
总结:
1、Flink Shuffle
Pipelined Shuffle:上游 Subtask 所在 TaskManager 直接通过网络推给下游 Subtask 的 TaskManager;
Blocking Shuffle:
Hash Shuffle-将数据按照下游每个消费者一个文件的形式组织;
Sort-Merge Shuffle-将上游所有的结果写入同一个文件,文件内部再按照下游消费者的 ID 进行排序并维护索引,下游读取数据时,按照索引来读取大文件中的某一段;
Hybrid Shuffle:支持以内存或文件的方式存储上游产出的结果数据,原则是优先内存,内存满了后 spill 到文件,无论是在内存还是文件中,所有数据在产出后即对下游可见。
2、Spark Shuffle
Shuffle Write:对Map结果进行聚合、排序、分区输出;
Shuffle Read:拉取Map结果进行聚合、排序;
3、MapReduce shuffle
Map计算后:对Map的结果进行分区、溢写、排序、合并输出到文件中;
Reduce计算前:拉取Map输出的结果文件中属于自己分区的数据,进行合并排序;
一、Flink Shuffle 详解
0、总结
Pipelined Shuffle:上游 Subtask 所在 TaskManager 直接通过网络推给下游 Subtask 的 TaskManager;
Blocking Shuffle:
Hash Shuffle:将数据按照下游每个消费者一个文件的形式组织;
Sort-Merge Shuffle:将上游所有的结果写入同一个文件,文件内部再按照下游消费者的 ID 进行排序并维护索引,下游读取数据时,按照索引来读取大文件中的某一段;
Hybrid Shuffle:支持以内存或文件的方式存储上游产出的结果数据,原则是优先内存,内存满了后 spill 到文件,无论是在内存还是文件中,所有数据在产出后即对下游可见。
1、概述
数据分治的核心:Shuffle;
计算分治的核心:调度器;
2、流计算的 Pipelined Shuffle
1)概述
Flink 流计算的 Shuffle,所有 Task 同时在运行,上下游 Task 通过网络流式地传输中间结果,不需要落盘,这种 Shuffle 被称为 Pipelined Shuffle。
2)算子
DataStream 的
keyBy
或
rescale
等分区算子;
SQL 中的
Group By
;
3)WebUI
在可视化的 DAG 上就是上下游划分到不同的两个节点,两者以一条边相连,边的类型有
HASH
、
BROADCAST
、
REBALANCE
等。
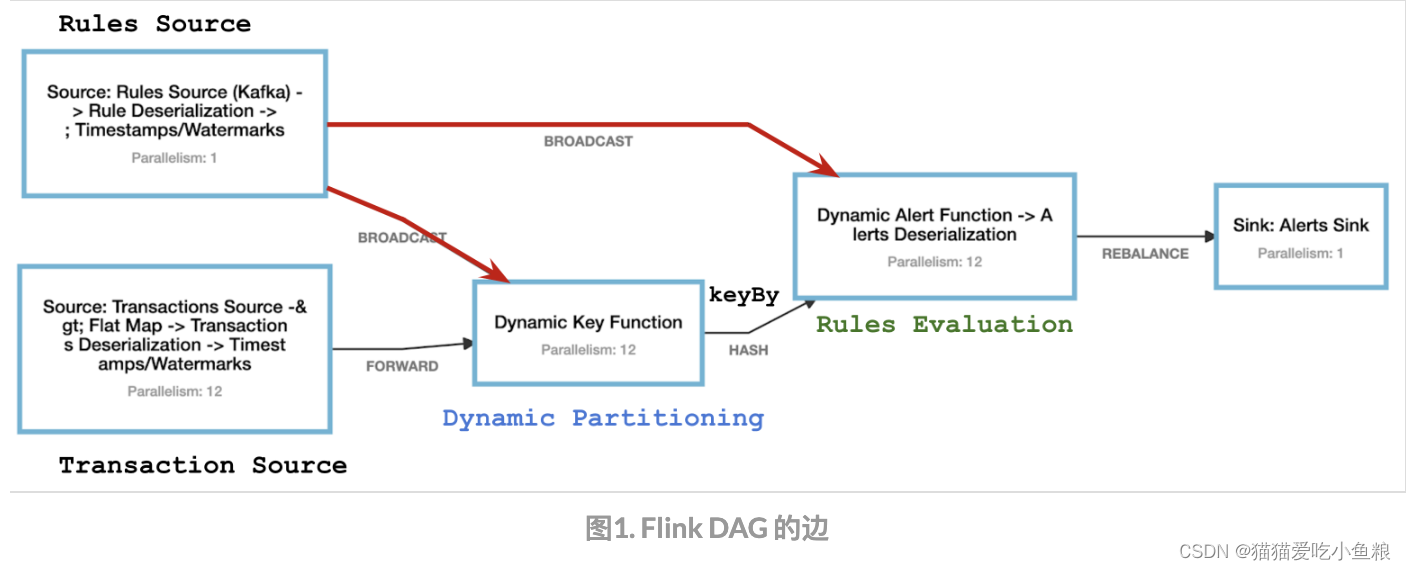
4)核心
逻辑上的 Partition 有多种算法,区别仅在于产出的结果如何划分给不同的下游 Subtask;
将中间结果提供给不同的下游 Subtask 读取,Partition 算法决定如何划分出 Subpartition,而 Shuffle 决定如何将 Subpartition 传递给 InputGate。
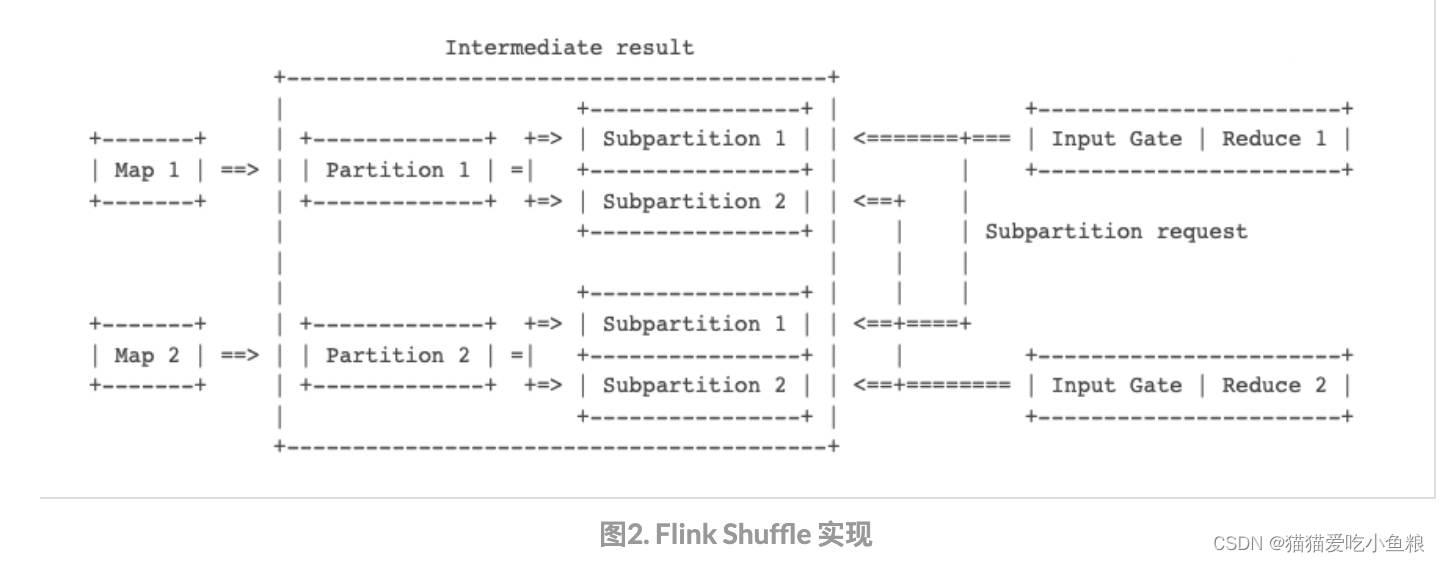
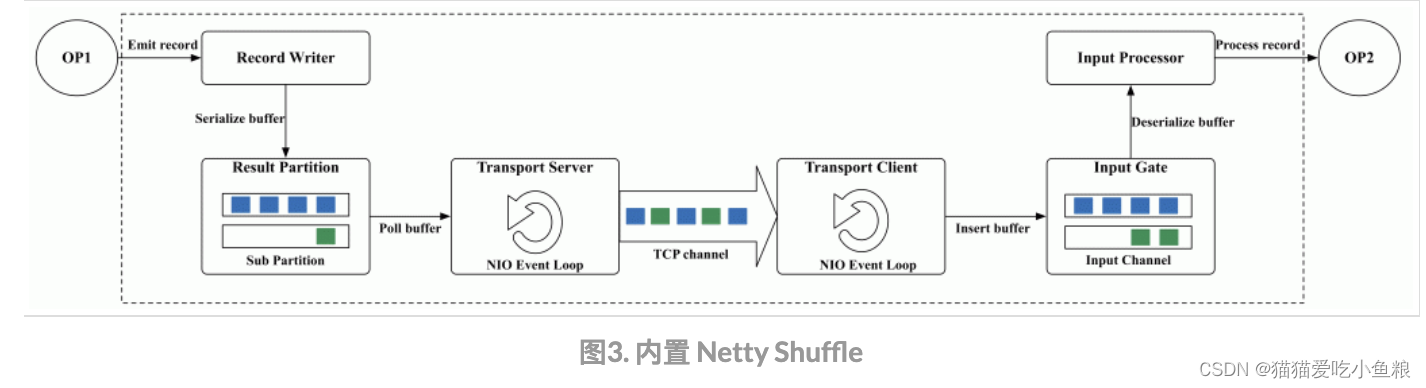
Pipelined Shuffle:上游 Subtask 所在 TaskManager 直接通过网络推给下游 Subtask 的 TaskManager。
Flink 在 TaskManager 里内嵌了基于 Netty 的 Shuffle Service,计算得出的中间数据会存到 TaskManager 的缓存池中,由 Netty 去定时轮询发送给下游。
3、批计算的 Blocking Shuffle
1)概述
