
再api测试时,避免不了高并发的测试情况。所以以下案例为线程并发请求代码,以请求百度为例
#!/usr/bin/env python#!coding:utf-8from __future__ import division
from threading import Thread
import requests
import matplotlib.pyplot as plt
import datetime
import time
import numpy as np
import json
classThreadTest(Thread):def__init__(self, func, args=()):"""
:param func: 被测试的函数
:param args: 被测试的函数的返回值
"""super(ThreadTest, self).__init__()
self.func = func
self.args = args
defrun(self):
self.result=self.func(*self.args)defgetResult(self):try:return self.result
except BaseException as e:return e.args[0]deffaultinJection(code, seconds):"""
:param code: 状态码
:param seconds: 请求响应时间
:return:
"""
url ="http://www.baidu.com/"
r = requests.post(url=url)
code = r.status_code
seconds = r.elapsed.total_seconds()return code, seconds
defcalculationTime(startTime,endTime):"""计算两个时间之差,单位是秒"""return(endTime-startTime).seconds
defgetResult(seconds):"""获取服务端的响应时间信息"""
data ={'Max':sorted(seconds)[-1],'Min':sorted(seconds)[0],'Median': np.median(seconds),'99%Line': np.percentile(seconds,99),'95%Line': np.percentile(seconds,95),'90%Line': np.percentile(seconds,90)}return data
defhighConcurrent(count):"""
对服务端发送高并发的请求
:param count: 并发数
:return:
"""
startTime = datetime.datetime.now()sum=0
list_count =list()
tasks =list()
results =list()#失败的信息
fails =[]#成功任务数
success =[]
codes =list()
seconds =list()for i inrange(1, count+1):
t = ThreadTest(faultinJection, args=(i, i))
tasks.append(t)
t.start()for t in tasks:
t.join()if t.getResult()[0]!=200:
fails.append(t.getResult())
results.append(t.getResult())
endTime=datetime.datetime.now()for item in results:
codes.append(item[0])
seconds.append(item[1])for i inrange(len(codes)):
list_count.append(i)#生成可视化的趋势图# fig, ax = plt.subplots()# ax.plot(list_count, seconds)# ax.set(xlabel='number of times', ylabel='Request time-consuming',# title='olap continuous request response time (seconds)')# ax.grid()# fig.savefig('olap.png')# plt.show()for i in seconds:sum+= i
rate =sum/len(list_count)
totalTime = calculationTime(startTime=startTime, endTime=endTime)if totalTime <1:
totalTime =1#吞吐量的计算try:
throughput =int(len(list_count)/totalTime)except Exception as e:
throughput =0print(e.args[0])
getResult(seconds=seconds)
errorrate ="{}%".format(str(len(fails)/len(list_count)*100))
throughput =str(throughput)+'/S'
timeData = getResult(seconds=seconds)
dict1 ={'吞吐量': throughput,'平均响应时间': rate,'响应时间': timeData,'错误率': errorrate,'请求总数':len(list_count),'失败数':len(fails),'总共持续时间':"%0.3fs"%(float((endTime-startTime).total_seconds()))}return json.dumps(dict1, indent=True, ensure_ascii=False)if __name__ =='__main__':print(highConcurrent(count=20))
上面代码执行完之后会生成如下信息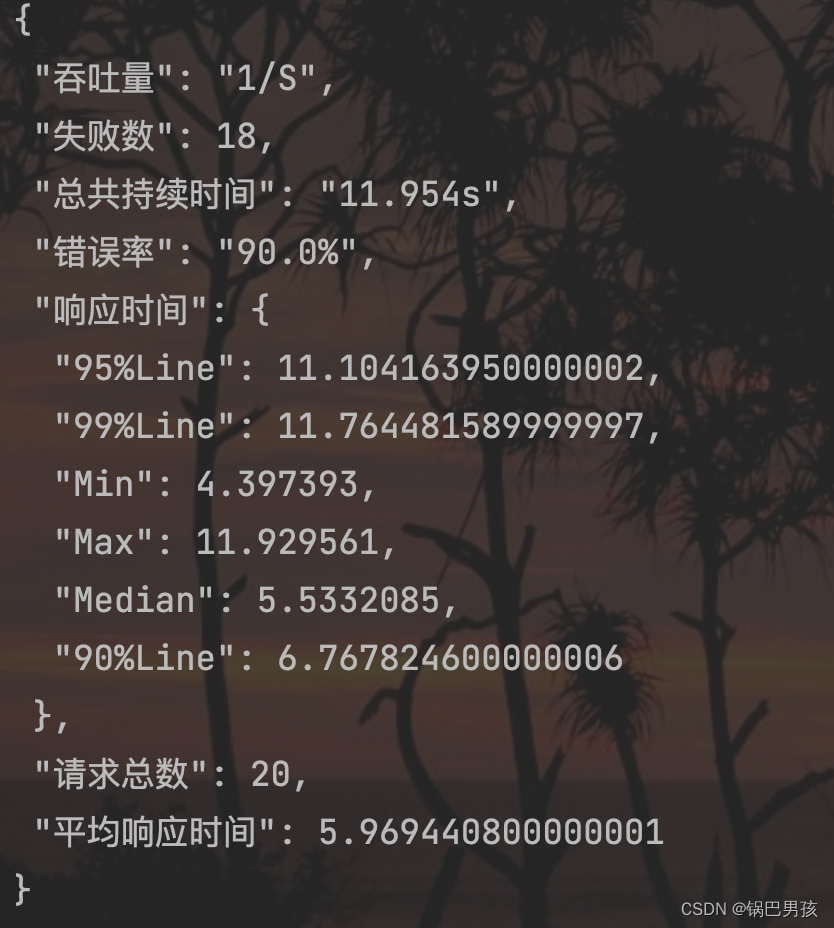
本文转载自: https://blog.csdn.net/weixin_45005012/article/details/126729156
版权归原作者 锅巴男孩 所有, 如有侵权,请联系我们删除。
版权归原作者 锅巴男孩 所有, 如有侵权,请联系我们删除。