
前 言
🍉 作者简介:半旧518,长跑型选手,立志坚持写10年博客,专注于java后端
☕专栏简介:深入、全面、系统的介绍redis知识
🌰 文章简介:本文将深入、全面介绍Redis的入门,包括redis的介绍、历史、安装、特点、基本知识等,建议收藏备用,创作不易,敬请三连哦
文章目录
01 redis介绍
1.1 Redis是一种数据库
Redis是一种数据库。数据库是用于存储数据、管理数据的软件,不同的数据库有不同的特点,因此我们要根据项目的需要选择数据库,有时候,我们甚至需要在一个项目中使用多个数据库。
1.2 数据库的发展历程
数据库的演变经历了单机数据时代、MemCached时代、水平切分时代,读写分离时代、分表分库(集群)时代、nosql时代。每一次数据库的变更,都会推动IT行业的一次变更。
💻 Tip:技术的更新不是一蹴而就的,这些技术都是现在主流的,我们了解技术的变更有利于建立宏观视野,当您成为项目经理、技术经理、架构师时可以进行合理的数据库选型。
单机数据库就是一个应用对应一个数据库实例。随着软件应用的发展,应用的功能和数据量急剧增加。
因此出现了MemCached时代,也就是缓存时代。对于经常访问的数据使用缓存存储。
缓存可以解决访问效率的问题,但是无法存储更多的数据量,解决不了数据量的需求。由于一个数据库已经存储不下我们的数据了,于是出现了水平切分时代。把数据表存在多个数据库中,访问数据表就找到对应的数据库进行访问即可。
水平切分时代,如果有一个数据表特别大,那么可能我们就会使用一个数据库来存储这张数据表,如果这个数据表还恰好访问的特别频繁,就会出现该数据库的业务量特别拥塞的情况。比如订单表,可能收到增加订单、修改订单、删除订单、查找订单等各种请求,如果是双十一,同一时间这个数据库就会收到特别多的并发请求。因此,我们开始设计了集群,将这个表的数据存储多份在不同的计算机中,不同的数据库负责不同的请求类型,多个数据库应用可以有效分散请求的压力。
 web1.0时代,用户只是读服务器的数据,而不会加入到创建数据的过程中,进入到web2.0时代以后,用户开始可以进行点赞、收藏、转发等创造数据的行为,并且这种行为是持续增长且不可控的,那就可能导致某些表的数据量不断增长,即使用一台单独的服务器也无法满足其存储需求了。水平切分已经不能满足需要,因此出现了垂直切分,把同一张表的数据切分到不同的数据表,甚至分到不同的数据库服务器存储。垂直切分也被称做分库分表,分库分表时代其实也属于集群时代。
web1.0时代,用户只是读服务器的数据,而不会加入到创建数据的过程中,进入到web2.0时代以后,用户开始可以进行点赞、收藏、转发等创造数据的行为,并且这种行为是持续增长且不可控的,那就可能导致某些表的数据量不断增长,即使用一台单独的服务器也无法满足其存储需求了。水平切分已经不能满足需要,因此出现了垂直切分,把同一张表的数据切分到不同的数据表,甚至分到不同的数据库服务器存储。垂直切分也被称做分库分表,分库分表时代其实也属于集群时代。
