
PartitionStateMachine分区状态转换实现
1 我为何读这源码?
PartitionStateMachine,分区状态机负责管理Kafka分区状态的转换,类似ReplicaStateMachine。
很多面试官都爱问Leader选举策略。学完本文,你不但能说出4种Leader选举场景,还能总结出它们的共性。
2 简介
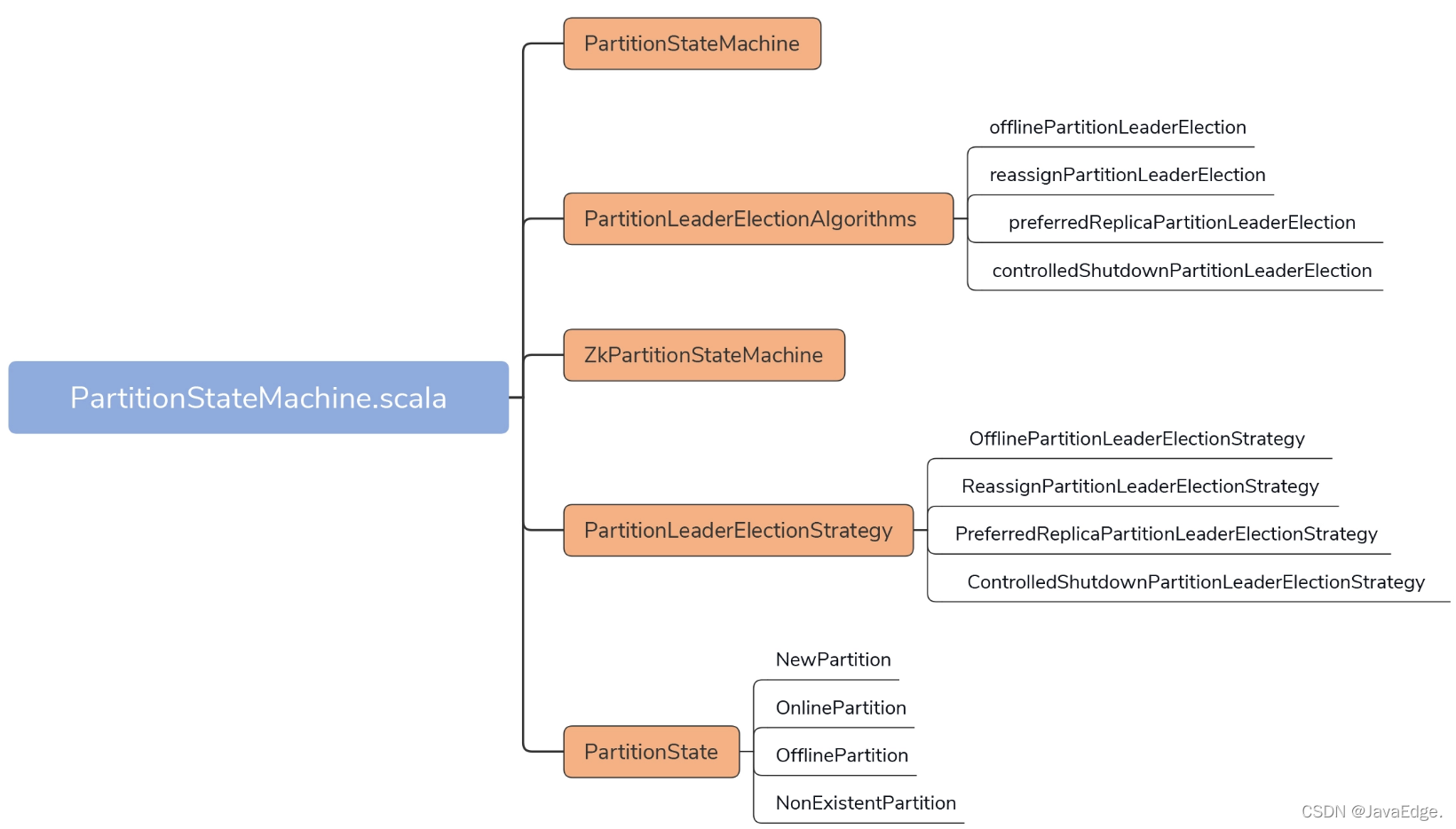
- PartitionStateMachine:定义如startup、shutdown公共方法及处理分区状态转换入口方法handleStateChanges的签名
- ZkPartitionStateMachine:PartitionSM目前唯一子类,实现分区状态机的主体逻辑功能。类似ZkReplicaStateMachine,重写了父类的handleStateChanges,和私有的doHandleStateChanges协作完成分区状态转换
- PartitionState接口及其实现对象:定义4类分区状态及相互流转关系
- PartitionLeaderElectionStrategy接口及其实现对象:定义4类分区Leader选举策略,发生Leader选举的4种场景
- PartitionLeaderElectionAlgorithms:分区Leader选举的算法实现。既然定义了4类选举策略,就一定有相应的实现代码,PartitionLeaderElectionAlgorithms就提供了这4类选举策略的实现代码。
3 类定义与字段
类似ReplicaSM:
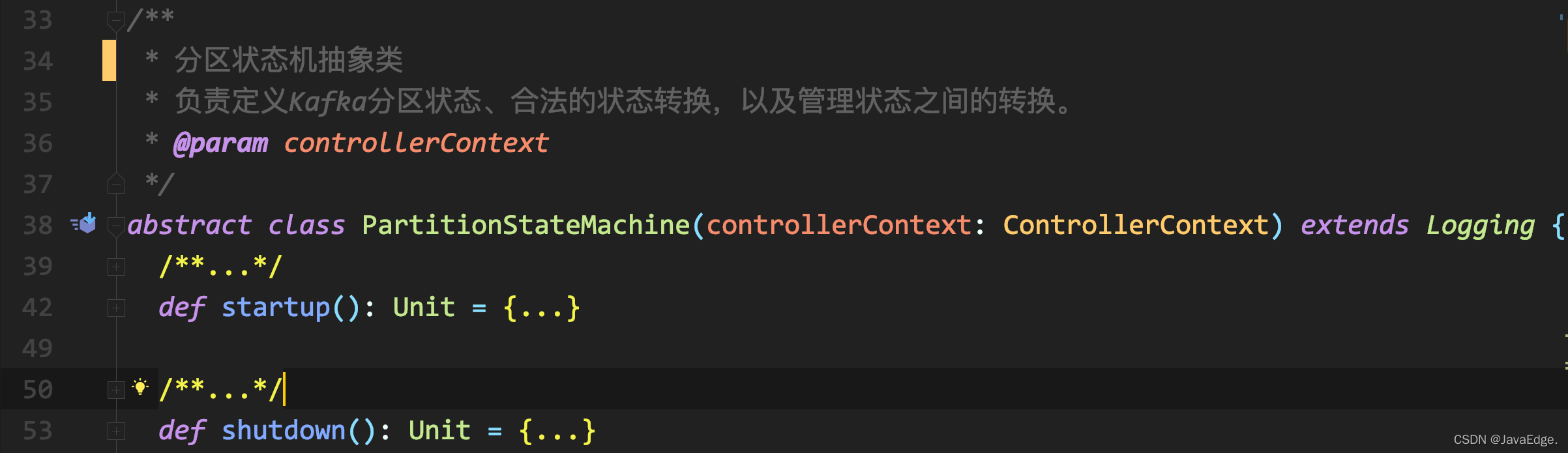

类定义一样!尤其是ZkPartitionSM和ZKReplicaSM,所接收字段列表都一致。所以功能其实也差不多。
