩比,但是吞吐量不高。
- lz4在吞吐量方面的优势比较明显。
在实际使用时,可以根据业务情况选择合适的压缩算法。但是要注意下,压缩消息必然增加CPU的消耗,如果CPU资源紧张,就不要压缩了。
关于数据压缩机制,在Broker端的broker.conf文件中,也是可以配置压缩算法的。正常情况下,Broker从Producer端接收到消息后不会对其进行任何修改,但是如果Broker端和Producer端指定了不同的压缩算法,就会产生很多异常的表现。
compression.type
Specify the final compression typefor a given topic. This configuration accepts the standard compression codecs ('gzip','snappy','lz4','zstd'). It additionally accepts 'uncompressed' which is equivalent to no compression; and 'producer' which means retain the original compression codec set by the producer.Type: string
Default: producer
Valid Values: [uncompressed, zstd, lz4, snappy, gzip, producer]
Server Default Property: compression.type
Importance: medium
如果开启了消息压缩,那么在消费者端自然是要进行解压缩的。在Kafka中,消息从Producer到Broker再到Consumer会一直携带消息的压缩方式,这样当Consumer读取到消息集合时,自然就知道了这些消息使用的是哪种压缩算法,也就可以自己进行解压了。但是这时要注意的是应用中使用的Kafka客户端版本和Kafka服务端版本是否匹配。
五、优化Kafka客户端使用方式
在使用Kafka时,也需要根据业务情况灵活进行调整,选择最合理的Kafka使用方式。
5.1 合理保证消息安全
在生产者端最好从以下几个方面进行优化。
- 设置好发送者应答参数:主要涉及到两个参数。- 一个是生产者的ACKS_CONFIG配置。acks=0,生产者不关心Broker端有没有将消息写入到Partition,只发送消息就不管了。acks=all or -1,生产者需要等Broker端的所有Partiton(Leader Partition以及其对应的Follower Partition都写完了才能得到返回结果,这样数据是最安全的,但是每次发消息需要等待更长的时间,吞吐量是最低的。acks设置成1,则是一种相对中和的策略。Leader Partition在完成自己的消息写入后,就向生产者返回结果。、其中acks=1是应用最广的一种方案。但是,如果结合服务端的min.insync.replicas参数,就可以配置更灵活的方式。- min.insync.replicas参数表示如果生产者的acks设置为-1或all,服务端并不是强行要求所有Paritition都完成写入再返回,而是可以配置多少个Partition完成消息写入后,再往Producer返回消息。比如,对于一个Topic,设置他的备份因子replication factor为3,然后将min.insync.replicas参数配置为2,而生产者端将ACKS_CONFIG设定为-1或all,这样就能在消息安全性和发送效率之间进行灵活选择。
- 打开生产者端的幂等性配置:ENABLE_IDEMPOTENCE_CONFIG。 生产者将这个参数设置为true后,服务端会根据生产者实例以及消息的目标Partition,进行重复判断,从而过滤掉生产者一部分重复发送的消息。
- 使用生产者事务机制发送消息: 在打开幂等性配置后,如果一个生产者实例需要发送多条消息,而你能够确定这些消息都是发往同一个Partition的,那么你就不需要再过多考虑消息安全的问题。但是如果你不确定这些消息是不是发往同一个Partition,那么尽量使用异步发送消息机制加上事务消息机制进一步提高消息的安全性。 生产者事务机制主要是通过以下一组API来保证生产者往服务端发送消息的事务性。
// 1 初始化事务voidinitTransactions();// 2 开启事务voidbeginTransaction()throwsProducerFencedException;// 3 提交事务voidcommitTransaction()throwsProducerFencedException;// 4 放弃事务(类似于回滚事务的操作)voidabortTransaction()throwsProducerFencedException;
尤其在与Spring框架整合使用时,通常会将Producer作为一个单例放入到Spring容器中,这时候就更需要注意事务消息使用。实际上SpringBoot集成Kafka时使用的KafkaTemplate就是使用事务消息机制发送的消息。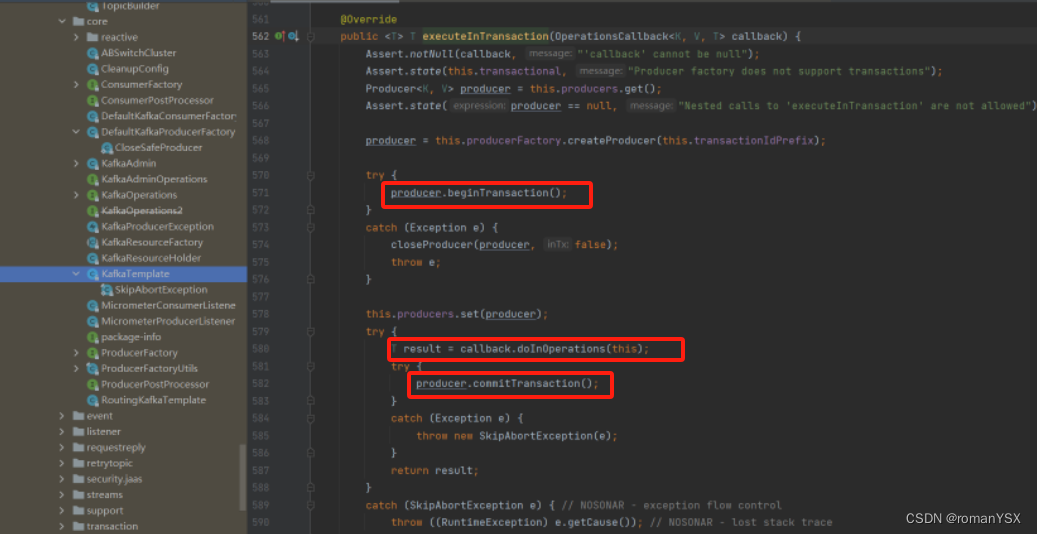