分库分表的标准可能是不统一的,有的场景按照时间进行分库分表是一个不错的策略,比如我们查询支x宝的帐单,就是按照月份,年份查,那么我们当然也可以按照月份、年份、甚至天数来存储数据。不过切分不难,但是与之对应的,我们在访问不同数据库时,就需要切换数据源。
上面的数据库技术都离不开数据表,属于关系型数据库,我们的科学家已经将其利用到极致,最大限度的满足数据量与性能的要求。但是随着大数据时代到来,海量数据,高并发对于数据库的要求更高了,因此上面的手段已经不足以满足需要,因此出现了非关系型数据库。
这是一个彻底的革命,我们之所以面临限制,就是因为使用的是数据表,我们需要按照表存储,按照表为单位进行增删改查,需要维护表与表的关系,现在我们干脆不用表这种数据结构存储了,使用聚合结构存储数据,彻底改变数据库的底层存储结构。
非关系型数据库就是NoSql数据库,所谓NoSql其实就是
not only sql
。常用的非关系型数据库有:redis,mongoDB,HBase…它们各自有各自擅长的场景。
1.3 redis介绍
redis(Remote dictionary server)基于
key-value
键值对来存储数据,由c语言编写,基于内存运行并支持持久化,是一种高性能的Nosql数据库。
Redis中的数据大部分时间都是存储在内存中,访问效率高。但是由于内存昂贵,因此redis的缺点是不能够存储太多的数据。我们一般使用redis存储频繁访问且数据量比较少的数据,因此redis又被称之为缓存数据库。MongoDB。HBase可以用来存储大数据量数据。
💐 思 考
可能有读者朋友会有疑问,redis和缓存又有什么区别呢,有了缓存为什么还需要redis?这是因为如果只使用缓存,无法将数据持久化,redis解决了内存数据的易失性问题。
1.4 redis的特点
🍉 支持数据持久化,redis可以将内存中的数据持久化到磁盘中,重启时可以再次加载使用
🍌 支持数据备份,即
master-slave
模式的数据备份。
🍎 支持多种数据结构,redis不仅仅是支持简单的
key-value
数据,还支持
set
,
zset
,
list
,
hash
等数据结构的存储。
2 redis的安装与使用
2.1 安装redis(linux)
(1)下载redis数据库
登陆官网:redis官网地址
点击download,选择redis版本下载,本教程使用redis版本为5.0.2.推荐将redis部署到linux环境。 (2)解压
(2)解压
sudotar -zxvf /home/wangzhou/Downloads/redis-5.0.2.tar.gz -C /opt/
检查下。
(3)安装gcc
gcc是一款c语言编译依赖的工具软件,由于我们后面需要编译redis源码,因此需要下载安装gcc。查看先,笔者这里就是已经有了,可以看到gcc的版本信息。
gcc -v