同理,ZkPartitionSM实例的创建和启动时机也和ZkReplicaSM完全相同:每个Broker进程启动时,会在创建KafkaController对象的过程中,生成ZkPartitionSM实例,而只有Controller组件所在Broker,才会启动分区状态机。
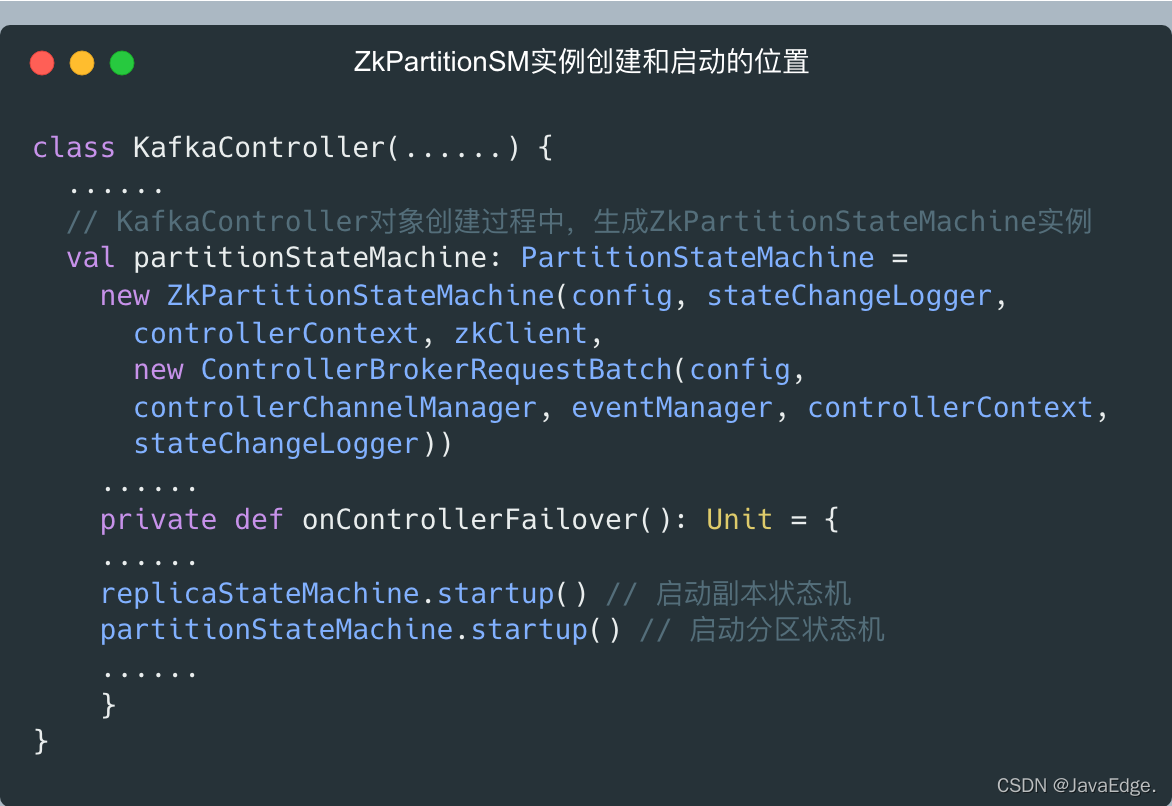
每个Broker启动时,都会创建对应分区状态机和副本状态机实例,但只有Controller所在的Broker才会启动它们。若Controller变更到其他Broker:
- 老Controller所在Broker要调用这些状态机的shutdown方法关闭它们
- 新Controller所在的Broker调用状态机的startup方法启动它们
4 分区状态
PartitionState定义了分区的状态空间及流转规则,以OnlinePartition态为例:


分区状态枚举
- NewPartition:分区被创建后被设置成这个状态,表明是全新的分区对象,Kafka认为是“未初始化”的初生牛犊子,因此不能竞选Leader
- OnlinePartition:分区正式提供服务时所处态
- OfflinePartition:分区下线后所处态
- NonExistentPartition:分区被删除,并且从分区状态机移除后所处态
分区状态转换规则
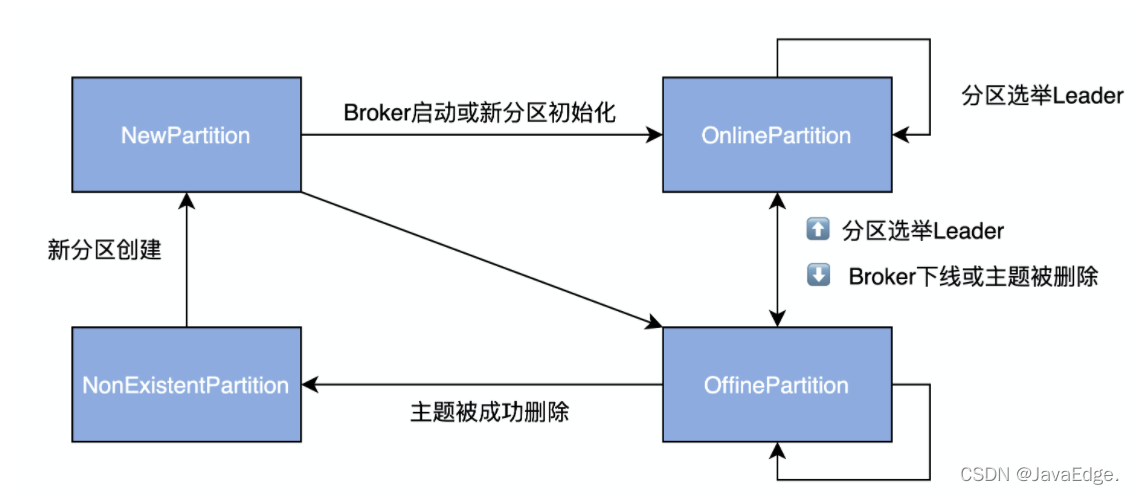
OnlinePartition和OfflinePartition都有一根箭头指向自己,表明OnlinePartition切换到OnlinePartition的操作是允许的。当分区Leader选举发生的时候,就可能出现。
5 分区Leader选举场景
分区Leader选举,PartitionStateMachine的特有功能。每个分区都得选举出Leader,才能正常提供服务。因此,对于分区,Leader副本很重要。所以必须熟悉Leader选举的流程实现。
Kafka定义了哪些推选策略,何时执行Leader选举?