然后在消费者端。Kafka消费消息是有重试机制的,如果消费者没有主动提交事务(自动提交或者手动提交),那么这些失败的消息是可以交由消费者组进行重试的,所以正常情况下,消费者这一端是不会丢失消息的。但是如果消费者要使用异步方式进行业务处理,那么如果业务处理失败,此时消费者已经提交了Offset,这个消息就无法重试了,这就会造成消息丢失。
因此在消费者端,尽量不要使用异步处理方式,在绝大部分场景下,就能够通过Kafka的消费者重试机制,保证消息安全处理。此时,在消费者端,需要更多考虑的问题,就变成了消费重试机制造成的消息重复消费的问题。
5.2 消费者防止消息重复消费
通常消费者消费消息的流程是这样的:
while(true){//拉取消息ConsumerRecords<String,String> records = consumer.poll(Duration.ofNanos(100));//处理消息for(ConsumerRecord<String,String> record : records){//do business ...}//提交offset,消息就不会重复推送。
consumer.commitSync();//同步提交,表示必须等到offset提交完毕,再去消费下一批数据。}
在大部分的业务场景下,这不会有什么问题。但是在一些大型项目中,消费者的业务处理流程会很长,这时就会带来一些问题。比如,一个消费者在正常处理这一批消息,但是时间需要很长。Broker就有可能认为消息消费失败了,从而让同组的其他消费者开始重试这一批消息。这就给消费者端带来不必要的幂等性问题。
消费者端的幂等性问题,当然可以交给消费者自己进行处理,比如对于订单消息,消费者根据订单ID去确认一下这个订单消息有没有处理过。这种方式当然是可以的,大部分的业务场景下也都是这样处理的。但是这样会给消费者端带来更大的业务复杂性。
但是在很多大型项目中,消费者端的业务逻辑有可能是非常复杂的。这时候要进行幂等性判断,,因此会更希望以一种统一的方式处理幂等性问题,让消费者端能够专注于处理自己的业务逻辑。这时,在大型项目中有一种比较好的处理方式就是将Offset放到Redis中自行进行管理。通过Redis中的offset来判断消息之前是否处理过。伪代码如下:
while(true){//拉取消息ConsumerRecords<String,String> records = consumer.poll(Duration.ofSeconds(1));
records.partitions().forEach(partition ->{//从redis获取partition的偏移量String redisKafkaOffset = redisTemplate.opsForHash().get(partition.topic(),""+ partition.partition()).toString();long redisOffset =StringUtils.isEmpty(redisKafkaOffset)?-1:Long.valueOf(redisKafkaOffset);List<ConsumerRecord<String,String>> partitionRecords = records.records(partition);
partitionRecords.forEach(record ->{//redis记录的偏移量>=kafka实际的偏移量,表示已经消费过了,则丢弃。if(redisOffset >= record.offset()){return;}//业务端只需要实现这个处理业务的方法就可以了,不用再处理幂等性问题doMessage(record.topic(),record.value());});//处理完成后立即保存Redis偏移量long saveRedisOffset = partitionRecords.get(partitionRecords.size()-1).offset();
redisTemplate.opsForHash().put(partition.topic(),""+ partition.partition(),saveRedisOffset);});//异步提交。消费业务多时,异步提交有可能造成消息重复消费,通过Redis中的Offset,就可以过滤掉这一部分重复的消息。。
consumer.commitAsync();}
将这段代码封装成一个抽象类,具体的业务消费者端只要继承这个抽象类,然后就可以专注于实现doMessage方法,处理业务逻辑即可,不用再过多关心幂等性的问题。
不过,很容易发现,如果在处理完成之后系统挂掉或者redis挂掉,会导致偏移量无法保存到redis,但是业务数据已经更新,还是会有问题,所有有两种方案:
1、在doMessage时开发人员自己保证幂等,这里可以使用上面提到的订单ID来保证;
2、可以用mysql替代redis,和doMessage使用同一个事务,但是这里可以会产生大事务,拉垮mysql。
所以还是需要具体情况具体分析
版权归原作者 romanYSX 所有, 如有侵权,请联系我们删除。