 如果没有gcc,可以用如下命令安装。
如果没有gcc,可以用如下命令安装。
yum -y gcc
(4)编译源代码。进入redis目录,执行
make
,编译src文件夹下的源代码
🥥 编译成功如图: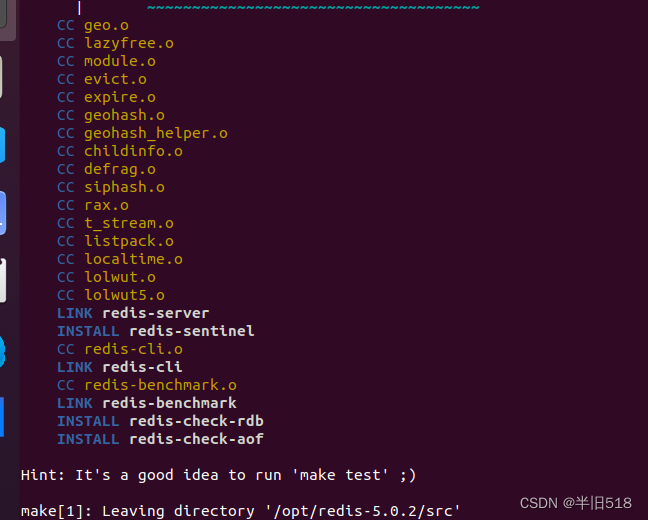
🍉 错误:如果您在之前就编译过,但是缺少gcc,重新编译时可能会报错。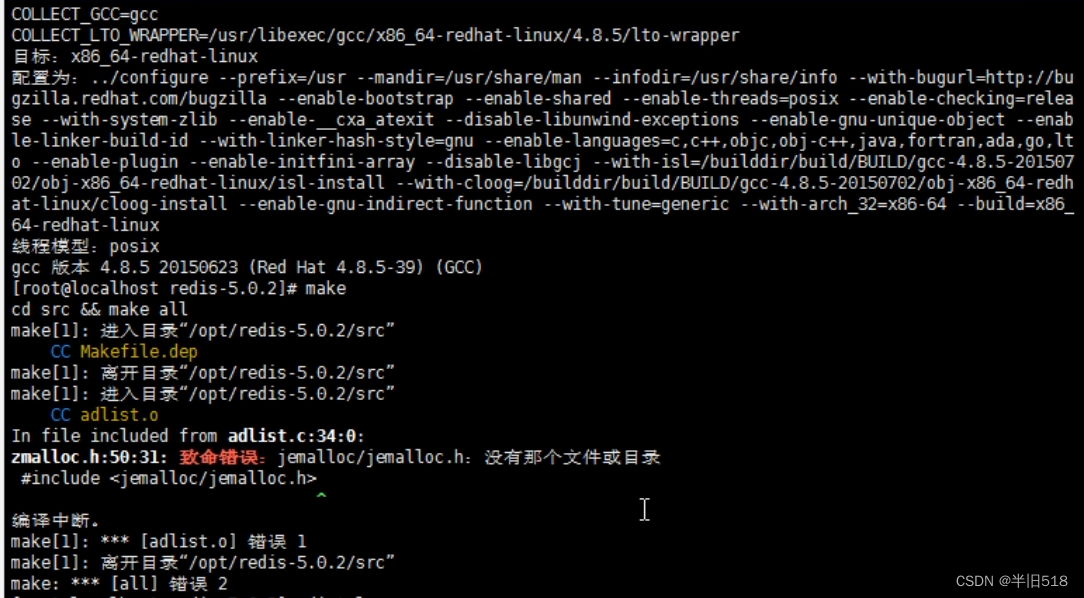
这是因为之前编译生成了部分文件,但是又缺少文件导致的,简单来说你需要把之前编译的内容先清空,再重新编译,可以执行如下命令。
make distclean
(5)安装redis
上面编译完其实已经可以使用了,但是还有一些redis的命令没有配置到环境变量中。我们执行如下命令安装redis,。
makeinstall
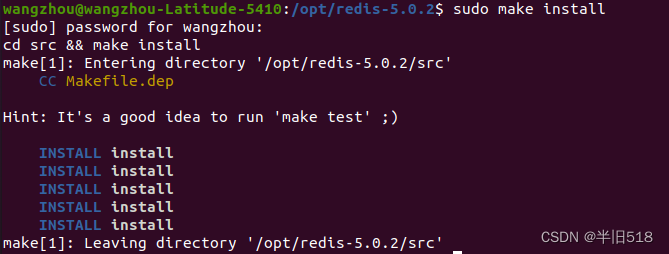 可以执行如下命令在环境变量的对应路径检查下,看看环境变量是否配置成功。
可以执行如下命令在环境变量的对应路径检查下,看看环境变量是否配置成功。
ls /usr/local/bin/
可以看到这里多了很多redis相关的命令。
2.2 启动redis
(1)前台启动(不推荐)
redis --server
这种方式会占用整个命令行终端,并且如果终端挂了,redis服务也会挂掉。
(2)后台启动
redis --server &
这种方式按回车,redis就会退出控制台,在后台运行。可以使用如下命令查看redis是否在启动中。
ps -ef|grep redis
 (3)启动redis服务时,指定配置文件
(3)启动redis服务时,指定配置文件
在redis的解压目录下,很容易找到配置文件
redis.conf
。配置文件可配置redis的端口号等,我们可以在启动redis指定配置文件,让redis使用配置文件的配置而不是默认配置。
redis --server redis.conf &
2.3 关闭redis
(1)通过
kill
命令杀进程(不推荐)
ps -ef|grep redis
下图中显示的第一行中,103201就是redis进程的pid了(1511是其父进程的pid)。
kill -9 103201
这种方式不推荐,因为容易丢失数据,可能redis中的数据还没有持久化,就被kill了。
(2)通过redis-cli命令关闭
redis-cli shutdown
 这里其实就是使用了redis的客户端向服务端发送了关闭的请求。
这里其实就是使用了redis的客户端向服务端发送了关闭的请求。
2.4 redis的客户端使用
服务器一般部署在远程,程序员在实际中都是同客户端给服务端发送请求使用redis。
☕ 注 意:
值的注意的是,redis与mysql不同,客户端与服务端不通过账号密码来连接,只需要ip与port即可,它追求的是效率而不是安全,因为使用redis存储的数据一般也都是一些不需要考虑信息安全问题的数据。