5.1 PartitionLeaderElectionStrategy
分区Leader选举:为Kafka主题的某个分区推选Leader副本,当前分区Leader选举有如下场景:

5.2 PartitionLeaderElectionAlgorithms
针对以上场景,分区状态机的PartitionLeaderElectionAlgorithms定义如下方法分别负责为每种场景选举Leader副本:
- offlinePartitionLeaderElection;
- reassignPartitionLeaderElection;
- preferredReplicaPartitionLeaderElection;
- controlledShutdownPartitionLeaderElection。
其中属offlinePartitionLeaderElection最复杂:
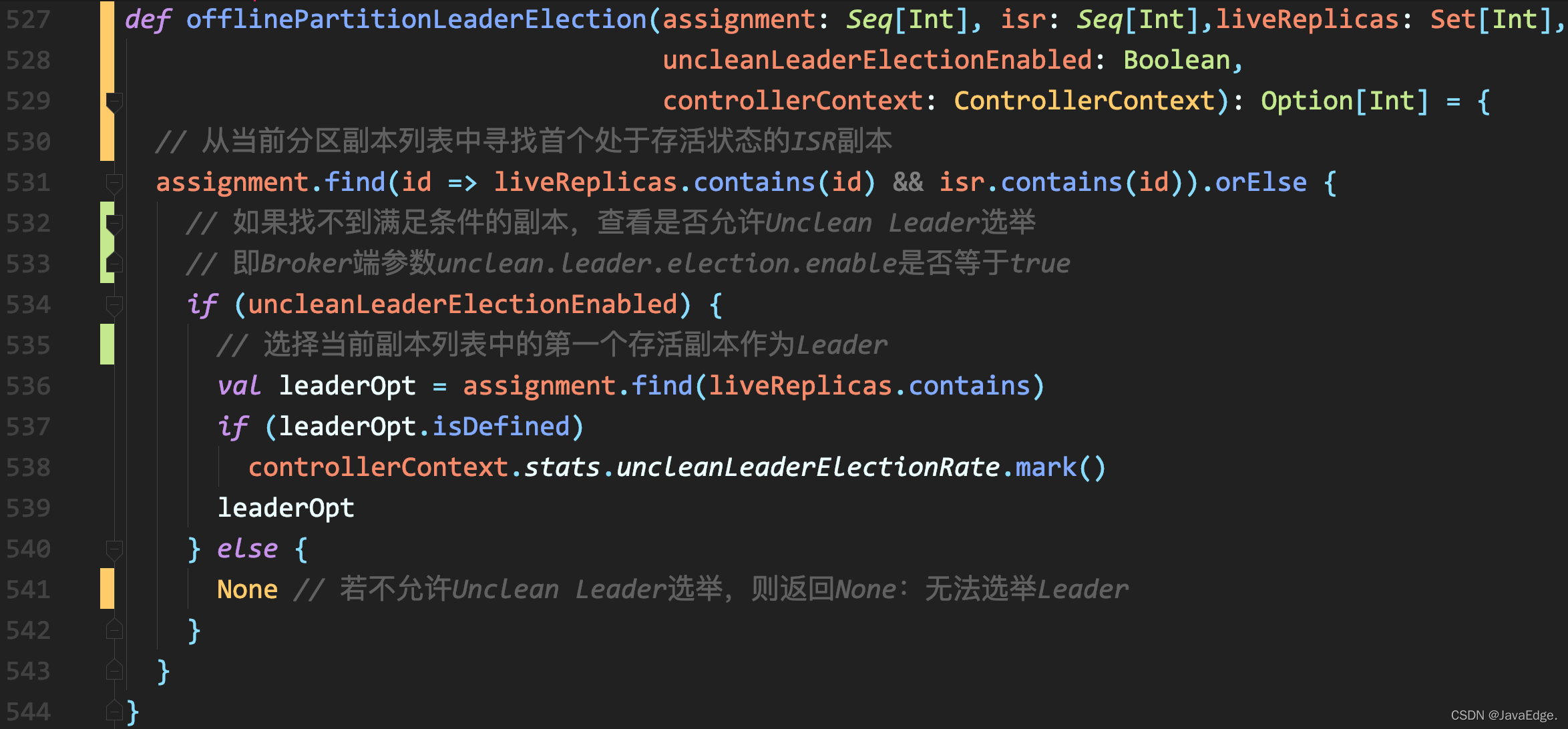
该方法接收如下参数:
1.assignments
分区的副本列表:Assigned Replicas,AR。创建主题后,使用kafka-topics脚本查看主题时,可见Replicas列数据:主题下每个分区的AR。assignments参数类型是Seq[Int],说明AR有序,不一定和ISR顺序相同
2.isr