批计算的上下游 Subtask 通常不会同时调度起来,所以上游产出数据首先需要落盘存储,等下游调度起来再去读取,这种方式被称为 Blocking Shuffle。
Blocking Shuffle 有 Hash Shuffle 和 Sort-Merge Shuffle 两种常见策略。
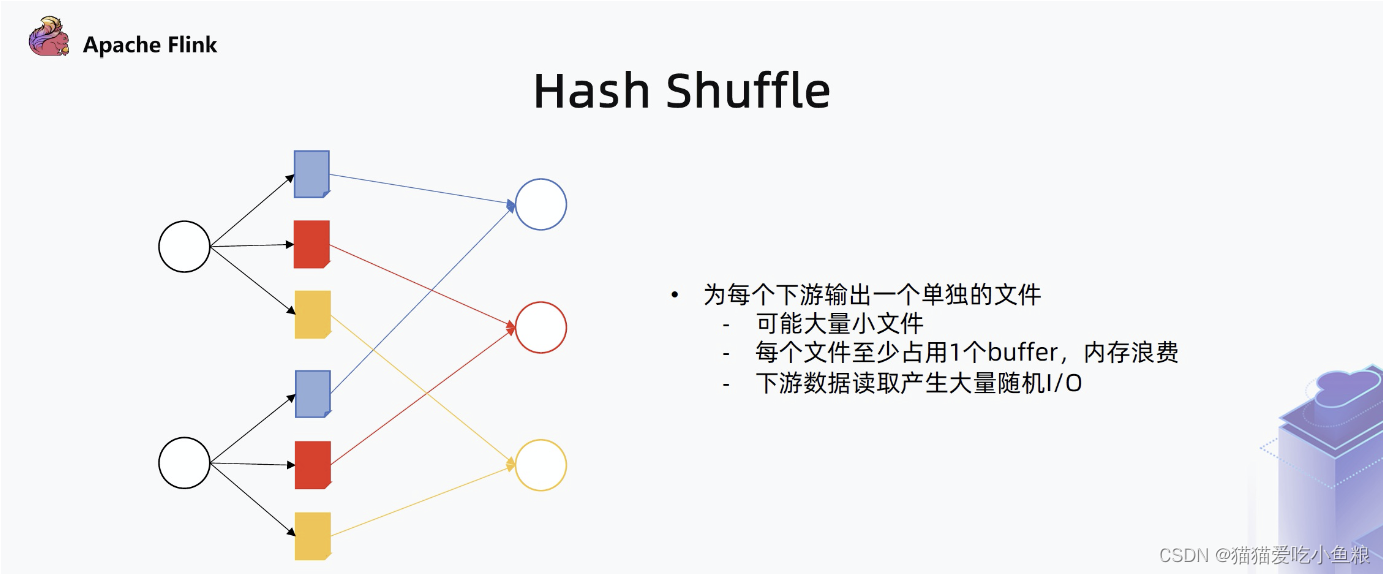
2)Hash Shuffle
Hash Shuffle 是将数据按照下游每个消费者一个文件的形式组织,当并行度高时会产生大量的文件,容易耗光操作系统的文件描述符,并产生大量随机 IO 对 HDD 磁盘不友好,此外每个文件需要一个独立 Buffer 占内存过多。
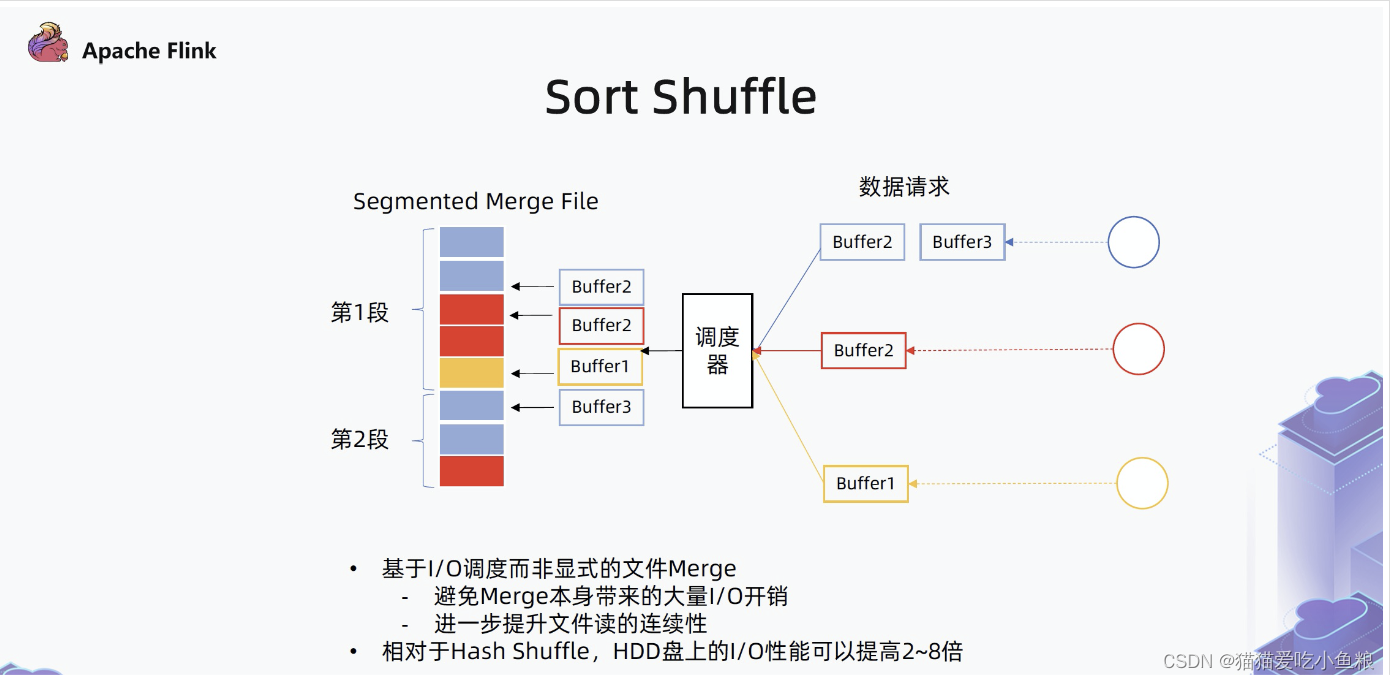
3)Sort-Merge Shuffle
Sort-Merge Shuffle 是将上游所有的结果写入同一个文件,文件内部再按照下游消费者的 ID 进行排序并维护索引,下游有读取数据请求时,则按照索引来读取大文件中的某一段。
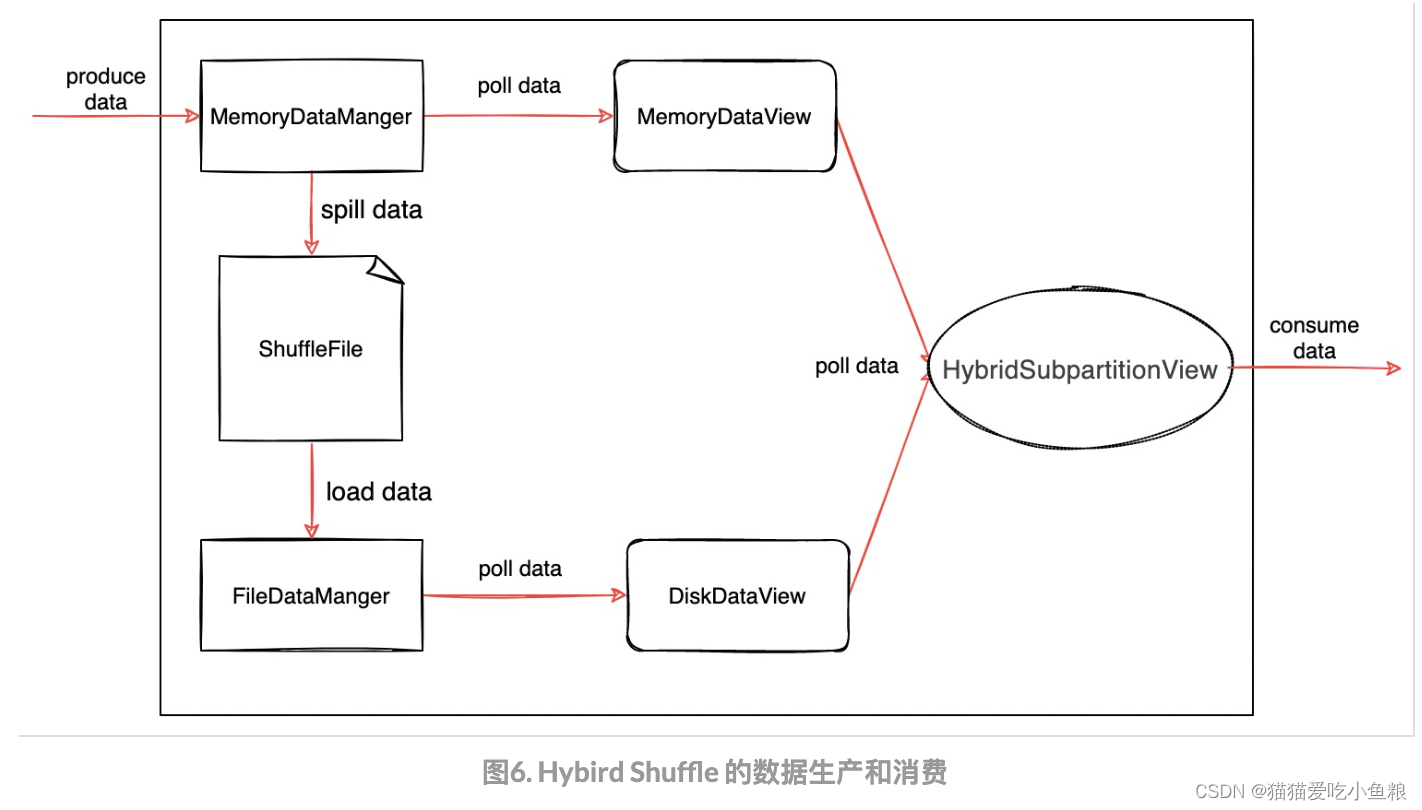
4、流批一体的 Hybrid Shuffle
1)概述
目前的 Hybrid Shuffle 只针对批场景有效。
Hybird Shuffle 支持以内存(Pipelined Shuffle 风格)或文件(Blocking Shuffle 风格)的方式存储上游产出的结果数据,原则是优先内存,内存满了后 spill 到文件。
无论是在内存或者文件中,所有数据在产出后即对下游可见,因此可以同时支持流式的消费或批式的消费。
2)Blocking Shuffle 问题
排斥上下游同时运行,因为上游计算结束之前,下游是没办法访问到其不完整的结果数据的,即使调度下游 Subtask 也只会让其空跑。
流批一体优化:
如果在执行上游作业时,集群有空余资源能跑下游作业,可以尽量 fallback 回 Pipelined Shuffle,用空间换时间,让作业更快完成。
3)案例
背景:以 WordCount 作业为例,假设一共有 2 个 Map 和 2 个 Reduce,但现在计算资源只有 3 个 slot,采用不同的 Shuffle 有以下效果
- Blocking Shuffle: 先调度 2 个 Map,再调度 2 个 Reduce,有 1 个 slot 被浪费。
- Pipelined Shuffle: 要求 4 个 slot,因此作业无法运行。
- Hybird Shuffle: 先调度 2 个 Map 和 1 个 Reduce,剩余一个 Reduce 等三者任意一个完成后再调度。
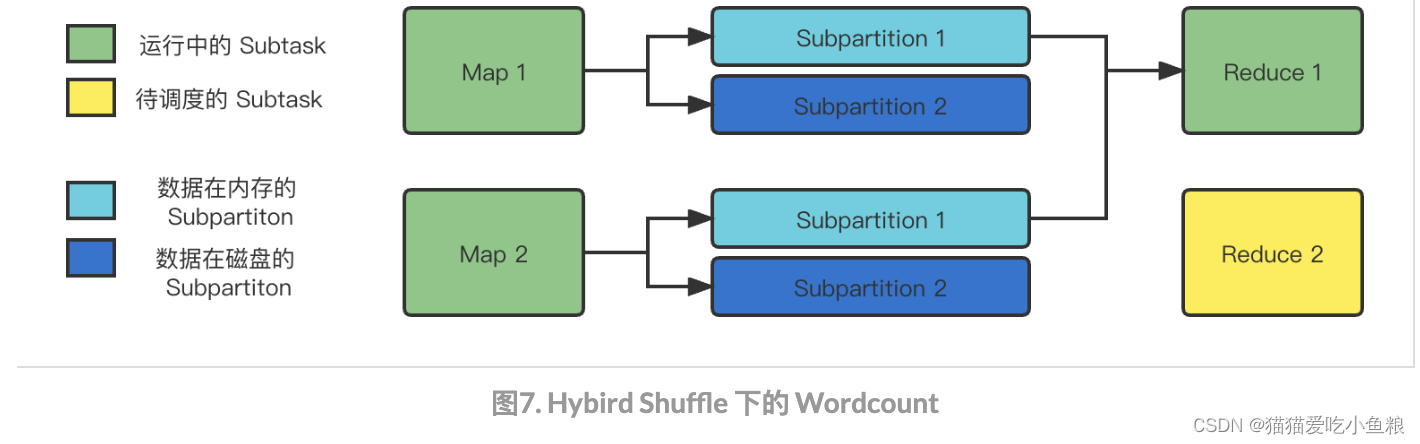
Map 产出的 Subpartition 1 被下游的 Reduce 1 流式读取,因此数据很可能是缓存在内存中;而 Subpartition 2 由于消费者 Reduce 2 还未运行,所以数据可能会在内存满之后 spill 到磁盘,等 Reduce 2 启动后再读取。
二、Spark Shuffle 详解
0、总结
Shuffle Write:对Map结果进行聚合、排序、分区输出;
Shuffle Read:拉取MapTask的结果进行聚合、排序;
1、概述
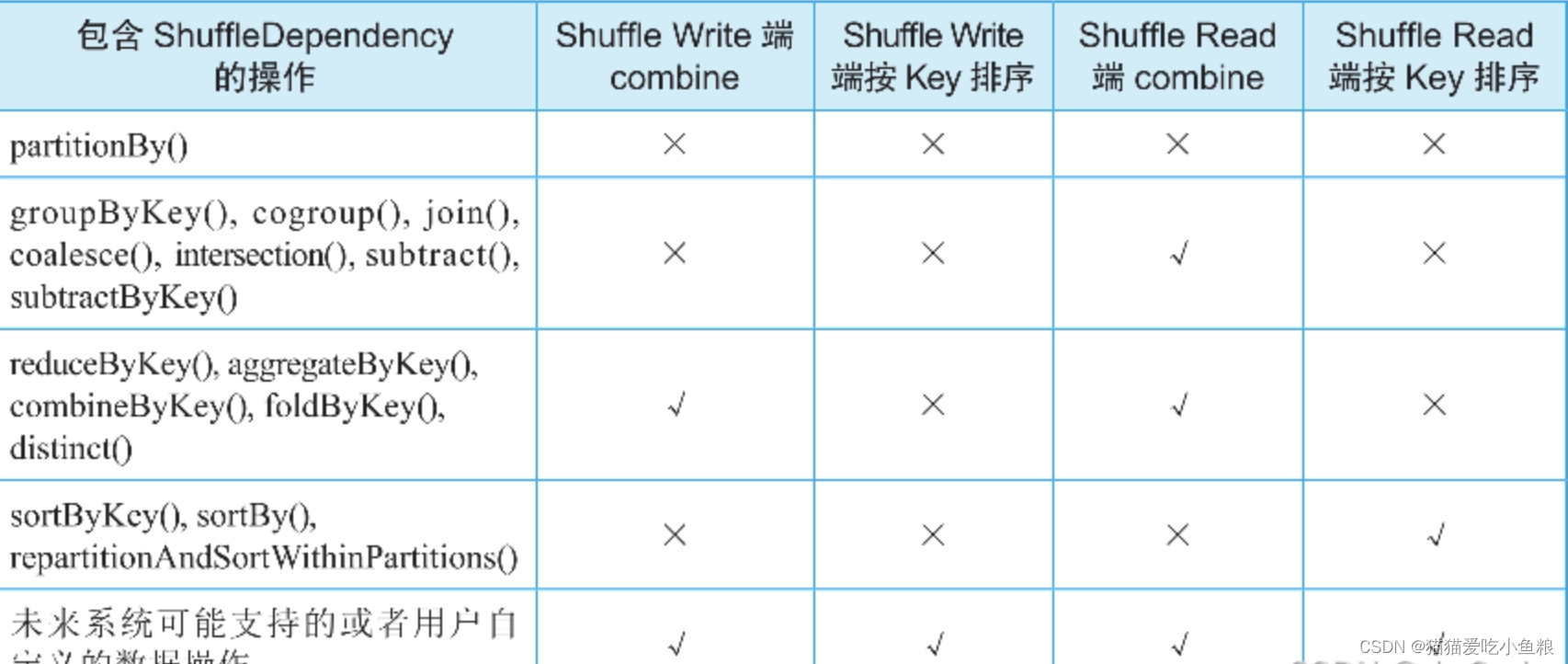
Spark Shuffle 是发生在宽依赖(Shuffle Dependency)的情况下,上游 Stage 和下游 Stage 之间传递数据的一种机制。
Shuffle 解决的是如何将数据重新组织,使其能够在上游和下游 task 之间进行传递和计算。
2、难点
需要计算(如聚合、排序)
数据量很大
3、分类
Spark Shuffle 分为 Shuffle Write 和 Shuffle Read 两个部分。