redis-cli
是redis自带的客户端。启动服务端后,使用命令
redis-cli
即可使用,默认连接本机6379端口的redis服务器。
如果想要指定端口号,可以使用如下命令。
redis-cli -p 6380
如果想要连接指定主机的服务器,可以使用如下命令。
redis-cli -h 10.10.11.218 -p 6380
退出客户端。在客户端执行命令
exit
和
quit
即可。
3 redis的基本知识
3.1 测试redis服务器性能
如果您是项目经理或者技术经理,需要进行选型,可以在redis服务器启动的前提下使用如下命令。
redis-benchmark
其结果如下。它会自己发送模拟请求,返回其处理请求的时间及其它细节情况。可以看到,它在0.7s内处理了十万条请求,其性能还是特别不错的。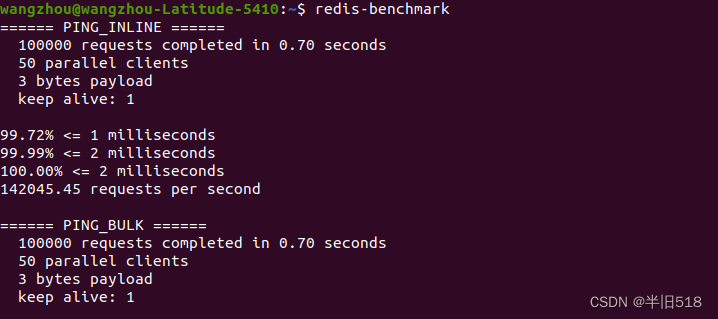
3.2 查看redis服务器是否正常连接
由于我们都是远程对redis服务器发送请求,在执行请求前,可以先使用
ping
命令确定是否与服务器保持正常的连接。 如果正常则会返回
pong
,否则返回空。
3.3 查看redis的统计信息
作为项目经理或者技术经理,可能需要查看redis的统计信息。执行命令
info
即可。下面截取了一部分结果,实际上它返回的信息很广,涉及集群,内存,cpu等等。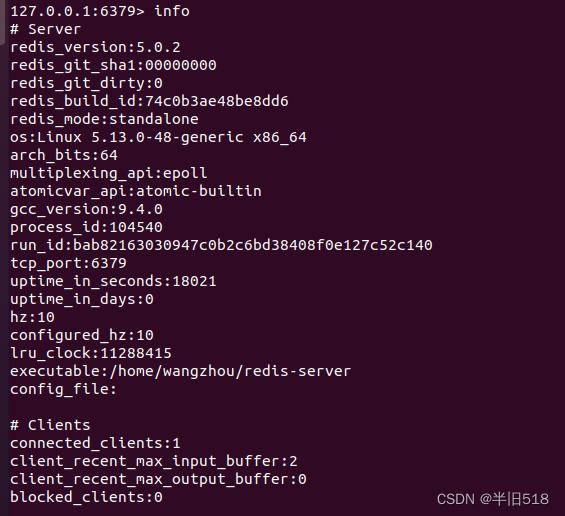 我们可以指定需要查看的信息。
我们可以指定需要查看的信息。
127.0.0.1:6379> info CPU
# CPU
used_cpu_sys:21.710256
used_cpu_user:25.014116
used_cpu_sys_children:0.000000
used_cpu_user_children:0.006322
3.4 redis的数据库实例
redis默认使用16个数据库实例,采用编号0-15命名,作用与myql的数据库实例相同。不过,mysql可以自己创建数据库实例,redis只能由redis服务来创建数据库实例(启动时就默认创建16个,也可以通过配置文件指定需要redis自动创建的数据库实例个数),而开发人员不能够创建或更改数据库实例。
💡 Tips:
redis数据库实例本身需要占用的存储空间是很小的,因此即使没有使用16个数据库实例,其实也不需要太担心存储空间的问题
默认情况下,redis客户端连接的是编号为0的数据库实例。可以使用
select [index]
命令切换数据库实例。
<pre>127.0.0.1:6379>set k1 v1
OK
127.0.0.1:6379> get k1
"v1"127.0.0.1:6379>select1
OK
127.0.0.1:6379[1]> get k1
(nil)</pre>127.0.0.1:6379[1]>select0