保存了分区所有与Leader副本保持同步的副本列表。Leader副本自己也在ISR中。作为Seq[Int]类型的变量,isr自身也是有顺序的。
3.liveReplicas
保存该分区下所有存活状态的副本。
- 怎知副本是否存活?根据Controller元数据缓存中的数据。所有在运行中的Broker上的副本,都认为是活的。
4.uncleanLeaderElectionEnabled
默认只要不是由AdminClient发起的Leader选举,该参数为false:Kafka不允许执行Unclean Leader选举。
Unclean Leader选举:在ISR列表为空时,Kafka选择一个非ISR副本作为新Leader。由于存在丢数据风险,Broker端参数unclean.leader.election.enable默认值为false,禁掉Unclean Leader选举。
2.4.0.0版本正式支持在AdminClient端为给定分区选举Leader:若Leader选举由AdminClient触发,默认开启Unclean Leader选举。
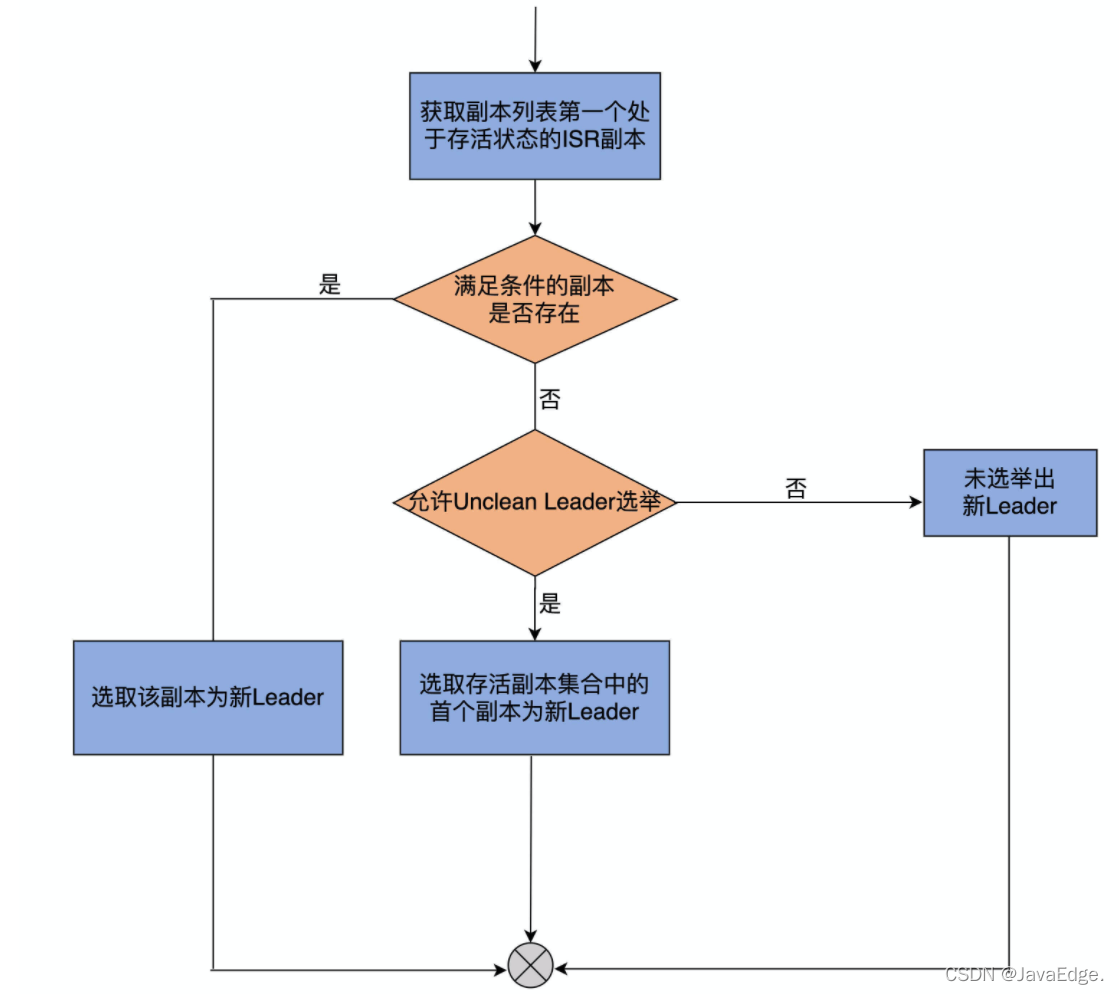
5.3 具体流程
顺序搜索AR列表,将第一个满足如下条件的副本作为新Leader返回:
- 该副本为存活状态,即副本所在Broker依然在运行中