Shuffle Write:解决上游 Stage 输出数据的分区问题;
Shuffle Read:解决下游Stage从上游Stage获取数据、重新组织、并为后续操作提供数据的问题;
4、Shuffle Write
1)概述
Shuffle Write 阶段,数据操作需要分区、聚合和排序,不同的数据操作所需要的功能不同,有些数据操作只需要一到两个功能。
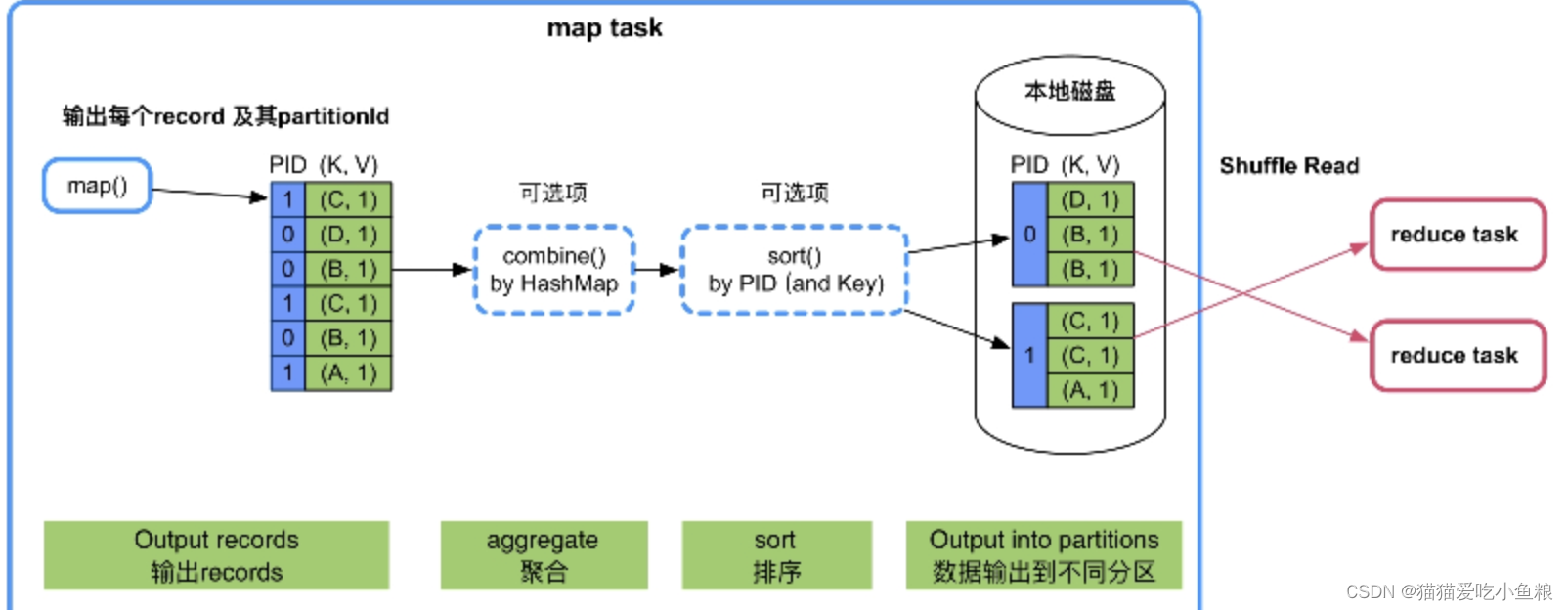
Shuffle Write有一个总体的设计框架,即 “map()输出->数据聚合(combine)->排序(sort)->分区”。
2)不需要聚合(combine)和排序(sort)
只需将数据分区,输出每条数据并通过hash取模(hashcode(key)%numPartitions)计算其分区id,然后按照分区 id 输入到不同的buffer 中,每当 buffer 填满时就溢写到磁盘分区文件中。
使用 buffer 是为了减少磁盘 I/O 次数,用缓冲提高效率,这种 Shuffle Write 叫做 BypassMergeSortShuffleWriter。
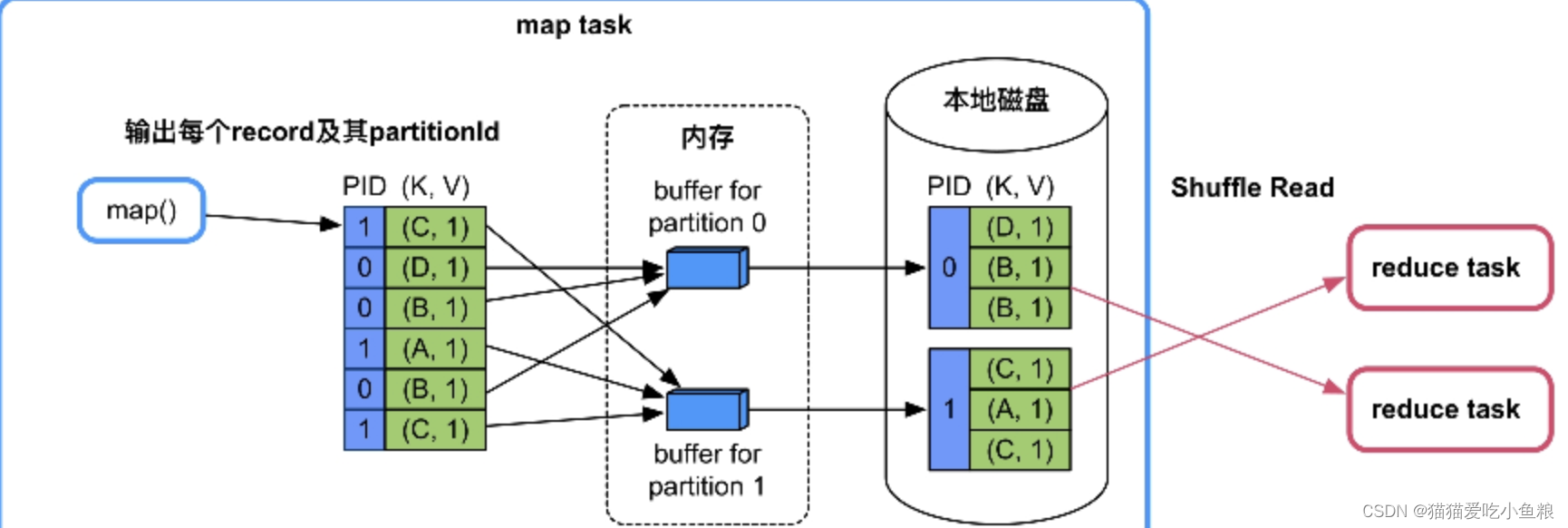
优点:
速度快,不需要聚合和排序操作,直接按照分区输出
缺点:
资源消耗高,每个分区都需要一个 buffer 和分区文件,不适合过大的分区数
场景:
map 端不需要聚合 (combine)、Key 不需要排序且分区个数较少 (spark.Shuffle.sort.bypassMergeThreshold,默认值为200)
例如,groupByKey(100),partitionBy(100),sortByKey(100) 等。
3)不需要聚合(combine),但需要排序(sort)
在计算出分区 id 后,会把数据放到一个 Array 中,会让 Array 的 Key 变成分区 id+Key 的形式,在 Spark Shuffle 中,这个 Array 叫PartitionedPairBuffer。
然后按照分区 id+Key 做排序,如果在接收数据过程中 buffer 满了,会先扩容,如果还存不下,会将当前 buffer 排序后溢写到磁盘,清空 buffer 继续写。
等数据输出完后,再将 Array 和磁盘的数据做全局排序,得到一个大的排序的分区文件,这个 Shuffle 模式叫做SortShuffleWrite。
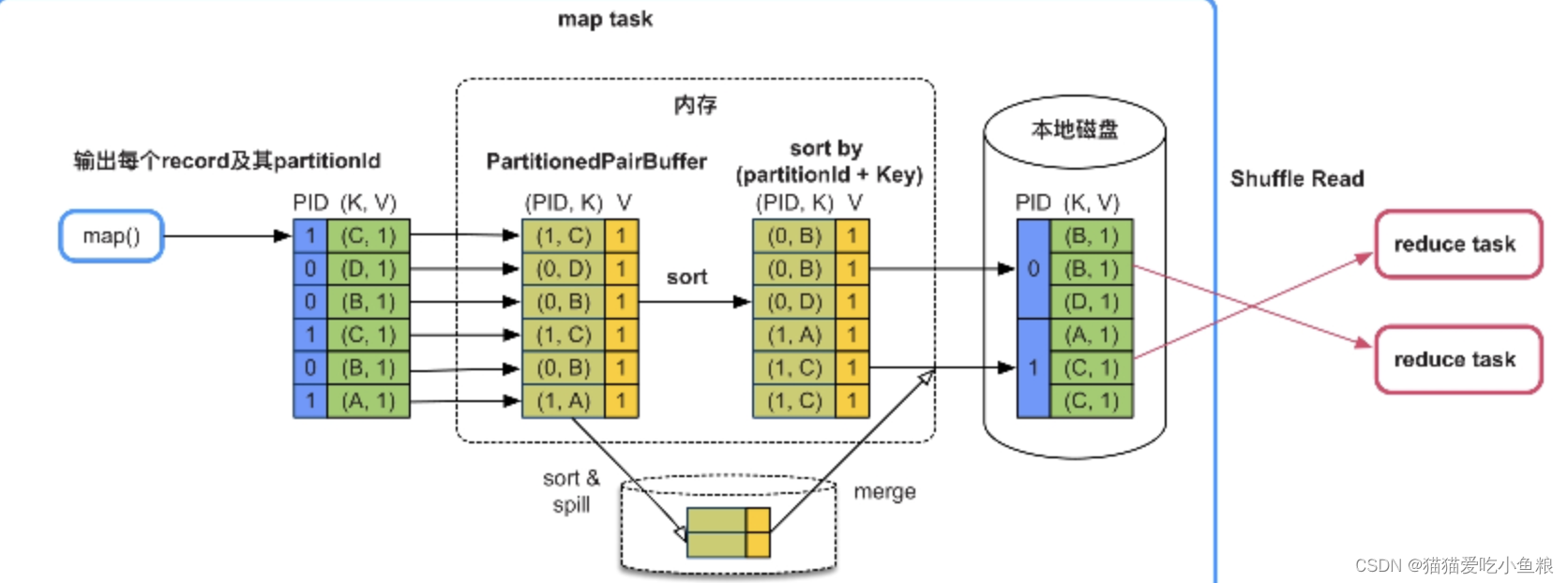
优点:
可以按照分区 id+Key 排序,并且 buffer 有扩容和溢写的功能,最后会整合到一个分区文件中,减少了磁盘I/O
缺点:
排序提高了计算时延
场景:
map 端不需要聚合(combine)、Key 需要排序、分区个数无限制
注意:
目前 Spark 没有提供这种排序类型的数据操作,sortByKey 操作虽然需要按 Key 排序,但排序过程在 Shuffle Read 端完成即可,不需要在 Shuffle Write 端排序。
BypassMergeSortShuffleWriter 的问题是分区过多 (>200) 会导致 buffer 过大、建立和打开文件数过多,可以将 SortShuffleWrite 中的"按照分区id+Key排序"改为“只按分区id排序”,就可以支持第一种情况中分区数过多的问题,例如 groupByKey(300)、partitionBy(300)、sortByKey(300)。
4)需要聚合(combine),需要或者不需要按Key进行排序(sort)
在数据聚合阶段,Spark Shuffle 会创建一个 Map 结构来聚合数据,Map 的数据格式是<(PID, K), V>,每次来数据时会按照分区id+Key来给数据做聚合,每来一条新数据就以 Map 的旧数据去更新 Map 的值。