OK
127.0.0.1:6379> get k1
"v1"
3.5 查看当前数据库的数据条数
使用
dbsize
,可以查看当前数据库的key的数目,即数据条数,下面看看0号数据库的数据条数
127.0.0.1:6379> dbsize
(integer)5
大家可能会奇怪,我们不是才插入1条数据吗?其实,redis的0号数据库实例和oracle等数据库会创建默认的数据表一样,会默认创建几条数据。
3.6 查看当前数据库的所有key
keys *
可以查看当前数据库的所有key
127.0.0.1:6379> keys *
1)"counter:__rand_int__"2)"k1"3)"key:__rand_int__"4)"myset:__rand_int__"5)"mylist"
3.7 清空当前数据库实例
flushdb
可以清空当前数据库实例的数据
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> keys *
(empty list or set)
3.8 清空所有数据库实例
flushall
可以清空所有数据库实例的数据,这个命令需要慎用。
127.0.0.1:6379> flushall
OK
3.9 查看redis的配置信息
使用如下命令查看所有配置信息
config get *
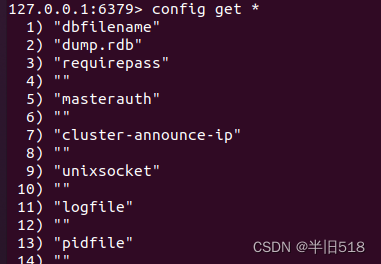
你当然也可以查看指定的信息。
127.0.0.1:6379> config get port
1)"port"2)"6379"
4.redis的五种数据结构
程序是用来处理数据的,数据库则是用来存储数据的,redis为了方便数据的存储,设计了五种数据结构,可以很方便的将程序处理过的多种类型的数据直接对应到这五种数据结构,不同的特点的数据,可以存储到redis不同类型的数据结构中,存取十分方便。
redis的五种数据结构中,前4种与java的数据结构都可以一一对应,第五种没有对应的类型,分别是:
- string对应字符串、数值类型与布尔类型(都可以用一个值表示)

- list对应有序集合list、数组等,按照数据插入顺序存储数据

- set对应无序无重复集合
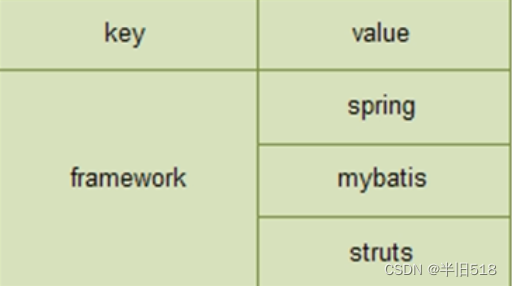
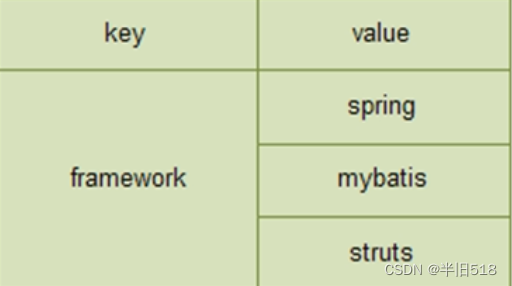
- hash对应实体类对象
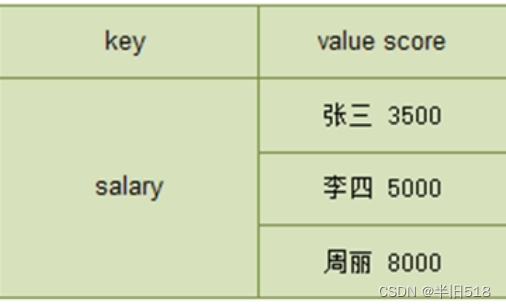
- zset(sorted set),它其实也是有序集合,不过它的顺序不是元素存放的先后顺序,而是排序,比如存放了中国所有的城市city,我们可以根据排序指标人数进行数据的排序。
下图总结了五种数据结构的存储方式,后文还会详细介绍。
版权归原作者 半旧518 所有, 如有侵权,请联系我们删除。