- 该副本在ISR列表
若找不到这样的副本,检查是否开启Unclean Leader选举:
- 若开启,则降低标准,只要满足上面第一个条件
- 若未开启,则本次Leader选举失败,无新Leader被选出
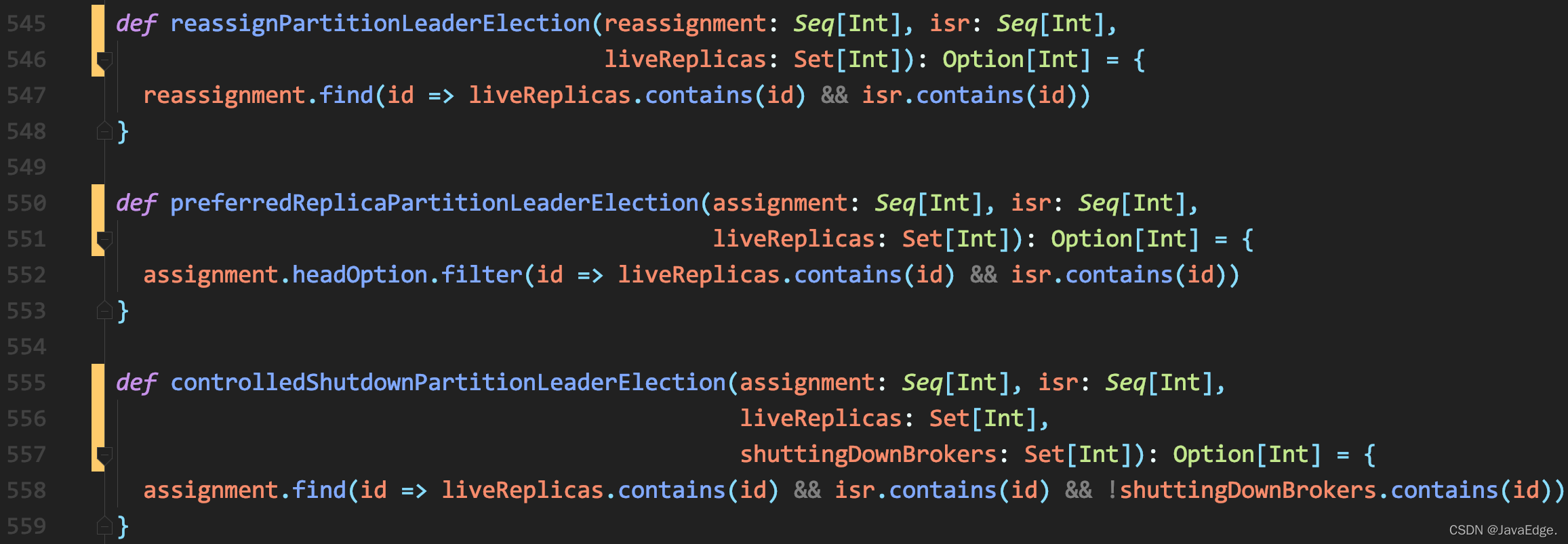
其它选举策略几乎相同,都是从AR或给定副本列表中寻找存活状态的ISR副本。
所以Kafka为分区选举Leader就是:AR列表(或给定副本列表)中首个处于存活状态,且在ISR列表的副本。
6 分区状态转换
PartitionSM的工作原理。
handleStateChanges
入口方法签名:
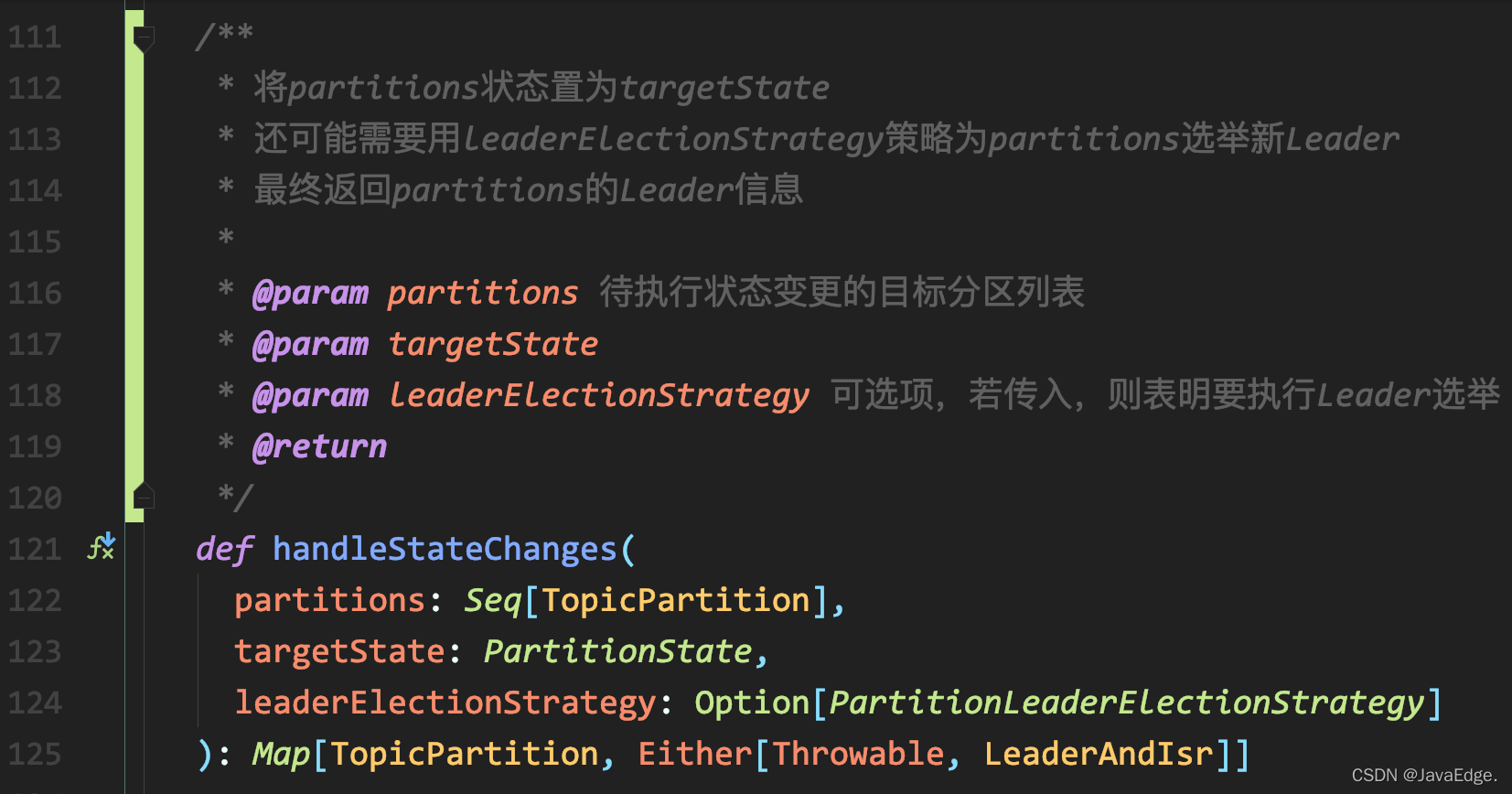
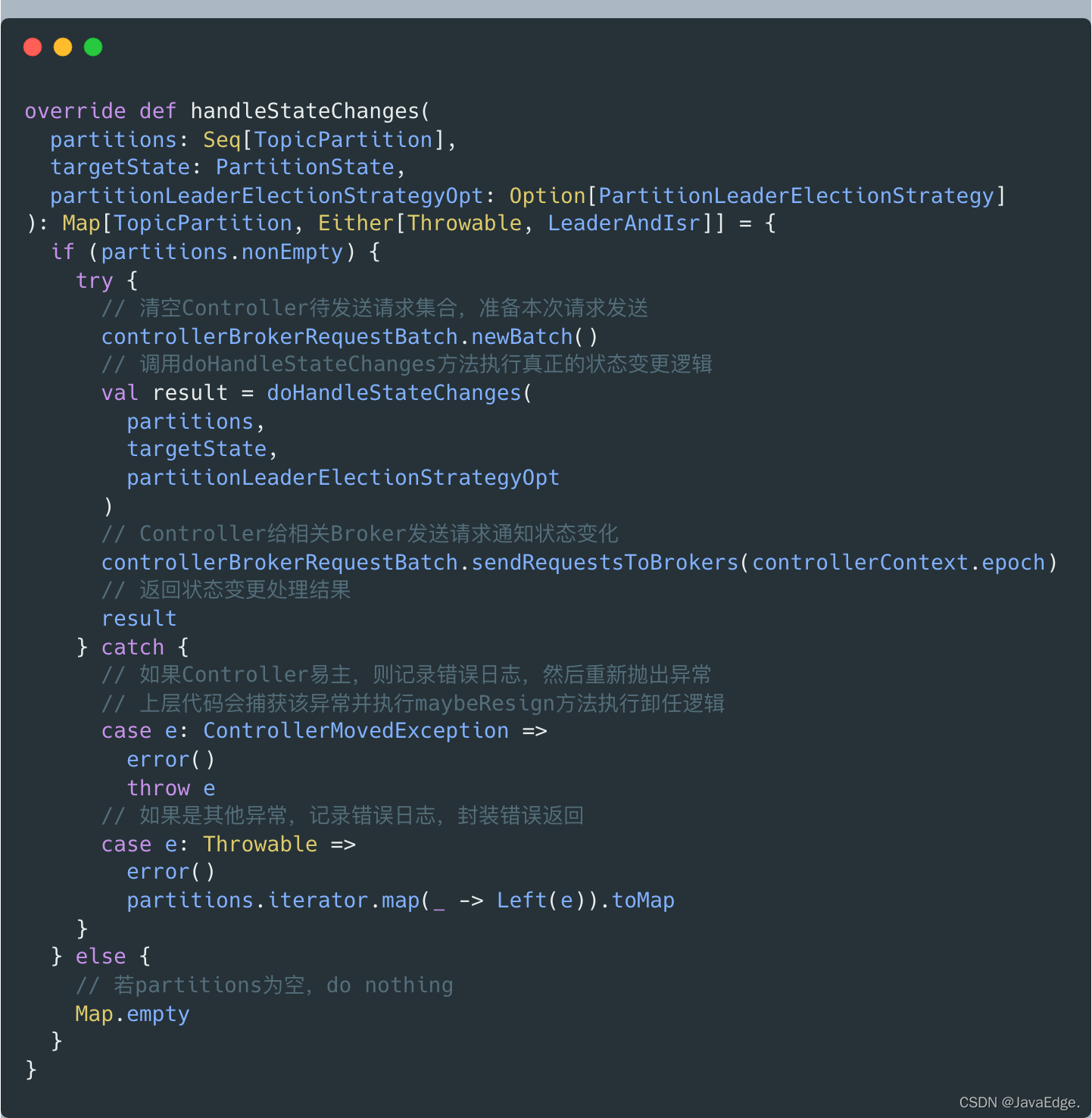
- 调用doHandleStateChanges执行分区状态转换包含确认哪些Broker属于下一步的相关Broker,给Broker发送哪些请求
- Controller给相关Broker发送请求,告知它们这些分区的状态变更
重点还是
doHandleStateChanges
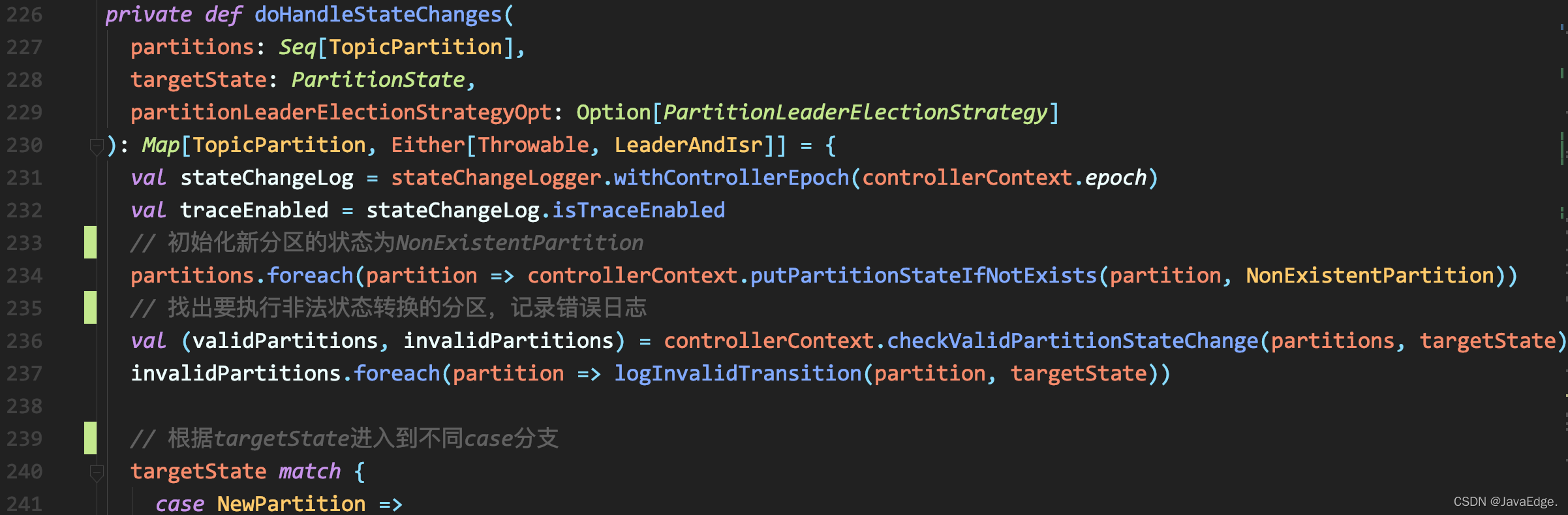
- 首先状态初始化,即在方法调用时,不在【元数据缓存】中的所有分区的状态被初始化为NonExistentPartition