数据聚合后,会通过 Array 将数据排序,如果需要按照 Key 排序,就按照分区id+Key来排序;如果不需要按照Key排序,那么只按照分区id排序。
如果Map放不下,会先扩容一倍,如果还放不下,就把Map中的数据排序后溢写到磁盘,并清空Map继续聚合,这个操作可以重复多次,当数据处理完后,会把Map数据和磁盘中的数据再次聚合(merge),最后得到一个聚合与排序后的分区文件。
优点:
只需要一个Map结构就可以支持map()端的combine功能,Map具有扩容和spill到磁盘的功能,支持小规模到大规模数据的聚合,也适用于分区个数很大的情况。
在聚合后使用Array排序,可以灵活支持不同的排序需求。
缺点:
在内存中聚合,内存消耗较大,需要额外的数组进行排序,如果有数据spill到磁盘上,还需要再次进行聚合。
注意:
Spark在Shuffle Write中,使用一个经过特殊设计和优化的Map,命名为PartitionedAppendOnlyMap,可以同时支持聚合和排序操作,相当于Map和Array的合体。
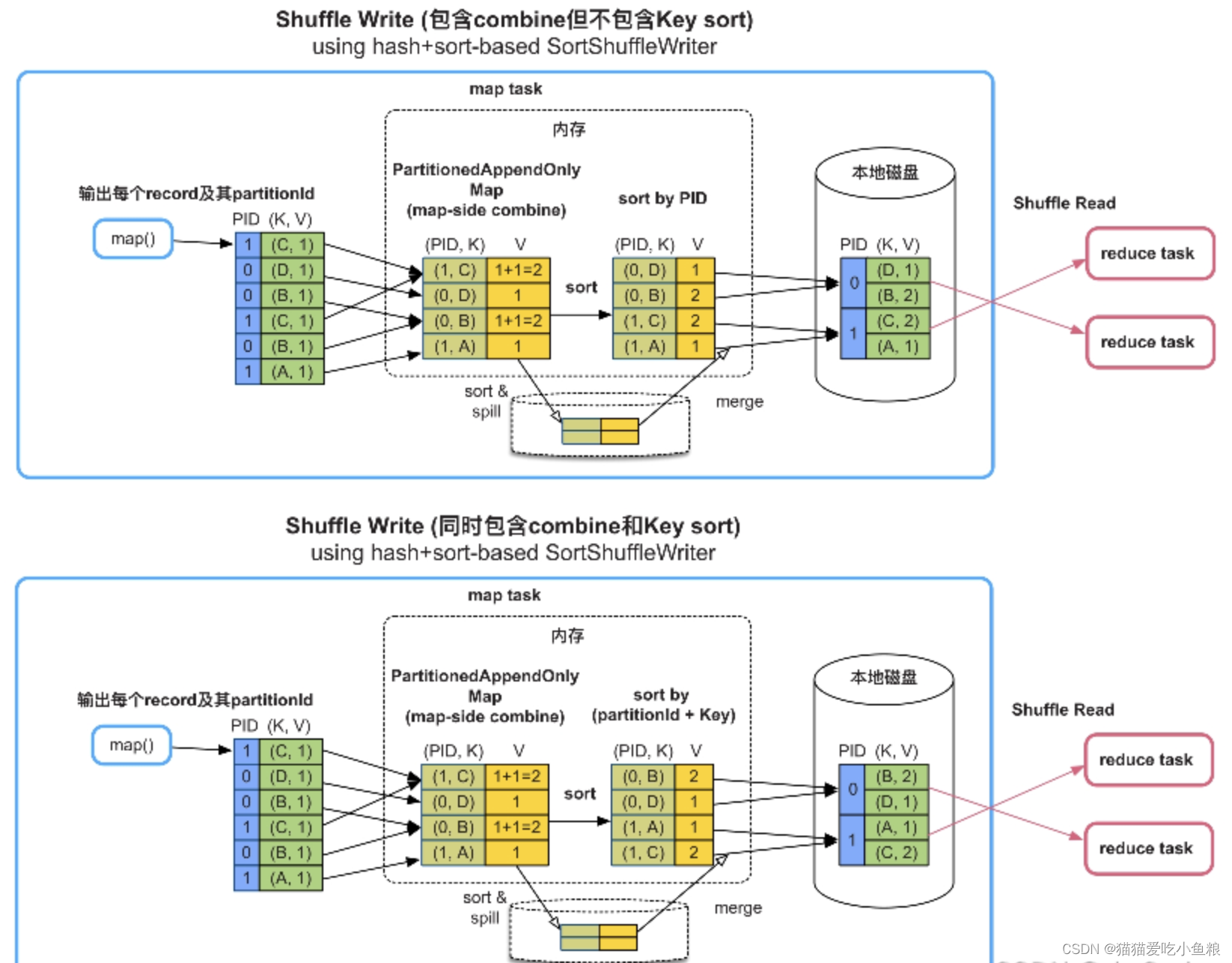
场景:
适合 map 端聚合(combine)、需要或者不需要按 Key 排序、分区个数无限制,如reduceByKey()、aggregateByKey()等。
5)总结
Shuffle Write 框架执行的3个步骤是"数据聚合→排序→分区"。
- 如果应用中的数据操作不需要聚合,也不需要排序,而且分区个数很少,可以直接输出,即BypassMergeSortShuffleWriter。
- 为克服BypassMergeSortShuffleWriter打开文件过多、buffer分配过多的缺点,也为了支持需要按Key排序的操作,Spark提供了SortShuffleWriter,基于Array排序的方法,以分区id或分区id+Key排序,只输出单一的分区文件即可。
- 为支持map()端combine操作,Spark提供了基于Map的SortShuffleWriter,将Array替换为类似HashMap的操作来支持聚合操作,在聚合后根据partitionId或分区id+Key对record排序,并输出分区文件。
5、Shuffle Read
1)概述
Shuffle Read 需要 “跨节点数据获取->聚合->排序”
Reduce Task从各个Map Task端获取属于该分区的数据,然后使用Map边获取数据边聚合,聚合完成后,放到Array中根据Key排序,最后将结果输出或者传递给下一个操作。
不需要聚合或排序的算子可以省下这些功能。
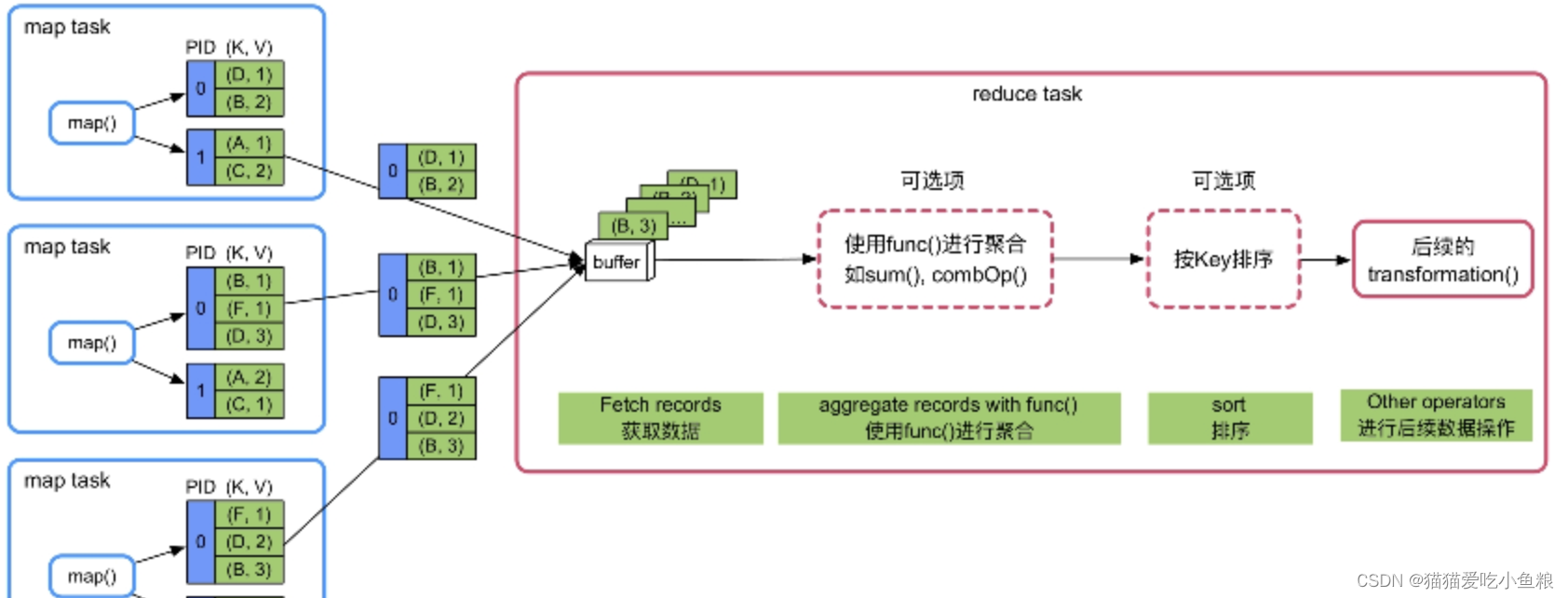
2)不需要聚合(combine)和排序(sort)
只需把各个Map Task获取的数据输出到buffer即可。
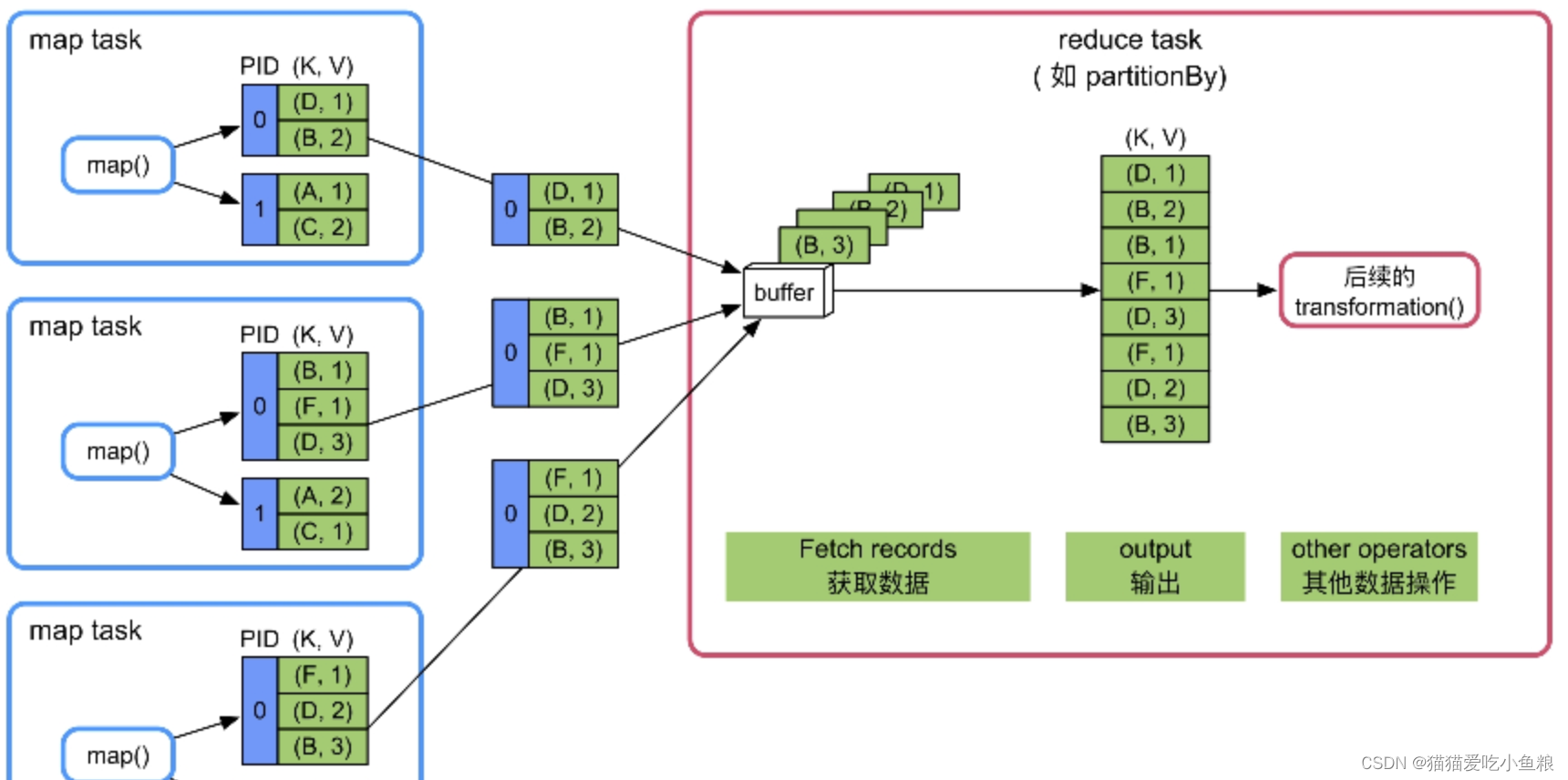
优点:
逻辑和实现简单,内存消耗小
缺点:
不支持聚合、排序等复杂功能
场景:
既不需要聚合也不需要排序的应用,如partitionBy()等。
3)不需要聚合(combine),需要按Key排序
把数据从Map Task端获取后,将buffer中的数据输出到一个Array中,使用Shuffle Write的PartitionedPairBuffer排序,保留了分区id,即使一个Reduce Task中的分区都是相同的。
当内存无法存下数据时,PartitionedPairBuffer会尝试扩容,若内存仍不够,就会在排序后将数据溢写到磁盘中,当所有数据都接收到后,再将buffer中的数据和磁盘中的数据做merge sort。
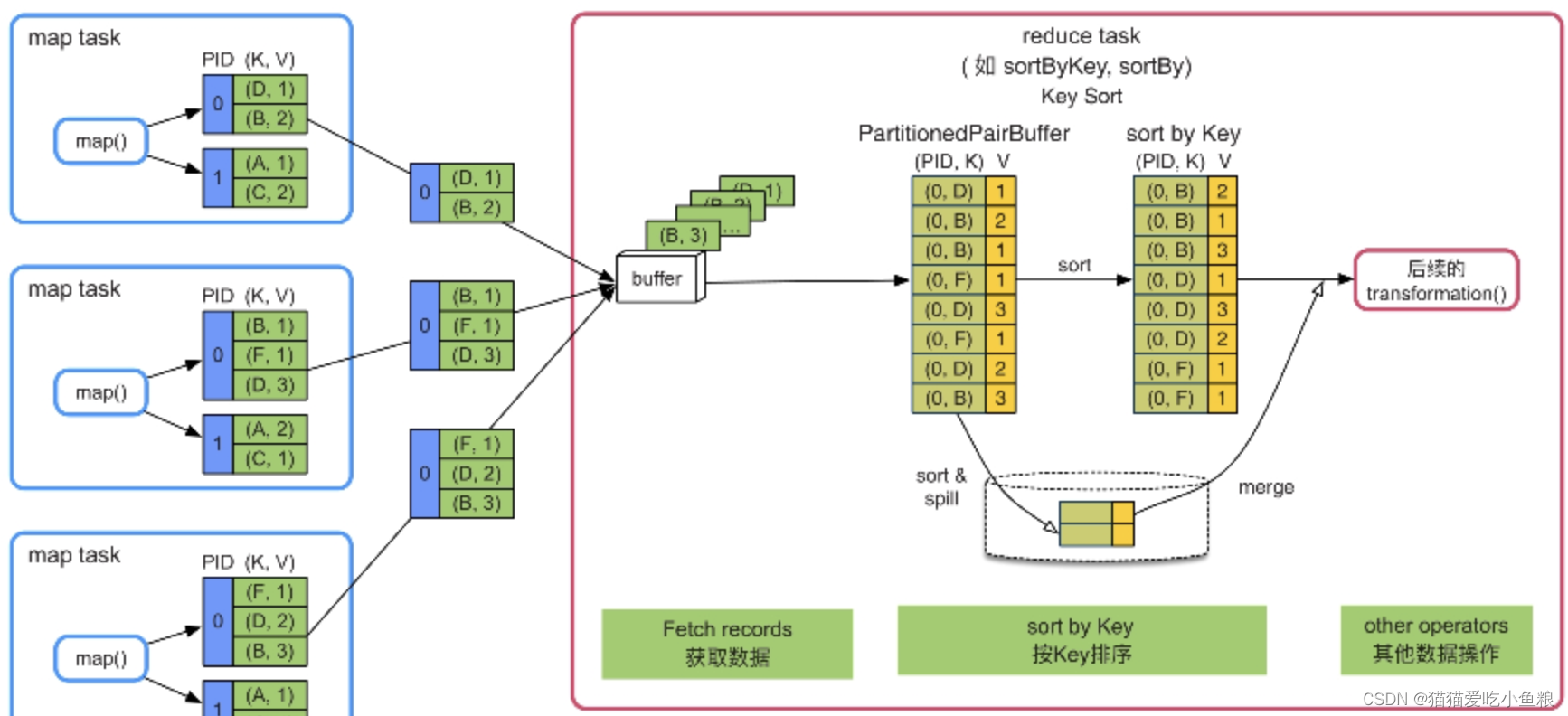
优点:
只需要一个Array就可以按照Key排序
Array大小可控,可以扩容和spill到磁盘,不受数据规模限制
缺点:
排序增加计算时延
场景:
适合reduce端不需要聚合,但需要按Key进行排序的操作,如sortByKey()、sortBy()等。
4)需要聚合(combine)不需要或者需要按Key进行排序(sort)
获取数据后会建立一个Map来对数据做聚合(ExternalAppendOnlyMap)聚合操作和Shuffle Write一致,用旧值和新数据更新新值。
聚合操作后,如果需要排序,就建立一个Array并排序,排序后将结果输出或者传递给下一步操作。
如果Map放不下,会先扩容一倍,如果还不够,会在排序后溢写到磁盘,数据都处理完后再将内存和磁盘的数据做聚合、排序,再将数据交给下一步操作。
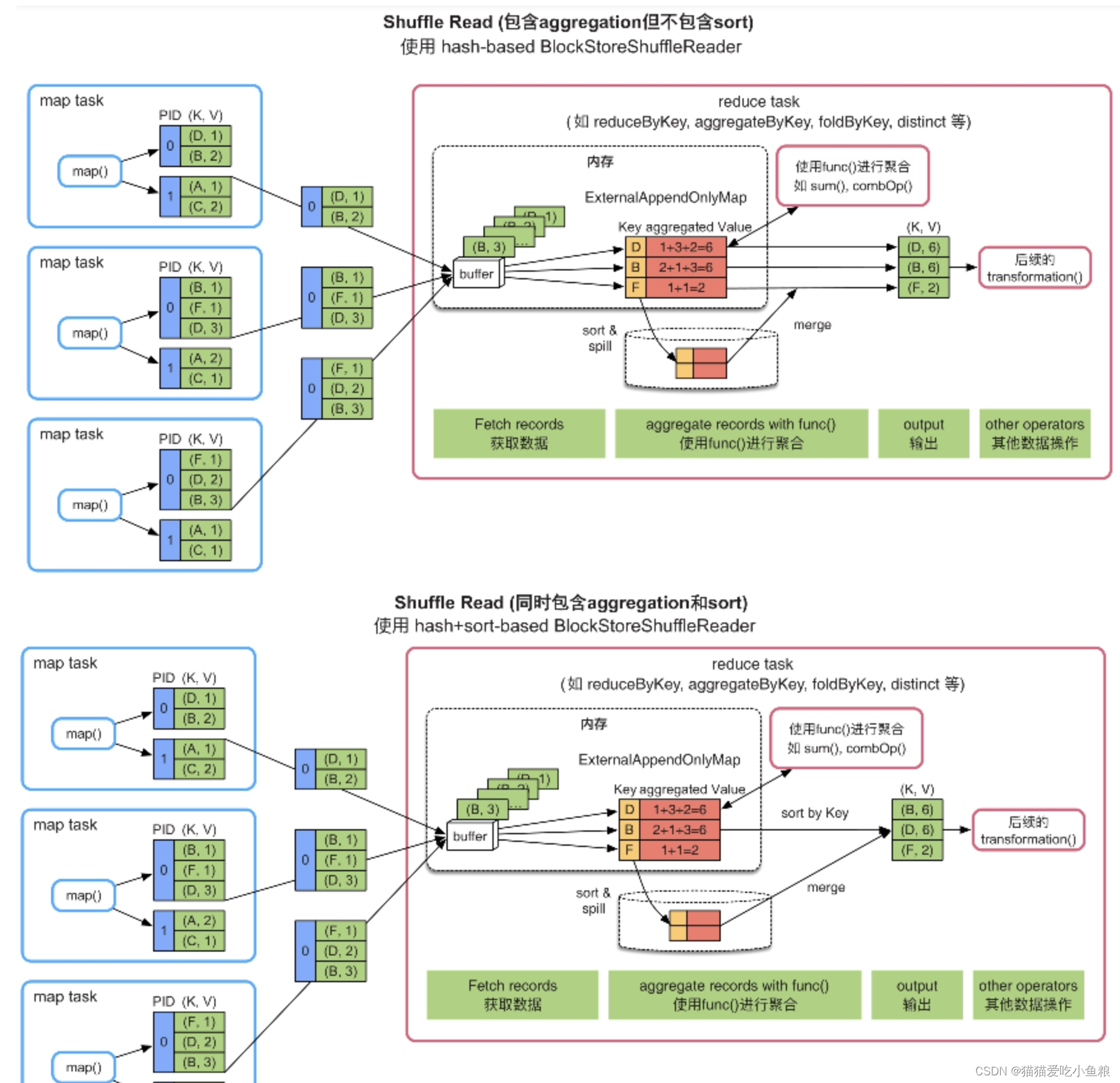
优点:
只需要一个Map和一个Array就可以支持reduce端的聚合和排序功能
Map 具有扩容和spill到磁盘的功能,支持小规模到大规模数据的聚合,边获取数据边聚合,效率较高
缺点:
需要在内存中聚合,内存消耗较大,如果有数据spill到磁盘上,还需要再次聚合
经过HashMap聚合后的数据仍然需要拷贝到Array中排序,内存消耗较大
场景:
适合reduce端需要聚合、不需要或需要按Key排序的操作,如reduceByKey()、aggregateByKey()等。
5)总结
Shuffle Read框架执行的3个步骤是 “数据获取→聚合→排序输出”
- 对于需要按Key进行排序的操作,Spark 使用基于Array的方法来对Key进行排序。
- 对于需要聚合的操作,Spark提供了基于HashMap的聚合方法,可以再次使用Array来支持按照Key排序。
6、为高效聚合和排序所设计的数据结构
1)概述
为提高Shuffle的聚合与排序性能,Spark Shuffle设计了三种数据结构,基本思想都是在内存中对record进行聚合和排序,如果存放不下,则进行扩容,如果还存放不下,就将数据排序后spill到磁盘,最后将磁盘和内存中的数据聚合、排序,得到最终结果。

2)特征
Shuffle Write/Read过程中使用数据结构的两个特征:
一是只需要支持record的插入和更新操作,不需要支持删除操作,可以对数据结构进行优化,减少内存消耗;
二是只有内存放不下时才需要spill到磁盘,数据结构的设计以内存为主,磁盘为辅;
3)AppendOnlyMap
AppendOnlyMap是一个只支持record添加和对Value更新的HashMap。
与Java HashMap采用“数组+链表”实现不同,AppendOnlyMap只使用数组来存储元素,根据元素的Hash值确定存储位置,如果存储元素时发生Hash值冲突,则使用二次地址探测法(Quadratic probing)来解决Hash值冲突。
对于每个新来的〈K,V〉record,先使用Hash(K)计算其存放位置,如果存放位置为空,就把record存放到该位置。如果该位置已经被占用,就使用二次探测法来找下一个空闲位置。
举例:对于新来的〈K6,V6〉record,第1次找到的位置Hash(K6)已被K2占用,按照二次探测法向后递增1个record位置,也就是Hash(K6)+1×2,发现位置已被K3占用,然后向后递增4个record位置(指数递增,Hash(K6)+2×2),发现位置没有被占用,放进去即可。
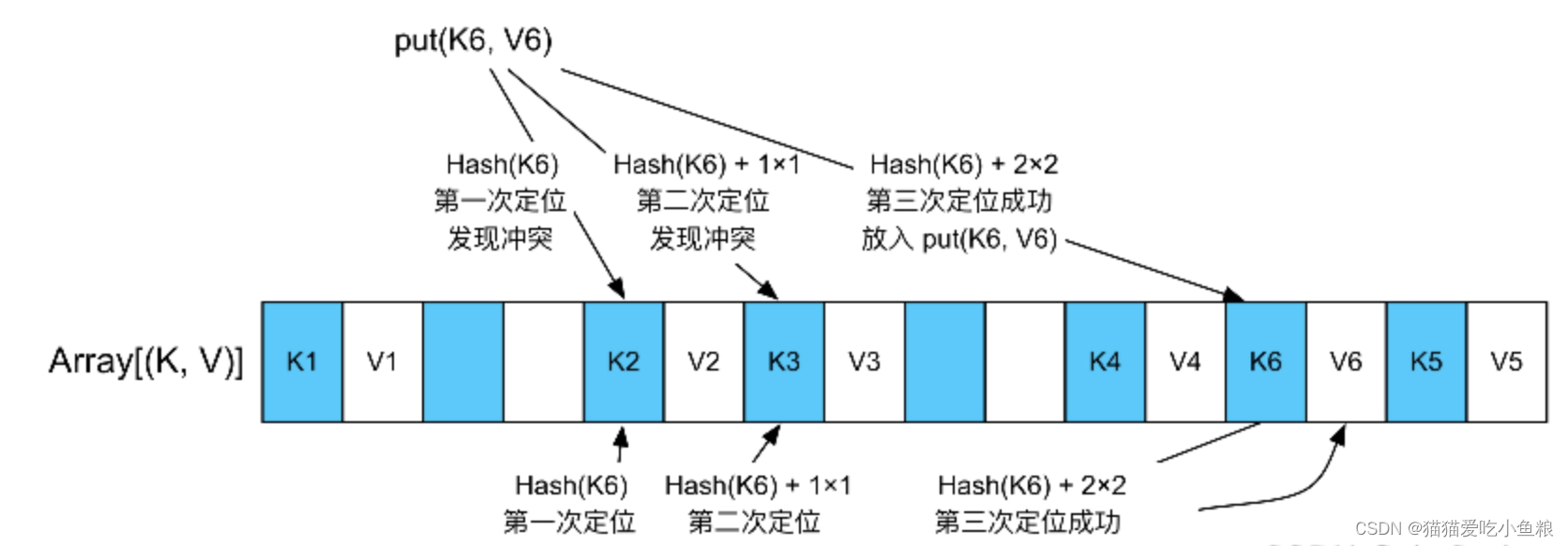
扩容:AppendOnlyMap使用数组实现的问题是,如果插入record太多,很快会被填满,Spark的解决方案是,如果AppendOnlyMap的利用率达到70%,就扩张一倍,扩张意味着原来的Hash失效,因此对所有Key进行rehash,重新排列每个Key的位置。