- 然后,检查哪些分区执行的状态转换非法&&记录错误日志
- 据合法状态转换的分区列表,进入case分支。分区状态只有4个,其case分支代码远比ReplicaSM的简单,且只有OnlinePartition分支较复杂,其余3路仅是将分区状态置成目标状态
重点看OnlinePartition分支:
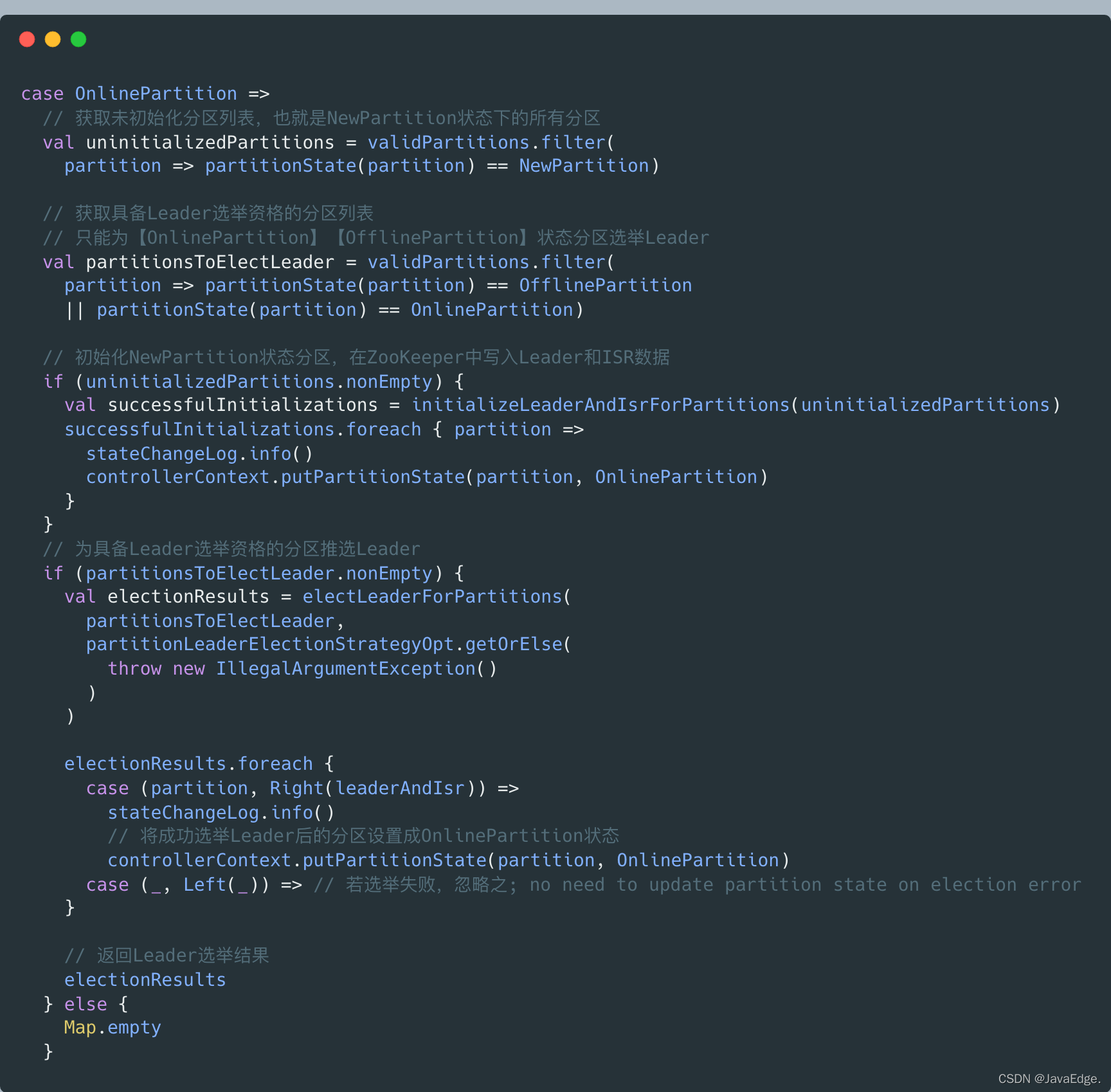
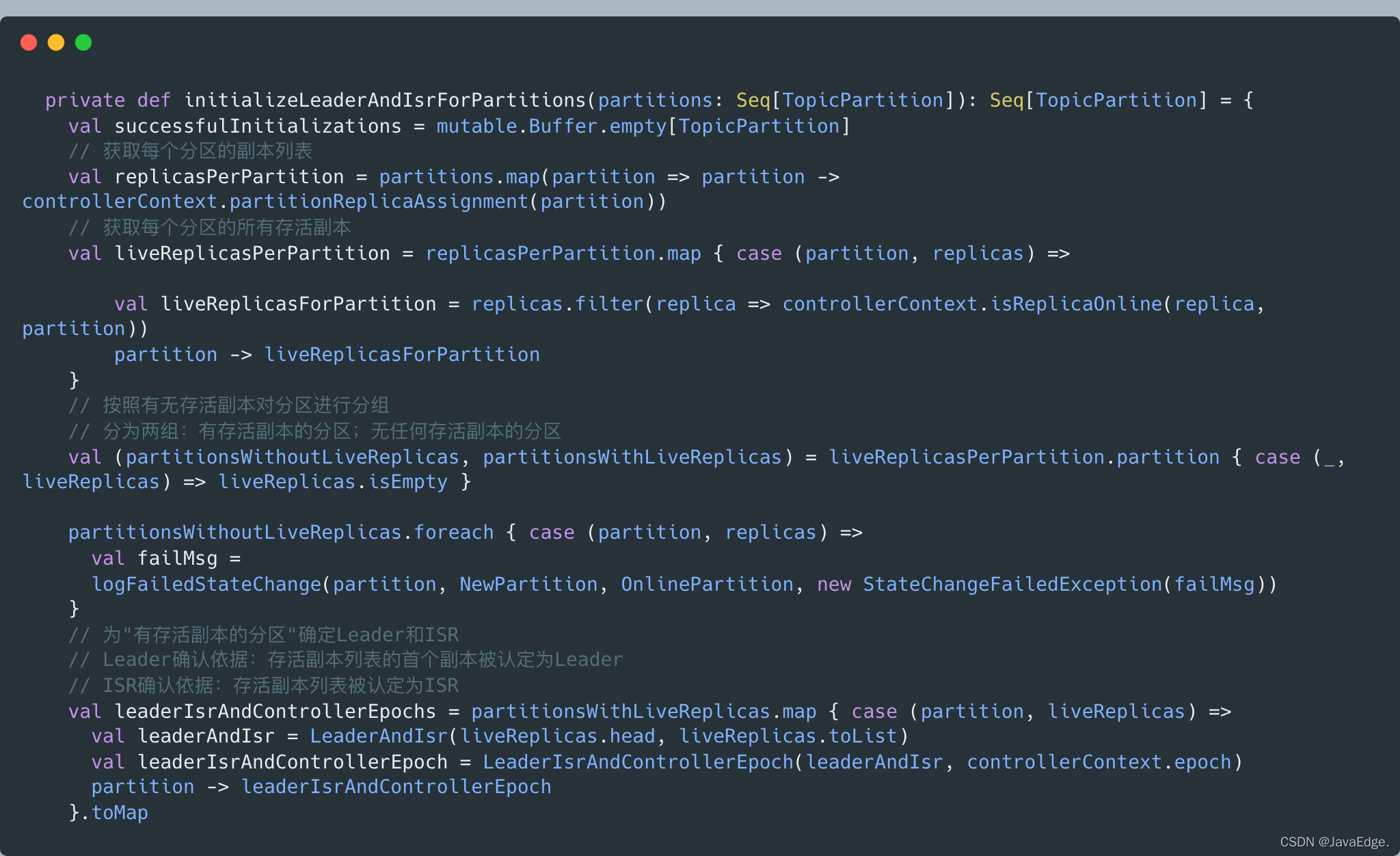
- 初始化NewPartition态的分区,即在zk中,创建并写入分区节点数据。节点位置:
/brokers/topics/<topic>/partitions/<partition>,每个节点都要包含分区的Leader和ISR。Leader和ISR的确定规则:- 选择存活副本列表的第一个副本作为Leader- 选择存活副本列表作为ISR详见initializeLeaderAndIsrForPartitions:
- 为具备Leader选举资格的分区推选Leader,调用electLeaderForPartitions实现:不断尝试为多个分区选举Leader,直到所有分区都成功选出Leader。
选举Leader的核心代码:
doElectLeaderForPartitions