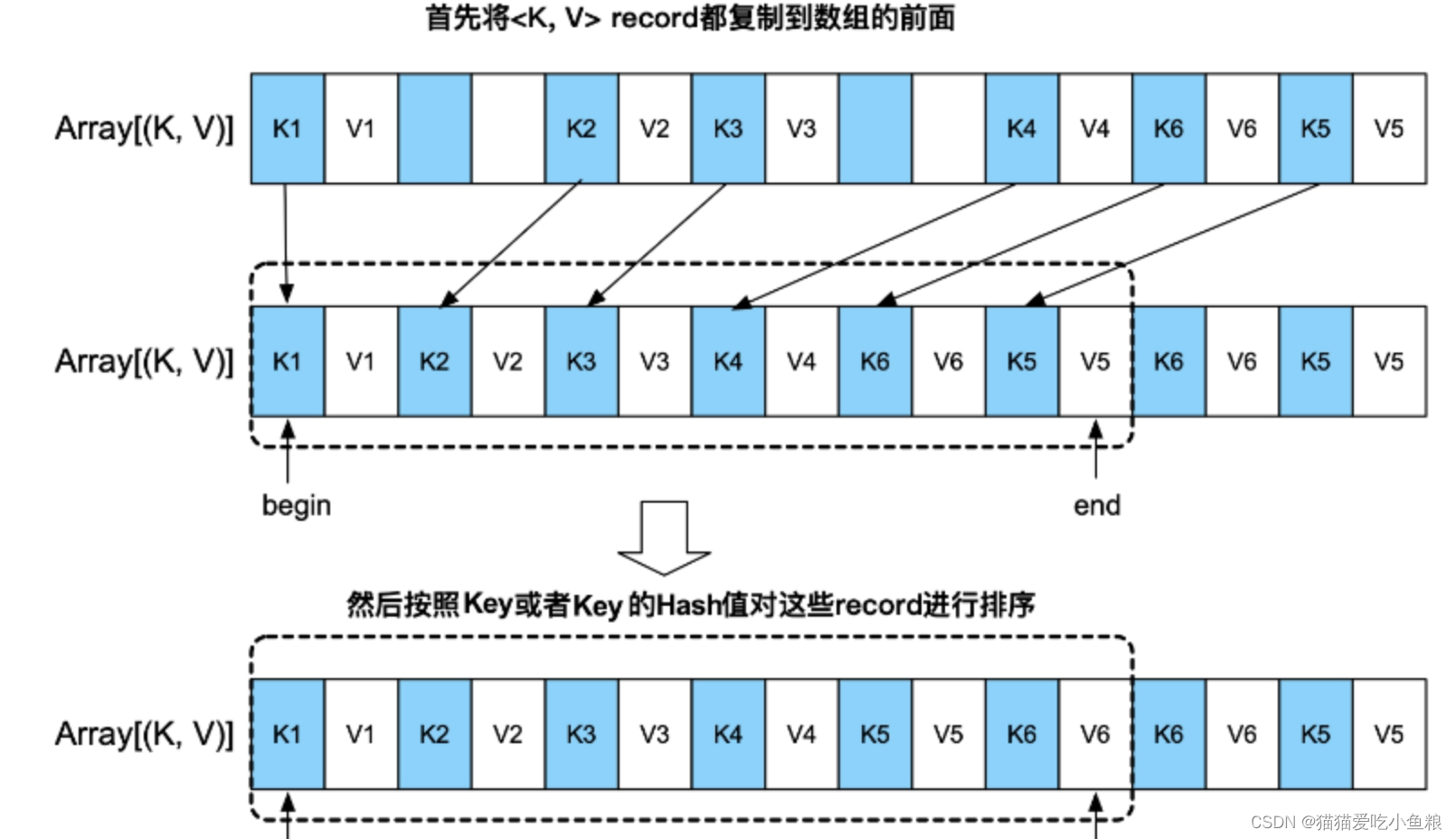
排序:由于AppendOnlyMap采用数组作为底层存储结构,支持快速排序等排序算法,先将数组中所有的〈K,V〉record转移到数组的前端,用begin和end来标示起始位置,然后调用排序算法对[begin,end]中的record排序,对于需要按Key排序的操作,如sortByKey,可以按照Key值排序;对于其他操作,只按照Key的Hash值排序即可。
4)ExternalAppendOnlyMap
1.ExternalAppendOnlyMap
a) AppendOnlyMap
优点:将聚合和排序功能结合在一起
缺点:只能使用内存,难以适用于内存空间不足的情况
方案:
Spark基于AppendOnlyMap设计实现了基于内存+磁盘的ExternalAppendOnlyMap,用于Shuffle Read端大规模数据聚合。
b)ExternalAppendOnlyMap
工作原理:
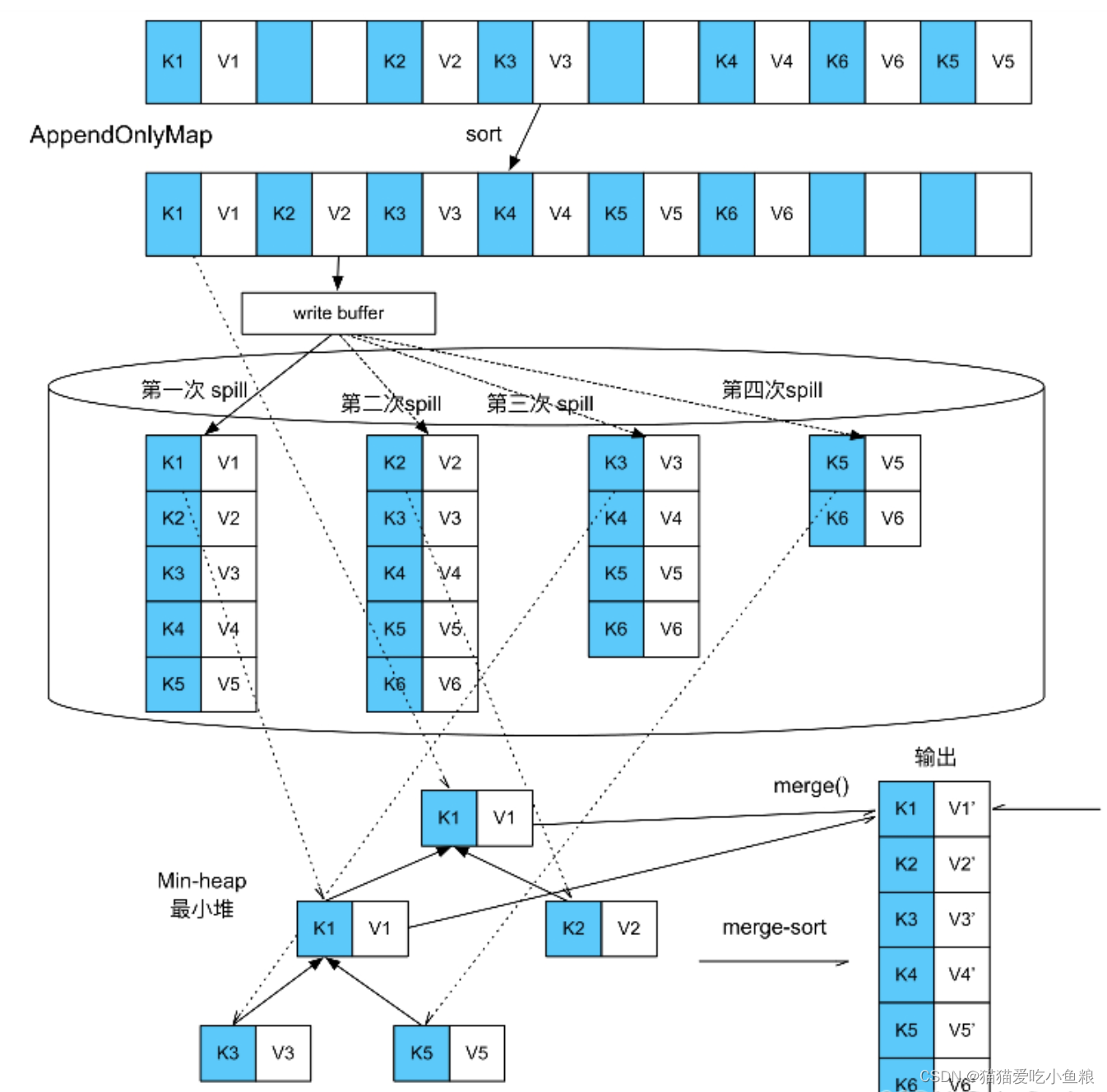
先持有一个AppendOnlyMap来不断接收和聚合新来的record,AppendOnlyMap快被装满时检查内存剩余空间是否可以扩展,可直接在内存中扩展,不可对AppendOnlyMap中的record进行排序,然后将record都spill到磁盘上。
因为record不断到来,可能会多次填满AppendOnlyMap,所以spill过程可以出现多次,最终形成多个spill文件。
等record都处理完,此时AppendOnlyMap中可能还留存聚合后的record,磁盘上也有多个spill文件。
ExternalAppendOnlyMap的最后一步是将内存中AppendOnlyMap的数据与磁盘上spill文件中的数据进行全局聚合,得到最终结果。
核心问题:
i)如何获知当前AppendOnlyMap的大小?因为AppendOnlyMap中不断添加和更新record,其大小是动态变化的,什么时候会超过内存界限是难以确定的。
ii)如何设计spill的文件结构,使得可以支持高效的全局聚合?
iii)怎样全局聚合?
AppendOnlyMap的大小估计
难点:
已知AppendOnlyMap中持有的数组的长度和大小,但数组里面存放的是Key和Value的引用,并不是实际对象(object)大小,而且Value会不断被更新,实际大小不断变化,想准确得到AppendOnlyMap的大小比较困难。
简单的解决方法
每次插入record或对现有record的Value更新后,扫描AppendOnlyMap中存放的record,计算每个record实际对象大小并相加,但这非常耗时,一般AppendOnlyMap会插入几万甚至几百万个record,如果每个record进入AppendOnlyMap都计算一遍,开销很大。
Spark设计的增量式的高效估算算法
在每个record插入或更新时,根据历史统计值和当前变化量直接估算当前AppendOnlyMap的大小,算法的复杂度是O(1),开销很小。
在record插入和聚合过程中会定期对当前AppendOnlyMap中的record抽样,然后精确计算record的总大小、总个数、更新个数及平均值等,并作为历史统计值。
进行抽样是因为AppendOnlyMap中的record可能有上万个,难以对每个都精确计算,之后,每当有record插入或更新时,会根据历史统计值和历史平均的变化值,增量估算AppendOnlyMap的总大小,抽样也会定期进行,更新统计值以获得更高的精度。
Spill过程与排序
当AppendOnlyMap达到内存限制时,会将record排序后写入磁盘中,排序是为了方便下一步全局聚合(聚合内存和磁盘上的record)时可以采用更高效的merge-sort(外部排序+聚合)。
根据什么对record排序?