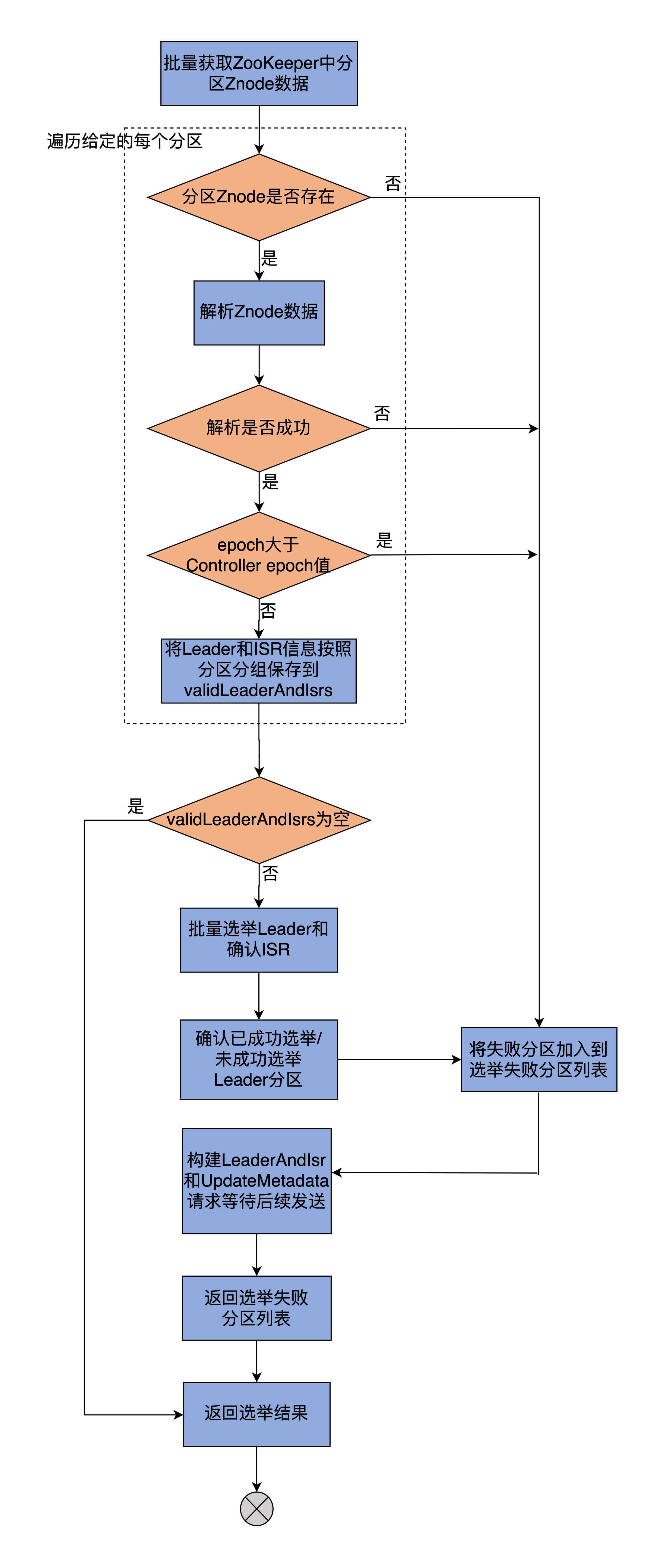
大体分为如下步骤:
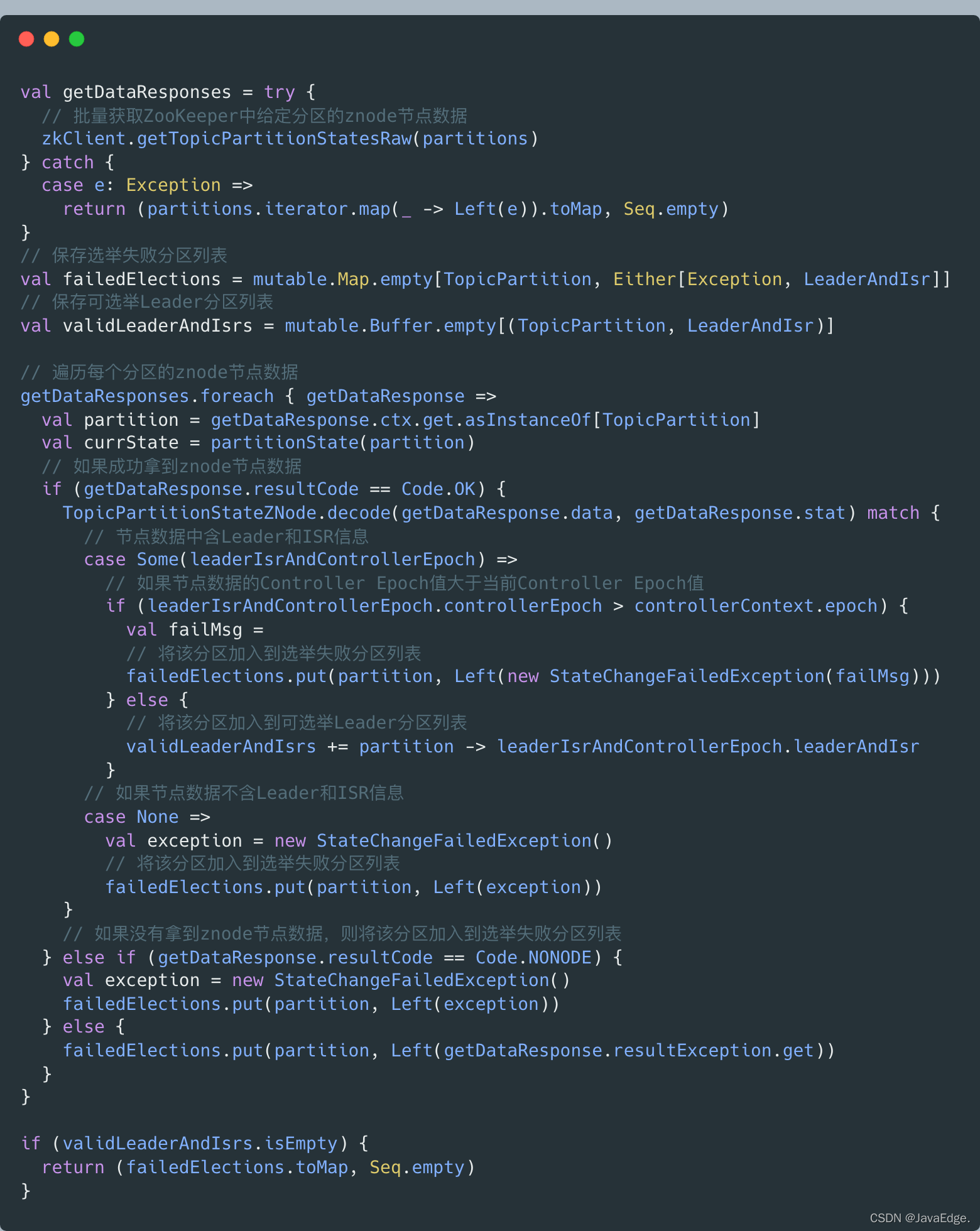
- 从zk获取给定分区的Leader、ISR信息,将结果封装进validLeaderAndIsrs:
- 开始选举Leader,并根据有无Leader将分区进行分区
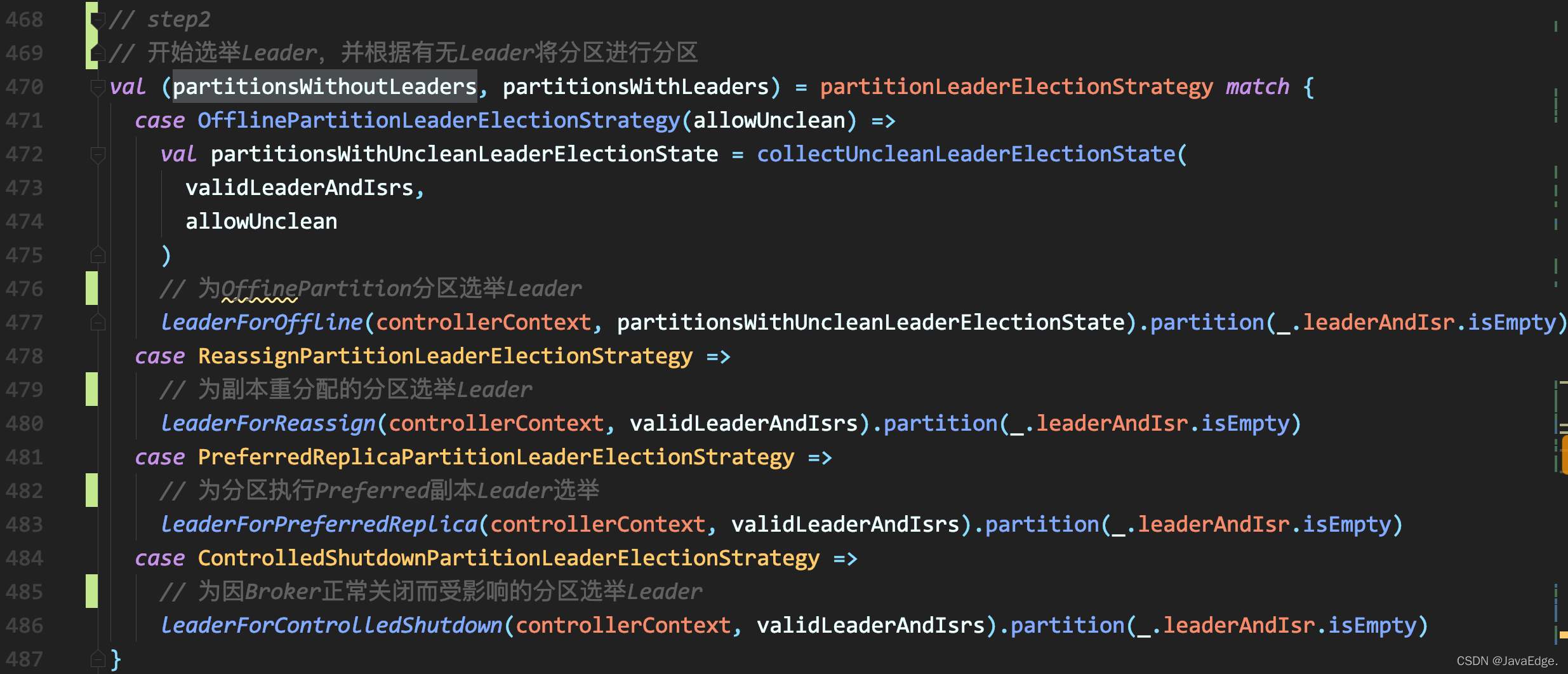
根据给定的PartitionLeaderElectionStrategy,调用PartitionLeaderElectionAlgorithms的不同方法执行Leader选举,同时,区分出成功选举Leader和未选出Leader的分区。
4种不同策略定义了4个专属方法执行Leader选举。选择Leader的规则:副本集合中首个存活&&处于ISR中的副本。
- 更新zk节点数据及Controller端元数据缓存信息:
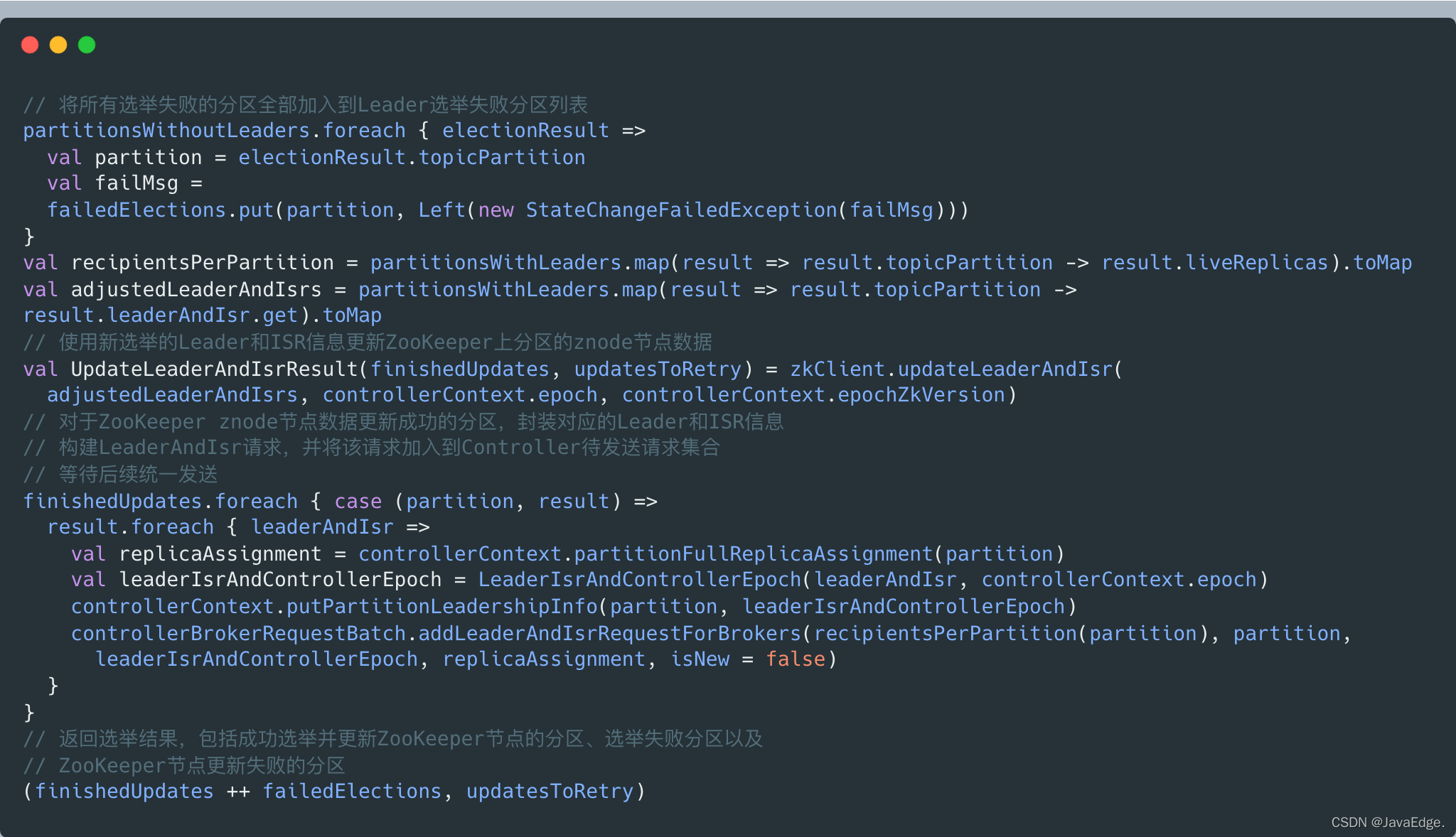
联想到handleStateChanges的step2是Controller给相关的Broker发送请求:

7 总结
本文深入研究了Kafka分区状态机的构造原理和工作机制。
Kafka目前提供4种Leader选举策略:
- 分区下线后的Leader选举
- 分区执行副本重分配时的Leader选举
- 分区执行Preferred副本Leader选举
- Broker下线时的分区Leader选举
这4类选举策略在选择Leader上,几乎都是选择当前副本有序集合中的、首个处于ISR集合中的存活副本作为新Leader。
PartitionSM是Kafka Controller端定义的分区状态机,负责定义、维护和管理合法的分区状态转换。每个Broker启动时都会实例化一个分区状态机对象,但只有Controller所在的Broker才会启动它。
Kafka分区有4类状态:
- NewPartition未初始化状态,处于该状态下的分区尚不具备选举Leader的资格
- OnlinePartition分区正常工作时的状态
- OfflinePartition
- NonExistentPartition
Leader选举有4类场景:
- Offline
- Reassign
- Preferrer Leader Election
- ControlledShutdown
每类场景都对应于一种特定的Leader选举策略。handleStateChanges是入口方法,内部调用doHandleStateChanges执行实际Leader选举功能
版权归原作者 JavaEdge. 所有, 如有侵权,请联系我们删除。