大部分操作,如groupByKey(),并没有定义Key的排序方法,也不需要输出结果是按照Key排序的,在这种情况下,Spark采用按照Key的Hash值排序的方法,既可以进行merge-sort,又不要求操作定义Key排序的方法,这种方法的问题是会出现Hash值冲突,也就是不同的Key具有相同的Hash值,为了解决这个问题,Spark在merge-sort的同时会比较Key的Hash值是否相等,以及Key的实际值是否相等。
由于最终的spill文件和内存中的AppendOnlyMap都是经过部分聚合后的结果,可能存在相同Key的record,还需要一个全局聚合阶段将AppendOnlyMap中的record与spill文件中的record聚合,得到最终聚合后的结果。
方案:
全局聚合的方法是建立一个最小堆或最大堆,每次从各个spill文件中读取前几个具有相同Key(或者相同Key的Hash值)的record,然后与AppendOnlyMap中的record进行聚合,并输出聚合后的结果。
举例:
在全局聚合时,Spark分别从4个spill文件中提取第1个〈K,V〉record,与还留在AppendOnlyMap中的第1个record组成最小堆,然后不断从最小堆中提取具有相同Key的record进行聚合merge,然后,Spark继续读取spill文件及AppendOnlyMap中的record填充最小堆,直到所有record处理完成,由于每个spill文件中的record是经过排序的,按顺序读取和聚合可以保证对每个record得到全局聚合的结果。
总结:
ExternalAppendOnlyMap是一个高性能的HashMap,只支持数据插入和更新,但可以同时利用内存和磁盘对大规模数据进行聚合和排序,满足了Shuffle Read阶段数据聚合、排序的需求。
2.PartitionedAppendOnlyMap
PartitionedAppendOnlyMap用于在Shuffle Write端对record聚合combine,PartitionedAppendOnlyMap的功能和实现与ExternalAppendOnlyMap的功能和实现基本一致。
唯一区别是PartitionedAppendOnlyMap中的Key是"PartitionId+Key",既可以根据partitionId排序(面向不需要按Key排序的操作),也可以根据partitionId+Key排序(面向需要按Key排序的操作),从而在Shuffle Write阶段进行聚合、排序和分区。
3.PartitionedPairBuffer
PartitionedPairBuffer本质上是一个基于内存+磁盘的Array,随着数据添加,不断扩容,当到达内存限制时,就将Array中的数据按照partitionId或partitionId+Key排序,然后spill到磁盘上,该过程可以进行多次,最后对内存和磁盘上的数据进行全局排序,输出或者提供给下一个操作。
三、MapReduce shuffle 详解
0、总结
Map计算后:对Map的结果进行分区、溢写、排序、合并输出到文件中;
Reduce计算前:拉取Map输出的结果文件中属于自己分区的数据,进行合并排序;
1、MapReduce 计算模型
MapReduce 计算模型由三个阶段构成:Map、shuffle、Reduce。
Map:将原始数据转化为键值对;
Reduce:将具有相同key值的value处理后再输出新的键值对作为最终结果;
Shuffle:对Map的输出进行排序与分割,然后交给对应的Reduce,以便Reduce可以并行处理Map的结果;
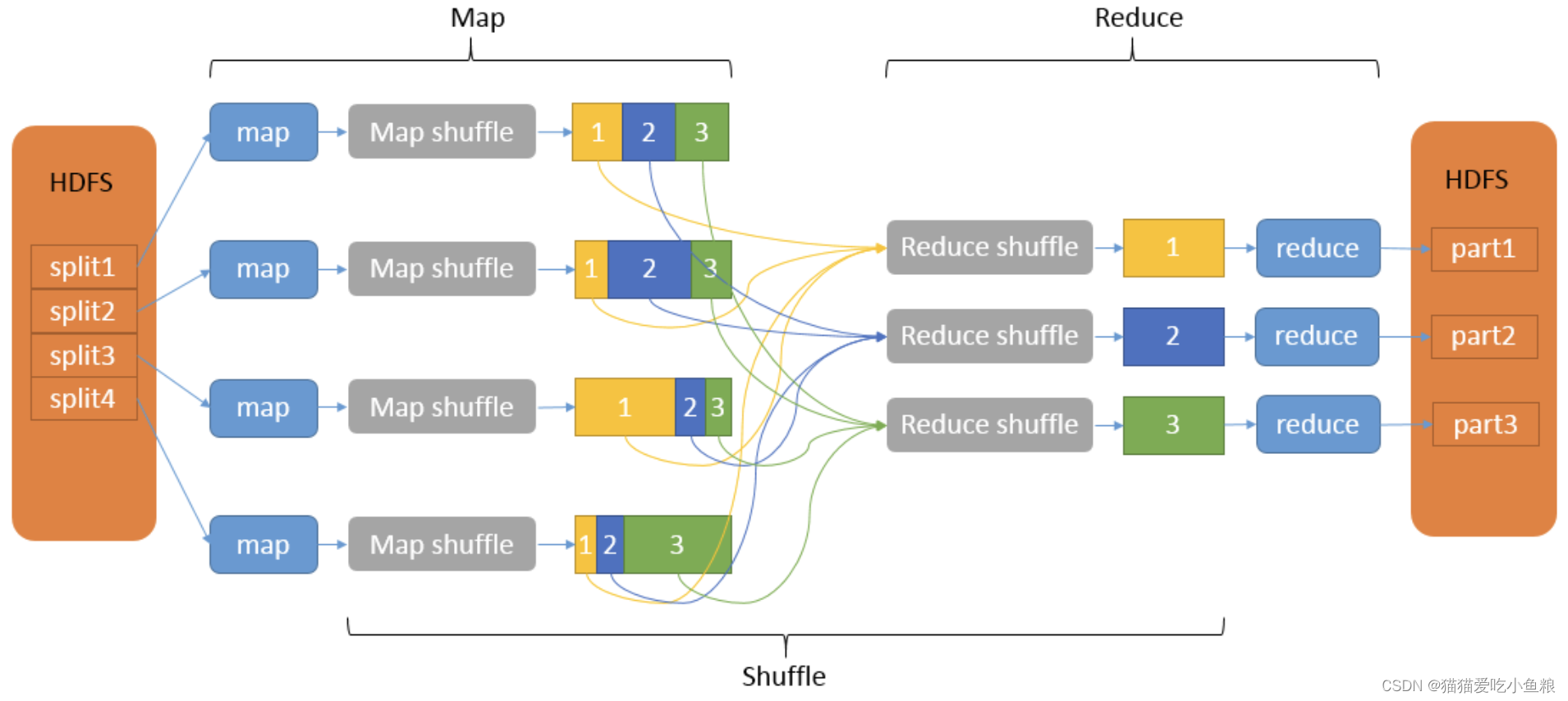
Shuffle过程包含在Map和Reduce两端,即Map shuffle和Reduce shuffle。
2、Map shuffle
对Map的结果,分区、排序、分割,然后将属于同一分区的输出合并在一起并写在磁盘上,最终得到一个分区有序的文件,分区有序的含义是map输出的键值对按分区排列,具有相同partition值的键值对存储在一起,每个分区里面的键值对又按key值升序排列。
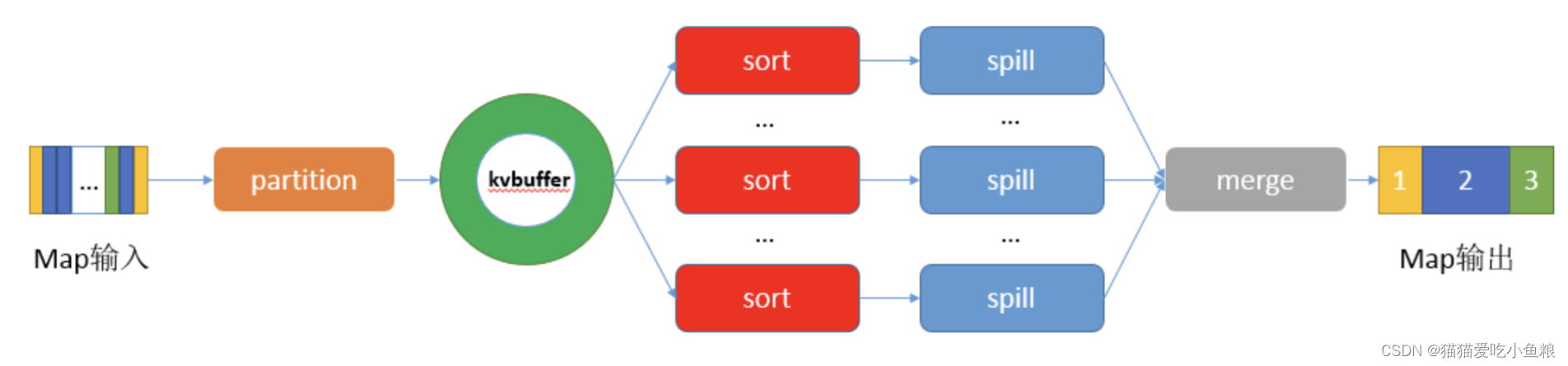
1)Partition
map输出的每一个键值对,系统都会给定一个partition,partition值默认是通过计算key的hash值后对Reduce task的数量取模获得。
2)Collector
Map的输出结果由collector处理,每个Map任务不断地将键值对输出到在内存中构造的一个环形数据结构中,使用环形数据结构是为了更有效地使用内存空间,在内存中放置尽可能多的数据。
环形数据结构是字节数组叫Kvbuffer,不仅存储数据,还存储索引,放置索引的区域叫Kvmeta。
数据区域和索引数据区域在Kvbuffer中是相邻不重叠的两个区域,用一个分界点来划分两者,分界点不是亘古不变的,而是每次Spill之后都会更新一次。初始的分界点是0,数据的存储方向是向上增长,索引数据的存储方向是向下增长。
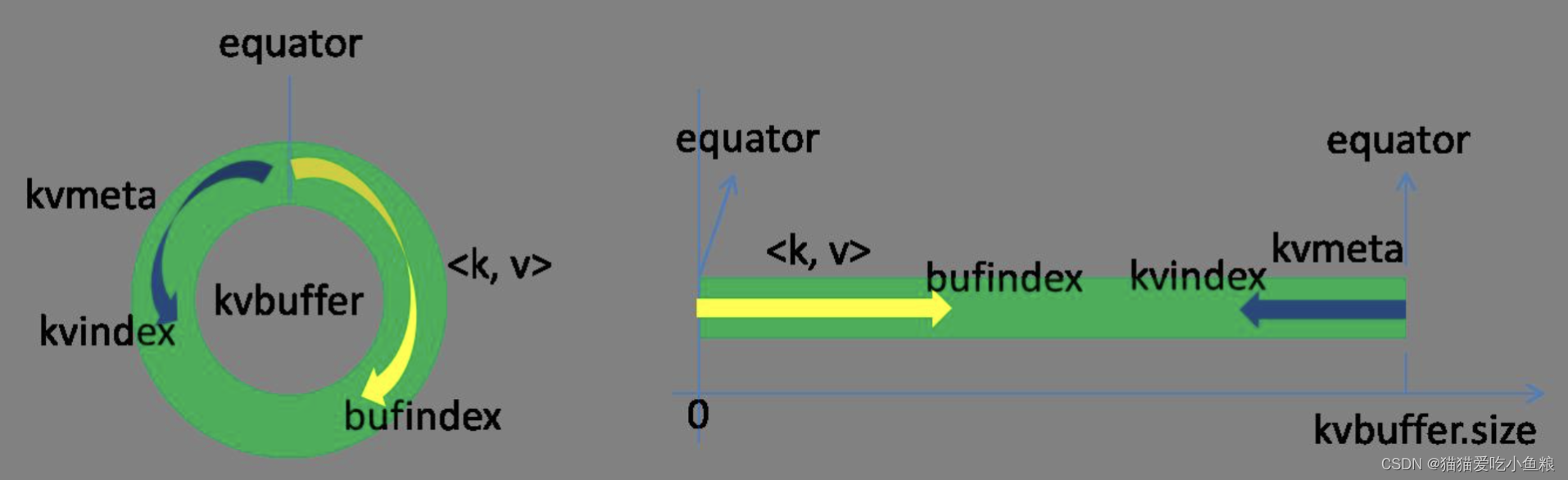
bufindex:
Kvbuffer的存放指针bufindex是向上增长,比如bufindex初始值为0,一个Int型的key写完之后,bufindex增长为4,一个Int型的value写完之后,bufindex增长为8。
Kvindex:
索引是对在kvbuffer中的键值对的索引,是个四元组,包括:value的起始位置、key的起始位置、partition值、value的长度,占用四个Int长度,Kvmeta的存放指针Kvindex每次向下跳四个“格子”,然后再向上一个格子一个格子地填充四元组的数据。
比如Kvindex初始位置是-4,当第一个键值对写完之后,(Kvindex+0)的位置存放value的起始位置、(Kvindex+1)的位置存放key的起始位置、(Kvindex+2)的位置存放partition的值、(Kvindex+3)的位置存放value的长度,然后Kvindex跳到-8位置,等第二个键值对和索引写完之后,Kvindex跳到-12位置。
Kvbuffer:
Kvbuffer的大小可以通过io.sort.mb设置,默认大小为100M,随着键值对和索引不断增加,当容量不足时,把数据从内存刷到磁盘上再接着往内存写数据,把Kvbuffer中的数据刷到磁盘上的过程就叫Spill。
Spill触发的条件:
如果把Kvbuffer用完再开始Spill,那Map任务就需要等Spill完成之后才能继续写数据;
如果Kvbuffer到达80%开始Spill,那在Spill的同时,Map任务还能继续写数据,Spill的阈值通过io.sort.spill.percent,默认是0.8。
Sort:
Spill由Spill线程承担,Spill线程从Map任务接到"命令"开始SortAndSpill,SortAndSpill先把Kvbuffer中的数据按照partition值和key两个关键字升序排序,移动的只是索引数据,排序结果是Kvmeta中数据按照partition为单位聚集在一起,同一partition内的按照key有序。
Spill:
Spill线程为此次Spill过程创建一个磁盘文件:从所有的本地目录中轮训查找能存储这么大空间的目录,找到之后在其中创建一个文件。
Spill线程根据排过序的Kvmeta逐个partition的把数据输入到这个文件中,一个partition对应的数据输入完成之后顺序地输入下个partition,直到把所有的partition遍历完。
Combiner:
一个partition在文件中对应的数据叫段(segment),如果用户配置了combiner类,那么在写之前会先调用combineAndSpill(),对结果进行合并后再写出,Combiner会优化MapReduce的中间结果。
partition对应的数据在这个文件中的索引:
有一个三元组记录某个partition对应的数据在这个文件中的索引:起始位置、原始数据长度、压缩之后的数据长度,一个partition对应一个三元组。
这些索引信息存放在内存中,如果内存中放不下,后续的索引信息就需要写到磁盘文件中,文件中不仅存储了索引数据,还存储了crc32的校验数据。
索引文件和数据文件的对应关系:
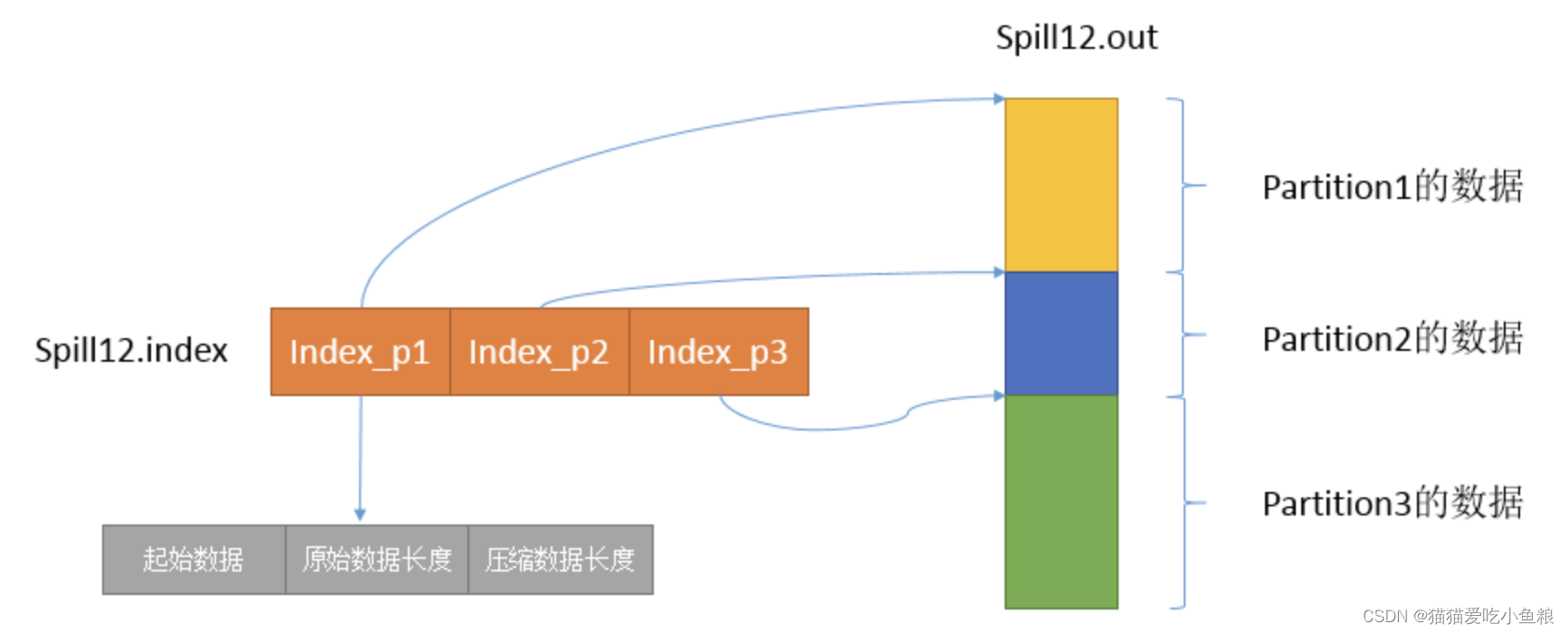
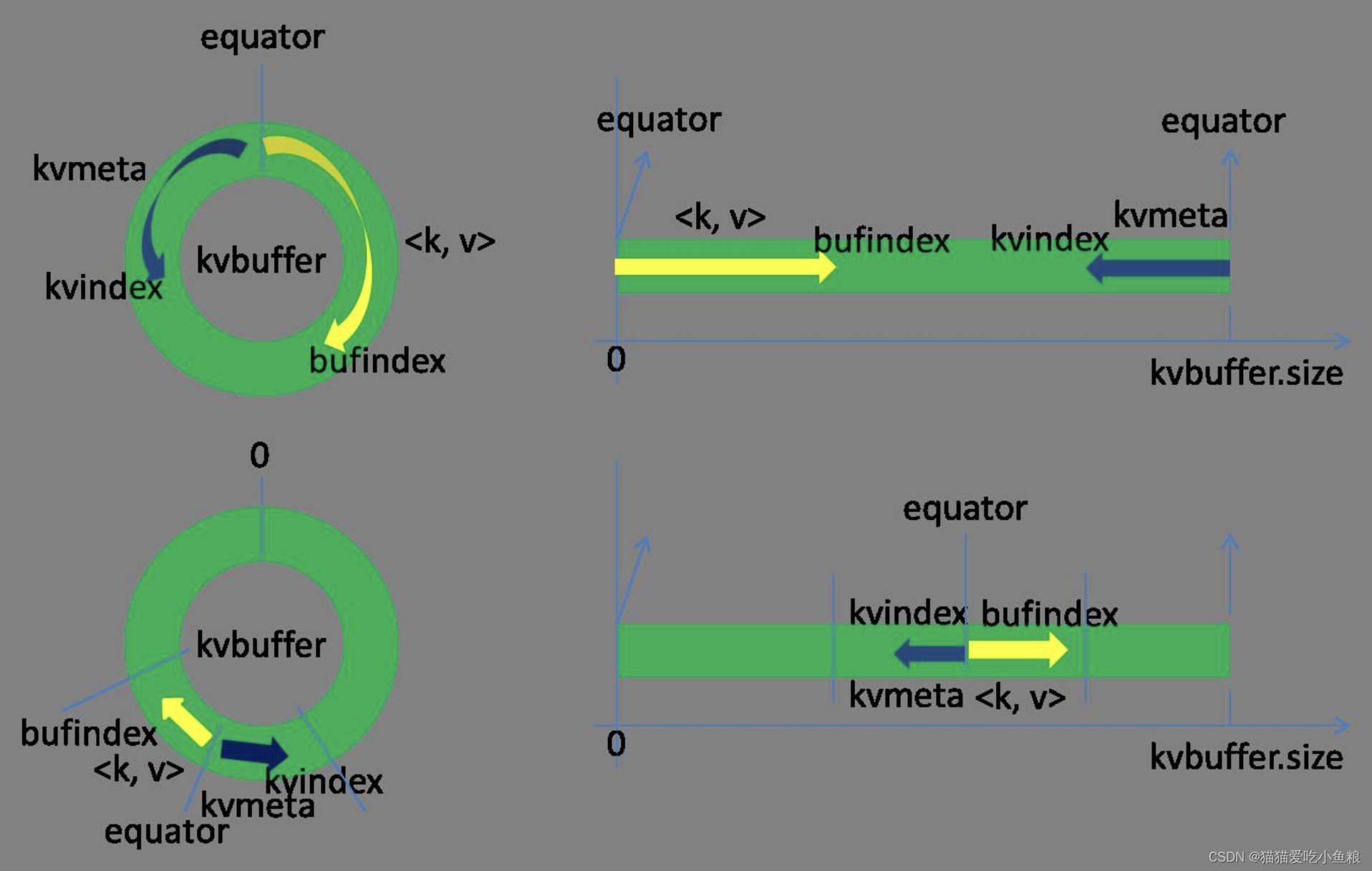
分界点位置:
Map取kvbuffer中剩余空间的中间位置,用这个位置设置为新的分界点,bufindex指针移动到这个分界点,Kvindex移动到这个分界点的-16位置,然后两者就可以按照自己既定的轨迹放置数据了,当Spill完成,空间腾出之后,不需要做任何改动继续前进。
Map任务总要把输出的数据写到磁盘上,即使输出数据量很小在内存中全部能装得下,在最后也会把数据刷到磁盘上。
Merge
Map任务如果输出数据量很大,会进行多次Spill,out文件和Index文件会产生很多,分布在不同的磁盘上,最后把这些文件合并。
Merge过程怎么知道产生的Spill文件都在哪?
从所有的本地目录上扫描得到产生的Spill文件,然后把路径存储在一个数组里。
Merge过程怎么知道Spill的索引信息呢?
从所有的本地目录上扫描得到Index文件,然后把索引信息存储在一个列表里。
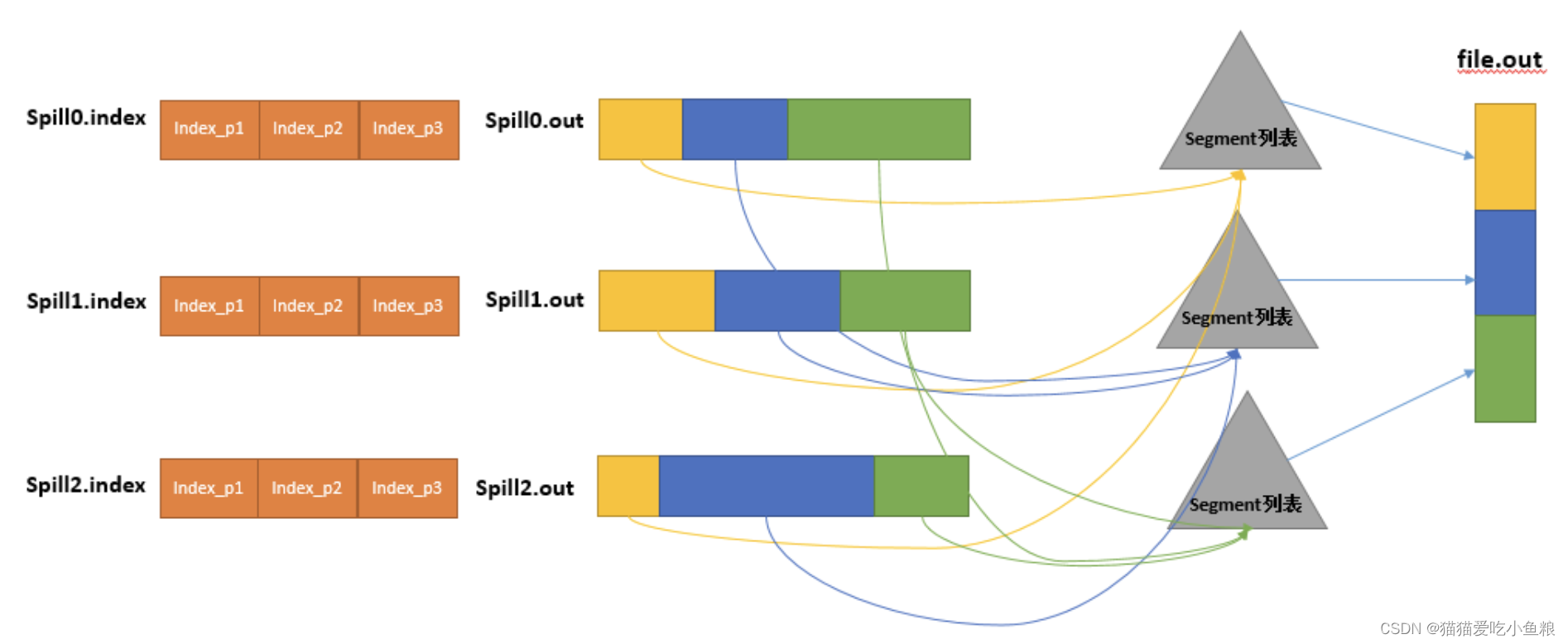
然后为merge过程创建一个 file.out 文件和一个叫 file.out.Index 文件存储最终的输出和索引,一个partition一个partition的进行合并输出。
对于某个partition,从索引列表中查询这个partition对应的所有索引信息,每个对应一个段插入到段列表中,也就是这个partition对应一个段列表,记录所有的Spill文件中对应的这个partition那段数据的文件名、起始位置、长度等。
然后对这个partition对应的所有的segment合并,目标是合并成一个segment,当这个partition对应多个segment时,会分批地进行合并:先从segment列表中把第一批取出来,以key为关键字放置成最小堆,然后从最小堆中每次取出最小的输出到一个临时文件中,这样就把这一批段合并成一个临时的段,把它加回到segment列表中;再从segment列表中把第二批取出来合并输出到一个临时segment,把其加入到列表中;这样往复执行,直到剩下的段是一批,输出到最终的文件中,最终的索引数据仍然输出到Index文件中。
3、Reduce shuffle
在Reduce端,shuffle主要分为复制Map输出、排序合并两个阶段。
1)Copy
Reduce任务通过HTTP向各个Map任务拉取所需要的数据,Map任务成功后,会通知父TaskTracker状态已经更新,TaskTracker进而通知JobTracker(通知在心跳机制中进行)
对于指定作业,JobTracker能记录Map输出和TaskTracker的映射关系。Reduce会定期向JobTracker获取Map的输出位置,一旦拿到输出位置,Reduce任务就会从此输出对应的TaskTracker上复制输出到本地,而不会等所有Map任务结束。
2、Merge Sort
Copy过来的数据会先放入内存缓冲区中,如果内存缓冲区中能放得下这次数据的话就直接把数据写到内存中,即内存到内存merge。
Reduce要向每个Map去拉取数据,在内存中每个Map对应一块数据,当内存缓存区中存储的Map数据占用空间达到一定程度的时候,开始启动内存中merge,把内存中的数据merge输出到磁盘上的一个文件中,即内存到磁盘merge。
在将buffer中多个map输出合并写入磁盘之前,如果设置了Combiner,则会压缩合并的map输出,Reduce的内存缓冲区可通过mapred.job.shuffle.input.buffer.percent配置,默认是JVM的heap size的70%,内存到磁盘merge的启动阈值通过mapred.job.shuffle.merge.percent配置,默认是66%。
当属于该reducer的map输出全部拷贝完成,则会在reducer上生成多个文件(如果拉取的所有map数据总量都没有超过内存缓冲区,则数据就只存在于内存中),开始执行合并操作,即磁盘到磁盘merge,Map的输出数据已经是有序的,Merge进行一次合并排序。
一般 Reduce 是边 copy 边 sort,最终 Reduce shuffle 过程会输出一个整体有序的数据块。
版权归原作者 猫猫爱吃小鱼粮 所有, 如有侵权,请联系我们删除。